
提示
本节课学习目标
- 通过 Linux 案例掌握 CPU、内存、网络、I/O 的基本定位顺序;
- 通过 Windows 案例掌握任务管理器、资源监视器、性能监视器的使用方法;
- 通过 JVM 案例掌握
jps、jstat、jmap、JVisualVM的核心用法; - 建立“先系统、后进程、再 JVM”的性能分析思路。
一、案例一:Windows 测试机执行压测时电脑卡顿
前言
很多学校实训环境、开发联调机、本地测试机都是 Windows。
因此,同学们不能只会 Linux 命令,还必须会使用 Windows 自带的图形化工具完成基础诊断。这个案例的优势是:上手快、可视化强、课堂效果好。
本案例的目标不是讲全 Windows 所有监控功能,而是让同学们学会 3 个最实用的工具:
- 任务管理器
- 资源监视器
- 性能监视器
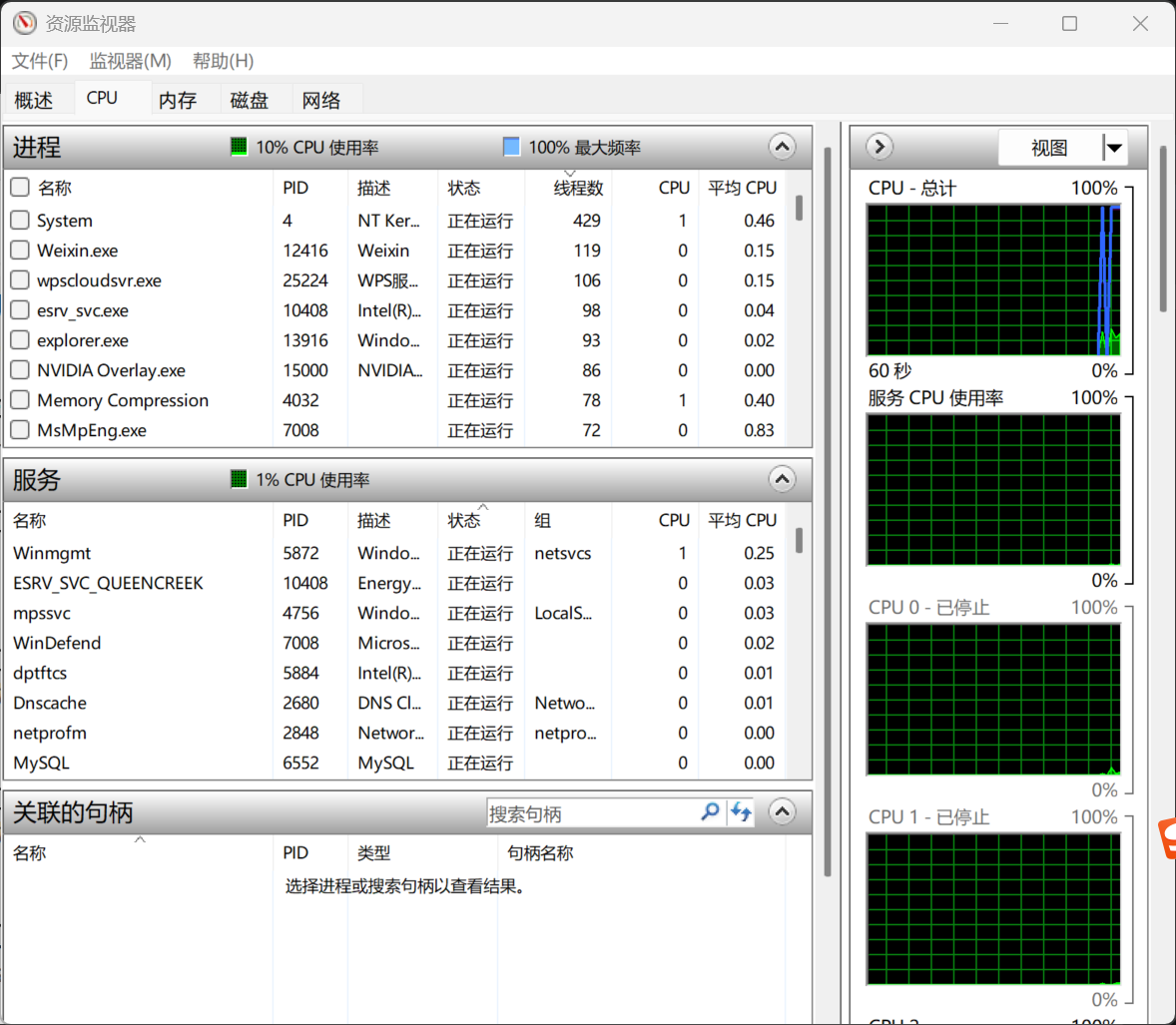
3.1 案例背景
现象
- 本地启动 JMeter 或其他压测工具后,电脑明显卡顿;
- 浏览器打开慢;
- 压测结果不稳定;
- 学生不知道是机器本身慢,还是被测系统慢。
3.2 第一步:先开任务管理器
打开方式:
Ctrl + Shift + Esc- 任务栏右键 -> 任务管理器
重点看两个页签
进程性能
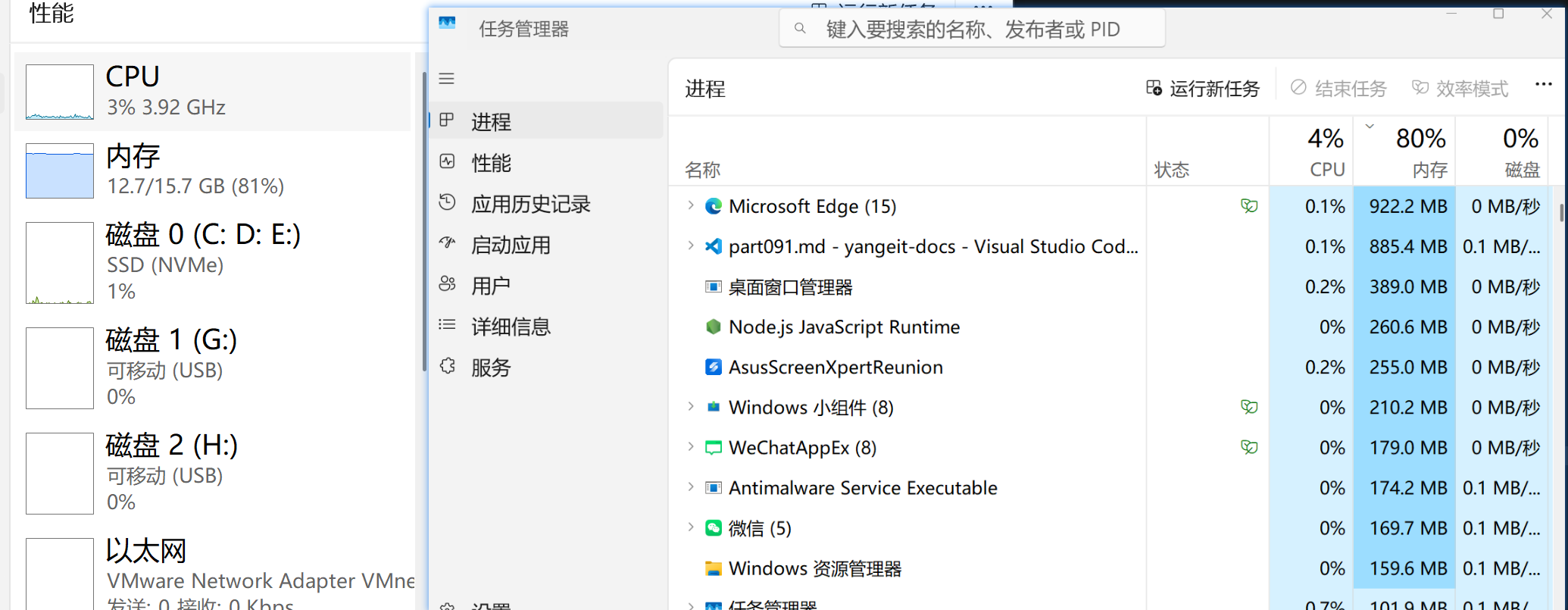
(一)看“进程”页签
课堂上重点让学生做 4 次排序:
- 按
CPU排序 - 按
内存排序 - 按
磁盘排序 - 按
网络排序
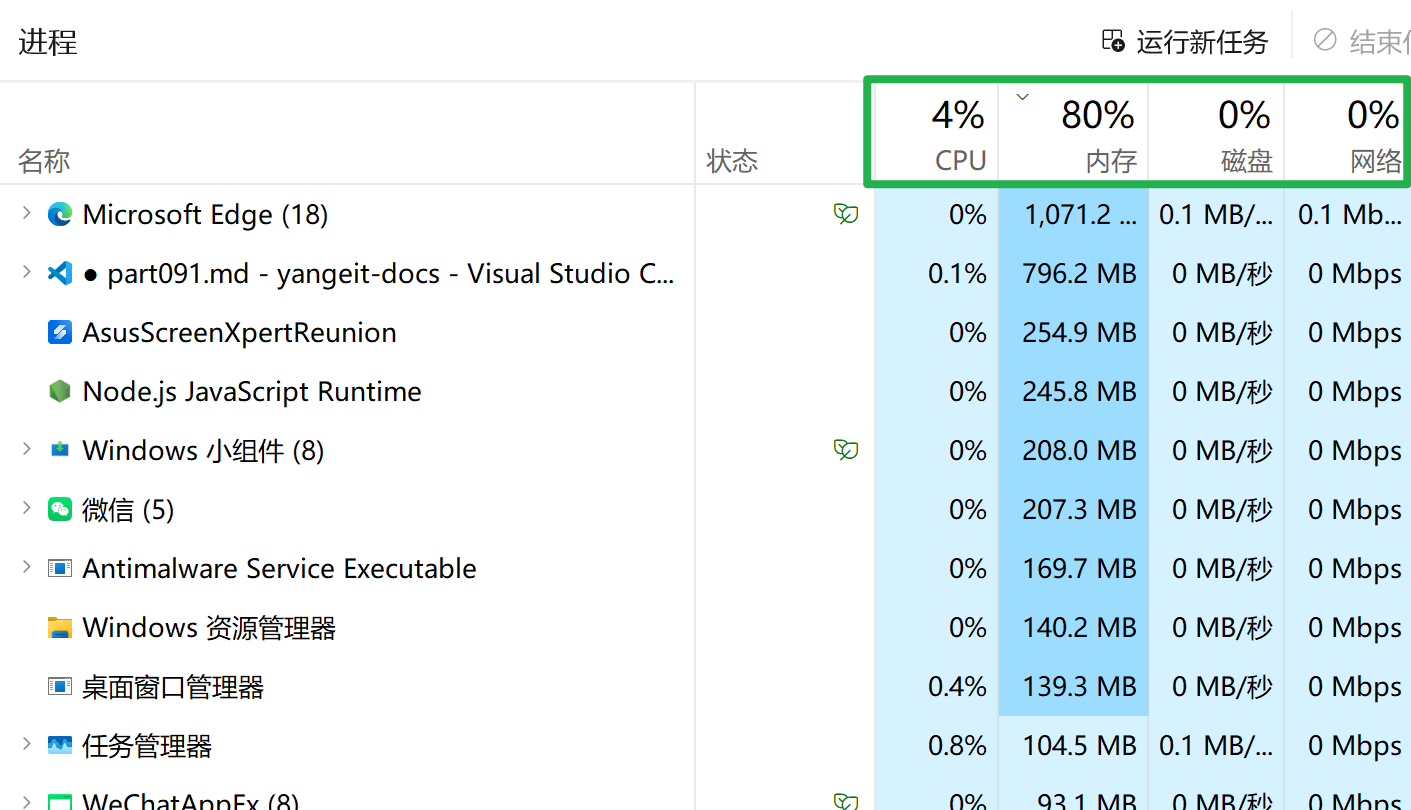
要学会回答
- 当前最吃 CPU 的是谁?
- 当前最占内存的是谁?
- 当前磁盘读写最大的是谁?
- 当前网络发送接收最多的是谁?
(二)看“性能”页签
重点看
- CPU 曲线
- 内存曲线
- 磁盘使用率
- 以太网 / Wi-Fi 流量
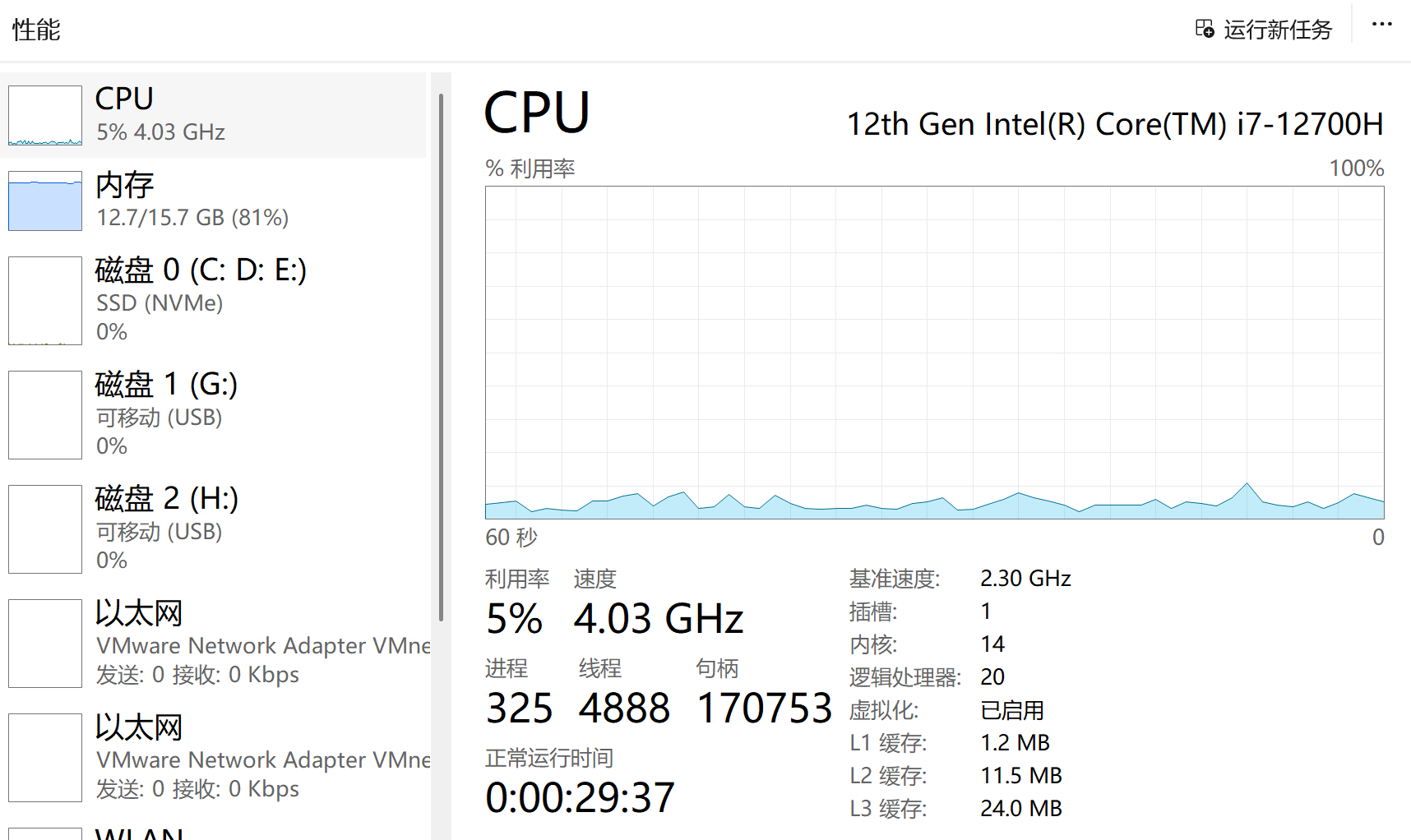
如何判断
- CPU 长时间高,说明整机忙;
- 内存接近打满,说明机器资源紧张;
- 磁盘长期 100%,说明 I/O 压力大;
- 网络峰值明显,说明存在大量数据传输。
3.3 第二步:再看资源监视器
运行:
resmon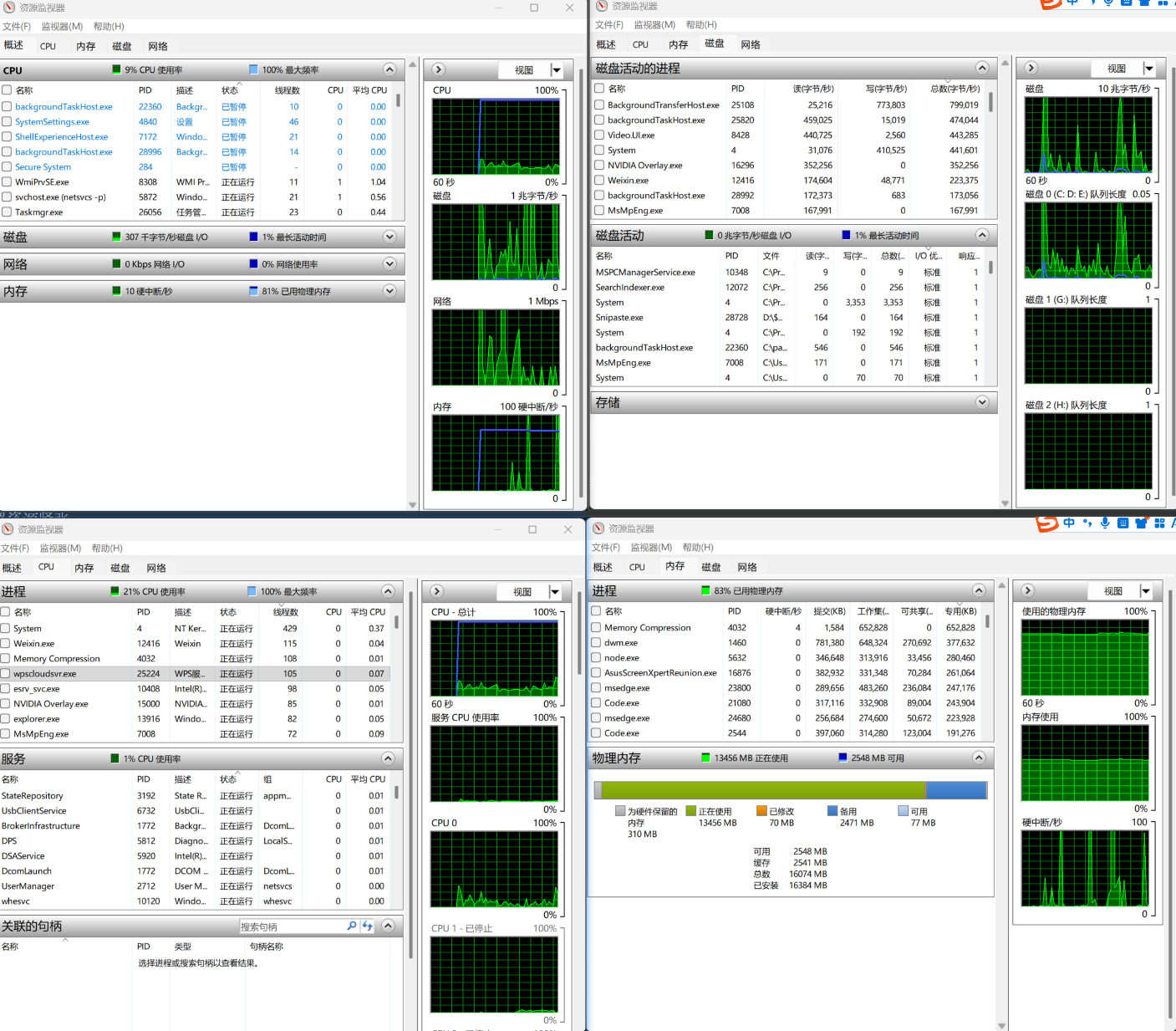
资源监视器比任务管理器更适合做“定位分析”,因为它能细看到:
- 哪个进程在占资源;
- 具体访问了哪些文件;
- 建立了哪些网络连接;
- 内存是否出现硬错误。
(一)CPU 页签
重点任务:
- 找出高 CPU 进程;
- 观察其是否持续高占用;
- 判断是不是
java.exe、chrome.exe、数据库,还是压测工具本身。
(二)内存页签
重点看:
工作集专用硬错误/秒
如何理解
专用高,说明进程自己真实占用的内存较多;硬错误/秒高,说明访问内存时频繁要去磁盘取数据,性能会明显受影响。
(三)磁盘页签
这是 Windows 案例中最值得重点演示的部分。
因为它不仅能看到“谁在读写磁盘”,还能看到“具体哪个文件被大量访问”。
适合排查:
- 日志文件写得太多;
- 临时文件频繁创建;
- 数据库文件读写压力大;
- 杀毒软件扫描影响测试。
(四)网络页签
重点看:
- 哪个进程占用网络;
- 连接到了哪些远程地址;
- 哪些端口处于监听状态。
截图补充建议:补资源监视器“磁盘”页签截图,圈出“进程磁盘活动”和“磁盘活动”区域。
3.4 第三步:需要持续采样时用性能监视器
运行:
perfmon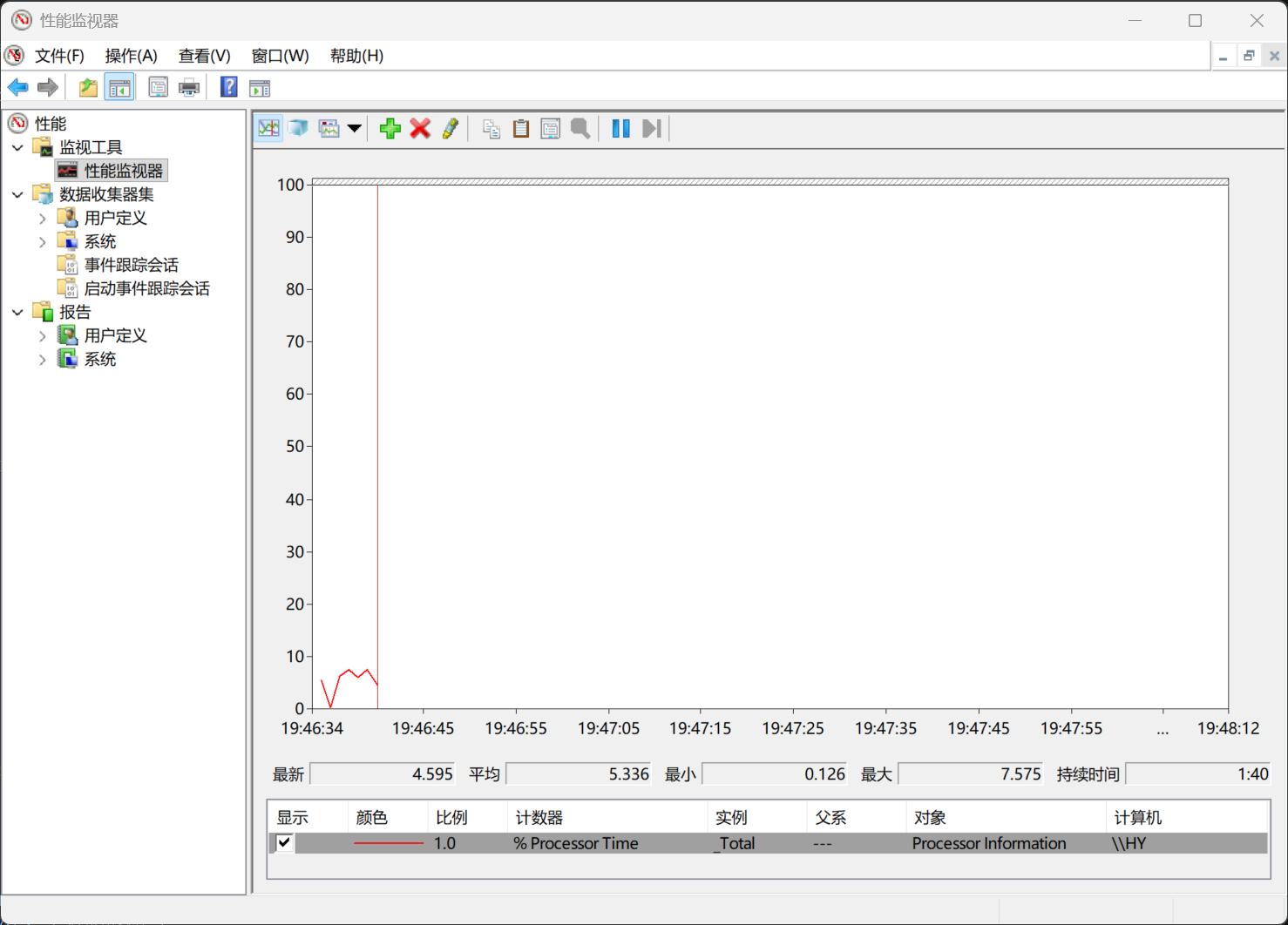
性能监视器的价值在于:
- 不只看瞬时状态;
- 可以观察一段时间的趋势;
- 可以把压测前、中、后的变化记录下来。
加入的计数器
| 类别 | 推荐计数器 | 作用 |
|---|---|---|
| CPU | Processor(_Total)\\% Processor Time | 看总 CPU |
| 内存 | Memory\\Available MBytes | 看可用内存 |
| 磁盘 | PhysicalDisk(_Total)\\% Disk Time | 看磁盘忙碌程度 |
| 磁盘 | PhysicalDisk(_Total)\\Avg. Disk Queue Length | 看磁盘排队 |
| 网络 | Network Interface(*)\\Bytes Total/sec | 看网络吞吐 |
| 进程 | Process(java)\\% Processor Time | 看 Java 进程 CPU |
重点
任务管理器适合“第一眼看问题”,PerfMon 适合“跟踪一段时间看趋势”。
操作如下:👇
## 一、打开性能监视器
1. Win + R → 输入:**perfmon** → 回车
## 二、新建“数据收集器集”(用来长时间记录)
1. 左边展开:**数据收集器集 → 用户定义**
2. 右键“用户定义” → **新建 → 数据收集器集**
3. 名称随便写(比如:**我的性能日志**)→ 选**手动创建(高级)** → 下一步
4. 勾选:**创建数据日志** → 只勾选**性能计数器** → 下一步
5. **添加计数器(要监控什么就加什么)**
点“添加” → 选:
- Processor → %Processor Time → _Total → 添加
- Memory → Available MBytes → 添加
- LogicalDisk → C盘 → Avg. Disk sec/Read → 添加
加完 → 确定
6. **采样间隔**:一般选 **15秒 或 30秒**(越短文件越大)→ 下一步
7. **保存位置**:
默认是:C:\PerfLogs\Admin\你的日志名
可以不改,或改到 D:\Logs 这类 → 下一步
8. 选:**保存并关闭** → 完成
## 三、改成 CSV(方便Excel打开)
1. 左边“用户定义”里,找到你刚建的日志 → 右键 **属性**
2. 切换到 **日志文件** 选项卡
3. 日志格式改成:**逗号分隔(CSV)** → 确定
## 四、开始记录(持续采样)
1. 选中你的日志 → 右键 **开始**
它就会**一直在后台记录**,你可以最小化窗口,正常用电脑。
## 五、停止并找到保存的文件
1. 不记录了 → 右键 **停止**
2. 去文件夹:
C:\PerfLogs\Admin\你的日志名\日期文件夹
里面有 **.csv 文件**,双击直接用Excel打开。二、案例二:Linux 服务器压测后接口变慢
前言
这是企业里最典型的性能定位场景。
压测开始前,接口平均响应时间是 200ms;并发一升高,响应时间上升到 3s~5s。这时候测试工程师不能只给出一句“系统变慢了”,而是要继续回答:
- 系统哪里慢?
- 是 CPU 忙,还是内存不够?
- 是网络异常,还是磁盘 I/O 堵住了?
- 是系统层问题,还是 Java 进程问题?
本案例的目标,就是带同学们把这条链路走一遍。
2.1 案例背景
现象
- JMeter 压测过程中响应时间突然升高;
- 吞吐量下降;
- 少量请求开始超时;
- Linux 服务器还能登录,但感觉明显变慢。
测试目标
在最短时间内判断,问题主要落在下面哪一类资源上:
- CPU
- 内存
- 网络
- I/O
2.2 Linux 案例的定位顺序
推荐按下面顺序排查:
top
free -h
vmstat 1 5
ss -s
iostat -x 1 5
pidstat -u 1 5
pidstat -d 1 5这组命令不是随便堆的,而是对应 4 类资源:
| 命令 | 主要看什么 | 用来判断什么 |
|---|---|---|
top | CPU、负载、进程总览 | 系统整体忙不忙 |
free -h | 可用内存、Swap | 是否内存紧张 |
vmstat 1 5 | Swap、等待、运行队列 | 是否发生交换或阻塞 |
ss -s | TCP 连接状态 | 连接数是否堆积 |
iostat -x 1 5 | 磁盘利用率、等待时间 | 是否 I/O 成为瓶颈 |
pidstat -u 1 5 | 进程 CPU | 谁最耗 CPU |
pidstat -d 1 5 | 进程 I/O | 谁在大量读写磁盘 |
2.3 第一步:先看 top
top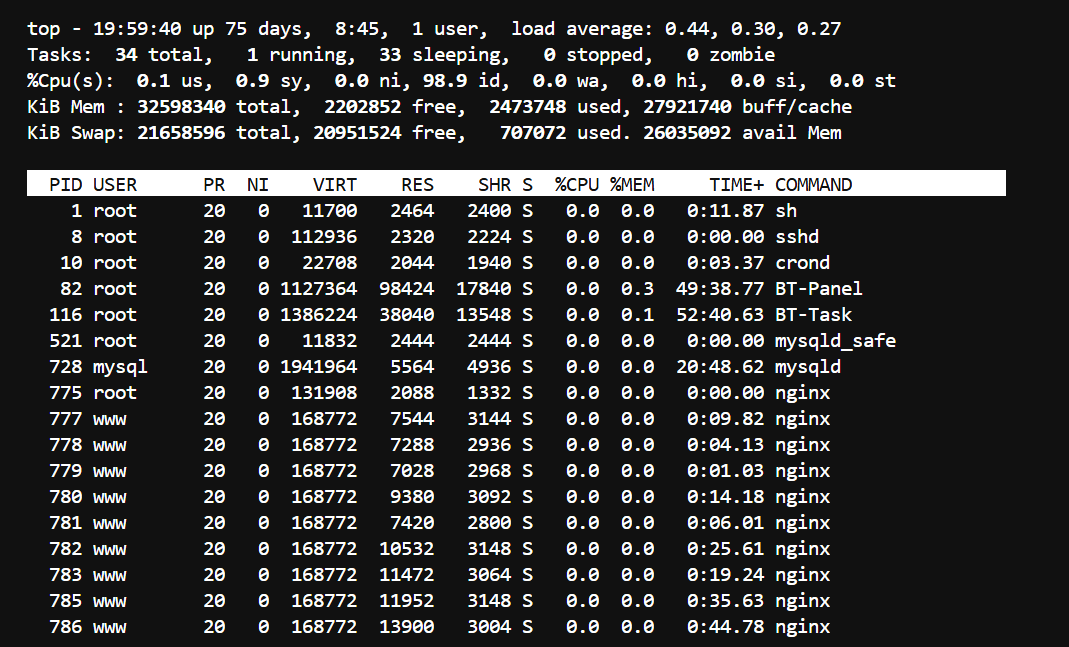
重点看 3 个地方
load average最近1分钟,最近5分钟,最近15分钟的平均负载;%Cpu(s): us sy id wa- 进程列表里谁排在最前面
如何理解
load average高,说明系统里排队任务多;us高,说明业务程序本身在占用 CPU;sy高,说明系统内核工作较多;wa高,说明 CPU 很多时间在等磁盘 I/O,不要误判成纯 CPU 问题;- 若
java进程排在最前面,下一步要考虑 JVM 分析。
重点
看到 CPU 高就下结论“CPU 不够”,这是不严谨的。
真正要看的是:CPU 真的在算,还是在等磁盘。
2.4 第二步:看内存和交换区
free -h
vmstat 1 5free -h 重点看
total used free shared buff/cache available
Mem: 31G 2.4G 2.1G 350M 26G 24G
Swap: 20G 690M 19G
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 707072 2194572 1499504 26425804 0 0 13 5 0 0 0 1 99 0 0
3 0 707072 2194564 1499504 26425804 0 0 0 5 1853 1327 0 2 98 0 0
0 0 707072 2194564 1499504 26425804 0 0 0 0 1354 1034 0 1 99 0 0
0 0 707072 2194564 1499504 26425804 0 0 0 0 758 938 0 0 100 0 0
0 0 707072 2195408 1499504 26425804 0 0 0 184 1605 4360 0 0 100 0 031G 大内存,程序只占用 2.4G,还剩 24G 可用,几乎不用虚拟内存,内存非常充足,毫无压力
availableswap
vmstat 1 5 每1 秒采样 1 次,一共采样5 行性能数据
si从 swap 读入内存so从 swap 读入内存rr 就绪队列:最多出现 3 最多有 3 个进程等着跑 CPU,压力很小bb 阻塞队列:一直是 0 没有进程卡在磁盘 IO 等待,无 IO 阻塞
如何判断
available很低,说明可用内存紧张;swap持续增大,说明物理内存开始不够;si/so持续不为 0,说明正在频繁交换;r很大,说明运行队列长;b很大,说明有很多进程在等待不可中断资源,常见于 I/O 等待。
重点
Linux 中“已用内存高”不一定有问题,因为系统会拿空闲内存做缓存。
真正重要的是 可用内存 和 是否开始 Swap。
2.5 第三步:看网络连接有没有堆积
netstat -an | wc -l结果:58 表示当前有 58 个 TCP 连接
重点
网络问题不一定表现为“完全不通”,更多时候是:
- 连接太多;
- 队列堆积;
- 重传或延迟变高。
2.6 第四步:重点看 I/O
iostat -x 1 5
pidstat -d 1 5iostat -x 1 5 重点看
%utilawaitavgqu-sz
pidstat -d 1 5 重点看
- 哪个进程读磁盘多;
- 哪个进程写磁盘多;
- 是否是
java、数据库或日志程序在持续读写。
如何判断
%util长时间接近100%,说明磁盘非常忙;await高,说明 I/O 请求等待时间长;avgqu-sz高,说明磁盘前面排队严重;- 如果
java写磁盘很高,要怀疑日志过多、文件处理或 GC 日志。
重点
很多“CPU 不高但系统很慢”的问题,最后根因其实在磁盘 I/O。
2.7 第五步:锁定高占用进程
pidstat -u 1 5 #每个进程 CPU 占用 每1 秒采样 1 次,一共采样5 行性能数据
pidstat -d 1 5 #看 每个进程 磁盘 IO 读写目的
前面看的是系统整体,这一步要回答:
到底是哪一个进程把资源吃掉了?
如何判断
- 某个
java进程 CPU 高,后续进入 JVM 分析; - 某个数据库进程 I/O 高,后续查数据库;
- 某个日志程序写磁盘高,后续查日志策略;
- 如果没有明显高进程,说明问题可能更偏网络、外部依赖或锁等待。
2.8 Linux 案例结论模板
模板输出结论:
- 压测过程中系统变慢;
top显示wa偏高;iostat -x 1 5显示磁盘%util接近100%,await明显升高;pidstat -d 1 5发现java进程写磁盘较高;- 初步判断:系统瓶颈主要在 磁盘 I/O,并且与
java进程磁盘写入有关; - 下一步建议:继续查看应用日志、GC 日志或文件写入逻辑。
这比一句“服务器有点慢”专业得多。
三、案例三:Java 服务内存持续升高,怀疑 JVM 异常
前言
前两个案例解决的是“系统层面”的问题,但如果系统层看下来没有特别明显的瓶颈,或者已经确认高占用进程就是 java,就必须进入 JVM 监控。
这部分是本章难点,但只要抓住一条主线,零基础同学也能学会:
先找 Java 进程,再看 GC,再看对象。
这就是本案例的核心。
4.1 案例背景
现象
- Java 服务运行一段时间后内存越来越高;
- 压测持续 10 分钟后响应时间明显上升;
- 系统层面没有特别严重的 CPU、网络问题;
- 怀疑是 JVM 堆内存或 GC 出现异常。
本案例目标
- 找到目标 Java 进程;
- 判断 GC 是否频繁;
- 判断老年代是否回收不掉;
- 判断是否需要做对象分析。
4.2 演示用 jar 说明
后台执行指令:nohup java -jar performance-test-server.jar > server.log 2>&1 &
前台执行:java -jar performance-test-server.jar
(一)接口总览
| 接口 | 方法 | 作用 | 课堂用途 |
|---|---|---|---|
/jvm/demo/leak-bytes | GET | 持续向堆中追加 byte[] | 演示堆内存上涨、GC 次数变化 |
/jvm/demo/leak-users | GET | 持续向堆中追加业务对象 LeakUser | 演示 jmap -histo 中业务类对象增长 |
/jvm/demo/status | GET | 查看当前缓存数量和堆内存使用情况 | 边调接口边看内存变化 |
/jvm/demo/clear | POST | 清空缓存并触发一次 System.gc() | 便于重复演示和前后对比 |
(二)接口 1:制造 byte[] 内存堆积
GET /jvm/demo/leak-bytes?count=50&kb=512参数说明:
count:本次创建多少个数组;kb:每个数组占多少 KB。
示例理解:
count=50kb=512
表示本次大约向堆中新增 50 x 512KB 的数据,也就是约 25MB 左右。
这个接口适合演示:
status中heapUsedMB持续上升;jstat -gcutil中YGC、FGC的变化;- 堆越来越满后,GC 压力逐渐增大。
(三)接口 2:制造业务对象堆积
GET /jvm/demo/leak-users?count=200&payloadKb=32参数说明:
count:本次创建多少个LeakUser对象;payloadKb:每个对象里附带多大的文本内容。
这个接口的特点是:
- 不只是产生
byte[],还会产生自定义业务对象; - 便于后续执行
jmap -histo:live <pid>时看到LeakUser、String等对象增长; - 更贴近“缓存没清理、业务对象越积越多”的真实场景。
(四)接口 3:查看当前内存状态
GET /jvm/demo/status返回结果中重点关注:
byteCacheBlocksuserCacheSizeheapUsedMBheapTotalMBheapMaxMB
课堂上可以这样讲:
- 先调用一次
status,记录初始堆内存; - 再多次调用
leak-bytes或leak-users; - 然后再次调用
status,对比heapUsedMB是否明显升高。
(五)接口 4:清空缓存,便于重复实验
POST /jvm/demo/clear作用:
- 清空
byte[]缓存; - 清空
LeakUser缓存; - 主动调用一次
System.gc(); - 方便重新开始一轮课堂演示。
演示顺序
可以按下面顺序:
- 先调用一次
GET /jvm/demo/status,让同学看初始堆大小; - 连续调用几次
GET /jvm/demo/leak-bytes?count=50&kb=512; - 再调用一次
GET /jvm/demo/status,让同学看heapUsedMB的变化; - 接着执行
jps -l找到 Java 进程; - 执行
jstat -gcutil <pid> 1000 10看 GC 情况; - 再连续调用几次
GET /jvm/demo/leak-users?count=200&payloadKb=32; - 执行
jmap -histo:live <pid> | head -n 20观察对象分布; - 如果环境允许,打开
JVisualVM看 Heap 曲线; - 最后调用
POST /jvm/demo/clear做收尾和对比。
4.3 第一步:先用 jps 找 Java 进程
jps -l
结果:
16785 jdk.jcmd/sun.tools.jps.Jps
16558 performance-test-server.jar作用
- 列出当前机器上所有 Java 进程;
- 看清楚到底是哪一个服务;
- 记下后续分析所需的
PID。
重点
机器上有 java.exe 或 java,就不知道下一步怎么跟。jps -l 的作用,就是把“Java 这个大概念”变成“某个具体进程号”。
4.4 第二步:用 jstat 看 GC 和堆变化
#Java 专用的 GC 持续性能监控命令 -gcutil:看 GC 垃圾回收 百分比 ,每 1 秒采样一次,连续采样 10 次
jstat -gcutil <pid> 1000 10
结果:
[root@pch18-baota-1 ~]# jstat -gcutil 16558 1000 10
S0 S1 E O M CCS YGC YGCT FGC FGCT CGC CGCT GCT
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023
0.00 100.00 23.75 2.21 96.75 90.47 4 0.019 0 0.000 4 0.003 0.023重点看 4 列
OYGCFGCGCT
如何理解
O:老年代使用率;YGC:Young GC 次数;FGC:Full GC 次数;GCT:GC 总耗时。
如何判断
YGC增长很快,说明对象创建速度快;FGC持续增加,说明老年代压力大;O长时间很高,说明老年代对象积压;- GC 之后老年代仍然降不下来,要警惕内存泄漏或缓存堆积。
重点
对于初学者,不需要一开始就讲太深的 GC 原理,先看结论:
- GC 是否频繁;
- Full GC 是否在增加;
- 老年代是否一直降不下来。
4.5 第三步:用 jmap 看对象分布
如果通过 jstat 已经怀疑有内存积压,下一步可以执行:
jmap -histo:live <pid> | head -n 20
结果:
[root@pch18-baota-1 ~]# jmap -histo:live 16558 | head -n 20
num #instances #bytes class name (module)
-------------------------------------------------------
1: 43754 2569160 [B (java.base@11.0.19)
2: 40742 977808 java.lang.String (java.base@11.0.19)
3: 25367 811744 java.util.concurrent.ConcurrentHashMap$Node (java.base@11.0.19)
4: 6803 807288 java.lang.Class (java.base@11.0.19)
5: 6714 590832 java.lang.reflect.Method (java.base@11.0.19)
6: 13950 446400 java.util.HashMap$Node (java.base@11.0.19)
7: 4491 396680 [Ljava.util.HashMap$Node; (java.base@11.0.19)
8: 6893 376184 [Ljava.lang.Object; (java.base@11.0.19)
9: 7811 312440 java.util.LinkedHashMap$Entry (java.base@11.0.19)
10: 3655 284408 [I (java.base@11.0.19)
11: 239 258736 [Ljava.util.concurrent.ConcurrentHashMap$Node; (java.base@11.0.19)
12: 8959 208592 [Ljava.lang.Class; (java.base@11.0.19)
13: 12970 207520 java.lang.Object (java.base@11.0.19)
14: 3229 180824 java.util.LinkedHashMap (java.base@11.0.19)
15: 2573 123504 java.util.HashMap (java.base@11.0.19)
16: 1886 90528 java.lang.invoke.MemberName (java.base@11.0.19)
17: 1950 78000 java.lang.ref.SoftReference (java.base@11.0.19)
18: 1476 70848 sun.util.locale.LocaleObjectCache$CacheEntry (java.base@11.0.19)结果显示:内存占用极低、无异常大对象、无内存泄漏迹象,项目处于极轻量健康状态。
作用
- 看哪些类的对象最多;instances 就是这个类在内存里创建了多少个实例
- 看哪些对象占内存最大;bytes 就是这个类在内存里占用了多少字节
- 辅助判断是不是集合、缓存、数组等对象异常堆积。
例如:
byte[]很多,可能与缓存、文件、网络数据有关;char[]很多,可能与字符串处理有关;HashMap、ArrayList很多,可能与集合堆积有关;- 某个业务对象特别多,说明具体业务模块值得重点排查。
4.6 第四步:用 JVisualVM 图形化验证
如果环境允许,可以继续演示 JVisualVM。
下载地址:https://visualvm.github.io/download.html
操作步骤
- 启动
jvisualvm; - 连接本地 Java 进程;
- 打开
Monitor页签; - 观察 Heap、Threads、CPU 曲线;
- 如有需要,再看
Sampler。
可以先访问上面的链接,然后再查看
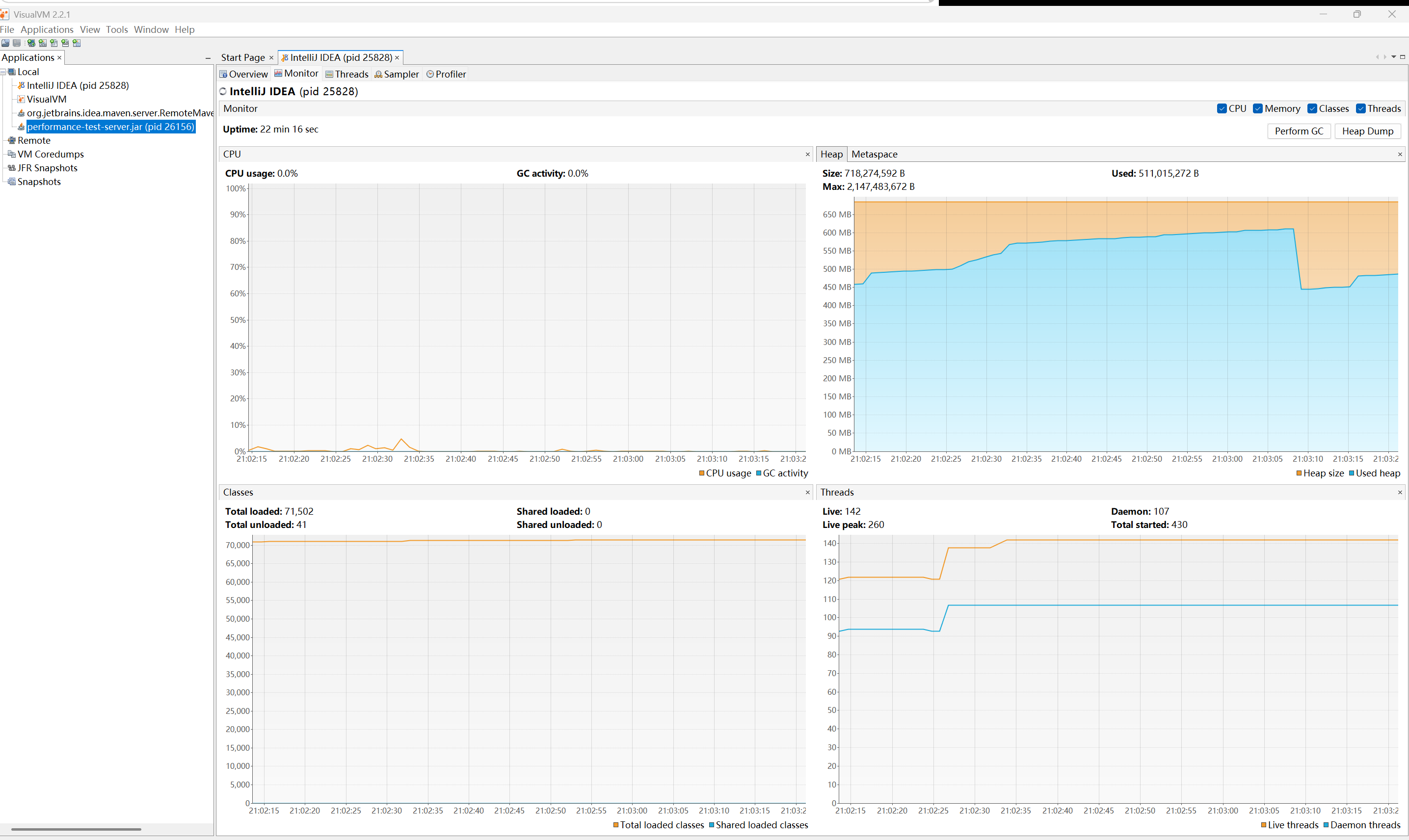
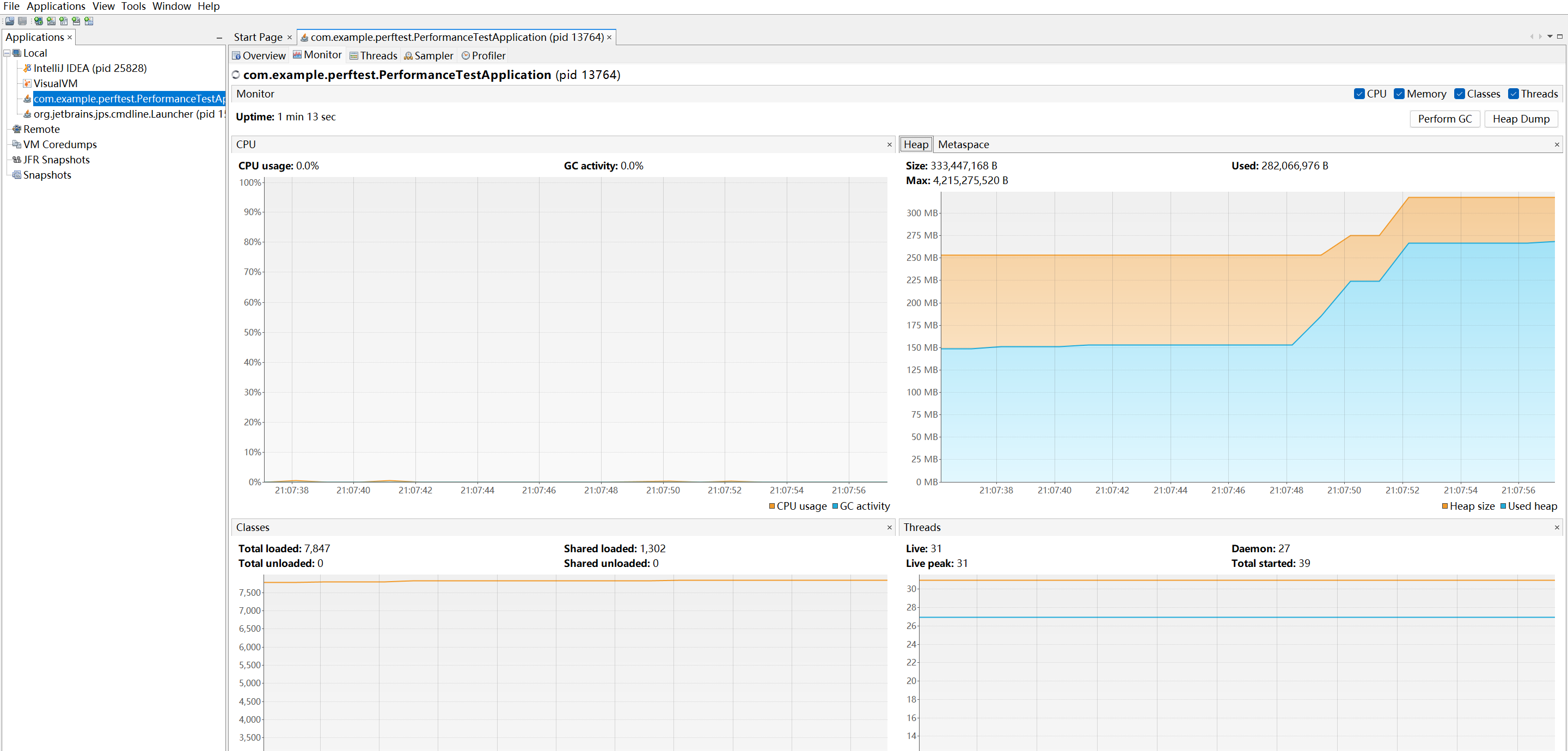
重点观察
- Heap 曲线是否一直上涨;
- GC 后是否能回落;
- 线程数是否异常增加;
- CPU 是否长期较高。
重点
命令行工具更适合快速确认,图形化工具更适合让学生“看见变化过程”。
4.7 JVM 案例结论模板
课堂上可以这样输出结论:
- 通过
jps -l确认目标 Java 服务 PID; jstat -gcutil显示FGC增加、O长时间较高;- 初步判断 JVM 老年代压力较大;
jmap -histo:live发现某类对象数量明显偏多;JVisualVM中 Heap 曲线持续升高且 GC 后回落不明显;- 初步结论:Java 服务存在对象积压或内存泄漏风险;
- 下一步建议:检查缓存策略、集合使用、对象生命周期。
4.8 课堂任务
- 执行
jps -l; - 选择一个 Java 进程执行
jstat -gcutil <pid> 1000 10; - 观察
O、YGC、FGC的变化; - 执行
jmap -histo:live <pid> | head -n 20; - 如果环境允许,打开
JVisualVM观察 Heap 曲线。