浏览器代理
浏览器代理
提示
- 完成浏览器代理本地部署,解决部署中的常见问题;
- 掌握基于Java+Selenium的DOM交互、页面元素操作;
- 实现浏览器代理与文件系统的交互(文件上传、截图保存);
- 掌握在线网站的浏览器代理操作,贴合实际工作场景。
一、理论知识
前言
1.1 浏览器代理核心定义
浏览器代理是介于用户(Java代码)与浏览器之间的中间服务/工具,本质是通过“驱动程序”建立代码与浏览器的通信桥梁,实现对浏览器的自动化控制(如页面操作、DOM交互、文件读写),核心作用是替代人工完成重复的浏览器操作,常用于自动化测试、数据爬取、页面监控等场景。
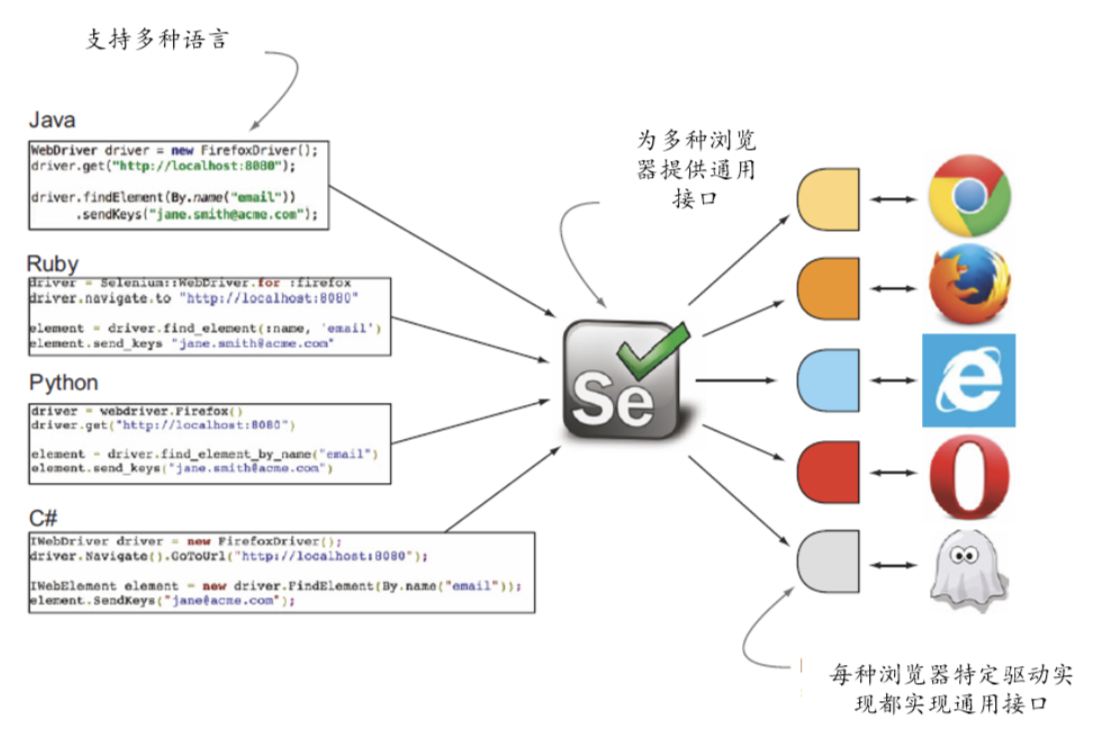
1.2 浏览器代理核心架构
浏览器代理的正常运行依赖“控制端(Java代码)→ 驱动程序 → 浏览器”三者的协同,缺一不可:
控制端:基于Java语言+Selenium框架编写的代码,负责发送操作指令(如打开页面、点击元素);
驱动程序 (如ChromeDriver):核心桥梁,将Java代码的指令转换为浏览器可识别的信号,同时将浏览器的执行结果反馈给控制端,需与浏览器版本完全匹配;
浏览器 (如Chrome):执行控制端发送的指令,完成页面加载、元素交互等操作,是实操的载体。
1.3 核心技术基础
Selenium框架:Java操作浏览器代理的核心工具,提供了一系列API用于定位页面元素、操作DOM、控制浏览器行为,无需关注底层通信细节;
驱动管理 :两种方式——手动指定驱动路径、通过WebDriverManager自动管理(推荐,可自动匹配浏览器版本,无需手动下载驱动);
开发中一般使用Python 操作驱动,由于计科班级没有学习Python,因此这里使用Java进行操作,原理一致。👈
- DOM交互:Document Object Model(文档对象模型),将HTML页面解析为树形结构,浏览器代理通过操作DOM元素(如输入文本、点击按钮)实现页面交互;
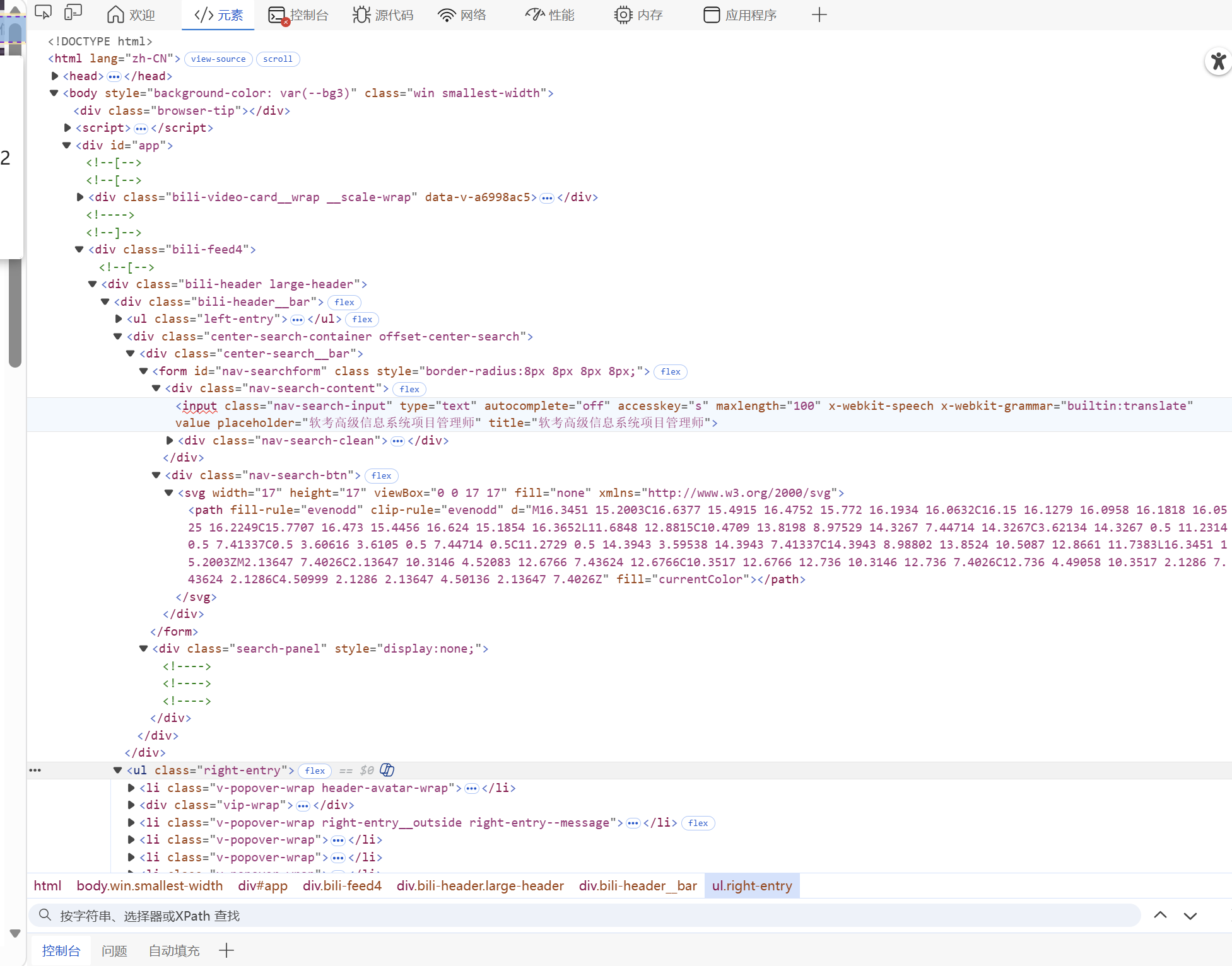
文件系统交互:通过浏览器代理实现本地文件上传(向页面控件传入文件路径)、页面截图保存(将浏览器页面转为本地文件),依赖Java IO操作和相关工具类(如FileUtils)。
与Selenium IDE的核心区别:Selenium IDE是Chrome/Firefox浏览器的插件,而本次学习的Java+Selenium是代码级别的浏览器代理操作,两者定位、功能、适用场景差异显著,具体对比如下:
- ① 定位不同 :Selenium IDE是可视化工具,无需编写代码,通过鼠标录制操作步骤,适合快速生成简单的自动化脚本;Java+Selenium是代码级操作,需手动编写Java代码,灵活性更高,可实现复杂的自动化逻辑。
- ② 功能复杂度 :Selenium IDE功能简单,仅支持基础的页面操作录制、回放,无法实现复杂的逻辑控制(如循环、条件判断、异常处理);Java+Selenium可通过Java语法实现复杂逻辑,支持多浏览器控制、数据驱动、文件交互等高级功能。
- ③ 适用场景 :Selenium IDE适合快速原型验证、简单的自动化操作(如重复提交表单),适合非开发人员使用;Java+Selenium适合企业级自动化测试、复杂数据爬取、规模化批量操作,适合开发、测试、数据相关从业人员使用。
- ④ 扩展性: Selenium IDE扩展性差,无法集成其他工具(如测试框架、报表工具);Java+Selenium可集成Maven、TestNG、JUnit等工具,实现脚本管理、测试报告生成、持续集成,适配企业级开发测试流程。
- ⑤ 维护成本 :Selenium IDE录制的脚本可维护性低,页面元素变化后需重新录制;Java+Selenium编写的脚本可维护性高,元素定位、操作逻辑可单独修改,适配项目迭代。
1.4 浏览器代理的用途与工作场景
学习浏览器代理并非单纯掌握技术操作,更核心是理解其实际应用价值,其用途围绕“自动化、高效化、规模化”展开,常见工作场景覆盖多个领域,具体如下:
1. 核心用途:
- 自动化测试:替代人工完成网页功能测试(如表单提交、页面跳转、元素交互),适用于Web项目迭代后的回归测试,提升测试效率、减少人工误差;
- 数据爬取与采集:批量获取网页公开数据(如商品信息、新闻内容、行业数据),通过浏览器代理模拟正常用户操作,规避部分网站的反爬限制;
- 页面监控与预警:实时监控网页状态(如页面可用性、内容更新、链接有效性),当出现异常时自动触发提醒,适用于网站运维场景;
- 批量操作自动化:完成重复的浏览器操作(如批量注册、批量提交表单、批量下载文件),节省人工成本,提升工作效率;
1.跨环境兼容性测试:通过代理控制不同浏览器(Chrome、Firefox等)、不同版本浏览器,快速测试网页在不同环境下的展示和交互效果。
1.5 核心注意事项
- 版本兼容:驱动程序(ChromeDriver)与浏览器(Chrome)版本必须完全匹配,否则无法建立连接;
- 路径规范:Java代码中文件路径需使用双反斜杠(
\\)或正斜杠(/),避免路径解析错误; - 依赖配置:Maven项目需正确导入Selenium、WebDriverManager、commons-io等依赖,否则代码无法正常运行;
- 异常处理:操作浏览器时需添加try-catch-finally结构,确保浏览器无论是否报错都能正常关闭,释放资源;
- 合规性提醒:使用浏览器代理进行数据爬取或操作时,需遵守目标网站的robots协议,不得爬取涉密、违规数据,避免违反相关法律法规。
二、实操环境准备
前言
前置要求:具备基础HTML、JavaScript、Java基础(面向对象、IO操作),了解浏览器基本工作原理。
1.环境准备
- 浏览器:Chrome浏览器(版本120+),避免低版本出现兼容性问题;
- 驱动程序:ChromeDriver(与Chrome浏览器版本完全匹配)
- 开发环境:JDK17(配置环境变量)、IntelliJ IDEA;
- 依赖管理:Maven3.9.5(用于自动导入项目依赖);
- 辅助素材:上述3个本地测试HTML文件、测试图片(用于文件上传实操)。
2. 创建项目
1. 创建一个Maven项目,命名为BrowserProxyTest
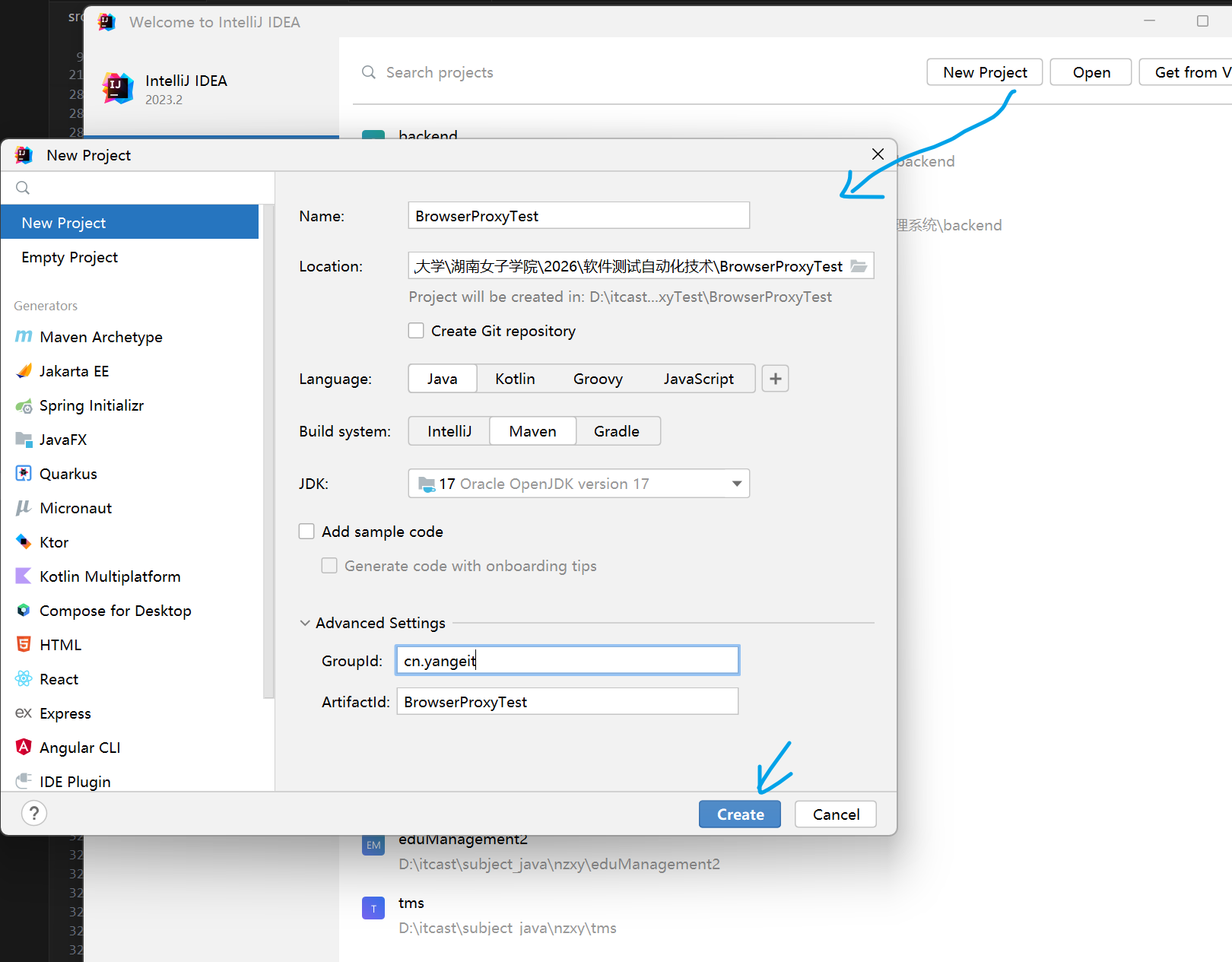
在java目录下创建cn.yangeit的包
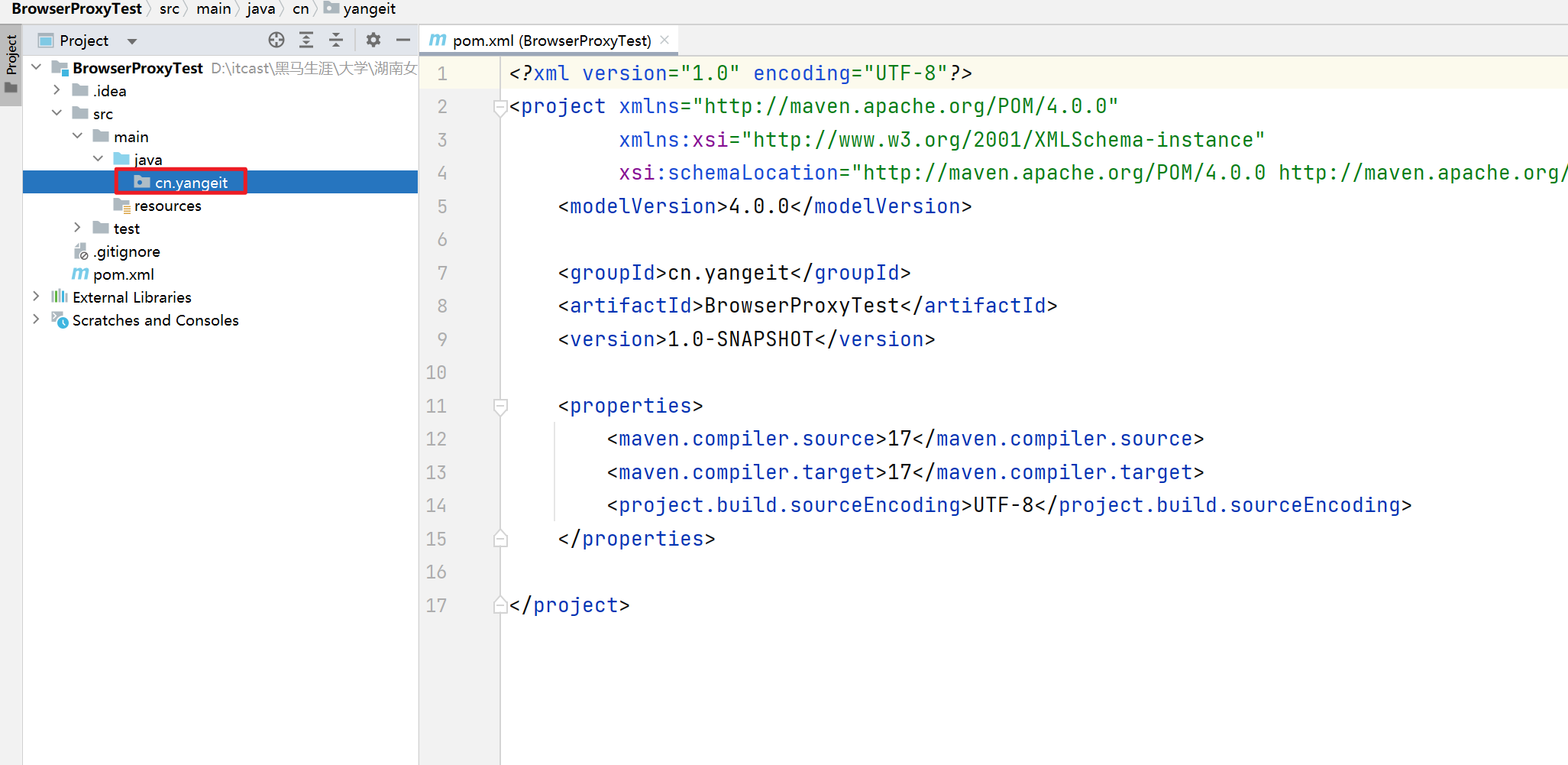
2. 打开Idea,设置统一的Maven环境
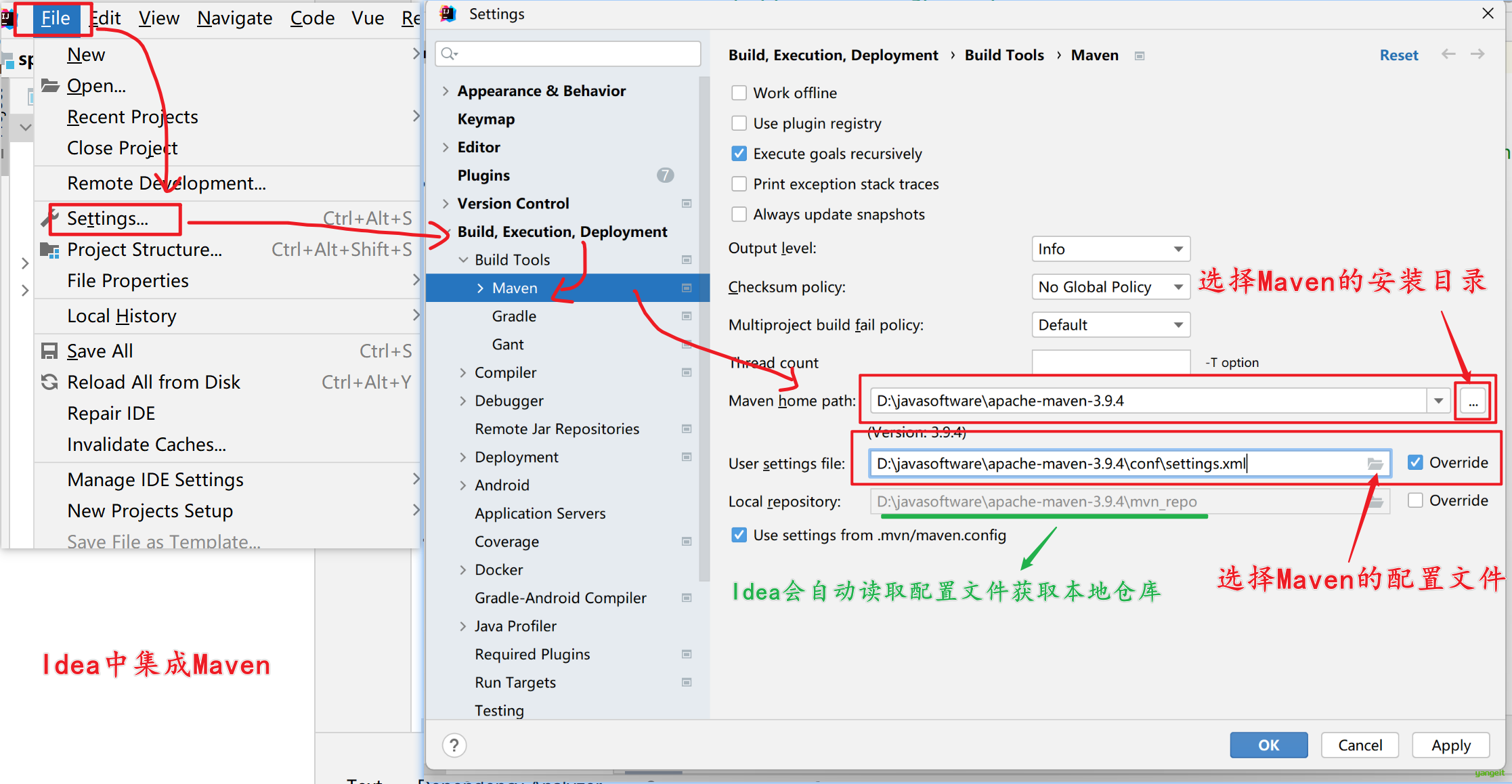
3. 依赖配置(Maven项目,pom.xml)
核心依赖3个,复制到pom.xml中,刷新Maven即可自动导入: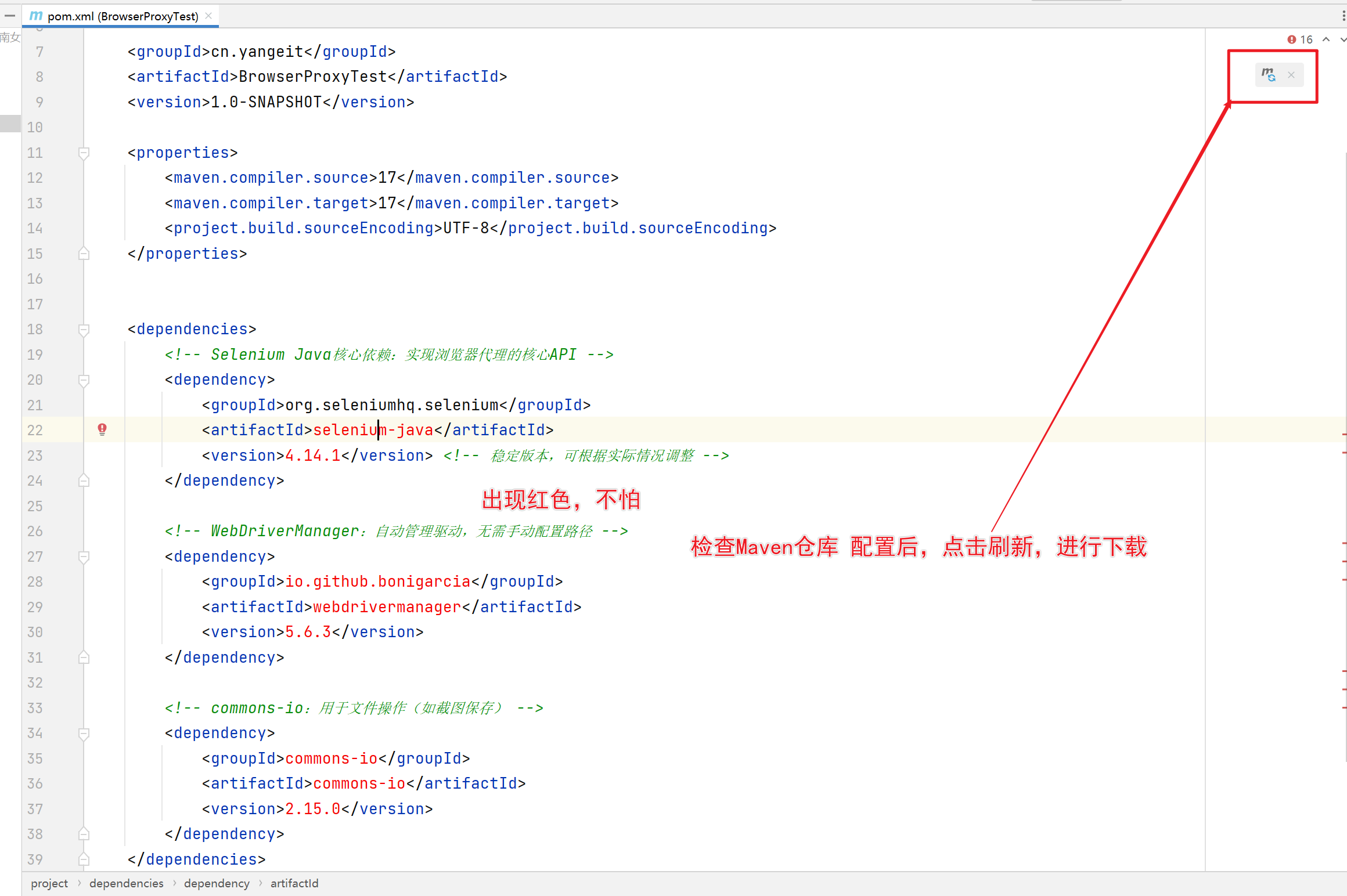
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.yangeit</groupId>
<artifactId>BrowserProxyTest</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- Selenium Java核心依赖:实现浏览器代理的核心API -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.14.1</version> <!-- 稳定版本,可根据实际情况调整 -->
</dependency>
<!-- WebDriverManager:自动管理驱动,无需手动配置路径 -->
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>5.6.3</version>
</dependency>
<!-- commons-io:用于文件操作(如截图保存) -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.15.0</version>
</dependency>
</dependencies>
</project>4. 在src/main/java目录下创建cn.yangeit的包下,创建BrowserProxyTest类,并准备main方法:
package cn.yangeit;
public class BrowserProxyTest {
public static void main(String[] args) {
System.out.println("开始学习浏览器代理自动化测试,非常开心");
}
}接下来浏览器代理环境部署,这里很容易出问题哦,一定要认真看哦!👈 👈
5. 核心:完成“驱动下载与配置”,建立Java代码与浏览器的连接。
- 查看Chrome浏览器版本:打开Chrome → 右上角三个点 → 帮助 → 关于Google Chrome,记录版本号(如122.0.6261.111)。
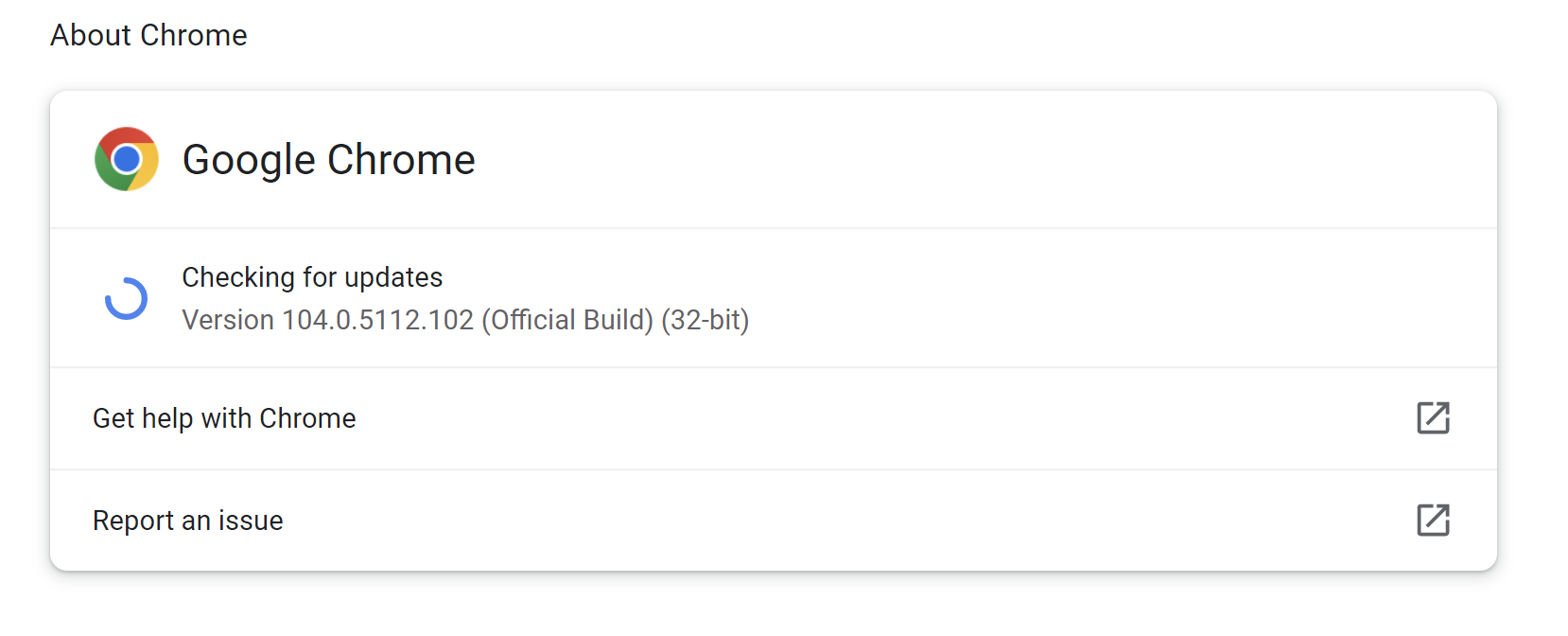
- 下载对应版本ChromeDriver:
访问官方地址:https://googlechromelabs.github.io/chrome-for-testing/根据自身系统(Windows/macOS)和浏览器版本,下载对应驱动文件(版本必须完全匹配)。

资源包中有焱哥提前准备的chromedriver.exe和chrome安装包,他们是配套的。
- 驱动配置:
① Windows系统:将chromedriver.exe放入任意路径(如D:\javasoftware\ChromeDriver),可在代码中手动指定路径;
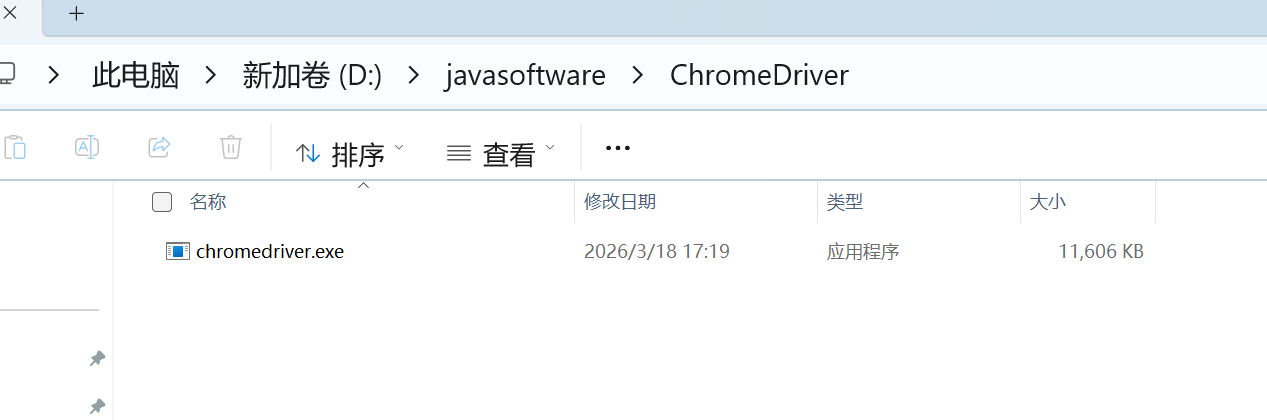
- 新建Java类BrowserProxyTest,编写如下代码,运行后若能打开Chrome并跳转至百度,说明部署成功。
package cn.yangeit;
import io.github.bonigarcia.wdm.WebDriverManager;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class BrowserProxyTest {
public static void main(String[] args) {
//手动指定驱动路径(Windows示例)
System.setProperty("webdriver.chrome.driver", "D:\\javasoftware\\ChromeDriver\\chromedriver.exe");
//指定Chrome安装位置,配置OPtion
ChromeOptions options = new ChromeOptions();
options.setBinary("D:\\javasoftware\\Chrome\\Application\\chrome.exe");
// 启动浏览器(通过代理驱动,完成本地代理部署)
WebDriver driver = new ChromeDriver(options);
// 测试:打开百度页面
driver.get("https://www.baidu.com");
System.out.println("浏览器代理部署成功,已打开百度页面");
// 停留5秒后关闭浏览器
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
driver.quit();
}
}运行结果:
正常打开 Chrome浏览器,并跳转至百度页面,说明部署成功。
常见故障排查:
- 报错“Could not find or load main class”:Java类路径配置错误,检查项目结构,确保包路径正确;
- 报错“session not created: This version of ChromeDriver only supports Chrome version XX”:驱动与浏览器版本不匹配,重新下载对应驱动;
- 报错“Maven dependency not found”:依赖导入失败,检查pom.xml配置,刷新Maven,或手动下载依赖放入本地仓库。
三、案例实操
3.1 页面元素操作与DOM交互
前言
核心:通过浏览器代理操控页面元素,实现DOM交互,包含本地页面和在线网站两个案例,贴合实际场景。
案例1:本地页面操作(百度搜索,基础练习)
- 代码示例(新建Java类ElementOperationTest):
package cn.yangeit;
import io.github.bonigarcia.wdm.WebDriverManager;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class ElementOperationTest {
public static void main(String[] args) {
// 方式:手动指定驱动路径(Windows示例)
System.setProperty("webdriver.chrome.driver", "D:\\javasoftware\\ChromeDriver\\chromedriver.exe");
// 启动浏览器(通过代理驱动,完成本地代理部署)
WebDriver driver = new ChromeDriver();
// 最大化浏览器窗口
driver.manage().window().maximize();
try {
// 打开百度页面(在线网站)
driver.get("https://www.baidu.com");
Thread.sleep(2000); // 停留2秒,等待页面加载完成
// 1. 页面元素操作:定位搜索框、输入内容、点击搜索
WebElement searchInput = driver.findElement(By.id("chat-textarea")); // 按ID定位搜索框(DOM元素ID为kw)
searchInput.sendKeys("浏览器代理实操(Java版)"); // 向输入框写入文本(DOM交互)
Thread.sleep(1000);
WebElement searchButton = driver.findElement(By.id("chat-submit-button")); // 按ID定位搜索按钮
// 使用JS强制执行点击
JavascriptExecutor js = (JavascriptExecutor) driver;
js.executeScript("arguments[0].click();", searchButton);
Thread.sleep(3000);
// 2. DOM交互:获取页面信息
String pageTitle = driver.getTitle(); // 获取页面标题(DOM属性)
String currentUrl = driver.getCurrentUrl(); // 获取当前URL
System.out.println("页面标题:" + pageTitle);
System.out.println("当前URL:" + currentUrl);
// 获取页面前5个a标签文本(DOM结构交互)
List<WebElement> aTags = driver.findElements(By.tagName("a"));
System.out.println("页面前5个a标签文本:");
for (int i = 0; i < 5; i++) {
System.out.println(aTags.get(i).getText());
}
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
driver.quit(); // 无论是否报错,都关闭浏览器,释放资源
}
}
}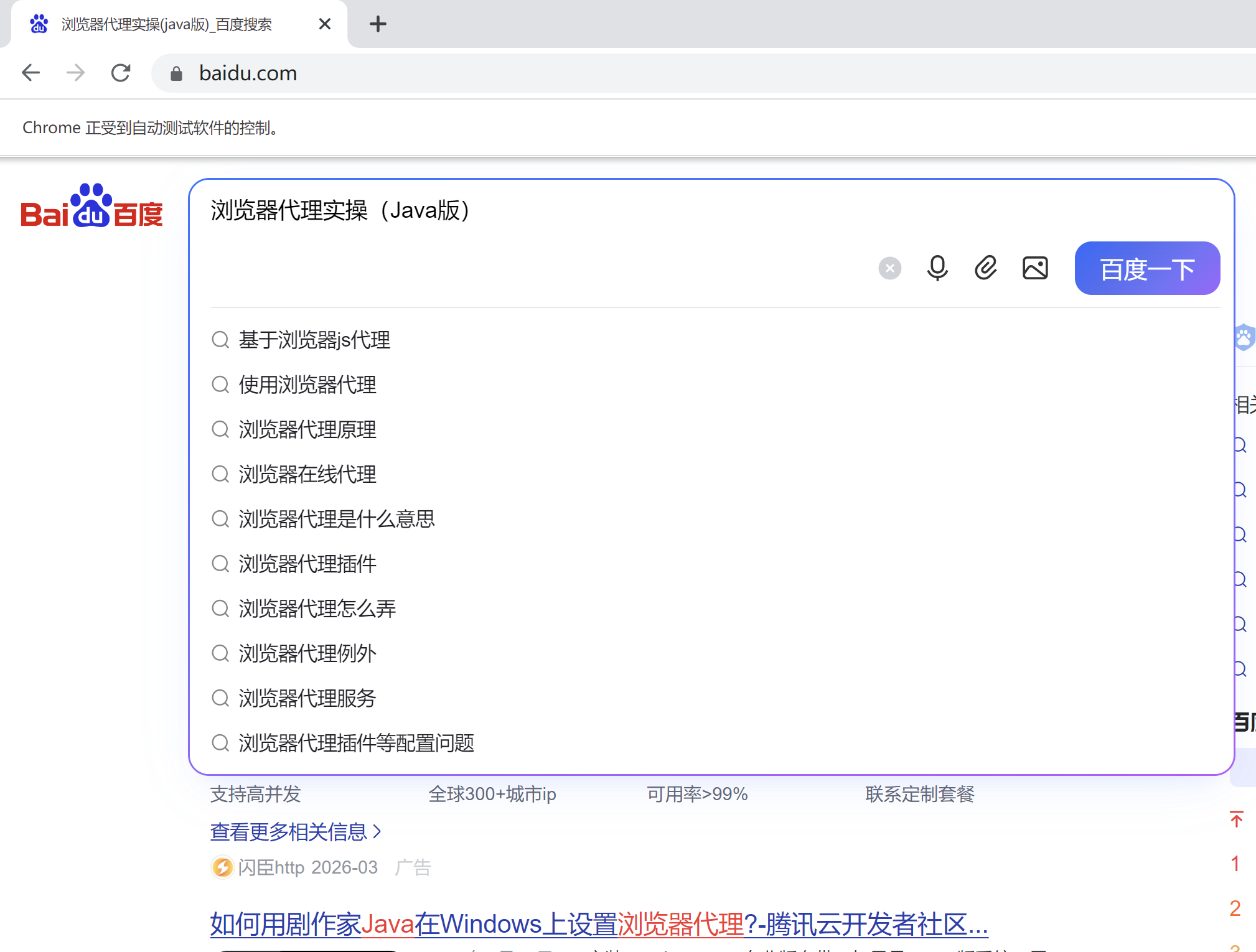
核心知识点总结:
- 在线网站操作与本地页面的区别:在线页面加载速度受网络影响,需适当延长等待时间(Thread.sleep);可能存在弹窗,需添加异常捕获处理,避免操作失败;
- 元素定位方式:在线网站的元素ID、类名可能会动态变化,若定位失败,可通过浏览器“检查”功能重新获取元素属性;
- 实操技巧:操作在线网站时,可先手动打开网站,确认元素位置和属性,再编写代码,减少定位错误。
3.2 在线网站截图
前言
在实际自动化测试、数据留存与页面监控场景中,对在线网站进行自动截图是非常实用的技能。它可以用于:测试结果留证、异常页面取证、数据页面存档、定时监控截图等。本案例以b站为目标网站,使用 Selenium 实现自动打开页面、等待加载、全屏截图并保存到本地,完整演示真实环境下的截图操作流程。
代码示例(新建Java类OnlineSiteScreenshotTest):
package cn.yangeit;
import io.github.bonigarcia.wdm.WebDriverManager;
import org.openqa.selenium.By;
import org.openqa.selenium.OutputType;
import org.openqa.selenium.TakesScreenshot;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
public class OnlineSiteScreenshotTest {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "D:\\javasoftware\\ChromeDriver\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.manage().window().maximize();
try {
// 打开在线网站:blibli,搜索内容并截图
driver.get("https://www.bilibili.com/");
Thread.sleep(3000);
// 关闭弹窗(避免干扰截图)
// try {
// WebElement closeBtn = driver.findElement(By.className("close-btn"));
// if (closeBtn.isDisplayed()) {
// closeBtn.click();
// Thread.sleep(1000);
// }
// } catch (Exception e) {
// System.out.println("未出现弹窗,继续操作");
// }
// 搜索框样式class =nav-search-input
WebElement searchInput = driver.findElement(By.className("nav-search-input"));
searchInput.sendKeys("自动化测试");
// 搜索按钮class nav-search-btn
WebElement searchBtn = driver.findElement(By.className("nav-search-btn"));
searchBtn.click();
Thread.sleep(3000);
//切换tab窗口
driver.switchTo().window(driver.getWindowHandles().toArray()[1].toString());
Thread.sleep(1000);
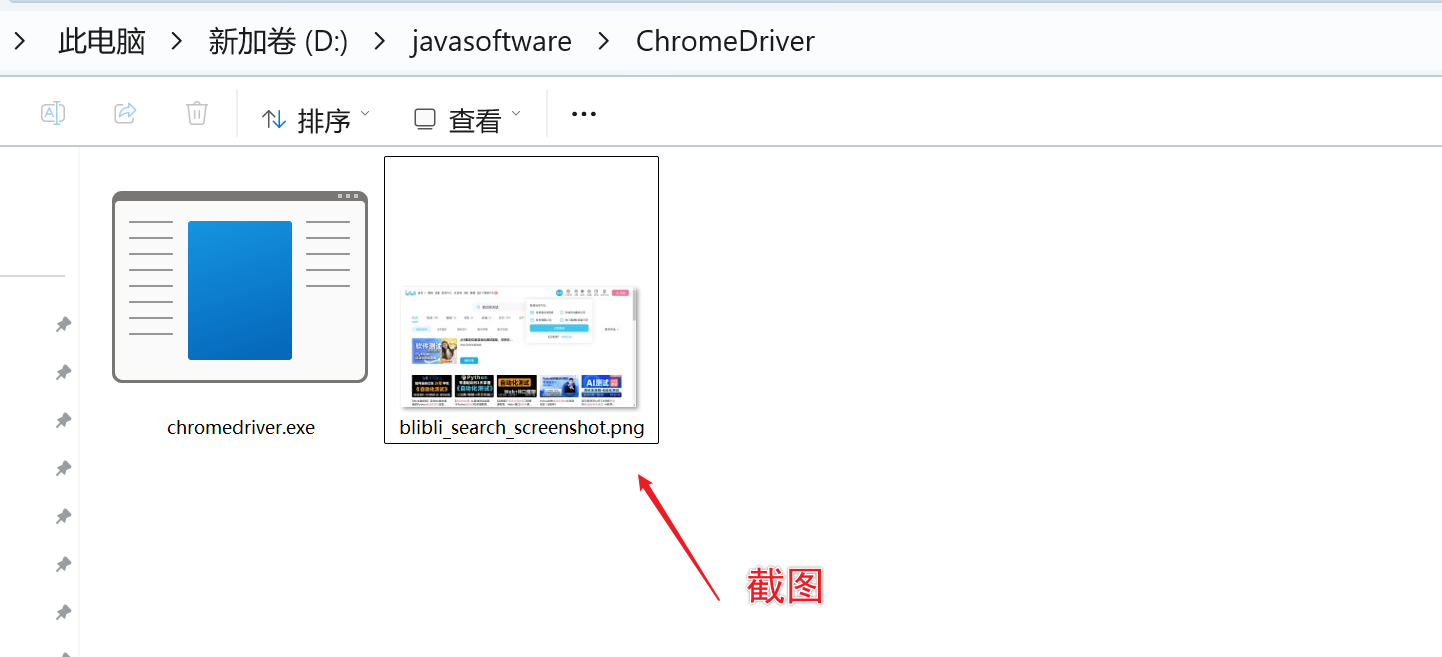
// 在线网站截图:保存搜索结果页面
TakesScreenshot screenshot = (TakesScreenshot) driver;
File srcFile = screenshot.getScreenshotAs(OutputType.FILE);
// 截图保存路径
File destFile = new File("D:\\javasoftware\\ChromeDriver\\blibli_search_screenshot.png");
FileUtils.copyFile(srcFile, destFile);
System.out.println("搜索结果截图已保存");
Thread.sleep(2000);
} catch (InterruptedException | IOException e) {
e.printStackTrace();
} finally {
driver.quit();
}
}
}
核心注意事项:
- 文件路径:必须使用绝对路径,Windows系统用双反斜杠(\),macOS用正斜杠(/);
- 截图保存:依赖commons-io依赖的FileUtils工具类,若导入失败,需检查pom.xml配置;
- 在线网站操作:需考虑网络延迟,适当延长等待时间;若网站元素属性变化,需重新获取元素定位信息。
3.3 采集豆瓣网数据
前言
在掌握了浏览器代理、Selenium 基础操作、元素定位与 DOM 交互后,我们已经具备了完成真实网页数据采集的能力。为了将理论知识落地到实际应用场景,接下来我们以豆瓣电影排行榜为实战目标,使用 Java + Selenium 实现公开数据的自动化采集。
在实际工作中,自动化数据采集是 Web 自动化最常见的应用场景之一,广泛用于数据分析、行业监控、信息汇总等领域。
豆瓣电影作为公开、规范、结构清晰的网站,非常适合作为 Selenium 实战入门案例。通过本次实战,我们将综合运用前面学习的浏览器驱动配置、页面加载控制、元素定位、批量数据提取、控制台输出等知识点,完成一次完整的 “打开网页 → 解析页面 → 采集数据 → 输出结果” 流程
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class DoubanMovieCrawler {
public static void main(String[] args) {
// ===================== 必须改成你自己的驱动路径 =====================
System.setProperty("webdriver.chrome.driver", "D:\\javasoftware\\ChromeDriver\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.manage().window().maximize();
try {
// 打开豆瓣动作片排行榜
String url = "https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=";
driver.get(url);
// 等待页面加载
Thread.sleep(3000);
// 获取所有电影列表
List<WebElement> movieList = driver.findElements(By.cssSelector(".movie-list-item"));
System.out.println("电影列表数量:" + movieList.size());
System.out.println("=====================================");
System.out.println(" 豆瓣动作片排行榜 ");
System.out.println("=====================================");
// 遍历输出
for (WebElement movie : movieList) {
try {
// 电影名
String name = movie.findElement(By.cssSelector(".movie-name-text")).getText();
// 主演
String actors = movie.findElement(By.cssSelector(".movie-crew")).getText();
//年份
String year = movie.findElement(By.cssSelector(".movie-misc")).getText();
// 评分
String score = movie.findElement(By.cssSelector(".rating_num")).getText();
//评论数
String commentCount = movie.findElement(By.cssSelector(".comment-num")).getText();
// 控制台输出
System.out.println("片名:" + name);
System.out.println("主演:" + actors);
System.out.println("评分:" + score);
System.out.println("信息:" + year);
System.out.println("评论数:" + commentCount);
System.out.println("----------------------------------");
} catch (Exception e) {
// 个别格式异常跳过
continue;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
driver.quit();
}
}
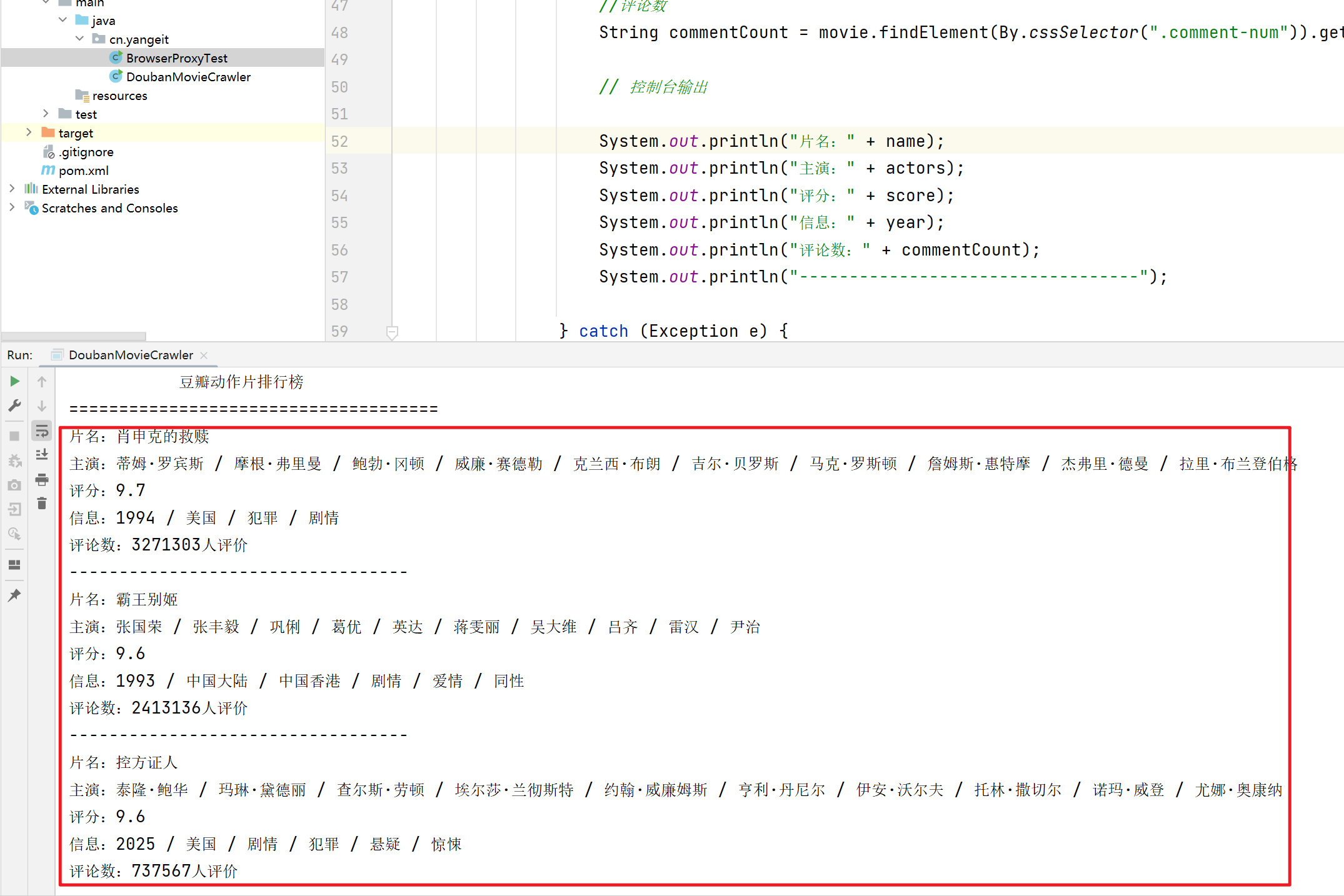
}运行结果如下: