
回顾
Series是Pandas的一维数据结构,用于存储一维数组数据,类似于Python中的列表或NumPy中的数组。
Series对象包含两个主要属性:索引和数据 。

- 索引是用于标识数据位置的标签
- 数据是存储在Series中的实际值。
- Series对象可以通过索引访问和操作数据,支持多种操作和函数,如切片、过滤、聚合等。
在线Python练习平台:https://jupyter.org/try-jupyter/lab/ 👈
还有这个可以:https://python-fiddle.com/
🐟课1. DataFrame
学习目标:理解DataFrame定义、掌握3种创建方式、熟记核心属性、学会列/行基础访问
1.1 什么是 DataFrame?
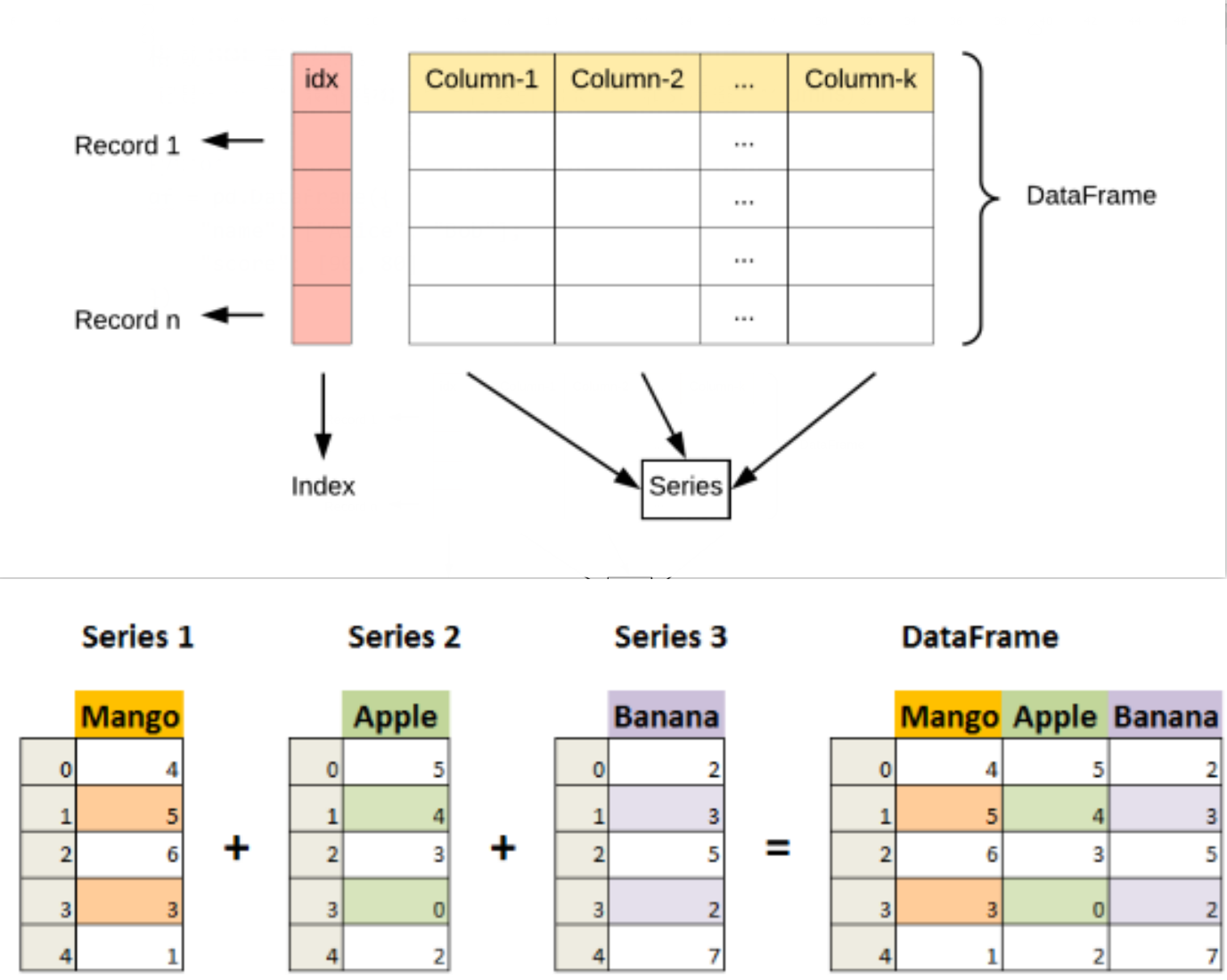
DataFrame 是 Pandas 最核心的二维表格数据结构,和 Excel 表格、SQL 查询结果完全一致。
- 结构:行索引(index)+ 列标签(columns)+ 表格数据(如下图👇)
- 本质:多个共用同一个行索引的 Series 组合而成
- 作用:用于数据分析、清洗、转换、可视化的核心载体
1.2 DataFrame 的 3 种创建方式
1️⃣方式1:直接用字典创建 ❤️
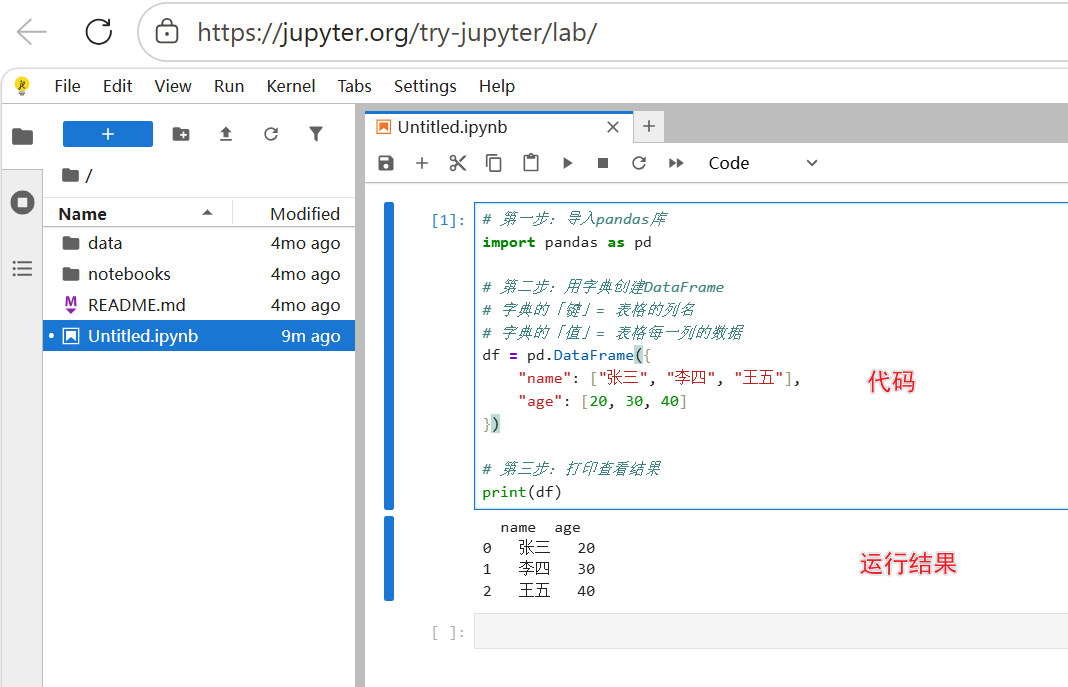
# 第一步:导入pandas库
import pandas as pd
# 第二步:用字典创建DataFrame
# 字典的「键」= 表格的列名
# 字典的「值」= 表格每一列的数据
df = pd.DataFrame({
"name": ["张三", "李四", "王五"],
"age": [20, 30, 40]
})
# 第三步:打印查看结果
print(df)✅ 代码解说:
pd.DataFrame():创建DataFrame的核心函数- 键值对一一对应列名和列数据,自动生成默认行索引(0、1、2...)
2️⃣方式2:通过 Series 创建
import pandas as pd
import numpy as np
# 设置随机种子,保证结果固定
np.random.seed(42)
# 创建2个Series
s1 = pd.Series(np.random.randint(0,10,6)) # 0~10随机整数,长度6
s2 = pd.Series(np.random.randint(0,20,6)) # 0~20随机整数,长度6
# 将Series组合为DataFrame
df = pd.DataFrame({"s1":s1,"s2":s2})
print(df)✅ 代码解说:
- 多个 Series 只要长度一致,就能合并为 DataFrame
- 合并后共用同一个行索引,这是 DataFrame 的核心特征
思考:如果两个 Series 长度不一致,会怎么样?
3️⃣方式3:指定列顺序 + 自定义行索引
df = pd.DataFrame(
# 原始数据
data={"age": [20, 30, 40], "name": ["张三", "李四", "王五"]},
# 强制指定列的顺序(覆盖字典默认顺序)
columns=["name", "age"],
# 自定义行索引(不用默认的0、1、2)
index=[101, 102, 103]
)
print(df)✅ 代码解说:
columns:控制列的展示顺序,灵活调整表格结构index:自定义行标签,适合用学号、工号、ID 做索引
运行结果:
name age
101 张三 20
102 李四 30
103 王五 401.3 DataFrame 核心属性
属性不需要加括号,直接调用,快速查看数据基础信息
方法就需要加括号,如 df.head()、df.tail()、df.info() 等
| 属性名称 | 详细作用 |
|---|---|
| df.index | 查看/修改行索引 |
| df.columns | 查看/修改列标签 |
| df.values | 查看所有原始数据(返回二维数组) |
| df.ndim | 查看维度(DataFrame 固定为2维) |
| df.shape | 查看形状(返回:(行数, 列数)) |
| df.size | 查看总元素个数(行数×列数) |
| df.dtypes | 查看每列的数据类型 |
| df.T | 行列转置(行变列、列变行) |
属性使用代码
# 创建带自定义索引的DataFrame
df = pd.DataFrame(
data={"id": [101, 102, 103], "name": ["张三", "李四", "王五"], "age": [20, 30, 40]},
index=["aa", "bb", "cc"]
)
# 1. 查看行索引
print("行索引:", df.index)
# 2. 查看列名
print("列名:", df.columns)
# 3. 查看数据形状(行数、列数)
print("形状:", df.shape)
# 4. 查看数据类型
print("数据类型:", df.dtypes)
# 5. 行列转置
print("转置后:\n", df.T)运行结果:
df格式:
id name age
aa 101 张三 20
bb 102 李四 30
cc 103 王五 40
行索引: Index(['aa', 'bb', 'cc'], dtype='object')
列名: Index(['id', 'name', 'age'], dtype='object')
形状: (3, 3)
数据类型: id int64
name object
age int64
dtype: object
转置后:
aa bb cc
id 101 102 103
name 张三 李四 王五
age 20 30 40s思考下,转置有什么用? 转置后索引修改了吗?
1.4 基础数据访问:列访问
DataFrame 基础访问优先学列访问,是最常用操作
1️⃣1. 访问单列(返回 Series)
df = pd.DataFrame({"name": ["张三","李四"], "age": [20,30]})
# 写法1:推荐(通用,支持特殊字符列名)
print(df["name"])
# 写法2:简洁(仅支持纯英文/数字列名)
print(df.name)2️⃣ 2. 访问多列(返回 DataFrame)
# 传入列名列表,获取多列
print(df[["name", "age"]])✅ 关键区别:
- 单层方括号
df["name"]:取单列 → Series - 双层方括号
df[["name","age"]]:取多列 → DataFrame
1.5 课堂实操练习 ✏️
总结
课堂作业
- 用字典创建一个包含
id、姓名、年龄、成绩4列的 DataFrame,共3行数据 - 查看这个 DataFrame 的行索引、列名、形状、数据类型
- 分别提取
姓名单列、姓名+成绩两列 - 对 DataFrame 做行列转置,查看结果
🐳课2.DataFrame 高级索引、筛选与数据运算
学习目标:掌握 loc/iloc 精准索引、at/iat 快速取值、条件筛选、标量/列间运算
2.1 核心索引:loc 与 iloc ❤️
这是 DataFrame 取数最核心的两个方法
| 方法 | 索引依据 | 切片规则 | 适用场景 |
|---|---|---|---|
| df.loc | 行/列标签(名称) | 闭区间(包含结束值) | 自定义索引、按名称取数 |
| df.iloc | 行/列整数位置(0开始) | 左闭右开(不含结束值) | 按位置取数、通用场景 |
1. loc:按标签取数
# 创建自定义索引的DataFrame
df = pd.DataFrame({
"name": ["张三","李四","王五"],
"age": [20,30,40]
}, index=[101,102,103])
print("df结构:\n", df)
print("-----")
# ① 取单行:行标签=101
print(df.loc[101])
# ② 多行切片:标签101~103(包含103)
print(df.loc[101:103])
print("-----")
# ③ 行+列组合:取101-102行,name+age列
print(df.loc[101:102, ["name"]])运行结果:
df结构:
name age
101 张三 20
102 李四 30
103 王五 40
-----
name 张三
age 20
Name: 101, dtype: object
name age
101 张三 20
102 李四 30
103 王五 40
-----
name
101 张三
102 李四
-----2. iloc:按位置取数
# ① 取第1行(位置0)
print(df.iloc[0])
# ② 取前2行(位置0、1,不含2)
print(df.iloc[0:2])
# ③ 行+列组合:前2行,前1列
print(df.iloc[0:2, 0:1])运行结果:
df结构:
name age
101 张三 20
102 李四 30
103 王五 40
-----
-----
name 张三
age 20
Name: 101, dtype: object
name age
101 张三 20
102 李四 30
name
101 张三
102 李四观察是否包前不包后
2.2 快速取值:at 与 iat
仅用于取单个单元格值,速度比 loc/iloc 更快 ❤️
# 按标签取单个值:行标签101,列name -->张三
print(df.at[101, "name"])
# 按位置取单个值:第0行,第0列-->张三
print(df.iat[0, 0])2.3 条件筛选:布尔索引
按条件筛选数据,数据分析最常用操作
print("----1. 单条件筛选----")
#
# 筛选年龄>30的行
print(df[df["age"] > 30])
print("----2. 多条件筛选(必加括号,&=且、|=或)-----")
# 年龄>20 并且 姓名=张三
print(df[(df["age"]>20) & (df["name"]=="张三")])
# 年龄>30 或者 姓名=李四
print(df[(df["age"]>30) | (df["name"]=="李四")])
print("----3. 空值筛选(isnull、notnull)----")
# 筛选年龄为空的行
print(df[df["age"].isnull()])
# 筛选年龄不为空的行
print(df[df["age"].notnull()])空值:np.nan, None, pd.NA 都表示空值,筛选时统一用 isnull/notnull
四、数据运算
1. 标量运算(每个元素都计算)和 列间运算(新增列)
print("----1. 标量运算(每个元素都计算)----")
# 年龄列×2
df["age"] = df["age"] * 2
print(df)
print("----2. 列间运算(新增列)----")
# 新增总分列:多列求和,axis=1 表示按行求和
df = pd.DataFrame({"语文":[80,90],"数学":[85,95]})
df["总分"] = df[["语文","数学"]].sum(axis=1)
print(df)运行结果:
----1. 标量运算(每个元素都计算)----
name age
101 张三 40
102 李四 60
103 王五 80
----2. 列间运算(新增列)----
语文 数学 总分
0 80 85 165
1 90 95 1852.5 课堂实操练习 ✏️
总结
import pandas as pd
df = pd.DataFrame({
"id": [101,102,103],
"姓名": ["小明","小红","小刚"],
"性别": ["男","女","男"],
"成绩": [92,88,95]
}, index=[101,102,103])
# 1. 最后一行最后一列
print("最后一个值:", df.iat[-1, -1])
# 2. 成绩>90
print("高分学生:\n", df[df["成绩"]>90])
# 3. 女且成绩>85
print("优秀女生:\n", df[(df["性别"]=="女") & (df["成绩"]>85)])
# 4. loc取数
print("指定学生:", df.loc[102, "姓名"])🐋课3:数据导入导出 + 统计分析 + 实战案例
学习目标:掌握CSV/Excel读写、常用统计函数、完成成绩/销售实战分析
3.1 数据导入与导出
1. 导出数据(保存到本地文件)
import pandas as pd
import os
# 创建文件夹(不存在则创建)
os.makedirs("data", exist_ok=True)
# 创建测试DataFrame
df = pd.DataFrame({
"name": ["张三","李四"],
"age": [20,30]
})
# ① 导出CSV(index=False 不保存行索引,最常用)
df.to_csv("data/student.csv", index=False)
# ② 导出Excel 容易报错,出现则用openpyxl引擎
# df.to_excel("data/student.xlsx", index=False)2. 导入数据(读取本地文件)
# 读取CSV文件
df_csv = pd.read_csv("data/student.csv")
# 读取Excel文件
# df_excel = pd.read_excel("data/student.xlsx")
# 查看前5行
print("CSV数据:\n", df_csv.head())3.2 常用统计方法
直接对列/整个DataFrame使用,快速做描述性统计
| 方法 | 详细作用 |
|---|---|
| df.head(n) | 查看前n行,默认5行 |
| df.describe() | 数值列全量统计(均值、标准差、分位数) |
| df.sum() | 列求和 |
| df.mean() | 列平均值 |
| df.max()/df.min() | 列最大/最小值 |
| df.value_counts() | 列值频次统计(计数) |
| df.count() | 列非空值个数 |
统计代码演示
df = pd.DataFrame({
"name": ["张三","李四","王五","张三"],
"score": [85,92,78,85]
})
print("df结构:\n", df)
# 1. 数值列描述统计
print(df.describe())
# 2. 成绩平均值
print("平均分:", df["score"].mean())
# 3. 姓名计数(统计重复人数)
print("姓名频次:\n", df["name"].value_counts())
运行结果:
df结构:
name score
0 张三 85
1 李四 92
2 王五 78
3 张三 85
score
count 4.000000
mean 85.000000
std 5.715476
min 78.000000
25% 83.250000
50% 85.000000
75% 86.750000
max 92.000000
平均分: 85.0
姓名频次:
name
张三 2
李四 1
王五 1
Name: count, dtype: int643.3 实战案例 ✏️
场景1:某班级的学生成绩数据如下,请完成以下任务:
1.计算每位学生的总分和平均分。
2.找出数学成绩高于90分或英语成绩高于85分的学生。
3.按总分从高到低排序,并输出前3名学生。
import pandas as pd
# 1. 创建成绩数据
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'数学': [85, 92, 78, 88],
'英语': [90, 88, 85, 92],
'物理': [75, 80, 88, 85]
}
df = pd.DataFrame(data)
# 2. 计算总分(按行求和)
df['总分'] = df[['数学', '英语', '物理']].sum(axis=1)
# 3. 计算平均分
df['平均分'] = df['总分'] / 3
# 4. 筛选数学>90或英语>85的学生
high_score = df[(df['数学']>90) | (df['英语']>85)]
print("完整成绩:\n", df)
print("高分学生:\n", high_score)场景2:某公司销售数据如下,请完成以下任务:
1.计算每种产品的总销售额(销售额 = 单价 × 销量)。
2.找出销售额最高的产品。
3.按销售额从高到低排序,并输出所有产品信息。
import pandas as pd
data = {
'产品名称': ['A', 'B', 'C', 'D'],
'单价': [100, 150, 200, 120],
'销量': [50, 30, 20, 40]
}
df = pd.DataFrame(data)
# 1. 计算总销售额
df['销售额'] = df['单价'] * df['销量']
# 2. 找出销售额最高的产品
max_sales = df[df['销售额'] == df['销售额'].max()]
# 3. 按销售额排序
sorted_df = df.sort_values('销售额', ascending=False)
print("销售额计算:\n", df)
print("\n销售额最高的产品:\n", max_sales)
print("\n按销售额排序:\n", sorted_df)场景3:某电商平台的用户行为数据如下,请完成以下任务: **
1.计算每位用户的总消费金额**(消费金额 = 商品单价 × 购买数量)
2.找出消费金额最高的用户,并输出其所有信息
3.计算所有用户的平均消费金额(保留2位小数)
4.统计电子产品的总购买数量
import pandas as pd
data = {
'用户ID': [101, 102, 103, 104, 105],
'用户名': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'商品类别': ['电子产品', '服饰', '电子产品', '家居', '服饰'],
'商品单价': [1200, 300, 800, 150, 200],
'购买数量': [1, 3, 2, 5, 4]
}
df = pd.DataFrame(data)
# 1. 计算总消费金额
df['消费金额'] = df['商品单价'] * df['购买数量']
# 2. 找出消费金额最高的用户
max_spend_user = df[df['消费金额'] == df['消费金额'].max()]
# 3. 计算平均消费金额
avg_spend = round(df['消费金额'].mean(), 2)
# 4. 统计电子产品的总购买数量
electronic_total = df[df['商品类别'] == '电子产品']['购买数量'].sum()
print("用户消费分析:\n", df)
print("\n消费金额最高的用户:\n", max_spend_user)
print("\n平均消费金额:", avg_spend)
print("电子产品总购买数量:", electronic_total)🐬 课4:数据清洗全流程
学习目标:掌握缺失值/重复值处理、数据类型转换、数据重塑,完成脏数据清洗
4.1 缺失值处理 ❤️
缺失值标记:NaN、None、pd.NA,处理三步:检测→删除→填充
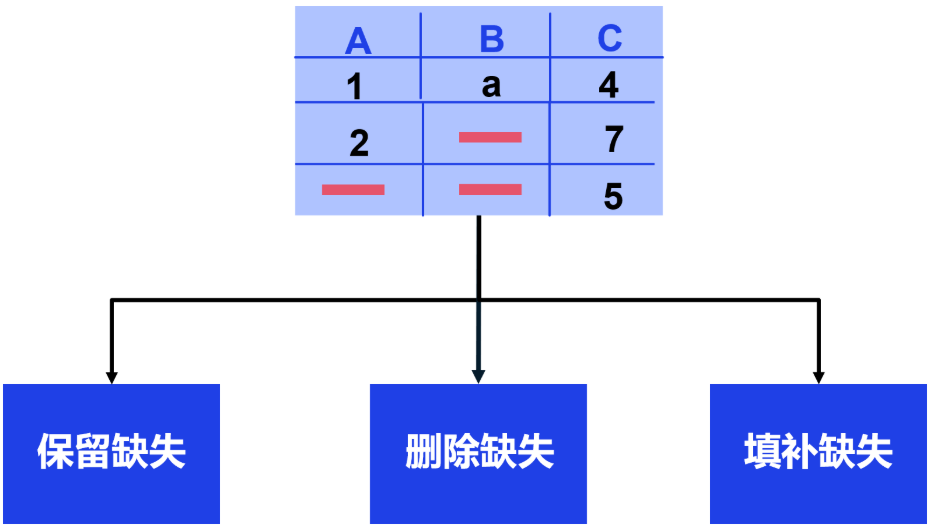
1️⃣1. 检测缺失值
import pandas as pd
import numpy as np
# 创建含缺失值的DataFrame
df = pd.DataFrame({
"name": ["张三",None,"王五"],
"score": [85,np.nan,85],
"age": [20,30,pd.NA]
})
# ① 判断是否缺失(返回布尔值)
print(df.isna())
# ② 统计每列缺失值数量(最常用)
print("每列缺失数:\n", df.isna().sum())2️⃣2. 删除缺失值
# ① 删除含缺失值的行(默认)
df_drop_row = df.dropna()
# ② 删除含缺失值的列
df_drop_col = df.dropna(axis=1)
# ③ 仅删除指定列有缺失的行
df_drop_sub = df.dropna(subset=["score"])3️⃣3. 填充缺失值
# ① 固定值填充(填0)
df_fill_0 = df.fillna(0)
# ② 均值填充(数值列推荐)
df_fill_mean = df.fillna(df.mean())
# ③ 前向填充(用前一个值补)
df_fill_ffill = df.ffill()
# ④ 后向填充(用后一个值补)
df_fill_bfill = df.bfill()4.2 重复值处理
重复值:数据集中出现多次的行,处理三步:检测→删除→保留
# 创建含重复行的DataFrame
df = pd.DataFrame({
"name": ["张三","李四","张三"],
"age": [20,30,20]
})
print("原始数据:\n", df)
# ① 检测重复行(True=重复)
print("重复行:\n", df.duplicated())
# ② 删除重复行(保留第一次出现)
df_drop_dup = df.drop_duplicates()
print("删除重复行:\n", df_drop_dup)
print("------")
# ③ 按指定列去重(仅判断name列)
df_drop_sub = df.drop_duplicates(subset=["name"])
print("按name列去重:\n", df_drop_sub)
print("------")
# ④ 保留最后一次出现的重复行
df_drop_last = df.drop_duplicates(keep="last")
print("保留最后一次出现的重复行:\n", df_drop_last)4.3 数据类型转换
数据类型转换主要包括:数值型、日期型、分类型。
为什么要转成数值型? 因为数值型数据可以进行数值计算,如计算平均值、方差等。
为什么要转成日期型? 因为日期型数据可以方便地进行日期计算,如计算两个日期之间的天数差。
为什么要转成分类型? 因为分类型数据可以节省内存,并且可以进行分类统计。
import pandas as pd
# 1. 创建DataFrame
df = pd.DataFrame({
"name": ["张三","李四","王五"],
"age": [20,30,20],
"score": [85,92,78],
"date": ["2024-01-01","2024-01-02","2024-01-03"]
})
# 1. 查看数据类型
print("转换前\n", df.dtypes)
# 2. 转换为整数类型
df["age"] = df["age"].astype(int)
# 3. 转换为日期类型
df["date"] = pd.to_datetime(["2024-01-01","2024-01-02","2024-01-03"])
# 4. 转换为分类类型(节省内存)
df["name"] = df["name"].astype("category")
print("转换后\n", df.dtypes)
输出 :
转换前
name object
age int64
score int64
date object
dtype: object
转换后
name category
age int32
score int64
date datetime64[ns]
dtype: object4.4 数据重塑:字符串分列
# 创建含复合字符串的DataFrame
df = pd.DataFrame({
"name": ["张 三","李 四","王 五"]
})
# 按空格拆分,生成新列
df[["姓","名"]] = df["name"].str.split(" ", expand=True)
print(df)4.5 课堂实操练习(清洗脏数据)✏️
总结
课堂作业
- 创建含缺失值、重复值的DataFrame
- 统计每列缺失值数量
- 用均值填充数值列缺失值
- 按
name列删除重复行 - 将
score列转换为int类型
import pandas as pd
import numpy as np
# 1. 创建脏数据
df = pd.DataFrame({
"name": ["张三","李四","张三",None],
"score": [85,np.nan,85,90],
"age": [20,30,20,np.nan]
})🐙 课5:数据可视化
为什么要进行数据可视化?
•数据可视化 = 把抽象的数据“看得见”
•目的是让数据背后的规律、异常、趋势一目了然
场景举例:

常见图表类型及使用场景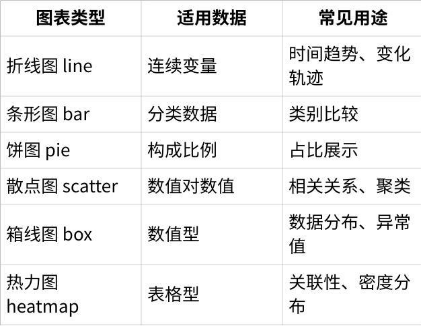
Matplotlib是一个Python绘图库,广泛用于创建各种类型的静态、动态和交互式图表。它是数据科学、机器学习、工程和科学计算领域中常用的绘图工具之一。
支持多种图表类型:折线图(Line plots)、散点图(Scatter plots)、柱状图(Bar charts)、直方图(Histograms)、饼图(Pie charts)、热图(Heatmaps)、箱型图
5.1 折线图 plt.plot()
用途:看趋势 → 销量、股价、温度、时间变化
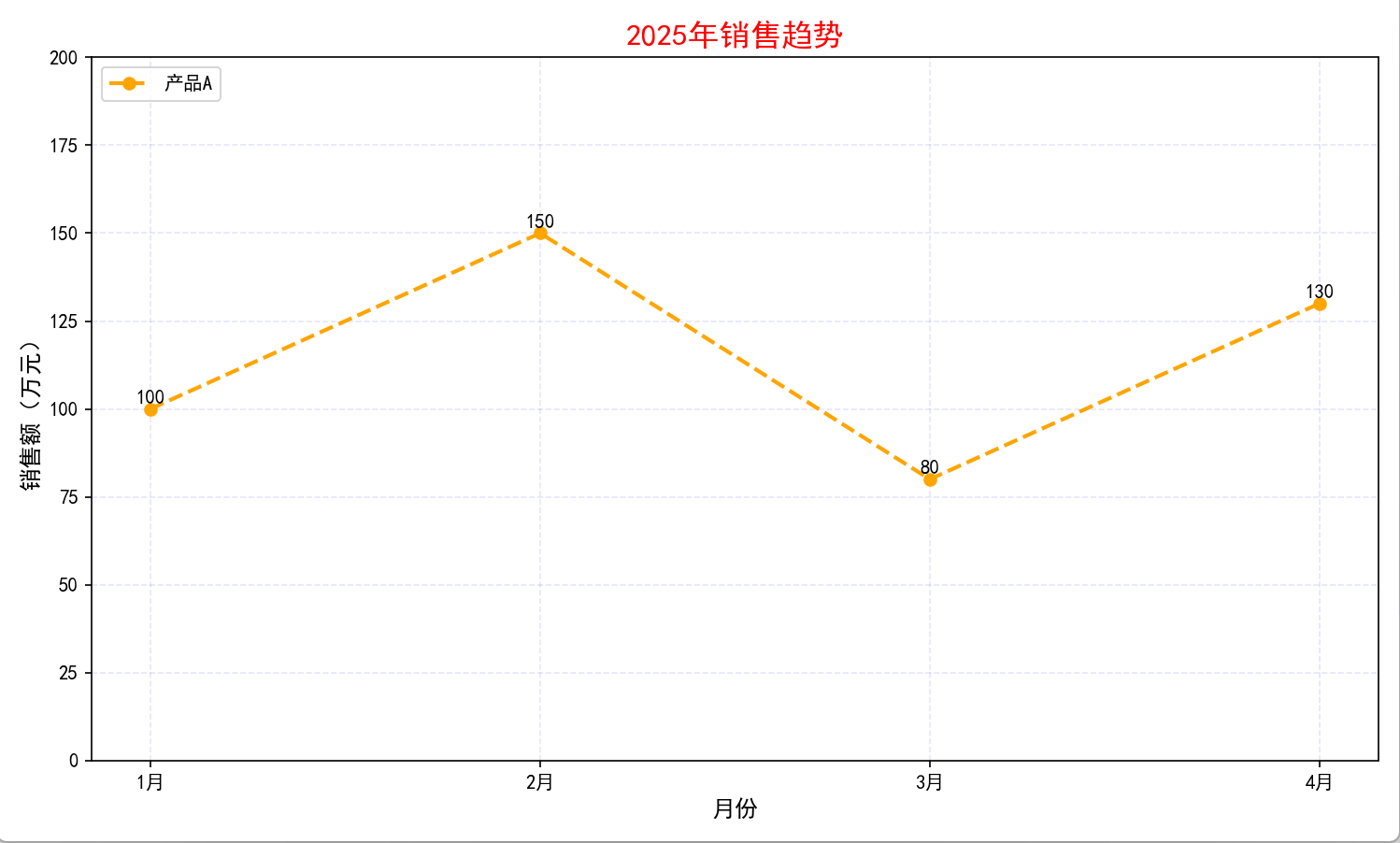
必须记住的语法
plt.plot(x, y)→ 画折线plt.title()→ 标题plt.xlabel()→ x轴说明plt.ylabel()→ y轴说明plt.grid()→ 网格plt.legend()→ 图例plt.show()→ 显示图片
案例代码
# 1. 导入画图工具包:matplotlib的pyplot,简写为plt(固定写法)
import matplotlib.pyplot as plt
# 2. 解决中文显示问题:让图表可以显示中文(Windows电脑必须写)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 让负号(-)正常显示
# ---------------------- 数据准备 ----------------------
# X轴数据:月份
month = ['1月','2月','3月','4月']
# Y轴数据:每个月对应的销售额
sales = [100,150,80,130]
# ---------------------- 1. 创建画布 ----------------------
# 设置图表大小:宽10,高6(单位:英寸)
plt.figure(figsize=(10,6))
# ---------------------- 2. 绘制折线图 ----------------------
plt.plot(
month, # 第1个参数:X轴数据(月份)
sales, # 第2个参数:Y轴数据(销售额)
label='产品A', # 图例名称:这条线代表什么
color='orange', # 线条颜色:橙色
linewidth=2, # 线条粗细:数字越大越粗
linestyle='--', # 线条样式:-- 虚线,- 实线,: 点线
marker='o' # 数据点样式:o 圆圈,s 方块,^ 三角
)
# ---------------------- 3. 添加标题 ----------------------
# 图表大标题,字体大小16,颜色红色
plt.title("2025年销售趋势",fontsize=16,color='red')
# ---------------------- 4. 设置坐标轴标签 ----------------------
# X轴下方的文字说明
plt.xlabel('月份',fontsize=12)
# Y轴左侧的文字说明
plt.ylabel('销售额(万元)',fontsize=12)
# ---------------------- 5. 显示图例 ----------------------
# 显示label里的文字,位置在左上角
plt.legend(loc='upper left')
# ---------------------- 6. 添加网格线 ----------------------
# True:显示网格;alpha=0.1:透明度(0透明,1不透明)
plt.grid(True,alpha=0.1,color='blue',linestyle='--')
# ---------------------- 7. 设置坐标轴刻度 ----------------------
# X轴文字不旋转,字体大小10
plt.xticks(rotation=0,fontsize=10)
# Y轴文字不旋转,字体大小10
plt.yticks(rotation=0,fontsize=10)
# ---------------------- 8. 设置Y轴范围 ----------------------
# Y轴从0开始,到200结束(防止数据贴顶/贴底)
plt.ylim(0,200)
# ---------------------- 9. 在每个点上方显示数字 ----------------------
# 循环:把月份和销售额一对一对取出来
for xi, yi in zip(month, sales):
# 在坐标(xi, yi+1.5)的位置写字
# str(yi):要写的数字
# ha='center':水平居中对齐
plt.text(xi, yi + 1.5, str(yi), ha='center',fontsize=10)
# ---------------------- 10. 自动优化布局 ----------------------
# 防止文字被截断、重叠
plt.tight_layout()
# ---------------------- 11. 显示图表 ----------------------
# 把画好的图弹出来
plt.show()5.2 柱状图 plt.bar()
用途:比大小 → 成绩对比、销量对比、分类对比
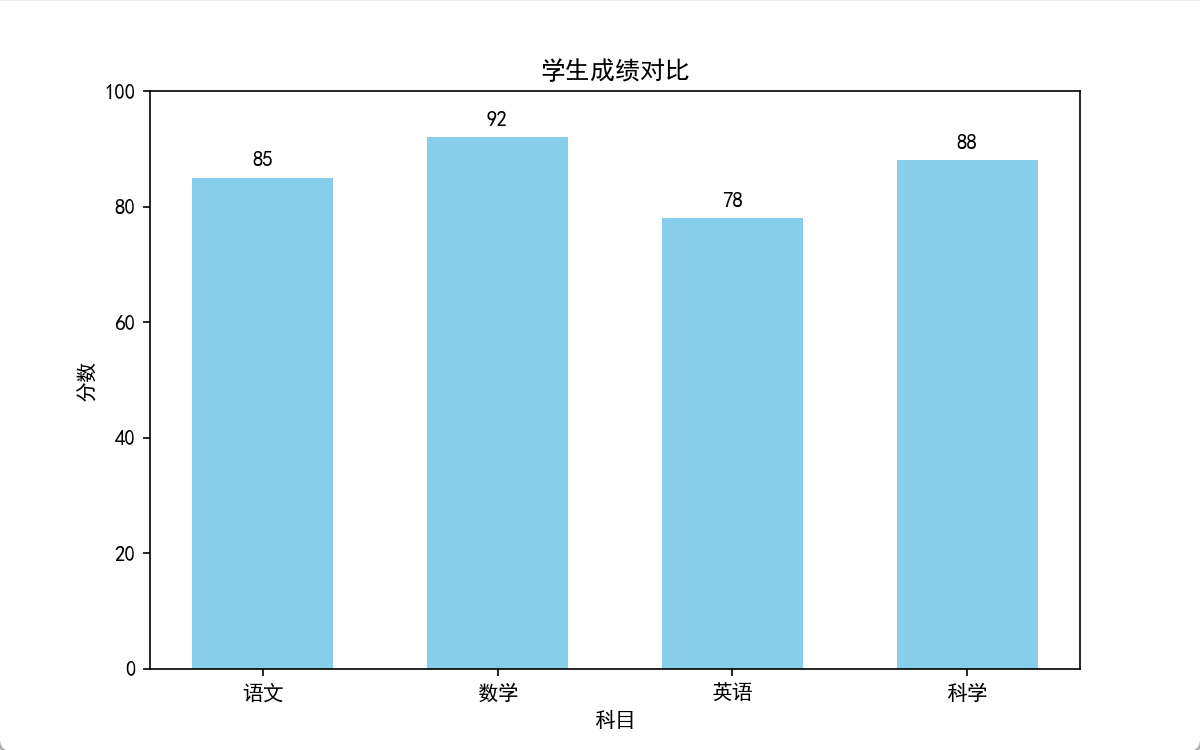
必须记住的语法
plt.bar()→ 画柱子plt.text()→ 在图上写字plt.ylim(0,100)→ y轴范围
案例代码
# 1. 导入画图工具包:matplotlib的pyplot,简写为plt(固定写法)
import matplotlib.pyplot as plt
# 2. 解决中文显示问题:让图表可以显示中文(Windows电脑必须写)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 让负号(-)正常显示
# 1. 数据
subjects = ["语文", "数学", "英语", "科学"]
scores = [85, 92, 78, 88]
# 2. 画布
plt.figure(figsize=(8, 5))
# 3. 画柱状图
plt.bar(
subjects, # x轴:分类
scores, # y轴:数值
color="skyblue",# 颜色
width=0.6 # 柱子宽度
)
# 4. 标注每个柱子的数字
for i in range(len(subjects)):
plt.text(
i, # x位置
scores[i] + 2, # y位置(往上挪一点)
scores[i], # 显示的数字
ha="center" # 居中
)
# 5. 装饰
plt.title("学生成绩对比")
plt.xlabel("科目")
plt.ylabel("分数")
plt.ylim(0, 100) # y轴从0开始
plt.show()5.3 饼图 plt.pie()
用途:看占比 → 时间分配、收支、市场份额
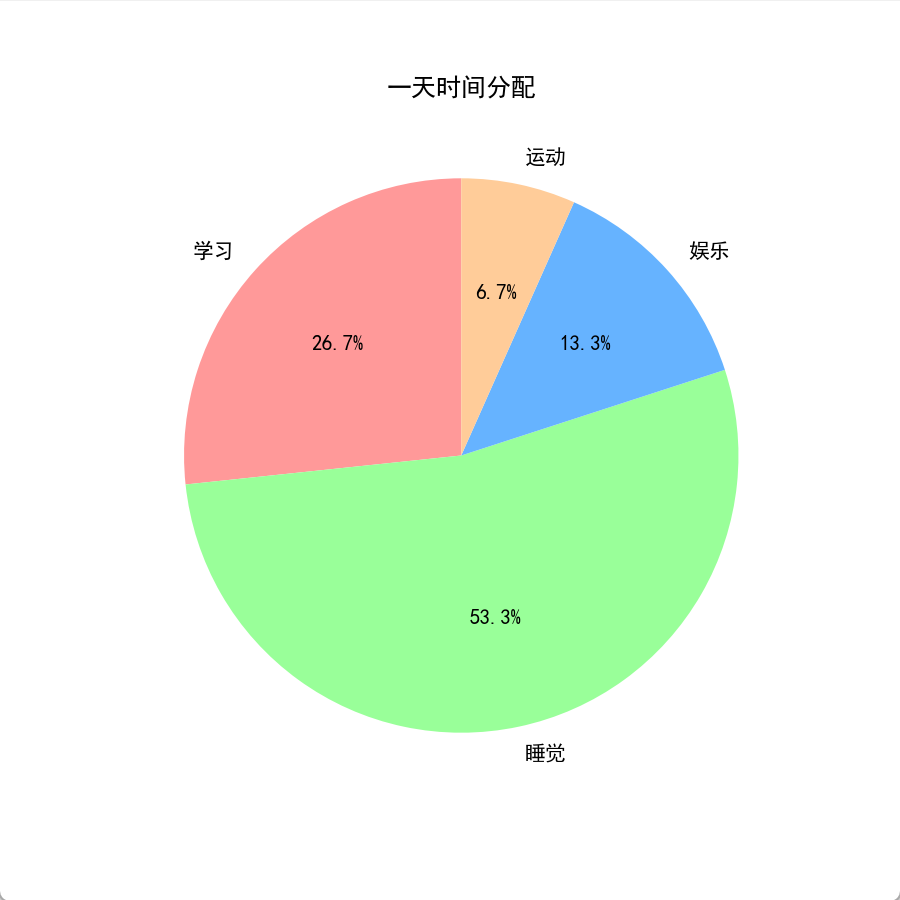
关键语法
autopct="%.1f%%"→ 显示百分比startangle=90→ 旋转饼图
案例代码
# 1. 导入画图工具包:matplotlib的pyplot,简写为plt(固定写法)
import matplotlib.pyplot as plt
# 2. 解决中文显示问题:让图表可以显示中文(Windows电脑必须写)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 让负号(-)正常显示
# 1. 数据
labels = ["学习", "睡觉", "娱乐", "运动"]
values = [4, 8, 2, 1]
# 2. 画布
plt.figure(figsize=(6, 6))
# 3. 画饼图
plt.pie(
values, # 数值
labels=labels, # 标签
autopct="%.1f%%", # 显示百分比(1位小数)
startangle=90, # 起始角度
colors=["#ff9999","#99ff99","#66b3ff","#ffcc99"]
)
# 4. 标题
plt.title("一天时间分配")
# 5. 显示
plt.show()5.4 散点图 plt.scatter()
用途:看关系 → 身高体重、学习时间→成绩、股价→成交量
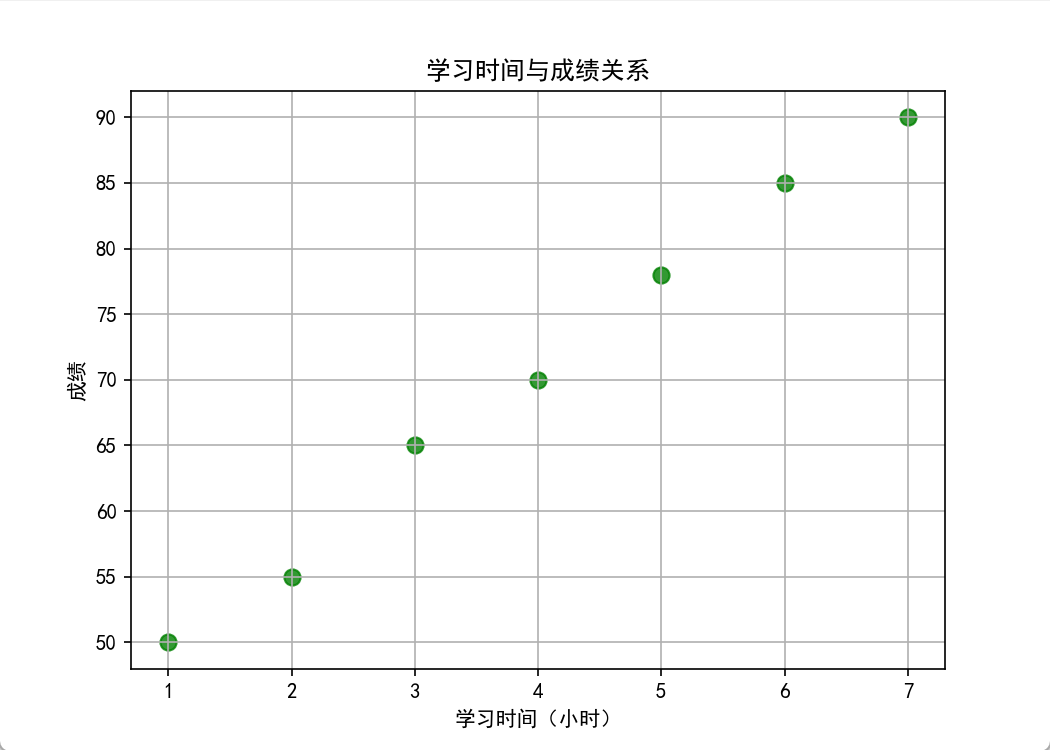
关键语法
plt.scatter()→ 画散点图s=60→ 点大小alpha=0.8→ 透明度
案例代码
# 1. 导入画图工具包:matplotlib的pyplot,简写为plt(固定写法)
import matplotlib.pyplot as plt
# 2. 解决中文显示问题:让图表可以显示中文(Windows电脑必须写)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 让负号(-)正常显示
# 1. 数据
study_hours = [1,2,3,4,5,6,7]
scores = [50,55,65,70,78,85,90]
# 2. 画布
plt.figure(figsize=(7,5))
# 3. 画散点图
plt.scatter(
study_hours, # x轴
scores, # y轴
color="green",# 颜色
s=60, # 点大小
alpha=0.8 # 透明度
)
# 4. 装饰
plt.title("学习时间与成绩关系")
plt.xlabel("学习时间(小时)")
plt.ylabel("成绩")
plt.grid(True)
plt.show()