
4 股票行情可视化
前言
本章目标
使用教材原始数据集 个股行情.csv,不更换数据集、不改动原始字段名,只优化讲解方式、统一代码写法,并补足零基础学生最容易缺失的金融基础。
这一章学完后,你至少要会 4 件事:👍
- 看懂
开盘价、收盘价、最高价、最低价、成交量、涨跌幅这些最常见字段。 - 用
pandas + numpy + matplotlib直接完成股票图形绘制,不依赖额外安装的冷门库。 - 把“观察现象”和“设计交易规则”区分开,不把图形信号误当成必然预测。
- 写出最基础的量化回测代码,并知道回测结果为什么不能直接等于实盘收益。
重点:👇
金融数据分析的重点不是“代码跑出来了”,而是“你知道这段代码在金融上表达了什么”。
4.1 6 个金融基础概念
股票相关名词解释
1️⃣ 什么是股票?
股票是股份证书的简称,是股份公司为筹集资⾦⽽发⾏给股东的⼀种有价证券,股东可凭此取得红利和买卖抵押,是资⾦市场中主要的信⽤⼯具之⼀;
举例:我和朋友开公司,⼀⼈出10万块钱,那怎么证明公司⾥的20万⾥有我的10万呢?
最传统的办法就是发⾏股票,也就是盖章签字的纸质凭证。
每⼈出了10万,那我们就发⾏200股,这样每个⼈就分得100股,
股票就是证明你是公司股东且占有公司200股⾥⾯100股的⼀个凭证。
2️⃣ 股票的分类
A股-⼈⺠币普通股票
- 即
⼈⺠币普通股票,是由中国境内注册公司发⾏,在境内上市,以⼈⺠币标明⾯值,供境内机构、组织或个⼈以⼈⺠币认购和交易的普通股股票; - 英⽂字⺟A没有特殊意义,只是⽤来区分⼈⺠币普通股票和⼈⺠币特种股票;
- 我们当前项⽬
重点关注A股的数据信息;
如传智教育
- 即
B股-⼈⺠币特种股票
- 即公司在中国
⼤陆注册和上市,但只能以外币认购和交易; - 主要吸引外资;
如神奇B股900904, 9开头的股票是在沪市上市的B股,以900打头
- 即公司在中国
其他股
- H股:指国有企业在⾹港 (Hong Kong) 上市的股票;
- N股:指在中国⼤陆注册,但是在纽约(New York)上市的外资股;
- SCA股: 指核⼼业务在中国⼤陆,⽽企业的注册地在新加坡(其他国家和地区),但是在新加坡交易所上市的企业股票;

在A股市场上,股票每天交易的时间都是在交易日的上午9:30-11:30 ,下午13:00-15:00;
股票编码
- 每个上市公司的股票都⼀个唯⼀的编码 ,通过这个编码就可定义具体股票;
沪市A股的代码是以600、601或603打头(6打头);深市A股深市A股的代码是以000打头(0打头);- 其它:
创业板股票代码以300打头,沪市B股代码以900打头,深圳B股代码以200打头等等;
开盘价
- ⼜称开市价 ,是证券交易所在每个交易⽇开市后的第⼀笔股票买卖成交的价格;
- 开盘价是在9点15分⾄9点25分买卖双⽅的竞价撮合产⽣(了解);
- 开盘价⼀般会参考前⼀个股票交易⽇收盘价;
收盘价
- ⼜称收市价 ,是指股票在每个交易⽇⾥
最后⼀笔买卖成交价格; - 昨收:上⼀个交易⽇的收盘价格;
- ⼜称收市价 ,是指股票在每个交易⽇⾥
当前价
- 当前股票实时的
最新成交价格;
- 当前股票实时的
涨跌值
涨跌值=最新价格-前收盘价格;- 股票涨跌值主要⽤于反应股票的涨跌情况,单位是元(A股);
- ⼀般⽤
+或-号表示,正值为涨 ,负值为跌 ,否则为持平;
涨跌幅度(涨幅)
- 股票涨幅=(最新成交价-前收盘价)÷ 前收盘价×
100%
- 股票涨幅=(最新成交价-前收盘价)÷ 前收盘价×
涨停与跌停
- 股市涨跌停的机制与⽣活中电路
过载保护思想⼀致,在股票市场中为了防⽌股价过分的暴涨暴跌,同时抑制过度投机⾏为,证券交易所给股价的涨跌做了相关限制; - 在A股市场中,股价的涨跌幅度范围:
-10%~+10%;
- 股市涨跌停的机制与⽣活中电路
经过计算,从1万到1亿至少需要连续经过97个涨停板,才可以到达1亿。
- 打新-对于新上市股票第⼀天交易中股价涨幅不设限,第⼆天才会有限制(了解);
- 振幅
股票振幅=(当⽇最⾼价-当⽇最低价)÷ 前收盘价×100%;- 股票振幅在⼀定程度上反应了股票的
活跃程度;
- 成交量
- 成交量指当天成交的股票
总⼿数(1⼿=100股);
- 成交量指当天成交的股票
- 成交⾦额
股票成交⾦额是成交量和成交价格的累加,由证券交易所计算得出;- 示例:投资者以每股10元的价格买⼊50⼿,那么此时成交⾦额为:10X50X100=5w
1️⃣ 个股K线图
- K线图源于 日本,早期主要⽤于 ⽶价涨跌 情况统计,后来发展到股市⾦融领域;
- k线图⼜分为
⽇K线、周K线、⽉K线等,信息主要包含股票的开盘、收盘、最⾼、最低等价格信息;
点击查看K线口诀
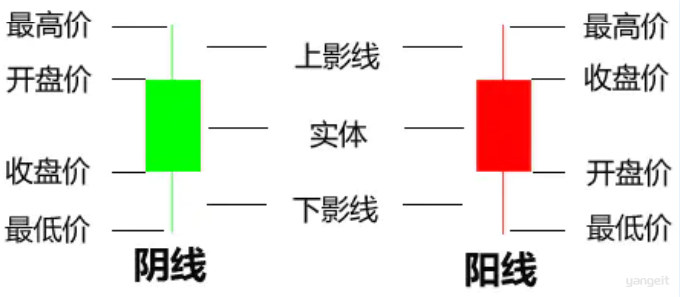
2️⃣ K线图示例
以传智教育股票为例:
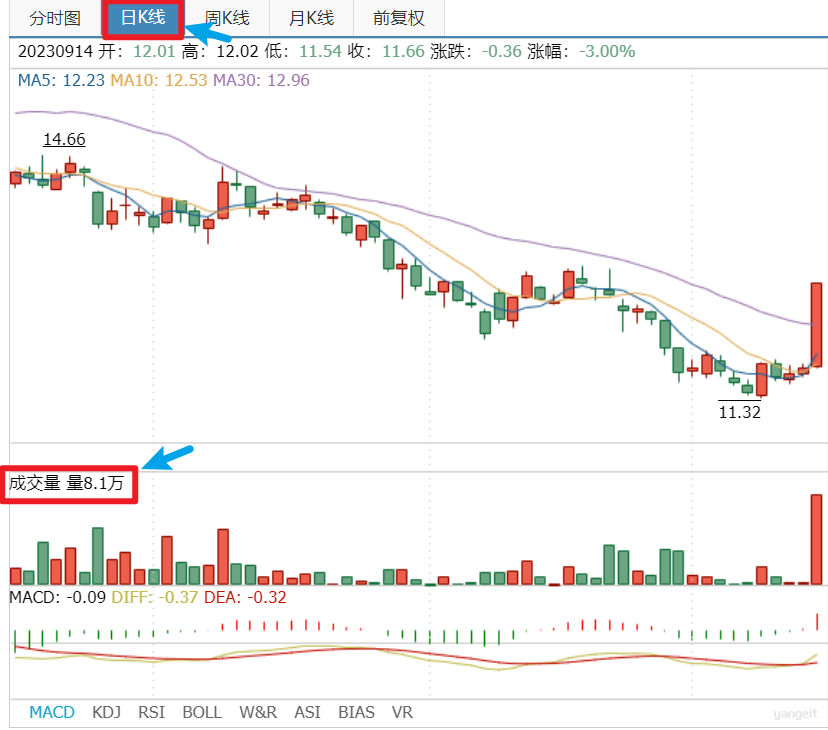
- 分时图:统计当天每分钟的交易数据(当前价格、均价、涨跌、涨幅、成交量和成交⾦额等)
- ⽇K线图:统计每天交易数据(最⾼、最低、开盘、收盘、涨跌、涨幅等)
- 周K线图:统计每周交易数据(最⾼、最低、开盘、收盘、涨跌、涨幅等)
- ⽉K线图:统计每⽉交易数据(最⾼、最低、开盘、收盘、涨跌、涨幅等)
1️⃣ 什么是⼤盘指数
股市的⼤盘指数是由证券交易所经过⼀系列专业计算得出的⼀个反应股市⾏情健康状态💓的指数。
国内A股公司的⼤盘指数有上海证券交易所(上交所)和深圳证券交易(深交所)所提供;
总之,⼤盘指数整体反应了股市的⾏情信息;
国外⼤盘信息

⼤盘指数参数与股票类似,也有开盘点、收盘点、当前点、涨跌、涨幅、振幅等信息;
2️⃣ 什么是板块指数
⼤盘指数反应了
整体的市场⾏情,不能反应具体某个⾏业,⽽板块指数可以更加细粒度的反应具体某个⾏业股市的活跃程度;根据定义板块的⽅式主要分为:
地域板块、⾏业板块、概念板块等;
趋势与震荡
趋势:价格整体朝一个方向走,例如持续上升或持续下降。震荡:价格来回波动,但没有明显单边方向。
后面你会看到:
- 均值回归策略更喜欢震荡。
- 趋势跟踪策略更喜欢单边行情。
技术指标怎么看
K 线、MACD、跳空缺口这些东西,本质上是“帮助你观察历史价格行为的工具”,不是“看到信号就一定会涨或一定会跌”的预言机。
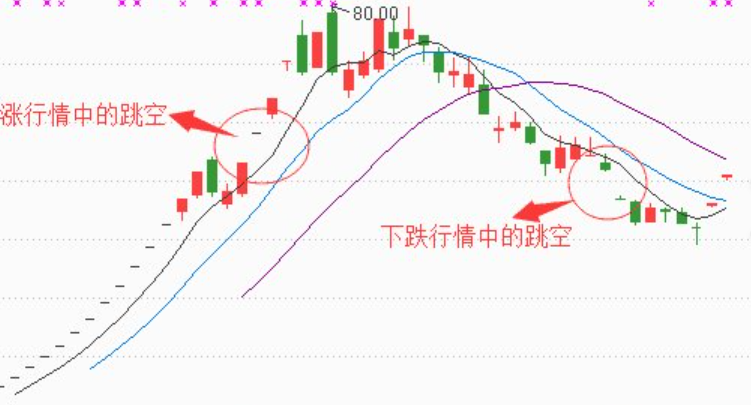
所以看到信号后,正确的问题应该是:
- 它反映了什么市场行为?
- 这个信号过去是否经常有效?
- 如果把它写成规则,回测后结果怎样?
回测是什么
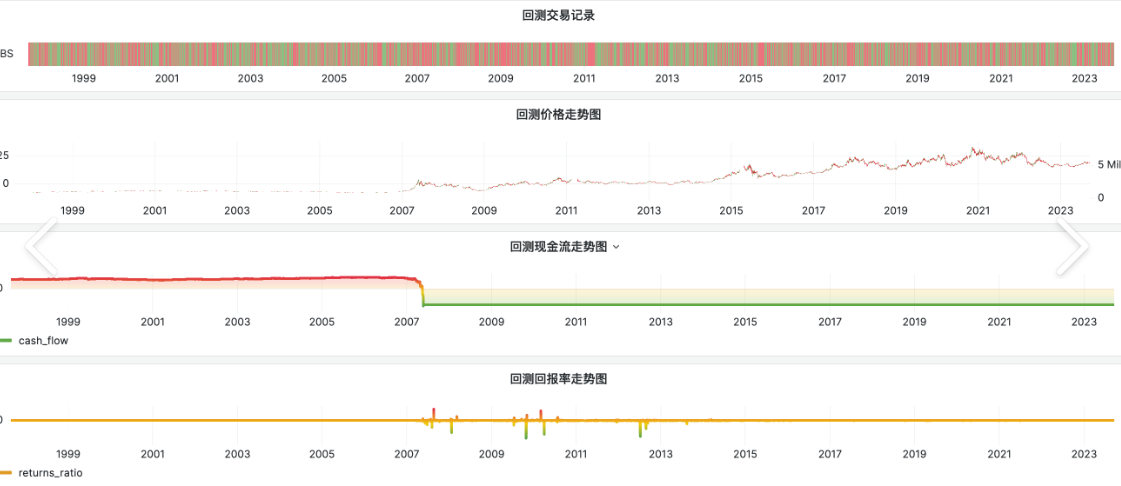
回测 就是把一套交易规则放到历史数据上,模拟“如果当时这样买卖,结果会怎样”。
回测的价值是:
- 把模糊想法写成明确规则。
- 检查规则在历史上是不是完全站不住脚。
回测的局限是:
- 历史有效不等于未来一定有效。
- 手续费、滑点、停牌、涨跌停、流动性等真实约束,都会让实盘结果变差。
4.2 统一运行准备
前言
环境与数据
condalist.txt 里已经包含了本章需要的核心库:pandas、numpy、matplotlib、seaborn、statsmodels。
因此下面所有代码都改成了只依赖这些常见库的写法,不再使用当前环境里没有的 mplfinance 和 TA-Lib。
建议把 个股行情.csv 放在下面两个位置之一:
- 当前目录
data子目录
这份教材数据集的基本规模是:
- 数据总行数:
3612326 - 股票代码数量:
1095
需要特别说明的是:
- 数据集完整字段共有
24列 - 但本章案例实际运行只强制依赖其中最核心的价格、成交量、涨跌幅字段
- 这样做的目的是让零基础学生先把重点放在“读懂行情数据”和“完成基础分析”上
公共准备代码
先运行一次下面的统一准备代码,后面所有案例都可以直接复用。如果你想单独复制某一个案例,也请把这段准备代码一起复制过去。
from pathlib import Path # 用来更方便地处理文件路径
import numpy as np # 数值计算库
import pandas as pd # 数据分析库,本章最常用
import matplotlib.dates as mdates # 处理图中的日期坐标
import matplotlib.pyplot as plt # 绘图库
from matplotlib.patches import Rectangle # 画 K 线实体时要用到矩形
# 让 matplotlib 尽量正常显示中文和负号
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei", "SimHei", "Arial Unicode MS"]
plt.rcParams["axes.unicode_minus"] = False
# 本章案例实际运行只依赖下面这些核心字段,
# 不要求一次性校验数据集中的全部 24 列。
REQUIRED_COLUMNS = [
"代码",
"日期",
"开盘价(元)",
"最高价(元)",
"最低价(元)",
"收盘价(元)",
"成交量(股)",
"涨跌幅(%)",
]
def load_stock_data(filename="个股行情.csv"):
# 先尝试两个常见位置:
# 1. 当前目录
# 2. data 子目录
candidates = [Path(filename), Path("data") / filename]
# next(...) 会返回第一个存在的路径;如果都不存在,就返回 None
data_path = next((path for path in candidates if path.exists()), None)
if data_path is None:
raise FileNotFoundError(
"未找到 个股行情.csv,请把它放在当前目录或 data 目录中。"
)
# 有些同学的数据文件可能是 GBK,也可能是 UTF-8,
# 所以这里按顺序尝试几种常见编码。
last_error = None
for encoding in ("gbk", "utf-8-sig", "utf-8"):
try:
df = pd.read_csv(data_path, encoding=encoding,engine="python")
break
except UnicodeDecodeError as exc:
last_error = exc
else:
raise last_error
# 检查本章代码最少需要哪些列,
# 如果缺少关键列,就直接报错提醒。
missing = [col for col in REQUIRED_COLUMNS if col not in df.columns]
if missing:
raise ValueError(f"数据缺少必要字段: {missing}")
# 把“日期”列转成真正的日期格式,后面按时间排序、分组、画图都会更方便
df["日期"] = pd.to_datetime(df["日期"])
# 这些列本来应该是数值。
# 如果原始数据里混入了空字符串或异常字符,errors="coerce" 会把它转成 NaN
numeric_cols = [
"开盘价(元)",
"最高价(元)",
"最低价(元)",
"收盘价(元)",
"成交量(股)",
"涨跌幅(%)",
]
for col in numeric_cols:
df[col] = pd.to_numeric(df[col], errors="coerce")
# 删除“代码”或“日期”缺失的行,因为这两列是后续分析的基础
df = df.dropna(subset=["代码", "日期"])
# 按股票代码和日期排序,保证同一只股票的时间顺序是正确的
df = df.sort_values(["代码", "日期"]).reset_index(drop=True)
return df
def get_stock(code):
# 先读入全市场数据
df = load_stock_data()
# 只保留某一只股票的数据
stock = df[df["代码"] == code].copy()
if stock.empty:
raise ValueError(f"数据中没有股票代码 {code}")
# 再按日期排序,保证时间序列从早到晚排列
return stock.sort_values("日期").reset_index(drop=True)
def calc_fee(turnover, rate=0.0001, min_fee=5):
# 这里模拟一个最基础的手续费规则:
# 手续费 = 成交金额 * 费率(万1),但不能低于最低收费
return max(turnover * rate, min_fee)
def max_affordable_shares(cash, price, lot_size=100):
# A 股通常按“手”交易,1 手 = 100 股,
# 所以先算在当前现金下最多能买多少股,并向下取整到 100 的倍数。
qty = int(cash // (price * lot_size)) * lot_size
while qty > 0:
# 真实买入时不只是付股票金额,还要加上手续费,
# 所以这里要检查“现金是否足够覆盖成交金额 + 手续费”
turnover = qty * price
if cash >= turnover + calc_fee(turnover):
return qty
# 如果钱不够,就减少 1 手继续试
qty -= lot_size
return 0
# 下面这几行属于“运行自检”:
# 目的是先确认文件能读进来、列名是否正常、数据规模是否符合预期
data = load_stock_data()
print(data.head())
print(data.columns.tolist())
print("数据总行数:", len(data))
print("股票代码数量:", data["代码"].nunique())运行结果:
列:['代码', '简称', '日期', '前收盘价(元)', '开盘价(元)', '最高价(元)', '最低价(元)', '收盘价(元)', '成交量(股)', '成交金额(元)', '涨跌(元)', '涨跌幅(%)', '均价(元)', '换手率(%)', 'A股流通市值(元)', 'B股流通市值(元)', '总市值(元)', 'A股流通股本(股)', 'B股流通股本(股)', '总股本(股)', '市盈率', '市净率', '市销率', '市现率']
数据总行数: 3612326
股票代码数量: 1095从这段输出里,至少要看懂 3 件事:
- 这份数据不是单只股票,而是覆盖
1095只股票的历史行情 - 数据行数达到
3612326,说明样本量足够大,适合做统计和回测入门练习 - 虽然完整字段很多,最核心的仍然是
日期、开盘价(元)、最高价(元)、最低价(元)、收盘价(元)、成交量(股)、涨跌幅(%)
4.3 股票 K 线图
前言
场景题目
把 600629.SH 的历史行情画成标准 K 线图,并同时观察成交量。
先抓关键词
- K 线图的核心是
开盘价、收盘价、最高价、最低价。 - 一根 K 线对应一个交易日。
- 成交量通常和 K 线图搭配使用,因为“价格变化”与“交易活跃度”要一起看。
金融知识补充
- 如果
收盘价 > 开盘价,通常称为阳线,表示当天价格整体偏强。 - 如果
收盘价 < 开盘价,通常称为阴线,表示当天价格整体偏弱。 - 上影线长,说明盘中冲高后回落;下影线长,说明盘中下探后又被拉起。
代码
# 只取 600629.SH 这只股票,并保留画 K 线真正需要的 6 列
stock = get_stock("600629.SH")[
["日期", "开盘价(元)", "最高价(元)", "最低价(元)", "收盘价(元)", "成交量(股)"]
].dropna().tail(60).copy()
# 为了和常见金融图形习惯保持一致,
# 把中文列名改成更短的英文名,后面写代码更清楚
plot_df = stock.rename(
columns={
"日期": "Date",
"开盘价(元)": "Open",
"最高价(元)": "High",
"最低价(元)": "Low",
"收盘价(元)": "Close",
"成交量(股)": "Volume",
}
)
# matplotlib 画日期坐标时,通常会先把日期转成内部使用的数字格式
plot_df["DateNum"] = mdates.date2num(plot_df["Date"])
# 建两个上下排列的子图:
# 上面画价格 K 线,下面画成交量
fig, (ax_price, ax_vol) = plt.subplots(
2,
1,
figsize=(14, 8),
sharex=True,
gridspec_kw={"height_ratios": [3, 1]},
)
# K 线实体的宽度
candle_width = 0.6
# 逐行遍历数据,每一行就是一个交易日
for row in plot_df.itertuples(index=False):
# 收盘价 >= 开盘价,用红色;否则用绿色
color = "#d62728" if row.Close >= row.Open else "#2ca02c"
# 先画影线:从最低价连到最高价
ax_price.vlines(row.DateNum, row.Low, row.High, color=color, linewidth=1.2)
# K 线实体下边界取开盘价和收盘价中的较小值
body_low = min(row.Open, row.Close)
# 实体高度 = 开盘价和收盘价的差值绝对值
# 如果两者完全相等,至少给一个很小高度,避免看不见
body_height = max(abs(row.Close - row.Open), 0.01)
ax_price.add_patch(
Rectangle(
(row.DateNum - candle_width / 2, body_low),
candle_width,
body_height,
facecolor=color,
edgecolor=color,
alpha=0.85,
)
)
# 下方同步画成交量柱状图,颜色与当天涨跌方向保持一致
ax_vol.bar(row.DateNum, row.Volume, width=candle_width, color=color, alpha=0.35)
# 设置标题、坐标轴名称和网格
ax_price.set_title("600629.SH 最近 60 个交易日 K 线图")
ax_price.set_ylabel("价格")
ax_price.grid(alpha=0.25)
ax_vol.set_ylabel("成交量")
ax_vol.grid(alpha=0.25)
# 告诉 x 轴:这里是日期
ax_vol.xaxis_date()
ax_vol.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m"))
# 自动旋转日期标签,避免重叠
fig.autofmt_xdate()
plt.tight_layout()
plt.show()结果解读
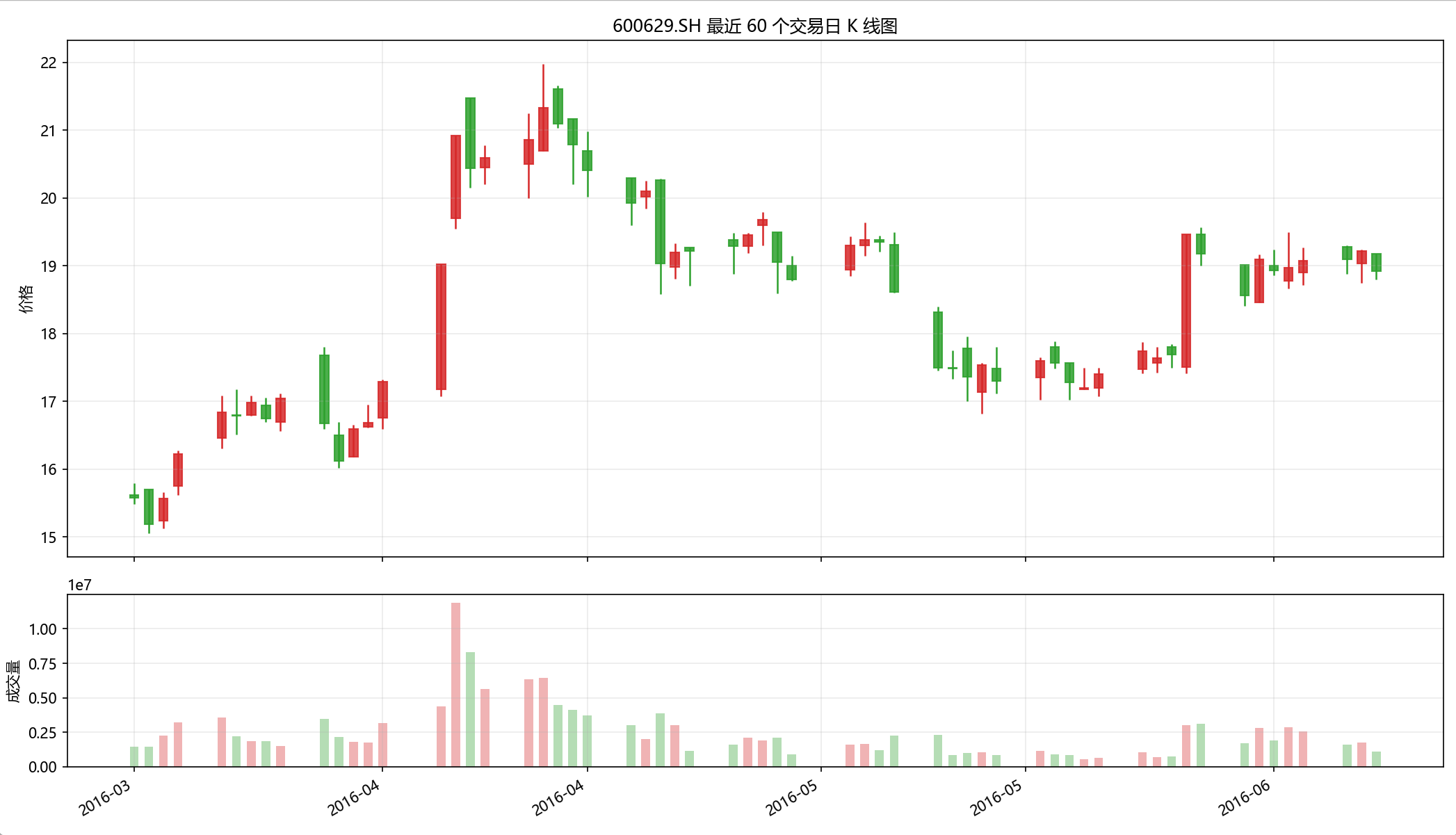
运行后会弹出两部分图形:
- 上半部分是 K 线图,每根蜡烛代表一天。
- 下半部分是成交量柱状图,颜色和当天涨跌方向一致。
看图时先做 3 个判断:
- 最近整体是上升、下降还是横向震荡。
- 是否经常出现长上影线或长下影线。
- 成交量是放大还是缩小,是否和价格趋势同步。
例如:
- 价格上涨同时成交量逐步放大,通常说明市场参与度在增强。
- 价格上涨但量能很弱,说明上涨的持续性还需要继续观察。
- 连续阴线并伴随放量,常常说明短期抛压较重。
易错提醒
- K 线图里最容易错的是把日期忘记转成可绘图的时间格式。
body_height用max(..., 0.01)是为了避免开盘价和收盘价完全相同的时候,实体高度为 0 而看不见。- 这里只画了最近 60 个交易日,是因为全样本太长时图会非常挤,不利于初学者观察。
4.3 MACD 绘制
前言
场景题目
使用 600629.SH 的收盘价计算 MACD,并画出 DIF、DEA 和柱状线。
先抓关键词
- MACD 是趋势类指标,不是价格本身。
DIF是快慢均线的差值。DEA是DIF的平滑线。- 柱状线反映
DIF与DEA的距离变化。
金融知识补充
MACD 的常见解释是:
DIF上穿DEA:通常叫金叉,常被解读为趋势转强信号。DIF下穿DEA:通常叫死叉,常被解读为趋势转弱信号。- 红柱变长:多头动能可能增强。
- 绿柱变长:空头动能可能增强。
注意:这只是“观察工具”,不是稳赚信号。
代码
# 只保留日期和收盘价,MACD 主要基于收盘价计算
stock = get_stock("600629.SH")[["日期", "收盘价(元)"]].dropna().copy()
# 计算 12 日指数移动平均线(短周期)
stock["EMA12"] = stock["收盘价(元)"].ewm(span=12, adjust=False).mean()
# 计算 26 日指数移动平均线(长周期)
stock["EMA26"] = stock["收盘价(元)"].ewm(span=26, adjust=False).mean()
# DIF = 短周期 EMA - 长周期 EMA
stock["DIF"] = stock["EMA12"] - stock["EMA26"]
# DEA 是 DIF 再做一次 9 日指数平滑
stock["DEA"] = stock["DIF"].ewm(span=9, adjust=False).mean()
# 这里采用常见写法:MACD 柱 = 2 * (DIF - DEA)
stock["MACD柱"] = 2 * (stock["DIF"] - stock["DEA"])
# 先打印最后几行,让学生看到:指标图的背后其实是一列列数值
print(stock[["日期", "收盘价(元)", "DIF", "DEA", "MACD柱"]].tail())
# MACD 柱大于等于 0 用红色,小于 0 用绿色
colors = np.where(stock["MACD柱"] >= 0, "#d62728", "#2ca02c")
# 画 DIF、DEA 两条线,再叠加 MACD 柱
fig, ax = plt.subplots(figsize=(14, 6))
ax.plot(stock["日期"], stock["DIF"], label="DIF", color="#d62728", linewidth=1.5)
ax.plot(stock["日期"], stock["DEA"], label="DEA", color="#1f77b4", linewidth=1.5)
ax.bar(stock["日期"], stock["MACD柱"], color=colors, alpha=0.45, label="MACD柱")
ax.set_title("600629.SH 的 MACD 指标")
ax.set_ylabel("指标值")
ax.legend()
ax.grid(alpha=0.25)
plt.tight_layout()
plt.show()结果解读
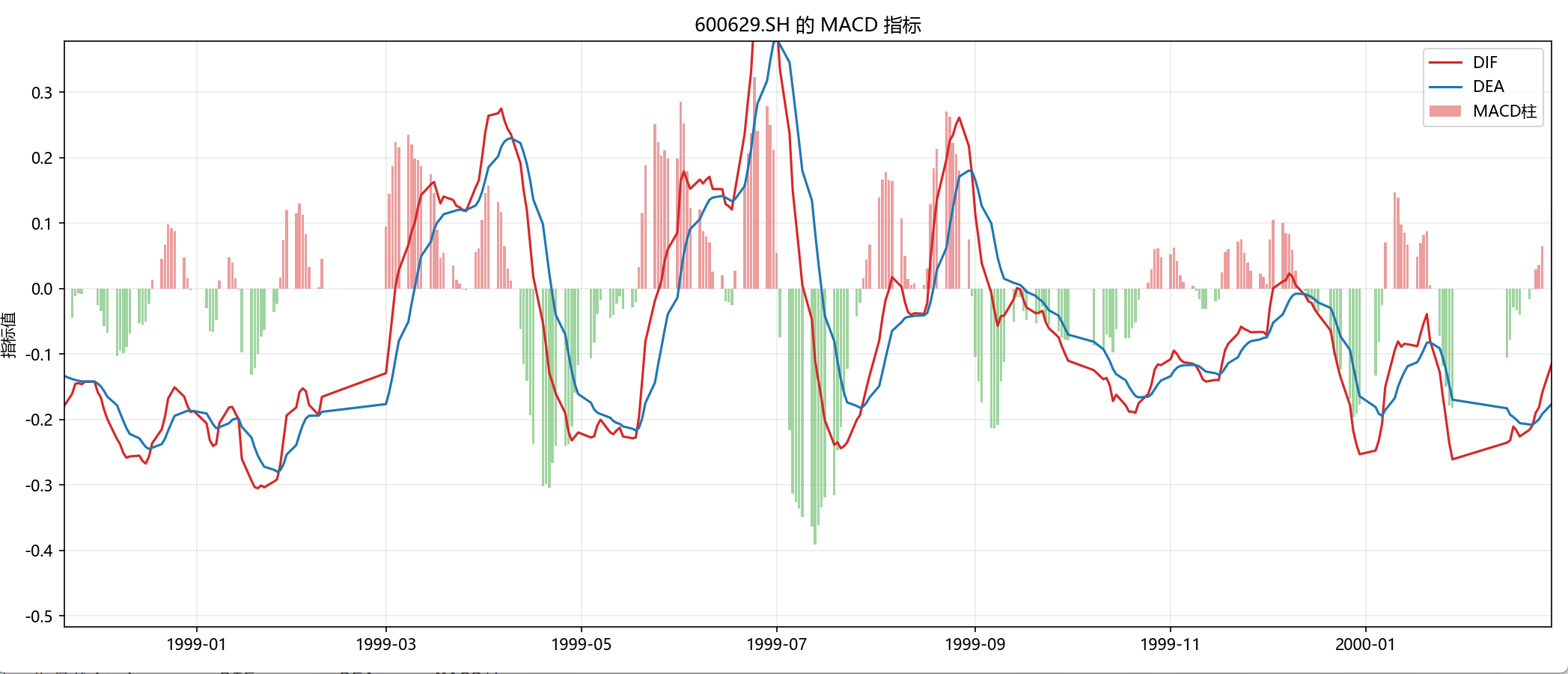
代码会先打印出最后几行指标值,再画出一张 MACD 图。
打印表格的作用是:
- 让你知道 MACD 不只是图,它本质上也是一列一列的数值。
- 以后做量化策略时,你就是根据这些数值来写规则。
图形的阅读顺序建议是:
- 先看
DIF和DEA谁在上面。 - 再看它们有没有发生交叉。
- 最后看柱状线是在放大还是缩短。
如果你看到:
DIF在DEA上方,而且红柱持续放大,通常表示短期趋势偏强。DIF在DEA下方,而且绿柱持续变长,通常表示短期趋势偏弱。
易错提醒
ewm()是指数加权平均,和普通移动平均不是一回事。span=12、26、9是常见默认参数,不是唯一答案。- MACD 是滞后指标,因为它基于历史价格计算,不可能领先于所有价格变化。
5 股票行情分析
前言
这一部分不再只看一只股票,而是开始从数据中总结“整体规律”和“结构特征”。
要学会把“看到一只股票”,升级成“看到一类现象”。
读图提醒
- 看到涨跌幅分布,要想到市场整体波动结构。
- 看到星期统计,要想到是否存在日历效应。
- 看到跳空缺口,要想到价格是否出现了明显的强弱变化。
5.1 股票涨跌幅分布统计
前言
场景题目
统计全样本股票的涨跌幅分布,看看大多数交易日到底是“小波动居多”还是“大涨大跌居多”。
先抓关键词
- 这里看的是“全样本分布”,不是只看一只股票。
- 分布图回答的是“常见情况是什么”,不是“明天会不会涨”。
round(1)的含义是把涨跌幅按0.1%为一个小区间来统计。
金融知识补充
研究涨跌幅分布,实际是在研究“市场波动结构”。
如果分布图出现:
- 中间高、两边低:说明大多数日子波动不大。
- 两边很厚:说明极端涨跌较多,市场风险更高。
这和只看平均收益不同。
平均收益可能差不多,但波动结构可以完全不同。
代码
# 先读入全市场数据,并删除“涨跌幅(%)”为空的记录
data = load_stock_data().dropna(subset=["涨跌幅(%)"]).copy()
# 把涨跌幅按 0.1% 四舍五入,便于后面统计“每个小区间出现了多少次”
data["涨跌幅分组"] = data["涨跌幅(%)"].round(1)
# 统计每个涨跌幅分组出现的次数,并按分组数值从小到大排序
dist = data["涨跌幅分组"].value_counts().sort_index()
# 先打印几个最基础的描述统计量,帮助学生理解样本整体波动情况
print("样本均值:", round(data["涨跌幅(%)"].mean(), 3))
print("样本标准差:", round(data["涨跌幅(%)"].std(), 3))
print("最小值:", round(data["涨跌幅(%)"].min(), 3))
print("最大值:", round(data["涨跌幅(%)"].max(), 3))
# 画柱状图:横轴是涨跌幅分组,纵轴是出现次数
fig, ax = plt.subplots(figsize=(14, 5))
ax.bar(dist.index, dist.values, width=0.09, color="#4c72b0")
ax.set_title("股票涨跌幅分布")
ax.set_xlabel("涨跌幅(%),已按 0.1% 分组")
ax.set_ylabel("出现次数")
ax.set_xlim(-12, 12)
ax.grid(alpha=0.25)
plt.tight_layout()
plt.show()结果解读
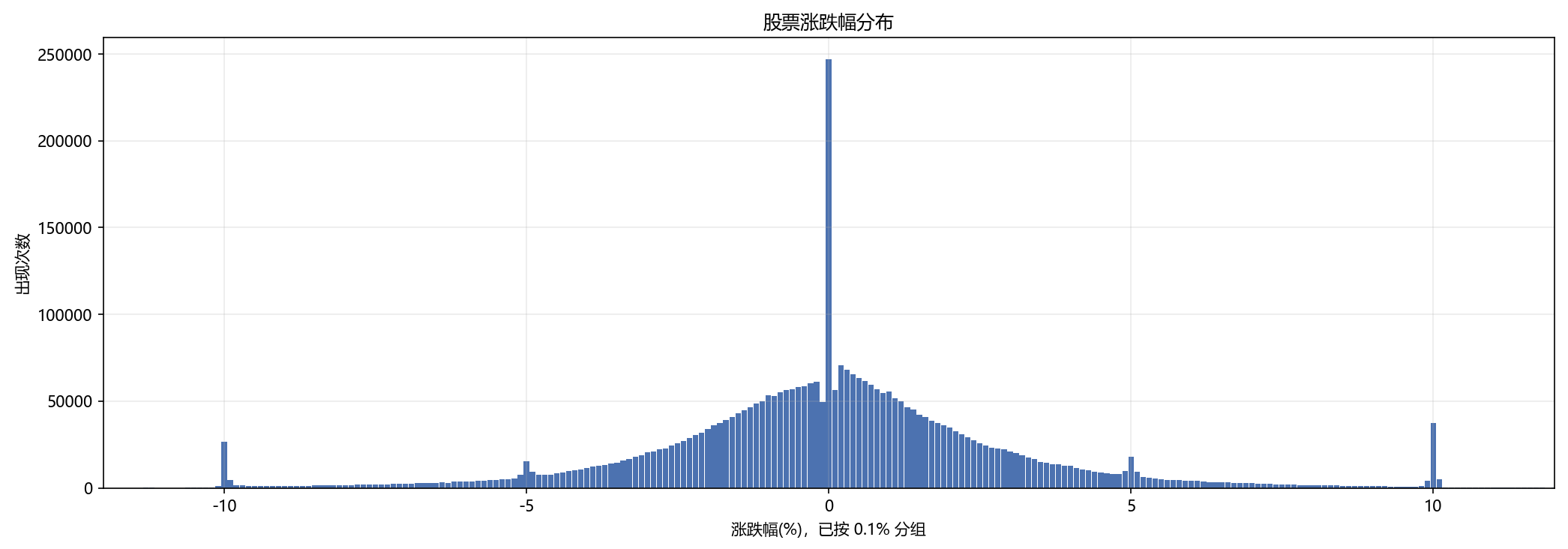
样本均值: 0.086
样本标准差: 3.338
最小值: -68.733
最大值: 1097.521会得到两部分结果:
- 终端里会打印均值、标准差、最小值、最大值。
- 弹出的柱状图会显示不同涨跌幅区间出现了多少次。
解读时重点看:
- 最高的柱子是不是集中在
0附近。 - 左右两侧是否大致对称。
- 极端大涨和极端大跌是不是很多。
如果 0 附近柱子最高,说明市场大多数时候并不是每天都在大起大落,而是更多处于相对温和的小波动状态。
易错提醒
涨跌幅(%)是百分数,不需要再除以100。- 这里研究的是“历史分布”,不是预测模型。
- 如果某些数据异常,比如涨跌幅出现明显错误值,图形会被拉得很怪,这时要先检查原始数据质量。
5.2 统计股票在周几更容易上涨
前言
场景题目
先对全体股票按“星期几 + 涨跌标签”统计,再单独观察 600629.SH 在周一到周五的上涨、平盘、下跌次数。
先抓关键词
- 关键词是“日历效应”。
- 这里统计的是次数,不是平均涨跌幅。
- 先做全样本分组,再抽取一只股票做阅读,会比直接打印所有结果更清楚。
金融知识补充
所谓“星期效应”,是指:
- 某些市场在周一、周五等特定交易日,可能更容易表现出某种偏向。
但这类规律常见两个风险:
- 样本期一变,结果可能就变了。
- 就算统计上有偏向,也未必足够覆盖手续费和交易成本。
所以这类分析适合做“发现现象”,不适合直接下结论“以后周五必涨”。
代码
# 先读入全市场数据,只保留涨跌幅不为空的记录
data = load_stock_data().dropna(subset=["涨跌幅(%)"]).copy()
# 把 weekday 数字映射成更直观的中文星期名
weekday_map = {0: "周一", 1: "周二", 2: "周三", 3: "周四", 4: "周五"}
weekday_order = ["周一", "周二", "周三", "周四", "周五"]
# 从日期里提取“星期几”
data["星期"] = data["日期"].dt.weekday.map(weekday_map)
# A 股只看工作日交易,因此把没映射上的记录排除掉
data = data[data["星期"].notna()].copy()
# 用 np.select 给每一条记录打标签:
# 涨跌幅 > 0 记为“上涨”
# 涨跌幅 < 0 记为“下跌”
# 等于 0 记为“平盘”
data["涨跌标签"] = np.select(
[data["涨跌幅(%)"] > 0, data["涨跌幅(%)"] < 0],
["上涨", "下跌"],
default="平盘",
)
# 按“股票代码 + 星期 + 涨跌标签”统计出现次数
stat = (
data.groupby(["代码", "星期", "涨跌标签"])
.size()
.reset_index(name="天数")
)
# 这里先拿 600629.SH 做教学演示
target_code = "600629.SH"
# 透视表的作用是把长表变宽表,
# 让“上涨、平盘、下跌”分别变成不同列,更方便阅读
table = (
stat[stat["代码"] == target_code]
.pivot(index="星期", columns="涨跌标签", values="天数")
.reindex(weekday_order)
.fillna(0)
.astype(int)
)
# 把列顺序固定下来,并补出总天数和上涨占比
table = table.reindex(columns=["上涨", "平盘", "下跌"], fill_value=0)
table["总天数"] = table.sum(axis=1)
table["上涨占比"] = (table["上涨"] / table["总天数"]).round(3)
# 打印最终结果表
print(table)结果解读
输出结果是一张按星期排列的小表。
星期 上涨 平盘 下跌 总天数 上涨占比
周一 470 69 478 1017 0.462
周二 496 67 478 1041 0.476
周三 510 69 466 1045 0.488
周四 438 80 518 1036 0.423
周五 468 80 483 1031 0.454每一行代表一个交易日类型,例如周一或周五;每一列代表上涨、平盘、下跌出现了多少次。
重点看两列:
上涨上涨占比
如果某一天的 上涨占比 明显高于其他天,说明这只股票在历史样本中,确实在这个星期几更容易上涨。
但要记住:
- “更容易”不等于“必然”。
- 次数多不等于赚钱多,因为涨 1 次 0.2% 和涨 1 次 8% 完全不是一回事。
易错提醒
weekday()里0表示周一,不是周日。- 如果直接打印全部股票,会得到很长的结果,初学者很难读,所以这里专门抽了
600629.SH做展示。 - 如果你想研究别的股票,把
target_code改掉即可。
5.3 自动识别跳空缺口
前言
场景题目
找出 600339.SH 历史上的跳空交易日,并区分是向上跳空还是向下跳空。
先抓关键词
- 跳空要和“昨天的价格区间”比较,不是和今天自己比。
shift(1)的作用,就是把昨天的数据对齐到今天。- 跳空可以分方向:向上跳空、向下跳空。
金融知识补充
跳空缺口的直观含义是:
- 今天一开盘,价格就直接跳到了昨天波动区间之外。
常见解释:
向上跳空:市场情绪突然变强。向下跳空:市场情绪突然转弱。
但缺口并不一定都有效,有的缺口很快会被“回补”,也就是后面价格又回到了原来的区间。
代码
# 只取 600339.SH,并保留识别跳空需要的 4 列
stock = get_stock("600339.SH")[
["日期", "开盘价(元)", "最高价(元)", "最低价(元)"]
].dropna().copy()
# 把前一天的最高价、最低价移动到今天这一行,
# 这样今天就能直接和“昨天的价格区间”做比较
stock["昨日最高价"] = stock["最高价(元)"].shift(1)
stock["昨日最低价"] = stock["最低价(元)"].shift(1)
# 向上跳空:今天开盘价 > 昨天最高价
gap_up = stock["开盘价(元)"] > stock["昨日最高价"]
# 向下跳空:今天开盘价 < 昨天最低价
gap_down = stock["开盘价(元)"] < stock["昨日最低价"]
# 给每一行打上“向上跳空 / 向下跳空 / 无”标签
stock["缺口方向"] = np.select(
[gap_up, gap_down],
["向上跳空", "向下跳空"],
default="无",
)
# 计算缺口幅度:
# 向上跳空时,用今天开盘价和昨天最高价比较
# 向下跳空时,用今天开盘价和昨天最低价比较
stock["缺口幅度(%)"] = np.select(
[gap_up, gap_down],
[
(stock["开盘价(元)"] / stock["昨日最高价"] - 1) * 100,
(stock["开盘价(元)"] / stock["昨日最低价"] - 1) * 100,
],
default=np.nan,
)
# 只保留真的发生了跳空的交易日
gaps = stock[stock["缺口方向"] != "无"].copy()
# 先看总共筛出了多少天,再看前 10 条样本
print("跳空交易日数量:", len(gaps))
print(
gaps[
["日期", "开盘价(元)", "昨日最高价", "昨日最低价", "缺口方向", "缺口幅度(%)"]
].head(10)
)结果解读
日期 开盘价(元) 昨日最高价 昨日最低价 缺口方向 缺口幅度(%)
8 2001-01-05 6.2201 6.1819 6.0498 向上跳空 0.617933
13 2001-01-12 5.9735 6.0675 5.9786 向下跳空 -0.085304
14 2001-01-15 5.9252 6.0116 5.9557 向下跳空 -0.512114
15 2001-01-16 5.7574 5.9735 5.8210 向下跳空 -1.092596
18 2001-01-19 5.8922 5.8718 5.7701 向上跳空 0.347423
20 2001-02-06 5.7956 5.9532 5.8083 向下跳空 -0.218653
26 2001-02-14 5.5668 5.7066 5.5871 向下跳空 -0.363337
30 2001-02-20 5.7142 5.6786 5.5922 向上跳空 0.626915
34 2001-02-26 5.8439 5.8083 5.6939 向上跳空 0.612916
35 2001-02-27 5.7193 5.8693 5.7574 向下跳空 -0.661757你会看到:
- 总共有多少个跳空交易日。
- 前 10 个跳空样本分别是哪一天、方向是什么、幅度有多大。
看结果时建议重点关注两点:
- 向上跳空和向下跳空哪个更多。
- 缺口幅度是不是很大。
如果某些缺口幅度特别大,往往说明当时市场情绪变化比较剧烈,值得回到 K 线图里进一步观察。
易错提醒
- 第一行没有昨天的数据,所以自然会出现空值,这是正常现象。
- 这里识别的是“缺口出现了没有”,不是判断“这个缺口是否值得交易”。
- 代码默认只看
600339.SH,因为跳空逐日核对时,一次盯一只股票最清楚。