
、
一、决策树分析
前言
1.理论与概念
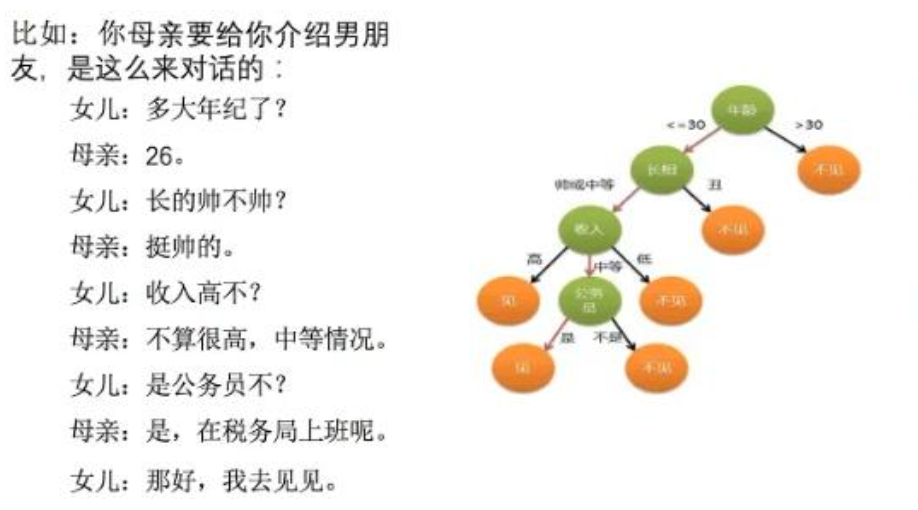
决策树基本上就是把我们以前的经验总结出来,如下图中的场景,如果去相亲,一般会根据“年龄”、“长相”、“身高”、“收入”这几个条件来判断,最后得到结果:去?还是不去?
- 决策树 = 提问题 → 分分支 → 得结果
- 节点:提一个问题(如: 多大年龄?)
- 分支:是 / 否
- 叶节点:最终结果(相亲 / 不相亲)
- 通俗例子:医院看病 → 先问发烧吗?再问咳嗽吗?最后判断感冒还是肺炎。
- 工作例子:HR分析员工为什么离职,找出最关键的因素。
2.案例1:分析各特征对员工离职的影响程度
- 把文字(男 / 女、是 / 否)转成机器能算的数字
- 把数据分成训练集、测试集
- 用模型计算每个因素影响力得分
- 输出一串数字:越大越重要
2.1 代码
# 导入需要的工具库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.preprocessing import LabelEncoder
# 定义函数:把文本类型的列(如部门、性别)转换成数字
def addNewCol(frame,preColName,newColName):
# 创建编码器
encoding= LabelEncoder()
# 让编码器学习文本内容
encoding.fit(frame[preColName])
# 把文本转成数字
education_new=encoding.transform(frame[preColName])
# 把转换后的数字列加到数据里
col_Attrition= pd.DataFrame(education_new, columns=[newColName])
frame= pd.concat([frame,col_Attrition], axis=1)
return frame
# 1. 读取员工数据文件
frame=pd.read_csv("bi-attrition.csv", sep=',')
# 2. 批量把文本列转成数字列
frame=addNewCol(frame,"Attrition", "NewAttrition")
frame=addNewCol(frame, 'BusinessTravel',"NewBusinessTravel")
frame = addNewCol(frame, 'Department',"NewDepartment")
frame = addNewCol(frame, "EducationField","NewEducationField")
frame = addNewCol(frame,"Gender","NewGender")
frame = addNewCol(frame,"JobRole","NewJobRole")
frame = addNewCol(frame, "MaritalStatus","NewMaritalStatus")
frame = addNewCol(frame, "Over18","NewOver18")
frame=addNewCol(frame,"OverTime","NewOverTime")
# 3. 删除原来的文本列,只保留数字列用于计算
#1Attrition:离职,2BusinessTravel:出差,3Department:部门,4EducationField:教育背景,5Gender:性别,6JobRole:工作角色,7MaritalStatus:婚姻状况,8Over18:是否成年,9OverTime:是否加班
frame.drop(columns=['Attrition',"BusinessTravel",'Department',"EducationField",
'Gender',"JobRole","MaritalStatus","Over18","OverTime"],inplace=True)
# 4. 设定目标变量(是否离职)和特征变量(其他所有信息)
y = frame['NewAttrition']
X=frame.drop(columns='NewAttrition')
# 5. 把数据分成训练集(80%)和测试集(20%)
X_train,X_test,y_train,y_test= train_test_split(X,y,test_size=0.2,random_state=7)
# 6. 创建模型:AdaBoost提升决策树,深度设为6
regressor=AdaBoostRegressor(DecisionTreeRegressor(max_depth=6))
# 7. 用训练数据训练模型
regressor.fit(X_train,y_train)
# 8. 输出每个特征对离职的影响重要性
print(regressor.feature_importances_)3.核心API说明
LabelEncoder:把文字(销售部、技术部)变成数字,机器才能计算train_test_split:把数据分成训练用和测试用AdaBoostRegressor:强化决策树,计算每个因素的重要程度feature_importances_:输出每个特征对离职的影响力大小
4.结果解说
输出一串小数:0.04049813 0.06458858 0.07285023 0.04720917 0.01052268 0. 0.03174929 0.03297091 0.0554335 0.02099191 0.01133699 0.02481439 0.08409242 0.06760596 0.03951079 0.04785432 0.00064354 0.01873737 0.02106002 0.03075606 0.01990919 0.01859748 0.02548275 0.01918998 0.02169489 0.04291414 0.01358034 0.00626735 0.01815389 0.00705275 0.03587704 0.01619881 0. 0.03185517
- 数字越大 → 这个因素越容易导致员工离职
- 数值最高的通常是:加班、工作满意度、工作生活平衡
- 数值接近0的(如年龄、性别)基本不影响离职
3. 案例2:决策树判断离职并可视化
上面的案例虽然能求出离职的影响因素,但无法直观地看到决策树的结构,HR和管理者等非专业人员很难理解。所以,我们还需要把决策树的结构可视化出来,让非技术人员也能看懂。
提前安装 :pydotplus和graphviz
pip install pydotplus
#安装 graphviz(必须装,否则决策树图出不来)
pip install graphviz3.1 代码
# 导入工具库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn import tree
import pydotplus
# 文本转数字函数
def addNewCol(frame,preColName,newColName):
encoding= LabelEncoder()
encoding.fit(frame[preColName])
education_new=encoding.transform(frame[preColName])
col_Attrition= pd.DataFrame(education_new, columns=[newColName])
frame= pd.concat([frame,col_Attrition], axis=1)
return frame
# 读取数据
frame= pd.read_csv("bi-attrition.csv", sep=',')
# 文本列转数字列
frame=addNewCol(frame,'Attrition',"NewAttrition")
frame=addNewCol(frame, 'BusinessTravel','NewBusinessTravel')
frame = addNewCol(frame, 'Department',"NewDepartment")
frame = addNewCol(frame, 'EducationField', 'NewEducationField')
frame=addNewCol(frame,"Gender","NewGender")
frame= addNewCol(frame, 'JobRole',"NewJobRole")
frame = addNewCol(frame, "MaritalStatus","NewMaritalStatus")
frame = addNewCol(frame, "Over18","NewOver18")
frame=addNewCol(frame,"OverTime","NewOverTime")
# 删除原文本列
frame.drop(columns=['Attrition',"BusinessTravel",'Department',"EducationField",
'Gender',"JobRole","MaritalStatus","Over18","OverTime"],inplace=True)
# 设定特征和目标
y = frame['NewAttrition']
X= frame.drop(columns='NewAttrition')
# 拆分训练集测试集
X_train,X_test,y_train,y_test= train_test_split(X,y,test_size=0.2,random_state=7)
# 创建决策树分类模型
model= tree.DecisionTreeClassifier()
# 训练模型
model.fit(X_train,y_train)
# 导出决策树结构
data = tree.export_graphviz(
model,
feature_names=X.columns, # 特征名称
class_names=["不离职","离职"], # 分类结果
filled=True, # 填充颜色
rounded=True # 圆角样式
)
# 生成图片并保存
graph = pydotplus.graph_from_dot_data(data)
graph.write_png('决策树结果.png')核心API说明
DecisionTreeClassifier:构建分类决策树export_graphviz:把树结构导出pydotplus:生成可视化图片
结果解说
- 关键判断节点:
- 环境满意度 < 1.5
- 工作生活平衡 ≤ 3.5
- 满足这两个条件的员工,离职概率极高
- HR可直接用这个规则做留人预警
二、线性规划分析
提示
企业资源永远有限:钱有限、原料有限、产能有限。你需要在限制条件下,找到最赚钱 / 最省钱的方案。
我们需要计算出:
- 生产多少最赚钱?
- 原料怎么配成本最低?
2.1 双变量生产规划(利润最大化)
前言
理论与概念
线性规划:在资源有限的条件下,算出利润最大或成本最小的方案。
- 通俗例子:妈妈只有100元,买苹果和香蕉,怎么买最划算
- 工作例子:工厂原料有限,怎么安排产量赚最多钱
- 核心结论:最优解一定出现在可行域的顶点上
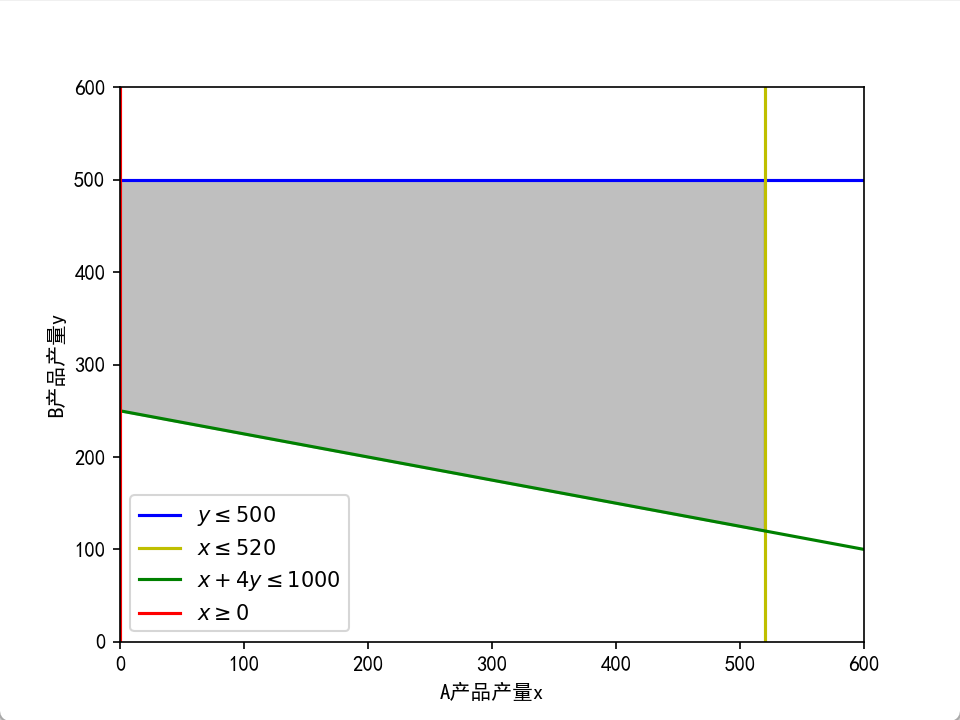
案例1:生产计划约束可行域可视化
某企业生产 A、B 两种产品,受到产量与综合产能限制:
- A 产品最大产量:
- B 产品最大产量:
- 综合产能约束:
- 产量非负:
代码
import numpy as np
import matplotlib.pyplot as plt
# 生成x轴数据
x1=np.linspace(0,600,1000)
# 定义约束条件直线
y1=(x1*0)+500 # y ≤ 500
y2=np.linspace(0,600,1000)
x2=(y2*0)+520 # x ≤ 520
y3=(1000-x1)/4 # x + 4y ≤ 1000
x4=(y1*0) # x ≥ 0
# 绘制4条约束线
plt.plot(x1,y1,"-b",label=r'$y\leq500$')
plt.plot(x2,y2,"-y",label=r'$x\leq520$')
plt.plot(x1,y3,'g',label=r'$x+4y\leq1000$')
plt.plot(x4,y2,'r',label=r'$x\geq0$')
# 设置坐标轴范围
plt.xlim(0,600)
plt.ylim(0,600)
plt.xlabel('A产品产量x')
plt.ylabel('B产品产量y')
# 填充可行域(灰色区域)
plt.fill_between(x1, y3,y1,where=x1<=520,color='grey',alpha=0.5)
# 显示图例
plt.legend()
# 显示图片
plt.show()结果解说
- 灰色区域 = 所有合法的生产方案
- 只有4个顶点,最优解一定在这4个点里
案例2:scipy求解最优产量
在资源有限、产量有限、产能有限的情况下,算出生产多少 A 产品、多少 B 产品,能让利润最大!
1.案例背景
某企业生产 A、B 两种产品,相关数据如下:
- A 产品单位利润:2 元
- B 产品单位利润:3 元
- 约束条件:
- A 产量上限:x ≤ 520
- B 产量上限:y ≤ 500
- 综合产能约束:x + 4y ≤ 1000
- 产量非负:x ≥ 0,y ≥ 0
目标:安排产量使总利润最大化。
2.模型建立
决策变量:x=A产量,y=B产量
目标函数(最大化):
约束条件:
3.Python 代码
from scipy import optimize as op
import numpy as np
# 目标函数系数:利润 2x + 3y
C = np.array([2, 3])
# 不等式约束系数矩阵(≤ 形式)
A_ub = np.array([
[1, 0], # x ≤ 520
[0, 1], # y ≤ 500
[1, 4], # x + 4y ≤ 1000
[-1, 0], # x ≥ 0
[0, -1] # y ≥ 0
])
# 约束右侧值
B_ub = np.array([520, 500, 1000, 0, 0])
# linprog 默认求最小值,求最大值需加负号
res = op.linprog(-C, A_ub, B_ub)
# 输出结果
print(res)4.运行结果
message: Optimization terminated successfully. (HiGHS Status 7: Optimal)
success: True
status: 0
fun: -1400.0
x: [520.0, 120.0]5.结果分析
- 求解状态:
success: True,模型求解成功,得到全局最优解。 - 最优产量:
- A 产品生产 520 件
- B 产品生产 120 件
- 最大利润:
- 目标函数
fun = -1400.0,还原后总利润 1400 元。
- 目标函数
- 约束利用情况:
- A 产品产量已达上限;
- 综合产能约束
x+4y=1000刚好用满; - B 产品仍有剩余产能。
6.结论
在现有约束条件下,企业应生产 A 产品 520 件、B 产品 120 件,可实现最大毛利润 1400 元。
案例3:pulp求解
1.提前安装:pip install pulp
/pʌlp/
1.案例背景
某企业生产 A、B 两种产品,相关数据如下:
- A 产品单位利润:2 元
- B 产品单位利润:3 元
- 固定成本:1000 元
- 约束条件:
- A 产量上限:x ≤ 520
- B 产量上限:y ≤ 500
- 综合产能约束:x + 4y ≤ 1000
- 产量非负:x ≥ 0,y ≥ 0
目标:安排产量使最终利润最大化。
2.模型建立
- 决策变量:x=A产品产量,y=B产品产量
- 目标函数(最大化):
- 约束条件:
3.Python 代码
import pulp
# 定义线性规划问题,目标:最大化利润
my_lp_problem = pulp.LpProblem("MyProblem", pulp.LpMaximize)
# 定义变量 x,y 表示产品产量,必须大于等于0
X = pulp.LpVariable('x', lowBound=0, cat='Continuous')
y = pulp.LpVariable('y', lowBound=0, cat='Continuous')
# 目标函数:总利润 = 2x + 3y - 固定成本1000
my_lp_problem += 2 * X + 3 * y - 1000
# 添加约束条件
my_lp_problem += X <= 520 # A产量上限
my_lp_problem += y <= 500 # B产量上限
my_lp_problem += X + 4 * y <= 1000 # 综合产能约束
my_lp_problem += X >= 0 # 产量非负
my_lp_problem += y >= 0
# 开始求解
my_lp_problem.solve()
# 输出每个变量的最优值
for variable in my_lp_problem.variables():
print("{}={}".format(variable.name, variable.varValue))
# 输出最大利润
print("最大利润:", pulp.value(my_lp_problem.objective))4.运行结果
x=520.0
y=120.0
最大利润: 400.05.结果分析
- 求解状态:程序正常运行,成功找到最优生产方案。
- 最优产量:
- A 产品生产 520 件
- B 产品生产 120 件
- 最大利润:扣除固定成本后,企业可获得最大利润 400 元。
- 约束说明:
- A 产品已达到生产上限;
- 产能约束
x+4y=1000完全用尽; - B 产品仍有剩余产能。
6.结论
在现有生产约束下,企业应生产 A 产品 520 件、B 产品 120 件,可实现最大利润 400 元。
2.2 多变量生产规划(成本最小化)
前言
1.案例背景
某企业生产 A、B 两种产品,均由 S1、S2、S3 三种原材料构成。
- 原材料成本:S1=4.32 元/公斤,S2=2.46 元/公斤,S3=1.86 元/公斤
- 生产需求:A 产品 500 件,B 产品 350 件,每件消耗原材料 0.05 公斤
- 配方约束:
- A 产品中 S1 占比 ≥ 60%
- B 产品中 S1 占比 ≥ 40%
- A、B 产品中 S3 占比均 ≤ 25%
- 库存约束:
- 23 ≤ S1 总用量 ≤ 30
- S2 总用量 ≤ 20
- S3 总用量 ≤ 17
目标:在满足所有约束下,使原材料总成本最低。
2.模型建立
- 决策变量:
- A 产品中 S1、S2、S3 用量:a1、a2、a3
- B 产品中 S1、S2、S3 用量:b1、b2、b3
- 目标函数(最小化总成本):
- 核心约束:
- 总重量约束:
- 配方比例约束、库存总量约束(见代码)
3.Python 代码
import pulp
# 定义线性规划问题,目标:成本最小化
my_lp_problem = pulp.LpProblem("MyProblem", pulp.LpMinimize)
# 定义产品类型与原材料种类
product_types = ['A', "B"]
ingredients = ['S1', 'S2', 'S3']
# 批量定义变量:每个产品使用各原材料的重量(≥0)
ing_weight = pulp.LpVariable.dicts(
"weight",
((i, j) for i in product_types for j in ingredients),
lowBound=0,
cat='Continuous'
)
# 目标函数:计算所有产品的原材料总成本
my_lp_problem += pulp.lpSum(
4.32 * ing_weight[(i, 'S1')]
+ 2.46 * ing_weight[(i, 'S2')]
+ 1.86 * ing_weight[(i, 'S3')]
for i in product_types
)
# ========== 约束1:产品总原材料重量 ==========
my_lp_problem += pulp.lpSum([ing_weight['A', j] for j in ingredients]) == 500 * 0.05
my_lp_problem += pulp.lpSum([ing_weight['B', j] for j in ingredients]) == 350 * 0.05
# ========== 约束2:S1原材料占比要求 ==========
my_lp_problem += ing_weight['A', 'S1'] >= 0.6 * pulp.lpSum([ing_weight['A', j] for j in ingredients])
my_lp_problem += ing_weight['B', 'S1'] >= 0.4 * pulp.lpSum([ing_weight['B', j] for j in ingredients])
# ========== 约束3:S3原材料占比上限 ==========
my_lp_problem += ing_weight['A', 'S3'] <= 0.25 * pulp.lpSum([ing_weight['A', j] for j in ingredients])
my_lp_problem += ing_weight['B', 'S3'] <= 0.25 * pulp.lpSum([ing_weight['B', j] for j in ingredients])
# ========== 约束4:原材料总库存限制 ==========
my_lp_problem += pulp.lpSum([ing_weight[i, 'S1'] for i in product_types]) <= 30
my_lp_problem += pulp.lpSum([ing_weight[i, 'S1'] for i in product_types]) >= 23
my_lp_problem += pulp.lpSum([ing_weight[i, 'S2'] for i in product_types]) <= 20
my_lp_problem += pulp.lpSum([ing_weight[i, 'S3'] for i in product_types]) <= 17
# 求解模型
my_lp_problem.solve()
# 输出求解状态
print("求解状态:", pulp.LpStatus[my_lp_problem.status])
# 输出各原材料最优用量
for var in ing_weight:
print(f"{var[0]}产品{var[1]}:{ing_weight[var].varValue} 公斤")
# 输出最小总成本
total_cost = pulp.value(my_lp_problem.objective)
print("最小总成本:", round(total_cost, 2))4.运行结果
求解状态: Optimal
A产品S1:15.0 公斤
A产品S2:3.75 公斤
A产品S3:6.25 公斤
B产品S1:8.0 公斤
B产品S2:5.125 公斤
B产品S3:4.375 公斤
最小总成本: 140.955.结果分析
- 求解状态:输出
Optimal,说明模型成功找到全局最优解。 - 最优用料方案:
- A 产品:S1=15.3kg,S2=3.75kg,S3=6.25kg
- B 产品:S1=8.0kg,S2=5.125kg,S3=4.375kg
- 最小成本:在满足配方、库存全部约束下,总成本最低为 140.95 元。
- 约束满足:所有配方比例、原材料库存限制均满足,方案可直接用于生产。
6.结论
企业应按照上述方案配比原材料,既能满足产品配方与生产需求,又能使原材料采购与使用成本达到最低,为最优生产用料决策。