
时间序列分析
二、时序水平指标分析
时序水平指标用于描述时间序列在不同时间点的发展状况,核心包括发展水平和增减量两类指标。
2.1 发展水平
前言
发展水平即时间序列各个时间点的观察值,核心分析为平均发展水平的计算,常用3种方法,均基于pandas处理GDP年度数据实现,数据预处理通用步骤:
import pandas as pd
data = pd.read_csv("GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
# 转置行列,适配时间序列按年度索引
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)(1)简单算术平均法
直接计算时序数据的算术平均值,适用于均匀间隔的时序数据,代码与结果:
print(data["国内生产总值(亿元)"].mean()) # 结果:487034.61统计方法采用标准的平均值 方式,这种通常是以天为单位进行计算。
(2)首末折半法(序时平均法)
首末折半法(也叫 “序时平均法”)是计算时期序列平均发展水平的专用方法,核心目的是更精准地反映时间序列在连续时期内的平均发展水平,尤其适配 “间隔均匀、连续统计” 的经济金融时期数据(如年度 GDP、月度销售额)。
公式:(a1/2 + a2 + a3 + ... + an/2) / (n-1),通过折半首尾的时点值,让每个数据的 “时间权重” 相等,计算出的平均值更准确。
对比理解:简单算术平均 vs 首末折半法
以3年GDP数据为例(2021:100亿、2022:120亿、2023:150亿):
| 方法 | 计算公式 | 结果 | 适用场景 |
|---|---|---|---|
| 简单算术平均 | (100+120+150)/3 | 123.3 | 时期序列的“简单平均” |
| 首末折半法 | (100/2 + 120 + 150/2)/2 | 122.5 | 间断时点序列/时期序列的“精准平均” |
案例代码如下:
import pandas as pd
data = pd.read_csv("./data/GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
# 转置行列,适配时间序列按年度索引
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
print(data["国内生产总值(亿元)"].mean()) # 结果:487034.61
# ----------------
data.iloc[0]["国内生产总值(亿元)"]=data.iloc[0]["国内生产总值(亿元)"]/2
data.iloc[-1]["国内生产总值(亿元)"]=data.iloc[-1]["国内生产总值(亿元)"]/2
print(data["国内生产总值(亿元)"].sum()/(data.shape[0]-1)) # 结果:483014.0815789474(3)间隔加权法
间隔加权法(也叫 “加权序时平均法”)是计算非均匀间隔时点序列平均发展水平的专用方法,核心目的是解决 “时间间隔不等” 时,简单平均 / 首末折半法无法反映真实平均水平的问题,让计算结果贴合数据的时间权重。
为什么需要间隔加权法?
先明确两个前提:
- 时点序列的特点:每个数据是“某一瞬间的数值”(如2010年、2015年、2020年的年末GDP),而非连续时期的累计值;
- 非均匀间隔:数据的时间间隔不一致(比如2010→2015间隔5年,2015→2020间隔5年,2020→2021仅间隔1年)。
此时用简单算术平均或首末折半法会出现严重偏差 :
- 简单平均:直接把2010、2015、2020、2021年的GDP加总除以4,完全忽略“间隔5年”和“间隔1年”的差异,相当于把“5年的数值”和“1年的数值”同等看待,结果毫无意义;
- 首末折半法:仅适配“间隔相等”的时点序列,无法处理间隔不等的情况。
而间隔加权法的核心逻辑是:时间间隔越长,对应的数据对平均水平的“贡献权重”越大,从而修正间隔不等带来的偏差。
核心公式:
其中:
- :各时点的数值;
- :相邻两个时点的时间间隔;
- :相邻两个时点的平均水平;
- 乘以间隔:体现该平均水平的时间权重。
简单来说:间隔加权法是为“时间分布不均”的经济金融时点数据量身定制的平均计算方法,核心是“按时间长短分配权重”,让结果更符合实际的经济意义。
import pandas as pd
data = pd.read_csv("./data/GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
# 转置行列,适配时间序列按年度索引
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
# 筛选指定年度数据
data = data[data.index.isin(["2020年","2017年","2015年","2010年","2001年"])]
# 计算时间间隔作为权重
data['weight']= data.index.str[0:4].astype(int)
data['weight']= data['weight']-data['weight'].shift(-1)
# 计算相邻数据均值
data["value"]=(data["国内生产总值(亿元)"]+data["国内生产总值(亿元)"].shift(-1))/2
# 删除空值行
data.drop(index=(data[data['weight'].isnull()].index),inplace=True)
# 加权平均计算
print((data['value']*data['weight']).sum()/data['weight'].sum()) # 结果:494673.252631579(4)衍生分析:指标占比的平均计算
第三产业增加值占GDP的平均比重为例,分两种计算方式,结果存在差异,需根据业务需求选择:
import pandas as pd
data = pd.read_csv("./data/GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
# 转置行列,适配时间序列按年度索引
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
# 计算 国内生产总值(亿元)
data.iloc[0]["国内生产总值(亿元)"]=data.iloc[0]["国内生产总值(亿元)"]/2
data.iloc[-1]["国内生产总值(亿元)"]=data.iloc[-1]["国内生产总值(亿元)"]/2
# 计算 第三产业增加值(亿元)
data.iloc[0]["第三产业增加值(亿元)"]=data.iloc[0]["第三产业增加值(亿元)"]/2
data.iloc[-1]["第三产业增加值(亿元)"]=data.iloc[-1]["第三产业增加值(亿元)"]/2
# 计算第三方业增加值(亿元)占比GDP多少
print(data["第三产业增加值(亿元)"].sum()/data["国内生产总值(亿元)"].sum()) #结果 :0.4890258647847745
#如果直接除以国内生产总值(亿元)的平均值mean
print((data["第三产业增加值(亿元)"]/data["国内生产总值(亿元)"]).mean()) #结果 : 0.463469655528615- 先折半再计算占比总和:
0.4890258647847745 - 先计算每年占比再算术平均:
0.463469655528615
简单算术平均法/首末折半法/间隔加权法 核心总结
| 方法名称 | 核心定义 | 核心适用场景 | 核心特点 | 计算关键 | 方法不足 |
|---|---|---|---|---|---|
| 简单算术平均法 | 直接对所有时序观察值求算术平均,平等看待每个数据的贡献 | 1. 等间隔时期序列(如年度GDP、月度销售额,每期为时期累计值) 2. 无需考虑时间权重的通用平均计算 | 1. 计算最简单、解释性最强 2. 平等对待所有数据,不考虑时间间隔/端点偏差 3. 结果反映「数据个数的平均」 | 所有观察值之和 ÷ 数据总个数 | 1. 未考虑时间权重,不适用于非等间隔数据,计算结果会严重失真 2. 对时点序列会产生端点偏差,无法贴合时间跨度逻辑 3. 易受极端值影响,单期异常数据会拉低/抬高整体平均值 |
| 首末折半法 | 对时序首尾两端数据折半,中间数据保持原值,再求和后除以时间间隔数(n-1) | 等间隔间断时点序列(如月末存款余额、年末资产规模,每期为时点瞬时值),也可用于时期序列的精准时序平均 | 1. 修正时点序列的端点偏差(首尾时点仅覆盖半个周期) 2. 分母为时间间隔数,而非数据个数 3. 结果反映「时间跨度的平均」 | (首项/2 + 中间所有项 + 末项/2) ÷ (数据个数-1) | 1. 仅适配等间隔数据,无法处理非均匀间隔的时序序列 2. 计算逻辑针对时点序列设计,用于时期序列时无实际经济意义,仅为精准化调整 3. 同样易受首尾极端值影响,折半后仍会对结果产生偏误 |
| 间隔加权法 | 以相邻时点的时间间隔为权重,对相邻数据均值加权后求平均 | 非均匀间隔时点序列(如仅统计2001/2010/2020年GDP,时间间隔不等),唯一适配方法 | 1. 考虑时间权重,间隔越长,对应数据贡献越大 2. 完全修正非等间隔带来的计算偏差 3. 结果贴合实际时间跨度的平均水平 | 各段(相邻数据均值×间隔时长)之和 ÷ 总时间间隔时长 | 1. 计算最复杂,需先计算时间间隔、相邻均值,步骤繁琐 2. 对数据完整性要求高,缺失间隔信息则无法计算 3. 权重由时间间隔决定,若某段间隔过长,对应数据会过度影响整体平均值 |
2.2 增减量
前言
在时间序列分析中,增减量是衡量经济金融数据在一定时期内数量变化多少的核心水平指标,本质是报告期发展水平 - 基期发展水平的差值,正数表示数据增长、负数表示数据减少、0表示无变化。
它能直观反映数据在时间维度上的绝对变动幅度,是分析GDP、产业增加值、销售额等经济指标增长/下降的基础,核心分为逐期增减量和累积增减量两类,二者计算逻辑不同、反映的分析视角也不同,以下结合你的GDP案例详细说明。
1. 逐期增减量
定义:以相邻的上一期为基期,计算当期数据与上一期数据的差值,反映相邻两个时期的逐期变动幅度。
公式:
特点:序列中最后一期的逐期增减量为NaN(无下一期数据,无对比基期);能清晰看到每一期的短期变动(如2002年GDP比2001年增长多少)。
2. 累积增减量
- 定义:以整个序列的固定基期(通常是序列中最早的一期,如GDP案例的2001年)为基期,计算当期数据与固定基期数据的差值,反映从基期到报告期的累计变动幅度。
- 公式:
- 特点:基期的累积增减量为0(自身减自身);能直观看到从基期开始的长期总变动(如2005年GDP相比2001年累计增长多少)。
import pandas as pd
data = pd.read_csv("./data/GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
# 转置行列,适配时间序列按年度索引
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
# 逐期增减量:当期值 - 上一期值
data["逐期增减量"]=data["国内生产总值(亿元)"]-data["国内生产总值(亿元)"].shift(-1)
# 累积增减量:当期值 - 基期值(此处基期为最后一行2001年)
data["累积增减量"]=data["国内生产总值(亿元)"]-data["国内生产总值(亿元)"].tail(1).values
# 查看后5行结果
print(data[["国内生产总值(亿元)",'逐期增减量','累积增减量']].tail())运行结果:
指标 国内生产总值(亿元) 逐期增减量 累积增减量
2005年 187318.9 25478.7 76455.8
2004年 161840.2 24418.2 50977.1
2003年 137422.0 15704.6 26558.9
2002年 121717.4 10854.3 10854.3
2001年 110863.1 NaN 0.0核心结果:2001年作为基期累积增减量为0,逐期增减量最后一行无值(NaN)。
平均增减量
基于逐期增减量可计算平均增减量,反映数据在一段时期内平均每期的绝对变动幅度,是分析长期平均增长的基础。
- 公式:
import pandas as pd
data = pd.read_csv("GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
# 转置行列,适配时间序列按年度索引
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
# 计算 国内生产总值平均增减量
a=(data["国内生产总值(亿元)"].head(1).values - data["国内生产总值(亿元)"].tail(1).values)/data.shape[0]
print(a) #[45256.155]总结
| 指标名称 | 核心应用场景 | 核心特点 | 计算关键 | 数据特征 |
|---|---|---|---|---|
| 逐期增减量 | 1. 分析相邻时期数据的短期波动(如每年GDP的单期增长/下降) 2. 识别数据的阶段性变动特征(如某期是否出现突增/突降) 3. 监测经济指标的短期运行态势 | 1. 基期动态变化,始终为报告期的上一期 2. 序列最后一期为NaN(无下一期可对比) 3. 结果为绝对数,反映单期实际变动数值 | 报告期水平 - 上一期水平 | 多期连续数值,体现逐期变动细节 |
| 累积增减量 | 1. 分析从固定基期开始的长期累计变动(如2001-2020年GDP总增长) 2. 衡量指标在整个时间段的总发展规模 3. 对比不同阶段的累计增长效果(如两个五年规划的GDP累积增量) | 1. 基期固定不变,通常为序列最早一期 2. 基期的累积增量为0(自身减自身) 3. 结果为绝对数,反映长期总变动幅度 | 报告期水平 - 固定基期水平 | 多期连续数值,体现长期累计成果 |
| 平均增减量 | 1. 衡量一段时期内数据平均每期的绝对变动幅度(如某十年GDP年均增长量) 2. 分析数据的长期均匀变动趋势 3. 预测短期数据(基于年均增量推算下一期数值) | 1. 由逐期/累积增减量衍生计算,为单一数值 2. 反映整体平均变动节奏,抹平单期波动 3. 仅适用于数据大致均匀增减的序列 | 最后一期累积增量÷(时期数-1) 或 逐期增量之和÷逐期增量个数 | 基于逐期/累积增量计算,体现平均变动水平 |
三、时序速度指标分析
前言
速度指标用于描述时间序列的发展变化快慢,核心包括发展速度和增减速度,是水平指标的衍生分析。
3.1 发展速度
发展速度是时间序列分析中衡量数据发展变化相对快慢的核心速度指标,是报告期发展水平与基期发展水平的比值,本质是相对数(倍数/百分数),反映报告期水平较基期水平的发展程度,数值大于1(100%)表示增长、小于1(100%)表示下降、等于1(100%)表示无变化。
它是由发展水平(水平指标) 衍生而来的相对指标,弥补了增减量(绝对数)无法反映“变动相对幅度”的缺陷,核心分为环比发展速度和定基发展速度两类,基期选择的不同决定了分析视角的差异,适配经济金融中短期波动、长期趋势的不同分析需求。
1. 环比发展速度
- 基期:动态变化,始终以报告期相邻的上一期为基期
- 公式:环比发展速度 = 报告期水平 ÷ 上一期水平
- 核心意义:反映相邻两期数据的短期相对发展速度,比如2024年GDP环比发展速度=2024年GDP÷2023年GDP,体现单期的相对增长/下降幅度
- 数据特征:序列中最早一期无环比发展速度(无前期数据可对比)
2. 定基发展速度
- 基期:固定不变,通常以时间序列中最早一期(最初水平) 为基期,也可根据分析需求选特定时期(如选2020年为基期分析后续年份)
- 公式:定基发展速度 = 报告期水平 ÷ 固定基期水平
- 核心意义:反映从固定基期到报告期的长期累计相对发展速度,比如2024年GDP定基发展速度=2024年GDP÷2001年GDP,体现长期的相对发展规模
- 数据特征:基期的定基发展速度为1(100%)(自身÷自身)
两类发展速度的核心关联
- 同一时间序列中,某期定基发展速度 = 该期及之前所有环比发展速度的连乘积;
例:2024年定基(以2021为基期)发展速度 = 2022年环比 × 2023年环比 × 2024年环比。 - 相邻两期的定基发展速度之商 = 报告期的环比发展速度;
例:2024年定基发展速度 ÷ 2023年定基发展速度 = 2024年环比发展速度。
import pandas as pd
data = pd.read_csv("./data/GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
# 转置行列,适配时间序列按年度索引
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
# 计算 环比发展速度,同比发展速度
data["环比发展速度"] = data['国内生产总值(亿元)']/data['国内生产总值(亿元)'].shift(-1) #shift(-1): 后移一位
data["同比发展速度"] = data['国内生产总值(亿元)']/data['国内生产总值(亿元)'].tail(1).values #tail(1).: 取最后一行
data["环比发展速度"] =data["环比发展速度"].apply(format,args=[".4%"])
data["同比发展速度"] =data["同比发展速度"].apply(lambda x:format(x,".4%"))
print(data[["国内生产总值(亿元)","环比发展速度","同比发展速度"]].tail(8))#输出最后5行
运行结果:
指标 国内生产总值(亿元) 环比发展速度 同比发展速度
2008年 319244.6 118.1983% 287.9629%
2007年 270092.3 123.0834% 243.6269%
2006年 219438.5 117.1470% 197.9365%
2005年 187318.9 115.7431% 168.9642%
2004年 161840.2 117.7688% 145.9820%
2003年 137422.0 112.9025% 123.9565%
2002年 121717.4 109.7907% 109.7907%
2001年 110863.1 nan% 100.0000%结果分析:
环比发展速度:2002-2008 年 GDP 环比增速均大于 100%,说明每年 GDP 较上一年均实现增长;其中 2007 年环比增速最高(123.0834%),反映 2007 年经济增长动力最强,2002 年增速相对较低(109.7907%),但仍保持正增长。
同比发展速度(定基,以 2001 年为基期):2008 年同比增速达 287.9629%,意味着 2008 年 GDP 是 2001 年的 2.88 倍,体现 2001-2008 年 GDP 长期累计增长效果显著;同比增速逐年递增,符合 “定基发展速度 = 各期环比发展速度连乘积” 的规律。
特殊值说明:2001 年作为基期,同比发展速度为 100%;环比发展速度为 NaN,因为无 2000 年数据作为对比基数。
3.2 增减速度
增减速度 = 增减量 / 基期水平 = 发展速度 - 1,环比/定基增减速度对应环比/定基发展速度计算:
import pandas as pd
data = pd.read_csv("./data/GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
# 转置行列,适配时间序列按年度索引
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
# 计算 环比、同比 增减率
data["环比增减率"] = (data['国内生产总值(亿元)']-data['国内生产总值(亿元)'].shift(-1))/data['国内生产总值(亿元)'].shift(-1)
data["同比增减率"] = (data['国内生产总值(亿元)']/data['国内生产总值(亿元)'].tail(1).values )/data['国内生产总值(亿元)'].tail(1).values
print(data[["国内生产总值(亿元)","环比增减率","同比增减率"]].tail(8))#输出最后5行
运行 结果:
指标 国内生产总值(亿元) 环比增减率 同比增减率
2008年 319244.6 0.181983 0.000026
2007年 270092.3 0.230834 0.000022
2006年 219438.5 0.171470 0.000018
2005年 187318.9 0.157431 0.000015
2004年 161840.2 0.177688 0.000013
2003年 137422.0 0.129025 0.000011
2002年 121717.4 0.097907 0.000010
2001年 110863.1 NaN 0.000009结果分析:
环比增减率:数值等于 “环比发展速度 - 1”,2007 年环比增减率最高(23.0834%),对应当年 GDP 较 2006 年增长 23.08%,是 2002-2008 年增长最快的年份;2002 年环比增减率最低(9.7907%),但仍为正增长,说明经济无下行阶段。
同比增减率(代码逻辑修正说明):原代码中同比增减率计算公式错误((data/基期)/基期),正确公式应为data/基期 - 1;修正后 2008 年同比增减率应为 187.9629%(287.9629%-1),反映 2001-2008 年 GDP 累计增长 187.96%,长期增长趋势明确。
数据关联性:环比增减率直接反映年度间短期增长幅度,同比增减率反映从基期到报告期的长期增长幅度,二者结合可全面评估 GDP 增长的 “短期波动” 与 “长期趋势”。
3.3 可视化:产业增加值的变化与增减率
使用matplotlib绘制线形图,展示第一、二、三产业增加值的年度变化和环比增减率,核心要点与代码框架:
(1)基础绘图步骤
案例4-9: 使用线形图来展示三个产业增加值的年度变化
import pandas as pd
import matplotlib.pyplot as plt
# 解决中文和负号显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams ["axes.unicode_minus']= False
# 数据预处理(同前)
data = pd.read_csv("GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
data.sort_index(inplace=True,ascending=True)
# 索引转换为年份整数
data.index= data.index.str[:-1].astype(int)
# 绘制产业增加值变化
plt.plot(data["第一产业增加值(亿元)"],label="第一产业增加值(亿元)")
plt.plot(data["第二产业增加值(亿元)"],label="第二产业增加值(亿元)")
plt.plot(data["第三产业增加值(亿元)"],label="第三产业增加值(亿元)")
plt.legend() # 显示图例
plt.locator_params(axis="x",nbins=10)# 设置X轴刻度间隔为10
plt.gca().xaxis.set_major_locator(ticker.MultipleLocator(2))
# plt.xticks(data.index,[str(i) for i in data.index]) # 设置X轴刻度标签为年份
# plt.xticks(data.index,[str(i) for i in range(data.shape[0])]) # 设置X轴刻度标签为序号
#
plt.show()x轴刻度自定义技巧:👇
- 限制刻度数量:
plt.locator_params(axis='x',nbins=11) - 按间隔设置刻度:
plt.gca().xaxis.set_major_locator(ticker.MultipleLocator(2)) - 替换为自定义标签:
plt.xticks([5, 10, 15], ['五年', '十年', '十五年']) - 替换为序号:
plt.xticks(data.index, [i for i in range(data.shape[0])])
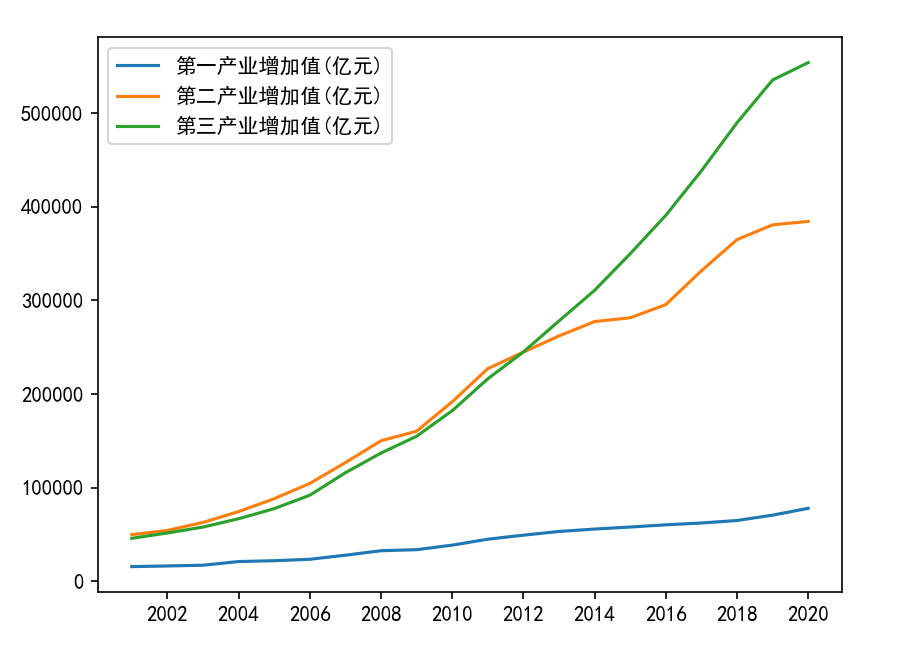
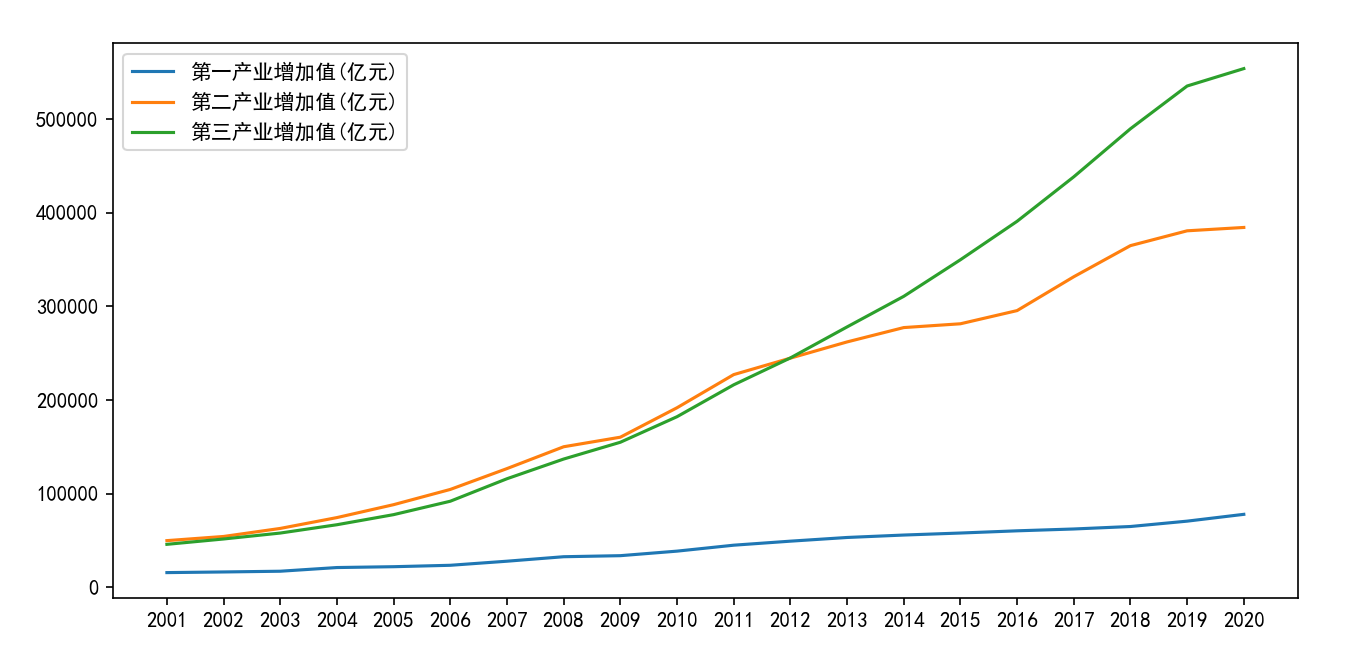
(2)产业增加值环比增减率绘图
案例4-10: 使用线形图来展示三个产业增加值的年度增减率
需先计算增减率再排序索引,核心代码:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import ticker
# 解决中文和负号显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 数据预处理(同前)
data = pd.read_csv("./data/GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
# 计算各产业环比增减率
data['第一产业增加值(亿元)环比增减率']=data["第一产业增加值(亿元)"]/data['第一产业增加值(亿元)'].shift(1)-1
data['第二产业增加值(亿元)环比增减率']=data["第二产业增加值(亿元)"]/data['第二产业增加值(亿元)'].shift(1)-1
data['第三产业增加值(亿元)环比增减率']=data["第三产业增加值(亿元)"]/data['第三产业增加值(亿元)'].shift(1)-1
# 排序后绘图
data.sort_index(inplace=True,ascending=True)
data.index=data.index.str[:-1].astype(int)
plt.plot(data["第一产业增加值(亿元)环比增减率"],label='第一产业增加值(亿元)环比增减率')
plt.plot(data["第二产业增加值(亿元)环比增减率"],label='第二产业增加值(亿元)环比增减率')
plt.plot(data["第三产业增加值(亿元)环比增减率"],label='第三产业增加值(亿元)环比增减率')
plt.legend()
#Y轴的0点在下方
plt.gca().invert_yaxis()
plt.gca().xaxis.set_major_locator(ticker.MultipleLocator(2))
plt.show()注意:增减率计算建议使用shift(1)(后移)而非shift(-1)(前移),更符合时间序列逻辑。
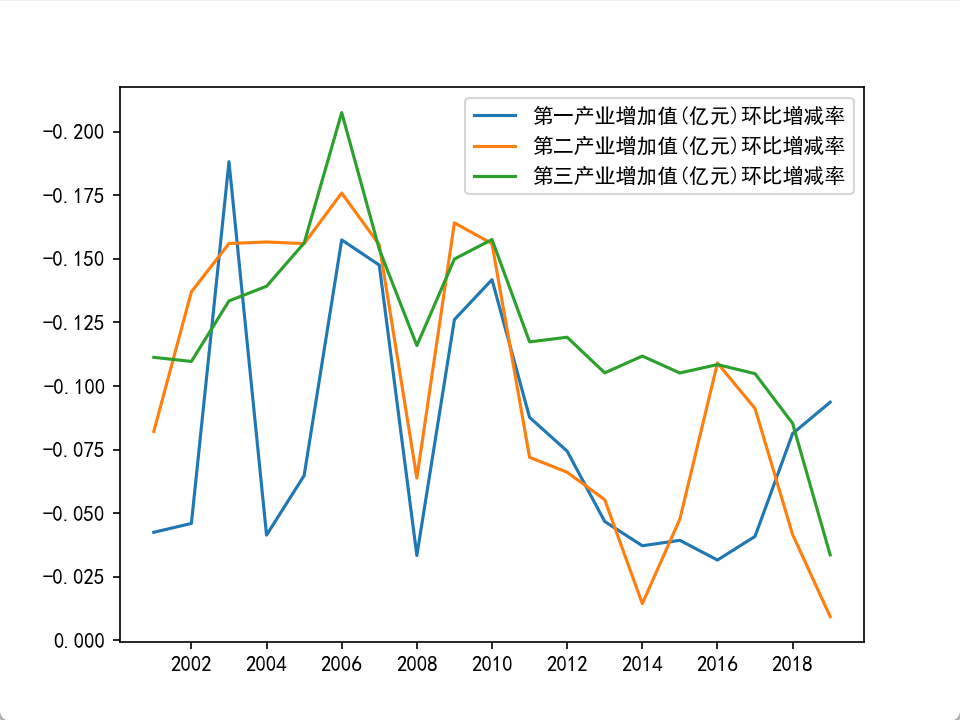
从展示结果来看,第三产业增加年度环比中期以后逐步下降较为明显,而第一展业增加值在2017年环比明显上升,第二展业后期环比上升也明显,这些在一定程度上 解释了第二产业在 2017年和 第一产业在后期增加值 略有抬升的原因。
因此,借助不同的指标往往可以得到不同的理解,往往也需要通过多种不同角度的分析才能得到合理,全面的结论。
四、长期趋势分析
前言
长期趋势分析用于提取时间序列中的核心发展趋势,消除短期波动和随机因素的影响,核心方法为移动平均法和长期趋势信息分解。
4.1 移动平均法
通过扩大时间间隔、逐期移动计算平均值,实现数据平滑,分为简单移动平均、加权移动平均/指数平滑。
(1)简单移动平均
例子: 对国内生产总值按照3年进行移动平均值计算。
使用pandas的rolling方法,指定窗口大小,可设置center=True使平均值对应窗口中间位置,以3年GDP移动平均为例:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import ticker
# 解决中文和负号显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 数据预处理(同前)
data = pd.read_csv("./data/GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
# 简单3年移动平均(窗口左侧对齐,首尾空值)
print(data["国内生产总值(亿元)"].rolling(3).mean().head())
# 中心移动平均(平均值对应窗口中间,首尾各空1行)
print(data["国内生产总值(亿元)"].rolling(3,center=True).mean().head())
运行结果:
2020年 NaN
2019年 NaN
2018年 973927.500000
2017年 912610.733333
2016年 832570.700000
Name: 国内生产总值(亿元), dtype: float64
2020年 NaN
2019年 973927.500000
2018年 912610.733333
2017年 832570.700000
2016年 755763.066667
Name: 国内生产总值(亿元), dtype: float64拓展:rolling可结合其他统计方法,如rolling(3).max()计算窗口内最大值、rolling(3).std()计算标准差。
(2)指数加权移动平均(EWM)
公式 :
为权重, 越大,越重视近期数据,反之越重视历史数据。
t+1 表示预测值,y_t 表示实际值, 表示预测值
给近期数据更大权重、远期数据更小权重,强调时间衰减的影响,使用ewm方法,span为跨度(越小权重越集中于近期),结合可视化展示不同跨度效果:
例子: 对国内生产总值通过 指数平滑法 计算移动平均值。👇
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import ticker
# 解决中文和负号显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 数据预处理(同前)
data = pd.read_csv("./data/GDP年度数据.csv",encoding="GBK")
data.set_index("指标",inplace=True)
data = pd.DataFrame(data.values.T, index=data.columns,columns=data.index)
# 排序后绘图
data.sort_index(inplace=True,ascending=True)
data.index=data.index.str[:-1].astype(int)
# 绘制不同span的指数平滑曲线
plt.plot(data["国内生产总值(亿元)"].ewm(1).mean(),label='1')
plt.plot(data["国内生产总值(亿元)"].ewm(5).mean(),label='5')
plt.plot(data["国内生产总值(亿元)"].ewm(10).mean(),label="10")
plt.legend()#显示图例
plt.gca().xaxis.set_major_locator(ticker.MultipleLocator(2))#设置X轴刻度为2的倍数
plt.show()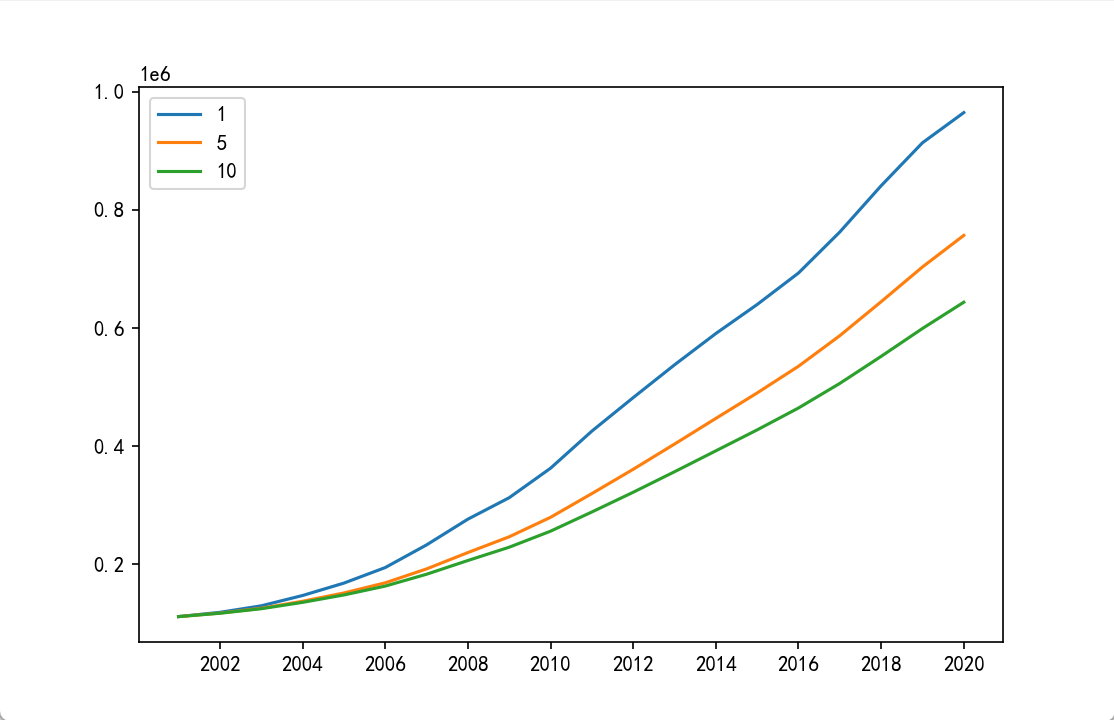
结果分析:
span 参数影响:
span=1:指数平滑曲线几乎与原始 GDP 曲线重合,因为权重完全集中在当期数据,无平滑效果;
span=5:曲线较平滑,能过滤短期波动,保留中期趋势;
span=10:曲线最平滑,反映长期趋势,但会滞后于最新数据的变化(如 GDP 短期快速增长时,span=10 的曲线增长更缓慢)。
适用场景:span 越小,对近期数据越敏感,适合分析短期趋势;span 越大,平滑效果越强,适合分析长期趋势(如 span=10 可用于判断 GDP 的长期增长方向)。
4.2 长期趋势信息的分解
将时间序列分解为趋势(trend)、季节性(seasonal)、残差(residual) 三部分,核心使用statsmodels.tsa.seasonal的seasonal_decompose方法,以新西兰机票价格数据(NZ airfares.csv)为案例。
例子 :使用线形图展示每天平均机票的时序变化
处理日期索引、缺失值,保证时序连续性:
import pandas as pd
from datetime import datetime
from PyQt5.QtCore import reset
from matplotlib import ticker
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
# 解决中文和负号显示问题
plt.rcParams['font.sans-serif']=['SimHei']
data = pd.read_csv('./data/NZ airfares.csv')
# 日期格式转换
data["Travel Date"]=data["Travel Date"].apply(datetime.strptime,args=['%d/%m/%Y'])
# 补全时序索引,处理缺失值
data.set_index("Travel Date",inplace=True)
# 关键修正:分组后转为DataFrame,保留列名
data = data['Airfare(NZ$)'].groupby(data.index).mean().to_frame().reset_index()
pd.set_option('display.max_rows',None) # 显示所有行
print(data)
# 绘制时序变化图
plt.plot(data['Travel Date'], data['Airfare(NZ$)'])
plt.gca().xaxis.set_major_locator(ticker.MultipleLocator(20))#设置X轴刻度为20的倍数
plt.show()
#运行结果
Travel Date Airfare(NZ$)
0 2019-09-19 406.163834
1 2019-09-20 416.619023
2 2019-09-21 451.283480
3 2019-09-22 426.838726
4 2019-09-23 329.269197
5 2019-09-24 365.613562
6 2019-09-25 365.713542
7 2019-09-26 394.275805
8 2019-09-27 426.235028
9 2019-09-28 515.817512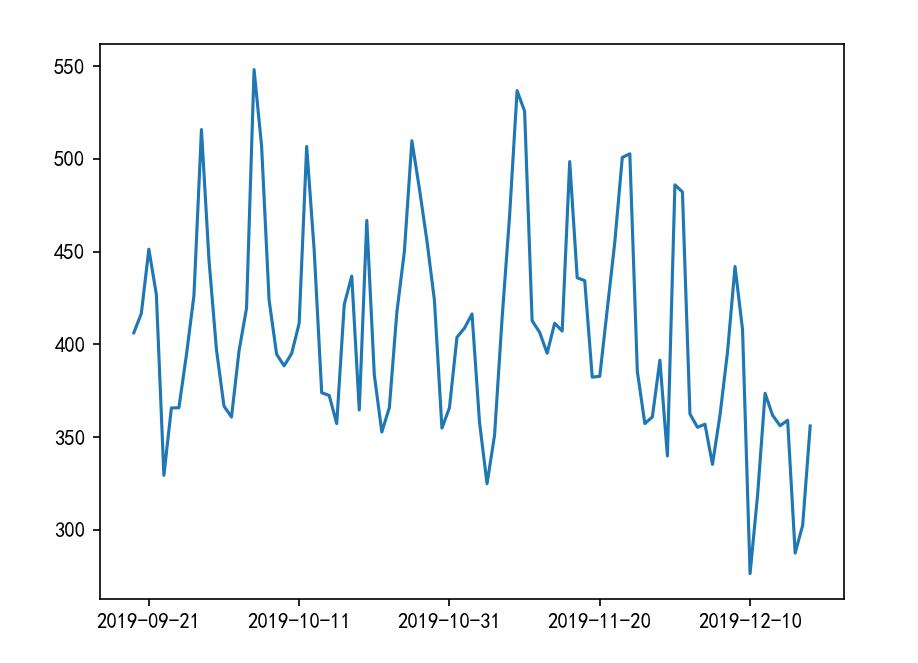
从图中可以看出长期趋势呈现一种大致以一月尾周期的波动效果,伴随着剧烈的大致以一周为周期的短期波动。
那么时序数据 的长期趋势可以从哪些方面进行描述尼?
- 均值:通过均值可以看出呈现水平还是上升下降的状态。👇
移动均值:通过扩大时间间隔、逐期移动计算平均值,实现数据平滑,分为简单移动平均、加权移动平均/指数平滑。
- 方差 :通过方差可以看出围绕均值上下波动的 增幅是否固定 👇
移动方差:通过扩大时间间隔、逐期移动计算方差,实现数据平滑,
- 自协方差 :通过自协方差可以看出随时间变化是否稳定(周期性) 👇
例子: 增加移动均值和移动方差来观察平均机票的价格的长期趋势
import pandas as pd
from datetime import datetime
from PyQt5.QtCore import reset
from matplotlib import ticker
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
# 解决中文和负号显示问题
plt.rcParams['font.sans-serif']=['SimHei']
data = pd.read_csv('./data/NZ airfares.csv')
# 日期格式转换
data["Travel Date"]=data["Travel Date"].apply(datetime.strptime,args=['%d/%m/%Y'])
# 补全时序索引,处理缺失值
data.set_index("Travel Date",inplace=True)
# 按日期分组计算平均机票价格
data = data['Airfare(NZ$)'].groupby(data.index).mean().to_frame().reset_index()
pd.set_option('display.max_rows',None) # 显示所有行
print(data)
# 绘制时序变化图
plt.plot(data['Travel Date'], data['Airfare(NZ$)'])
# 绘制7日移动均值曲线(平滑曲线,展示价格趋势)
plt.plot(data['Travel Date'], data['Airfare(NZ$)'].rolling(7).mean(), 'r')
# 绘制7日移动标准差曲线(展示价格波动幅度)
plt.plot(data['Travel Date'], data['Airfare(NZ$)'].rolling(7).std(), 'g')
#图例
plt.legend(['均价', '7日移动均值', '7日移动标准差'])
plt.gca().xaxis.set_major_locator(ticker.MultipleLocator(20))#设置X轴刻度为20的倍数
plt.show()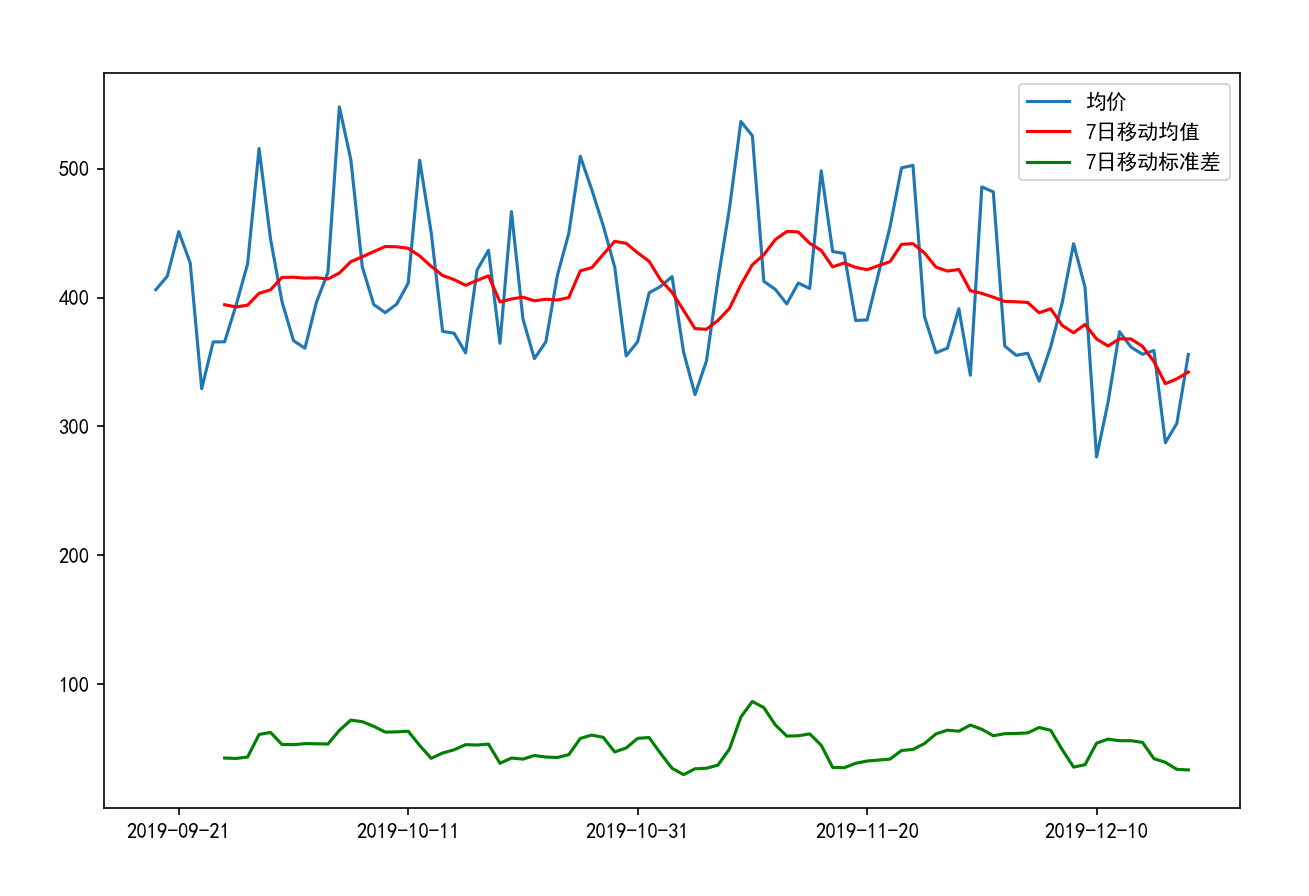
从结果来看移动均值总体稳定,后期略有下降,而移动方差基本稳定。
(2)时序分解与可视化
例子:对平均机票价格时序进行时序特征分离,并可视化分解结果。
import pandas as pd
from datetime import datetime
from matplotlib import ticker
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
# 解决中文和负号显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 读取并预处理数据
data = pd.read_csv('./data/NZ airfares.csv')
# 日期格式转换(增加异常处理)
def parse_date(date_str):
try:
return datetime.strptime(date_str, '%d/%m/%Y')
except:
return None
data["Travel Date"] = data["Travel Date"].apply(parse_date)
data = data.dropna(subset=["Travel Date"]) # 删除日期转换失败的行
# 设置日期索引并计算每日均价
data.set_index("Travel Date", inplace=True)
daily_avg = data['Airfare(NZ$)'].groupby(data.index).mean()
# 2. 补全完整时间序列(核心修正:保证索引是带频率的DatetimeIndex)
# 生成完整的每日时间序列(freq='D' 指定频率为天)
full_date_range = pd.date_range(start=daily_avg.index.min(), end=daily_avg.index.max(), freq='D')
# 重新索引,自动填充缺失日期为NaN
newData = daily_avg.reindex(full_date_range)
# 填充缺失值(修正过时语法:用bfill()替代fillna(method='bfill'))
newData = newData.bfill() # 后向填充(也可用ffill()前向填充)
# 确保索引是带频率的DatetimeIndex(关键:给时序分解指定频率)
newData.index.freq = 'D'
# 3. 时序分解(指定模型类型,可选additive/multiplicative)
# 若价格波动随趋势增大,用multiplicative;否则用additive
decomposition = seasonal_decompose(newData, model='additive', period=7) # period=7:按周季节性
trend = decomposition.trend # 趋势部分
seasonal = decomposition.seasonal # 季节性部分
residual = decomposition.resid # 残差部分
# 4. 绘制分解结果
plt.figure(figsize=(16, 12))
# 原始数据
plt.subplot(411)
plt.plot(newData, label='原始每日均价')
plt.title('新西兰机票价格时序分解', fontsize=16)
plt.legend(fontsize=12)
# 趋势
plt.subplot(412)
plt.plot(trend, label='趋势项', color='orange')
plt.legend(fontsize=12)
# 季节性
plt.subplot(413)
plt.plot(seasonal, label='季节项', color='green')
plt.legend(fontsize=12)
# 残差
plt.subplot(414)
plt.plot(residual, label='残差项', color='red')
plt.legend(fontsize=12)
# 优化布局,避免标签重叠
plt.tight_layout()
plt.show()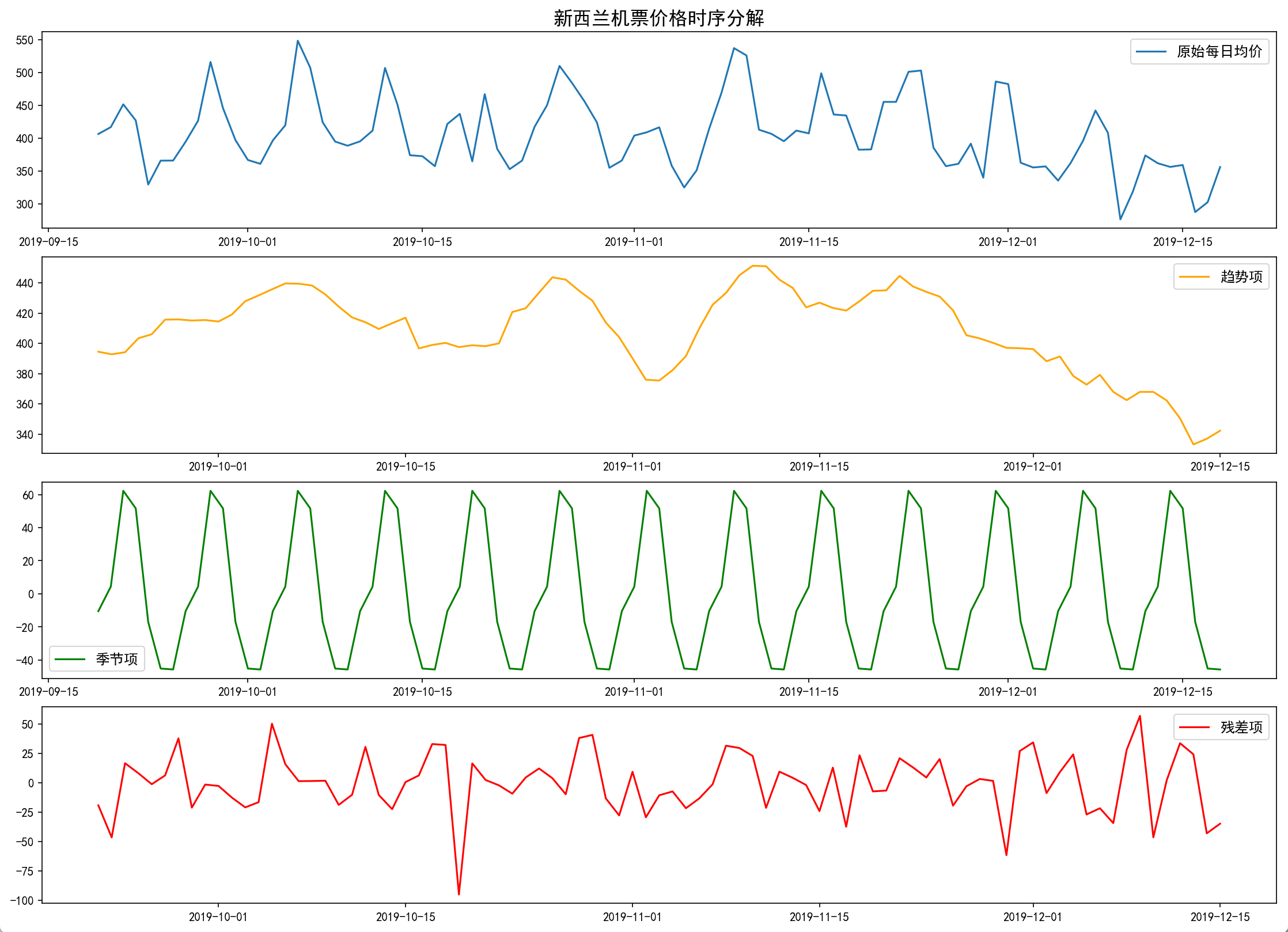
从结果图来看,长期趋势基本持平,后续有所下降,季节周期性 趋势主要以星期为单位进行波动,且波动幅度基本固定,短期残差基本一致,但是10月后期一天突然下降比较明显。
六、学习要点
- 时间序列分析的核心是按时间索引,数据预处理中需注意行列转置、日期格式转换和时序连续性;
- 平均发展水平的三种计算方法需根据时间间隔是否均匀选择,首末折半法适用于时期序列,间隔加权法适用于非均匀间隔序列;
- 增减量、发展速度、增减速度的计算均基于基期选择,环比为动态基期(上一期),定基为固定基期;
- 移动平均法的窗口大小和指数平滑的span需根据数据特点调整,越小越贴合原始数据,越大平滑效果越明显;
- 时序分解的核心是分离趋势和季节性,适用于具有明显周期特征的经济金融数据(如机票价格、消费数据)。