
数据相关性分析
课前导入
在经济金融数据分析中,数据之间往往存在着相互关联的关系,例如职业早期薪酬与中期薪酬的关联、股票价格与成交量的关联、行业就业率与经济指标的关联等。
数据相关性分析是研究数据间关联程度、方向和形态的核心方法,而回归分析则是在相关分析的基础上,进一步构建数据间的数量依存关系,实现对目标变量的预测。
需要注意的是,相关性≠因果性,两个数据存在相关关系并不代表一方必然导致另一方,这是数据分析的重要原则。
本章将从相关度计算入手,逐步讲解线性回归、非线性回归的Python实现方法,同时介绍回归模型的评估与检验手段,所有案例均以高校毕业生薪酬数据集为核心展开,贴合经济金融实际应用场景。
前置概念:函数关系与相关关系
在分析数据间的依存关系前,需明确两类核心关系的区别,这是相关性分析的基础:
- 函数关系:数据之间存在严格、确定性的依存关系,一个变量的取值可由其他变量唯一确定,例如圆的面积,半径确定后面积唯一确定。
- 相关关系:数据之间存在非确定性的依存关系,一个变量的取值受其他变量影响,但无法由其他变量唯一确定,例如早期职业薪酬与中期职业薪酬,前者会影响后者,但无法通过前者精确计算后者,这是经济金融数据的主要关系形式。
数据集说明如下:
| 列名 | 中文含义 | 补充说明(数据类型/常见场景) |
|---|---|---|
rank | 排名 | 整数,通常是院校/专业的综合排名(如薪资排名、性价比排名) |
name | 名称 | 字符串,院校名称(如“斯坦福大学”)或专业名称(如“计算机科学”) |
state_name | 州名 | 字符串,美国州名(如“California”“Texas”),仅适用于美国院校数据集 |
early_career_pay | 职业生涯初期薪资 | 数值(美元),通常指毕业1-5年的平均年薪 |
mid_career_pay | 职业生涯中期薪资 | 数值(美元),通常指毕业10+年的平均年薪 |
make_world_better_percent | 「让世界变得更好」占比 / 社会影响力占比 | 百分比(0-100),指该专业/院校毕业生从事“对社会有正向贡献”工作的比例(如公益、环保、医疗、教育等领域) |
stem_percent | STEM专业占比 / STEM从业者比例 | 百分比(0-100),STEM指科学(Science)、技术(Technology)、工程(Engineering)、数学(Mathematics)相关专业/职业 |
回归的简化版流程
| 全流程(多元) | 一元回归流程 | 要不要做? | 核心原因 |
|---|---|---|---|
| 建模 | 建模 | ✅ 必须做 | 先算出回归系数和基本结果 |
| 看系数 | 看系数 | ✅ 必须做 | 看自变量是否显著、系数符号是否合理 |
| 学生化残差找异常点 | 学生化残差找异常点 | ✅ 必须做 | 一元回归更怕极端值(比如某所大学薪资离谱),一两个异常点就会拉偏回归线 |
| DFFITS看强影响点 | DFFITS看强影响点 | ✅ 建议做 | 一元回归中强影响点对系数的“破坏力”更明显,删掉一个点可能让系数从正变负 |
| 多重共线性检验 | 跳过(或简单验证) | ❌ 不用做 | 只有1个自变量,没有“变量之间相关”的问题,共线性不存在 |
| 正态性检验(残差正态) | 正态性检验(残差正态) | ✅ 必须做 | 一元回归的P值、置信区间依然依赖“残差正态”的假设,不验证就不可信 |
1.相关度
前言
相关度是衡量数据之间相互联系概率的指标,反映了变量间关联的密切程度,根据变量间的关联形态,可分为 线性相关度和非线性相关度 两类.
1.1 线性相关度计算
线性相关度研究变量间的线性依存关系,即一组数据可以用另一组或多组数据的线性组合表示,核心计算指标为皮尔逊(Pearson)相关系数,也是最常用的相关度指标。
我们先看一个例子:使用相关图来测度早期职业薪酬和中期职业薪酬之间的相关性
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示
data = pd.read_csv('salary_potential.csv')
plt.scatter(data['early_career_pay'], data['mid_career_pay'], alpha=0.4) # alpha:透明度,避免点重叠
plt.xlabel('早期职业薪酬')
plt.ylabel('中期职业薪酬')
plt.title('早期与中期职业薪酬散点图')
plt.show()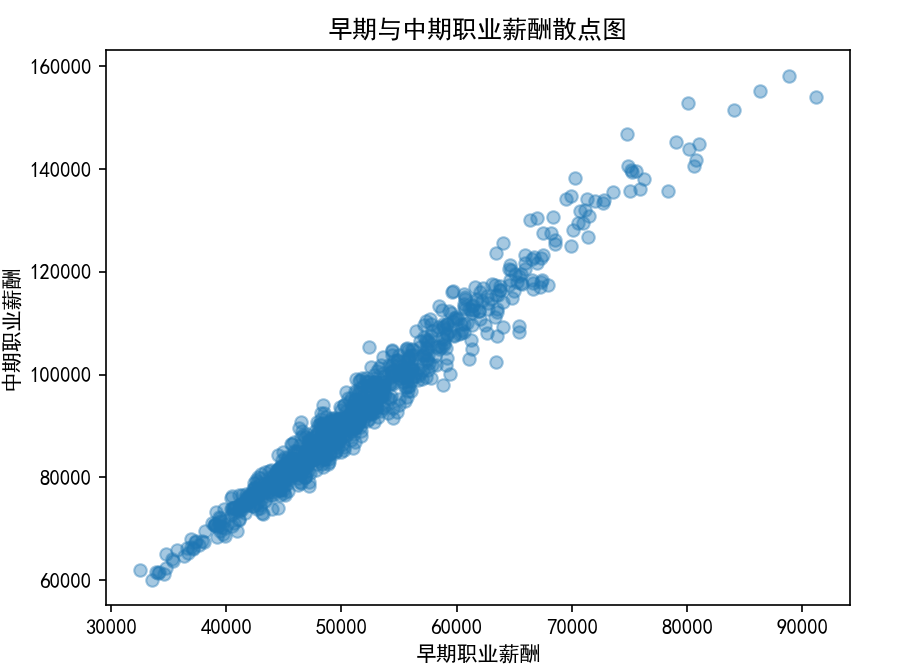
可以看出: 大部分散点都分布在对角线周围,因此两者呈现非常明显的相关性,就是一个变量变化时,另外一个变量也跟着变化。
思考: 那么这个相关性的具体数值(相关度 )是多少呢?我们可以使用皮尔逊相关系数来计算一下。👇
1.1.1 皮尔逊相关系数说明
- 取值范围:
- 数值含义:
- 1:完全正线性相关,一个变量随另一个变量的增加而线性增加;
- -1:完全负线性相关,一个变量随另一个变量的增加而线性减少;
- 0:无线性相关关系;
- 绝对值越接近1,线性相关程度越强,越接近0则越弱。
- 适用场景:变量均为连续型数据,且服从正态分布,无明显异常值。
1.1.2 线性相关的可视化与计算实操
核心思路:先通过散点图直观观察变量间的线性趋势,再通过corr()方法计算皮尔逊相关系数。
案例:分析高校毕业生早期职业薪酬(early_career_pay)与中期职业薪酬(mid_career_pay)的线性相关性
# 2. 计算:皮尔逊相关系数(默认方法)
r = data['early_career_pay'].corr(data['mid_career_pay'])
print(f"皮尔逊相关系数:{r:.4f}") # 结果约为0.9833,高度正线性相关
运行结果:皮尔逊相关系数:0.9833结果解读:皮尔逊相关系数接近1,说明早期职业薪酬与中期职业薪酬存在高度正线性相关。
1.2 非线性相关度计算
当变量间的关联形态非直线,或数据不满足正态分布、存在异常值时,皮尔逊系数不再适用,需采用非线性相关度指标,核心为斯皮尔曼(Spearman)等级相关系数和肯德尔(Kendall)系数,二者均基于变量的秩(排序位置) 计算,不受数据分布和异常值影响。
1.2.1 两个系数说明
| 系数 | 计算依据 | 取值范围 | 核心特点 |
|---|---|---|---|
| 斯皮尔曼 | 变量的秩次差 | 计算效率高,适用于大部分非线性场景 | |
| 肯德尔 | 变量的秩次协同性 | 对异常值更稳健,适用于样本量较小的场景 |
1.2.2 非线性相关度计算实操
案例:计算早期职业薪酬与中期职业薪酬的斯皮尔曼和肯德尔相关系数
import pandas as pd
data = pd.read_csv('salary_potential.csv')
# 斯皮尔曼相关系数
r_spearman = data['early_career_pay'].corr(data['mid_career_pay'], method='spearman')
# 肯德尔相关系数
r_kendall = data['early_career_pay'].corr(data['mid_career_pay'], method='kendall')
print(f"斯皮尔曼相关系数:{r_spearman:.4f}") # 约0.9797
print(f"肯德尔相关系数:{r_kendall:.4f}") # 约0.8834结果解读:两个系数均接近1,说明即使不考虑线性关系,早期职业薪酬与中期职业薪酬仍存在高度的非线性相关关系。
2 回归分析
2.1 线性回归分析
前言
回归分析是在相关分析的基础上,构建变量间的数量依存模型,实现对目标变量(因变量)的预测 ,是经济金融预测分析的核心方法。
相关分析是回归分析的基础(只有存在相关关系的变量才适合做回归),回归分析是相关分析的延续(将相关关系量化为数学模型)。
回归分析的分类维度多样:按自变量数量 可分为一元回归(一个自变量)和多元回归(多个自变量);按模型形态 可分为线性回归和非线性回归。
2.1 线性回归分析
线性回归分析假设自变量与因变量之间存在线性依存关系,模型形式为,其中为截距,为回归系数,为随机误差。
本节重点讲解一元线性回归(单个自变量)和多元线性回归(多个自变量)的Python实现,核心工具为sklearn.linear_model.LinearRegression(快速建模)和statsmodels.api(详细统计结果)。
☝️ ☝️ 上面有印象吗? 在数仓那门课中,我们讲过哦!!!☝️ ☝️
2.1.1 一元线性回归
研究一个自变量对一个因变量的线性影响,是最简单的线性回归模型,以“早期职业薪酬预测中期职业薪酬”为例展开。
例子:利用早期职业薪酬和中期职业薪酬数据进行回归拟合
sklearn是Python机器学习核心库,建模步骤为数据准备→模型初始化→拟合→预测→可视化,需注意:sklearn要求自变量为二维数组,需用reshape(-1,1)转换。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 1. 数据准备
data = pd.read_csv('salary_potential.csv')
X = data['early_career_pay'].values.reshape(-1,1) # 自变量:转换为二维数组
y = data['mid_career_pay'] # 因变量
# 2. 模型初始化与拟合
model = LinearRegression()
model.fit(X, y) # 拟合线性模型
# 3. 模型参数:回归系数(β1)、截距(β0)
print(f"回归系数:{model.coef_[0]:.4f}") # 约1.8638
print(f"截距:{model.intercept_:.4f}") # 约-2920.1575
# 模型公式:mid_career_pay = -2920.1575 + 1.8638*early_career_pay
# 4. 预测
y_pred = model.predict(X)
# 5. 可视化:原始散点+回归直线
plt.scatter(X, y, c='k', alpha=0.4, label='原始数据')
plt.plot(X, y_pred, c='r', label='回归直线')
plt.xlabel('早期职业薪酬')
plt.ylabel('中期职业薪酬')
plt.legend()
plt.show()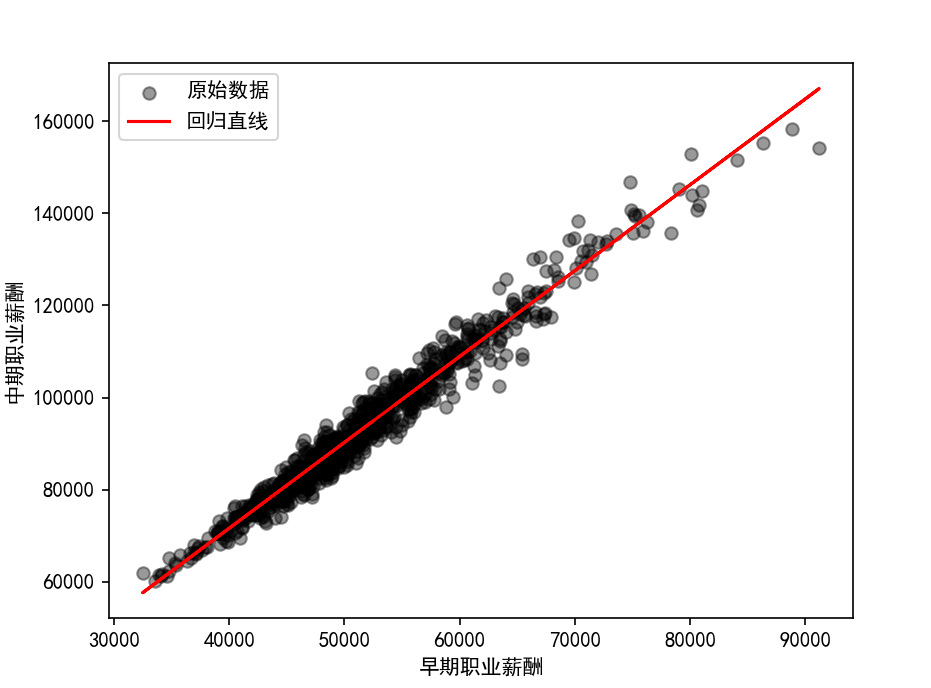
上面的图中,不方便显示截距,原点不是0,可以增加对绘图坐标的修改 👇
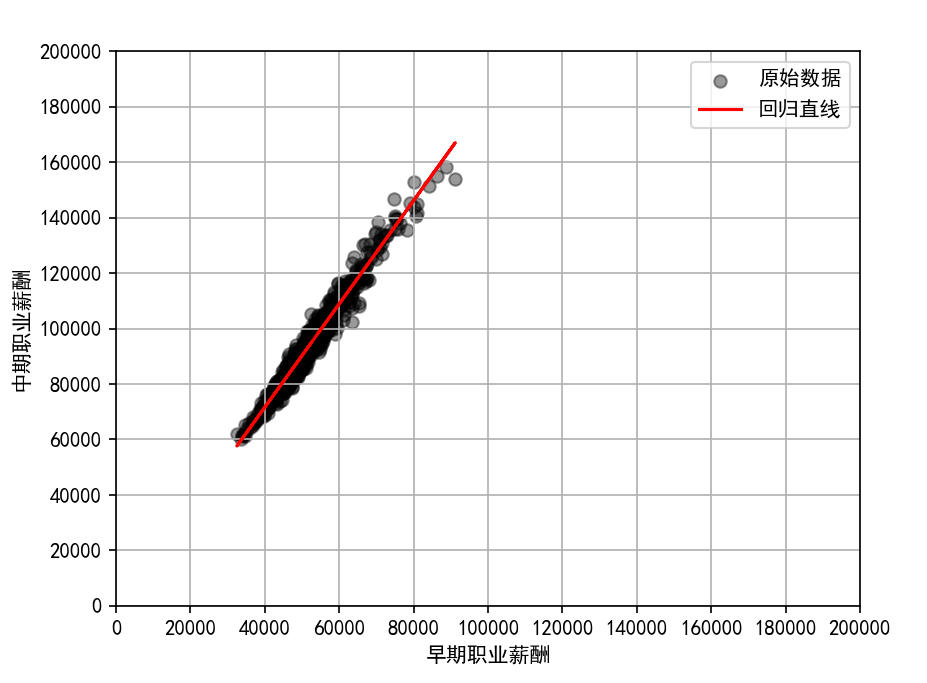
可以发现,原点是0了,方便观察。 上面是使用sklearn框架,其实statsmodels库也可以实现,并且可以输出详细的统计结果,更加方便。
方法:statsmodels实现(详细统计结果)
statsmodels库可输出回归模型的详细统计指标(如R方、F值、P值),更适合统计分析,支持公式化建模(类似R语言)。
import pandas as pd
import statsmodels.api as sm
data = pd.read_csv('salary_potential.csv')
# 建模:formula格式为"因变量~自变量"
model = sm.formula.ols('mid_career_pay ~ early_career_pay', data=data).fit()
# 输出模型参数
print(model.params)结果解读:
Intercept -2920.157469 # 截距
early_career_pay 1.863834 # 回归系数2.1.2 多元线性回归
研究多个自变量对一个因变量的线性影响,更贴合经济金融实际场景(目标变量往往受多个因素影响),以“make_world_better_percent和stem_percent预测早期职业薪酬”为例展开。
方法1:sklearn实现(多自变量建模+模型评估)
多自变量建模与一元建模步骤一致,仅需将自变量转换为多列的二维数组,同时引入模型评估指标(MSE、RMSE、MAE、R方)。
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn import metrics
# 1. 数据准备:填充缺失值,避免建模报错
data = pd.read_csv('salary_potential.csv')
# 缺失值填充:用0填充
data = data.fillna(0)
# 自变量:两个特征,转换为二维数组
X = data[['make_world_better_percent', 'stem_percent']].values.reshape(-1,2)
y = data['early_career_pay'] # 因变量
# 2. 建模与预测
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
# 3. 模型参数
print(f"回归系数:{model.coef_}")
print(f"截距:{model.intercept_}")
# 4. 模型评估:核心指标
r2 = metrics.r2_score(y, y_pred) # R方:模型对因变量变异的解释程度,取值[0,1],越接近1解释力越强
print(f"R2:{r2:.4f}")
输出结果:
回归系数:[ -0.43068338 328.69561408]
截距:45807.246313053234
R2:0.3661结果解读:
- 原始数据存在空值,因此填充为0,
- 模型评估指标R方为0.3661,说明模型对因变量变异的解释程度为36.61%,这个值越接近1,越拟合,现在为0.366,说明解释力一般,需进一步优化模型。
为了更好的看清拟合的特点,可以通过三维可视化来观察拟合效果
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn import metrics
import matplotlib.pyplot as plt
# 1. 数据准备:填充缺失值,避免建模报错
# 1. 数据准备:填充缺失值,避免建模报错
data = pd.read_csv('salary_potential.csv')
# 缺失值填充:用0填充
data = data.fillna(0)
# 自变量:两个特征,转换为二维数组
X = data[['make_world_better_percent', 'stem_percent']].values.reshape(-1,2)
y = data['earl_career_pay'] # 因变量
# 2. 建模与预测
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
#3.3d展示
plt.subplot( projection='3d')
# 原始数据
plt.plot(data['make_world_better_percent'], data['stem_percent'], data['early_career_pay'],y,'k. ') #原始数据
# 预测值:加号
plt.plot(data['make_world_better_percent'], data['stem_percent'], y_pred,'r+') #预测值
plt.show()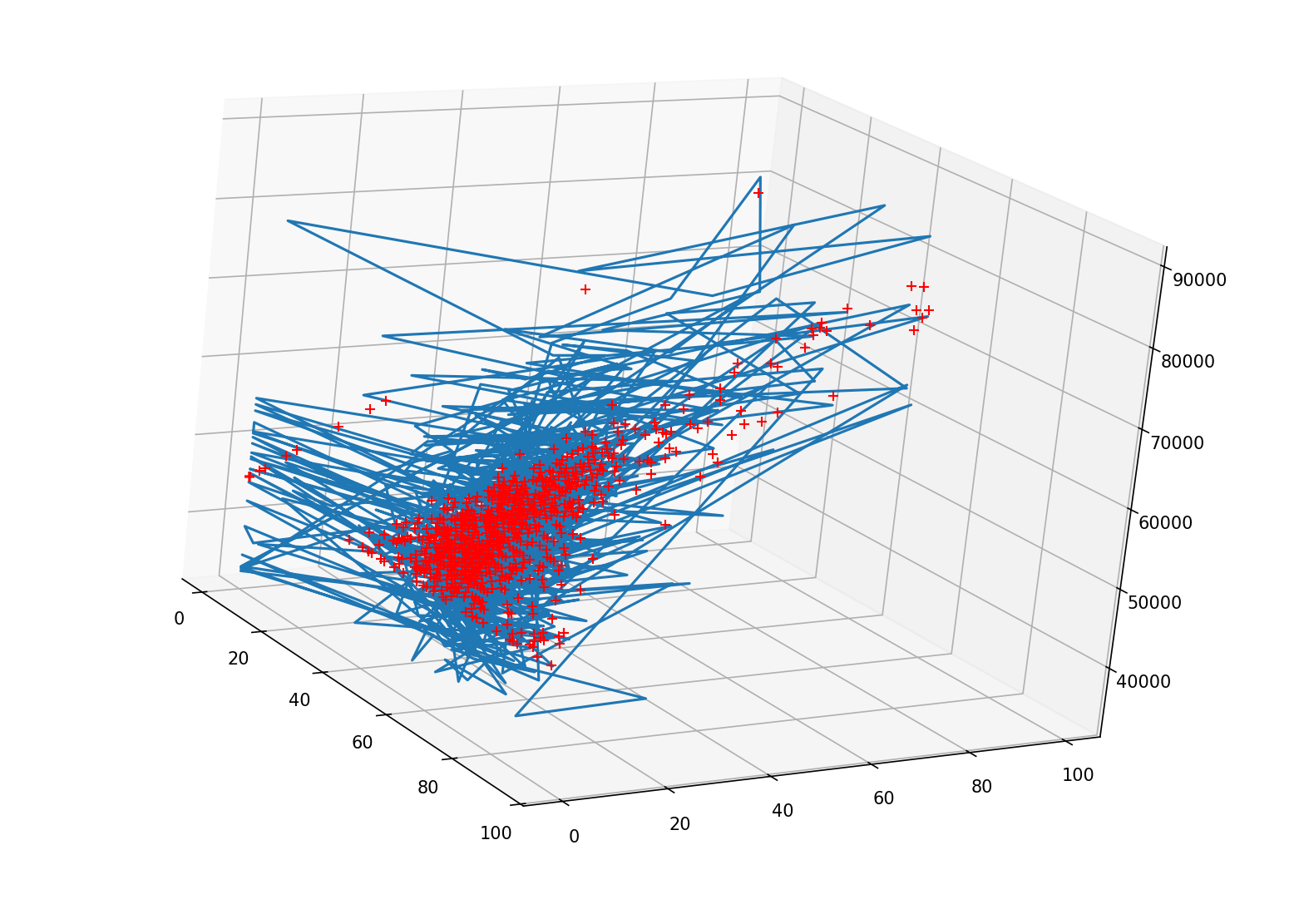
从上图可以,看出,确实不是线性关系,所以,R方为0.3661,说明模型对因变量变异的解释程度为36.61%,这个值越接近1,越拟合,现在为0.366,说明解释力一般,需进一步优化模型。
👉 学到这里,我们使用了散点图和线性回归对数据进行拟合,由于预测值和真实的数据存在误差,因此对于回归模型的好坏就要根据误差大小来做出判断,这种误差我们称为训练误差或者交残差 ;
简而言之:选择回归模型后,需要对模型进行评估,评估的标准就是训练误差,训练误差越小,说明模型拟合的越好。
常见的指标有:MSE、RMSE、MAE、R方。
- MSE:误差的平方均值,放大较大误差,他的值越小,说明误差越小,模型越好。
- RMSE:将误差还原为原变量量纲,更易解释,他的值越小,说明误差越小,模型越好。
- MAE:误差的绝对值均值,对异常值更稳健,他的值越小,说明误差越小,模型越好。
- R方:模型对因变量变异的解释程度,取值[0,1],越接近1解释力越强,他的值越大,说明误差越小,模型越好。
下面的我们来验证下之前的早期职业薪酬和中期职业薪酬的线性关系,看看他的误差是多少。👇
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn import metrics
data = pd.read_csv('./daa/salary_potential.csv')
X = data['early_career_pay'].values.reshape(-1,1) # 自变量:转换为二维数组
y = data['mid_career_pay'] # 因变量
# 2. 模型初始化与拟合
model = LinearRegression()
model.fit(X, y) # 拟合线性模型
# 3. 预测
y_pred = model.predict(X)
# RMSE MAE R2
print('RMSE:', metrics.mean_squared_error(y, y_pred) ** 0.5) #** 0.5 : 开方
print('MAE:', metrics.mean_absolute_error(y, y_pred))
print('R2:', metrics.r2_score(y, y_pred))
#运行结果:
RMSE: 2882.920049401636
MAE: 2182.852905759447
R2: 0.9669085091405043结果解读:
- RMSE:2882.92,说明误差为2882.92,误差越小,说明模型拟合的越好。
- MAE:2182.85,说明误差为2182.85,误差越小,说明模型拟合的越好。
- R2:0.9669,说明模型对因变量变异的解释程度为96.69%,这个值越接近1,越拟合,现在为0.9669,说明解释力很强,模型拟合的很好。
通过上面的结果,可以看出,模型拟合的很好,说明线性回归模型适合用于预测中期职业薪酬。
方法2:statsmodels实现(含哑变量建模)
无论哪种回归方法,都需要对数据进行处理,如果遇到非数值型数据,就需要线进行数值化处理,如:哑变量化。 👈
在经济金融数据中,常存在分类变量(如高校名称、行业类别),无法直接参与线性回归,需转换为哑变量(虚拟变量)(0-1编码),pandas的pd.get_dummies()可实现该转换,statsmodels支持直接将分类变量纳入公式建模(自动生成哑变量)。
import pandas as pd
import statsmodels.api as sm
data = pd.read_csv('./data/salary_potential.csv')
data = data.fillna(0)
# 案例1:手动生成哑变量(高校名称)
dummies_name = pd.get_dummies(data['name']) # 分类变量转哑变量
#显示所有的列
# pd.set_option('display.max_columns', None)
print(dummies_name)
# 案例2:以高校毕业生新手数据集的比列值和高效名称来进行线性预测早期薪酬
# 公式化建模(自动生成哑变量),纳入分类变量+连续变量
model = sm.formula.ols(
'early_career_pay ~ make_world_better_percent + name',
data=data[['early_career_pay', 'make_world_better_percent', 'name']]
).fit()
print(model.params) # 输出包含哑变量的所有回归参数运行结果 :
Intercept 52477.519363
name[T.Adventist University of Health Sciences] 11815.725350
name[T.Agnes Scott College] 1744.241417
name[T.Alabama A&M University] 4588.482834
name[T.Alabama State University] -3878.792914
...
name[T.Xavier University] 5957.585828
name[T.Xavier University of Louisiana] 3309.689920
name[T.Yale University] 25467.275748
name[T.Yeshiva University] 16792.137325
make_world_better_percent -144.241417可以看出高校的名字都转成了一个一个的数据类,单独成了一个自变量,因此有了一个单独的系数。比方说:name[T.Yale University] = 25467.275748:耶鲁大学比基准组薪资高约 2.55 万美元
有了上面的截距,和各个自变量的系数,我们的多元方程就可以求出来了,
其中,,,,...,是自变量,,,,...,是回归系数,是误差项。
多元线性仍然属于线性回归模型范畴,也需要满足一些基本假设,才能保证模型结果的可靠性,如:线性性、正态性、无多重共线性、残差独立、方差齐性等,若假设不成立,模型结果将失去统计意义,因此建模后需进行针对性检验。
2.1.3 线性回归模型的检验
线性回归模型的成立需要满足一系列基本假设(线性性、正态性、无多重共线性、残差独立、方差齐性等),若假设不成立,模型结果将失去统计意义,因此建模后需进行针对性检验。
检验1:正态性检验(因变量)
👉 👉 线性回归要求因变量服从或近似服从正态分布,可通过直方图+核密度曲线可视化检验,结合scipy.stats.normaltest统计检验。 👈👈
例子:对高效毕业生早期薪资进行正态性检验 👇
import pandas as pd
import seaborn as sns
import scipy.stats as stats
import matplotlib.pyplot as plt
data = pd.read_csv('salary_potential.csv')
# 可视化:直方图+核密度曲线+标准正态曲线
sns.distplot(data['early_career_pay'], bins=10, fit=stats.norm, norm_hist=True)
plt.xlabel('早期职业薪酬')
plt.title('因变量正态性检验')
plt.show()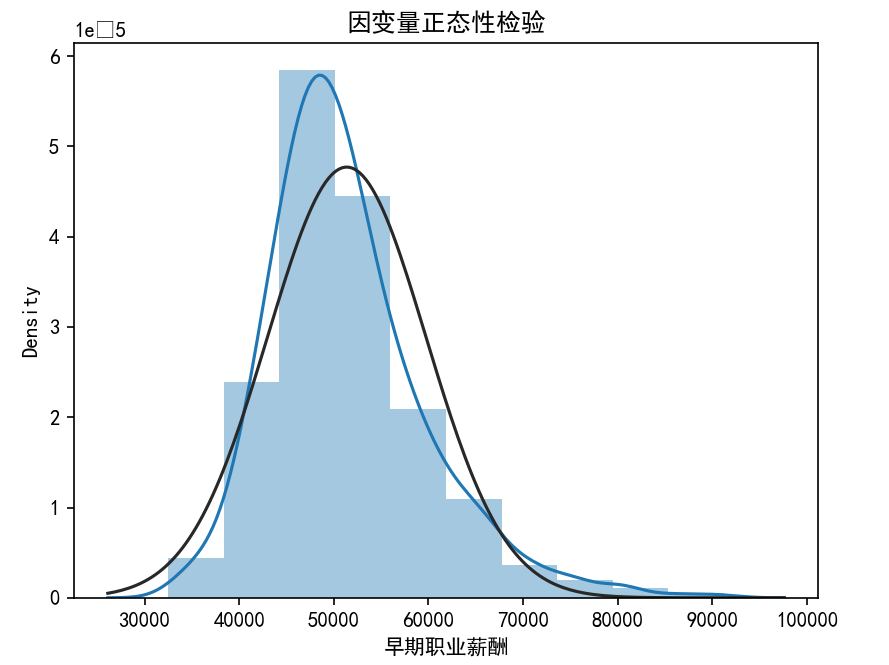
结果解读:图呈现一定的正态分布特征。 接下来要考虑自变量之间的关系(诸多自变量)
检验2:多重共线性检验(自变量)
多元线性回归要求自变量之间无严重的多重共线性(即自变量间高度相关),否则会导致回归系数不稳定,核心检验方法为方差膨胀因子(VIF):
- VIF<5:无多重共线性;
- VIF>10:存在多重共线性;
- VIF>100:严重多重共线性,需剔除或合并自变量。
实操:通过statsmodels计算VIF,对高校薪酬的2个比例值make_world_better_percent和stem_percent进行多重共线性检验。 👇
import pandas as pd
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
data = pd.read_csv('./data/salary_potential.csv')
data = data.fillna(0)
# 自变量矩阵:添加常数项
X = sm.add_constant(data[['make_world_better_percent', 'stem_percent']])
# 计算VIF
vif_result = pd.DataFrame()
vif_result['features'] = X.columns
vif_result['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(vif_result)
结果如下:
features VIF
0 const 17.690558
1 make_world_better_percent 1.002663
2 stem_percent 1.002663结果解读 :2个自变量对应的VIF均小于5,说明不存在多重共线性。
检验3:线性相关性
线性相关性比较简单,直接可以通过皮尔逊相关系数来计算,皮尔逊相关系数的取值范围为[-1,1],越接近1,说明线性相关性越强。
例子:对高校数据集中的早期薪酬和其他列进行线性检测
import pandas as pd
import numpy as np
data = pd.read_csv('./data/salary_potential.csv')
data = data.fillna(0)
# 计算皮尔逊相关系数
# corrwith() 只能计算数值型变量的相关系数,非数值型变量会报错
#剔除2个非数字的列
data = data.drop(['name','state_name'], axis=1)
corr = data.corrwith(data['early_career_pay'])
print(corr)
运行结果:
rank -0.485140
early_career_pay 1.000000
mid_career_pay 0.983315
make_world_better_percent -0.031872
stem_percent 0.605061结果解读:
从数据可以看出早期薪酬和mid_career_pay(中期薪酬)的皮尔逊相关系数为0.983315,说明两者线性相关系数非常高,说明两者之间有很强的线性关系。
这里要注意的是如果存在非线性关系,皮尔逊相关系数会很小,甚至为负数,因此皮尔逊相关系数并不能完全判断线性关系,还需要结合散点图来看。如果只是建立线性模型,可以关注mid_career_pay和stem_percent,因为这两个变量的皮尔逊相关系数相对较大,说明线性关系比较强。
检验4:异常点检测
异常点会严重影响线性回归模型的拟合结果,需识别并剔除,核心检测方法有DFFITS值、学生化残差、Cook距离,常用statsmodels的get_influence()实现。
DFFITS(全称:Difference in Fits)是用来判断:某一行数据是不是 “强势异常点”,删掉它,回归系数会不会大变。
- 绝对值 越大 = 这条数据对模型影响 越大
- 绝对值 越小 = 这条数据 没什么影响
怎么判断是不是异常强影响点? 经验判断规则(最常用):
- (p):自变量个数(包括截距)
- (n):样本数
import pandas as pd
import statsmodels.api as sm
import math
data = pd.read_csv('./data/salary_potential.csv')
data = data.fillna(0)
# 建模
model = sm.formula.ols(
'early_career_pay ~ make_world_better_percent + stem_percent',
data=data[['make_world_better_percent', 'early_career_pay', 'stem_percent']]
).fit()
# 获取异常点检测结果
outliers = model.get_influence()
# 方法1:DFFITS值检测,阈值为2*sqrt((特征数+1)/样本量)
p = model.df_model # 特征数
n = data.shape[0] # 样本量
threshold = 2 * math.sqrt((p+1)/n)
print(f"DFFITS阈值为:{threshold}")
dffits = outliers.dffits[0]
dffits_outlier = [abs(i) > threshold for i in dffits]
print(f"DFFITS异常点数量:{sum(dffits_outlier)}")
# 方法2:学生化残差检测,阈值为±2:帮你找出哪些样本是 “异常点 / 离群点”,让模型不准、结果不可信。
resid_stu = outliers.resid_studentized_external
resid_outlier = data[abs(resid_stu) > 2] # 找出异常点
print(f"学生化残差异常点:\n{resid_outlier[['name', 'early_career_pay']]}")
运行结果:
DFFITS阈值为:0.11328823680740416
DFFITS异常点数量:69
学生化残差异常点:
name early_career_pay
24 Miles College 34800
43 Southern Arkansas University Main Campus 42800
49 Lyon College 41200
53 Philander Smith College 34600
54 Harvey Mudd College 88800检验5:残差检验(独立性+方差齐性)
线性回归要求残差(真实值-预测值)满足独立性和方差齐性:
- 残差独立性检验:采用杜宾-瓦特森(DW)检验,DW值接近2则残差独立;
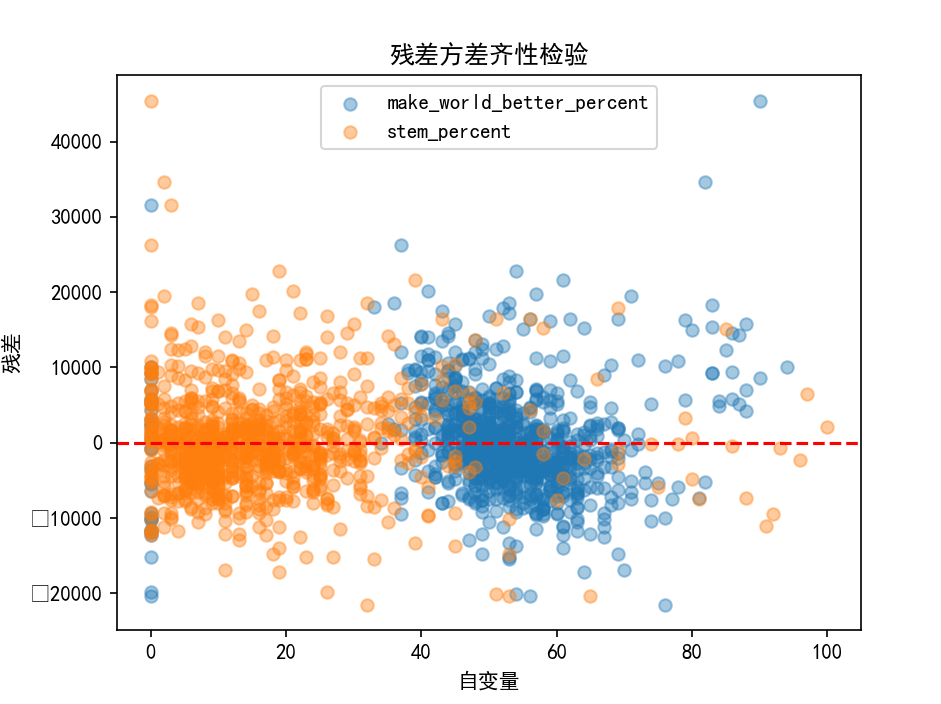
- 残差方差齐性检验:采用散点图检验,残差随自变量的分布无明显趋势则满足方差齐性。
实操:残差的独立性与方差齐性检验
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
data = pd.read_csv('salary_potential.csv')
data = data.fillna(0)
model = sm.formula.ols(
'early_career_pay ~ make_world_better_percent + stem_percent',
data=data
).fit()
resid = model.resid # 获取残差
# 1. 独立性检验:杜宾-瓦特森检验
dw_value = sm.stats.stattools.durbin_watson(resid)
print(f"杜宾-瓦特森值:{dw_value:.4f}") # 约1.0485,偏离2,残差存在自相关
# 2. 方差齐性检验:残差散点图
plt.scatter(data['make_world_better_percent'], resid, alpha=0.4, label='make_world_better_percent')
plt.scatter(data['stem_percent'], resid, alpha=0.4, label='stem_percent')
plt.axhline(y=0, c='r', linestyle='--')
plt.xlabel('自变量')
plt.ylabel('残差')
plt.legend()
plt.title('残差方差齐性检验')
plt.show()杜宾-瓦特森值:1.0485,偏离2,残差存在自相关;残差散点图显示残差随自变量分布无明显趋势,说明方差齐性。
2.2 非线性回归分析
前言
当自变量与因变量之间的关联形态为非线性,或线性回归模型的假设不满足、拟合效果差时,需采用非线性回归分析。非线性回归无固定的数学模型,核心通过机器学习算法拟合变量间的非线性关系,常用算法包括基本回归算法和集成回归算法。
2.2.1 常用非线性回归算法
分为基本回归算法和集成回归算法,集成算法通过组合多个基本算法,显著提升预测效果,是实际应用的首选。
| 类别 | 常用算法 | 核心特点 |
|---|---|---|
| 基本回归算法 | 决策树回归、SVM回归、KNN回归 | 原理简单,单模型效果有限 |
| 集成回归算法 | 随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees | 组合多模型,拟合能力强,泛化性好 |
KNN: K近邻算法,用于分类和回归,回归时,输出为k个邻居的均值。
SVM: 支持向量机
所有算法均可通过sklearn实现,建模步骤与线性回归一致:数据准备→模型初始化→拟合→预测→评估。
2.2.2 非线性回归建模实操
案例:使用8种非线性回归算法,基于make_world_better_percent和stem_percent和**早期职业薪酬(early_career_pay)**进行分析,并对比模型效果。
import pandas as pd
from sklearn import tree, svm, neighbors
from sklearn.ensemble import RandomForestRegressor, AdaBoostRegressor, GradientBoostingRegressor, BaggingRegressor
from sklearn.tree import ExtraTreeRegressor
from sklearn import metrics
# 1. 数据准备
data = pd.read_csv('salary_potential.csv')
data = data.fillna(0)
X = data[['make_world_better_percent', 'stem_percent']].values.reshape(-1,2)
y = data['early_career_pay']
# 2. 初始化8个非线性回归模型
models = [
tree.DecisionTreeRegressor(), # 决策树
svm.SVR(), # SVM回归
neighbors.KNeighborsRegressor(), # KNN回归
RandomForestRegressor(n_estimators=10), # 随机森林(10棵树)
AdaBoostRegressor(n_estimators=10), # Adaboost
GradientBoostingRegressor(n_estimators=10), # GBRT
BaggingRegressor(), # Bagging
ExtraTreeRegressor() # ExtraTrees极端随机树
]
# 3. 模型训练、预测与评估(以R方为指标)
model_names = ['决策树','SVM','KNN','随机森林','Adaboost','GBRT','Bagging','ExtraTrees']
for name, model in zip(model_names, models):
model.fit(X, y)
y_pred = model.predict(X)
r2 = metrics.r2_score(y, y_pred)
print(f"{name} R2:{r2:.4f}")
# 结果示例:
决策树 R2:0.8599
SVM R2:-0.0178
KNN R2:0.5607
随机森林 R2:0.7670
Adaboost R2:0.4478
GBRT R2:0.4138
Bagging R2:0.7746
ExtraTrees R2:0.8599结果解读:决策树和ExtraTrees的R方最高,SVM效果最差,说明不同非线性算法对同一数据集的拟合能力差异显著,需根据数据特点选择。
思考
上面这种用全部特征进行训练,然后用全部特征进行预测,有没有什么问题呢?
2.2.3 交叉验证
上述建模采用全样本训练+全样本测试,容易出现过拟合(模型在训练集效果好,测试集效果差),更合理的验证方法是交叉验证(Cross Validation),将数据集随机划分为训练集和测试集,多次划分并计算平均效果,核心通过sklearn.model_selection.cross_val_score实现。
实操:10折交叉验证评估非线性回归模型
同学们,交叉验证上学期讲过的,还记得吗?
10折交叉验证:将数据集随机划分为10个部分,轮流将其中9个部分作为训练集,1个部分作为测试集,进行10次训练和测试,最终结果取10次的平均。
import pandas as pd
from sklearn import tree, svm, neighbors
from sklearn.ensemble import RandomForestRegressor, AdaBoostRegressor, GradientBoostingRegressor, BaggingRegressor
from sklearn.tree import ExtraTreeRegressor
from sklearn.model_selection import cross_val_score
# 1. 数据准备
data = pd.read_csv('salary_potential.csv')
data = data.fillna(0)
X = data[['make_world_better_percent', 'stem_percent']].values.reshape(-1,2)
y = data['early_career_pay']
# 2. 初始化模型
models = [
tree.DecisionTreeRegressor(),
svm.SVR(),
neighbors.KNeighborsRegressor(), #KNN回归
RandomForestRegressor(n_estimators=10),# 随机森林(10棵树)
AdaBoostRegressor(n_estimators=10),
GradientBoostingRegressor(n_estimators=10),
BaggingRegressor(),
ExtraTreeRegressor()
]
model_names = ['决策树','SVM','KNN','随机森林','Adaboost','GBRT','Bagging','ExtraTrees']
# 3. 10折交叉验证,计算平均R方
for name, model in zip(model_names, models):
scores = cross_val_score(model, X, y, cv=10, scoring='r2').mean() #cv=10表示10折交叉验证
print(f"{name} 10折交叉验证平均R2:{scores:.4f}")
# 结果示例:
决策树 10折交叉验证平均R2:-0.2163
SVM 10折交叉验证平均R2:-0.0631
KNN 10折交叉验证平均R2:0.3061
随机森林 10折交叉验证平均R2:0.1451
Adaboost 10折交叉验证平均R2:0.2596
GBRT 10折交叉验证平均R2:0.3340
Bagging 10折交叉验证平均R2:0.1596
ExtraTrees 10折交叉验证平均R2:-0.2350结果解读:
从结果看,模型的实际 效果 没有 那么好,R方的 值最高不过 0.4,有的值还是负数,还不如直接盲猜,当然也说明这个2个比例值和早期薪资 之间相关性较弱。
本章总结
本章围绕数据相关性分析展开,从相关度计算到回归分析,逐步实现了数据间关联关系的量化和预测,核心知识点可总结为以下四点:
- 相关度是基础:区分线性相关(皮尔逊系数)和非线性相关(斯皮尔曼、肯德尔系数),通过散点图直观观察,通过
pandas.corr()快速计算,注意相关性≠因果性; - 线性回归是核心:一元/多元线性回归是经济金融预测的基础方法,sklearn实现快速建模,statsmodels实现详细统计分析,建模后需通过MSE、RMSE、R方等指标评估效果;
- 模型检验是关键:线性回归需满足正态性、无多重共线性、残差独立等假设,通过VIF、DFFITS、杜宾-瓦特森检验等验证假设,剔除异常点和多重共线性特征;
- 非线性回归是补充:当线性假设不满足时,采用决策树、随机森林等机器学习算法实现非线性回归,通过交叉验证评估模型的泛化能力,避免过拟合。
课后作业
- 基于
salary_potential.csv,计算mid_career_pay与所有其他变量的线性和非线性相关度,筛选出相关度绝对值大于0.5的变量; - 以
stem_percent为自变量,mid_career_pay为因变量,构建一元线性回归模型,输出模型公式并计算所有评估指标; - 以
rank、stem_percent、make_world_better_percent为自变量,early_career_pay为因变量,构建多元线性回归模型,检验自变量的多重共线性并识别异常点; - 选择3种非线性回归算法,对上述多元回归问题进行建模,使用10折交叉验证评估模型效果,并与线性回归模型的R方对比。