
1.数据类型
前言
1 数据类型
数据是分析的基础,不同类型的数据适用的统计方法与分析模型存在显著差异,需先明确数据的分类方式与识别方法。数据类型可分为单一数据类型和组合数据类型两大类。
1.1 单一数据类型
单一数据类型是构成数据的基本单元,可从存储计算、取值特点、次序属性、间隔计量四个维度划分,各维度分类并非互斥,而是从不同角度描述数据特征,具体分类如下:
- 按存储计算类型划分:整型(如100)、浮点型(如123.45)、布尔型(True/False)、字符型(如'010',注意与数值010的区别,字符型无法参与数值计算);
- 按取值特点划分:连续型数据(区间/浮点型数据,如价格、身高)、离散型数据(计数型数据,又可细分为分类型数据、二元数据,如性别、行业类别);
- 按次序属性划分:定序数据(有明确次序,如成绩等级A/B/C)、不定序数据(无次序,如品牌、颜色);
- 按间隔计量划分:定距数据(有固定计量单位,如温度、工资)、不定距数据(无固定计量单位,如满意度评分)。
1.2 组合数据类型
组合数据类型是由多个单一数据类型按一定结构组合而成,经济金融分析中最常用的是一维和二维组合数据:
- 一维组合数据:如一维数组、列表,用于存储单一维度的序列数据(如某支股票的每日收盘价);
- 二维组合数据:如表格、DataFrame,是经济金融分析的核心数据结构,包含行(样本)和列(特征),例如:
| ID | name | gender | age | height |
|---|---|---|---|---|
| 000001 | 黎明 | 男 | 16 | 1.88 |
| 000002 | 赵怡春 | 女 | 20 | 1.78 |
| 000003 | 张富平 | 男 | 18 | 1.81 |
在Python中,二维组合数据主要通过pandas的DataFrame实现,是后续抽样、分组、分析的主要操作对象。
2 数据抽样
前言
当面对大规模经济金融数据(如海量二手车交易数据、全行业就业数据)时,直接分析会消耗大量计算资源,且无实际必要,因此需要从大规模数据中有针对性地选择一部分数据作为分析样本,抽样的核心是保证样本的代表性。数据抽样主要分为随机抽样和非随机抽样(等距、分层、整群),均可通过Python+pandas实现。
1. 简单随机抽样(完全乱抽)
总体:■ ■ ■ ■ ■ ■ ■ ■ ■ ■
样本:■ □ ■ □ □ ■ □ ■ □ □
特点:**随机、无规律、随便抽**
2. 等距抽样(按固定间隔抽)
总体:■ ■ ■ ■ ■ ■ ■ ■ ■ ■
间隔:每隔 3 个抽1个
样本:■ □ □ ■ □ □ ■ □ □ ■
特点:**按序号、等距离、有规律**
3. 分层抽样(每层都抽一点)
层1:■ ■ □ □
层2:■ ■ □ □
层3:■ ■ □ □
特点:**每层都抽,每层抽部分**
4. 整群抽样(抽几群,全要)
群1:■ ■ ■ ■ (抽中,全要)
群2:□ □ □ □ (不抽)
群3:□ □ □ □ (不抽)
特点:**只抽部分群,抽中全调查**2.1 随机抽样
随机抽样是从全部数据中按照随机原则抽取所需数量的样本,样本结果不固定,每次抽取均为随机生成。
- 核心方法:pandas中DataFrame的
sample()方法; - 关键参数:
n(抽取样本数量)、frac(抽取样本比例)、replace=True(重复抽样,允许同一数据被多次抽取); - 实操案例:从二手车交易数据
car_train_0110.csv中重复抽取10条记录
import pandas as pd
data = pd.read_csv('car_train_0110.csv', sep=' ')
print(data.sample(10, replace=True)) # 数量抽样
# print(data.sample(frac=0.01, replace=True)) # 比例抽样(1%)
# 10条数据结果
SaleID name regDate ... v_21 v_22 v_23
159347 179083 2419 20030905 ... 3.775984 -2.304658 4.624588
213241 64750 151 19960010 ... 6.517135 3.139330 -0.546828
161484 331256 210880 19991101 ... -2.954625 -3.580479 -1.445003
126592 189834 128729 19800001 ... 2.751083 -1.057836 -0.478977
189 106859 76835 19930902 ... -3.225490 -2.521426 -1.254968
245322 201276 15718 20171204 ... 1.910520 -1.145999 -1.233223
17797 7813 7040 20081110 ... -3.432106 -2.683408 -1.543393
10162 188258 127761 19990211 ... -2.933166 -1.691865 -1.094587
135071 255984 167834 20101005 ... -3.511693 -2.883519 -1.651740
196197 290326 18846 20040606 ... 4.479932 -2.448235 -1.767866
[10 rows x 40 columns]2.2 等距抽样
等距抽样又称系统抽样,按照固定的步幅从数据中选择样本,适用于数据按一定规律排列且无周期性偏差的场景。
- 核心思路:确定抽样步幅(数据总量/样本量),从起始位置开始,每隔固定步幅选取一个样本;
- 适用场景:如按时间顺序排列的金融交易数据,等距抽取某一时间段的样本。
- 实操案例:按照等距抽样来抽取2000个数据样本
import pandas as pd
data = pd.read_csv('car_train_0110.csv', sep=' ')
n = 2000 # 样本数量
step = len(data) // n # 计算步幅
result = pd.DataFrame(columns=data.columns)
for i in range(0, len(data), step):
result = result.append(data.iloc[i]) # 按步幅选取样本
print(result)注意 :上面代码在pandas版本2.0+以上会报错,因为append方法在pandas2.0+已被弃用,可使用pd.concat()方法替代,具体代码如下:
核心特性总结
| 特性维度 | DataFrame.append() (已移除) | pd.concat() (推荐替代) |
|---|---|---|
| 核心定位 | 仅用于行方向追加的专用便捷方法 | 支持行/列拼接的通用型数据拼接工具 |
| 版本兼容性 | pandas 2.0+ 彻底移除,低版本可用 | 全版本兼容,官方长期推荐 |
| 拼接方向 | 仅支持行拼接(axis=0),无列拼接能力 | 支持行拼接(axis=0)、列拼接(axis=1),灵活可控 |
| 性能表现 | 循环拼接时频繁创建新对象,时间复杂度O(n²),效率极低 | 先收集数据片段再批量拼接,时间复杂度O(n),效率更高 |
| 参数灵活性 | 参数少,仅支持ignore_index等基础配置 | 参数丰富,支持索引重置、层级索引、空值处理等复杂场景 |
import pandas as pd
# 读取数据(sep=' ' 表示空格分隔,若实际是逗号可改为sep=',')
data = pd.read_csv('./data/car_train_0110.csv', sep=' ')
n = 2000 # 目标样本数量
# 计算步幅(避免步幅为0,若数据量小于n则直接取全部)
step = max(1, len(data) // n)
# 初始化结果列表(用列表收集行,最后concat更高效)
result_list = []
# 按步幅选取样本
for i in range(0, len(data), step):
# 选取单行并添加到列表(iloc[i]返回Series,需转成DataFrame行)
result_list.append(data.iloc[i:i+1]) # i:i+1 保持DataFrame格式,避免Series拼接问题
# 合并所有选取的行
result = pd.concat(result_list, ignore_index=True)
# 确保最终样本数不超过n(防止步幅计算偏差)
if len(result) > n:
result = result.head(n)
print(f"最终采样数量:{len(result)}")
print(result)考虑到大家基本安装的是最新的anaconda,Python版本一般都在Python12以上,因此后面我们将使用pd.concat()方法替代append()方法。 这和教材上存在一定出入。
2.3 分层抽样
分层抽样是先将总体数据按某一特征划分为多个类别(层),再从每个类别中采用随机/等距抽样选取样本,核心是保证每个类别在样本中均有代表,适用于数据分布不均匀的场景。
- 实操案例:在二手车数据中,按汽车品牌分层,每个品牌随机抽取20个样本
import pandas as pd
data = pd.read_csv('./data/car_train_0110.csv', sep=' ')
brands = data['brand'].unique() # 获取所有品牌(分层依据)
#输出品牌个数
print('品牌个数:', len(brands))
result = pd.DataFrame(columns=data.columns) # 初始化结果数据集
result_list = [] # 结果列表
# 循环 brands 将每个品牌数据集随机抽取20个样本
for brand in brands:
result_list.append(data[data['brand'] == brand].sample(n=20))
# 将结果列表拼接成结果数据集
result = pd.concat(result_list)
print(result)
输出结果:
个数: 40
SaleID name regDate ... v_21 v_22 v_23
29267 140569 23409 20040903 ... -1.131758 -0.937426 -1.132098
89479 290258 187612 20090912 ... -3.214885 -1.692465 -1.388357
84118 365145 229863 19980706 ... -2.802282 -1.437043 4.568623
241183 6777 6146 20171001 ... -1.354750 -0.878235 -1.102089
184750 214348 143443 20061012 ... -8.210236 3.639864 -0.956632
... ... ... ... ... ... ... ...
88078 52626 40610 19990508 ... 0.868516 1.480524 -0.667411
85422 29146 23740 19850805 ... 2.080432 3.224460 -0.504647
67583 288709 186726 20091204 ... -3.144834 -1.528116 -1.315564
138025 215522 144151 19990509 ... -2.919177 -2.075426 -1.178634
246819 282982 23353 20000506 ... 3.659252 -0.895660 -1.240179
[800 rows x 40 columns]2.4 整群抽样
整群抽样是先将所有数据分为若干个小群体,再随机抽取部分群体,将抽中群体的全部数据作为样本,与分层抽样的区别:分层抽样是“每层抽部分”,整群抽样是“抽部分群,群内全要”。
- 实操案例:从二手车品牌中随机抽取2个品牌,将这2个品牌的全部数据作为样本
import random
import numpy as np
import pandas as pd
# - **实操案例**:从二手车品牌中随机抽取2个品牌,将这2个品牌的全部数据作为样本
data = pd.read_csv('./data/car_train_0110.csv', sep=' ')
brands = data['brand'].unique().tolist()
# 随机 抽取2个品牌
simple_brands= random.sample(brands, 2) # 随
# 打印 brands
print('品牌列表:', simple_brands)
#创建一个空的DataFrame
result = pd.DataFrame(columns=data.columns)
result_list= []
for brand in simple_brands:
temp=data[data['brand']==brand]
result_list.append(temp)
# 将2个品牌数据拼接
result=pd.concat(result_list)
# 只显示name和brand列
print(result[['name', 'brand']])
# 结果输出
品牌列表: [20, 24]
name brand
22 63075 20
28 65087 20
381 103182 20
758 10294 20
936 169391 20
... ... ...
249303 120124 24
249315 219576 24
249464 19467 24
249789 163325 24
249815 9724 24
[3288 rows x 2 columns]抽样方法总结
| 抽样方法 | 核心特点 | 适用场景 | Python核心工具 |
|---|---|---|---|
| 随机抽样 | 完全随机,无规律 | 数据分布均匀,无明显类别特征 | pandas.DataFrame.sample() |
| 等距抽样 | 固定步幅,系统选取 | 数据按时间/顺序排列,无周期性偏差 | 自定义循环+步幅选取 |
| 分层抽样 | 按特征分层,层内抽样 | 数据存在明显类别,需保证各层代表性 | pandas+循环+分层条件 |
| 整群抽样 | 分群后随机抽群,群内全取 | 数据可划分为独立群体,群体内部特征相似 | pandas+random.sample()+群条件 |
3 数据分组
前言
原始的单变量数值往往杂乱无章,直接计算难以发现规律,数据分组是将具有相同/相似含义的数据归入同一类,形成数据量更少、特征更明显的数据组,是数据分布分析的前提。数据分组主要分为等距分组和不等距分组,核心工具为pandas的cut()和qcut()方法。
3.1 等距分组
等距分组是按照固定的数值区间划分各组,区间间隔相等,关键在于确定组数,可参考Sturges经验公式确定组数,适用于数据分布相对均匀的场景。
3.1.1 核心方法与参数
- 核心方法:
pd.cut(x, bins, labels, right=True); - 关键参数:
x(待分组数据列)、bins(组数/自定义区间列表)、labels(组标签)、right=True(右闭区间,默认)/right=False(左闭区间)。
3.1.2 实操案例(二手车价格等距分组)
- 查看二手车价格的唯一数值种数
import pandas as pd
data = pd.read_csv('./data/car_train_0110.csv', sep='')
result=data[['SaleID', 'price']].groupby('price').count()
print(result) # 分组统计唯一值
结果输出:
price SaleID
0 7312
1 791
2 9
3 4
5 17
... ...
99500 1
99900 3
99990 1
99999 10
100000 4- 将价格分为13组并展示分组结果
print(pd.cut(data['price'], bins=13)) # 自动划分13个等距区间
运行结果:
0 (-100.0, 7692.308]
1 (-100.0, 7692.308]
2 (-100.0, 7692.308]
3 (-100.0, 7692.308]
4 (-100.0, 7692.308]
...
249995 (-100.0, 7692.308]
249996 (-100.0, 7692.308]
249997 (15384.615, 23076.923]
249998 (30769.231, 38461.538]
249999 (-100.0, 7692.308]- 等距分组后统计每组数据数量
# 方法1:cut+value_counts
print(pd.cut(data['price'], bins=13, labels=range(13)).value_counts())
运行结果::point_down:
price
0 191550
1 37471
2 12754
3 4669
4 1725
5 804
6 357
7 250
8 154
9 109
10 61
11 52
12 44
Name: count, dtype: int643.2 不等距分组
不等距分组打破了“区间间隔一致”的特点,可避免等距分组中因数据分布不均导致的部分组数据量过多/过少的问题,核心是让各组数据数量尽可能一致,常用方法为pandas的qcut()方法。
3.2.1 核心方法与区别
- 核心方法:
pd.qcut(x, q, labels),q为分组数,按数据分位数划分区间; - cut与qcut的核心区别:
cut按数值区间分组,区间等距;qcut按数据数量分组,各组数量大致相等。
3.2.2 实操案例(二手车价格不等距分组)
- 将价格分为10组,保证每组数量大致一致
import pandas as pd
data = pd.read_csv('car_train_0110.csv', sep='')
print(pd.qcut(data['price'], q=10).value_counts())
运行结果:
price
(-0.001, 500.0] 28232
(1400.0, 2000.0] 25780
(4100.0, 5999.0] 25615
(8790.0, 13999.0] 25062
(900.0, 1400.0] 24985
(13999.0, 100000.0] 24916
(2950.0, 4100.0] 24589
(5999.0, 8790.0] 24341
(2000.0, 2950.0] 23913
(500.0, 900.0] 22567
Name: count, dtype: int64- 基于位序的精准不等距分组(解决重复值/数据量无法整除问题)
位序是将数据排序后分配唯一序号,结合rank(method='first')(避免重复值位序相同)和qcut(),可实现每组数据数量完全一致:
data['data1'] = data['price'].rank(method='first') # 生成位序
print(pd.qcut(data['price'], q=10).value_counts()) # 按位序分组,每组25000条
运行结果:
price
(-0.001, 500.0] 28232
(1400.0, 2000.0] 25780
(4100.0, 5999.0] 25615
(8790.0, 13999.0] 25062
(900.0, 1400.0] 24985
(13999.0, 100000.0] 24916
(2950.0, 4100.0] 24589
(5999.0, 8790.0] 24341
(2000.0, 2950.0] 23913
(500.0, 900.0] 22567
Name: count, dtype: int64- 自定义不等距区间分组(按业务需求划分)
如将二手车价格按0、1000、10000划分为“无意义、低价、中价、高价”四组,使用float('-inf')(无穷小)和float('inf')(无穷大)覆盖全部数据:
bins = [-np.inf, 0, 1000, 10000, np.inf]
labels = ["无意义", "低价", "中价", "高价"]
print(pd.cut(data['price'], bins=bins, labels=labels).value_counts())
运行结果:
price
中价 150127
低价 52080
高价 40481
无意义 7312
Name: count, dtype: int64- 四分位数分组(按数据分位数四等分)
属于不等距分组的特殊形式,将数据按25%、50%、75%分位数划分为四组,适用于分析数据的分布特征:
data=pd.read_csv('car_train_0110.csv', sep=' ')
print(pd.qcut(data['price'], q=4, labels=['Q1', 'Q2', 'Q3', 'Q4']).value_counts())
运行结果:
price
Q1 63446
Q3 62479
Q4 62044
Q2 62031
Name: count, dtype: int644 数据分布分析
前言
数据分布分析是挖掘数据内在规律的核心环节,通过统计数据的频次、时序变化、集中度等特征,结合可视化手段,直观展现数据的分布形态。主要包括频次分布分析、时序分布分析、集中度分析三大类。
4.1 频次分布分析
频次分布分析是将数据出现的频次按一定标准分组,统计各组频次数量,分为不定序数据和定序数据的频次分析,定序数据可在不定序分析方法的基础上增加累积频次/频率分析,核心可视化工具为matplotlib。
4.1.1 不定序数据的频次分析
不定序数据无先后次序,改变次序不影响理解(如行业、品牌),常用可视化方法:柱状图(纵向/横向)、饼状图、散点图。
实操案例:2019年不同行业就业人员频次可视化
- 纵向柱状图(解决X轴标签重叠问题:调整画布、旋转标签)
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示问题
data = pd.read_csv('就业人口行业划分.csv', encoding='GBK')
data.set_index("年度", inplace=True)
data = data.T # 转置:行业为行,年度为列
fig = plt.figure(figsize=(20, 20), dpi=40)
fig.subplots_adjust(bottom=0.2)
plt.bar(data.index[1:], data[2019][1:])
plt.xticks(rotation=20, fontsize=24)
plt.yticks(fontsize=36)
plt.show()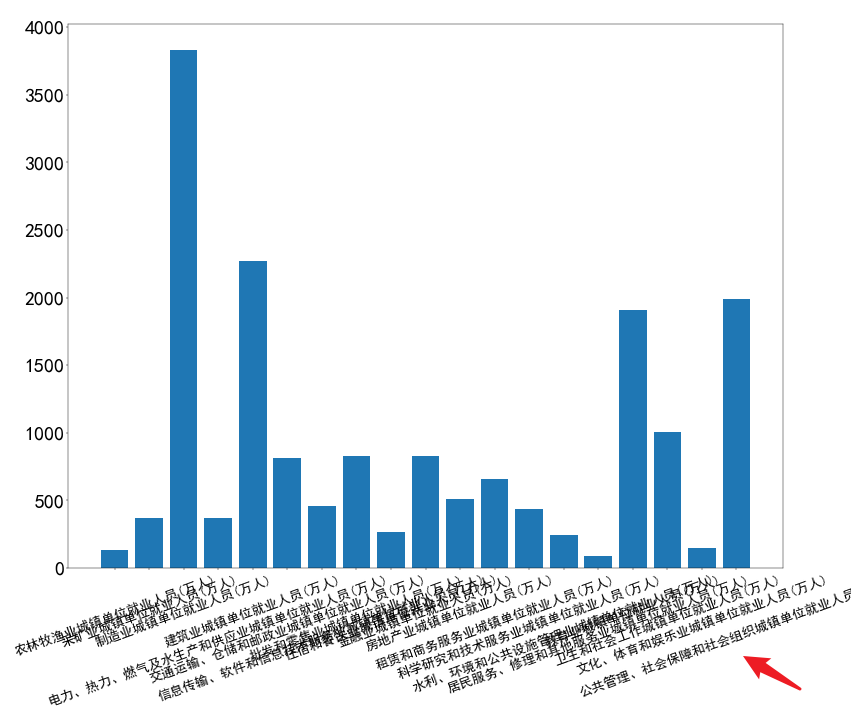
- 横向柱状图(最优解,彻底解决标签重叠)
plt.barh(data.index[1:], data[2019][1:]) # 替换bar为barh
plt.yticks(fontsize=36)
plt.xticks(fontsize=36)
plt.show()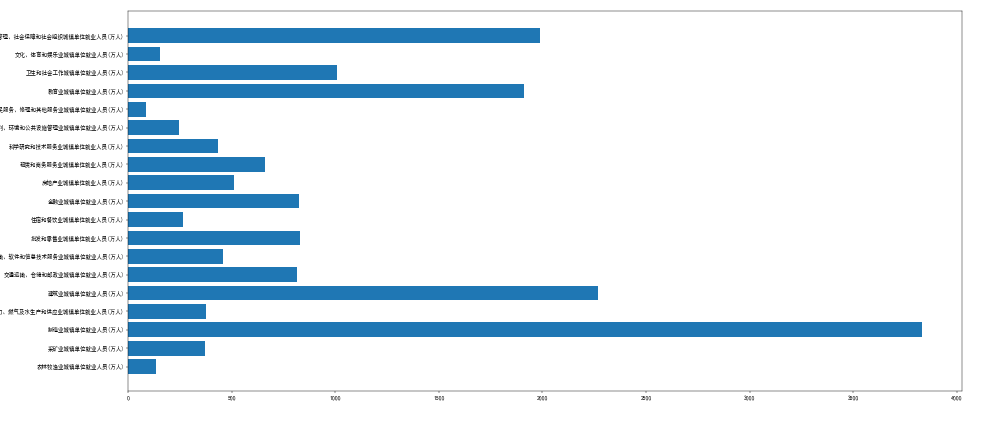
- 饼状图(展示各行业占比)
fig = plt.figure(figsize=(12, 8))
plt.pie(data[2019][1:], labels=data.index[1:], autopct='%.1f%%',
colors=['yellowgreen', 'gold', 'lightskyblue', 'lightcoral'],
textprops={'color': "#444444", 'size': 10, 'weight': 'bold'})
plt.show()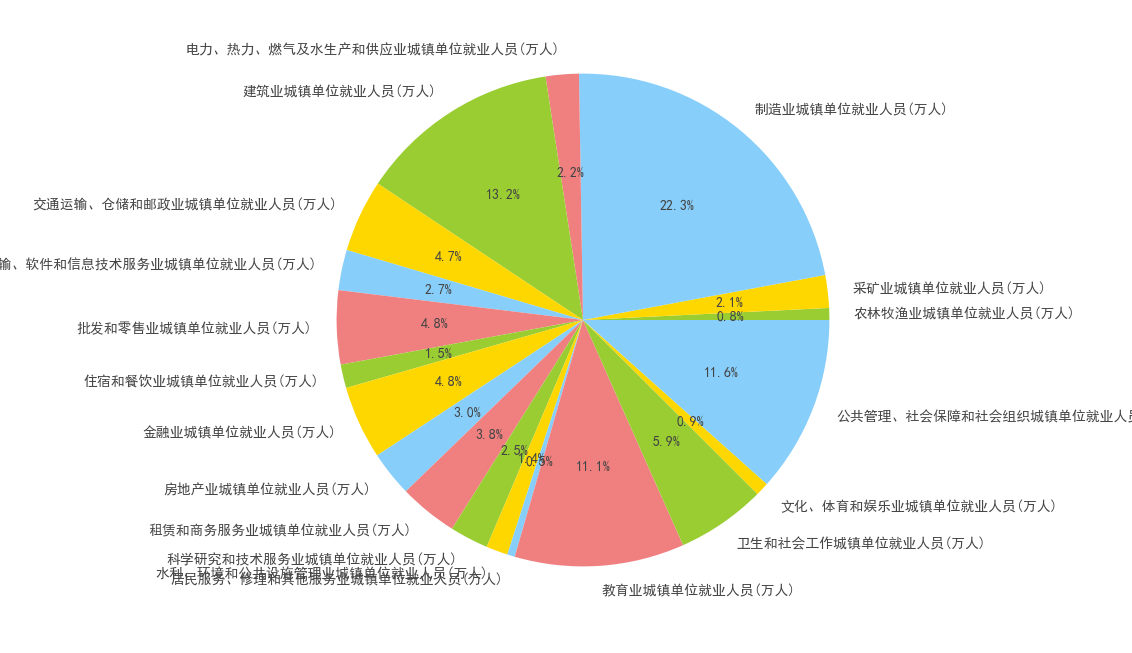
- 散点图(展示二手车价格的数值分布)
data = pd.read_csv('car_train_0110.csv', sep='')
plt.scatter(data.index, data['price'], alpha=0.2, s=1) # alpha:透明度,s:点大小
#x轴字体
plt.xticks(fontsize=10)
#y轴字体
plt.yticks(fontsize=10)
plt.show()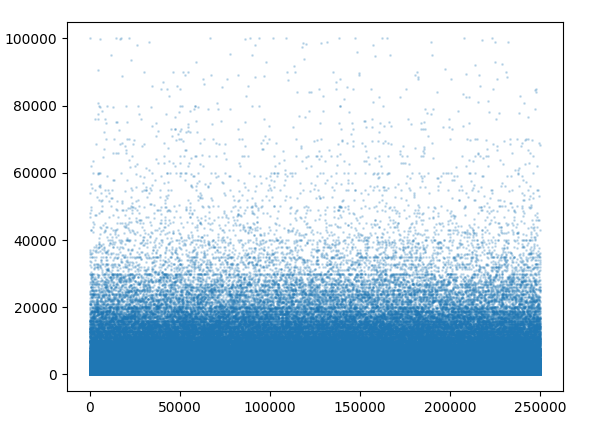
可以发现点非常小,无法看出趋势,可以价格分组后展现数值分布
data= pd.read_csv('car_train_0110.csv', sep='')
relust=data[['price']].groupby(data['price']).count()
plt.scatter(relust.index, relust['price'], alpha=0.2, s=1) # alpha:透明度,s:点大小
plt.show()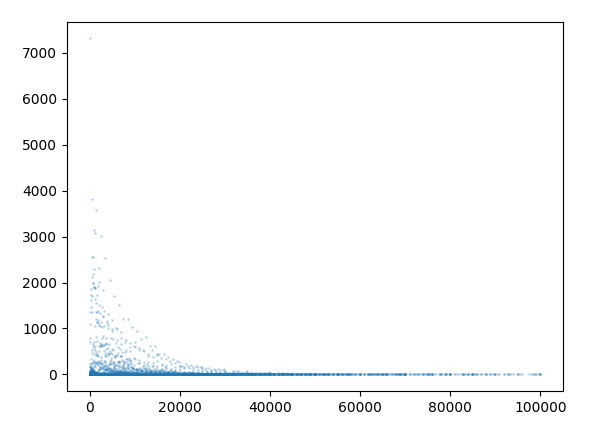
4.1.2 定序数据的频次分析
定序数据有明确次序(如工资、就业人数),除使用不定序数据的分析方法外,还可通过直方图、累积频次/频率、茎叶图等方法加强分析效果。
实操案例:租赁和商务服务业就业人员频次分析
- 基础直方图(展示数值分布)
import pandas as pd
from matplotlib import pyplot as plt
data = pd.read_csv('./data/就业人口行业划分.csv', encoding='GBK')
result=data["租赁和商务服务业城镇单位就业人员(万人)"]
plt.hist(result, bins=20, color="#13EAC9") # hist:直方图 bins 设置柱状图的宽度 colcor 颜色
plt.show()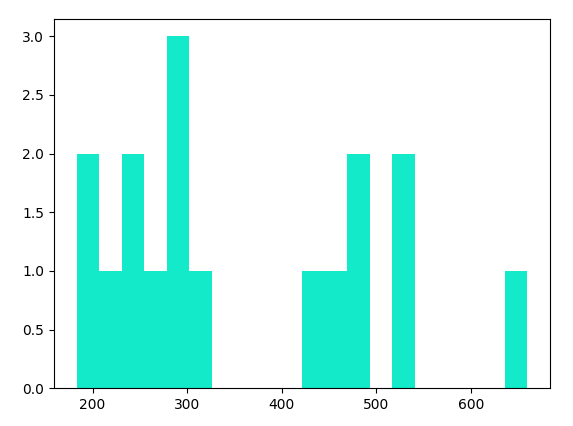
- 自定义直方图(带趋势线,指定数值范围)
n, bins_limits, patches = plt.hist(result,range=[0, 1000], bins=10, color="#13EAC9")
# range=[0, 1000] 设置X轴的显示范围
plt.plot(bins_limits[:len(n)], n, '--') # 趋势线(去除最后一个区间边界)
plt.show()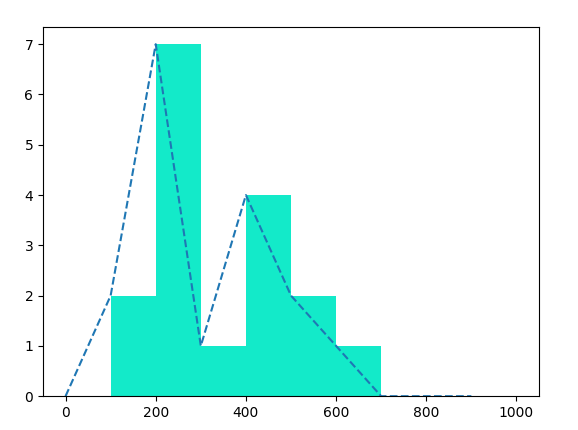
- 累积频次/频率直方图
# 累积频次
plt.hist(result, range=[0, 1000],
bins=10, cumulative=True, color="#13EAC9") # bins=10,表示分成10组,cumulative=True,表示累积频次
# 累积频率(density=True)
plt.hist(result, range=[0, 1000],
bins=10, cumulative=True, density=True, color="#13EAC9") #density=True,表示累积频率
plt.show()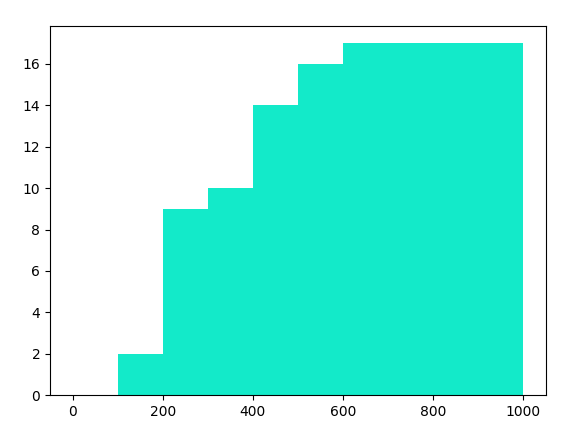
- 对比直方图(两个行业频次对比,透明叠加)
plt.hist(result, label="租赁和商务服务业",bins=20, alpha=0.5)
result1=data["房地产业城镇单位就业人员(万人)"]
plt.hist(result1, label="房地产业",bins=20, alpha=0.5)
plt.legend()
plt.show()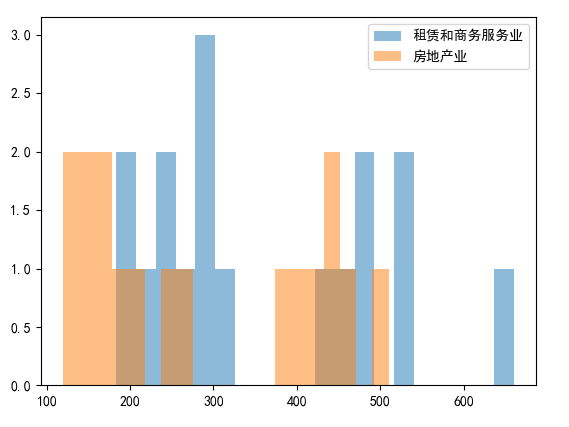
- 二维直方图(展示两个行业的频次相关性)
plt.hist(result, label="租赁和商务服务业",
bins=20, alpha=0.5)
result1=data["房地产业城镇单位就业人员(万人)"]
plt.hist2d(result, result1, bins=5, cmap="Blues")
plt.colorbar() # 颜色刻度条
plt.xlabel("租赁和商务服务业")
plt.ylabel("房地产业")
plt.show()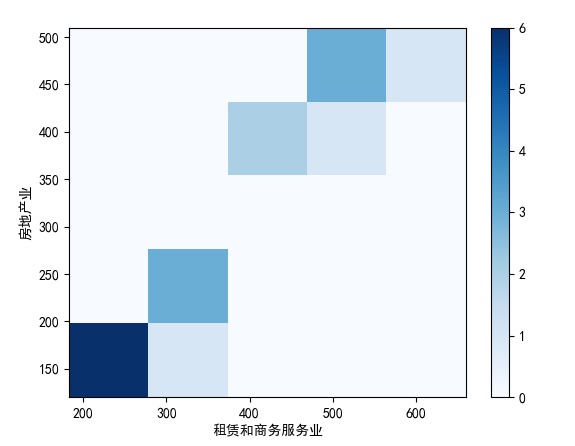
- 茎叶图(展示数值的分布细节,按百位分组)
from itertools import groupby
for k, g in groupby(sorted(result), key=lambda x: x // 100):
g = [str(i) for i in g]
print(k, '|', ' '.join(g))
运行结果
1 | 183 194
2 | 219 237 247 275 287 290 292
3 | 310
4 | 422 449 474 488
5 | 523 530
6 | 6604.2 时序分布分析
时序分布分析是从时间维度分析数据的变化趋势,适用于时间序列数据(如年度就业人数、月度金融指标、每日股价),核心是挖掘数据的时间演变规律,常用可视化方法为柱状图、折线图,可结合累积频率曲线加强分析。
实操案例:租赁和商务服务业就业人员年度变化趋势分析
- 年度变化柱状图(添加数值标签)
import pandas as pd
from matplotlib import pyplot as plt
# 中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
data = pd.read_csv('./data/就业人口行业划分.csv', encoding='GBK')
result=data["租赁和商务服务业城镇单位就业人员(万人)"]
# 绘制柱状图
plt.bar(data["年度"], result)
# 添加数值标签
for i, j in zip(data["年度"], result):
plt.text(i, j, '%.0f'%j, ha='center')
plt.xticks(data["年度"])
plt.show()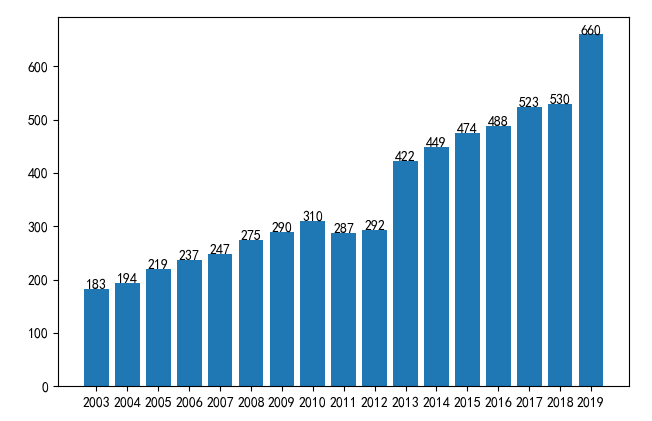
- 累积频率曲线(向上/向下累积,展示频率变化)
# 计算单年度频率、向上累积频率、向下累积频率
data['col1'] = result / result.sum()
data['col2'] = data['col1'].cumsum() # 向上累积
data['col3'] = data['col1'][::-1].cumsum()[::-1] # 向下累积
# 绘制累积曲线
plt.plot(data["年度"], data['col2'], label="向上累积")
plt.plot(data["年度"], data['col3'], label="向下累积")
plt.legend()
plt.show()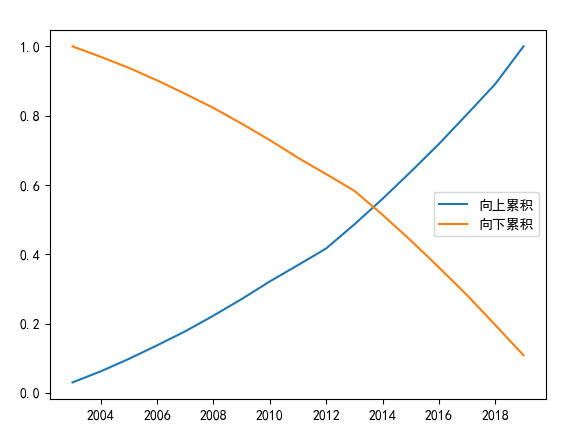
4.3 集中度分析
集中度分析反映数据向其中心值靠拢的倾向,同时结合离中趋势反映数据的分散程度,是描述数据统计特征的核心,分为数值平均数、位置平均数、离中趋势三大类,核心工具为pandas、numpy、scipy。
4.3.1 数值平均数分析
数值平均数是通过数值计算得到的平均值,包括算术平均数、加权平均数、调和平均数、几何平均数,适用于定量数据的集中趋势分析。
实操案例:各行业城镇单位就业人员平均工资的平均数计算
import pandas as pd
import numpy as np
import statistics as s
from scipy import stats
import math
data = pd.read_csv('./data/城镇单位就业人员平均工资与人数.csv', encoding='GBK')
data['平均工资(万元)'] = data['平均工资(元)'] // 10000 # 单位转换:元→万元
# 1. 算术平均数
print("算术平均数:%f" % data["平均工资(万元)"].mean())
# 2. 加权平均数(以就业人数为权重,更贴合经济实际)
print("加权平均数:%f" % np.average(data["平均工资(万元)"], weights=data["人数(万人)"]))
# 3. 调和平均数
print("调和平均数:%f" % s.harmonic_mean(data["平均工资(万元)"]))
# 4. 几何平均数(方法1:scipy.stats.gmean)
print("几何平均数:%f" % stats.gmean(data["平均工资(万元)"]))
# 5. 几何平均数(方法2:对数+算术平均数+指数,手动实现)
data['log_wage'] = data["平均工资(万元)"].apply(math.log)
print("几何平均数(手动):%f" % math.exp(data['log_wage'].mean()))
# 6. 去除极值后的算术平均数(scipy.stats.tmean)
print("去极值算术平均数:%f" % stats.tmean(data["平均工资(万元)"], limits=(5, 12)))
运行结果:
算术平均数:8.684211
加权平均数:7.796610
调和平均数:7.563751
几何平均数:8.151872
几何平均数(手动):8.151872
去极值算术平均数:8.0000004.3.2 位置平均数分析
位置平均数是根据数据在序列中的位置确定的平均值,不受极端值影响,更适用于数据存在异常值的场景,包括众数、中位数、四分位数 ,还可通过偏度、峰度描述数据的分布形态。
偏度:数据分布的不对称性,>0右偏,<0左偏,=0对称
峰度:数据分布的集中程度,>0尖峰,<0平峰,=0正态峰
实操案例:各行业平均工资的位置平均数与分布形态计算
import pandas as pd
import numpy as np
import statistics as s
from scipy import stats
import math
data = pd.read_csv('./data/城镇单位就业人员平均工资与人数.csv', encoding='GBK')
data['平均工资(万元)'] = data['平均工资(元)'] // 10000 # 单位转换:元→万元
# 1. 众数(出现次数最多的数值)
print("众数:%f" % data["平均工资(万元)"].mode().iloc[0])
# 2. 中位数(50%分位数,数据排序后中间值)
print("中位数:%f" % data["平均工资(万元)"].median())
# 3. 四分位数(0/25%/50%/75%/100%分位数)
q0 = data["平均工资(万元)"].quantile(0)
q1 = data["平均工资(万元)"].quantile(0.25)
q2 = data["平均工资(万元)"].quantile(0.5)
q3 = data["平均工资(万元)"].quantile(0.75)
q4 = data["平均工资(万元)"].quantile(1)
print(f"四分位数:{q0:.2f}, {q1:.2f}, {q2:.2f}, {q3:.2f}, {q4:.2f}")
# 4. 偏度(skew:>0右偏,<0左偏,=0对称)
print("偏度:%f" % data["平均工资(万元)"].skew())
# 5. 峰度(kurt:>0尖峰,<0平峰,=0正态峰)
print("峰度:%f" % data["平均工资(万元)"].kurt())
运行结果:
众数:9.000000
中位数:9.000000
四分位数:3.00, 6.50, 9.00, 10.00, 16.00
偏度:0.569681
峰度:0.8401994.3.3 离中趋势分析
离中趋势反映数据的变异程度和分散程度,与集中趋势结合可全面描述数据特征,包括全距、方差、标准差、变异系数 等,pandas提供了便捷的计算方法。
实操案例:各行业平均工资的离中趋势计算
import pandas as pd
data = pd.read_csv('城镇单位就业人员平均工资与人数.csv', encoding='GBK')
data['平均工资(万元)'] = data['平均工资(元)'] // 10000
# 1. 全距(极差,最大值-最小值)
range_val = data["平均工资(万元)"].max() - data["平均工资(万元)"].min()
print("全距:%f" % range_val)
# 2. 方差(var)
print("方差:%f" % data["平均工资(万元)"].var())
# 3. 标准差(std,方差的平方根)
print("标准差:%f" % data["平均工资(万元)"].std())
# 4. 描述性统计(一键输出count/mean/std/min/四分位数/max)
print(data["平均工资(万元)"].describe())4.3.4 集中度与离中趋势可视化
通过频数分布图、箱型图可直观展示数据的集中与分散特征:
- 工资频数分布图(seaborn实现)
import seaborn as sns
nums = pd.cut(data["平均工资(万元)"], [0, 3, 10, 1000], labels=["低工资", "中工资", "高工资"])
nums = nums.value_counts()
result = pd.DataFrame({"工资等级": nums.index, "数量": nums.values})
sns.barplot(x="工资等级", y="数量", data=result)
plt.show()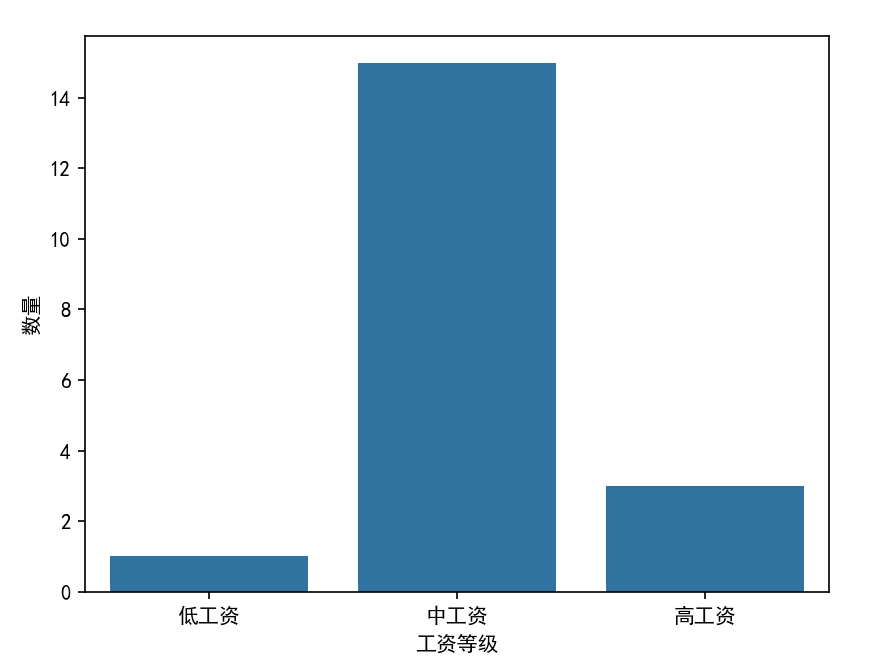
- 箱型图(展示四分位数、异常值)
data["平均工资(万元)"].plot.box() #plot.box : 绘制箱型图
plt.ylabel("平均工资(万元)")
plt.show()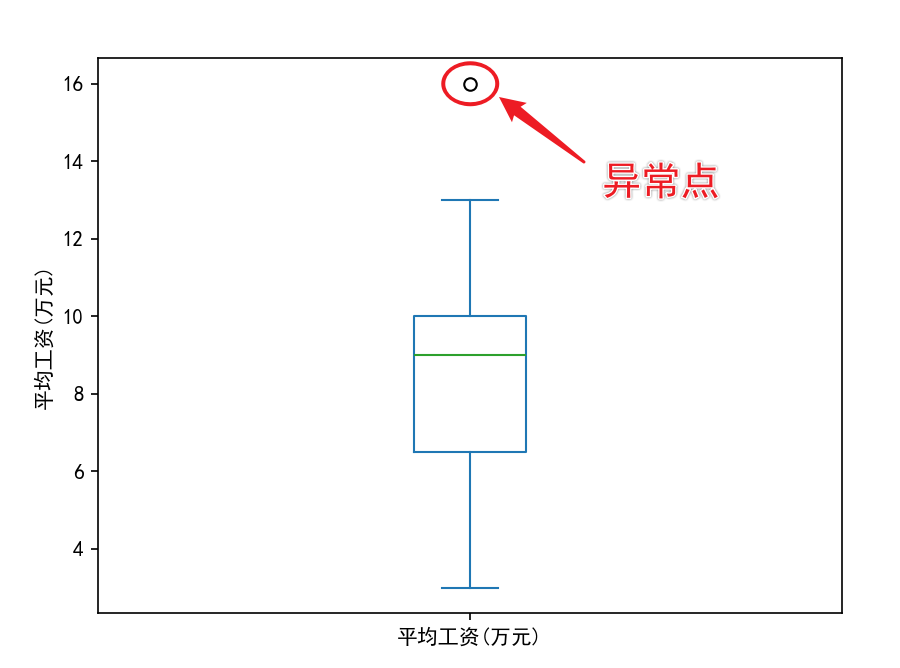
5 数据假设检验
前言
数据假设检验是对总体数据的参数或分布做出假设,利用样本数据的特征信息检验假设是否成立,从而判断样本与总体、样本与样本之间是否存在显著差异,是推断统计的核心。
本章重点讲解经济金融分析中最常用的正态分布检验和T值检验,核心工具为scipy.stats、statsmodels。
5.1 正态分布检验
正态分布是最常用的统计分布,许多统计方法(如T检验、方差分析)均要求数据符合正态分布,正态分布检验的核心是判断样本数据是否服从正态分布,常用方法为scipy.stats.normaltest(),结合直方图+密度曲线、QQ图可视化验证。
5.1.1 正态分布检验的统计方法
核心方法:scipy.stats.normaltest(x),返回统计量和p值,p值>0.05时,认为数据服从正态分布;p值≤0.05时,拒绝原假设,认为数据不服从正态分布。
实操案例:二手车价格的正态分布检验(整体数据vs抽样数据)
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import scipy.stats as ss
#中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
data = pd.read_csv('./data/car_train_0110.csv', sep=' ')
sample_data = data['price'].sample(frac=0.01, replace=True) # 1%抽样数据
# 整体数据正态检验
print(ss.normaltest(data['price']))
# 抽样数据正态检验
print(ss.normaltest(sample_data))
# 结果解读:p值=0.0,远小于0.05,说明二手车价格不服从正态分布'''5.1.2 正态分布的可视化验证
- 直方图+核密度曲线+标准正态密度曲线
sns.distplot(data['price'], kde=True, fit=ss.norm) # kde:核密度曲线,fit:标准正态曲线
plt.xlabel("二手车价格")
plt.ylabel("密度")
plt.show()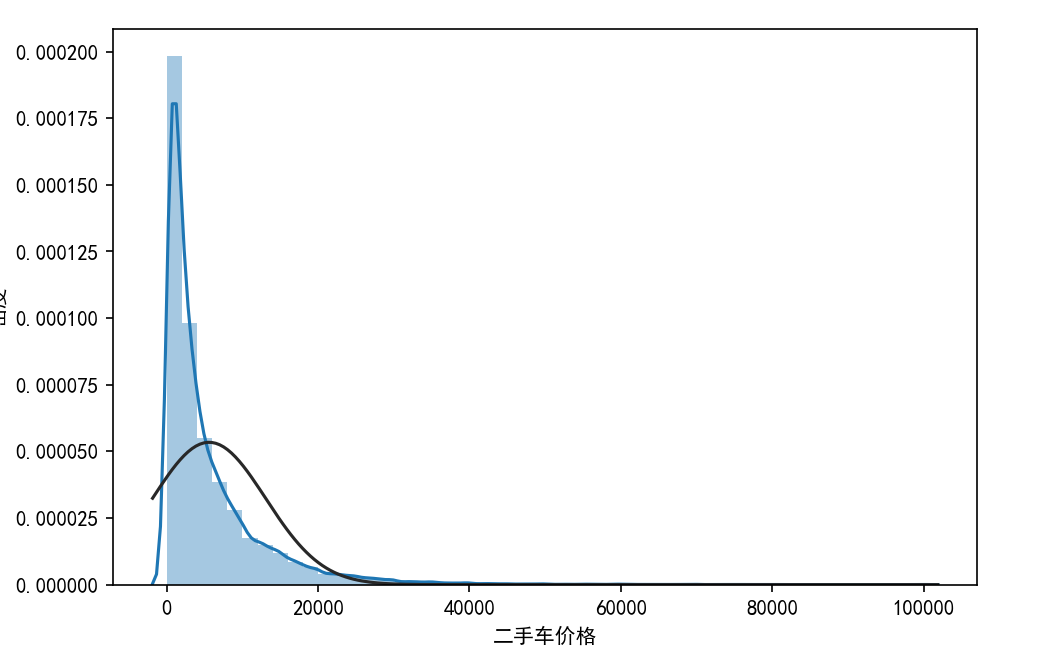
- QQ图(若数据服从正态分布,散点应沿对角线分布)
from scipy import stats
# 用 scipy 绘制 QQ 图(替代 statsmodels 的 qqplot)
fig, ax = plt.subplots(figsize=(6, 6))
stats.probplot(sample_data, dist="norm", plot=ax) # dist="norm" 表示正态分布
ax.set_title('QQ Plot (scipy version)')
plt.show()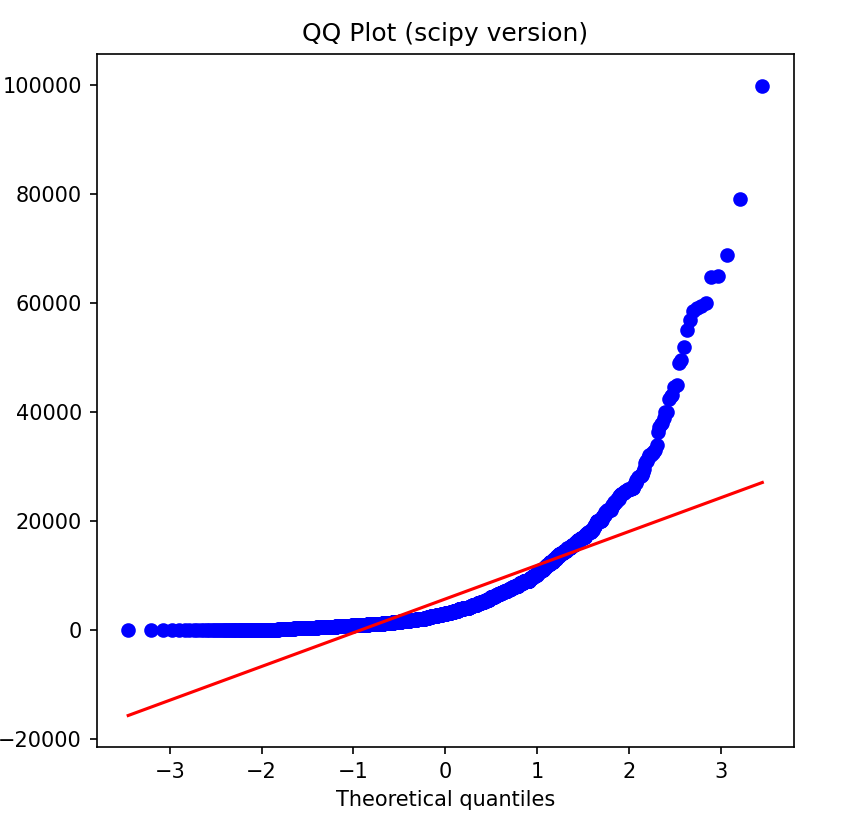
- 蓝色点线: 是抽样后 sample_data 的实际数据点(每个点对应数据的分位数),是 QQ 图的核心;
- 红色直线 :scipy 默认的理论正态分布参考线(也就是你想要的 “对角线”),用来对比数据是否贴合正态分布。
鉴别数据是否近似服从正态分布,只需要看QQ图上的点是否近似的在一条直线附近,图像是直线的说明数据近似服从正态分布,否则不服从正态分布,且该直线的斜率为标准差,截距为均值。
5.2 T值检验(单样本T检验)
T值检验适用于总体方差未知、数据服从/近似服从正态分布的场景,单样本T检验用于检验样本均值与已知总体均值是否存在显著差异,核心是判断样本是否来自某一特定总体。
5.2.1 核心方法与结果解读
- 核心方法:
scipy.stats.ttest_1samp(a, popmean),a为样本数据,popmean为已知总体均值; - 结果解读:返回统计量和p值,p值>0.05时,认为样本均值与总体均值无显著差异;p值≤0.05时,认为存在显著差异。
5.2.2 实操案例:二手车价格的单样本T检验
检验发动机功率>200、行驶15万公里、自动挡豪华轿车的二手车价格与8000元是否存在显著差异:
import pandas as pd
from scipy import stats as ss
#中文显示
data = pd.read_csv('./data/car_train_0110.csv', sep=' ')
# 筛选符合条件的样本
result = data[(data['bodyType'] == 0) & (data['power'] > 200) &
(data['gearbox'] == 1) & (data['kilometer'] == 15)]['price']
# 单样本T检验,总体均值为8000
t_result = ss.ttest_1samp(a=result, popmean=8000)
print(t_result)
# 结果解读:p值=0.8457>0.05,说明该类二手车价格与8000元无显著差异p 值的本质是:在 “原假设成立” 的前提下,出现当前样本结果(或更极端结果)的概率。
你的 p 值 = 0.8457,意思是:
“如果这类二手车的平均价格真的是 8000 元,那么抽到你当前这个样本(价格数据)的概率是 84.57%”。
这个概率很高,说明 “当前样本结果” 和 “原假设(8000 元)” 是兼容的 —— 没有足够的证据推翻 “平均价格 = 8000 元” 这个假设。
本章总结
前言
本章围绕经济金融数据分析的核心环节——数据统计分析,从数据类型识别出发,逐步讲解了数据抽样、分组、分布分析、集中度分析及假设检验的Python实现方法,核心知识点可总结为以下五点:
- 数据类型是分析的基础,需从存储计算、取值特点等维度识别,DataFrame是二维组合数据的核心结构;
- 数据抽样的核心是保证样本代表性,随机/等距/分层/整群抽样适用于不同数据场景,pandas是核心实现工具;
- 数据分组分为等距(cut)和不等距(qcut),可根据数据分布和业务需求选择,是数据分布分析的前提;
- 数据分布分析结合频次、时序、集中度,通过matplotlib/seaborn实现可视化,是挖掘数据规律的核心;
- 数据假设检验是推断统计的基础,正态分布检验是前提,T值检验适用于样本均值与总体均值的差异检验,核心关注p值的解读。
所有方法均结合二手车价格、就业人口、行业工资等经济金融实际场景展开,实操性强,需熟练掌握pandas、matplotlib、scipy的核心用法,做到“知其然,更知其所以然”,为后续复杂的经济金融数据分析与决策奠定基础。