
1.1 数据获取
前言
- 专业数据库
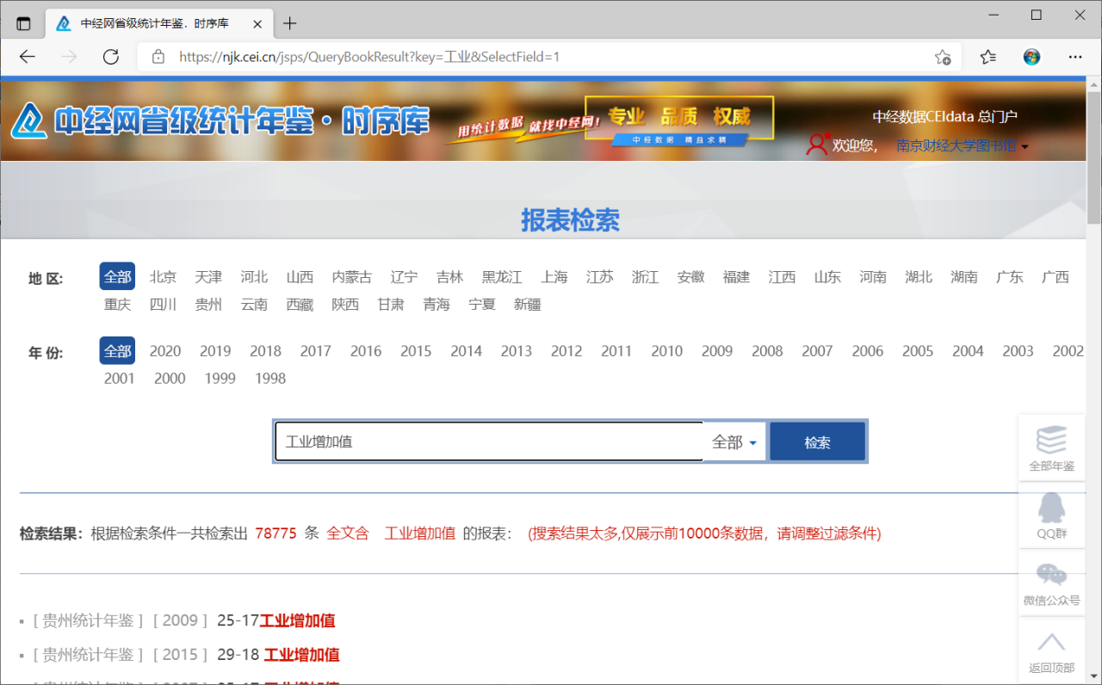
可以直接利用专业数据库的数据下载功能, 很多专业数据库提供的数据并没有直接的下载功能:
- 1.选择所需数据并右击复制
- 1.到WPS的“表格”(或者Excel)中,直接粘贴
- 1.删除和调整无用行列,形成规范可用的数据表格文件
- 互联网数据网站
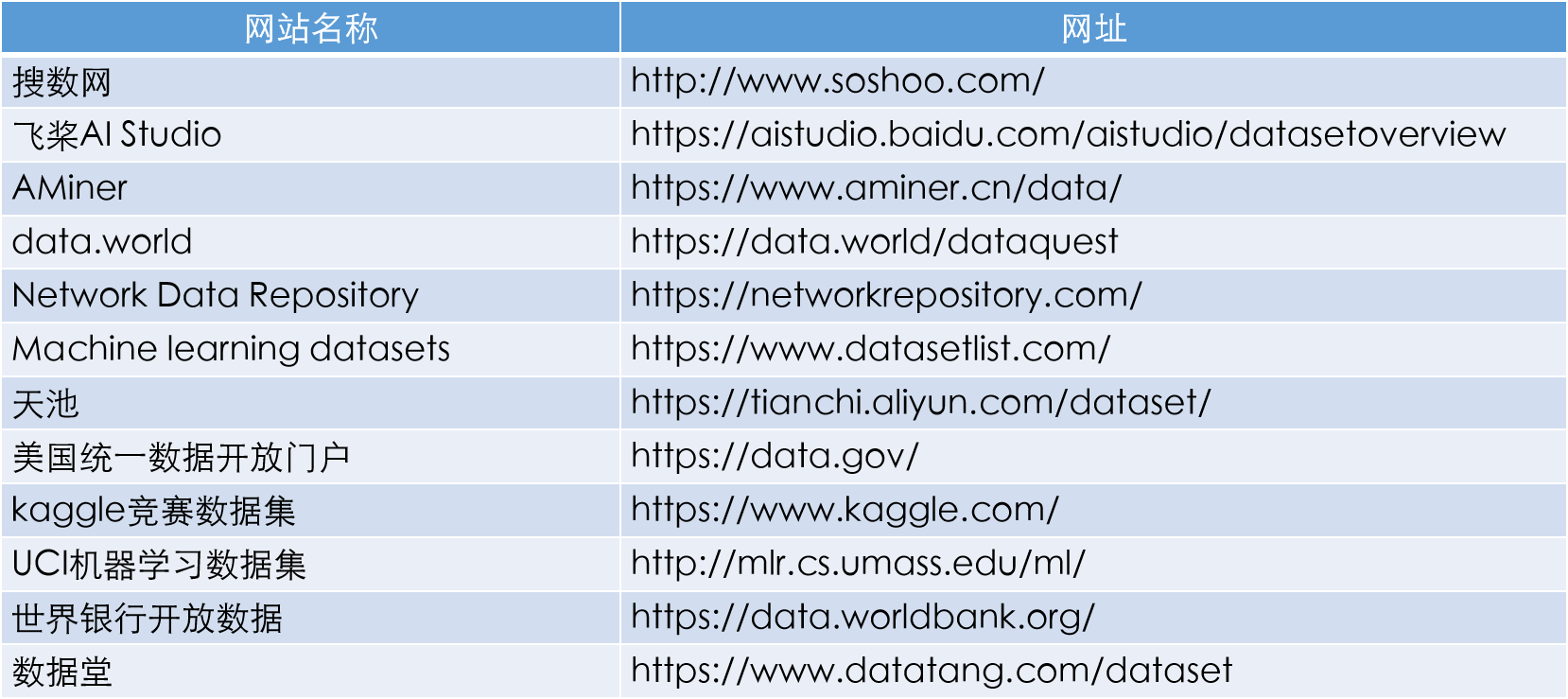
注意:本课程的数据在学习通的资料中,请自行下载(文件较大,请提前下载)
1.2 数据读取
1.2.1 文件读取
前言
准备工作
上学期,我们使用JupyterNote进行教学,考虑到文本较大,这学期我们使用PyCharmIdea进行编程
- 创建一个空的Python项目
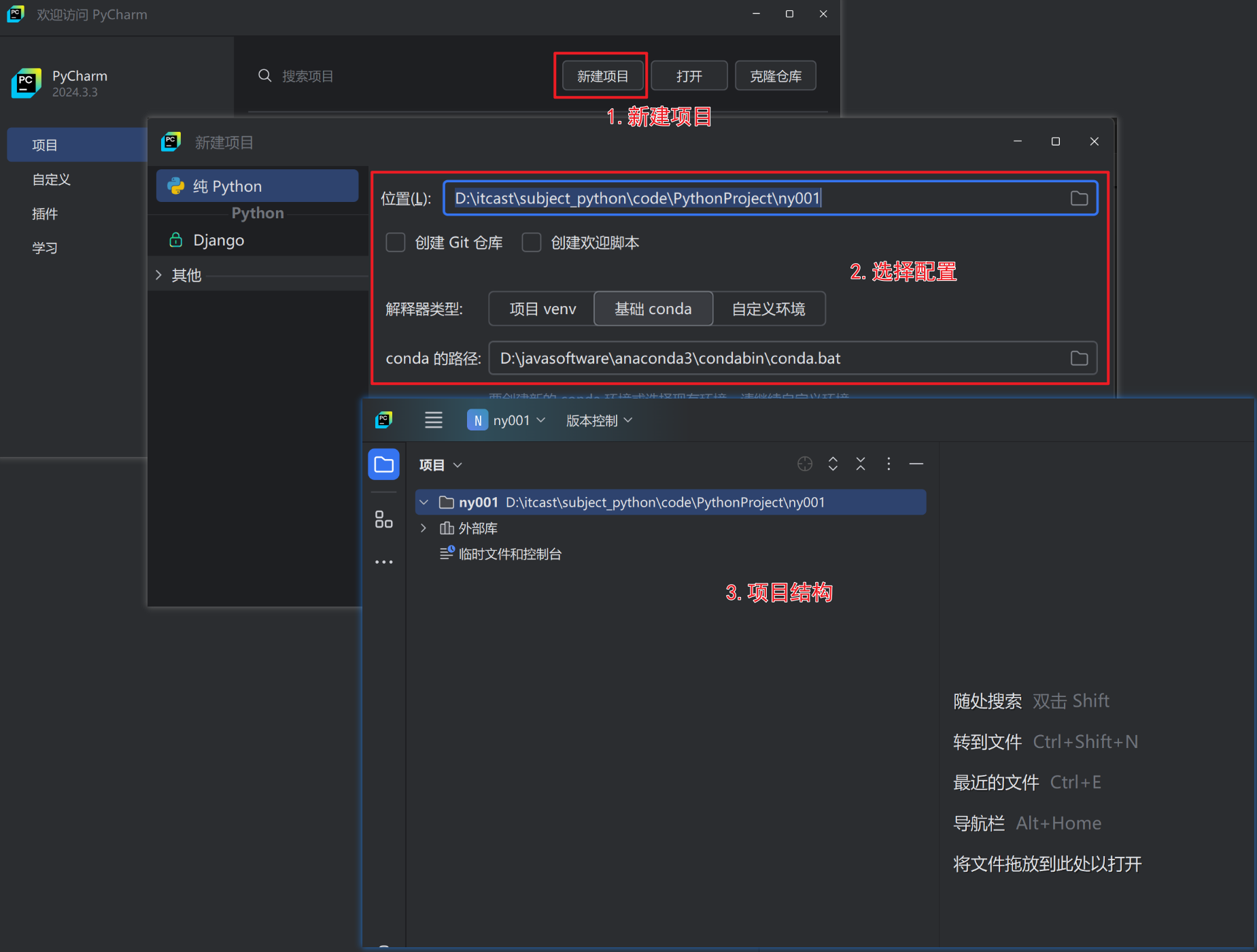
- 创建一个空文件
p1-1.py
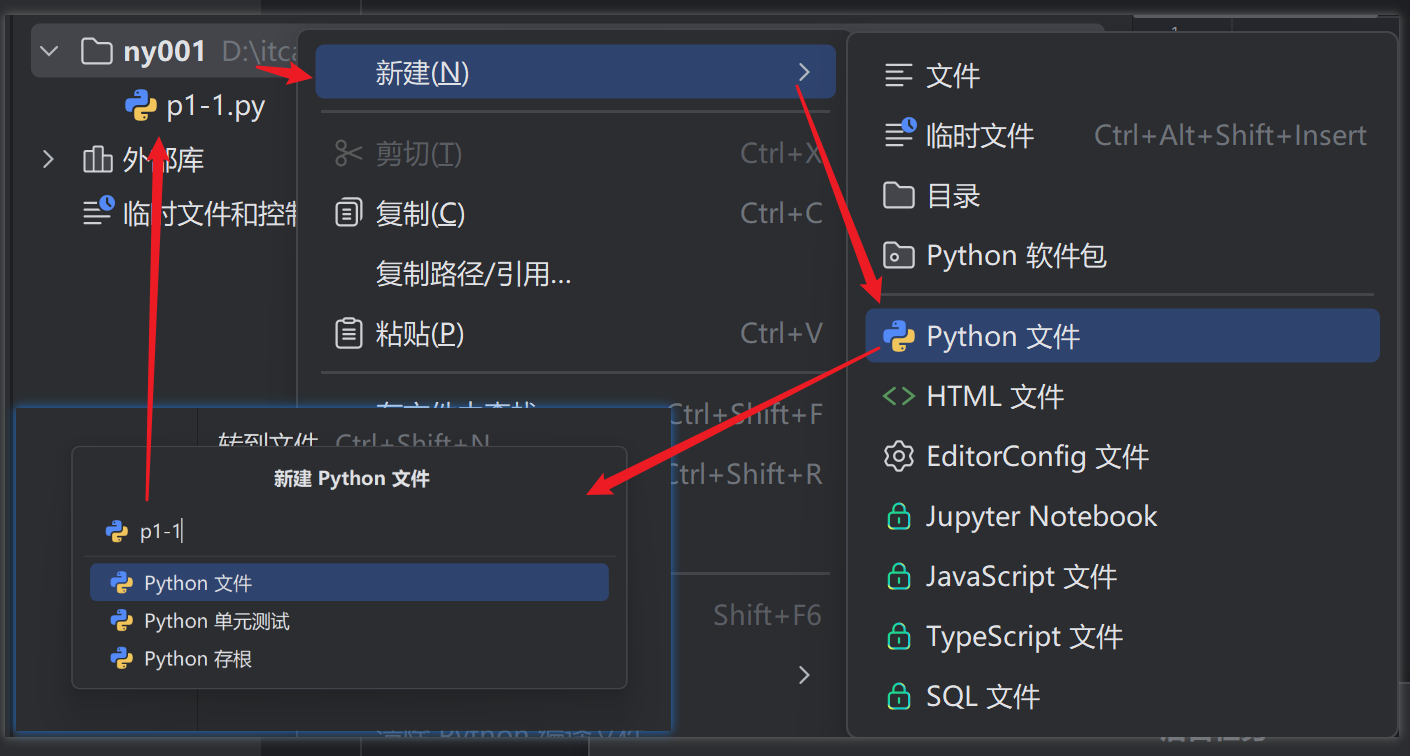
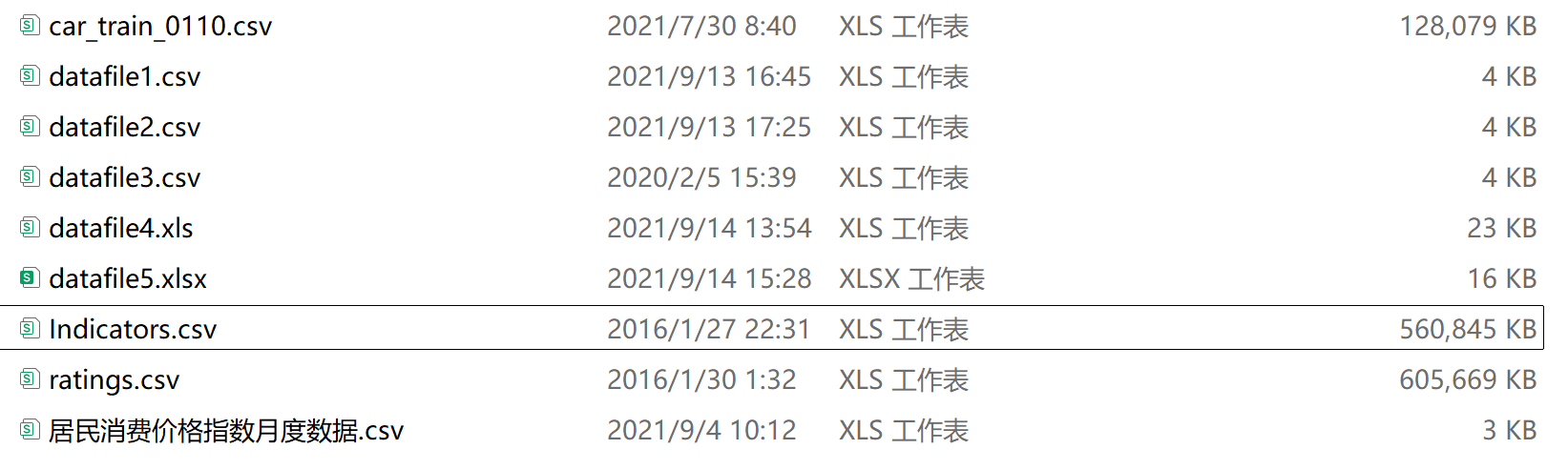
- 接着将资料文件复制到项目的
data目录下
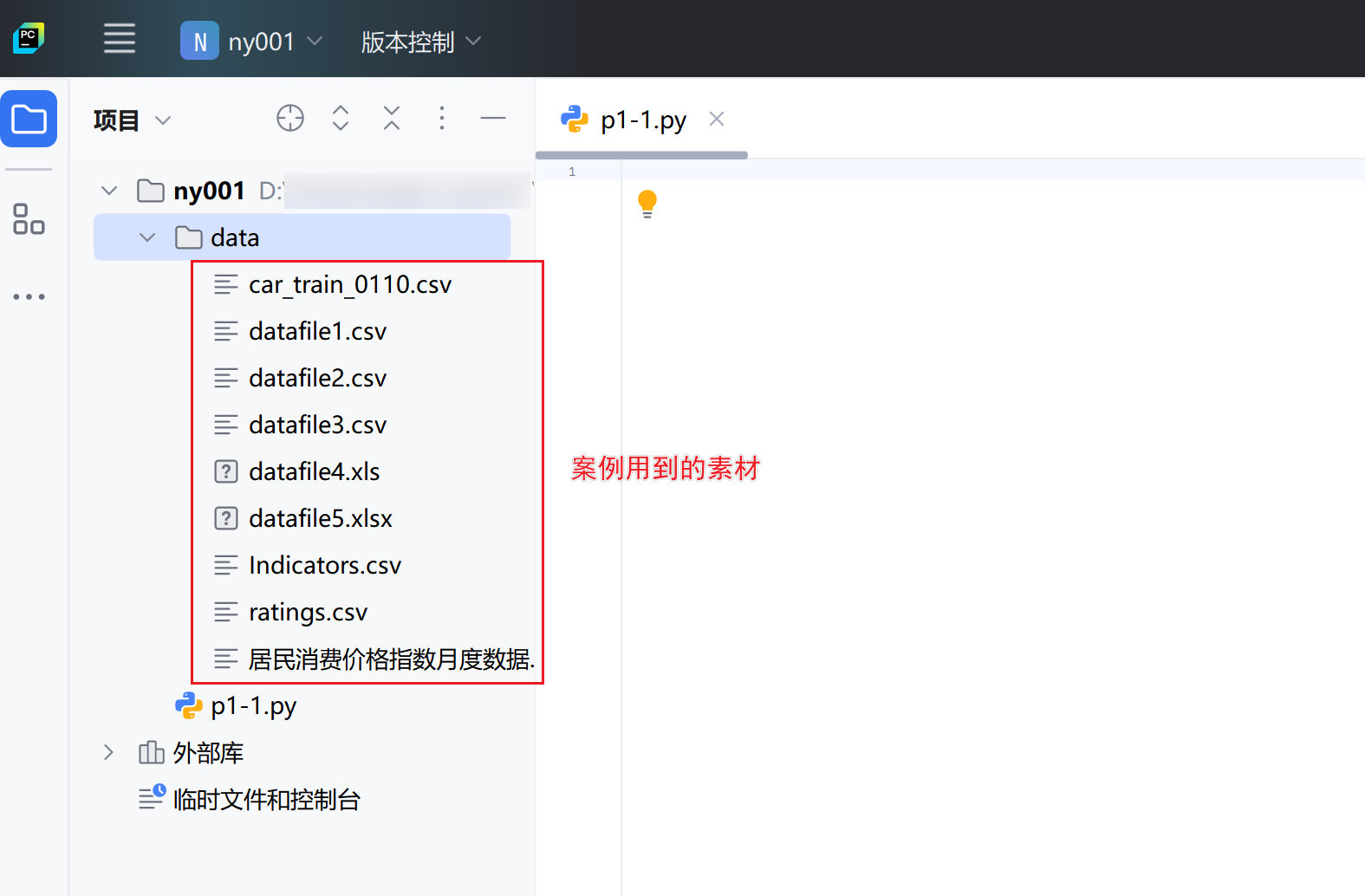
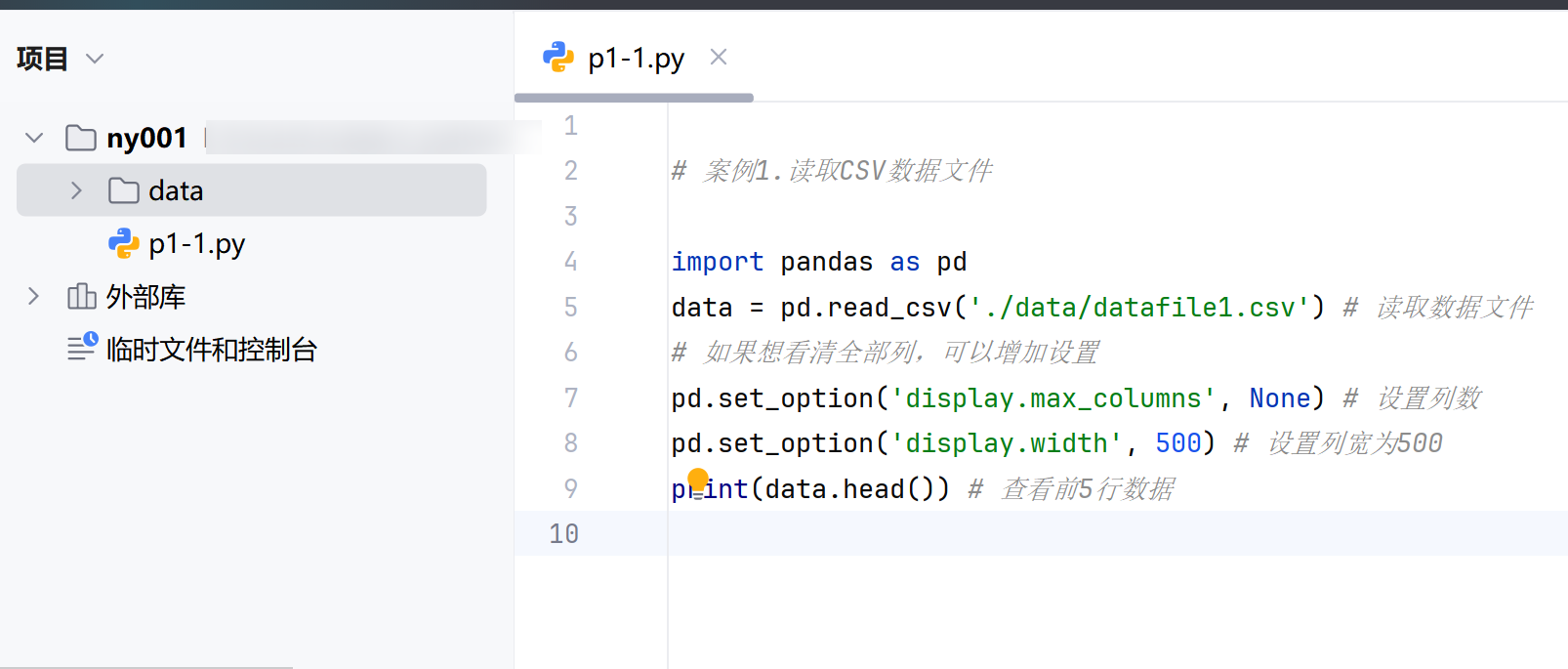
案例
1.读取CSV数据文件
D:\javasoftware\anaconda3\python.exe D:\itcast\subject_python\code\PythonProject\ny001\p1-1.py
2018/12/31 0.17 -- --.1 ... 7,024,257 6,857,100 2,347,972 4.13
0 2017/12/31 0.12 -- -- ... 6,848,235 6,682,483 2,273,404 3
1 2016/12/31 0.28 -- -- ... 7,287,902 7,099,881 1,654,760 4.43
2 2015/12/31 -1.64 -- -- ... 317,412 280,977 5,657 -178.71
3 2014/12/31 -0.29 -- -- ... 286,873 251,297 100,392 -15.55
4 2013/12/31 0.01 -- -- ... 263,287 252,783 117,375 0.46
[5 rows x 20 columns]
设置Option后,可以显示更多的列
D:\javasoftware\anaconda3\python.exe D:\itcast\subject_python\code\PythonProject\ny001\p1-1.py
2018/12/31 0.17 -- --.1 5,862,288 418,206 169,036 8,246 5,398 174,434 95,502 84,610 861,405 874,638 9,375,400 8,491,850 7,024,257 6,857,100 2,347,972 4.13
0 2017/12/31 0.12 -- -- 5,536,375 470,995 147,169 3,297 3,098 150,268 67,001 47,456 281,123 109,984 9,124,783 8,230,474 6,848,235 6,682,483 2,273,404 3
1 2016/12/31 0.28 -- -- 5,065,944 440,535 185,223 37,066 5,183 190,406 128,754 -43,202 118,241 93,215 8,945,604 7,986,995 7,287,902 7,099,881 1,654,760 4.43
2 2015/12/31 -1.64 -- -- 192,928 -5,135 -99,922 1,270 2,265 -97,657 -94,762 -96,704 11,722 12,022 324,539 57,441 317,412 280,977 5,657 -178.71
3 2014/12/31 -0.29 -- -- 262,640 19,971 -19,293 2,356 1,680 -17,614 -16,932 -19,214 8,764 -4,738 393,385 50,602 286,873 251,297 100,392 -15.55
4 2013/12/31 0.01 -- -- 305,726 32,270 -569 1,193 3,036 2,467 540 -2,183 35,536 -9,648 389,446 55,045 263,287 252,783 117,375 0.462.读取不使用逗号分隔符的数据文件
对于一些分隔符异常的数据文件需要设置分隔符才能正确读取, 如下图👇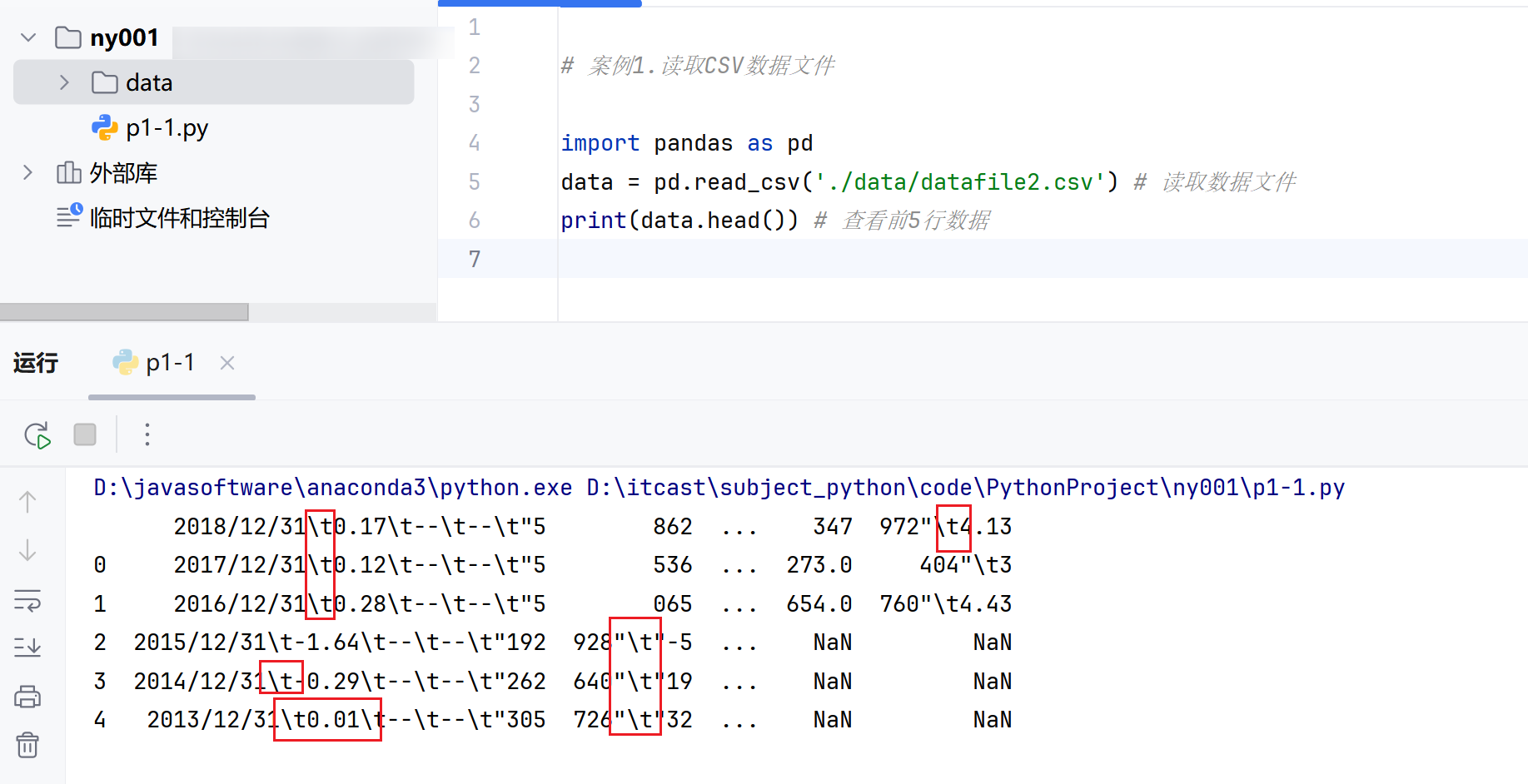
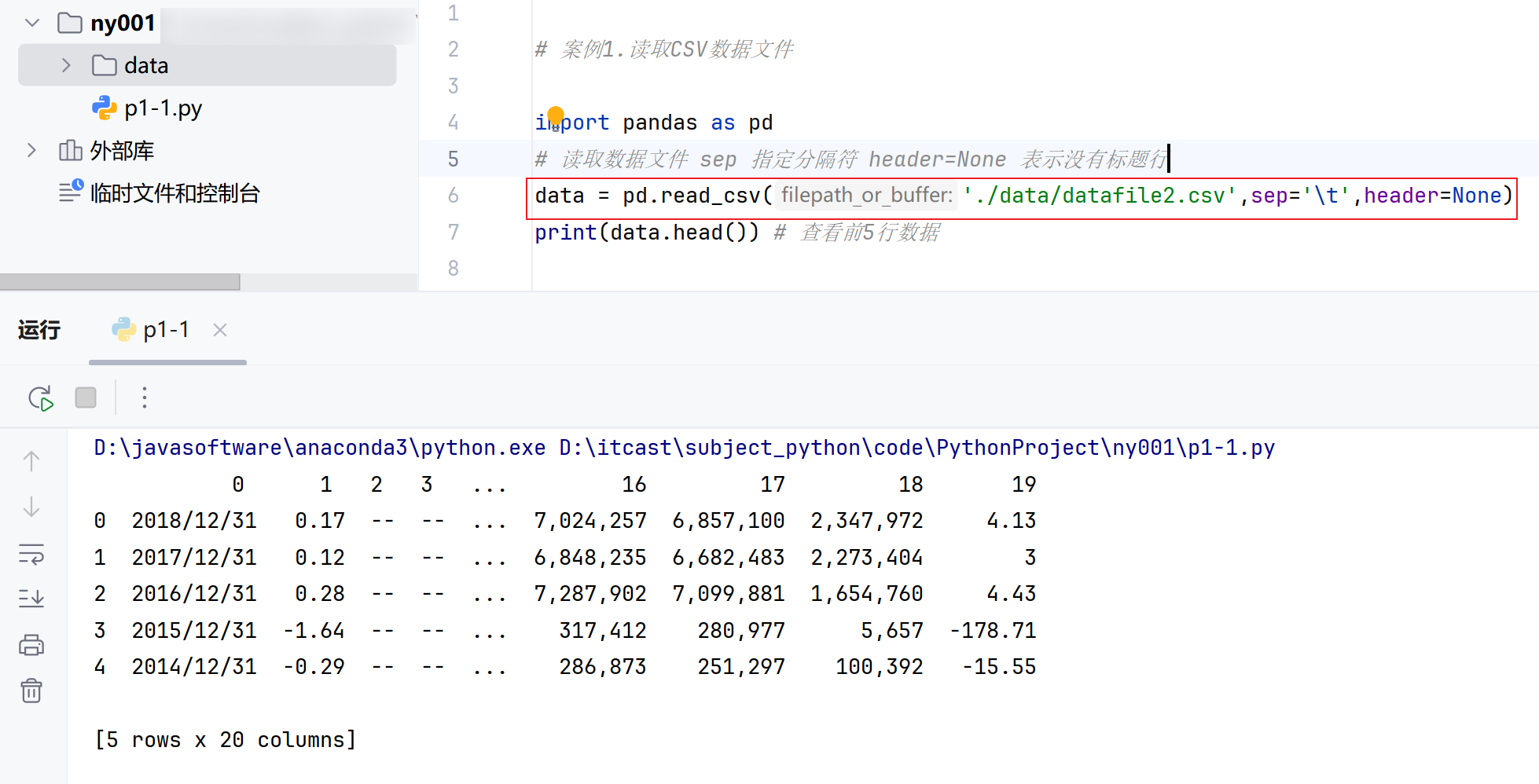
3.读取含有中文字符的数据文件
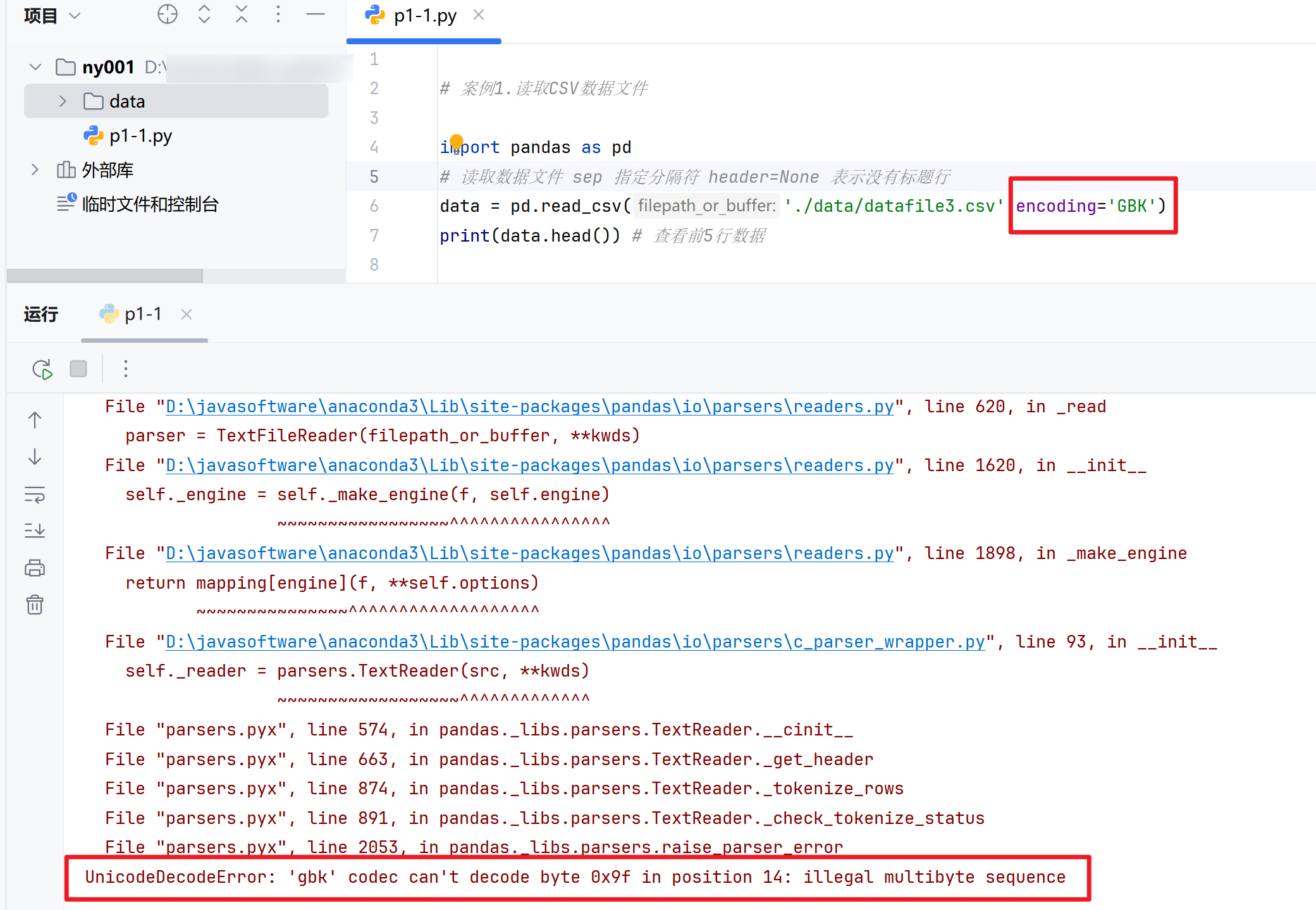
上图读取中文发生了乱码,因为文本本身是UTF-8编码,而读取采用GBK编码,所以出现了乱码。
为什么会出现乱码?
UTF-8编码,一个汉字占3个字节,而GBK编码,一个汉字占2个字节。因此,在读取UTF-8编码的文件时,如果采用GBK编码去读取,就会出现乱码。
import pandas as pd
# 读取数据文件 sep 指定分隔符 header=None 表示没有标题行
data = pd.read_csv('./data/datafile3.csv',encoding='Utf-8')
print(data.head()) # 查看前5行数据运行结果是👇
报告日期 基本每股收益(元) 每股净资产(元) ... 流动负债(万元) 股东权益不含少数股东权益(万元) 净资产收益率加权(%)
0 2018-12-31 0.17 -- ... 6,857,100 2,347,972 4.13
1 2017-12-31 0.12 -- ... 6,682,483 2,273,404 3.00
2 2016-12-31 0.28 -- ... 7,099,881 1,654,760 4.43
3 2015-12-31 -1.64 -- ... 280,977 5,657 -178.71
4 2014-12-31 -0.29 -- ... 251,297 100,392 -15.55
[5 rows x 20 columns]
上面的我们一般称为文本文件的读取,接下来我们来读取Excel数据文件(xls和xlsx两种常见的格式),也就是常说的非文本文件
4.读取Excel数据文件
- 读取xls和xlsx格式的Excel数据文件,使用read_excel()函数
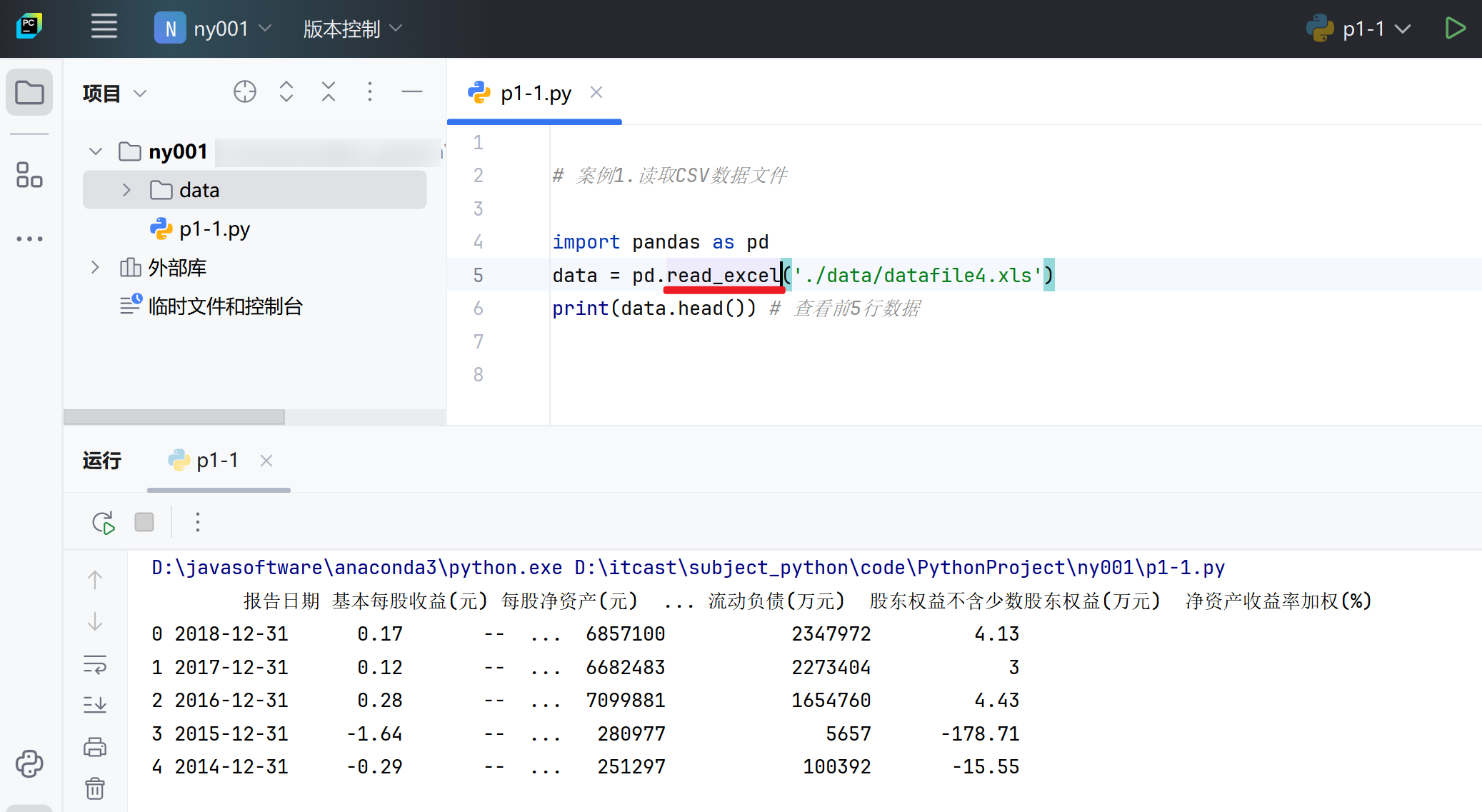
- 读取xlsx格式的Excel数据文件,需要安装openpyxl库
import pandas as pd
# data = pd.read_excel('./data/datafile4.xls')
# 使用openpyxl进行读取,默认使用xlrd 区别:xlrd不支持xlsx格式文件
data = pd.read_excel('./data/datafile5.xlsx', engine='openpyxl',sheet_name='2') #sheet_name='2' 表示读取第2个sheet
print(data.head()) # 查看前5行数注意: 在实际操作中,有时也可以通过WPS或者Excel先行将这些Excel格式数据文件转换为CSV数据文件,再使用一般的文本文件读取方法来处理
1.2.2 动态生成数据文件
前言
通过代码直接生成数据集合, 经常应用于仿真分析和测试用例.
读取案例
1.设定列名称并生成记录
# 动态生成数据文件
import pandas as pd
# 创建数据列 company,city 2列
columns=['company','city']
# 创建数据格
data=pd.DataFrame(columns=columns)
# 添加2行数据
data.loc[0]=['IBM','北京']
data.loc[1]=['Google','上海']
# 打印数据
print(data)
# company city
# 0 IBM 北京
# 1 Google 上海
#还可以这样创建
data=pd.DataFrame({'company':['IBM','Google'],'city':['北京','上海']})
print(data)
#还可以这样创建
cols=['company','city']
data=pd.DataFrame([['IBM','北京'],['Google','上海']],columns=cols)
print(data)
#还可以这样创建
data=pd.DataFrame()
data['company']=['IBM','Google']
data['city']=['北京','上海']
print(data)输出结果👇
company city
0 IBM 北京
1 Google 上海3.根据现有的DataFrame来构建新的DataFrame
通过这种方法可以快速得到结构一样的新数据结构
import pandas as pd
#还可以这样创建
data=pd.DataFrame()
data['id']=[1,2]
data['company']=['IBM','Google']
data['city']=['北京','上海']
print(data)
#利用原有的DataFrame创建
data2=pd.DataFrame(columns=data.columns)
data2['id']=[1,2]
data2['company']=['HUAWEI','Tencent']
data2['city']=['深圳','深圳']
print(data2)1.2.3 大规模数据读取与存储
前言
对于大规模的数据文件,直接采取传统的数据文件读取方法会导致很明显的性能问题,甚至会因此而读取失败。
案例
1.一次性读取较大规模的数据文件
import pandas as pd
from time import time
start_time = time()
data=pd.read_csv('ratings.csv')
end_time = time()
# 时间间隔的获取是通过time模块的time函数
# 该数值可能会因为电脑软硬件性能的不同而有差异
print('运行时间:%s 秒' % (end_time - start_time))
print(data.info()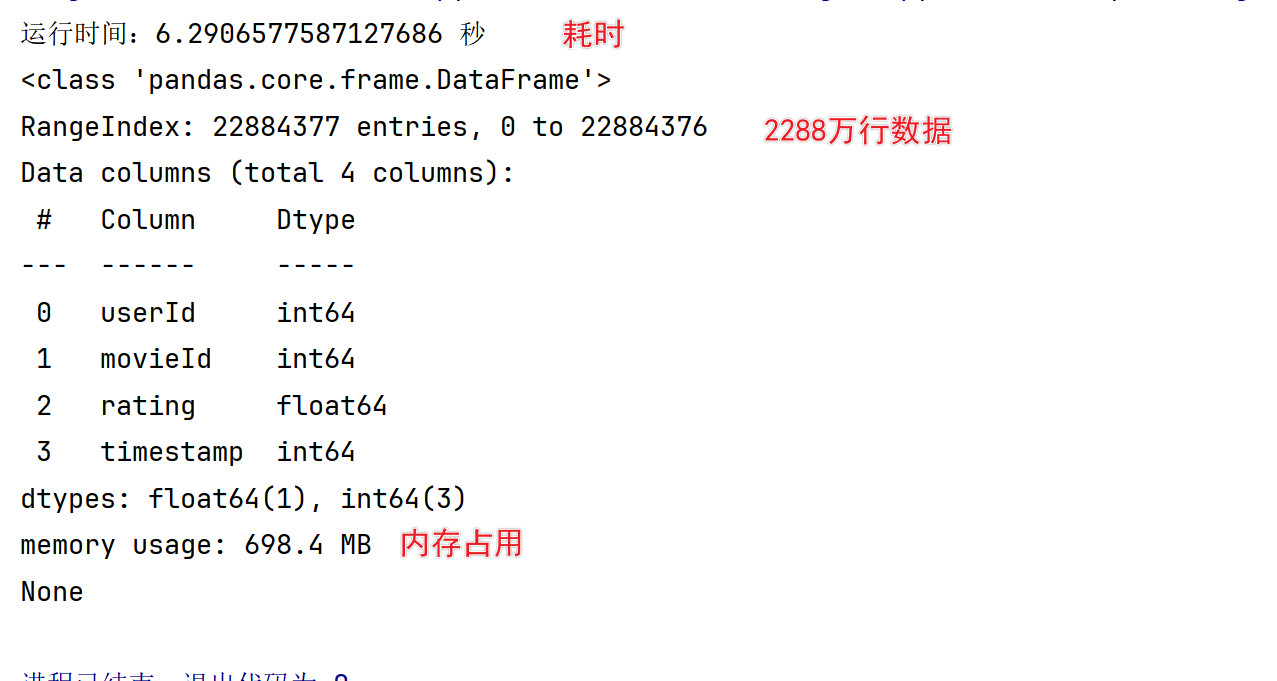
显示每个数据列的类型,可以发现很多数据类型精度太大而存在浪费
2.读取较大规模数据文件部分行记录
使用部分读取方式,指定每次读取的行数
import pandas as pd
from time import time
start_time = time()
data=pd.read_csv('ratings.csv',nrows=5) # 指定读取5行
end_time = time()
print('运行时间:%s 秒' % (end_time - start_time))
print(data.info())3.分块读取较大规模数据文件
read_csv方法通过设置chunksize可以实现每次读取的行数
特点:
- 一次读取一部分数据,占用内存较小
- 可以处理完后再读取再处理
- 实现对大规模数据文件的有效处理
import pandas as pd
from time import time
start_time = time()
reader=pd.read_csv('ratings.csv',chunksize=100000) # 指定每次读取100000行
data=[]
for chunk in reader:# 迭代读取
data.append(chunk) # 将每次读取的行数据添加到data中
data=pd.concat(data) # 将data中的数据连接起来
end_time = time()
print('运行时间:%s 秒' % (end_time - start_time))
print(data.head())4.读取较大规模数据文件部分列记录
要先确定数据文件中的列名称,在read_csv方法的usecols属性中通过列表来选择所需的列
import pandas as pd
from time import time
start_time = time()
data=pd.read_csv('ratings.csv',usecols=['userId','rating']) # 指定读取2列
end_time = time()
print('运行时间:%s 秒' % (end_time - start_time))
print(data)存储案例
1.查看读取数据的基本情况
DataFrame的info方法可以直接返回读取数据的基本信息
import pandas as pd
from time import time
start_time = time()
data=pd.read_csv('ratings.csv')
end_time = time()
# 时间间隔的获取是通过time模块的time函数
# 该数值可能会因为电脑软硬件性能的不同而有差异
print('运行时间:%s 秒' % (end_time - start_time))
print(data.info()) # 查看数据集的属性信息,包含内存使用情况
print(data.describe()) # 查看数据集的描述信息 最大值、最小值、平均值、中位数、标准差、25%、50%、75%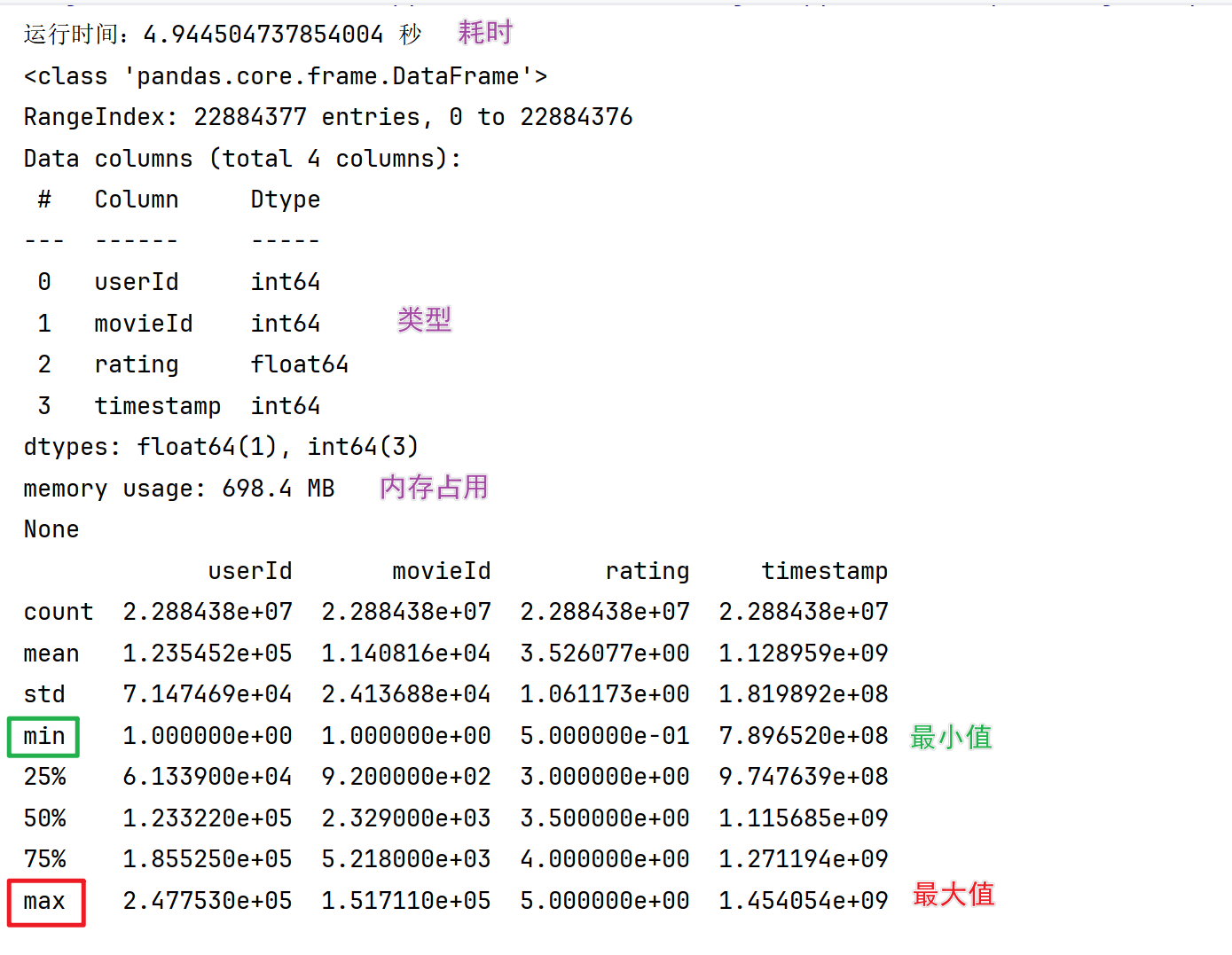
2.通过数据类型精度转换来降低数据内存占用
先通过观察列的取值来判断合适的数据类型
#1.一次性读取较大规模的数据文件
import pandas as pd
from time import time
start_time = time()
data=pd.read_csv('ratings.csv')
data['userId']=data['userId'].astype('int32')
data['movieId']=data['movieId'].astype('int32')
data['rating']=data['rating'].astype('int8')
data['timestamp']=data['timestamp'].astype('int32')
end_time = time()
# 时间间隔的获取是通过time模块的time函数
# 该数值可能会因为电脑软硬件性能的不同而有差异
print('运行时间:%s 秒' % (end_time - start_time))
print(data.info()) # 查看数据集的属性信息,包含内存使用情况
print(data.describe()) # 查看数据集的描述信息 最大值、最小值、平均值、中位数、标准差、25%、50%、75%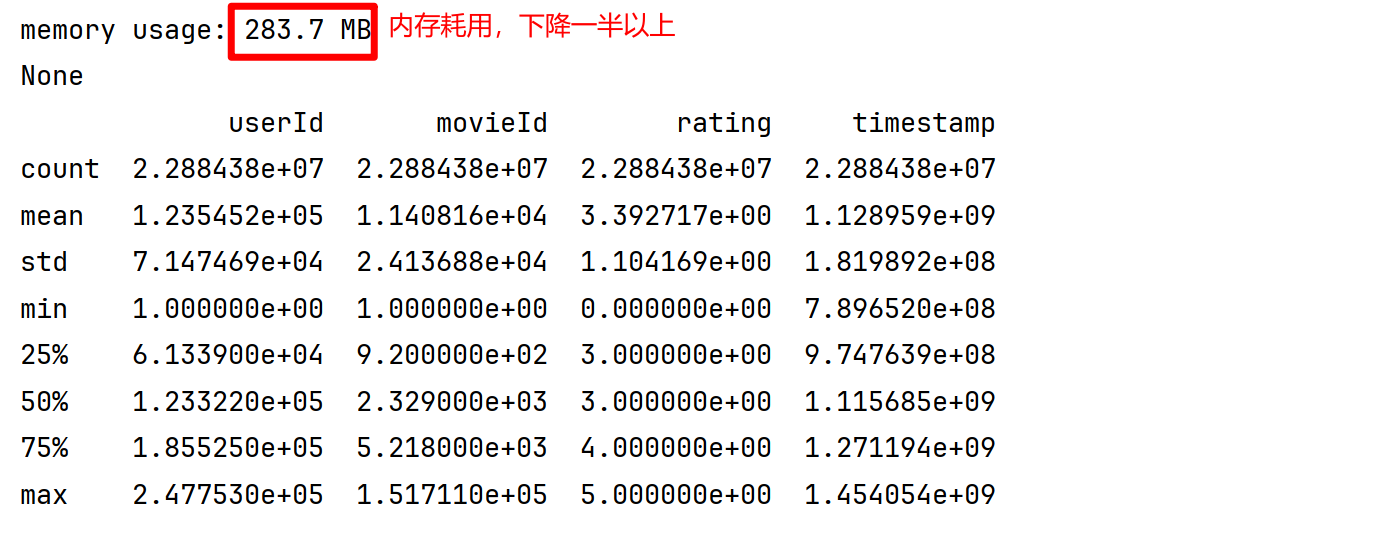
- describe方法可以直接返回所有数据列的数值分布情况,比如对于userId,最大值约25万,最小值为1
- 通过astype方法将几个精度过高的数据类型转换为低精度,从而减少不必要的内存占用,此时的内存占用只有284MB,不到最初的一半
3.通过转换字符串类型来降低数据内存占用
字符串占用的空间要远远大于整数和浮点数类型
默认字符串类型显示为object
通过转换为类别(categoricals)类型来提高存储效率
- 自动将存在重复值的字符数据映射为存储消耗更小的整数
- 对于数据使用没有任何影响,但是极大降低存储消耗
import pandas as pd
from time import time
start_time = time()
data=pd.read_csv('Indicators.csv')
data['CountryName']=data['CountryName'].astype('category')
data['CountryCode']=data['CountryCode'].astype('category')
data['IndicatorName']=data['IndicatorName'].astype('category')
data['IndicatorCode']=data['IndicatorCode'].astype('category')
end_time = time()
# 时间间隔的获取是通过time模块的time函数
# 该数值可能会因为电脑软硬件性能的不同而有差异
print('运行时间:%s 秒' % (end_time - start_time))
print(data.info()) # 查看数据集的属性信息,包含内存使用情况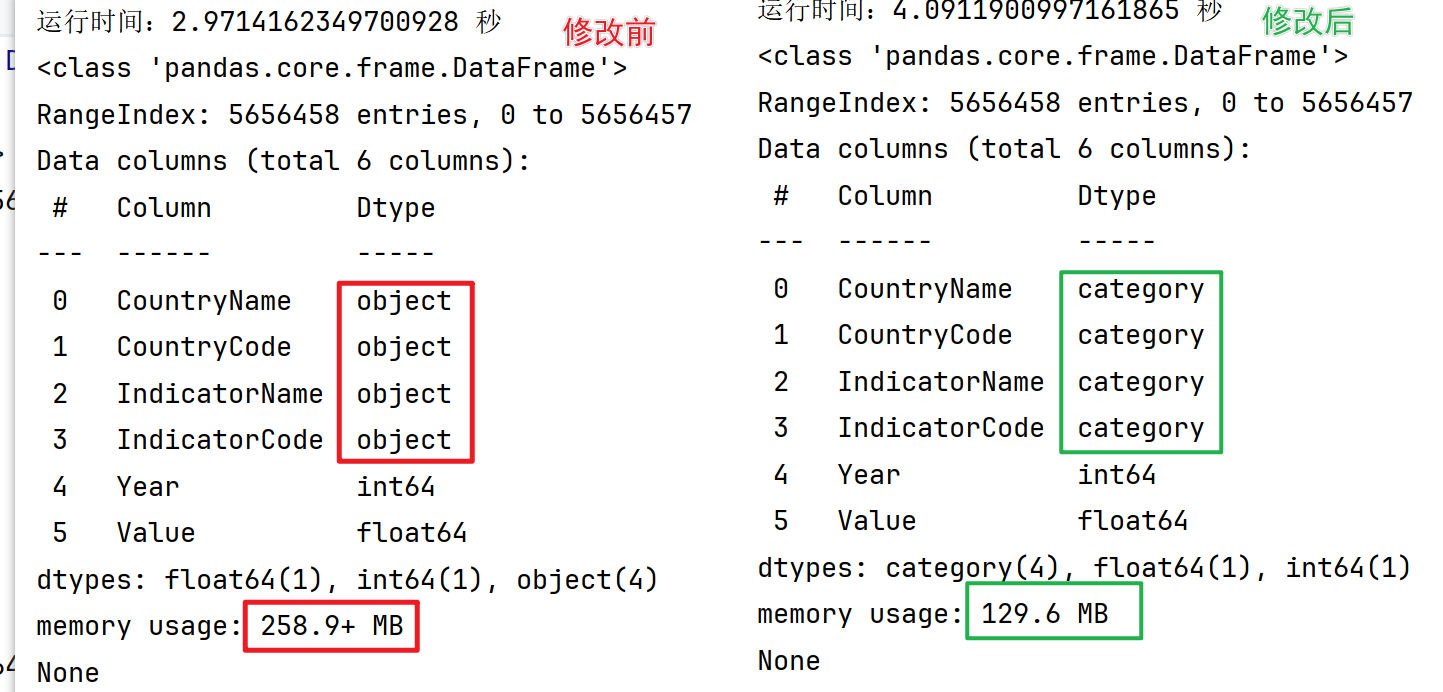
可以将字符串转换为类别类型
data['CountryName'].astype('category')
转换后只有不到130MB,几乎又少了一半
1.1 数据预处理
1.3.1 定位缺失数据
前言
获取的原始数据往往会因为各种原因存在着很多错误数据:👇
- 缺失数据
- 数据类型错误
- 数据表达不符合计算要求
准确的数据分析往往依赖于有效的数据预处理
NaN代表该值缺失,NaN意思是“Not a Number(不是一个数值),缺失值也被称为“空值”
import pandas as pd
# 数据读取
data=pd.read_csv('data/car_train_0110.csv',sep=' ')
# 设置最大列数
pd.set_option('display.max_columns', None)
# 设置宽度为500
pd.set_option('display.width', 500)
# 1.查看(定位)数据中缺失值
# print(data.isnull())
# 查看数据中是否有缺失值 返回False表示没有缺失值
# isnull方法返回了和原始的DataFrame一样大小的矩阵,矩阵中的元素都是布尔值,True表示有缺失值,False表示没有缺失值
# 2.查看哪些列有缺失值
# 数据太多了,不方便看,可以使用any方法进行筛选,
# 如果参数为1,表示列方向进行筛选,返回值为Series,
# 如果参数为0,表示行方向进行筛选,返回值为Series
# print(data.isnull().any(axis=1))
# 3.查看缺失值所在的行列位置
result=data.isnull()
print(result)
# for index in result.index:
# for column in result.columns:
# if result.loc[index,column]==True:
# print(index,column)
# 这段代码明确给出了缺失值所在的行和列位置,但是非常耗时
#iloc方法和loc方法一样,都是用于数据定位
# for indexs in result.index:
# for i in range(len(result.columns)):
# if result.iloc[indexs,i]==True:
# print(indexs,result.columns[i])1.3.2 处理缺失数据
前言
1. 删除缺失值
如果数据量比较大,可以考虑删除缺失值,但是删除缺失值会导致数据的丢失,所以需要谨慎处理
import pandas as pd
# 数据读取
data=pd.read_csv('data/car_train_0110.csv',sep=' ')
print("处理前:",data.shape) #shape属性查看数据集的行数和列数 (250000, 40)
# axis=0 表示行,axis=1 表示列 inplace=True 表示直接修改原数据
data.dropna(axis=0,inplace=True) # 删除有缺失值的行
print("处理后:",data.shape)
# 结果:
# 处理前: (250000, 40)
# 处理后: (180251, 40)2. 填充缺失值
如果数据量比较小,可以考虑填充缺失值,但是填充缺失值会导致数据的偏差,所以需要谨慎处理
import pandas as pd
# 数据读取
data=pd.read_csv('data/car_train_0110.csv',sep=' ')
print("处理前:",data.shape) #shape属性查看数据集的行数和列数 (250000, 40)
#填写固定值
# data.fillna(0,inplace=True)
# 填写最可能到值,如median 中位数,mean 平均值,mode 众数
data.fillna(data.median(),inplace=True)
print("处理后:",data.shape)
# 结果:
# 处理前: (250000, 40)
# 处理后: (250000, 40)1.3.3 数据类型转换
前言
1.数据转置
数据转置可以将数据的行列互换,从而可以方便的查看数据的结构。
接下来以居民消费价格指数月度数据.csv为例,查看数据的结构。
import pandas as pd
data= pd.read_csv('data/居民消费价格指数月度数据.csv',encoding='GBK')
data.set_index('指标',inplace=True) # 设置指标为索引, inplace=True表示修改原数据
print(data.head())
# 输出结果:
# 2021年7月 2021年6月 ... 2018年10月 2018年9月
# 指标 ...
# 居民消费价格指数(上年同月=100) 101.0 101.1 ... 102.5 102.5
# 食品烟酒类居民消费价格指数(上年同月=100) 98.2 99.6 ... 102.9 103.0
# 衣着类居民消费价格指数(上年同月=100) 100.4 100.4 ... 101.4 101.2
# 居住类居民消费价格指数(上年同月=100) 101.1 100.9 ... 102.5 102.6
# 生活用品及服务类居民消费价格指数(上年同月=100) 100.3 100.3 ... 101.5 101.6
# 接下来进行转置
data2=pd.DataFrame(data.values.T,index=data.columns,columns=data.index) # 转置
print(data2)
# 指标 居民消费价格指数(上年同月=100) ... 其他用品和服务类居民消费价格指数(上年同月=100)
# 2021年7月 101.0 ... 98.7
# 2021年6月 101.1 ... 99.1
# 2021年5月 101.3 ... 99.1
# 2021年4月 100.9 ... 98.7
# 2021年3月 100.4 ... 98.5
# 2021年2月 99.8 ... 99.2
# 2021年1月 99.7 ... 99.1
# 2020年12月 100.2 ... 102.2
# 2020年11月 99.5 ... 102.5
# 2020年10月 100.5 ... 102.4
# 2020年9月 101.7 ... 104.3
# 2020年8月 102.4 ... 106.1
# 2020年7月 102.7 ... 105.1
# 2020年6月 102.5 ... 105.1
# 2020年5月 102.4 ... 105.32.粒度转换
粒度转换是将数据的粒度进行转换,例如将月度数据转换为季度数据,将季度数据转换为年度数据等。
接下来以二手车交易记录数据集car_train_0110.csv为例,将售卖时间转为月份信息
import pandas as pd
from datetime import datetime
data=pd.read_csv('data/car_train_0110.csv', sep=' ')
# print(data)
# 只显示SaleID,name,creatDate三列
print(data[['SaleID', 'name', 'creatDate']])
# 数据如下:可以发现creatDate是数字,需要先转成字符串,然后格式化时间类型
# SaleID name creatDate
# 0 134890 734 20160316
# 1 306648 196973 20160311
# 2 340675 25347 20160323
# 3 57332 5382 20160330
# 4 265235 173174 20160307
data['creatDate']=data['creatDate'].astype('string');
# strptime是时间格式转换函数, %Y%m%d是格式
# data['creatDate']=data['creatDate'].apply(datetime.strptime, args=['%Y%m%d']).dt.month
# print(data[['SaleID', 'name', 'creatDate']])
# SaleID name creatDate
# 0 134890 734 3
# 1 306648 196973 3
# 2 340675 25347 3
# 3 57332 5382 3
# 4 265235 173174 3
# 也可以使用季度quarter
data['creatDate']=data['creatDate'].apply(datetime.strptime, args=['%Y%m%d']).dt.quarter
print(data[['SaleID', 'name', 'creatDate']])
# 结果如下:
# SaleID name creatDate
# 0 134890 734 1
# 1 306648 196973 1
# 2 340675 25347 1
# 3 57332 5382 1
# 4 265235 173174 1
# 还可以采用字符串截取的方式获取月份str[4:6]除了时间数据外,还可以处理收入等数值型数据
如将二手车交易价格price 转为价格区间(千位的整数)
import pandas as pd
from datetime import datetime
data=pd.read_csv('data/car_train_0110.csv', sep=' ')
# 如将二手车交易价格price 转为价格区间
data['price1'] = data['price']//1000*1000 #x//1000*1000 表示先整除1000,再乘以1000 将价格转为1000的倍数
data['price2'] = round(data['price'], -3) #round(x, -3) 四舍五入 -3表示千分位
print(data[['SaleID','price', 'price1', 'price2']])
# 结果输出:
# SaleID price price1 price2
# 0 134890 520 0 1000
# 1 306648 5500 5000 6000
# 2 340675 1100 1000 1000
# 3 57332 1200 1000 1000
# 4 265235 3300 3000 3000如果将交易价格转为三级区间,如10000以下的为低价,10000-50000的为中价,50000以上的为高价
import pandas as pd
from datetime import datetime
# **如果将交易价格转为三级区间,如10000以下的为低价,10000-50000的为中价,50000以上的为高价**
data=pd.read_csv('data/car_train_0110.csv', sep=' ')
# 增加一列priceLevel loc函数是位置索引,根据条件赋值
data['priceLevel'] = ''
data.loc[data['price'] < 10000, 'priceLevel'] = '低价'
data.loc[(data['price'] >= 10000) & (data['price'] < 50000), 'priceLevel'] = '中价'
data.loc[data['price'] >= 50000, 'priceLevel'] = '高价'
print(data[['price', 'priceLevel']])
# 查看数据
# price priceLevel
# 0 520 低价
# 1 5500 低价
# 2 1100 低价
# 3 1200 低价
# 4 3300 低价
# ... ... ...
# 249995 1200 低价
# 249996 1200 低价
# 249997 16500 中价
# 249998 31950 中价
# 249999 1990 低价作业
查阅资料,了解读取PDF数据文件的方法,尝试读取PDF文件,并将数据转换为DataFrame格式。
你认为哪种补充缺失数据的方法更加合理?给出不同策略的实现方法。