
专家系统与机器学习
提示
专家系统是人工智能的重要分支,已广泛应用于各领域并产生显著效益;
机器学习是计算机模拟人类学习行为的核心技术,
知识发现与数据挖掘 是其重要应用。
本章节围绕专家系统的原理、构建,以及机器学习、知识发现的核心方法展开讲解。
一、专家系统的产生和发展
前言
专家系统 的发展经历了 初创期、成熟期、发展期 三个阶段,从最初的单一专业小系统,逐步发展为结构完整、功能全面、可复用的通用工具/环境,应用范围也不断拓展。
1.1 初创期(20世纪60年代中期-70年代初)
典型系统
- DENDRAL系统(1968,斯坦福大学):推断化学分子结构的专家系统,是专家系统的开山之作。
- MYCSYMA系统(1971,麻省理工):用于数学运算的数学专家系统。
阶段特点
高度专业化,专门问题求解能力强,但结构、功能不完整,移植性差,缺乏解释功能(只能给出答案,无法说明为什么得出该答案 )。
1.2 成熟期(20世纪70年代中期-80年代初)
典型系统
- MYCIN系统:斯坦福大学开发,血液感染病诊断专家系统;
- PROSPECTOR系统:斯坦福研究所开发,探矿专家系统;
- CASNET系统:青光眼诊断与治疗系统;
- AM系统:模拟人类归纳推理,发现数论概念和定理;
- HEARSAY系统:卡内基-梅隆大学开发,语音识别专家系统。
阶段特点
- 以单学科专业型系统为主;
- 系统结构完整、功能全面,移植性大幅提升;
- 具备推理解释功能,透明性好(能说明推理过程);
- 采用启发式推理、不精确推理,贴合实际问题;
- 用产生式规则、框架、语义网络表达知识;
- 支持限定性英语进行人机交互,使用更便捷。
1.3 发展期(20世纪80年代至今)
典型成果
- 实用化专家系统:DEC公司与卡内基-梅隆大学合作的XCON系统,为VAX计算机系统制订硬件配置方案,实现工业化应用;
- 专家系统开发工具:出现骨架系统(EMYCIN、KAS、EXPERT)、通用型知识表达语言(OPS5)、开发环境(AGE),大幅降低专家系统开发成本;
- 国内研究成果:施肥专家系统、新构造找水专家系统、关幼波肝病诊断专家系统等,覆盖农业、地质、医学等多个领域。
阶段特点
从单一专业系统向通用化、工具化、实用化发展,应用领域从科研走向工业、民生,与实际生产生活深度结合。
二、专家系统的概念
前言
2.1 专家系统的定义
核心定义
专家系统是一种智能的计算机程序,它运用知识和推理来解决只有专家 才能解决的复杂问题。
通俗理解
把某一领域专家的知识和经验整理出来,存入计算机,计算机通过模仿专家的推理方式,解决该领域的复杂问题,相当于计算机版的领域专家。
本质:一类包含知识和推理的智能计算机程序,区别于传统的数值计算程序。 👈❤️
2.2 专家系统的特点
专家系统具备六大核心特点,也是其能模拟人类专家求解问题的关键:
- 具有专家水平的专业知识:掌握领域内专家的知识和经验,知识量达到专家级别;
- 能进行有效的推理:运用领域知识进行合理推理,而非简单的数值计算;
- 具有启发性:能利用启发式知识(专家的经验、技巧),解决非结构化、不确定性问题;
- 具有灵活性:知识库可灵活修改、扩充,适应领域知识的更新;
- 具有透明性:能解释自己的推理过程和结论,让用户理解“为什么得出这个答案”;
- 具有交互性:支持人机交互,能接收用户输入的信息,也能向用户反馈推理过程/结果。
专家系统与传统程序的核心区别
这是理解专家系统的关键,二者的设计思想和核心逻辑完全不同:
| 对比维度 | 传统程序 | 专家系统 |
|---|---|---|
| 编程思想 | 数据结构 + 算法 | 知识 + 推理 |
| 知识存储 | 知识隐含在程序代码中,与程序不可分割 | 知识单独存于知识库,与推理机分离 |
| 处理对象 | 数值计算和数据处理 | 符号处理(如文字、概念、规则) |
| 解释功能 | 无,只能给出结果 | 有,能解释推理过程 |
| 结果特性 | 保证产生正确答案 | 通常产生正确答案,偶尔因知识局限产生错误 |
| 体系结构 | 单一的程序结构 | 由知识库、推理机、人机接口等多个模块组成 |
通俗例子:
- 计算1+1=2是传统程序(数值计算,算法固定);
- 诊断感冒并给出药方是专家系统(符号处理,用“感冒→咳嗽→吃止咳药”的知识推理)。 👈❤️
2.3 专家系统的类型
根据解决问题的类型,专家系统可分为10类,每类对应不同的应用场景和代表性系统,核心是利用知识完成不同类型的推理任务:
| 类型 | 核心功能(解决的问题) | 代表性系统 |
|---|---|---|
| 解释 | 根据感知数据推理情况描述(如分析分子结构、地质数据) | DENDRAL、PROSPECTOR |
| 诊断 | 根据观察结果推理系统是否存在故障/疾病 | MYCIN、CASNET、PUFF |
| 预测 | 指导给定情况可能产生的后果(如预测灾害、作物生长) | PLANT/ds、I&W、TYT |
| 设计 | 根据给定要求进行相应设计(如硬件配置、工程设计) | XCON、KBVLSI |
| 规划 | 设计完成任务的动作流程(如作业规划、行动规划) | NOAH、SECS、TATR |
| 控制 | 控制整个系统的行为,保证系统正常运行 | YESAMVS |
| 监督 | 比较观察结果和期望结果,发现异常 | REACTOR |
| 修理 | 执行计划来修复故障/问题 | ACE、DELTA |
| 教学 | 诊断、调整学生行为,辅助教学 | GUIDON |
| 调试 | 建议故障的补救措施 | TIMM/TUNER |
2.4 专家系统的应用
专家系统的应用已渗透到医学、地质学、计算机、化学、数学、工程、军事等几乎所有领域,核心是替代/辅助人类专家完成专业任务,以下是各领域的典型应用:
1.医学领域
MYCIN(细菌感染病诊断)、CASNET(青光眼诊断)、PUFF(肺功能试验结果解释)等,辅助医生诊断疾病、制定治疗方案;
2.地质学领域
PROSPECTOR(矿物量评估)、MUD(钻探泥浆问题处理)、HYDRO(水源总量咨询)等,助力地质勘探、资源评估;
3.计算机领域
XCON(VAX计算机配置)、DART(硬件故障诊断)、YES MVS(操作系统监控)等,实现计算机系统的配置、故障排查;
4.化学领域
DENDRAL(分子结构分析)、SECS(有机合成规划)、MOLGEN(DNA分子结构分析)等,辅助化学研究和实验设计;
5. 工程/军事领域
REACTOR(核反应堆事故处理)、TATR(空军攻击计划制定)、HASP(海洋声纳信号识别)等,解决工程和军事中的复杂问题。
三、专家系统的工作原理
前言
专家系统的核心是利用知识库中的知识,通过推理机完成推理。
3.1 专家系统的一般结构
- 核心组成模块(专家系统的“大脑”)
- 知识库:存储领域专家的知识和经验(如规则、事实、框架),是专家系统的基础,相当于专家的“记忆库”;
- 推理机:根据用户输入的信息,运用知识库中的知识进行推理,得出结论,相当于专家的“思考能力”;
- 数据库(动态数据库):存储推理过程中的临时数据/信息(如用户输入的症状、检测数据),推理完成后可清空;
- 解释机构:向用户解释推理过程和结论,回答“为什么得出这个结论”,提升系统透明性;
- 知识获取机构:负责知识库的构建、修改、扩充,是专家系统的“学习能力”,保证知识的更新和完善。
- 外部交互角色
- 领域专家:提供领域内的知识和经验,是专家系统的“知识来源”;
- 知识工程师:将领域专家的知识整理、转化为计算机能识别的形式,存入知识库,是“知识翻译官”;
- 用户:向系统提出问题、输入信息,接收系统的推理结果和解释,是系统的使用者。
核心工作流程
用户通过人机接口输入问题→信息存入动态数据库→推理机从知识库中调取知识,结合动态数据库的信息进行推理→推理结果通过人机接口反馈给用户→若用户需要,解释机构解释推理过程。
通俗例子:医学诊断专家系统
- 用户输入“咳嗽、发烧、喉咙痛”(动态数据库);
- 推理机从知识库中调取“发烧+咳嗽→可能感冒,感冒+喉咙痛→需用清热解毒药”的规则;
- 推理得出“感冒,建议服用XX药”的结论,反馈给用户;
- 解释机构向用户说明:“因为你有发烧、咳嗽、喉咙痛的症状,根据感冒的诊断规则,判断为感冒,XX药可缓解相关症状”。
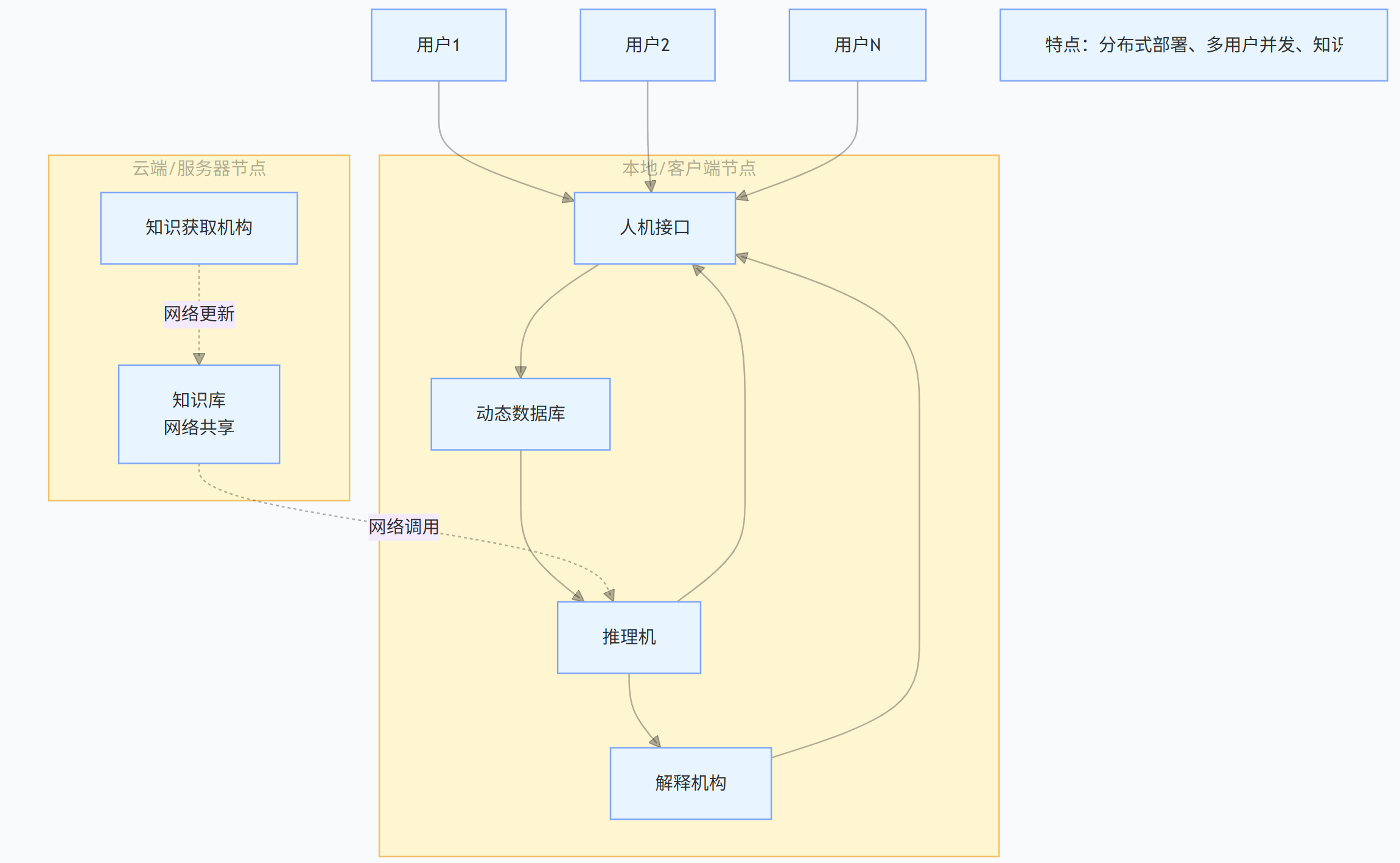
3.2 网络环境下的专家系统结构
在网络环境下,专家系统的结构进行了拓展,核心是实现知识和资源的网络共享,各模块可分布在不同的网络节点上(如知识库放在云端,推理机在本地终端),支持多用户同时访问、协同使用,更贴合现代信息化需求。如下图:👇
四、知识获取的主要过程与模式
前言
知识获取是将领域专家的知识转化为专家系统知识库中知识的过程,是专家系统开发的核心难点(被称为“专家系统的瓶颈”),其质量直接决定专家系统的性能。
4.1 知识获取的过程
知识获取是一个循序渐进的过程,核心分为4个步骤,由知识工程师和领域专家协同完成:
- 抽取知识:从领域专家的经验、科技文献中,提取与问题相关的核心知识(如规则、事实、技巧),剔除无关信息;
- 知识的转换:将抽取的知识(通常是自然语言、图表形式)转化为计算机能识别的形式(如产生式规则、语义网络);
- 知识的输入:将转换后的知识,通过知识编辑工具输入到知识库中;
- 知识的检测:对知识库中的知识进行检测,排查矛盾、冗余、错误的知识,保证知识的一致性和正确性。
通俗理解:知识获取就像老师整理教案——先从教材、教学经验中提取知识点(抽取),再把知识点整理成清晰的教案格式(转换),最后把教案存入电脑(输入),并检查教案是否有错误(检测)。
4.2 知识获取的模式
根据自动化程度,知识获取分为3种模式,自动化程度从低到高,开发成本从高到低:
1. 非自动知识获取(人工知识获取)
最传统、最常用的模式,核心依赖知识工程师的人工操作:
- 知识工程师通过与领域专家对话、阅读科技文献,提取知识;
- 人工将知识转换为计算机可识别的形式;
- 通过知识编辑器将知识输入知识库,并人工检测知识的正确性。
数据标注 → 本质就是 “把专家知识交给机器”
2. 自动知识获取
自动化程度最高的模式,无需知识工程师介入,系统可自动从外部环境中获取知识:
- 系统通过文字/图象识别、语音识别,接收领域专家的自然语言知识;
- 系统自动对知识进行归纳、理解、翻译,转化为内部表示形式;
- 系统自动将知识输入知识库,并完成一致性检测。
3. 半自动知识获取
介于非自动和自动之间的模式,结合了人工和自动的优势:
- 系统辅助知识工程师完成知识抽取、转换(如自动识别自然语言中的规则);
- 知识工程师进行人工审核和修正;
- 系统自动完成知识输入和部分检测工作。
三种模式对比
| 模式 | 自动化程度 | 依赖程度 | 开发成本 | 适用场景 |
|---|---|---|---|---|
| 非自动 | 低 | 高度依赖知识工程师 | 高 | 领域知识复杂、难以自动化提取 |
| 自动 | 高 | 几乎不依赖人工 | 低 | 领域知识结构化、易被机器识别 |
| 半自动 | 中 | 部分依赖知识工程师 | 中 | 大多数专家系统开发场景 |
五、机器学习
前言
5.1 机器学习的基本概念 👈 🍐
核心定义
机器学习使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善。
通俗理解
让计算机像人类一样“从经验中学习”——不需要人类手动编写所有规则,计算机能通过分析数据/例子,自己总结规律、获取知识,并用学到的知识解决新问题。
机器学习的三大研究问题
- 学习机理:研究人类获取知识、技能和抽象概念的天赋能力,为机器学习提供理论参考;
- 学习方法:在简化人类学习机理的基础上,用计算的方法再现学习过程,设计具体的机器学习算法;
- 学习系统:能够在一定程度上实现机器学习的计算机系统,是学习方法的实际载体。
机器学习系统的基本组成
一个完整的学习系统由4个基本部分组成,各部分形成一个闭环,实现“学习-应用-评价-优化”的过程:
- 环境:学习系统的“知识来源”,向系统提供学习所需的信息(如数据、例子、规则);
- 学习:系统的核心模块,对环境提供的信息进行分析、归纳、总结,提取知识并存入知识库;
- 知识库:存储系统学到的知识,是学习的成果,可不断更新和完善;
- 执行与评价:运用知识库中的知识解决实际问题,并对执行结果进行评价;若结果不好,反馈给学习模块,让系统重新学习、优化知识。
通俗例子:教计算机识别猫的图片
- 环境:向系统提供大量带标签的图片(猫的图片标“猫”,狗的图片标“狗”);
- 学习:系统分析猫的图片特征(尖耳朵、圆脸蛋、长胡须),总结出“猫的特征规则”,存入知识库;
- 执行:给系统一张新的猫的图片,系统运用知识库中的规则,判断这是“猫”;
- 评价:若判断正确,说明知识有效;若判断错误,反馈给学习模块,系统重新分析特征,优化规则。
5.2 机器学习的分类 👈 🍐
机器学习的分类方式有多种,核心的分类方式包括按学习方法、学习能力、推理方式、综合属性分类,其中按学习能力分类是最常用的方式。
1. 按学习方法分类(温斯顿,1977)
根据系统获取知识的具体方法,分为:机械式学习、指导式学习、示例学习、类比学习、解释学习等。 👈 🍐
2. 按学习能力分类(最常用)
根据系统学习时是否有教师指导、是否有评价反馈,分为三大类,也是目前人工智能领域最主流的分类方式:
(1)监督学习(有教师学习)
- 核心特点:有“教师”指导,环境提供的信息带有正确标签/正确响应;
- 学习过程:系统根据输入的信息和教师给出的正确响应,学习输入与输出之间的映射关系;
- 通俗例子:小学生做数学题,老师给出题目(输入)和正确答案(正确响应),学生学习解题方法。
(2)强化学习(再励/增强学习)
- 核心特点:无直接的正确答案,但有评价反馈(奖励/惩罚);
- 学习过程:系统执行某个动作后,环境给出评价(做得好给奖励,做得不好给惩罚),系统通过不断尝试,学习“能获得最大奖励的动作策略”;
- 通俗例子:机器人走迷宫,走出迷宫(奖励),碰到墙壁(惩罚),机器人通过反复尝试,学习最优的走迷宫路线。
(3)非监督学习(无教师学习)
- 核心特点:无教师指导,无正确标签,也无评价反馈;
- 学习过程:系统自动对输入的信息进行聚类、分析,发现数据中的内在规律和结构;
- 通俗例子:孩子整理玩具,没人告诉孩子怎么分,孩子自己根据玩具的形状、颜色,将玩具分成不同的类别。
3. 按推理方式分类
根据系统学习时采用的推理方式,分为:
- 基于演绎的学习:从一般知识推导出具体知识(如解释学习);
- 基于归纳的学习:从具体例子推导出一般知识(如示例学习、发现学习)。
4. 按综合属性分类
结合学习方法、推理方式、系统结构等综合特征,分为:归纳学习、分析学习、连接学习、遗传式学习等。
5.3 机械式学习 👈 🍐
核心定义
机械式学习又称记忆学习/死记式学习,是最简单的机器学习方法:通过直接记忆或存储外部环境所提供的信息达到学习的目的,并在以后通过对知识库的检索,直接用存储的知识求解问题。
核心实质
用存储空间来换取处理时间——提前将计算结果/问题答案存储起来,下次遇到相同问题,直接调取答案,无需重新计算/推理。
典型例子
塞缪尔(A.L.Samuel)的跳棋程序CHECKERS(1959年):
- 程序在玩跳棋时,计算每个棋局的倒推值(表示该棋局的优劣),并将“棋局-倒推值”的对应关系存储起来;
- 下次遇到相同的棋局时,直接调取存储的倒推值,决定最佳走步,无需重新计算。
机械式学习的主要问题
- 存储组织信息:需要采用合适的存储方式(如索引),保证检索速度尽可能快;
- 环境的稳定性:存储的信息必须适应环境变化,若环境变了,旧的信息可能失效(如跳棋规则变了,原来的倒推值就没用了);
- 存储与计算的权衡:不能盲目存储信息,若存储的信息过多,会占用大量存储空间,反而降低系统效率。
5.4 指导式学习 👈 🍐
核心定义
指导式学习又称嘱咐式学习/教授式学习:由外部环境(教师)向系统提供一般性的指示或建议,系统把它们具体地转化为细节知识并送入知识库中;在学习过程中反复对知识进行评价,使其不断完善。
核心特点
比机械式学习更高级,系统不是简单记忆,而是对教师的指示进行“消化吸收”,转化为自己的知识。
指导式学习的4个步骤
- 征询指导者的指示或建议:系统向教师获取一般性意见,分为简单征询、复杂征询、被动征询、主动征询(主动征询是最高级的,系统能主动提出问题);
- 转换为内部形式:将教师的自然语言指示,转化为计算机能执行的内部表示形式(如产生式规则),并进行语法和语义检查;
- 加入知识库:将转换后的知识存入知识库,同时进行一致性检查,防止出现矛盾、冗余、环路等问题;
- 评价:通过执行标准例子,测试新知识的有效性;若执行结果不好,反馈并修改知识。
通俗例子:老师教学生解应用题
- 老师告诉学生“解应用题的一般步骤:审题→找数量关系→列算式→计算”(一般性指示);
- 学生将这个步骤转化为自己的解题方法(内部形式);
- 学生用这个方法做几道应用题(评价);
- 若有的题解不出来,学生向老师提问,老师补充细节(如“找数量关系要先找关键词”),学生完善自己的解题方法。
5.5 示例学习 👈 🍐
核心定义
示例学习又称实例学习/从例子中学习:通过从环境中取得若干与某概念有关的例子(正例和反例),经归纳得出一般性概念的一种学习方法。
核心特点
从具体例子推导出一般规律,是典型的归纳学习,也是最贴近人类归纳推理的学习方法。
核心要求
外部环境提供的例子需包含正例(属于某概念的例子)和反例(不属于某概念的例子),系统归纳的知识需覆盖所有正例,排除所有反例。
通俗例子:教孩子识别“苹果”
- 家长给孩子看红苹果、绿苹果、黄苹果(正例),告诉孩子这是“苹果”;
- 家长给孩子看梨、桃子、橘子(反例),告诉孩子这不是“苹果”;
- 孩子归纳出苹果的特征:圆形、有果柄、果肉脆甜(一般性概念);
- 下次孩子看到一个新的绿苹果,能准确判断这是“苹果”;看到梨,能判断这不是“苹果”。
示例学习的学习模型
示例学习的核心是从示例空间中归纳出知识,其学习模型分为5个步骤,形成闭环:
- 示例空间:存储所有的正例和反例,是学习的基础;
- 搜索:从示例空间中选取合适的例子,供系统学习;
- 解释:分析例子的特征,找出正例和反例的本质区别;
- 形成知识:根据例子的特征,归纳出一般性的概念/规则,存入知识库;
- 验证:用新的例子验证归纳的知识是否正确;若不正确,返回示例空间,重新选取例子学习。
六、知识发现与数据挖掘
前言
知识发现和数据挖掘是机器学习的重要应用,核心是从海量数据中提取有价值的知识,解决“数据多、知识少”的问题,是现代大数据分析的核心技术。
6.1 知识发现与数据挖掘的概念
- 知识发现(KDD):全称是从数据库中发现知识,是从海量数据中提取出隐含的、未知的、有价值的知识和规律的过程 ;
- 数据挖掘(DM):是知识发现的核心步骤,指从数据库中挖掘知识的具体算法和过程 ;
- 二者关系:知识发现是一个完整的过程,数据挖掘是知识发现的核心环节,二者通常被合称为KDD-DM。
核心目的
从大规模的数据集中抽取和精化一般规律或模式,将海量的原始数据转化为有价值的知识,为决策提供支持。
通俗例子:超市的购物数据挖掘 👈🍐
- 原始数据:大量顾客的购物清单(如“牛奶+面包”“薯片+可乐”“牛奶+鸡蛋+面包”);
- 数据挖掘:从数据中发现规律——80%的顾客买牛奶时会同时买面包;
- 知识应用:超市将牛奶和面包放在相邻的货架,提高销量。
6.2 知识发现的一般过程
知识发现是一个循序渐进的过程,核心分为3个步骤,若结果不满足要求,需进行迭代优化:
6.2.1. 数据准备
数据准备是知识发现的基础,直接决定挖掘结果的质量,分为3个子步骤:
- 数据选取:根据用户需求,从原始数据库中抽取与任务相关的一组数据,剔除无关数据,减少数据量;
- 数据预处理:对选取的数据进行清洗,包括消除噪声(如错误数据、异常值)、推导计算缺值数据、消除重复记录、完成数据类型转换等;
- 数据变换:对预处理后的数据进行特征提取,找出真正有用的特征,减少挖掘时的特征个数,提高挖掘效率。
6.2.2. 数据挖掘
数据挖掘是知识发现的核心步骤,是运用算法从数据中提取规律的过程,分为2个关键环节:
- 确定挖掘任务:明确挖掘的目的,如数据总结、分类、聚类、关联规则、序列模式等(如超市购物数据的挖掘任务是“发现关联规则”);
- 选择挖掘算法:根据数据特点和用户要求选择合适的算法;
✅ 数据特点:不同的数据类型(数值、分类、文本)适合不同的算法;
✅ 用户要求:有的用户需要易理解的描述型知识(如关联规则),有的需要预测准确度高的预测型知识(如分类模型)。
6.2.3. 结果的解释与评价
数据挖掘得到的规律可能存在冗余、无关或错误的情况,需要进行解释和评价,分为3个核心动作:
- 评价:由用户或机器对挖掘出的知识模式进行评价,判断其是否有价值、是否满足用户要求;
- 迭代优化:若模式不满足要求,返回数据准备或数据挖掘阶段,重新选取数据、更换算法或调整参数;
- 知识表示:将挖掘出的知识转换为用户易懂的形式(如将分类决策树转换为“if-then”规则,将关联规则表示为“A→B,支持度80%”)。
6.3 知识发现的任务
根据挖掘的目标和结果类型,知识发现的任务主要分为7类,覆盖大数据分析的主要应用场景:
- 数据总结:对数据进行浓缩,给出紧凑描述(如统计数据的均值、中位数、方差);
- 概念描述:从相关数据中提取总体特征(如“年轻人的消费特征:喜欢网购、注重性价比”);
- 分类:构建分类模型(分类器),将数据项映射到给定类别中(如根据用户特征将用户分为“潜在客户”和“非潜在客户”);
- 聚类:根据数据的不同特征,将其划分为不同的类,类内数据相似性高,类间数据相似性低(如将客户分为不同的消费群体);
- 相关性分析:发现特征之间或数据之间的相互依赖关系(如“气温升高→冰淇淋销量增加”);
- 偏差分析:寻找观察结果与参照量之间的有意义的差别(如“某门店的销量比同区域其他门店低20%,分析原因”);
- 建模:构造数学模型,描述一种活动、状态或现象(如构建销量预测模型,预测未来的产品销量)。
6.4 知识发现的主要方法
知识发现的方法多样,融合了统计学、机器学习、模糊数学等多个学科的技术,核心方法有4种:
- 统计方法:从事物的外在数量表现推断内在规律性,如回归分析、判别分析、聚类分析、探索性分析等;
- 粗糙集方法:一种处理模糊和不确定知识的数学方法,用“是、不是、也许”三值隶属函数描述数据,常与规则归纳、分类结合使用;
- 可视化方法:将数据、信息和知识转化为图形、图表等可视化形式,让抽象的数据信息形象化,便于用户理解(如用折线图展示销量变化,用热力图展示客户分布);
- 机器学习方法:是知识发现的核心方法,包括符号学习(如示例学习、规则归纳)和连接学习(如神经网络),从数据中自动归纳规律。
6.5 知识发现的对象
知识发现的对象是各种类型的海量数据,随着数据类型的不断丰富,挖掘的对象也在不断拓展,核心包括4类:
- 数据库:最传统的挖掘对象,目前研究最多的是关系数据库(如MySQL、Oracle中的数据);
- 数据仓库:数据仓库是面向决策的集成化数据集合,数据挖掘为数据仓库提供深层次的数据分析手段,数据仓库为数据挖掘提供经过良好预处理的数据源,二者相辅相成;
- Web信息:互联网上的海量数据,包括网页内容、链接关系等,Web知识发现分为内容发现(从网页内容中提取知识)和结构发现(从网页链接结构中推导知识);
- 图像和视频数据:如卫星拍摄的图像、监控视频、短视频等,从其中提取有用的信息(如从卫星图像中分析植被覆盖情况,从监控视频中识别异常行为)。
七、专家系统的建立
前言
专家系统的建立是一个复杂的系统工程,需要领域专家、知识工程师、用户协同完成,核心是选择合适的问题、遵循科学的设计原则和开发步骤、进行全面的评价。
7.1 适合于专家系统求解的问题
并非所有问题都适合用专家系统解决,威特曼(Waterman)提出了三个核心问题,判断一个问题是否适合开发专家系统:
1. 什么情况下开发专家系统是可能的?
满足3个条件,保证技术上可实现:
- 问题主要依靠经验性知识解决,无需运用大量常识性知识;
- 存在真正的领域专家(能提供足够的知识和经验);
- 有明确的开发目标,且任务不太难实现(任务规模适中)。
2. 什么情况下开发专家系统是合理的?
满足3个条件,保证经济和社会价值:
- 开发后能产生较高的经济效益(如降低成本、提高效率);
- 人类专家奇缺,但在许多地方又十分需要(如偏远地区的医疗专家);
- 人类专家的经验不断丢失(如老专家退休,经验无人传承);
- 危险场合需要专业知识(如核反应堆操作、矿山勘探,人类专家现场作业风险高)。
3. 什么情况下开发专家系统是合适的?
满足3个条件,保证问题本身适配专家系统的特点:
- 问题本质是符号操作和符号结构求解,需使用启发式知识、经验规则才能得到答案(非简单的数值计算);
- 问题具有一定的复杂性(人类专家需要花费大量时间和精力才能解决);
- 任务的大小可驾驭,且有实用价值(避免任务过大难以开发,或任务过小无实际意义)。
通俗判断:一道数学题的计算适合传统程序,而医生诊断疾病、工程师排查复杂故障,适合用专家系统。
7.2 专家系统的设计原则与开发步骤
7.2.1 专家系统的设计原则
为了保证专家系统的开发质量和效率,需遵循6个核心设计原则:
- 专门的任务:专家系统的目标要明确,只解决某一领域的特定问题,避免“大而全”(如只做糖尿病诊断,不做所有疾病诊断);
- 专家合作:开发过程中必须与领域专家密切合作,保证知识库的知识质量;
- 原型设计:先开发原型系统(最小可行系统),快速实现核心功能,测试后再逐步完善和扩充;
- 用户参与:让用户全程参与开发,保证系统的功能和人机交互符合用户的使用习惯;
- 辅助工具:尽量使用现有的专家系统开发工具(如骨架系统、开发环境),降低开发成本;
- 知识库与推理机分离:这是专家系统的核心设计原则,保证知识库的修改、扩充不会影响推理机,提高系统的灵活性。
7.2.2 专家系统的开发步骤
专家系统的开发是一个迭代优化的过程,核心分为6个步骤,若某一步的结果不满足要求,需返回上一步重新设计:
- 问题识别:明确要解决的问题,确定系统的目标、任务、领域范围和用户需求;
- 概念化:将问题转化为领域内的概念模型,梳理领域知识的结构、概念、关系和推理规则;
- 形式化:将概念模型转化为计算机能识别的形式化表示(如产生式规则、语义网络),确定知识表示方法和推理方式;
- 实现:根据形式化的结果,选择开发工具,编写程序,构建知识库和推理机,实现原型系统;
- 测试:对原型系统进行全面测试,检测知识的正确性、推理的有效性、功能的完整性,找出系统的问题和缺陷;
- 完善:根据测试结果,修改和完善知识库、推理机,优化系统功能;若问题较大,需重新概念化或形式化。
7.3 专家系统的评价
专家系统的评价是开发过程中的重要环节,核心是检验系统的正确性和有用性,为系统的完善提供依据,评价需覆盖系统的设计、测试、运行全流程。
7.3.1 正确性
正确性是专家系统的基础,指系统的设计、测试和运行过程均符合规范,推理结果准确,分为3个层面:
- 系统设计的正确性:设计思想、设计方法、开发工具的选择均正确合理;
- 系统测试的正确性:测试的目的、方法、条件明确,测试结果、数据、记录真实准确;
- 系统运行的正确性:推理结论、求解结果、咨询建议准确;推理解释及可信度估算正确;知识库中的知识无矛盾、无冗余、无错误。
7.3.2 有用性
有用性是专家系统的核心价值,指系统能解决实际问题,满足用户需求,分为6个层面:
- 推理结论、求解结果、咨询建议具有实际应用价值;
- 系统的知识水平高,可用范围广,易扩展、易更新;
- 具有较强的问题求解能力,能适应不同的应用场合和环境;
- 人机交互友好,操作简单,便于用户使用;
- 运行可靠,故障率低,易维护、可移植;
- 具有良好的经济性,开发成本低,使用后能带来显著的经济效益或社会效益。
八、专家系统实例及其骨架系统
前言
在专家系统的发展过程中,出现了一些经典的专家系统,基于这些系统抽去领域知识后形成的骨架系统,成为开发新专家系统的重要工具,大幅降低了开发成本。
8.1 骨架系统的概念
骨架系统又称外壳系统,是从成熟的专家系统中抽去原有的领域知识,保留其知识表示方法、推理机、人机接口、解释机构等核心模块形成的专家系统开发工具。
核心特点
- 复用性强:保留了原专家系统的核心框架,无需重新开发推理机、人机接口等模块;
- 开发效率高:开发新专家系统时,只需将新的领域知识填入骨架系统的知识库,即可快速实现;
- 针对性强:不同的骨架系统适用于不同类型的问题(如EMYCIN适用于诊断型问题,KAS适用于解释型问题)。
核心优势
让开发者无需关注专家系统的底层实现,只需专注于领域知识的整理和录入,大幅降低专家系统的开发门槛和成本。
8.2 EMYCIN骨架系统
8.2.1 原型系统:MYCIN系统
EMYCIN的原型是MYCIN系统(斯坦福大学,1972-1978),是经典的血液感染病诊断专家系统:
- 开发语言:INTER LISP语言;
- 知识库:包含200多条规则,能识别51种病菌,正确处理23种抗生素;
- 咨询过程:确定病人是否有细菌感染→确定细菌类型→优选治疗处方→确定抗生素药物;
- 系统结构:由知识库、咨询模块、知识获取模块、动态数据库、解释模块组成,支持人机交互和推理解释。
8.2.2 EMYCIN系统的核心功能
EMYCIN是从MYCIN中抽去医学领域知识后形成的骨架系统,保留了MYCIN的核心框架,新增了多种开发辅助功能,核心功能包括:
- 解释程序:支持推理过程的解释,保持了MYCIN的透明性;
- 知识编辑程序:提供类英语的简化会话语言,方便用户录入和修改知识;
- 知识库管理和维护:支持知识的添加、删除、修改,以及一致性检测;
- 跟踪和调试功能:方便开发者跟踪推理过程,调试系统问题。
8.2.3 EMYCIN系统的工作过程
EMYCIN的工作过程分为专家系统建立过程和咨询过程:
- 建立过程:开发者通过知识编辑程序,将新的领域知识录入知识库→系统自动进行一致性检测→完成专家系统的构建;
- 咨询过程:与MYCIN一致,接收用户输入的信息→推理机运用知识库中的知识推理→给出结论并解释推理过程。
8.2.4 EMYCIN的应用
EMYCIN适用于开发诊断型、解释型专家系统,基于EMYCIN开发的典型系统包括:
- SACON:帮助解决结构分析问题的策略;
- PLANT/CDP:通过油井钻探数据鉴定地下岩层;
- CLOT:分析病人血液凝固机制的问题;
- LIGHO:预测麦田是否受黑鳞翅目幼虫侵害。
8.3 KAS骨架系统
8.3.1 原型系统:PROSPECTOR系统
KAS的原型是PROSPECTOR系统,是经典的探矿专家系统,用于地质勘探和矿物量评估。
8.3.2 KAS系统的核心特点
KAS是从PROSPECTOR中抽去地质勘探知识后形成的骨架系统,适用于开发解释型专家系统,核心特点:
- 知识表示方法:采用产生式规则和语义网络相结合的方式,能更灵活地表示领域知识;
- 推理控制策略:采用启发式正反向混合推理,既能从事实推结论(正向推理),也能从结论推所需事实(反向推理),推理效率更高;
- 核心辅助程序:
- 网络编辑程序:将用户输入的信息转化为语义网络,检测语法错误和知识一致性;
- 网络匹配程序:分析两个语义网络的关系(等价、包含、相交),检测知识的矛盾和冗余。
8.3.3 KAS系统的应用
KAS适用于开发解释型、诊断型专家系统,基于KAS开发的典型系统包括:
- AIRID:根据飞行物特征和环境条件识别飞机型号;
- CONPHYDE:帮助化学工程师选择化工生产中的物理参数。
九、专家系统的开发环境
前言
专家系统的开发环境又称专家系统开发工具包,是比骨架系统更通用的开发工具,为专家系统的开发提供多种方便的构件,支持开发者灵活构建不同类型、不同功能的专家系统。
9.1 开发环境的核心功能
开发环境整合了专家系统开发所需的各类工具和模块,核心功能包括:
- 提供知识获取的辅助工具(如知识编辑器、数据挖掘工具);
- 支持多种不同知识结构的知识表示模式(如产生式规则、框架、语义网络);
- 提供多种不同的不确定推理机制(如概率推理、模糊推理);
- 包含知识库管理系统,支持知识的存储、管理、维护;
- 提供人机接口、解释机构、调试工具等辅助模块。
9.2 典型开发环境:AGE
AGE(attempt to generalize)是一种典型的模块组合式开发工具,核心是提供一系列独立的专家系统模块,开发者可根据需求灵活组合,构建自定义的专家系统。
基于AGE构造专家系统的两种途径
- 模块复用:用户直接使用AGE现有的各种组件(如推理机、知识库、解释模块)作为构造材料,快速组合设计所需的专家系统;
- 自定义模块:用户通过AGE的工具界面,根据需求定义和设计各种所需的组成部件,构建个性化的专家系统,灵活性更高。
9.3 专家系统开发的核心编程语言
开发专家系统需要使用适合符号处理和推理的编程语言,核心分为两类:
1. 传统AI专用语言
- LISP语言(1960年,麦卡锡):表处理语言,擅长符号处理,许多早期经典专家系统(MYCIN、PROSPECTOR)都是用LISP开发的;
- PROLOG语言(1972年,A. Comerauer):基于演绎推理的逻辑型程序设计语言,擅长知识表示和逻辑推理,是专家系统开发的经典语言。
2. 现代通用编程语言
随着编程语言的发展,现代专家系统开发更多使用通用编程语言,兼顾符号处理和工程实现:
- Python:语法简洁,拥有丰富的AI库(如PyTorch、Scikit-learn),是目前最主流的AI/专家系统开发语言;
- C/C++:执行效率高,适合开发对性能要求高的专家系统;
- Java:跨平台性好,适合开发网络环境下的专家系统。
十、课程总结
- 专家系统是包含知识和推理的智能计算机程序,能模拟人类专家解决领域复杂问题,其发展经历了初创期、成熟期、发展期,核心结构包括知识库、推理机、解释机构等,知识获取是其开发的核心瓶颈;
- 机器学习是计算机模拟人类学习行为的核心技术,核心是从数据/例子中自动获取知识,分为监督学习、强化学习、非监督学习三大类,机械式学习、指导式学习、示例学习是最基础的学习方法;
- 知识发现与数据挖掘是机器学习的重要应用,核心是从海量数据中提取有价值的知识,一般过程包括数据准备、数据挖掘、结果解释与评价,是大数据分析的核心技术;
- 专家系统的建立需遵循科学的步骤,先开发原型系统,再迭代优化,评价核心关注正确性和有用性;
- 骨架系统(EMYCIN、KAS)和开发环境(AGE)是专家系统开发的重要工具,能大幅降低开发成本,提高开发效率;
- 专家系统和机器学习是人工智能的核心分支,二者相辅相成——机器学习可为专家系统提供自动知识获取能力,专家系统可为机器学习提供知识指导,共同推动人工智能的发展和应用。