
人工神经网络及其应用
一、神经元与神经网络
前言
人工神经网络(ANN)的核心是模拟人脑生物神经元的结构和工作原理,由大量简单的人工神经元通过广泛连接构成,是一种隐式的知识表示方法(知识存储在神经元之间的连接权值中,而非显式的规则/公式)。
1.1 生物神经元的结构
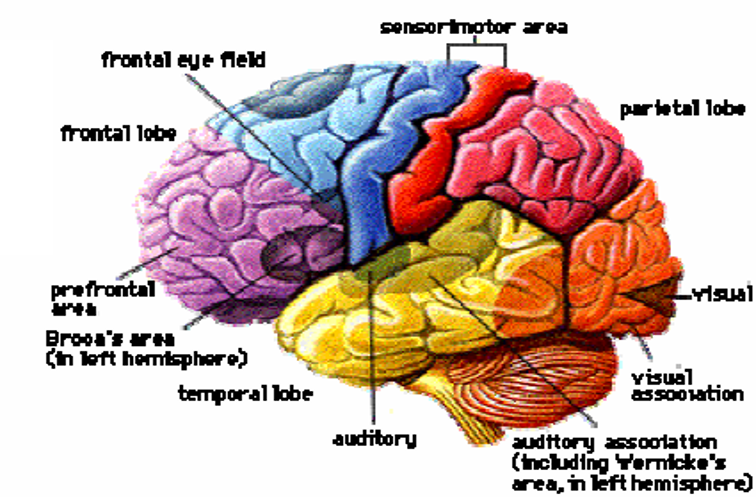
人脑由约 ~ 个神经细胞(神经元)组成,大脑皮层约140亿个、小脑皮层约1000亿个,每个神经元与1000~10000个其他神经元相连,形成复杂的网状结构。
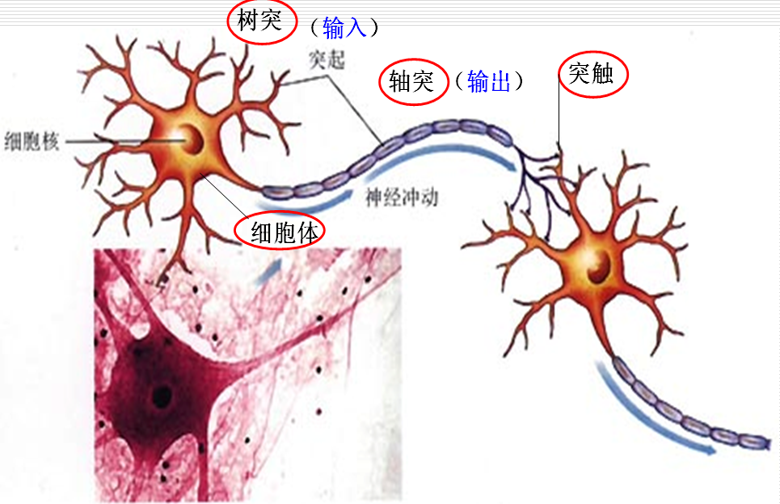
生物神经元的核心组成(输入→处理→输出)
- 树突:神经元的输入端,接收其他神经元传递的信号;
- 细胞体:神经元的处理中心,对树突接收的信号进行整合计算;
- 轴突:神经元的输出端,将细胞体处理后的信号传递给其他神经元;
- 突触:神经元之间的连接节点,是信号传递的关键,突触的传递作用可增强/减弱(对应学习与遗忘)。
生物神经元的工作状态
神经元通过细胞膜电位判断是否传递信号,核心是阈值判断:
- 兴奋状态:细胞膜电位 > 动作电位阈值 → 产生神经冲动,向其他神经元传递信号;
- 抑制状态:细胞膜电位 < 动作电位阈值 → 不产生神经冲动,抑制信号传递。
1.2 神经元数学模型
1943年McCulloch和Pitts提出M-P模型,是第一个人工神经元数学模型,模拟生物神经元的输入、整合、阈值判断与输出。
公式:
激活函数(阶跃函数):
,当
,当
符号说明:
- :输入(天气、时间)
- :权重
- :阈值
- :输出(1出去散步,0不出去)
实例:是否出去散步 👈
设:
- 天气,好=1,不好=0
- 时间,合适=1,不合适=0
- 权重
- 阈值
计算:
例1:天气好、时间合适
→ 出去散步
例2:天气好、时间不合适
→ 不出去
1.3 神经网络的核心拓扑结构
拓扑结构就是神经元的排列连接方式,主要分2类,重点记前馈型(最常用):
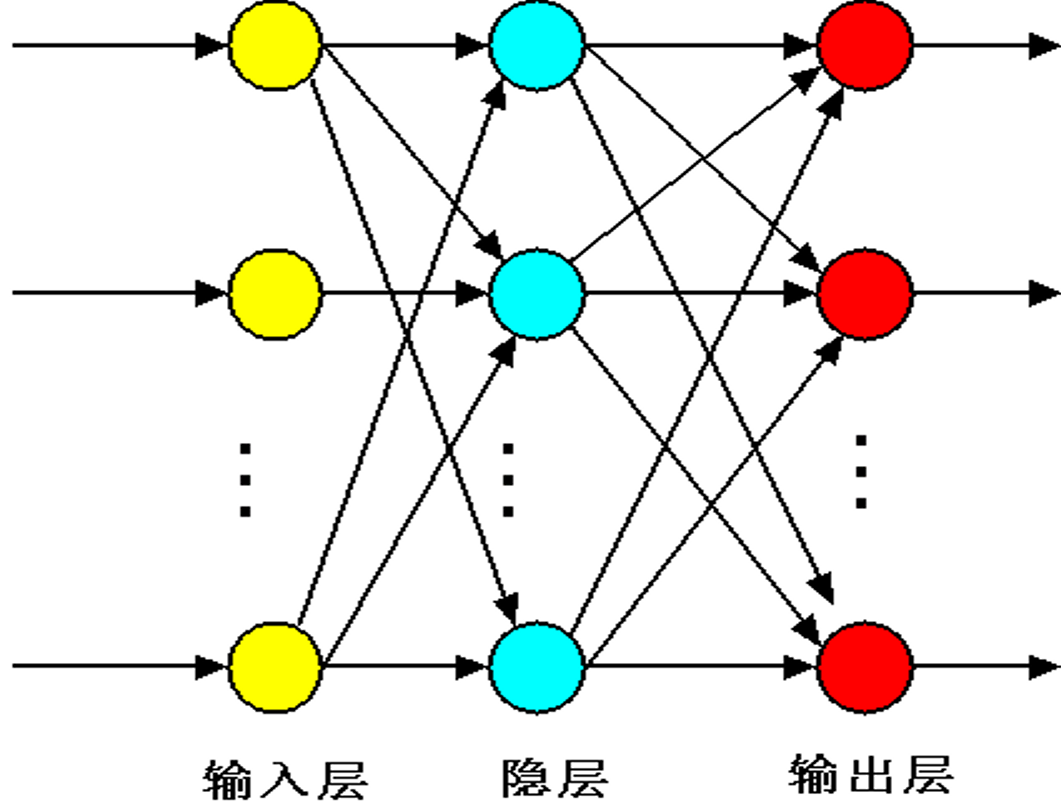
1. 前馈型(前向型)神经网络
- 结构:神经元按「输入层→隐层(隐藏层)→输出层」分层排列,信号单向传播(只能从输入到输出),层间不反馈、层内不连接。
- 特点:结构简单、容易训练,日常用得最多。
- 典型:BP神经网络、卷积神经网络(后续重点学的)。
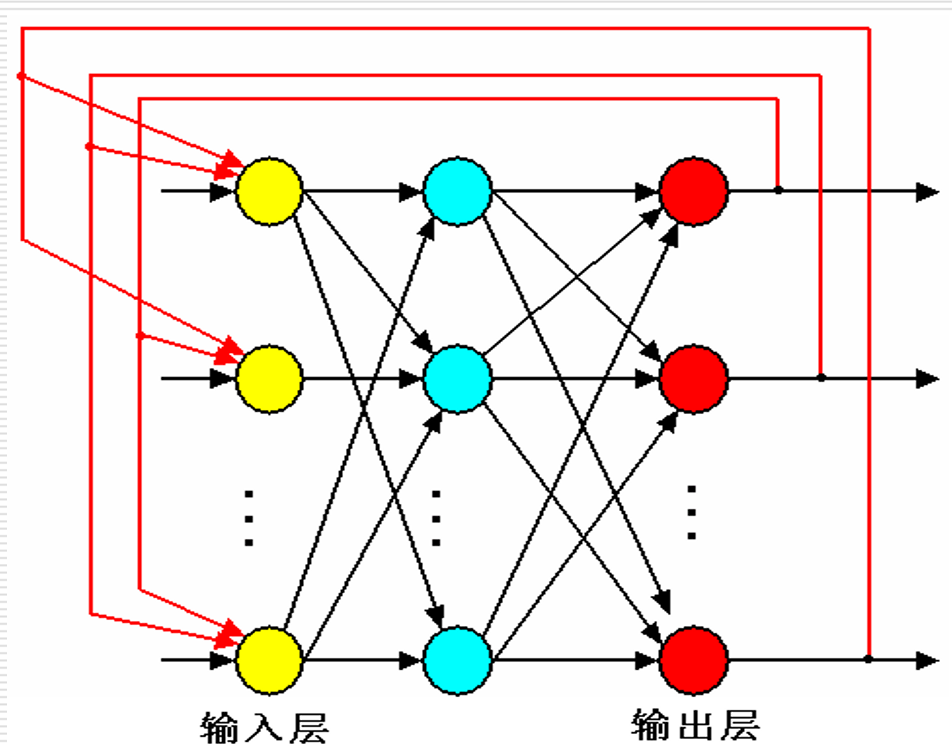
2. 反馈型神经网络
- 结构:神经元之间双向连接,信号可正向传、也可反向反馈(比如自身输出再当输入)。
- 特点:有记忆性,能稳定下来,适合做联想记忆、优化问题。
- 典型:Hopfield神经网络。
1.4 神经网络的工作方式(信息处理方式)
按神经元调整状态的同步性,分2种,简单理解为“同时动”和“逐个动”:
- 同步(并行)方式:同一时刻,所有神经元一起调整状态,处理信息快、效率高。
- 异步(串行)方式:同一时刻,只有1个神经元调整,其他不变,稳定性更强。
神经网络的学习说白了就是调整神经元之间的连接权值,让网络能 “记住” 输入和输出的关系,比如输入 “天气、时间”,能输出 “是否散步”,后续遇到新数据也能准确判断。

二、BP神经网络
前言
1.时间线
1. BP(误差反向传播)神经网络
- 思想萌芽:1974年
Paul Werbos 在博士论文中首次提出反向传播思想,但未被学界重视。 - 正式系统提出并普及:1986年
Rumelhart、Hinton、Williams 在《Nature》正式发表 BP 算法,解决多层前馈网络权值训练问题,引发神经网络复兴。
2. Hopfield 神经网络
- 首次提出:1982年
美国物理学家 John J. Hopfield 发表论文,提出离散 Hopfield 模型(反馈型、联想记忆网络)。 - 完善与扩展:1984年
提出连续 Hopfield 模型,并给出电子线路实现方案。
2.BP神经网络
核心定位:BP神经网络(误差反向传播神经网络),是最常用的前馈型神经网络,核心作用是通过“误差反向传播”调整权值,实现输入与输出的精准映射,用于分类、预测等任务。
一、BP神经网络的结构
整体为“三层结构”(核心,可扩展多层隐层),信号从输入层→隐层→输出层,无反馈、无层内连接,对应前馈型网络的典型特点:
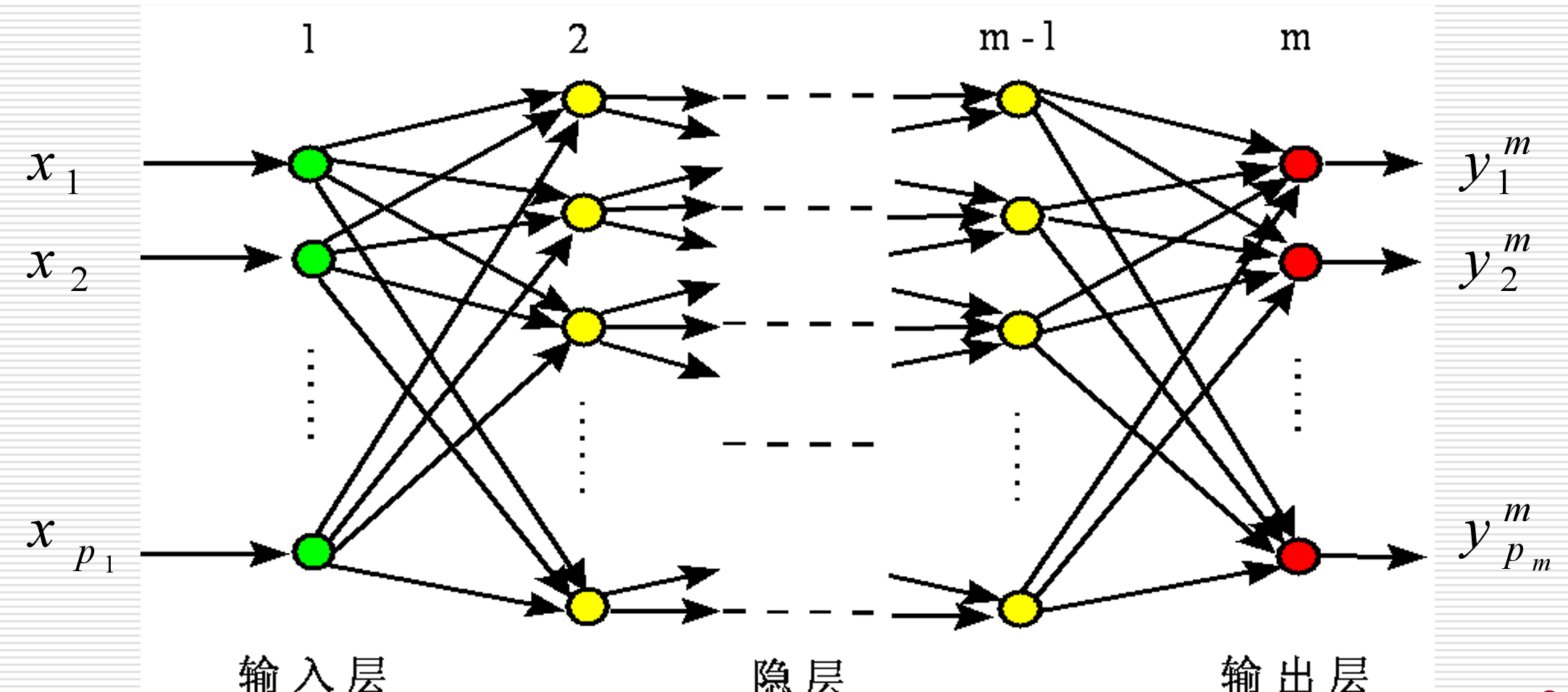
- 输入层:接收原始数据(比如“是否散步”案例中的天气、时间),是网络的“信息入口”,每个神经元对应一个输入特征。
- 隐藏层:核心“处理层”,接收输入层信号,通过加权、激活运算,将信息传递给输出层;可设置1层或多层,层数越多,处理复杂问题的能力越强。
- 输出层:网络的“结果出口”,输出处理后的结果(比如“出去散步”或“不出去”,分类任务的类别、预测任务的数值)。
补充:层与层之间的神经元通过“连接权值”传递信号,权值是可调整的(学习的核心就是调权值)。
二、BP算法(核心:误差反向传播,调权值减误差)
BP算法=“正向传播(算输出、找误差)+ 反向传播(调权值、减误差)”,两步循环,直到误差达到最小、网络稳定。

1. 正向传播( forward propagation )
简单说:从输入层到输出层,算“实际输出”,对比“期望输出”,找出误差。
- 输入层接收数据,通过权值传递到隐层;
- 隐层神经元对信号做“加权求和+激活运算”(用激活函数,比如Sigmoid,将输出限制在合理范围);
- 隐层信号传递到输出层,同样做加权求和+激活运算,得到“实际输出”;
- 计算“实际输出”与“期望输出”的误差(比如平方误差,衡量偏差大小)。
2. 反向传播( back propagation )
简单说:从输出层到输入层,根据误差,反向调整每一层的连接权值,让下次的误差变小。
- 从输出层开始,计算误差对输出层权值的影响(梯度计算);
- 误差逐层反向传递,依次计算隐层、输入层的权值调整量;
- 按照“权值调整规则”(基于Hebb规则扩展),更新所有连接权值;
- 重复“正向传播→反向传播”,直到误差达到预设值(网络收敛)。
3. 核心关键
激活函数 :解决线性不可分问题(比如无法用一条直线区分两类数据),常用Sigmoid、ReLU;
权值更新 :核心是“误差越大,权值调整幅度越大”,逐步逼近最优权值。
三、BP算法的实现
核心步骤
- 初始化:设置网络结构(输入层、隐层、输出层神经元数量),初始化连接权值(随机小数值)、激活函数、误差阈值;
- 正向传播:输入训练数据,计算各层输出,得到误差;
- 反向传播:计算误差梯度,逐层更新权值;
- 迭代训练:重复步骤2-3,直到误差小于预设阈值,停止训练;
- 测试验证:用未训练过的数据输入网络,看输出结果是否准确,验证网络效果。
四、BP神经网络的应用场景
核心:适合“输入→输出”的映射任务(分类、预测、拟合),应用广泛,典型场景:
- 分类任务:比如图像识别(识别猫/狗)、文本分类(垃圾邮件识别)、疾病诊断(根据症状判断是否患病);
- 预测任务:比如房价预测(输入面积、地段,预测房价)、销量预测(输入往期销量,预测下期销量)、天气预测(输入气象数据,预测气温/降雨);
- 拟合任务:比如数据拟合(根据已知数据,拟合出趋势曲线)、信号处理(过滤噪声,还原真实信号)。
三、Hopfield神经网络
前言
BP 是前馈网络,擅长“输入→输出”的预测、分类,像一个会做题的学生。
Hopfield 是反馈网络,更像一个会回忆、联想、找最优解的大脑。
1982年,J.J.Hopfield提出,是最早、最经典的反馈型神经网络,核心能力是联想记忆和优化求解。

Hopfield 是一种单层、全连接、带反馈的神经网络,核心能力是联想记忆和优化求解。
你可以把它理解成:
- 给它一个模糊、残缺的图案 → 它能自动补全成清晰的
- 给它一个混乱的初始状态 → 它能慢慢稳定到一个最优结果
- 不靠 BP 反向传播,不靠梯度下降,靠自己迭代收敛
一、离散型 Hopfield 网络
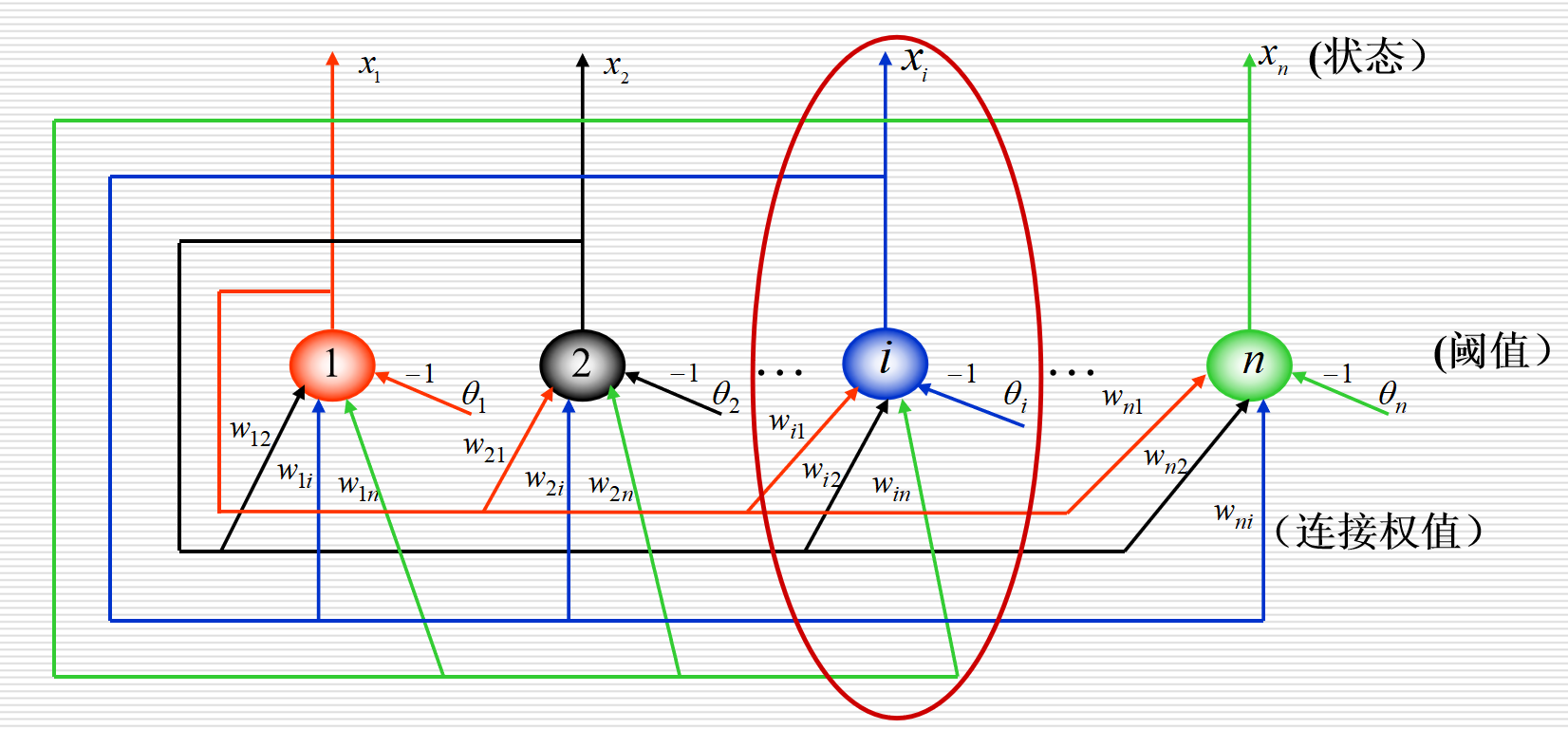
1. 结构特点
- 神经元输出只有 0 或 1(也常用 -1 / 1)
- 每个神经元都和其他神经元相连
- 有反馈:输出会重新送回输入
- 没有明显的输入层、输出层
2. 工作方式
- 设定一组要“记住”的模式(比如数字 0~9)
- 用 Hebb 规则一次性算出连接权值
- 输入一个残缺、带噪声的模式
- 网络不断更新状态
- 最终稳定在一个最接近的“记忆模式”
3. 核心思想
网络有“能量”,每次更新都会让能量降低,直到能量最小,状态就稳定了。
就像小球从山坡滚到谷底,停在最低点不动。
二、连续型 Hopfield 网络
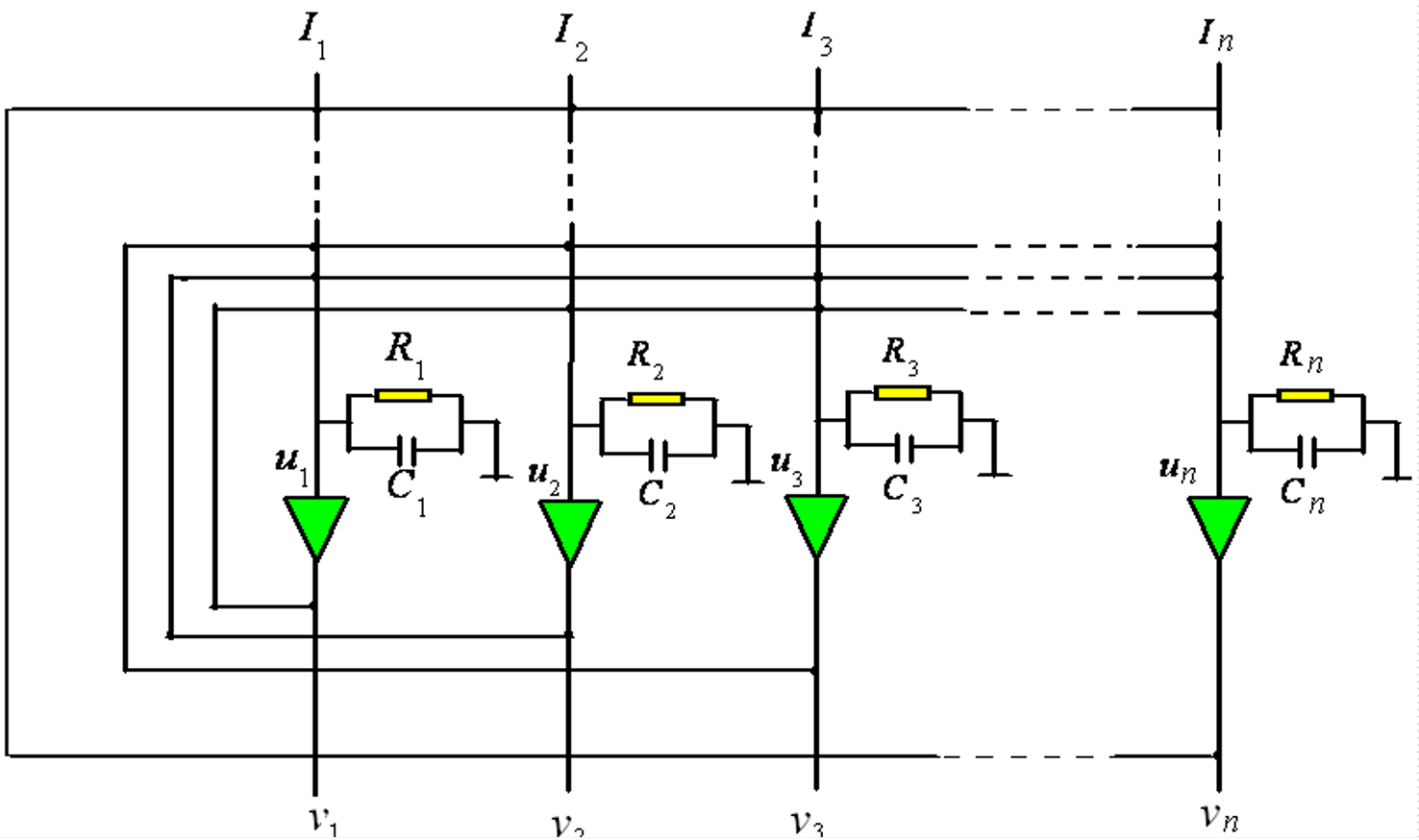
1. 和离散型的区别
- 离散型:输出只有 0/1 或 ±1,像开关
- 连续型:输出是 0~1 之间的连续值,更接近真实神经元
2. 特点
- 用连续的激活函数(如 Sigmoid)
- 状态平滑变化,不是跳变
- 更适合做优化问题,而不只是联想记忆
- 可以用电路模拟,是早期硬件实现神经网络的重要模型
3. 意义
连续型让 Hopfield 从“记忆网络”扩展到了优化计算网络,用途更广。
三、Hopfield(应用场景)
1. 联想记忆(最经典)
- 输入残缺图像 → 自动恢复完整图像
- 输入带噪声文字 → 自动识别干净文字
- 类似人类:看到半张脸就能认出是谁
2. 模式识别
- 手写数字识别
- 字符、符号识别
- 简单图像分类
3. 组合优化问题
- 旅行商问题(TSP:找最短路线)
- 任务调度
- 路径规划
- 各种“找最优解”的问题
4. 信号处理
- 去噪
- 信号恢复
- 纠错编码
四、Hopfield神经网络优缺点
优点
- 结构简单直观
全连接反馈结构,仿生思路清晰,容易理解和实现。 - 具有联想记忆能力👈
输入残缺、带噪声的模式,能自动恢复成完整记忆,类似人脑回忆。 - 不用 BP 反向传播
依靠 Hebb 规则一次性设置权值,训练简单、计算量小。 - 有稳定收敛性
依靠能量函数不断下降,最终一定能稳定到某个状态。 - 适合组合优化问题
可用于旅行商问题、路径规划等“找最优解”场景。 - 易于硬件实现👈
连续型 Hopfield 可用电路模拟,是早期神经网络硬件的重要基础。
缺点
- 记忆容量很小
能记住的模式数量有限,多了容易记混、出错。👈 - 容易陷入局部最优
能量函数可能卡在次低点,得不到全局最优解。 - 学习能力弱
权值一次性设定,无法像 BP 那样反复迭代、精细学习。 - 抗干扰能力有限
输入噪声过大时,会联想错误,无法正确恢复模式。 - 无法处理复杂高维数据👈
只能处理简单图像、字符,不适合大图、语音、文本等复杂任务。 - 无深层结构
只有单层网络,不能像深度学习那样逐层提取高级特征。 - 串行更新效率低
异步更新时收敛慢,同步更新又容易出现震荡不稳定。
总结
- Hopfield 是反馈型神经网络,分离散型(记忆)和连续型(优化)。
- 靠能量函数收敛,不用 BP,不用梯度下降。
- 擅长联想记忆、模式恢复、组合优化。
- 优点是直观、仿生、可硬件实现;
- 缺点是容量小、易局部最优、能力有限,因此后来被BP、深度学习替代。
- 学它是为了理解:反馈、稳定性、能量函数、联想记忆这些核心思想。

四、卷积神经网络与深度学习
前言
一、第一代神经网络:萌芽与基础(20世纪40–60年代)
- 1943 年:M-P 神经元模型
第一个人工神经元,奠定神经网络数学基础。 - 1944 年:Hebb 学习规则
神经网络“学习”的核心思想:一起激活,连接增强。 - 1958 年:感知机(Perceptron)
第一个可训练的单层神经网络,能做简单分类。 - 局限:只能解决线性可分问题,无法处理异或等简单非线性问题,导致第一次神经网络寒冬。
二、第二代神经网络:复兴与经典模型(20世纪80年代)
突破单层限制,出现多层网络与反馈网络,神经网络再次兴起。
1982 年:Hopfield 神经网络
- 反馈型网络
- 核心能力:联想记忆、组合优化
- 不用 BP,靠能量函数收敛
- 开创了反馈网络研究方向
1986 年:BP 神经网络(误差反向传播)
- 多层前馈网络
- 用误差反向传播训练权值
- 能解决非线性问题,是神经网络里程碑
- 成为后续深度学习的训练基础
- 局限:网络层数浅、易过拟合、训练慢,无特征提取能力,进入第二次低谷。
三、第三代神经网络:深度学习时代(2006 年至今)
那问题来了,为什么图像AI早早就崛起了,而会写字说话的AI却来的这么晚呢?
接下来揭开这个谜底,带你从CNN、RNN一路走到Transformer,看看AI到底怎么一步一步学会听懂人话的。👍
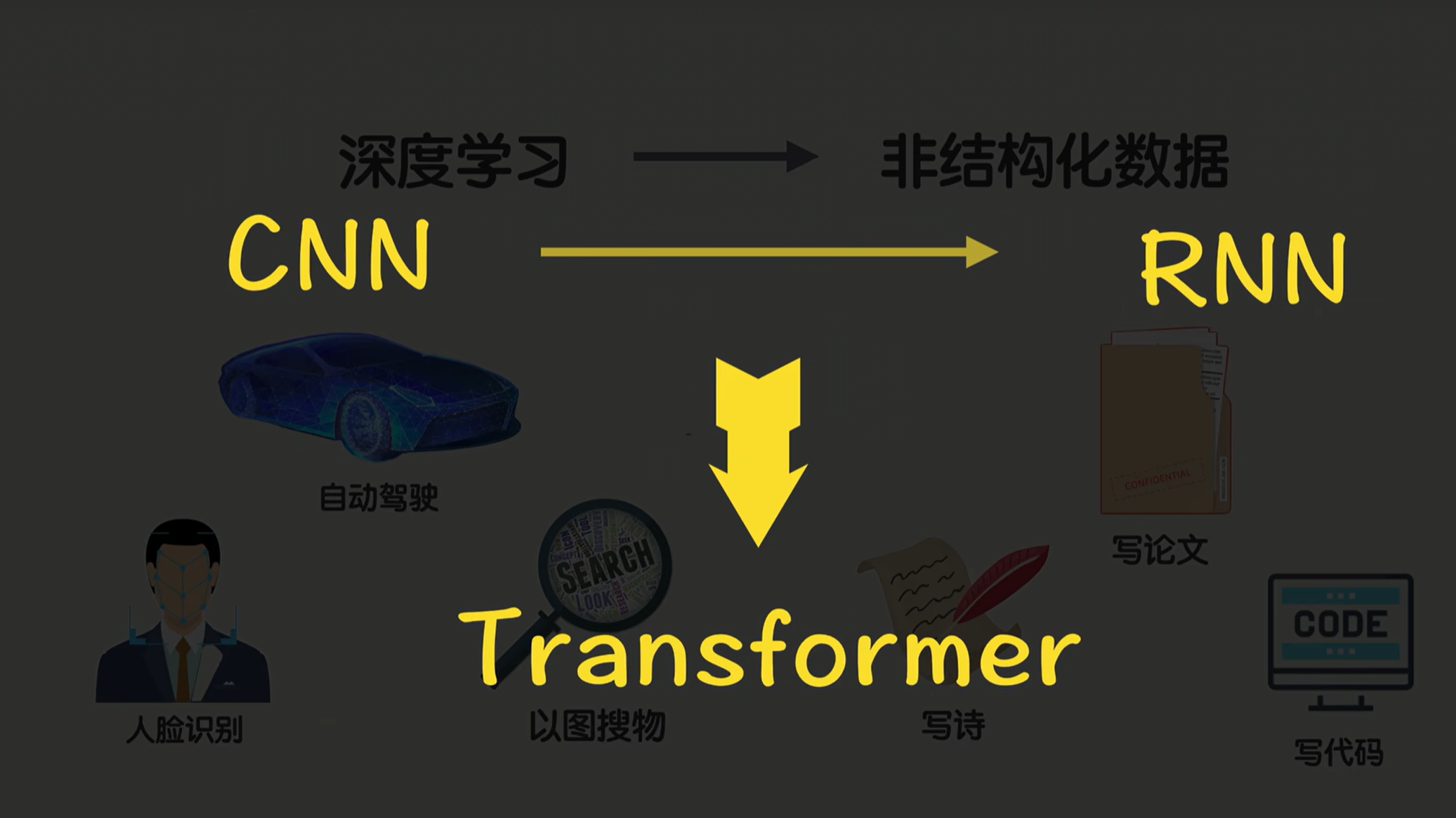
2.CNN
先来看一张照片,它本质就是像素的排列,但我们人眼为什么一看就知道这是猫啊?因为我们能抓住关键特征,比如说我看到尖耳朵、圆眼睛、毛茸茸啊。

那么AI就也学会了这一招,于是CNN卷积神经网络就诞生了。首先他像一个抓特征的猎人,用一个个的小探测器在图片上划来划去,这些小探测器的学名叫卷积核 。比如有个探测器专门找边缘,有个探测器专门找眼睛,有个探测器专门去找毛发纹理。他每划到一个地方,就要打个分,比如说这里像耳朵吗?这里像眼睛吗?匹配度高的话呢,它就亮红灯,匹配度低呢它就灭灯。那这个过程就叫卷积 x,他用小窗口扫描全局,去抓局部特征。

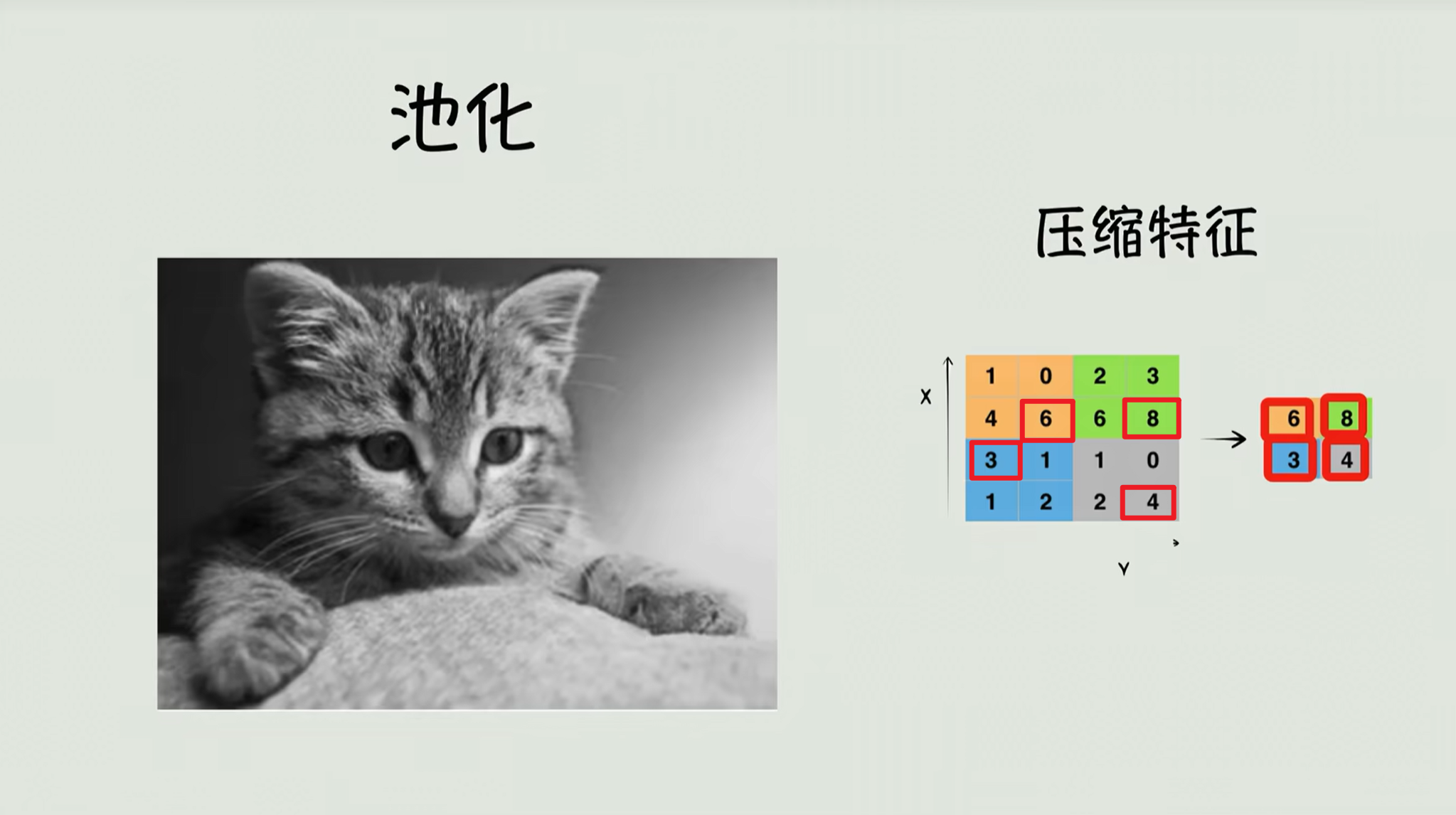
卷积神经网络还有另外一个操作叫池化 ,简单说来就是压缩照片。比如我们把像素矩阵的四个格子缩小成一个,只保留那个最亮的值,这样呢图片变小了,计算也变快了,但关键信息还都还在。就这么2个步骤。
CNN的经典网络AlexNet在2012年的ImageNet大赛上,直接把错误率干到了15.3%,大家知道,这个错误率可是比我们人眼识别照片的错误率都还要低。手机里的美颜、扫码自动对焦,背后都是他在干活。

但是CNN有一个致命的问题:看不懂文字 。为什么?

因为我们的文字它不是局部特征的组合,而是顺序决定意义。比如说我们看“我吃苹果”和“苹果吃我”,词一模一样,但顺序一换,意思天差地别。前面就是一个正常的剧情,后面就是一个科幻甚至恐怖的剧情。

CNN是不管顺序,他会把一个句子当做一个词袋子来处理,自然就傻了。于是专门为序列设计的RNN ,循环神经网络上场了。

3.RNN
循环神经网络RNN的核心思想特别像人一边读一边记笔记。
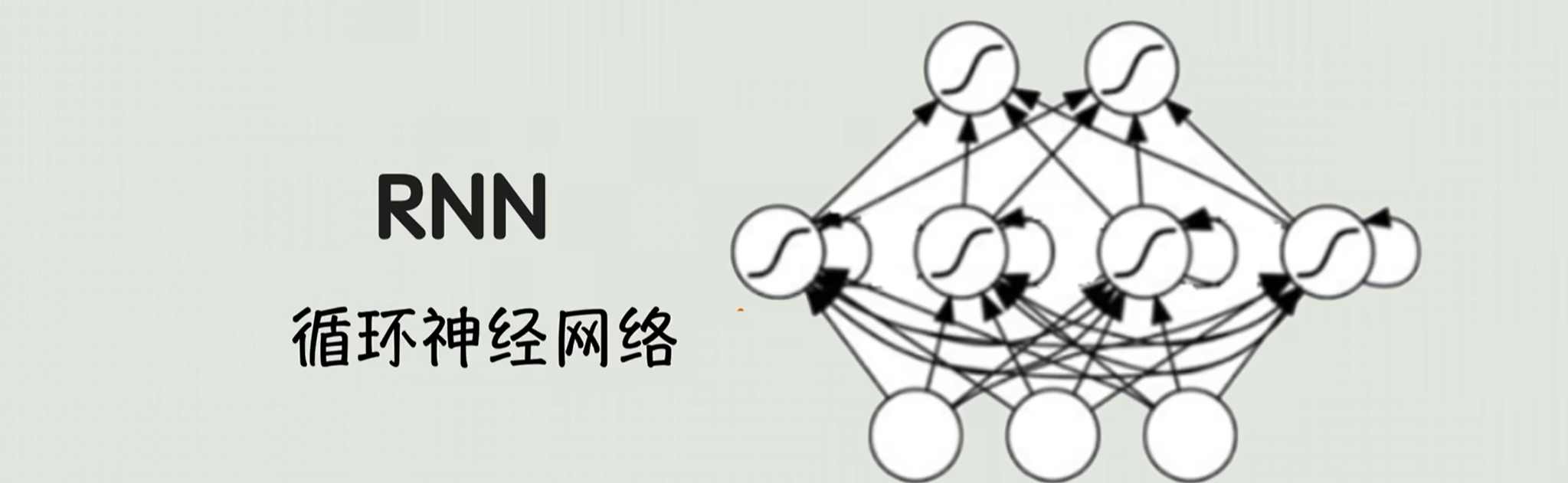
比如他看到“我吃苹果”,那就先读“我”哎就记下来,就主语是我;
再看到“吃”,结合前面的笔记,就知道是我在吃;
最后看到“苹果”,他就继续推我吃的对象是苹果。
那么这个笔记的学名叫隐藏状态。

RNN在处理文本时,它会按照词的顺序一个一个算,每处理一个词呢,就把这个词的信息存到隐藏状态里,下一个词的计算必须要用到这个隐藏状态。所以我们的RNN可以干摘要、翻译、写摘要、判断情感,早期NLP就全靠它。

但是RNN也有两个大毛病。第一太慢了 ,它必须一个词儿一个词儿算,不能并行计算 。1000个字的文章,它必须得等前面999个词儿算完,才能推到第1000个,这扛不住大数据啊!!!

第二个特点就是记性差 ,这个太长的句子,它开头的信息传到结尾就忘了。比如这句话:“他昨天去超市买了牛奶,因为他孩子喜欢喝什么啊?”那他看到“喝”,等到要填的时候,他可能早就忘了孩子是谁,就填不出牛奶。
这个问题叫做长距离依赖问题 ,也就是说RNN,记不住前因,所以文本的AI就一直被卡在这里。

4.Transformer
直到2017年一个王炸出现,当年谷歌就甩出一篇论文《Attention is All You Need》,也是现在学大模型的一个奠基性的文章。那么他就提出了一个全新的架构Transformer ,直接解决了RNN的两大难题,还成了现在所有大语言模型的地基,相当于我们AI界的奠基石了。 666666

五、生成对抗网络及其应用
前言
前面学的BP、CNN、RNN,都是“识别型”模型——给数据(图、文字),让模型分辨、预测;但人们需要模型能“创造”新数据(比如画一张不存在的猫、写一段连贯的文字),于是2014年Ian Goodfellow提出GAN,解决了“生成逼真数据”的核心需求,弥补了传统深度学习“只会看、不会造”的短板。

补充时间线:BP(1986)→ Hopfield(1982)→ CNN/RNN(深度学习基础)→ GAN(2014,生成式模型)→ Transformer(2017,更通用架构)
1.GAN 的核心原理
GAN 由 两个神经网络 组成,二者“互相对抗、互相学习”,最终达到一个平衡状态(纳什均衡),就像“造假者”和“警察”的博弈:
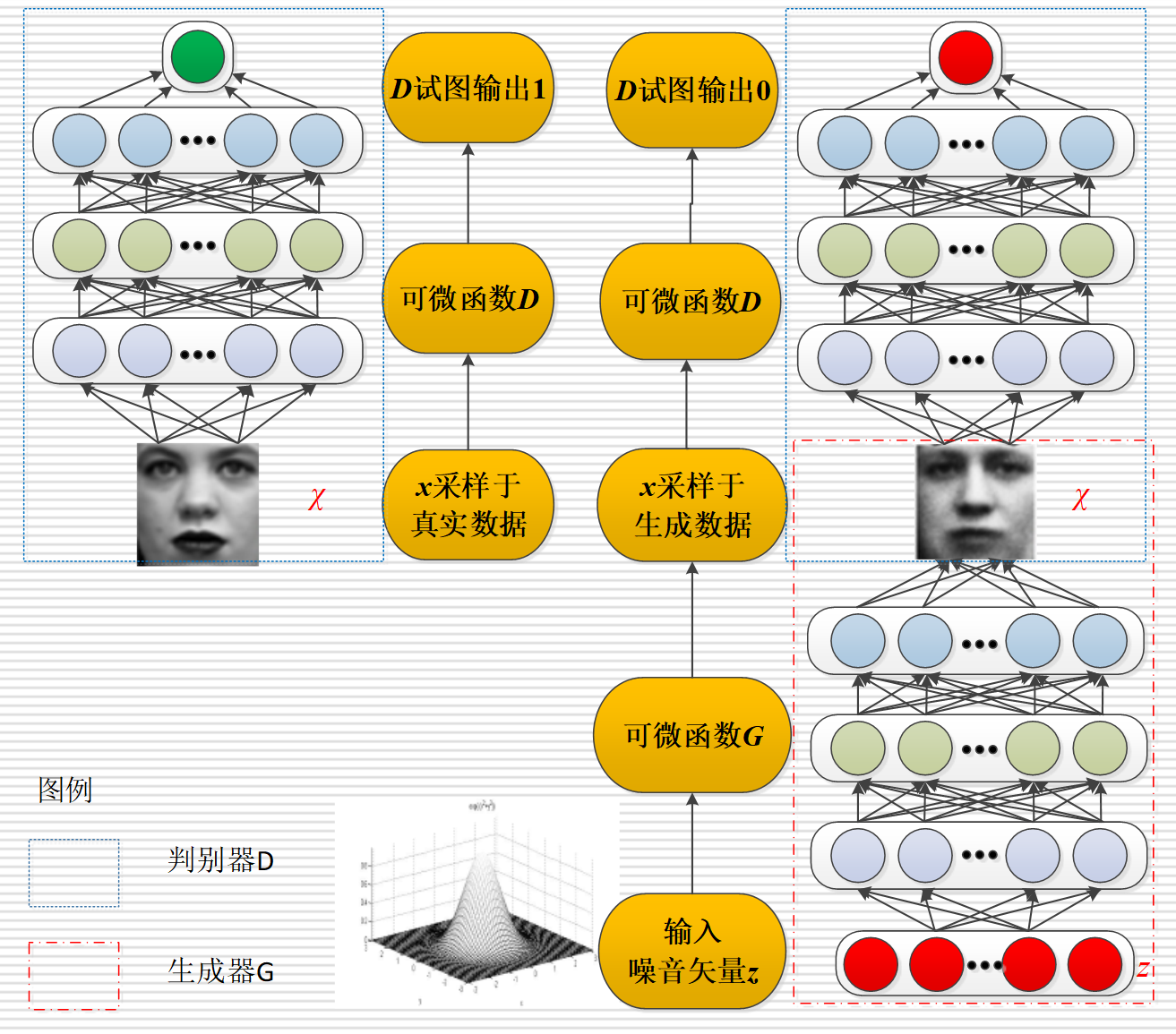
(1)生成器(Generator,G)—— 造假者
- 核心任务:生成“假数据”(比如假图像、假文字),努力模仿真实数据,争取让判别器认不出来。
- 结构基础:通常用 CNN(做图像生成,如DCGAN)、Transformer(做文字生成),本质是多层神经网络,靠 BP 算法调整权值。
- 通俗理解:就像一个学画画的人,一开始画得很假,慢慢模仿真实画作,越画越像。
(2)判别器(Discriminator,D)—— 警察
- 核心任务:分辨数据是“真的”还是“假的”(输入真实数据或生成器造的假数据),输出“是真”(接近1)或“是假”(接近0)的判断。
- 结构基础:也是多层神经网络(类似CNN分类器),同样靠 BP 算法训练,不断提升分辨能力。
- 通俗理解:就像一个文物鉴定师,一开始能轻松认出假货,慢慢被造假者的高超技艺难住,分辨越来越难。
2. 对抗训练的过程
- 初始化:生成器(G)和判别器(D)都是未训练的“新手”,G 生成的假数据很粗糙,D 能轻松分辨。
- 第一轮对抗:
- G 生成假数据,和真实数据一起交给 D 分辨;
- D 分辨后,通过 BP 算法调整自身权值,提升分辨能力(下次更难被骗);
- 同时,D 会把“哪里假”的信号反馈给 G,G 也通过 BP 算法调整权值,让下次生成的假数据更逼真。
- 反复迭代:不断重复“G 造假 → D 分辨 → 两者都用 BP 优化”的过程,直到达到平衡。
- 最终状态:G 生成的假数据,D 再也分不出真假(D 输出概率接近0.5),此时 G 就学会了生成和真实数据几乎一样的内容。
3.GAN 的应用场景
核心:生成逼真的“假数据”,覆盖多个领域,比传统生成模型效果更好:
- 图像领域(最常用):生成人脸、风景、动漫头像,图像修复(补全残缺图像)、图像风格转换(把照片变成油画);
- 文本领域:生成短文、诗歌、对话(早期文本生成,后来被 Transformer 主导,但仍是基础);
- 数据扩充:当真实训练数据不足时,用 GAN 生成假数据,辅助训练其他模型(比如用假医疗图像训练疾病诊断模型);




4.GAN 的优缺点
优点
- 生成效果好:生成的图像、文字等非常逼真,接近真实数据;
- 不用手动标注大量数据:训练时只需真实数据,不用像 BP、CNN 那样标注“输入-期望输出”;
- 灵活性高:可结合 CNN、Transformer 等结构,适配不同生成任务;
- 创新能力强:能生成全新的、不存在的内容(比如从未见过的人脸)。
缺点
- 训练不稳定:容易出现“模式崩溃”(生成的内容千篇一律,比如只生成一种人脸);
- 难以控制生成内容:原始 GAN 无法精准控制生成的细节(比如指定生成“戴眼镜的人脸”);
- 训练难度高:需要调整大量参数,新手容易训练失败;
- 缺乏可解释性:无法说清“生成器为什么能生成这样的内容”,黑箱操作;
- 后来被 Transformer 部分替代:在文本生成、多模态生成(文生图)领域,Transformer 架构(如 GPT、 diffusion 模型)效果更好,成为主流。