
智能计算及其应用
一、进化计算与基本遗传算法
前言

一、智能计算概述
- 定义:也叫计算智能,向大自然/生物界规律学习,设计求解复杂优化问题的算法簇,属于人工智能实用分支。
- 核心分类:智能优化方法分为两类
- 进化计算:模拟生物进化规律;
- 群智能算法:模拟动物群体协作行为。
- 应用场景:组合优化、机器学习、工业工件调度、物流配送路径规划等(传统方法难以解决的复杂问题)。
二、进化算法基础
- 核心概念:基于生物自然选择+遗传变异的搜索算法,通过选择、重组、变异三大操作实现解的“进化”,本质是留优汰劣,逐步逼近最优解。
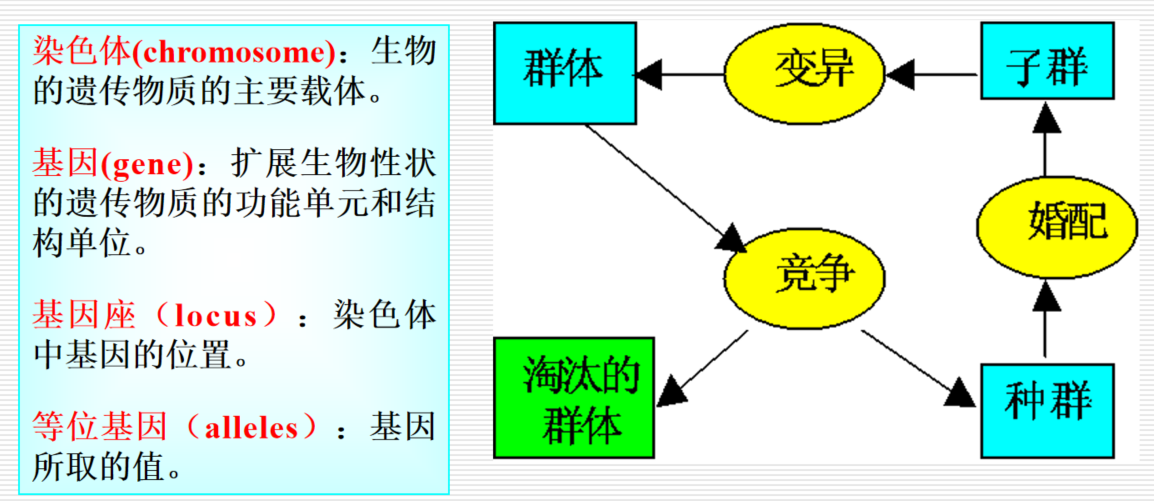
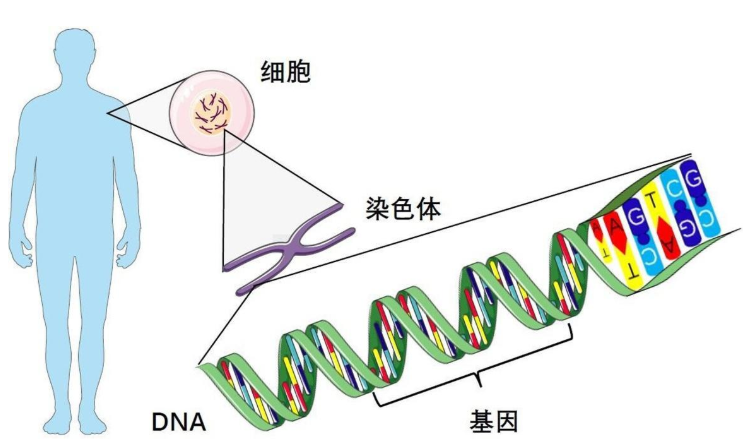
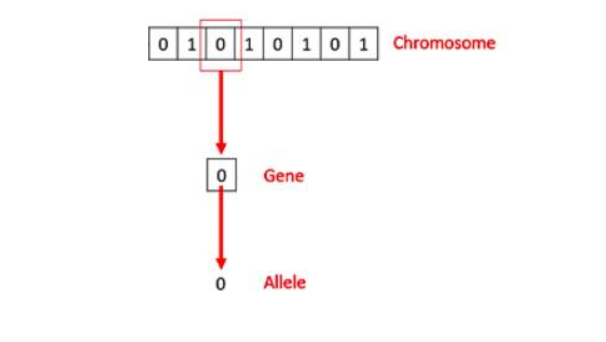
- 生物遗传概念与算法的简单对应:
染色体→解的编码;基因→编码的小单元。
- 核心设计原则(5个仅记2个)
- 收敛性原则:能收敛到全局最优解,避免局部最优;
- 生物类比原则:借鉴生物界规律改进算法,是算法优化的核心思路。
三、基本遗传算法
1. 核心思想
将问题的解模拟为生物个体,让解通过模拟生物的遗传、变异、选择过程实现“繁衍进化 ”,最终得到最优解 。
生物遗传与算法核心对应:
| 生物遗传概念 | 遗传算法对应内容 |
|---|---|
| 个体 | 问题的一个解 |
| 种群 | 一组解(初始解) |
| 染色体 | 解的编码(如01二进制串,向量) |
| 适应度 | 解的好坏(数值越大,解越优) |
| 婚配 | 交叉(两个解交换编码生成新解) |
| 变异 | 编码的单个单元发生变化(如0变1) |
通俗比喻:如同农民培育优良小麦品种,初始种子(初始解)→选优(选择)→杂交(交叉)→少量突变(变异)→反复培育→最优品种(最优解)。👈
2. 关键操作
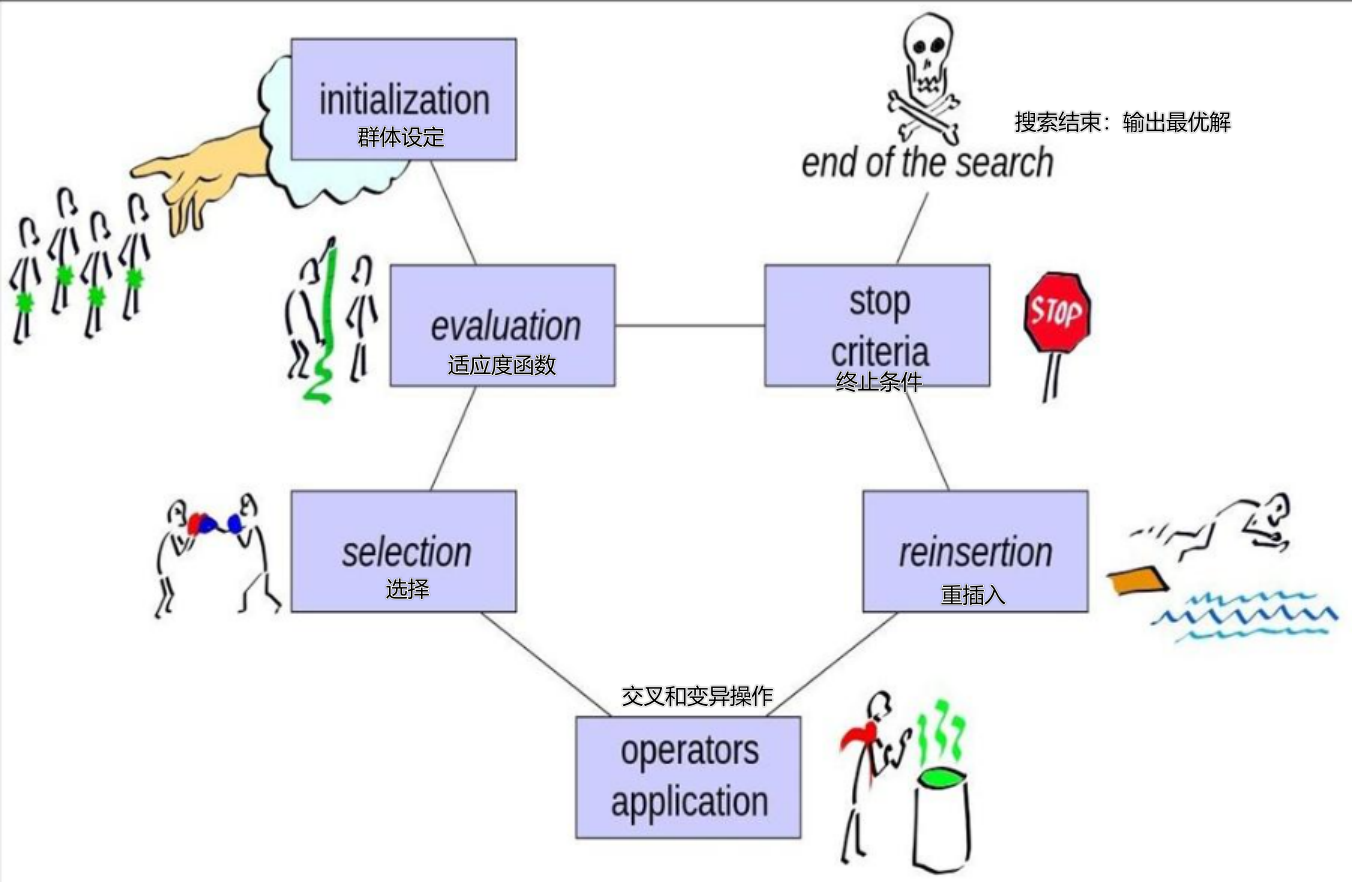
执行交叉(crossover)和变异(mutation)操作,生成新个体
reinsertion:将新生成的个体放回种群,替换掉较差的个体
evaluation:用适应度函数给每个个体打分,判断 “好不好”
| 操作名称 | 核心内容 | 关键要点/经验值 |
|---|---|---|
| 编码 | 把解翻译成算法能识别的形式,最基础为二进制编码(解→01串) | 优点:操作易实现;缺点:相邻数编码差异大(Hamming距离大),搜索效率低;Gray编码/实数编码为改进型,仅作了解 |
| 群体设定 | 从一群解(种群) 开始搜索,初始种群最常用随机生成 | 种群规模:20-100(平衡搜索效果与计算效率,太小易局部最优,太大计算慢) |
| 适应度函数 | 评价解的好坏,是算法的“裁判” | 遗传算法默认最大化适应度;最大化问题:直接用目标函数;最小化问题:目标函数取倒数(保证非负);尺度变换:解决“过早收敛/停滞现象” |
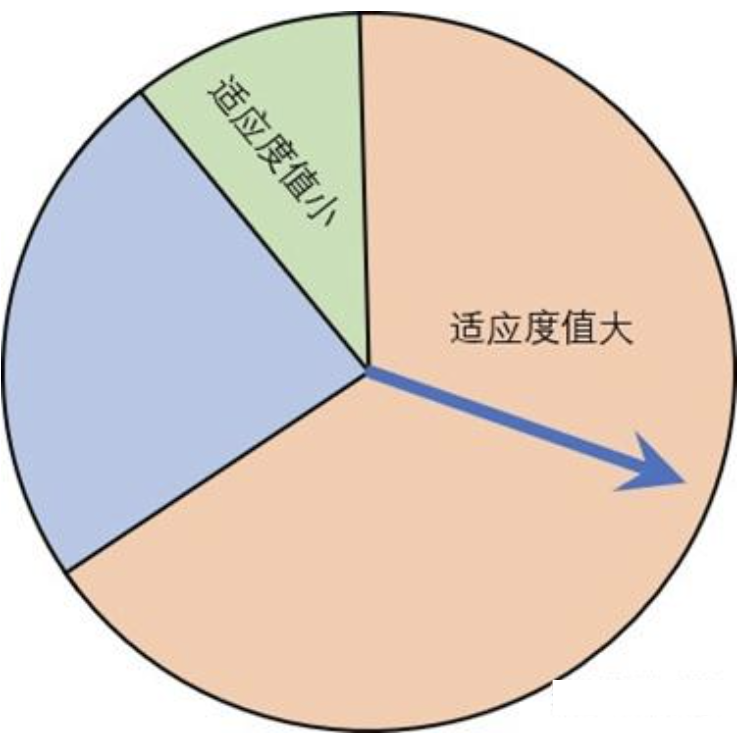
| 选择 | 从种群中挑选优解,使其有机会繁衍,核心“适应度越高,选中概率越大” | 最常用:转盘赌选择(适应度对应转盘面积,概率与面积成正比)+精英保留(最优解直接保留到下一代,避免被破坏) |
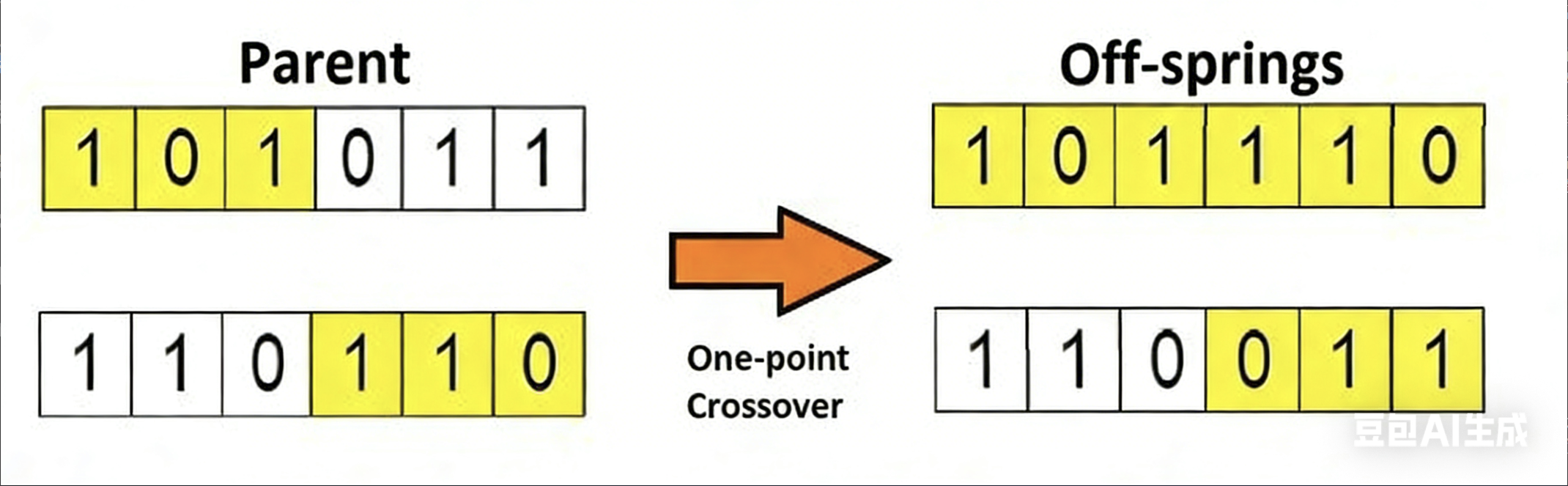
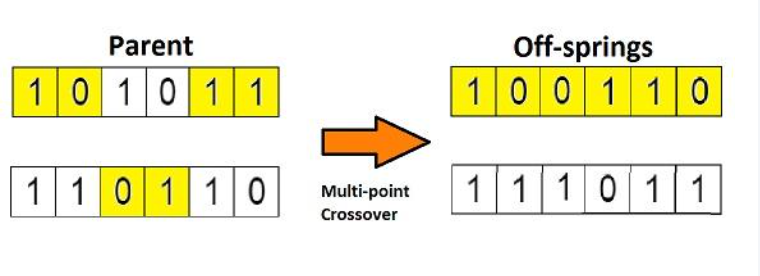
| 交叉 | 模拟生物杂交,两个父代解交换部分编码生成子代解,是产生新解的核心 | 最常用一点交叉(随机选交叉点,交换点后编码);交叉概率一般0.6-0.9 |
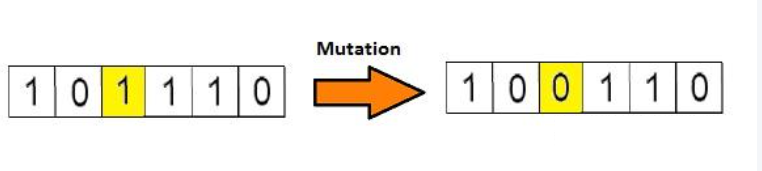
| 变异 | 随机改变编码的单个单元,模拟基因突变 | 最常用位点变异;变异概率极低(0.001-0.01),目的是保持种群多样性,避免局部最优;概率太高会变成随机搜索 |

一般流程 : 初始化种群(随机生成N个解,编码)→计算适应度(评价所有解的好坏)→判断停止条件(迭代次数达标/找到最优解/适应度收敛,不满足则继续)→选择(转盘赌+精英保留挑优解)→交叉(两两配对,按概率生成新解)→变异(按低概率调整编码,生成新一代种群)→返回“计算适应度”迭代,直至满足停止条件,输出最优解。
3. 核心特点
- 对问题要求低 :无需问题连续、可微,能解传统方法搞不定的复杂非线性优化问题;
- 群体搜索 :从多个解开始,支持并行计算,搜索效率高;
- 全局搜索能力强 :交叉+变异覆盖整个解空间,不易陷入局部最优;
- 通用性强 :仅修改编码和适应度函数,即可适配各类优化问题。
遗传算法在以下场景具有明显优势: 👇
- 目标函数不可导、不连续、无解析表达式;
- 解空间为离散、整数或组合优化问题;
- 函数多峰,传统方法易陷入局部最优;
- 优化变量多、维度高;
- 约束复杂、非线性、非凸;
- 需要全局最优解而非局部最优。
反过来:什么时候不要用遗传算法?
- 函数简单、连续、可导
- 单峰函数
- 能直接求导、解方程
1.1 基本遗传算法应用
前言
遗传算法代码,用来求解函数 在区间 上的最大值。代码包含详细注释,同时我会逐段解释核心逻辑,让你能直观理解算法的运行过程。
1. 遗传算法步骤:
1. 编码
把变量 (x) 变成一串二进制数字(染色体)。
例:,用 10 位二进制表示。
1111111111→ 对应 (x=10)0000000000→ 对应 (x=0)
2. 初始化种群
随机生成一串一串的二进制,比如:
10101010100110011001
每个串就是一个“个体”,代表一个可能的 (x)。
3. 计算适应度
适应度函数直接用:
把二进制解码成 ,算 ,值越大说明这个个体越优秀。
4. 选择
谁的 大,谁被选中的概率就高。
比如:
- (x=9),适应度 81
- (x=2),适应度 4
算法会优先留下 (x=9) 这类个体。
5. 交叉
两个个体交换部分基因,产生新个体。
例:
父1:1010 | 101010
父2:0101 | 010101
交叉后:1010 010101
相当于产生一个新的 。
6. 变异
很小概率把某一位 0 变 1、1 变 0。
例:1010101010 → 1010101011
让 (x) 稍微变一点,避免算法卡住。
7. 迭代进化
重复“选择→交叉→变异→算适应度”,
一代代进化,(x) 越来越接近 10。
8. 输出结果
最后适应度最大的个体,解码得到 (x≈10),
就是 的最大值点。
2. 完整代码实现
import random
import math
import matplotlib.pyplot as plt
import numpy as np
#中文显示
plt.rcParams['font.sans-serif'] = ['KaiTi']
# ===================== 1. 基础参数与函数 =====================
# 目标函数
def target_function(x):
return x ** 2
# 遗传算法参数
POPULATION_SIZE = 30 # 种群大小
CHROMOSOME_LENGTH = 10 # 染色体长度
CROSSOVER_RATE = 0.7 # 交叉概率
MUTATION_RATE = 0.01 # 变异概率
GENERATION = 50 # 迭代代数
X_MIN = 0 # x最小值
X_MAX = 10 # x最大值
# ===================== 2. 遗传算法核心函数 =====================
# 解码:二进制染色体转十进制x
def decode_chromosome(chromosome):
decimal = int(chromosome, 2)
x = X_MIN + (decimal / (2 ** CHROMOSOME_LENGTH - 1)) * (X_MAX - X_MIN)
return x
# 计算适应度
def calculate_fitness(chromosome):
x = decode_chromosome(chromosome)
return target_function(x)
# 初始化种群
def init_population():
population = []
for _ in range(POPULATION_SIZE):
chromosome = ''.join([str(random.randint(0, 1)) for _ in range(CHROMOSOME_LENGTH)])
population.append(chromosome)
return population
# 选择(轮盘赌)
def selection(population):
fitness_list = [calculate_fitness(chrom) for chrom in population]
total_fitness = sum(fitness_list)
probabilities = [fit / total_fitness for fit in fitness_list]
def select_one():
r = random.random()
cumulative_prob = 0
for i, prob in enumerate(probabilities):
cumulative_prob += prob
if cumulative_prob >= r:
return population[i]
new_population = [select_one() for _ in range(POPULATION_SIZE)]
return new_population
# 交叉(单点交叉)
def crossover(parent1, parent2):
if random.random() < CROSSOVER_RATE:
cross_point = random.randint(1, CHROMOSOME_LENGTH - 1)
child1 = parent1[:cross_point] + parent2[cross_point:]
child2 = parent2[:cross_point] + parent1[cross_point:]
return child1, child2
else:
return parent1, parent2
# 变异(位翻转)
def mutation(chromosome):
chromosome_list = list(chromosome)
for i in range(CHROMOSOME_LENGTH):
if random.random() < MUTATION_RATE:
chromosome_list[i] = '1' if chromosome_list[i] == '0' else '0'
return ''.join(chromosome_list)
# ===================== 3. 可视化核心逻辑 =====================
def genetic_algorithm_with_visualization():
# 初始化画布
plt.ion() # 开启交互模式
fig, ax = plt.subplots(figsize=(10, 6))
# 绘制目标函数曲线
x_range = np.linspace(X_MIN, X_MAX, 1000)
y_range = target_function(x_range)
ax.plot(x_range, y_range, 'b-', label='$f(x)=x^2$')
ax.set_xlabel('x')
ax.set_ylabel('f(x)')
ax.set_title('遗传算法求解 $f(x)=x^2$ 最大值 (迭代过程)')
ax.set_xlim(X_MIN, X_MAX)
ax.set_ylim(0, 110)
ax.grid(True)
ax.legend()
# 初始化种群
population = init_population()
# 迭代进化 + 实时绘图
for gen in range(GENERATION):
# 遗传算法核心步骤
population = selection(population)
new_population = []
for i in range(0, POPULATION_SIZE, 2):
parent1 = population[i]
parent2 = population[i + 1] if i + 1 < POPULATION_SIZE else population[i]
child1, child2 = crossover(parent1, parent2)
new_population.append(child1)
new_population.append(child2)
population = new_population[:POPULATION_SIZE]
population = [mutation(chrom) for chrom in population]
# 提取当前种群的x和y值
x_vals = [decode_chromosome(chrom) for chrom in population]
y_vals = [calculate_fitness(chrom) for chrom in population]
# 找到当前最优解
fitness_list = y_vals
best_fitness = max(fitness_list)
best_index = fitness_list.index(best_fitness)
best_x = x_vals[best_index]
best_y = best_fitness
# 清除上一代的点,绘制新一代
ax.clear()
ax.plot(x_range, y_range, 'b-', label='$f(x)=x^2$')
# 绘制种群所有个体(蓝色散点)
ax.scatter(x_vals, y_vals, c='blue', alpha=0.6, label='种群个体')
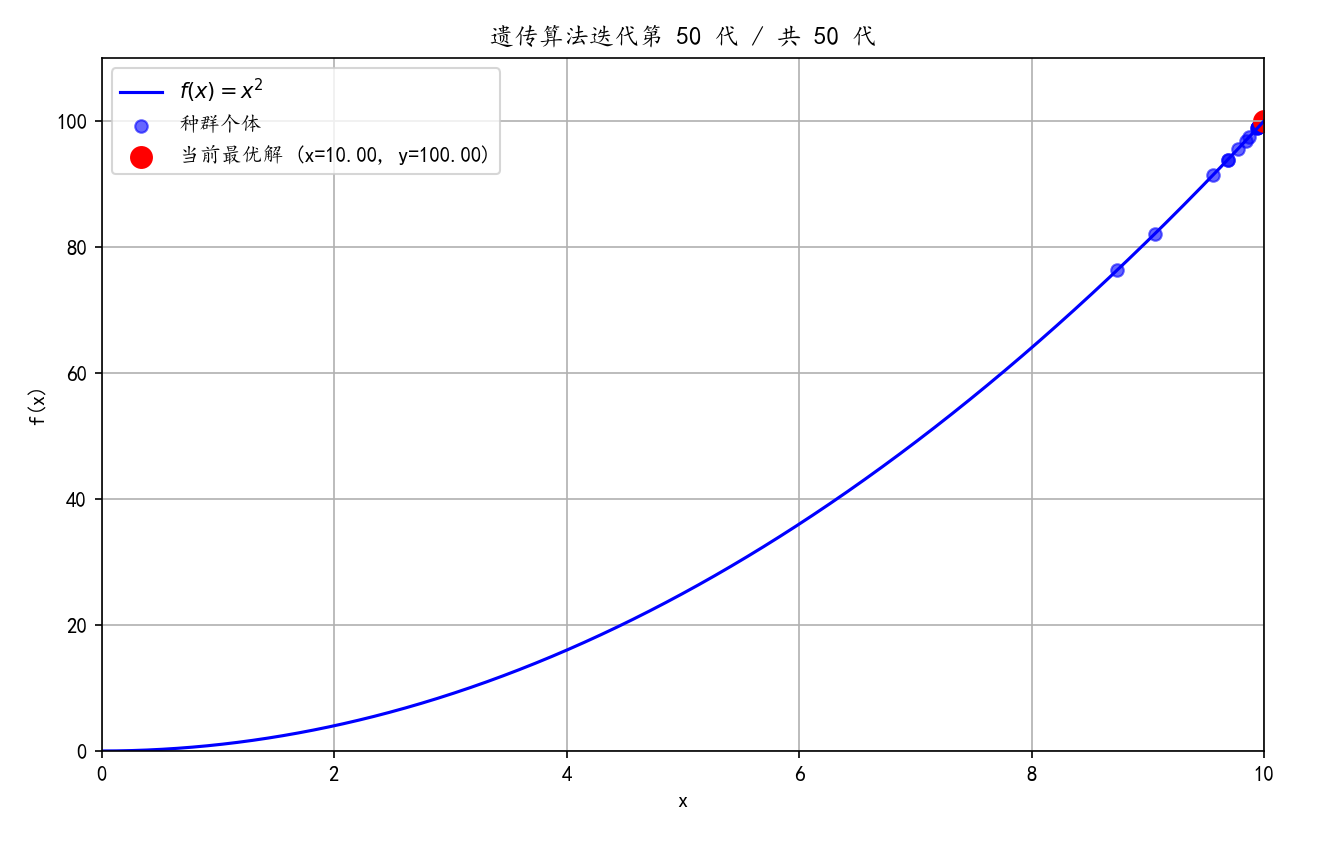
# 绘制当前最优解(红色大圆点)
ax.scatter(best_x, best_y, c='red', s=100, label=f'当前最优解 (x={best_x:.2f}, y={best_y:.2f})')
ax.set_xlabel('x')
ax.set_ylabel('f(x)')
ax.set_title(f'遗传算法迭代第 {gen + 1} 代 / 共 {GENERATION} 代')
ax.set_xlim(X_MIN, X_MAX)
ax.set_ylim(0, 110)
ax.grid(True)
ax.legend()
# 刷新画布
plt.draw()
plt.pause(0.2) # 暂停0.2秒,方便观察
# 迭代结束后,绘制最终结果
plt.ioff() # 关闭交互模式
ax.clear()
ax.plot(x_range, y_range, 'b-', label='$f(x)=x^2$')
ax.scatter(x_vals, y_vals, c='blue', alpha=0.6, label='最终种群')
ax.scatter(best_x, best_y, c='red', s=150, label=f'全局最优解 (x={best_x:.2f}, y={best_y:.2f})')
ax.set_xlabel('x')
ax.set_ylabel('f(x)')
ax.set_title('遗传算法求解完成 - 最终结果')
ax.set_xlim(X_MIN, X_MAX)
ax.set_ylim(0, 110)
ax.grid(True)
ax.legend()
plt.show()
return best_x, best_y
# ===================== 4. 运行程序 =====================
if __name__ == "__main__":
best_x, best_y = genetic_algorithm_with_visualization()
print(f"\n最终结果:")
print(f"最优x值:{best_x:.4f}")
print(f"函数最大值:{best_y:.4f}")总结
- 核心流程:遗传算法求最值的关键是「编码→初始化种群→适应度计算→选择→交叉→变异→迭代」,通过模拟自然进化逐步逼近最优解。
- 适应度函数:求最大值且目标函数非负时,可直接用目标函数作为适应度;若求最小值或函数值为负,需对目标函数做反向/平移修正。
- 核心优势:无需依赖函数的连续性、可导性,能在复杂解空间中找到全局近似最优解,适合解决传统方法难以处理的优化问题。
二、遗传算法改进
前言
1.遗传算法的改进算法
基本遗传算法缺陷:易局部最优、收敛慢、交叉/变异固定概率适配性差 (说白了就是比较蠢);
👉改进核心目标:平衡收敛速度与全局搜索能力,实际应用优先选改进算法。👇
| 改进算法 | 核心改进点(通俗理解) | 解决的原算法问题 | 核心通俗理解 🍐 |
|---|---|---|---|
| 双倍体遗传算法 | 为每个解设计显性+隐性两个染色体,显性评价好坏,隐性“记忆”优秀基因 | 收敛速度慢;低变异概率下种群多样性不足 | 一个解,2套方案,主用+备用 |
| 双种群遗传算法 | 设计两个独立种群,各自进化,每轮交换种群内的优秀解 | 单一种群易陷入局部最优,无法跳出搜索瓶颈 | 两个群,分开算,互传好解 |
| 自适应遗传算法 | 让交叉/变异概率随适应度动态变化(优解低概率,差解高概率;解趋同则增大概率,解分散则减小概率) | 固定概率无法适配算法进化过程,易早收敛或停滞 | 看好坏,调规则,优解保护、差解多改 |
2. 遗传算法改进应用
2.1. 函数优化 / 数学最优解求解
- 求复杂函数最大值、最小值
- 多维、非线性、不可导函数优化
改进作用:解决基本 GA 容易陷入局部最优、收敛慢 。
2.2. 组合优化问题
- 旅行商问题(TSP,最短路径)
- 背包问题(选物品价值最大)
- 调度问题(车间排班、工序安排)
改进作用:双种群、精英保留能大幅提高搜索效率。
2.3. 神经网络优化(GA-BP)
- 用遗传算法优化神经网络的权值、阈值
- 避免 BP 神经网络收敛慢、易局部最优
典型改进:自适应遗传算法 + 精英保留。
2.4. 路径规划 / 机器人路径优化
- AGV 小车、无人机、移动机器人避障路径
改进作用:双种群 + 小生境保持多样性,找到全局最短路径。
2.5. 电力系统优化
- 电网经济调度(发电成本最低)
- 无功优化、负荷分配
改进作用:自适应 GA 提高收敛速度,适合实时控制。
2.6. 图像处理与特征选择
- 图像分割、特征提取、参数寻优
- 选择最有用的特征,减少冗余
改进作用:精英保留防止丢失最优特征组合。
2.7. 控制系统参数整定
- PID 参数自动优化(Kp、Ki、Kd)
- 控制器参数寻优
改进作用:自适应遗传算法比手动调参快、准、稳。
2.8. 物流、供应链、资源分配
- 仓库选址、配送路线优化、资源调度
改进作用:双种群遗传算法跳出局部最优,找到全局最优分配方案。
三、群智能核心算法
前言

1. 群智能算法背景
- 核心思想 :模拟动物群体协作行为,通过信息共享+协作搜索实现优化;个体能力简单,但群体能表现出高智能。
- 核心特点 :与进化计算不同,不模拟生物进化,侧重“群体协作”;
- 经典算法 :粒子群优化算法(PSO)、蚁群算法(ACO)
- 通俗比喻 :蜜蜂集体采蜜,单个蜜蜂找不到花蜜,群体协作可快速定位花蜜位置。
3.1. 粒子群优化算法
前言
1 .场景:
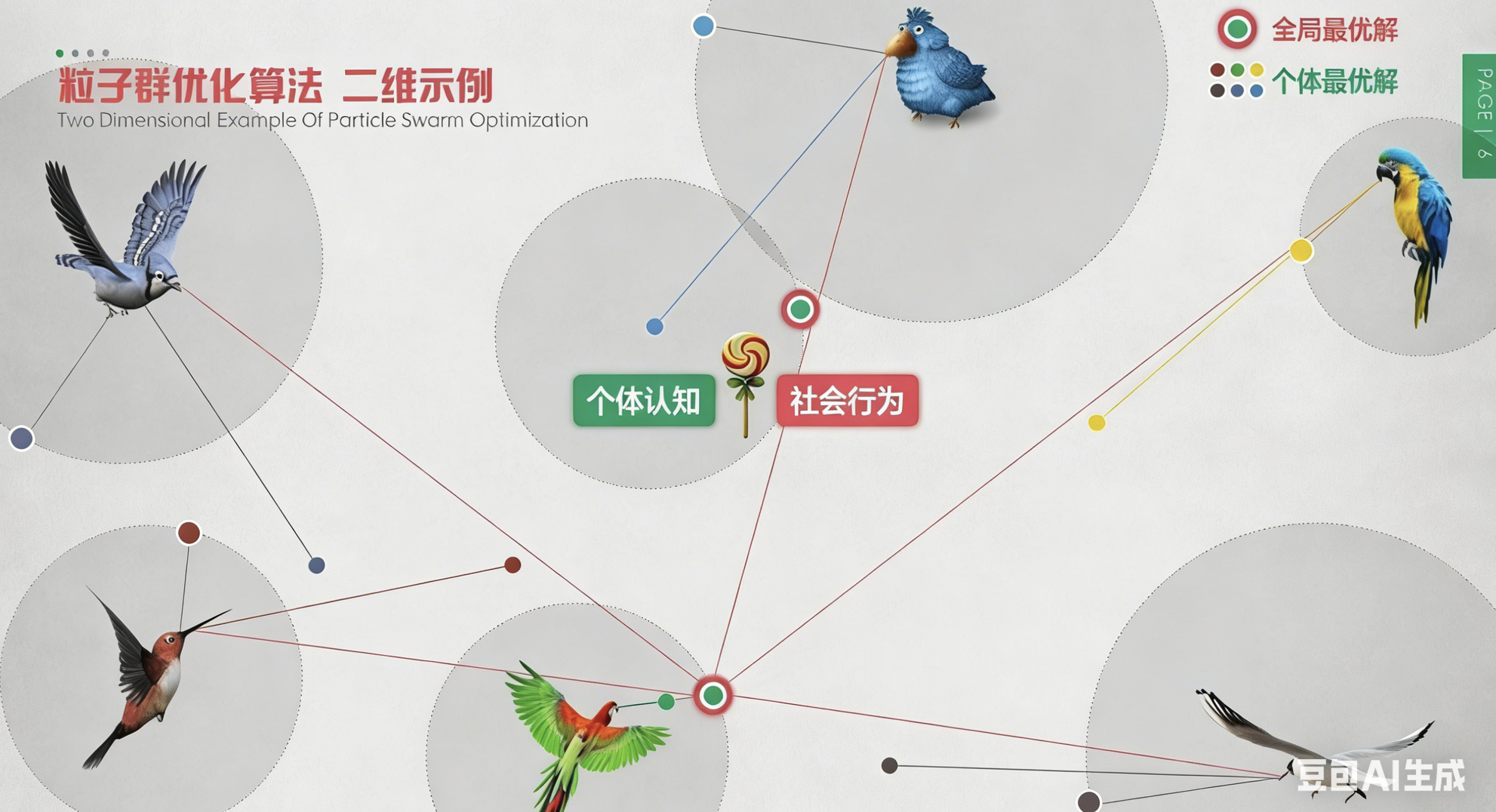
一群鸟在随机搜寻食物,在这个区域里只有一块食物,所有的鸟都不知道食物在哪里,但是它们知道当前的位置离食物还有多远。
鸟群觅物最优策略:
最简单有效的就是搜寻目前离食物最近的鸟的周围区域。小鸟们的目标很简单,要在这一带找到食物最充足的位置安家、休养生息。 试着想一下一群鸟在寻找食物,在这个区域中只有一只虫子,所有的鸟都不知道食物在哪。
但是若:
- 它们知道自己的当前位置距离食物有多远;
- 同时它们知道离食物最近的鸟的位置。
想一下这时候会发生什么?👈
- 鸟A:哈哈哈,原来虫子离我最近!
- 鸟B,C,D:我得赶紧往 A 那里过去看看!
- 同时各只鸟在位置不停变化时候,离食物的距离也不断变化,所以一定有过离食物最近的位置,这也是它们的一个参考。
- 某鸟:我刚刚的位置好像靠近了食物,我得往那里靠近!(鸟类的这几种想法是粒子群算法的核心)
2. 产生背景+基本思想
- 背景 :1995年由美国科学家提出,灵感来自鸟群觅食行为;
- 核心模拟 :将解映射为搜索空间中的粒子,粒子以一定速度飞行,通过跟踪两个“极值”调整飞行方向,最终聚集到最优解位置;
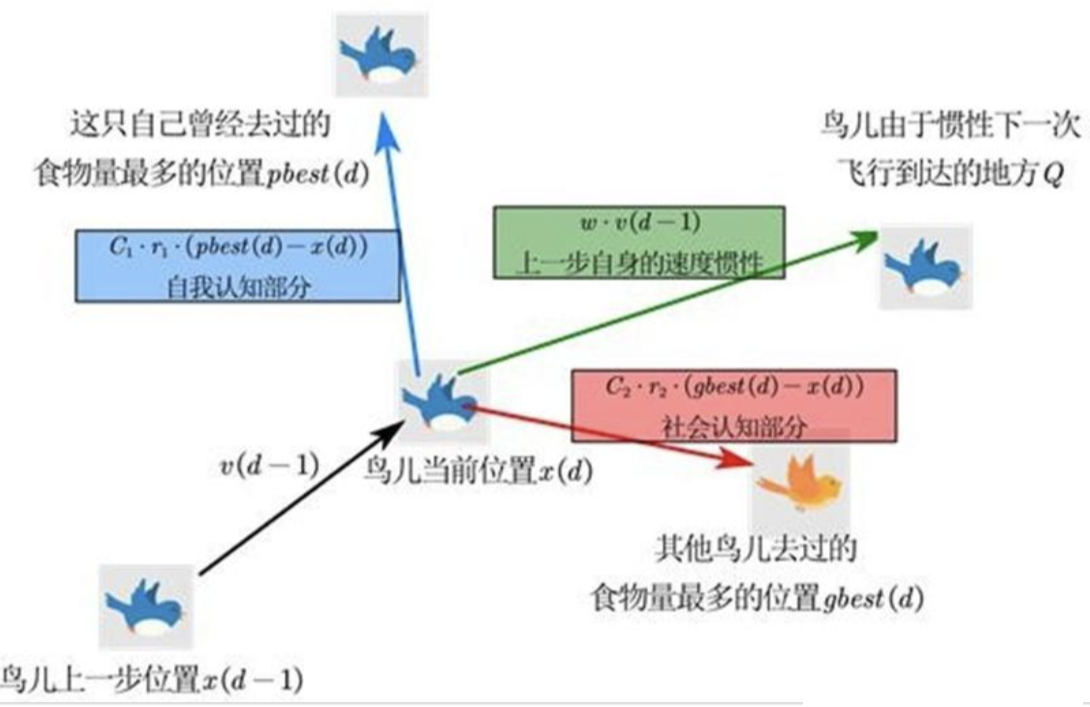
- 核心概念对应(鸟群觅食→PSO) :
- 鸟→粒子;
- 鸟的位置→粒子在搜索空间的位置;
- 鸟离食物的距离→粒子适应度;
- 自己曾离食物最近位置→个体极值(pbest);
- 整个鸟群离食物最近位置→全局极值(gbest)。
3. 粒子群优化算法PSO - 基本原理
基于以上情况,鸟群在该地方的搜索策略如下: 👇
- 每只鸟随机找一个地方,评估这个地方的食物量;
- 所有的鸟一起开会,选出这群鸟遇到的食物量最多的地方作为安家的候选点G(未来);
- 每只鸟回顾自己的旅程,记住自己曾经去过的食物量最多的地方P(过去);
- 每只鸟为找到食物量更多的地方,于是向着G飞行,但是呢,不知是出于选择困难症还是对P的留恋,或者是对 G的不信任,小鸟向G飞行时,时不时也向P飞行,其实它自己也不知道到底是G的食物多还是向P的食物多。毕竟G和P方向的食物都比较多;
- 另外还考虑鸟儿飞行的惯性,也就是鸟儿无法立即停下来,由于惯性它会下一次飞行到达点Q(当前);
- 又到开会时间,如果小鸟们决定停止寻找,则会选择G来安家;否则继续2->3->4->5->6来寻找栖息地。
4.核心流程
初始化粒子群(随机生成粒子,设定初始位置+速度)→计算适应度(评价粒子好坏)→更新极值(粒子适应度更优则更新pbest;群体出现更优解则更新gbest)→更新速度和位置(粒子按“自身惯性+pbest个体认知+gbest群体社会”调整飞行方向和速度)→判断停止条件(达标则输出gbest对应最优解,不达标则迭代)。
5. 特点+应用场景
- 核心特点:结构简单、参数少、收敛速度快,易实现、易调参;
- 适配场景:优先解决连续优化问题(如神经网络调参、电力系统参数优化、函数寻优);改进编码后可扩展至离散问题(如物流车辆路径规划)。
3.2. 蚁群算法
前言
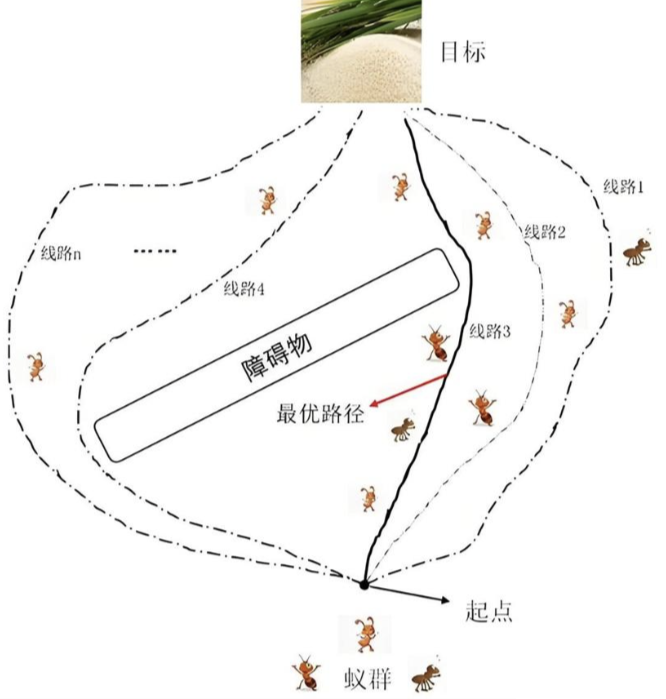
1. 产生背景+基本思想
- 背景:90年代初由意大利科学家Marco Dorigo提出,灵感来自蚂蚁觅食行为;
- 核心机制:信息素正反馈(蚂蚁走最短路径→释放更多信息素→吸引更多蚂蚁→信息素更浓;长路径信息素逐步挥发,最终所有蚂蚁走最短路径);
- 信息素累积:蚂蚁在觅食时会在其经过的路径上释放一种称为信息素的物质,其他蚂蚁能够感知环境中的信息素并倾向于选择信息素浓度较高的路径。
- 正反馈机制:随着时间的推移,信息素的积累和挥发形成了一种正反馈机制,使得蚁群能够找到最短路径到达食物源。
- 通俗理解:让“虚拟蚂蚁”在解空间搜索,优解路径释放更多信息素,劣解路径信息素挥发,最终蚂蚁聚集到最优解路径;
- 核心适配:与PSO互补,优先解决离散组合优化问题。
2. 核心思想

- 蚂蚁利用信息素进行通信,蚂蚁会在经过的路径上释放信息素,其他蚂蚁能够感知环境中的信息素并选择信息素浓度较高的路径。
- 蚂蚁具有记忆行为,一个蚂蚁一般不会选择相同的路径两次。
- 蚂蚁具有集群活动,某条路径上通过的蚂蚁越多,路径上留下的信息素就越高,信息素还会挥发。
- 蚁群算法的一个重要原则是避障原则,即蚂蚁不能穿过障碍物。此外,蚂蚁在刚离开窝或者食物附近播散的信息素最多,信息素会自然挥发。
蚁群算法最早用来求解旅行商问题(Traveling Salesperson Problem, TSP),并且表现出了很大的优越性。它具有分布式特性、鲁棒性强并且容易与其他算法结合,但是同时也存在收敛速度慢、容易陷入局部最优等缺点。
3. 特点+应用场景
- 核心特点 :信息素正反馈(优解不断强化)、全局搜索能力强、适配离散组合优化;
- 应用场景 :旅行商问题(TSP)、柔性作业车间调度(贴近实际工厂)、物流车辆路径规划、网络路由优化(工业调度领域最常用的智能计算算法之一);
- 蚂蚁数量经验值 :与问题规模相当(如10个城市设10只蚂蚁)。
四、课程核心总结
提示
| 算法 | 模拟对象 | 核心操作/机制 | 核心适配场景 | 关键优势 |
|---|---|---|---|---|
| 基本遗传算法 | 生物进化 | 选择、交叉、变异 | 复杂非线性优化问题(连续/离散均可) | 全局搜索强、通用性高 |
| 粒子群优化算法(PSO) | 鸟群觅食 | 个体极值(pbest)+全局极值(gbest) | 连续优化问题(可扩展至离散) | 结构简单、参数少、收敛快 |
| 蚁群算法(ACO) | 蚂蚁觅食 | 信息素正反馈(挥发+累积) | 离散组合优化问题 | 正反馈强化优解、适配工业调度/路径规划 |