
搜索求解策略
提示
本讲聚焦人工智能最基础、最核心的问题求解方法——搜索技术。我们将结合通俗语言、生活实例与符号示意图,把生涩的状态空间、盲目搜索、启发式搜索等核心知识点讲透彻,内容兼顾课堂讲授的逻辑性与课后复习的实用性,助力大家快速理解掌握。
一、搜索的概念
前言
1. 什么是搜索?
通俗定义:搜索,就是从已知的初始状态出发,遵循既定规则,一步步试探、寻找,最终找到一条能够到达目标状态的路径或操作序列的过程。
AI视角:在人工智能领域,许多问题的本质都是搜索问题。我们可以用简单的符号示意图来理解(□表示任意状态,→表示状态之间的转移):
初始状态 □ → □ → □ → ... → 目标状态 □生活中常见的搜索场景的例子:
- 走迷宫:从入口(初始状态)寻找通往出口(目标状态)的路径;
- 下棋:从当前棋局(初始状态)寻找能获胜的落子顺序(操作序列);
- 路径规划:从出发地(初始状态)寻找前往目的地(目标状态)的最优路线;
- 逻辑推理:从已知条件(初始状态)推出最终结论(目标状态)。
2.搜索的策略
1,搜索的方向
就像走路有方向,搜索也有3种走法:
- 正向搜索:从起点(初始状态)往终点(目标状态)走(最常用)
- 逆向搜索:从终点往起点倒着走(适合终点很明确的问题)
- 双向搜索:起点和终点同时往中间走,效率更高(像两队人碰头)
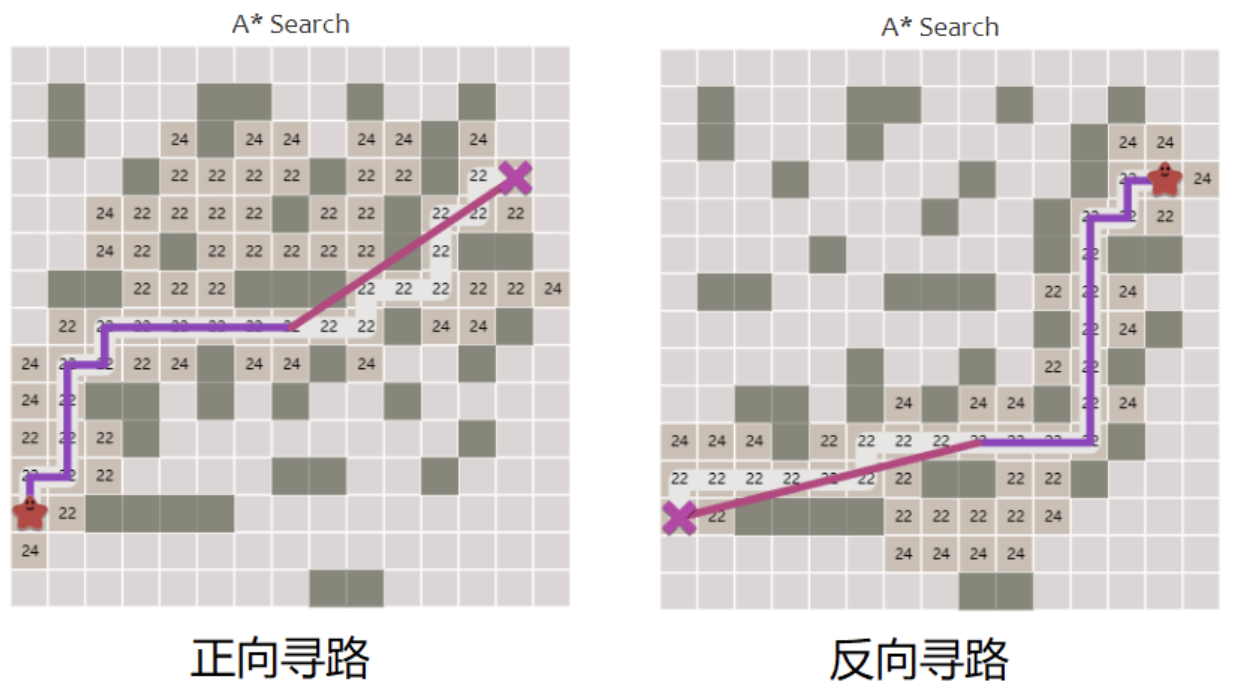
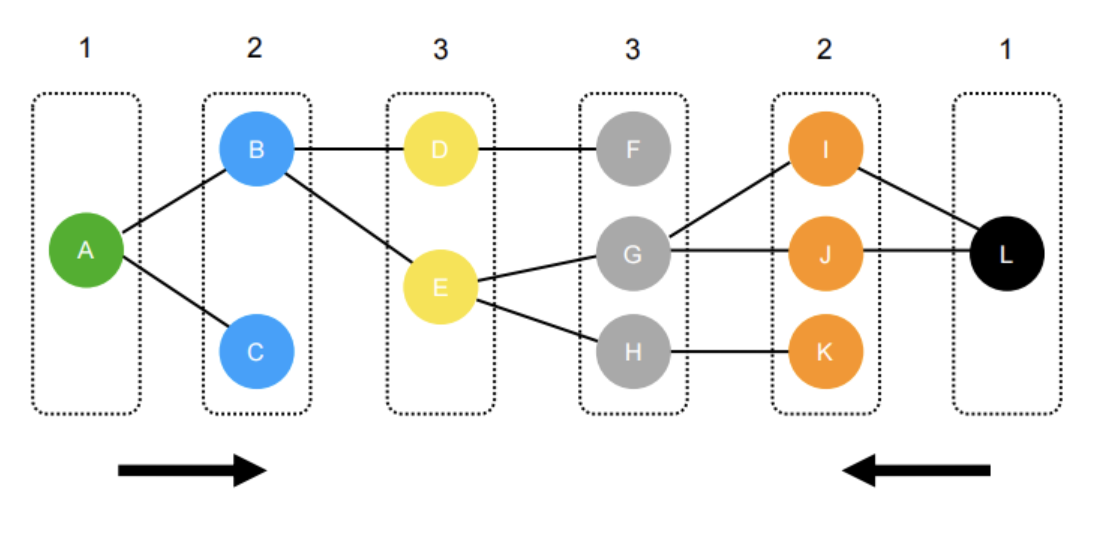
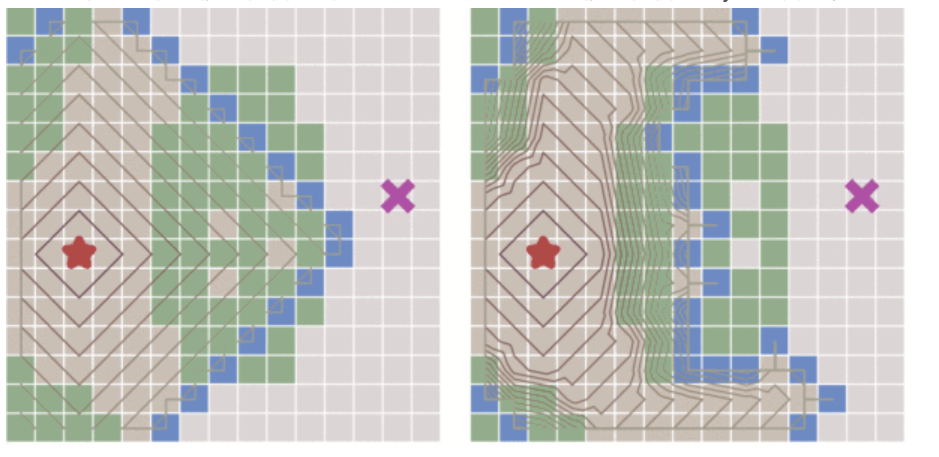
2. 盲目搜索和启发式搜索
- 盲目搜索:没有利用任何问题的特定信息,只按照某种固定的策略进行搜索,如深度优先搜索(DFS)、广度优先搜索(BFS)等;
- 启发式搜索:利用问题的特定信息,通过某种启发式函数来评估搜索路径的优劣,从而选择最优路径进行搜索,如A*搜索算法等。
| 类型 | 通俗理解 | 特点 | 例子 |
|---|---|---|---|
| 盲目搜索 | 闭着眼睛瞎走,没有任何“经验” | 按固定步骤试错,不挑路,简单但慢 | 闭着眼走迷宫,挨个试岔路口 |
| 启发式搜索 | 带着导航走,知道“哪条路更近” | 用问题信息优先选对的路,聪明且高效 | 看导航避开堵车,优先走近路 |
3.人工智能主要搜索策略
一、求任一解的搜索策略(找到一个解就行)
- 宽度优先搜索(BFS)👉
- 深度优先搜索(DFS)👉
- 有界深度优先搜索
- 迭代加深搜索
二、求最优解的搜索策略(代价最小/路径最好)
- 代价树宽度优先搜索(一致代价搜索)
- A 算法
- A* 算法(A 星算法,最常用最优)👉
- 蒙特卡洛树搜索(MCTS)👉
三、与/或图 的搜索策略
- 与/或图的宽度优先搜索
- 与/或图的深度优先搜索
- 与/或图的有序搜索(最优解树)
- 博弈树搜索(α-β 剪枝)
4. 搜索的核心目标:
不管什么搜索问题,我们都要先想清楚这4件事:
- 能不能找到解?:这条路真的能走到终点吗?会不会根本走不通?---可行性
- 会不会一直跑下去?:程序会不会无限绕圈,永远停不下来? ---最优性
- 找到的解是最好的吗?:是最短路径,还是绕了远路?---最优性
- 要花多少时间和内存?:电脑要算多久?会不会内存不够用?---高效性
二、状态空间:把问题“翻译”成电脑能懂的语言
前言
1. 什么是状态空间?
我们要先把现实问题,变成电脑能处理的“数学模型”,这个模型就叫状态空间。
它是一个四元组 ,每个字母都有明确含义:
- :所有可能的状态集合
- 比如:迷宫里的每一个格子、拼图的每一种摆法、机器人的每一个位置
- :所有可能的操作算子集合
- 比如:迷宫里“向上走/向下走”、拼图里“交换两块碎片”、机器人“左转/前进”
- :初始状态
- 问题的起点,比如“你站在家门口”“拼图刚拆开”
- :目标状态
- 问题的终点,比如“你走到学校”“拼图拼完整”
2. 状态怎么表示?
状态可以用任何形式记录,只要电脑能看懂:
- 简单问题:用符号(比如
A/B/C)、字符串(比如"在家") - 复杂问题:用向量(比如
(x,y)坐标)、树、表格、多维数组
3. 什么是操作?操作怎么表示?
操作就是从当前状态,转移到下一个状态的方法。它是一个二元组 ,每个字母都有明确含义:
- :操作算子,,比如“向上走”
- :状态,比如“从家到学校”
操作可以用任何形式记录,只要电脑能看懂:
- 简单问题:用符号(比如
↑/↓)、字符串(比如"走")
4. 什么是“解”?
从 到 的有限操作序列,就是问题的解。
比如:
在家 → 出门左转 → 直走500米 → 右转 → 到达学校
这个步骤序列,就是“从家到学校”这个问题的一个解。
三、盲目的图搜索策略
前言
回溯策略:最基础的“试错法”
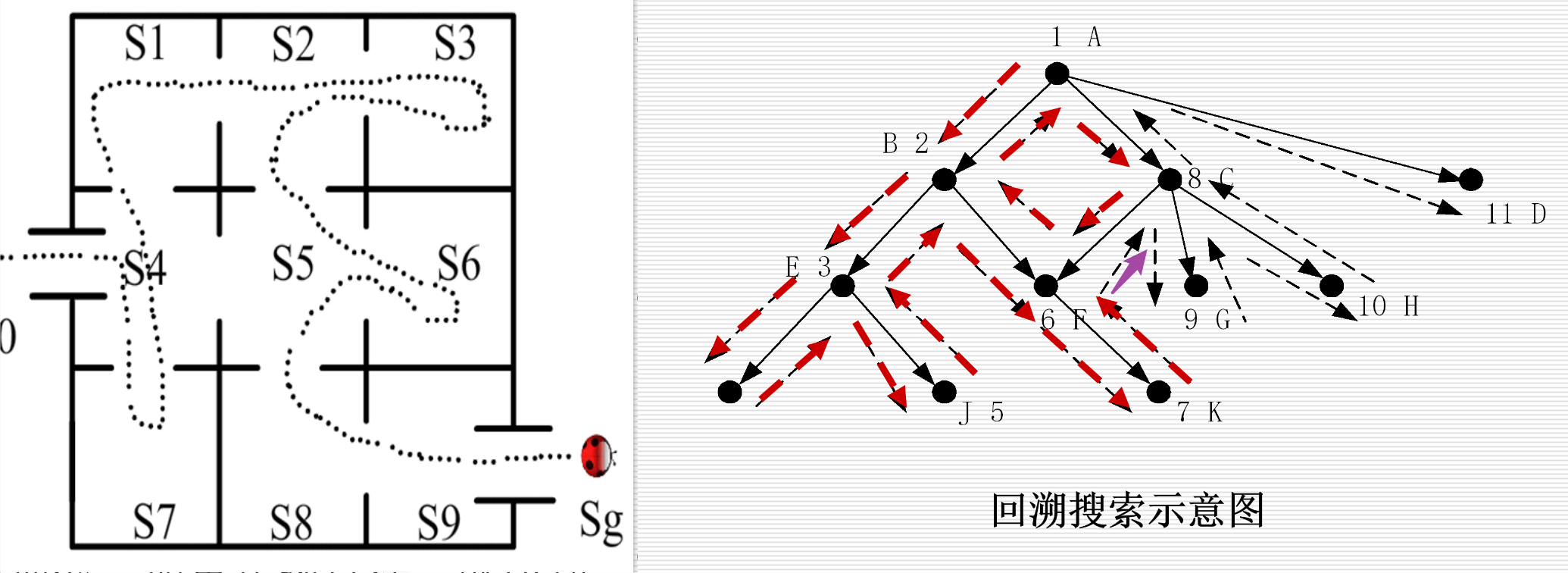
1. 核心逻辑
从起点出发,先选一条路一直走:
- 如果走到终点 ✅:成功,返回步骤
- 如果走到死胡同 ❌:退回到上一个岔路口(父结点),换另一条路继续试
- 直到找到终点,或遍历完所有可能
2. 通俗类比
就像你走迷宫:
- 从入口进去,选左边的路走
- 走到头发现是死胡同,退回到刚才的岔路口
- 换右边的路走,又走到死胡同,再退回来
- 直到找到出口,或确认迷宫没有出口
3. 特点
- ✅ 简单易懂,是所有图搜索算法的基础
- ❌ 效率低,容易走很多冤枉路
- 深度优先、宽度优先等算法,都包含“回溯”的思想(走不通就回头)
宽度优先搜索:一层一层“扫”遍所有可能
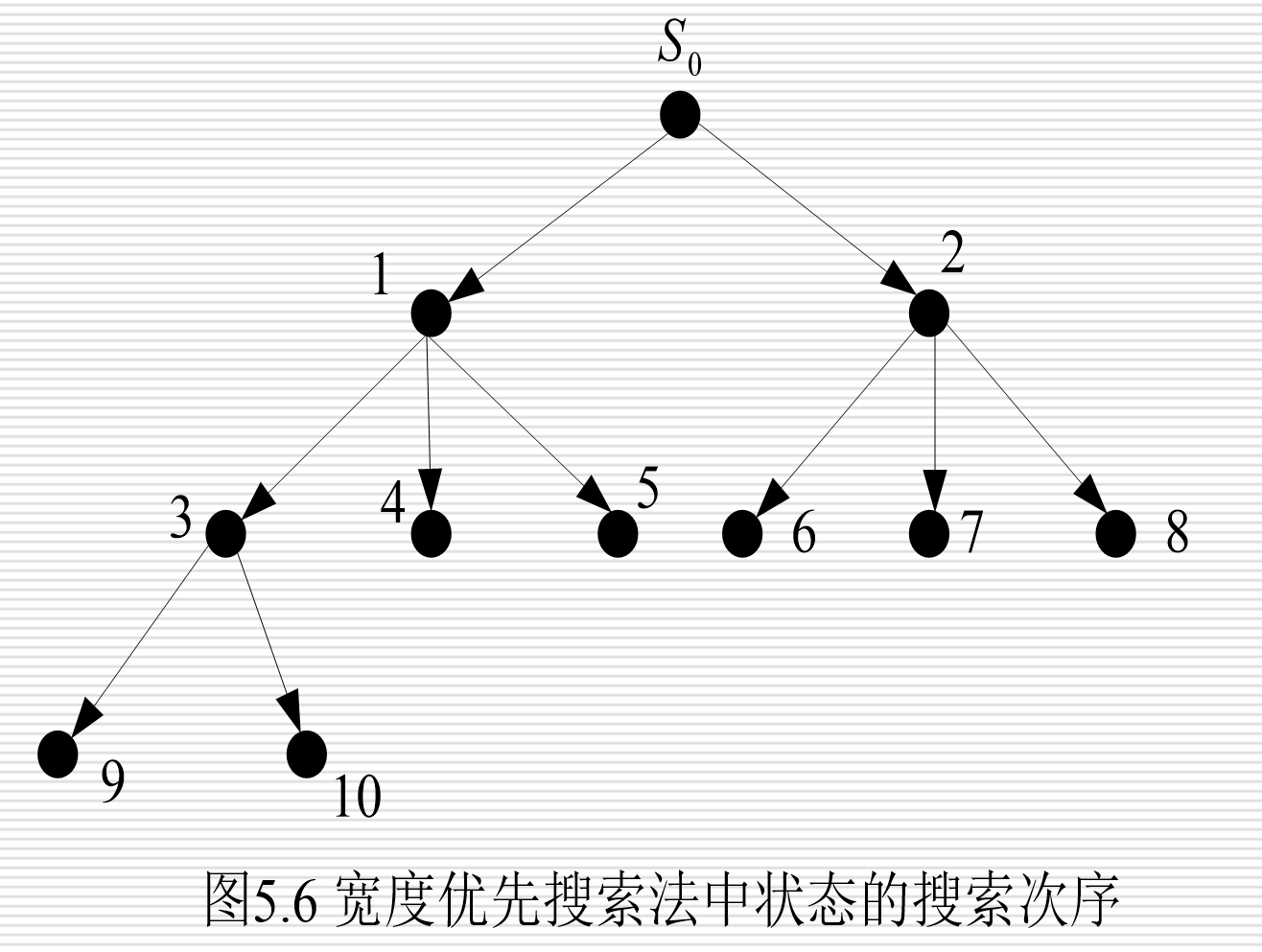
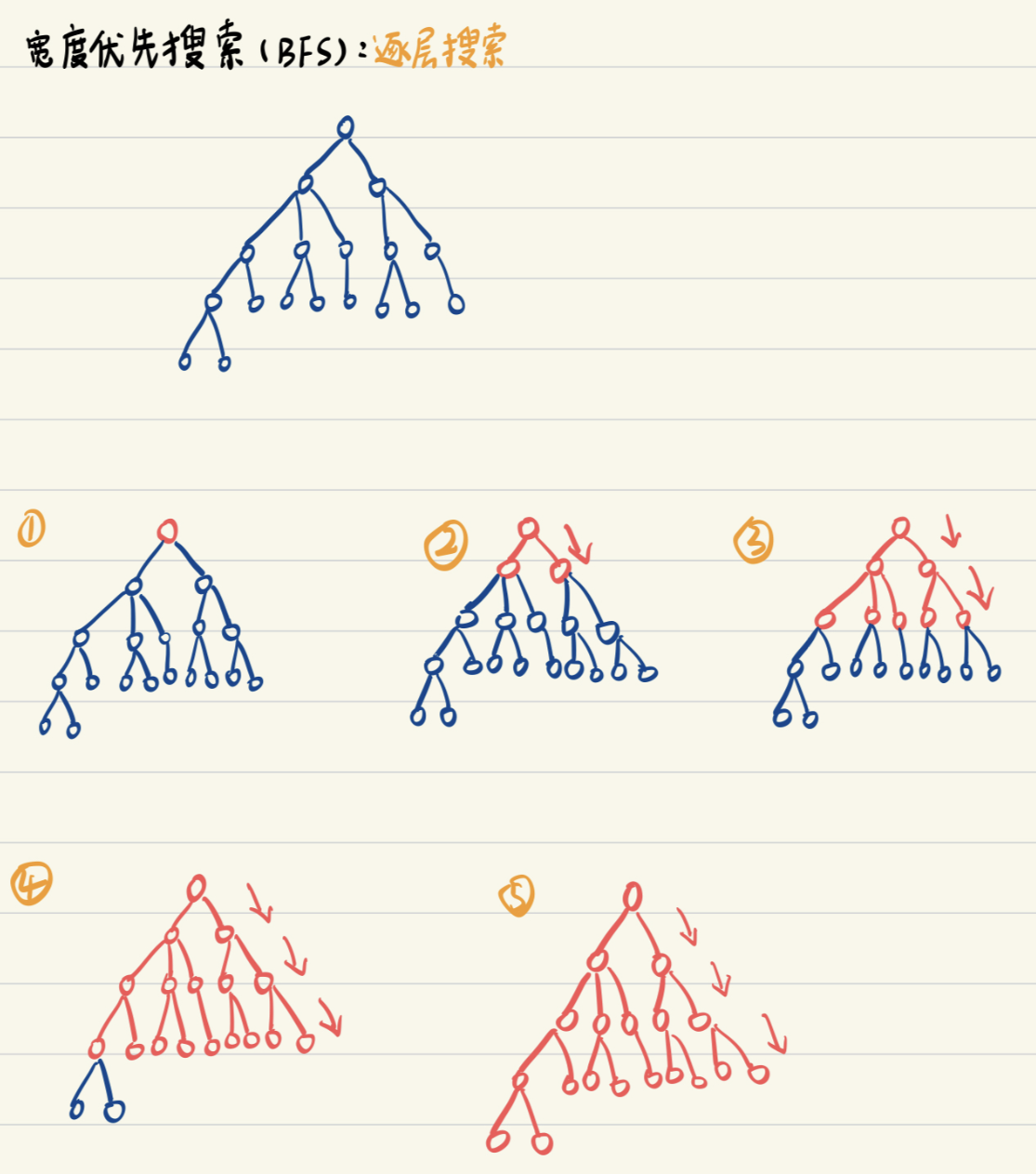
1. 核心逻辑
从起点开始,先把身边所有能直接走到的位置都走一遍(第一层),再挨个走这些位置的下一层,一层一层往外扩,直到找到终点。
2. 通俗类比
像往水里扔石头,波纹一圈一圈往外扩散:
- 第1圈:起点相邻的所有格子
- 第2圈:第1圈格子相邻的所有格子
- 第3圈:第2圈格子相邻的所有格子
- ……直到波纹碰到终点
3. 关键特点
- ✅ 一定能找到最短路径:因为是按“距离”一层层找,第一次碰到终点时,走的就是最近的路
- ❌ 占内存:要记住每一层所有的格子,问题复杂时会很耗电脑内存
- ✅ 适合:目标离起点近、需要最短路径的问题(比如找最短路线)
深度优先搜索:一条路“走到黑”
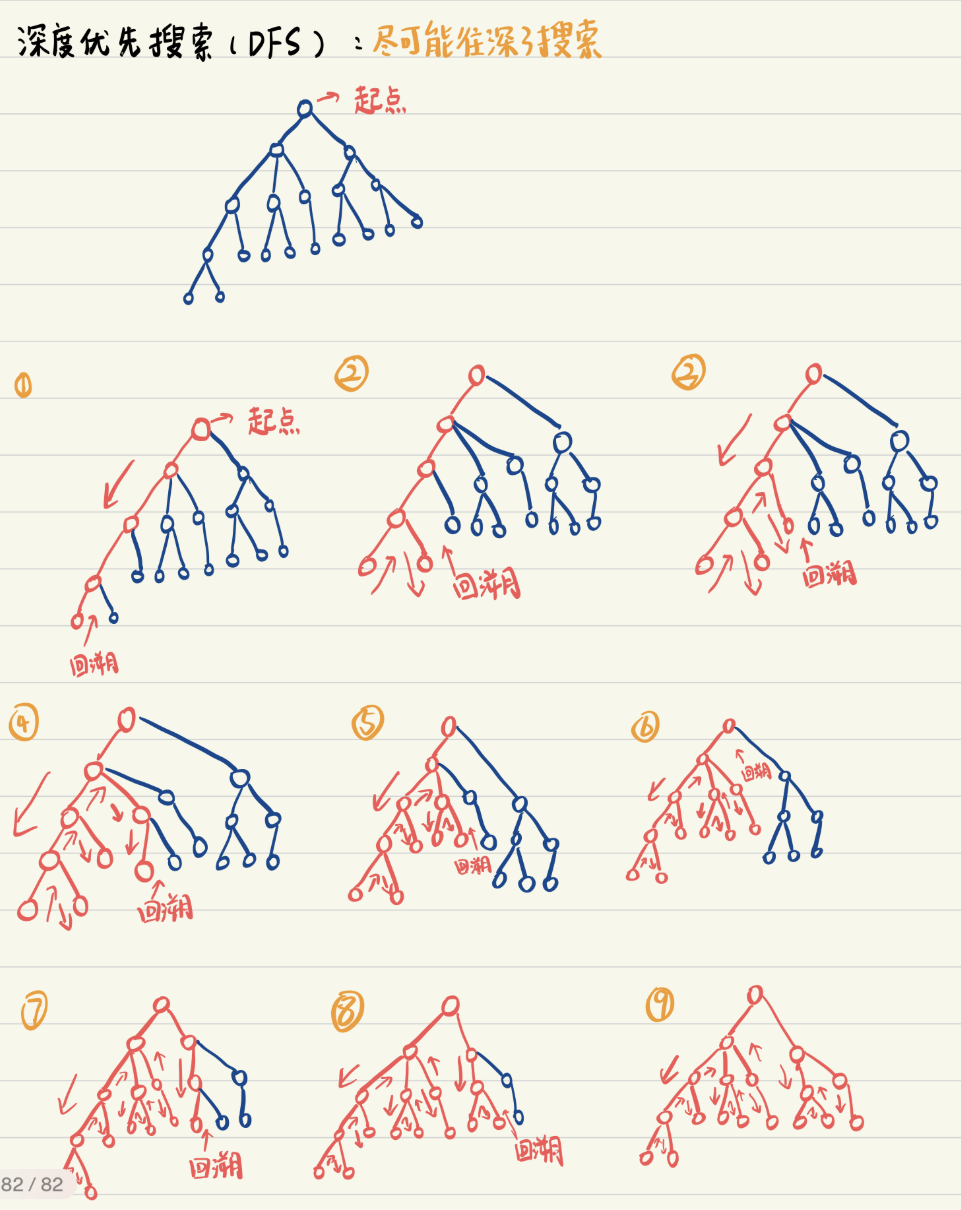
1. 核心逻辑
从起点出发,选一条路一直往深了走,走到头还没到终点,就退回到上一个岔路口,换另一条路继续深走,循环往复。
2. 通俗类比
像钻山洞:
- 从洞口进去,选左边的通道一直往里钻
- 钻到最里面发现没路了,退回到刚才的分叉口
- 换右边的通道继续往里钻
- 直到找到出口,或钻完所有通道
3. 关键特点
- ✅ 省内存:只需要记住当前走的这条路径,不用存所有格子
- ❌ 不一定是最短路径:可能绕很远才找到终点,甚至走进死胡同
- ✅ 适合:目标离起点远、不太在意路径长度的问题(比如解谜游戏)
Open和Closed表:记录走过的路
核心结论:BFS和DFS的Open/Close表结构完全一样,唯一区别是Open表的取数规则——BFS取队头,DFS取队尾。
Open/Close 表的核心作用
| 表名 | 核心作用 | 类比(好理解) |
|---|---|---|
| Open 表 | 待探索的状态(“候选名单”) | 排队等面试的人 |
| Close 表 | 已经探索过的状态(“已处理名单”) | 面试完离开的人 |
核心逻辑:
- 初始状态放进 Open 表,Close 表为空;
- 从 Open 表取一个状态,放到 Close 表;
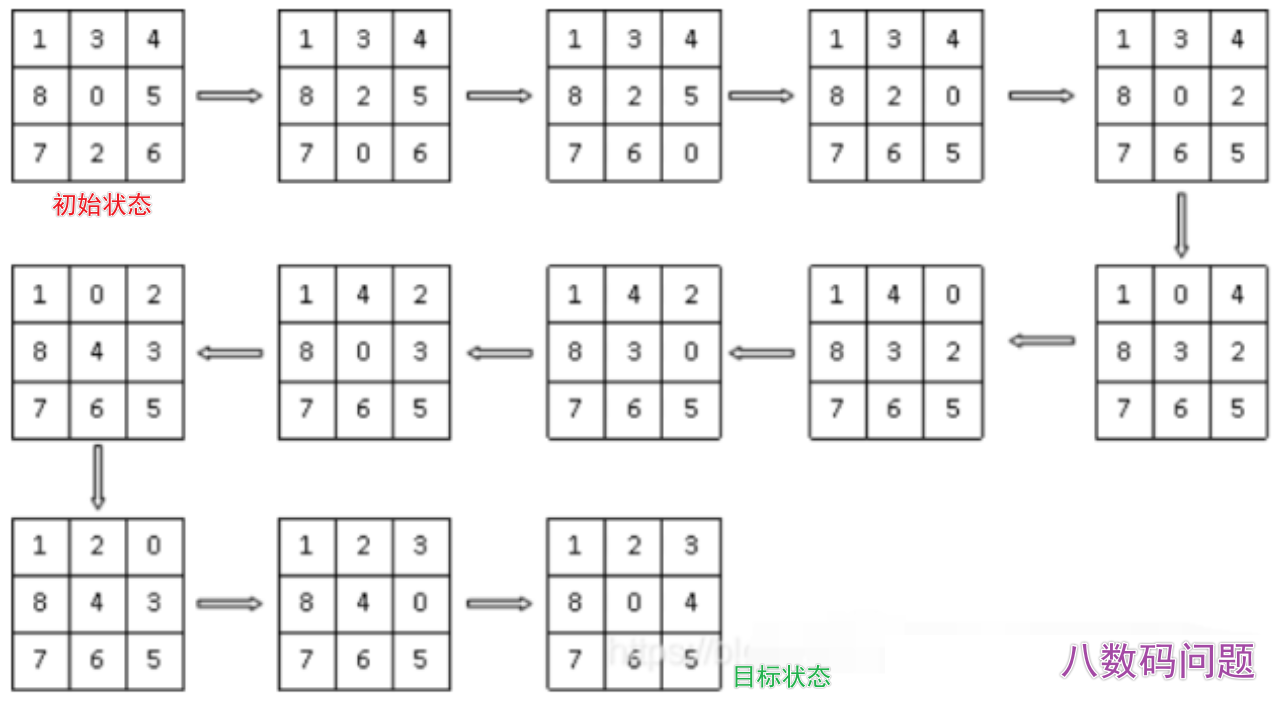
- 对这个状态做「合法操作」(比如八数码移空格),生成所有新状态;
- 新状态如果不在 Open/Close 表中,就放进 Open 表;
- 重复 2-4,直到 Open 表为空(无解)或找到目标状态(有解)。
1. 宽度优先(BFS)—— Open表是「队列」(先进先出 FIFO)
- Open表取数规则:每次取队头(最先进来的状态);
- Open表存数规则:新状态加到队尾;
- 特点:先探索完「当前层所有状态」,再探索下一层(“广撒网,逐层搜”)。
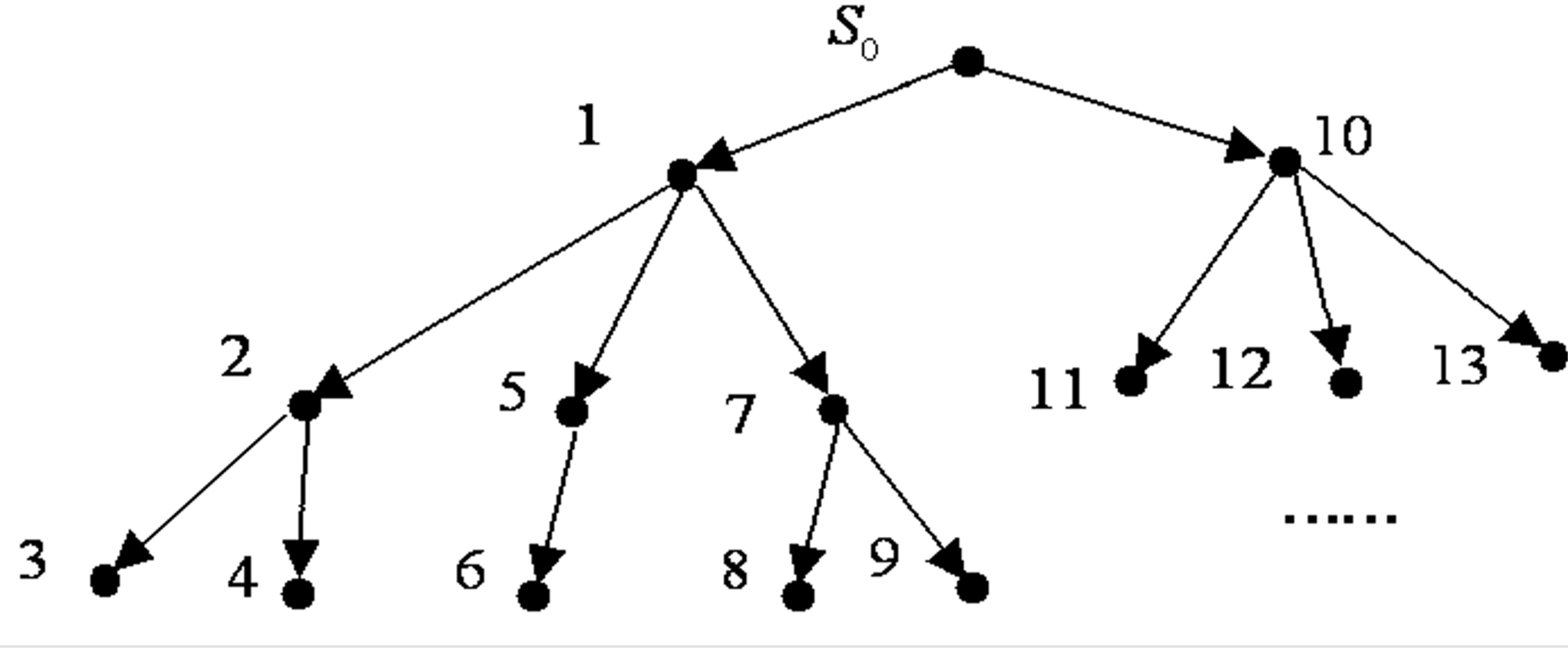
举例:
S (起点)
/ \
A B
/ \
C G (目标)
---
一、先记住两个表的意思
- OPEN 表:待走名单(还没去看的路口)
- CLOSED 表:已走名单(已经看过,不再去)
---
二、开始一步一步走!
第 0 步:刚开始
- 只把起点 放进 OPEN
- OPEN:[ S ]
- CLOSED:[ ]
---
第 1 步:拿出 S 来走
1. 从 OPEN 拿出 S
2. 看看 S 旁边是谁:A、B
3. 把 S 放进 CLOSED(标记:走过了)
4. 把 A、B 放进 OPEN
现在:
- OPEN:[ A, B ]
- CLOSED:[ S ]
---
## 第 2 步:拿出 A 来走(广度优先:先拿先放进去的)
1. 从 OPEN 拿出A
2. 看看 A 旁边是谁:C
3. 把 A 放进 CLOSED
4. 把 C 放进 OPEN
现在:
- OPEN:[ B, C ]
- CLOSED:[ S, A ]
---
## 第 3 步:拿出 B 来走
1. 从 OPEN 拿出 B
2. 一看:B 旁边就是终点 G!
3. 结束!找到了!如果你能看懂上面的流程,那么彻底懂了 BFS,恭喜你!
- OPEN 表:存还没走的路口
- CLOSED 表:存已经走的路口
- 所有搜索算法,本质就是:
从 OPEN 拿 → 走 → 丢进 CLOSED → 把新路口放进 OPEN
四、启发式图搜索:带着“导航”找捷径
前言
https://gallery.selfboot.cn/zh/algorithms
1. 什么是路径搜索问题?
我们用最经典的「网格迷宫」举例:
- 有一个二维网格,
0代表可以走的空地,1代表墙/障碍物,不能走; - 有一个起点
S,一个终点E; - 我们只能上下左右4个方向走(也可以扩展8个方向),不能斜着穿障碍物;
- 目标:找到一条从
S到E的路径,最好是最短/代价最小的那条。
所有的路径搜索算法,都是解决这个问题的,只是找路的「思路」不一样。
2. 什么是启发信息?
就是和问题相关的“经验信息”,比如:
- 去学校时,知道“学校在东边,优先往东走”
- 拼图时,知道“先拼边框,再拼中间”
- 机器人拿玩具时,知道“玩具在右边,优先往右转”
利用这些信息,就能少走弯路,这就是启发式搜索。
3. 「盲目搜索」和「启发式搜索」的区别
这是理解A/A*算法的核心,我们用「找路去商场」举例子:
| 搜索类型 | 核心思路 | 生活例子 | 代表算法 | 缺点 |
|---|---|---|---|---|
| 盲目搜索 | 不看终点在哪,只按固定规则瞎找,没有「方向感」 | 去商场不看地图,每条路都挨个走一遍,直到撞到商场 | 深度优先搜索(DFS)、广度优先搜索(BFS) | 效率极低,地图大了会卡死,浪费大量算力 |
| 启发式搜索 | 会看终点在哪,用「经验/预估」给下一步打分,优先往「离终点更近」的方向找 | 去商场先看地图,优先往商场所在的东边走,不往西绕路 | A算法、A*算法 | 找路效率极高,是游戏、机器人导航的核心算法 |
简单说:A和A*都是启发式搜索算法,核心是给每个路口打分,优先走分数最高、最可能到终点的路。
4. 核心概念:估价函数
启发式搜索的核心,就是「打分公式」,我们叫它估价函数,公式长这样:f(n) = g(n) + h(n)
零基础不用怕公式,我们逐字拆解,每个字母都对应找路的实际意义:
n:当前你站的这个路口(节点)g(n):实际代价,从起点S走到当前节点n,已经实实在在走了多少步/花了多少成本。
比如从起点走了5步到你现在的位置,那g(n)=5,这个值是确定的、真实的。h(n):启发函数/预估代价,从当前节点n走到终点E,你估计还要走多少步/花多少成本。
这个值是预估的、猜的,也是A和A*算法最核心的区别所在。f(n):当前节点的总估价分,分数越低,代表「从起点到终点走这条路的总成本越低」,我们就优先走这个节点。
5.A算法
A算法,就是基于上面这个f(n)=g(n)+h(n)估价函数的启发式搜索算法,是A*算法的前身。
5.1. A算法的核心逻辑
A算法没有对h(n)做任何限制,你可以随便预估代价,只要能给节点打分就行。
- 好处:灵活,你可以根据自己的需求设计
h(n); - 坏处:如果
h(n)估错了,比如估的比实际小太多/大太多,可能会找不到最优路径,甚至绕远路、找不到路。
5.2. A算法的执行步骤(迷宫找路为例)
我们用最简单的步骤,讲清楚A算法是怎么一步步找路的:
- 初始化两个列表:
- 开放列表(Open List):放「待考察的路口」,比如起点周围的路口,我们还没决定走不走;
- 关闭列表(Close List):放「已经考察完的路口」,已经确定了从起点到这里的最小代价,不用再回头看了。
- 把起点放进开放列表,作为找路的开始。
- 循环找路,直到找到终点/开放列表空了:
① 从开放列表里,找出f(n)分数最低的节点,把它叫做「当前节点」;
② 把这个当前节点,从开放列表移到关闭列表里(已经考察完了);
③ 检查当前节点是不是终点?如果是,找路结束,回溯路径即可;
④ 如果不是,遍历当前节点周围所有能走的相邻节点(上下左右):- 如果这个相邻节点是障碍物,或者已经在关闭列表里了,直接跳过;
- 如果这个相邻节点不在开放列表里:给它计算
g(n)、h(n)、f(n),记录它的「父节点」是当前节点(方便最后回溯路径),然后把它放进开放列表; - 如果这个相邻节点已经在开放列表里了:看看如果从当前节点走过去,新的
g(n)是不是比它原来的g(n)更小。如果更小,就更新它的g(n)、f(n)和父节点;如果更大,就不用管。
- 循环结束后:如果找到了终点,就从终点顺着父节点往回走,一直走到起点,倒过来就是完整的路径;如果开放列表空了还没找到终点,说明迷宫里没有能到终点的路。
5.3. A算法的关键局限
A算法最大的问题,就是对h(n)没有约束:
- 如果你把
h(n)设的特别大,算法会优先往终点冲,可能会忽略更短的路径,找不到最优解; - 如果你把
h(n)设成0,那f(n)=g(n),A算法就退化成了广度优先搜索(BFS),虽然能找到最优解,但失去了启发式搜索的效率优势。
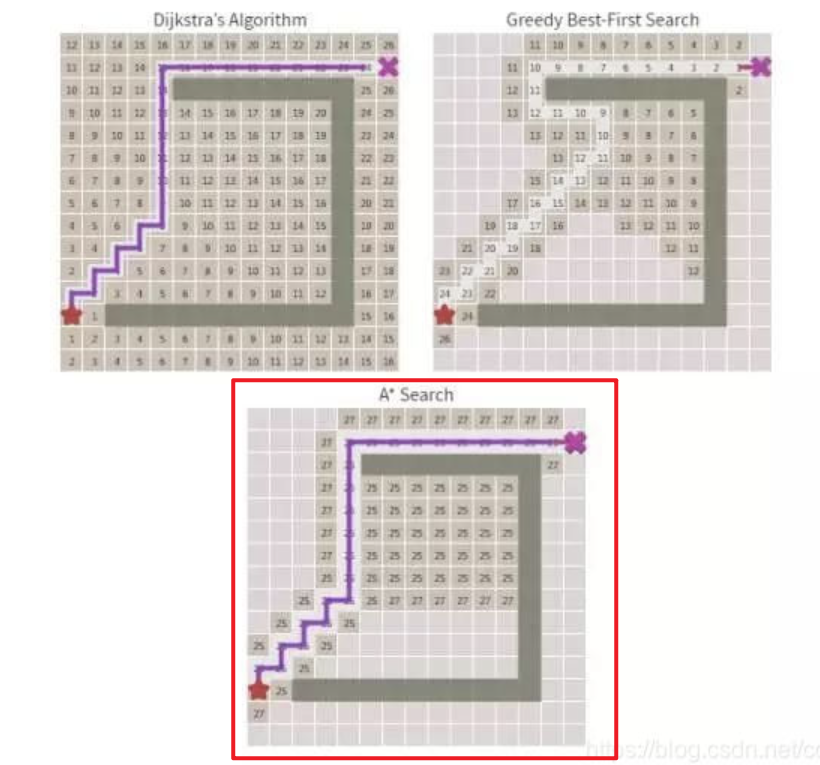
6.A*(A星)算法
A* 算法是对A算法的完美优化,也是目前最常用的路径搜索算法,游戏里的角色寻路、机器人导航、自动驾驶路径规划,核心都是A*算法。
6.1. 从A到A*:核心改进(只加了一个约束)
A*算法的估价函数和A算法完全一样,还是:f(n) = g(n) + h(n)
唯一的区别,就是对启发函数h(n)加了一个铁则:
h(n) ≤ h(n)*
其中h*(n)是从当前节点n到终点的实际最小代价。
这个约束,在算法里叫可采纳性。用人话讲就是:你预估的剩余步数,绝对不能超过实际最少需要走的步数。
只要满足这个约束,A*算法就有两个无敌的优点:
- 一定能找到从起点到终点的最优路径(最短路径/最小代价路径);
- 在所有能找到最优路径的算法里,A*的效率是最高的,考察的节点最少,找路最快。
这就是为什么A*算法比A算法应用广得多的原因。👍
6.2. 关键:h(n)启发函数怎么选?
要满足h(n) ≤ 实际最小代价,我们需要根据「能走的方向」,选对应的距离公式,零基础记住3个最常用的就行,都是小学数学知识。
场景1:只能上下左右4个方向走(网格迷宫)→ 曼哈顿距离
这是最常用的,也是网格迷宫里唯一满足「可采纳性」的。
公式:h(n) = |x1 - x2| + |y1 - y2|
- (x1,y1)是当前节点的坐标,(x2,y2)是终点的坐标;
- 两个竖线是绝对值,比如|3-5|=2;
- 含义:横向要走的步数 + 纵向要走的步数,正好是4方向走的最少步数,完美满足
h(n)=h*(n),绝对不会超估。
举个例子:当前节点(1,1),终点(4,3),曼哈顿距离=|1-4| + |1-3| = 3+2=5步,正好是最少要走的步数。
场景2:可以上下左右+斜着8个方向走 → 切比雪夫距离
公式:h(n) = max(|x1-x2|, |y1-y2|)
- 含义:横向和纵向里,步数更多的那个,因为斜着走可以同时覆盖横纵的步数,满足8方向的最小步数约束。
场景3:可以随便走,没有网格限制(比如无人机导航)→ 欧式距离
公式:h(n) = √[(x1-x2)² + (y1-y2)²]
- 含义:两点之间的直线距离,是所有路径里最短的,绝对不会超过实际代价,满足可采纳性。
6.3. A*算法的执行步骤
和A算法的步骤几乎完全一样,唯一的区别就是h(n)必须满足「可采纳性」约束,步骤再给零基础的同学简化一遍,方便对应代码理解:
- 初始化:开放列表(用优先队列/最小堆,快速找f(n)最小的节点)、关闭列表;
- 把起点加入开放列表,起点的
g(n)=0,h(n)=曼哈顿距离到终点,f(n)=0+h(n);👈 - 循环处理:
① 取出开放列表里f(n)最小的节点,作为当前节点;
② 如果当前节点是终点,结束循环,回溯路径;
③ 把当前节点加入关闭列表;
④ 遍历当前节点的4个/8个相邻节点:- 相邻节点是障碍物/在关闭列表里 → 跳过;
- 计算从起点到这个相邻节点的新
g(n)= 当前节点的g(n)+ 1(走一步代价是1); - 如果相邻节点不在开放列表里 → 计算h(n)、f(n),记录父节点,加入开放列表;
- 如果相邻节点已经在开放列表里 → 新g(n) < 原来的g(n),就更新它的g、f和父节点;
- 路径回溯:从终点开始,顺着父节点往回走到起点,反转后就是完整的最优路径。
7. 核心问题
7.1. A算法和A*算法的核心区别是什么?
只有一个核心区别:对启发函数h(n)的约束。
A算法:对h(n)无约束,灵活但不一定能找到最优路径;A*算法:强制h(n) ≤ 实际最小代价,保证一定能找到最优路径,且效率最高。
7.2. 为什么我的A*算法找不到最优路径?
99%的问题出在启发函数h(n)不满足可采纳性,也就是你预估的h(n)比实际最小代价大了。
- 比如4方向的网格迷宫,你用了欧式距离,就会低估?不,欧式比曼哈顿距离小,是满足的;但如果你随便给
h(n)乘了一个大于1的系数,就会超估,导致找不到最优路径。
7.3. 开放列表为什么要用最小堆(heapq)?
因为我们每次都要找开放列表里f(n)最小的节点,如果用普通列表,每次找最小值都要遍历一遍,效率极低;用最小堆,只需要O(1)的时间就能拿到最小值,插入新节点也只需要O(logn)的时间,效率天差地别。
7.4. A*算法的常见应用场景有哪些?
- 游戏开发:MOBA游戏里英雄的自动寻路、NPC的移动,几乎都是A*算法;
- 机器人/自动驾驶:扫地机器人的路径规划、无人车的局部路径规划;
- 地图导航:高德/百度地图的驾车路线规划,核心是
A*算法的变种(如双向A*); - 谜题求解:华容道、八数码问题等,都可以用A*算法求解。
8.蒙特卡罗树搜索
蒙特卡罗树搜索(简称MCTS),核心就是靠「大量随机模拟试玩+统计结果」,在有对抗、有不确定性、可能性多到算不完的场景里,找出赢面最大的那一步决策。
最经典的例子:下围棋/五子棋/井字棋,你走一步对手会反制,未来的走法多到数不清(围棋的可能性比全宇宙原子还多),根本没法把所有情况全算一遍。MCTS不用穷举,靠反复随机模拟对局,统计哪一步赢的次数最多,就选哪一步。
它和之前学的A*算法核心区别:A*解决「路是固定的、结果100%确定」的路径规划问题;MCTS解决「有对手对抗、未来不确定、没法全算完」的博弈决策问题。
8.1 核心逻辑:4步循环,越算越准
MCTS的全部操作,就是循环执行4个极简步骤,循环的次数越多,对「哪一步最优」的判断就越准。
1. 选(Selection)
从当前的局面(树根)开始,顺着之前统计出来「赢面大、又没怎么被试过」的分支往下走,一直走到一个还没摸透的、没被充分模拟的节点为止。
核心是平衡两件事:既不浪费时间在明显的臭棋上,也不错过可能藏着妙招的新走法。
2. 扩(Expansion)
在刚才走到的、没摸透的节点上,开出一个新分支,对应一个合法的走法和全新的局面,为后续模拟做准备。
3. 演(Simulation,也叫随机模拟)
从这个新局面开始,让对局双方完全随机落子、瞎走,一直玩到分出最终输赢(赢/输/平局),拿到一个明确的对局结果。
这一步不用任何策略,就是纯随机快速走完一局,拿到结果就行。
4. 传(Backpropagation,反向传播)
把这次随机模拟的输赢结果,从刚才瞎玩的结束节点,一路往回传,更新这条路径上所有节点的两个核心数据:「这个局面被模拟了多少次」、「这个局面累计赢了/输了多少」。
相当于把这次试玩的经验,同步给所有相关的决策节点,让下一次的「选择」更准。
一次循环走完,就完成了一次「试玩+攒经验」。重复成千上万次后,树根(当前局面)的所有可选走法,都有了足够的统计数据,直接选「被模拟次数最多、平均赢率最高」的那一步,就是MCTS给出的最优决策。
8.2 核心优势
- 不用穷举,算力花在刀刃上:不用算完所有可能性,赢面大的分支会被反复模拟、越挖越深,明显的坏棋会被快速放弃,算力效率极高。
- 随时能停,灵活度极高:模拟100次有100次的决策结果,模拟10万次有更精准的结果,算力够就多算,算力有限就少算,适配性极强。
- 对规则要求极低:只要能判断「哪些走法合法、最终谁赢了」,就能用MCTS,不用提前给算法灌输棋谱、策略,它自己靠模拟就能摸索出最优解。
8.3 最常见的应用场景
- 棋类AI:围棋、象棋、五子棋等博弈类游戏,比如AlphaGo的核心组件之一就是MCTS;
五、与或图搜索
前言
1. 分解与树(与节点/AND节点)
1. 核心本质:问题的「分解」逻辑
分解与树,用来解决 **「一个大问题,必须拆成多个子问题,所有子问题全部做完,大问题才能解决」**的场景。
定义:将原问题分解为若干个子问题,原问题可解的充要条件是「所有子问题全部可解」,这种分解关系形成的树状结构,就是分解与树。
2. 核心规则
- 父问题和子问题是「缺一不可」的强绑定关系:少解决任何一个子问题,父问题都完不成;
- 树的分支是「分解」出来的,不是多选的,是必须全部覆盖的;
- 典型特征:分解与树的多个分支,会用一段圆弧线连起来(与连接符),用来和或树做区分,代表「这些分支必须全部完成」。
3. 通俗例子
原问题:完成一篇课程期末论文
分解成4个子问题:① 查文献资料 ② 写正文内容 ③ 做论文查重 ④ 调整格式排版
这4个子问题,必须全部做完,「完成期末论文」这个大问题才算解决,少一个都不行。
把这个分解关系画成树,根节点是「完成期末论文」,下面分4个分支对应4个子问题,这就是一棵最典型的分解与树。
完成期末论文(根节点,与节点)
│
┌──────────────────┼──────────────────┬──────────────────┐
│ │ │ │
查文献资料 写正文内容 做论文查重 调整格式排版
(子问题1) (子问题2) (子问题3) (子问题4)
└──────────────────────────────────────────────────────┘
(圆弧线:表示 AND 关系)4. 可解性判断规则
- 叶子节点(最底层的子问题):能直接解决,就是可解节点;做不到,就是不可解节点;
- 父节点(与节点):只有它所有的子节点全部可解,它才是可解的;只要有一个子节点不可解,整个父节点就不可解。
2.变换或树(或节点/OR节点)
1. 核心本质:问题的「变换/等价替换」逻辑
变换或树,用来解决 「一个大问题,有多种可替代的解决办法,只要完成其中任意一个办法,大问题就能解决」 的场景。
定义:将原问题变换为若干个可替代的备选子问题,原问题可解的充要条件是「至少有一个子问题可解」,这种变换关系形成的树状结构,就是变换或树。
2. 核心规则
- 父问题和子问题是「多选一」的替代关系:只要任意一个子问题解决了,父问题就解决了;
- 树的分支是「可选的解决方案」,不是必须全做的,选一个能成的就行;
- 典型特征:分支之间没有圆弧线连接,和 与树 做明确区分,代表「分支之间是多选一的关系」。
3. 通俗例子
原问题:论文里要做一份数据分析
变换出3个可替代的备选子问题:① 用Python做分析 ② 用Excel做分析 ③ 用SPSS做分析
这3个办法,只要完成任意一个,「做数据分析」的问题就解决了,不用全部都做。
把这个变换关系画成树,根节点是「做论文数据分析」,下面分3个分支对应3个可选办法,这就是一棵最典型的变换或树。
做论文数据分析(根节点,或节点)
│
┌────────────────┴────────────────┐────────────────┐
│ │
用Python做分析 用Excel做分析 用SPSS做分析
(可选方案1) 可选方案2) 可选方案3)4. 可解性判断规则
- 叶子节点(最底层的子问题):能直接解决,就是可解节点;做不到,就是不可解节点;
- 父节点(或节点):只要它的任意一个子节点可解,它就是可解的;只有当所有子节点全部不可解时,父节点才不可解。
3. 与或图(与或树)
1. 核心本质:「分解+变换」的组合逻辑
实际的问题归约场景中,往往会同时用到「分解(与关系)」和「变换(或关系)」,形成既有与节点、又有或节点的嵌套结构,这就是与或图(如果结构是无环的树状,也叫与或树),也是与或图搜索的核心处理对象。
2. 通俗例子
原问题:完成一篇课程期末论文
第一步分解(与关系):必须全部完成4个子问题:① 确定选题 ② 完成论文主体 ③ 查重降重 ④ 格式排版
其中「完成论文主体」子问题,又可以变换(或关系):3个方案任选其一即可:① 做实验写实证论文 ② 做案例分析写案例论文 ③ 做理论推导写综述论文
这个同时嵌套了与、或关系的树状结构,就是最典型的与或树。
完成一篇课程期末论文(AND 根节点)
│
┌───────────────┬───────────────┬───────────────┐
│ │ │ │
确定选题 完成论文主体 查重降重 格式排版
(子问题1) (AND子节点) (子问题3) (子问题4)
│
┌──────────┴──────────┐
│ │
做实验写实证论文 做案例分析写论文 做理论推导写综述论文
(OR方案1) (OR方案2) (OR方案3)
(圆弧表示 AND;无圆弧表示 OR)3. 可解性判断规则
按照节点类型,分别套用与节点、或节点的可解性规则,从叶子节点向上递归判断即可。