
人工智能
一、不确定性推理的基本概念
前言
1. 核心定义
推理:从已知事实(证据)出发,运用相关知识推出结论或验证假设的思维过程。
👉不确定性推理:从不确定性的初始证据出发,通过运用不确定性的知识,最终推出具有一定程度不确定性、但合理/近乎合理结论的思维过程。
2. 不确定性推理中的基本问题
现实世界存在随机性、模糊性,导致知识和证据都带有不确定性,要实现有效的不确定性推理,需先解决5个核心问题,这是所有不确定性推理方法的基础框架:
- 不确定性的表示与量度
- 知识不确定性 :由领域专家给出,用数值表示(知识的静态强度);
- 证据不确定性 :用户提供的初始证据/推理中间结论,用数值表示(证据的动态强度);
- 量度要求 :能表达不确定程度、范围直观、便于计算、有理论依据。
- 不确定性匹配算法及阈值的选择
- 匹配算法:计算证据与知识的相似程度;
- 阈值:判断相似性是否达到“可推理”的限度。
- 组合证据不确定性的算法
解决多个单一证据合取(AND)、析取(OR)后的不确定性计算,常用最大最小方法、概率方法等。 - 不确定性的传递算法
解决两步核心问题:①单步推理中,将证据和知识的不确定性传递给结论;②多步推理中,将初始证据的不确定性传递给最终结论。 - 结论不确定性的合成
解决多个知识/证据推出同一结论时,如何合并各结论的不确定性,得到最终的不确定程度。
二、可信度方法(CF模型)
前言
我们已经明确了不确定性推理的核心框架和要解决的基本问题,接下来需要学习具体的推理方法。其中可信度方法是最直观、简单且工程应用最广泛的方法,也是教学大纲的重点,我们先从这一方法入手。👇 👇
1. 方法起源与特点
前面我们讲了不确定性推理的核心问题——现实中证据和知识都不是绝对确定的,比如咳嗽不一定是感冒、路面湿不一定刚下雨,而我们要做的,就是把这种“模糊的不确定”变成可计算、能推理的数学规则,让机器也能像人一样做判断。
早期科学家尝试用概率论来解决这个问题,但发现有个大痛点:需要精准的统计数据,还得算复杂的公式,比如要知道“咳嗽的人里多少感冒”,现实中根本没法精准统计,工程上也用不起来。
所以在1975年,科学家肖特里菲就跳出了概率论的框架,结合医生看病、工程师排查故障的实际经验,提出了一套简单、直观、能直接落地的不确定性推理方法——可信度方法。
它的核心特别好理解:不用算复杂概率,只用一个简单的数值表示“相信的程度”,再通过几步加减乘、取最大最小的简单运算,就能实现从证据到结论的不确定性推理,这也是目前专家系统中最常用的方法,今天我们就重点学这一方法。
2. 核心概念:可信度
可信度:根据经验对一个事物/现象为真的相信程度,带有主观性和经验性;
C-F模型:基于可信度表示的不确定性推理基本方法,核心是可信度因子CF。
3. 知识不确定性的表示
用产生式规则表示:IF E THEN H (CF(H,E))
- CF(H,E):可信度因子,反映前提E与结论H的联系强度,取值范围
[-1,1];- CF(H,E)>0:证据E出现支持H为真,值越大支持程度越高;
- CF(H,E)<0:证据E出现支持H为假,值越小否定程度越高;
- CF(H,E)=0:证据E与H无关。
- 示例:
IF 头痛 AND 流涕 THEN 感冒 (0.7),表示头痛且流涕时,支持感冒的可信度为0.7。
4. 证据不确定性的表示
证据E的不确定性用CF(E) 表示,取值范围[-1,1](证据的动态强度):
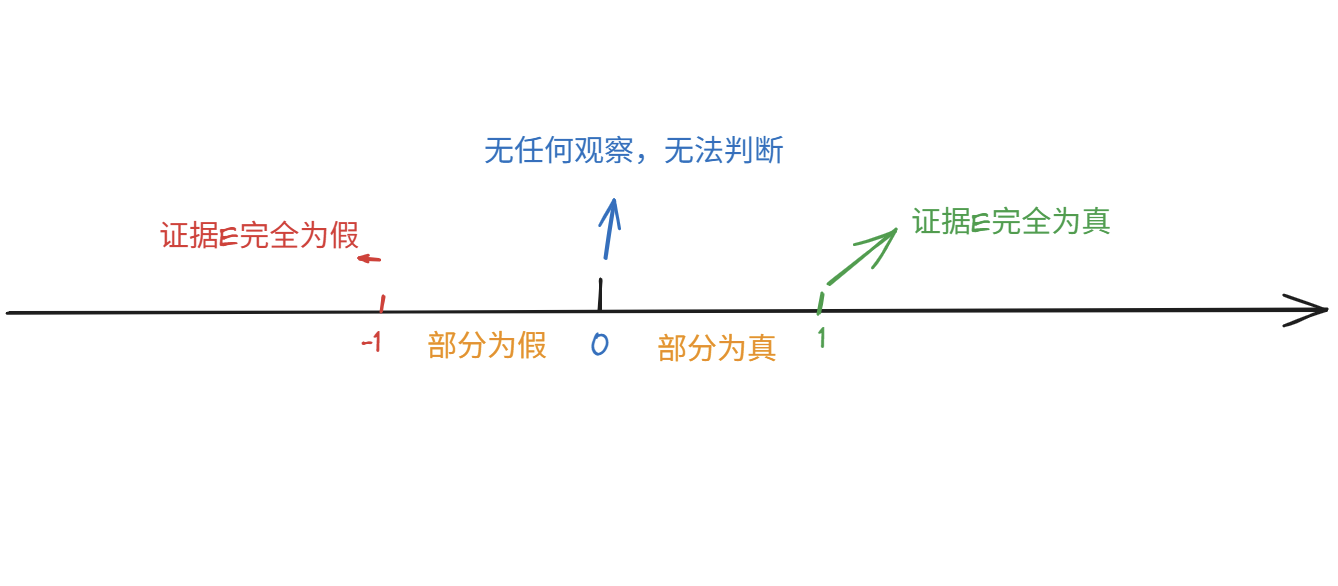
CF(E)=1:证据E完全为真;CF(E)=-1:证据E完全为假;0<CF(E)<1:证据E部分为真;-1<CF(E)<0:证据E部分为假;CF(E)=0:无任何观察,无法判断E的真假。- 示例:CF(头痛)=0.6,表示“头痛”这一证据的可信度为0.6。
5. 组合证据不确定性的算法
我们生活中做任何不确定判断,从来不会只看一个证据,而是会综合多个线索,而多个线索的靠谱程度,会共同决定整体判断的依据是否靠谱:
比如医生判断感冒:不会只看 “咳嗽”,会综合 “咳嗽 + 头痛 + 流涕 + 发烧” 多个症状;如果咳嗽很明显(CF=0.9)、头痛轻微(CF=0.3)、流涕很明显(CF=0.8),那这组症状的 “整体靠谱程度”,肯定不是简单的相加 / 相减,而是有明确的判断逻辑;组合证据不确定性的算法,就是解决「多个不确定的证据放在一起,整体的不确定程度该怎么算」的问题,它是不确定性推理的必备前置步骤
针对多个单一证据的合取(AND)∧ 和析取(OR)∨,采用最大最小法计算:
最大最小法:取所有证据中最小可信度作为
合取后的可信度,取所有证据中最大可信度作为析取后的可信度。
- 合取:E = E1 AND E2 AND … AND En
CF(E) = min - 析取:E = E1 OR E2 OR … OR En
CF(E) = max
- 示例1:CF(头痛)=0.6,CF(流涕)=0.8,则CF(头痛AND流涕)=min{0.6,0.8}=0.6。
- 示例2: CF(头痛)=0.6,CF(流涕)=0.8,则CF(头痛OR流涕)=max{0.6,0.8}=0.8。
6. 不确定性的传递算法
我们生活中做判断,从来都不是 “非黑即白”,而是会根据证据的靠谱程度,调整对结论的相信程度,这就是天然的 “不确定性传递”:
比如医生判断感冒:规则是 “咳嗽→感冒(比较相信)”,但如果只是轻微咳嗽(证据不靠谱、不确定),医生只会 “有点怀疑感冒”;如果是剧烈咳嗽 + 发烧(证据很靠谱、确定),医生才会 “高度怀疑感冒”。
这里的 “证据靠谱程度→结论相信程度” 的推导过程,就是不确定性传递算法要解决的问题 —— 它把人类这种 “模糊思考” 变成了可计算、可编程的数学规则,让机器能模仿人类做不确定判断。
从不确定的初始证据出发,推出结论并计算结论的可信度,核心公式:
CF(H) = CF(H,E) × max{0, CF(E)}-----》结论的可信度 = 规则的支持强度 × 证据的实际真实程度
- 解读:仅当证据E为真(CF(E)>0)时,才将知识的不确定性传递给结论;若E为假/无关,结论可信度为0。
- 示例:
IF 咳嗽 THEN 感冒(0.7),CF(咳嗽)=0.8,则CF(感冒)=0.7×0.8=0.56。
说明:0.7 不是 “感冒的可信度”,而是 “咳嗽为真时,对感冒的支持强度”
CF(H,E)=0.7:这是知识的静态强度,意思是「如果咳嗽这个证据100% 为真(CF (咳嗽)=1),那么感冒的可信度就是 0.7」—— 这是专家定的 “规则强度”,是理想情况下的支持度。
CF(E)=0.8:这是证据的动态强度,意思是「当前实际观察中,咳嗽这个证据并不是完全真的,只是 “轻微咳嗽”,真实程度只有 0.8」—— 这是实际情况下的证据可信度。
理想情况:咳嗽完全为真(CF=1)→ 感冒 CF=0.7×1=0.7(这就是你以为的 0.7,是证据完全真实时的结果);
实际情况:咳嗽部分为真(CF=0.8)→ 感冒 CF=0.7×0.8=0.56(证据只有 80% 的真实度,规则的支持强度也只能发挥 80%)
如果 CF (咳嗽)=-0.9,CF (感冒)=0.7 × max {0, -0.9} = 0.7×0=0,证据为假,感冒的可信度为0.
7. 结论不确定性的合成算法
当两条及以上知识推出同一结论H时,需合并各结论的可信度,步骤为:
- 分别根据每条知识计算出结论H的可信度,记为CF1(H)、CF2(H);
- 按以下公式合成综合可信度CF12(H):
- 若CF1(H)≥0且CF2(H)≥0:CF12(H) = CF1(H) + CF2(H) - CF1(H)×CF2(H)
- 若CF1(H)<0且CF2(H)<0:CF12(H) = CF1(H) + CF2(H) + |CF1(H)×CF2(H)|
- 若CF1(H)与CF2(H)一正一负:CF12(H) = [CF1(H) + CF2(H)] / [1 - min{|CF1(H)|, |CF2(H)|}]
情况1: 且 (两个证据均支持结论H)
公式:
公式解读:两个证据都支持结论,综合可信度会比单个更高,但需扣除重复支持的部分(避免可信度超过1),符合“多证据佐证,结论更可信”的直觉。
案例:
已知两条独立规则:
① IF 咳嗽 THEN 感冒(0.8),CF(咳嗽)=0.9 → 传递得;
② IF 流涕 THEN 感冒(0.7),CF(流涕)=0.8 → 传递得;
两个可信度均为正,均支持“感冒”,合成综合可信度:
结论:结合“咳嗽”和“流涕”两个证据,感冒的综合可信度为0.8768,比单个证据的可信度更高,佐证更充分。
情况2: 且 (两个证据均否定结论H)
公式:
公式解读:两个证据都否定结论,综合否定程度会比单个更强,通过加绝对值弥补负号带来的计算偏差,确保可信度不低于-1。
案例:
已知两条独立规则:
① IF 无咳嗽 THEN 非感冒(-0.8),CF(无咳嗽)=0.9 → 传递得;
② IF 无流涕 THEN 非感冒(-0.7),CF(无流涕)=0.8 → 传递得;
两个可信度均为负,均否定“感冒”,合成综合可信度:
结论:结合“无咳嗽”和“无流涕”两个证据,否定感冒的综合可信度为-0.8768,比单个证据的否定程度更强,更能确定不是感冒。
情况3:与一正一负(一个证据支持H,一个证据否定H)
公式:
公式解读:支持和否定的证据相互抵消,分母为修正因子(扣除两者中强度较弱的那个,避免抵消后可信度超出[-1,1]范围),最终结果的正负由“支持/否定的强度孰大孰小”决定。
案例1:支持强度 > 否定强度(最终综合结果支持结论)
已知两条独立规则:
① IF 咳嗽 THEN 感冒(0.8),CF(咳嗽)=0.9 → (正,支持);
② IF 无发烧 THEN 非感冒(-0.6),CF(无发烧)=0.8 → (负,否定);
一正一负,先算绝对值:,,;
合成综合可信度:
结论:“咳嗽支持感冒”的强度大于“无发烧否定感冒”的强度,最终综合仍支持感冒,可信度约0.4615(因相互抵消,比单一支持的0.72低)。
案例2:支持强度 < 否定强度(最终综合结果否定结论)
已知两条独立规则:
① IF 咳嗽 THEN 感冒(0.7),CF(咳嗽)=0.6 → (正,支持);
② IF 无流涕 THEN 非感冒(-0.9),CF(无流涕)=0.8 → (负,否定);
一正一负,先算绝对值:,,;
合成综合可信度:
结论:“无流涕否定感冒”的强度大于“咳嗽支持感冒”的强度,最终综合否定感冒,可信度约-0.5172(因相互抵消,比单一否定的-0.72弱)。
案例3:支持强度 = 否定强度(最终综合结果无倾向,可信度为0)
已知:,,一正一负且绝对值相等;
合成综合可信度:
结论:支持和否定的强度完全抵消,无法判断结论H的真假,可信度为0。
作业
1.什么是不确定性推理?它需要解决的问题是什么?
2.什么是可信度?可信度方法中证据不确定是如何表示的?
三、证据理论(D-S理论)
前言
可信度方法简单易用,能解决大部分单/多证据的推理问题,但它无法清晰表示“不知道”的不确定性,也难以处理多源证据的深度融合。而证据理论(D-S理论) 恰好能弥补这一缺陷,它能明确表示“不确定”,支持多证据融合,是本节的重点+难点。
DS 证据理论 = 能处理「我不知道」的概率。 而传统贝叶斯 不能处理「我不知道」,这就是它的局限。
贝叶斯要求:
所有可能事件的概率加起来 = 1
你不能留空,不能说「我不知道」。
举个最简单的例子:
假设你面前有个杯子:
可能是:
A:真的
B:假的
贝叶斯必须让你:
P(A) + P(B) = 1
比如:
P(A)=0.5,P(B)=0.5
哪怕你完全没信息,也必须硬猜一个分布。
👉 问题:
现实中,很多时候你就是:不知道!
贝叶斯逼你「强行猜概率」,这就是它的局限。
DS 理论:允许「我不知道」
DS 里有三个东西:
- A:真
- B:假
- {A,B}:我不知道是真还是假
你可以把信任度分给「不知道」!
完全没证据时:
m(A) = 0
m(B) = 0
m({A,B}) = 1
意思就是:
我什么都不知道,全部信任都给「不确定」。
1. 方法起源与应用
D-S证据理论起源于20世纪60年代的哈佛大学数学家A.P. Dempster利用上、下限概率解决多值映射问题,1967年他起连续发表一系列论文,标志着证据理论的正式诞生。而后Dempster的学生G.shafer对证据理论做了进一步研究,引入信任函数概念,形成了一套“证据”和“组合”来处理不确定性推理的数学方法从而形成了该理论。没错,D-S理论就是以这对师生的名字命名的。可处理不确定性和不知道两种不确定情况,适合多传感器、多专家决策的场景。
2. 核心基本概念
(1)样本空间D
变量x的所有可能取值的集合,且元素互斥;D的任一子集A对应命题“x的值在A中”。
或者说:某件事的所有可能结果的集合,结果之间互斥(不能同时发生)、穷尽(没有其他可能),比如风门故障的所有原因,记为 D={原因 1,原因 2,原因 3};
D = 你现在要判断的所有 “可能结果” 的全集
它必须满足两个条件:
互斥:同一时间只能有一个是真的
完备:所有可能情况都在里面,没有漏掉
- 示例:你要判断明天天气,可能的结果只有:晴、阴、雨,则D={晴,阴,雨},这就是证据理论里的样本空间 D。它不直接给单个结果赋值概率,而是给 D 的子集 分配信任度,如子集A={晴}表示“明天天气是晴”,A={晴,雨}表示“我相信明天不会阴”,D 就是所有这些子集的 “老家”,所有证据、信任函数、基本概率分配,全都围绕 D 展开。
- 示例:x为“看到的颜色”,则D={红,黄,蓝},子集A={红}表示“x是红色”,A={红,蓝}表示“x是红色或蓝色”。
命题:D 的任意子集就是一个命题,比如 “故障是原因 1”“故障是原因 1 或原因 2”,都是命题;
核心目标:用 3 个核心函数,量化对每个命题的信任程度,最终通过 “信任区间 ” 判断哪个命题最可能成立。
(2)概率分配函数m(A)【重点】
- D 是:你要判断的「所有可能答案」---圈出所有可能
- m 函数是:你对这些答案「到底信多少」----告诉你每一种可能有多大可信度
- 没有 m,D 只是一堆空结果,没法推理、没法决策
举个例子理解:
假设:D = {甲,乙,丙} (三个嫌疑人,凶手一定在里面)
你只知道 D,有用吗?没用,因为你不知道谁更可能是凶手。
这时候就需要 m 函数:它负责给子集分配信任度,比如:
m ({甲}) = 0.4 → 我有 0.4 相信是甲
m ({乙,丙}) = 0.6 → 我有 0.6 相信不是甲,但分不清乙和丙
这就是 概率分配 。
定义4.1
设D为样本空间,m: 2^D → [0,1] 为概率分配函数,满足两个条件:
- m(∅) = 0(空集的概率分配值为0);
- ∑(A⊆D) m(A) = 1(D的所有子集的概率分配值之和为1)。
- 含义:m(A)是对命题“A为真”的精确信任度,仅分配给D的子集,而非单个元素;
- 注意:2^D:所有子集,m:给每个子集分配信任度,m(A)是我精确相信 A 这个判断的程度,不是概率,无需满足∑(x∈D) m({x})=1;
- 示例:D={红,黄,蓝},m({红})=0.3,m({红,黄})=0.2,m(D)=0.1,其余子集m(A)=0,满足m(∅)=0且所有子集和为1。
m (A) 就是 “明确确定归属于 A 的信任度”,不包含任何猜测,剩下的信任度分配给 D,就是 “不知道” 的部分。
(3)信任函数Bel(A)【重点】
我们已经知道,基本概率分配函数 m 是对单个子集的精确信任度。但在实际判断中,我们往往需要知道对某个命题全部的、总的信任程度。
- 通俗定义
对某个命题 A(D 的子集),Bel (A) 是 A 的所有子集的 m 值之和,记为:Bel (A) = ∑m (B) (B⊆A,即 B 是 A 的子集),取值 0~1,代表对命题 A 为真的总信任程度,也是信任度的下限(至少有这么多信任度)。 - 核心逻辑
A 的子集是比 A “更具体的命题”,比如 A={a,b}(故障是 a 或 b),子集是 {a}、{b}、∅,Bel (A) 就是把这些具体命题的精确信任度加起来,得到对 A 的总信任。
再比如在样本空间 红,黄,蓝 中,已知基本概率分配:红,红黄。
如果只看 m,只能得到对单独集合的信任;为了求出对 红、红黄 这些命题总共相信多少,就需要引入信任函数 Bel(A)。
Bel: 2^D → [0,1],定义为:Bel(A) = ∑(B⊆A) m(B)
- 含义:对命题“A为真”的总信任度,是A的所有子集的精确信任度之和;
- 性质:Bel(∅)=0,Bel(D)=1;
- 示例:D={红,黄,蓝},m({红})=0.3,m({红,黄})=0.2,则Bel({红})=0.3,Bel({红,黄})=m({红})+m({红,黄})=0.3+0.2=0.5, Bel({红,黄,蓝})=1。
{红} 里面只有它自己这一个 “有效子集”,所以 Bel ({红}) 就等于 m ({红})。
Bel ({红,黄}) 就是:只要是 {红,黄} 里面的子集,全都算进去! 所以 Bel ({红,黄}) = m ({红}) + m ({红,黄})+ m ({黄}) + ∅ =0.3+0.2+0+0=0.5
Bel (A) 是 “能百分百确定 A 为真的信任度”,是对 A 最保守的信任判断,只算 “实锤 ” 的部分。
(4)似然函数Pl(A)【重点】
我们已经通过信任函数
得到了对命题 (A) 确定支持的总程度,它代表对 (A) 信任的下限。
但仅靠下限无法完整描述不确定性:
我们还需要知道 (A) “有可能成立”的最大程度,也就是信任的上限。 为此,我们引入似然函数:对 A 的最大可能信任度 —— 哪怕有猜测、有不确定,对 A 的信任度也不会超过这个数。 👇
其中 ¬A 表示 A 的对立命题(A 不发生)。
含义:
- Bel(A):完全相信 A 的程度(下限)
- Pl(A):不否定 A 的程度(上限)
只有同时得到
这个信任区间,才能完整刻画对命题 (A) 的不确定性。
总结:
- 含义:不可驳斥函数/上限函数,表示对命题“A为真”的不否定程度,即A可能为真的最大信任度;
- 信任函数与似然函数的关系:Bel(A) ≤ Pl(A);
- 区间[Bel(A), Pl(A)]为信任区间,区间越小,不确定性越低;
- 若Bel(A)=Pl(A),则A的不确定性为0,等价于概率;
- 若Bel(A)=0且Pl(A)=1,则对A完全不确定。
- 示例:Bel({红})=0.3,Bel(¬{红})=Bel({黄,蓝})=0,则Pl({红})=1-0=0.7,信任区间为
[0.3,0.7]。
Pl (A) 是 “最多可能信任 A 为真的程度”,包含所有 “实锤 + 猜测” 的部分,只要没有证据否定 A,Pl (A) 就会接近 1。
单独的 Bel (A) 或 Pl (A) 都不能完整描述命题的不确定性,把两者结合成「信任区间」,才是 D-S 理论的核心价值,区间的宽窄直接反映不确定性的大小。
3. 概率分配函数的正交和【重难点】
正交和是证据理论的核心,解决多证据融合问题:将多个证据对应的概率分配函数m1、m2合并为一个综合的概率分配函数m = m1⊕m2。
(1)核心公式
设m1和m2是样本空间D上的两个概率分配函数,其正交和m(A)定义为:
其中,K为归一化因子,消除融合中的矛盾,公式为:
(2)关键结论
- 若K≠0,则正交和m是有效的概率分配函数;
- 若K=0,则m1和m2矛盾,无正交和,即无法融合。
总结一句话就是:👇
- 单个 m 只能表示一条证据
- Bel,Pl 只能对一条证据做评估
- 正交和 ⊕ 才能把多条证据合成一条
- 没有它,证据理论就无法做多源信息融合、无法做最终决策
总结 D-S 理论:
用 m (A) 给实锤信任度,用 Bel (A) 算下限、Pl (A) 算上限,用 [Bel,Pl] 区间描述完整不确定性,用正交和融合多证据,最终从区间中判断最可能的结论,完美解决 “既不能肯定、也不能否定” 的推理问题。
5. 基于证据理论的不确定性推理案例
规则:
如果 流鼻涕 则感冒但非过敏性鼻炎(0.9) 或 过敏性鼻炎但非感冒(0.1);
如果 眼发炎→则感冒但非过敏性鼻炎(0.8)/或 过敏性鼻炎但非感冒(0.05);
又有事实:小王流鼻涕(0.9)、眼发炎(0.4),括号中的数字表示规则和事实的可信度。
用证据理论推理出小王患什么病?
基于证据理论的不确定性推理步骤: 👇
- 建立问题的样本空间D;
- 由经验/规则给出各证据的基本概率分配函数m;
- 若有多证据,计算概率分配函数的正交和,得到综合m;
- 计算所关心子集的信任函数Bel(A)、似然函数Pl(A),得到信任区间[Bel(A), Pl(A)];
- 根据信任区间判断结论:区间越小,结论越确定。
我给你最精简、纯符号、能直接复制的完整步骤,只写推导,不写公式,你要的我全补上:
1. 建立样本空间 D
D = {感冒, 过敏性鼻炎}
2. 给出基本概率分配
证据1:流鼻涕
事实可信度 = 0.9
规则:
感冒但非过敏性鼻炎:0.9
过敏性鼻炎但非感冒:0.1
m1(感冒非鼻炎) = 0.9 × 0.9 = 0.81
规则可信度:如果流鼻涕 → 感冒但非过敏性鼻炎,可信度 = 0.9;事实可信度:小王确实流鼻涕,这条事实可信 = 0.9;这条规则真正能支持结论的可信度 =规则可信度 × 事实可信度
m1(鼻炎非感冒) = 0.1 × 0.9 = 0.09
m1(D) = 1 - 0.81 - 0.09 = 0.1
m₁(D) = 不确定、无法判断、证据不足的那部分可信度
证据2:眼发炎
事实可信度 = 0.4
规则:
感冒但非过敏性鼻炎:0.8
过敏性鼻炎但非感冒:0.05
m2(感冒非鼻炎) = 0.8 × 0.4 = 0.32
m2(鼻炎非感冒) = 0.05 × 0.4 = 0.02
m2(D) = 1 - 0.32 - 0.02 = 0.66
3. 计算正交和,得到综合 m
两两交集计算
冲突 K = 0.81×0.02 + 0.09×0.32 = 0.045
1-K = 0.955
综合 m:
m(感冒非鼻炎) ≈ 0.865-----> Pl (鼻炎非感冒) = 1 - Bel (感冒非鼻炎)= 1 - 0.865 = 0.135
m(鼻炎非感冒) ≈ 0.066----->Pl (感冒非鼻炎) = 1 - Bel (鼻炎非感冒)= 1 - 0.066 = 0.934
m(D) ≈ 0.069
4. 计算信任区间
感冒非鼻炎:[0.865, 0.934]
鼻炎非感冒:[0.066, 0.135]
5. 结论
小王患 感冒但非过敏性鼻炎
四、模糊推理方法
前言
概率方法、可信度方法、证据理论处理的都是随机性不确定性——事件要么真要么假,只是我们对结果不确定。但现实中还有一类模糊性不确定性(如“温度高”“个子高”“衣服多”),这类概念没有明确的边界,无法用经典集合/概率描述,需用模糊推理方法解决,这也是教学大纲的重点。
1. 模糊逻辑的起源与发展
1965年美国L.A.扎德发表《fuzzy set》,首次提出模糊集合理论,奠定模糊推理基础;
- 1974年,Mamdani首次将模糊理论应用于工业控制(蒸汽机控制);
- 1980年后,模糊理论在日本、欧美广泛应用,诞生模糊洗衣机、空调、地铁控制系统等产品;
- 核心:用隶属度描述元素属于模糊集合的程度,突破经典集合“非此即彼”的限制。
1.1 案例理解:
假如你想让空调:s
- 太热 → 猛吹
- 有点热 → 小风
- 正好 → 停机
传统程序只能写死阈值:
- 30℃ = 热
- ≤30℃ = 不热
问题: 29.9℃ 不吹,30.1℃ 狂吹?太僵硬、不舒服。这就是模糊逻辑要解决的:二值逻辑太绝对,现实是渐变的。
模糊逻辑怎么解决? 它不搞 0 或 1,只搞程度(0~1)。
- 把温度变成「模糊集合」:冷,舒适,微热,很热
每个温度,都有一个隶属度: 28℃:微热 0.8,很热 0.2 | 32℃:微热 0.2,很热 0.8
👉 不是 “是 / 不是”,而是 “有多像”。 👈
- 用人类语言写规则
- 如果很热,则大风
- 如果微热,则中风
- 如果舒适,则停机 / 小风
- 模糊推理 → 输出精确风速
系统自动算出:28℃ → 风速 80% | 30℃ → 风速 20%
1.2 模糊逻辑真正解决的 4 类问题
- 概念模糊,没法精确定义高 / 矮、快 / 慢、美 / 丑、冷 / 热
- 规则来自经验,不是数学公式老司机怎么开车、老师傅怎么调机器
- 系统太复杂,建不出精确模型洗衣机、空调、无人机、机器人
- 要求稳定、平滑,不允许剧烈突变温控、调速、避障、自动泊车
2. 核心基础:模糊集合
(1)经典集合vs模糊集合
- 经典集合:元素与集合的关系只有“属于”或“不属于”,特征函数值为{0,1};
- 模糊集合:给每个元素赋予一个[0,1]的实数,描述其属于集合的强度,该实数为隶属度μ(x),所有隶属度构成隶属函数。
- 示例:“成年人”模糊集合中,25岁μ=1,35岁μ=0.5,45岁μ=0.1,无明确的“成年年龄界限”。
(2)模糊集合的表示方法
设论域U为元素的全体,模糊集合A的表示分3种情况:
- Zadeh表示法(最常用)
- 离散有限论域:(“+”为并集,非加法);
- 连续论域:。
- 序偶表示法:;
- 向量表示法:(省略元素,仅保留隶属度)。
(3)隶属函数
- 定义:描述元素属于模糊集合的程度,是模糊集合的核心;
- 常见形式:正态分布、三角分布、梯形分布;
- 确定方法:模糊统计法、专家经验法、二元对比排序法等;
- 示例:扎德给出“年老(O)”和“年青(Y)”的隶属函数(论域U=[0,100]):
3. 模糊集合的运算
设A、B为论域U上的模糊集合,μ_A(x)、μ_B(x)为其隶属函数,核心运算如下:
- 包含:若对任意x∈U,有μ_A(x) ≤ μ_B(x),则A⊆B;
- 相等:若对任意x∈U,有μ_A(x) = μ_B(x),则A=B;
- 交运算(∩):μ_A∩B(x) = min{μ_A(x), μ_B(x)}(取小);
- 并运算(∪):μ_A∪B(x) = max{μ_A(x), μ_B(x)}(取大);
- 补运算(¬):μ_¬A(x) = 1 - μ_A(x);
- 代数运算:代数积μ_A·B(x)=μ_A(x)×μ_B(x)、代数和μ_A+B(x)=μ_A(x)+μ_B(x)-μ_A(x)×μ_B(x)等。
4. 模糊关系与模糊关系的合成
(1)模糊关系
- 普通关系:描述元素间“是否有关联”;
- 模糊关系:描述元素间“关联程度的大小”,用模糊矩阵表示,记为R,元素r_ij∈[0,1]表示x_i与y_j的关联程度。
- 示例:身高论域X={140,150,160,170,180},体重论域Y={40,50,60,70,80},r_ij表示身高x_i与体重y_j的匹配程度,构成5×5的模糊关系矩阵。
(2)模糊关系的合成
设R1是X→Y的模糊关系,R2是Y→Z的模糊关系,则R1与R2的合成R = R1∘R2(X→Z的模糊关系),核心计算为最大-最小合成法:
- 含义:取行与列的最小隶属度,再取所有最小值的最大值,得到合成后的隶属度。
5. 模糊推理核心方法
模糊推理的核心是模糊规则,形式为IF A THEN B(A为条件模糊集合,B为结论模糊集合),推理本质是条件模糊向量与模糊关系的合成,步骤为:
- 根据模糊规则
IF A THEN B,计算A到B的模糊关系R; - 若已知新的输入条件A’,则输出结论B’ = A’ ∘ R(模糊关系的合成);
- 若有N条模糊规则,先分别计算每条规则的模糊关系R1、R2…Rn,再求总模糊关系R = R1∪R2∪…∪Rn(取大)。
6. 模糊决策
模糊推理的结论是模糊向量,需转化为精确数值才能应用于实际控制,这一过程为模糊决策,常用3种方法:
- 最大隶属度法:取模糊向量中隶属度最大的元素作为精确值;
- 示例:模糊向量B’=[0,0,0.3,0.6,0.8],最大隶属度为0.8,对应元素5,取结论为5。
- 加权平均判决法:以隶属度为权重,对元素进行加权平均,公式为:
- 最常用,适合工业控制场景。
- 中位数法:取模糊向量的隶属度曲线与横坐标围成面积的中位数作为精确值,适合隶属度分布均匀的场景。
7. 模糊推理的实际应用
示例:模糊控制规则IF 温度低 THEN 风门开大,论域为{1,2,3,4,5};
- “温度低”:A=[1,0.6,0.3,0,0],“风门大”:B=[0,0,0.3,0.6,1];
- 已知事实“温度较低”:A’=[0.8,1,0.6,0.3,0];
- 推理步骤拆解:
- 求规则的模糊关系矩阵 R(Mamdani 法:取小运算 ∧);
- 用事实 A′ 与关系矩阵 R 合成,得到风门开度的模糊集合 B′;
- 对 B′ 解模糊(重心法),得到最终的精确风门开度值。