
文生图公选课
文生图公选课
本节内容
- 人工智能生成内容(AIGC)的发展与应用场景
- 文生图大模型的核心原理
- 主流文生图模型简介
- 如何选择诸多优质的Checkpoint?
- Checkpoint大模型调用技巧
- 正向提示词
- 提示词权重
- 反向提示词
- 风景类案例
1. AIGC的发展与应用场景
概要
1. AIGC简介 👇
人工智能生成内容(AI-Generated Content, AIGC)是指使用人工智能技术自动创建的各类数字内容,包括文本、图像、音频、视频等多媒体形式。近年来随着深度学习技术的发展,AIGC在质量和多样性方面取得了突破性进展。
2. 发展历程 👇
- 2014年:GAN(生成对抗网络)的提出,开启了 AI 生成内容的新纪元
- 2020年:GPT-3展示了大规模语言模型的强大能力
- 2021年:DALL-E展示了文本到图像生成的可能性
- 2022年:Stable Diffusion和Midjourney等开源模型掀起文生图浪潮
- 2023年:多模态生成模型兴起,支持文本、图像、音频、视频等跨模态内容生成
- 2024年:AIGC在游戏、电商、广告、教育、娱乐等多个行业得到广泛应用
- 2025年:AIGC技术不断优化,生成质量与多样性进一步提升
3. 应用场景 👇
- 创意设计
- 品牌设计:logo、海报、包装设计
- 数字艺术:概念图、插画、数字绘画
- UI/UX设计:界面原型、图标设计

- 内容创作
- 社交媒体内容
- 营销物料
- 教育资源

- 娱乐传媒
- 游戏素材生成
- 影视特效制作
- 虚拟人物设计

- 商业应用
- 电商产品展示
- 房地产效果图
- 工业设计草图


4. 技术特点 👇
- 自动化生成:通过简单的文本提示即可生成复杂内容
- 可定制性:支持风格迁移和精确控制
- 高效率:大幅提升内容生产效率
- 成本优势:降低内容制作成本
- 创新性:能产生新颖独特的创意表达
5.挑战:👇
- 版权问题:AI 生成的图像是否算“原创艺术”引发法律争议
- 职业冲击:部分插画师和平面设计师面临竞争压力
- 虚假信息:生成逼真虚假图片
- 伦理道德:AI 生成内容可能引发伦理道德问题
总结
回答一下问题,看看你掌握了多少
- AIGC是什么?🎤
- AIGC的应用场景有哪些?🎤
- AIGC的技术特点是什么?🎤
- AIGC的挑战有哪些?🎤
2. 文生图
概要
1. 什么是文生图?
文生图(Text-to-Image)是指通过输入文本描述,利用AI模型自动生成相对应的图像的技术。它是AIGC技术中最受欢迎的应用之一。
2. 为什么要学习文生图?
- 提升工作效率:快速生成创意素材
- 降低创作门槛:无需专业设计技能
- 拓展职业机会:掌握AI创作工具
- 激发创意灵感:探索更多可能性
3. 文生图的原理是什么?
- 文本理解:将输入的文本转换为向量表示
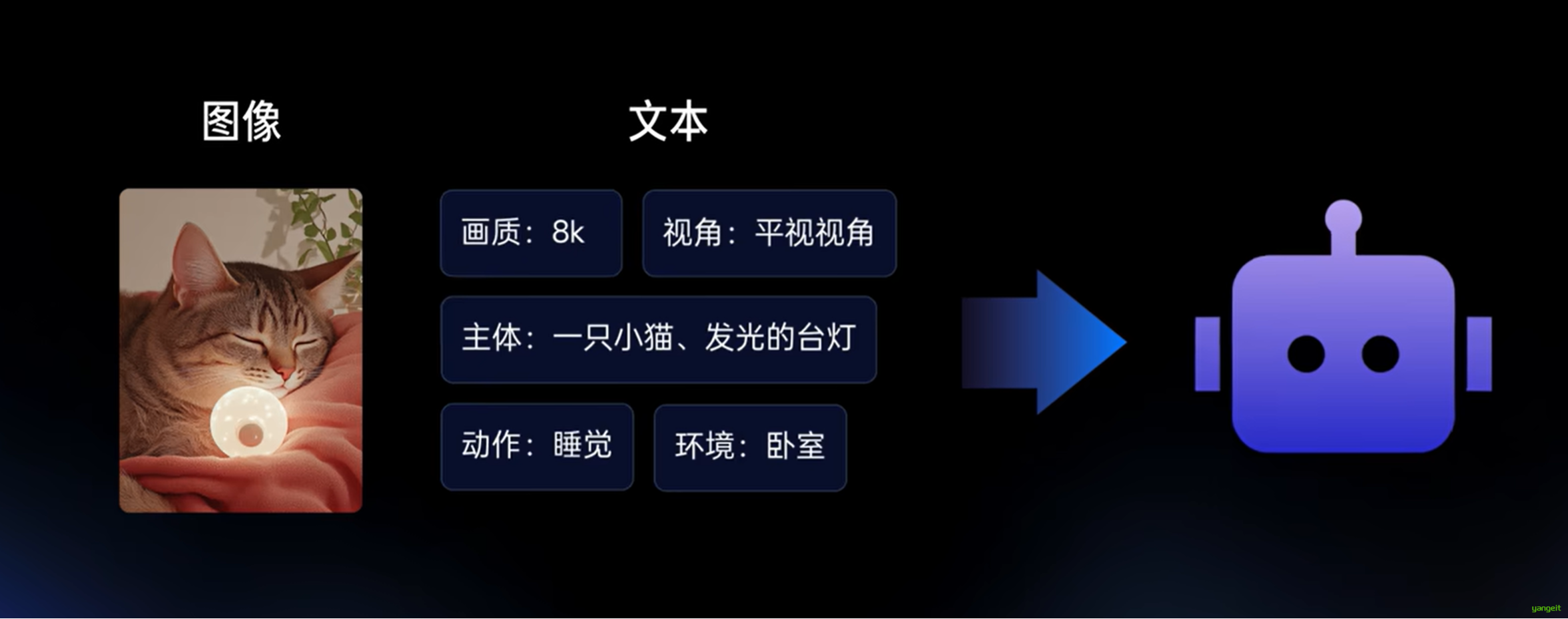
- 扩散过程:从随机噪声逐步生成图像

- 迭代优化:不断调整图像以符合文本描述

- 当训练者认为生成的图像符合描述时,将这个点进行存档,称为checkpoint
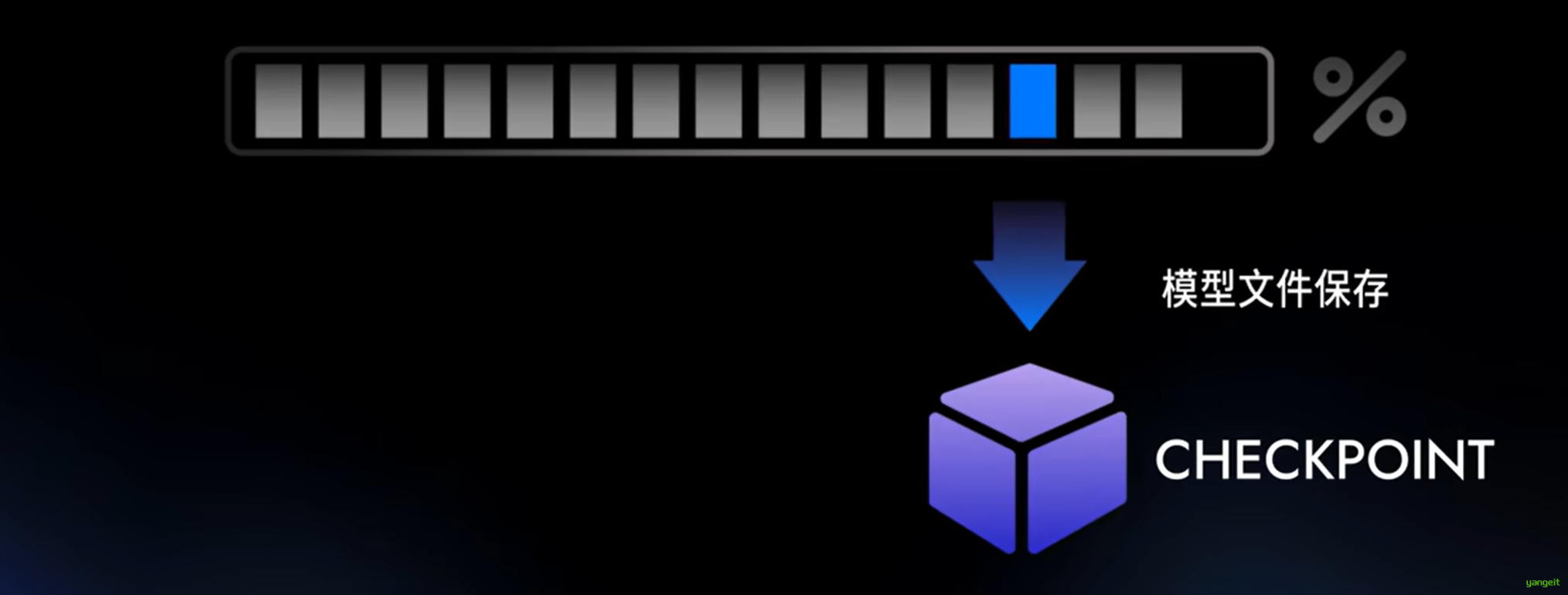
- checkpoint就像游戏中的存档点一样,记录了模型在此训练阶段学到的所有知识.

当模型训练到新的阶段时,可以加载checkpoint,继续训练,从而避免从头开始训练。
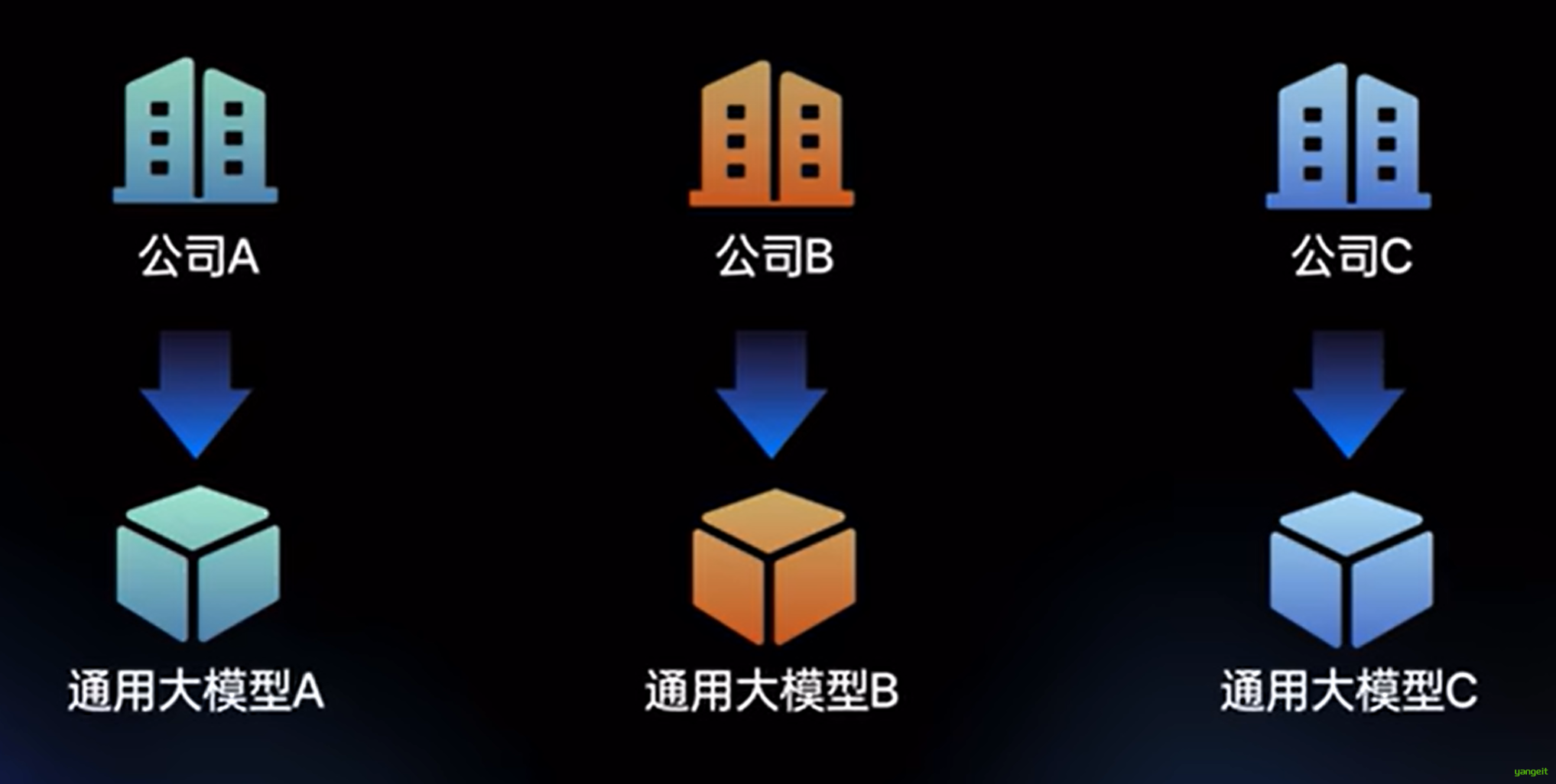
- 按照上述的训练方式,不同的公司根据不同的数据集,训练出不同的模型,这些模型被称为通用的checkpoint
- 风格控制:通过额外参数调整生成效果
4. 常用的生图产品
- Midjourney(简称MJ,特点:付费、专业、稳定)
- Stable Diffusion(简称SD,特点:开源、免费、可定制性强)
- 豆包(特点:免费、简单、易用)
- DALL-E(特点:付费、专业、稳定)
5. 文生图的本质 👇
文生图的本质是:从文本描述中提取语义信息,生成符合描述的图像。
生图的过程本质是:从随机噪声逐步生成图像,并不断调整以符合文本描述。

总结
回答一下问题,看看你掌握了多少
- 文生图的原理是什么?用自己的话总结一下:🎤
- 常用的生图产品有哪些?各有什么特点?🎤
- 生图的过程本质是什么?🎤
3. Sd产品介绍
概要
Stable Diffusion是一个开源的文生图模型,由CompVis、Stability AI和LAION的研究团队共同开发。它基于Diffusion Model,是一种生成模型,能够从随机噪声逐步生成图像,并不断调整以符合文本描述。

webui是sd的一个前端界面,它提供了一个图形用户界面,用户可以通过这个界面来使用sd模型。webui还支持一些高级功能,如风格迁移、图像编辑等。
comfyui是另一个sd的前端界面(由Stability AI开发,原作者已经离职了),它是一个基于gradio的webui,具有更简洁的界面和更好的性能。与webui相比,comfyui在性能和稳定性方面都有所提升,同时支持更多的模型和功能,特别适合可控的批量生图,且硬件消耗小于webui。
总结
回答一下问题,看看你掌握了多少
- 什么是Stable Diffusion?特点是什么?🎤
- 什么是webui?特点是什么?🎤
- 什么是comfyui?特点是什么?🎤
4. SD安装
概要
本地搭建SD环境有2中方式:

相比而言,一键安装更加简单
如果你的电脑配置较低,可以使用云部署,直接使用在线的服务器和显卡 👇

推荐使用:LiblibAI
特点: liblib云端部署,不消耗本机配置,有浏览器就可以访问,每天送200算力,日常学习练习沟通了
生图一般10算力/张
总结
课堂作业
- 完成liblibai网站的注册,并且尝试生成一张图片,看看效果如何?✏️
5. SD基础界面介绍1
webui界面介绍
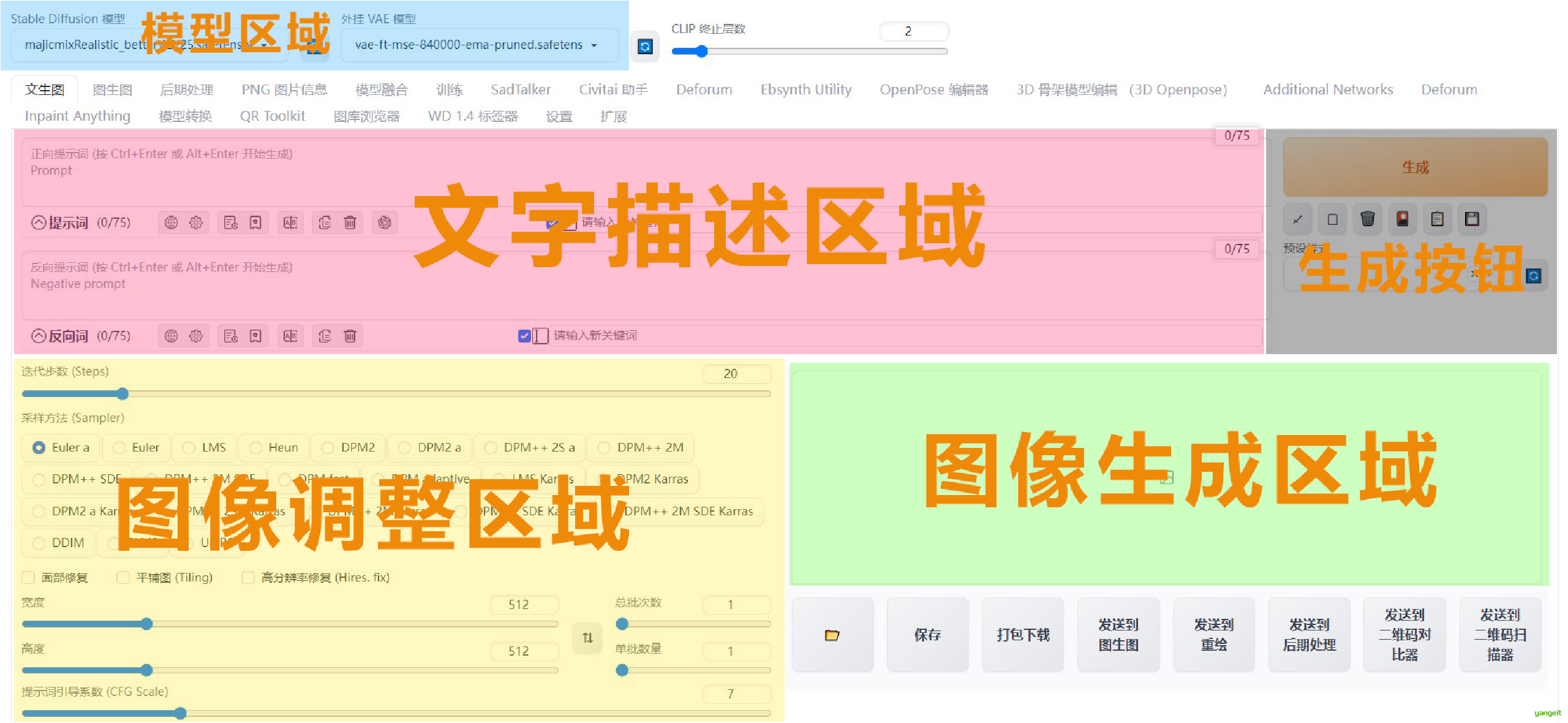
webui面板 👇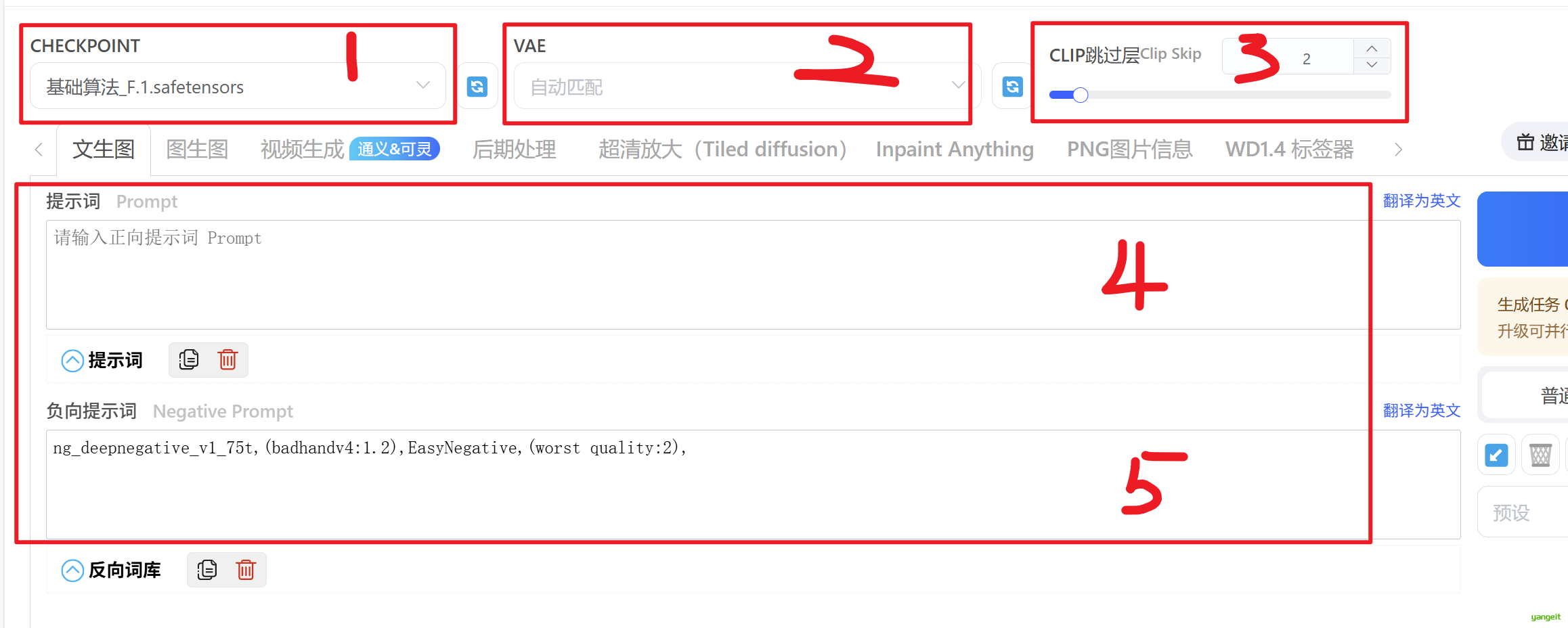
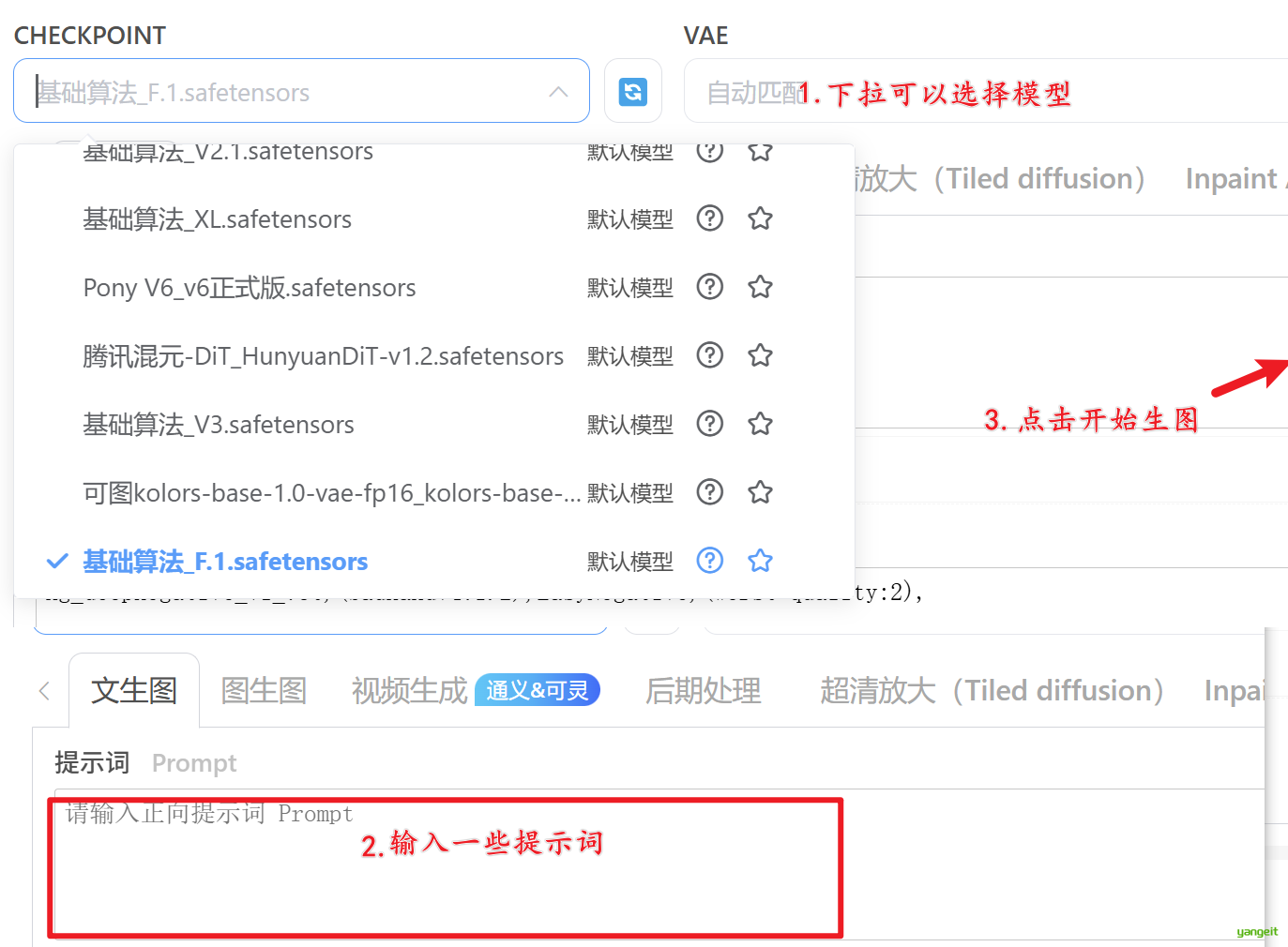
1. Checkpoint 👇

Checkpoint是SD模型训练过程中的一个中间状态,它记录了模型在训练过程中学到的所有知识。Checkpoint可以用于生成图像,也可以用于微调模型。不同的Checkpoint生成的图像风格和细节可能会有所不同。



更多模型请查看:https://www.liblib.art/
2. VAE 👇
VAE,全名 Variational autoenconder,中文叫变分自编码器。作用差不多可以理解为滤镜。 在生成 AI 绘画时,会对输出的颜色和线条产生影响。
显然,有无 VAE 会产生明显的差异。没有 VAE,整体颜色会变得暗淡。

有些 VAE 模型可能会内置制作者推荐的 VAE,但大多数情况下应该认为没有内置,Liblib会自动选择。 此外,如果您想要更改色调等内容,也可以通过更改 VAE 来实现,因此最好尽可能自己准备。
3. CLIP跳过层 👇
正如您从上图中看到的,可以观察到显著的变化。(很简单大家理解 1-5 是推荐调整的数值,从 6 开始不推荐) 从构图的变化来看,当 Clip Skip 超过 5 时,虽然大部分的构图变得相对稳定,但图像的清晰度变得非常差。这可能是因为参考层的深度较浅,传递的信息量减少,无法进行正确的语言转换,不准确的信息成为噪声并传递。
总而言之:👇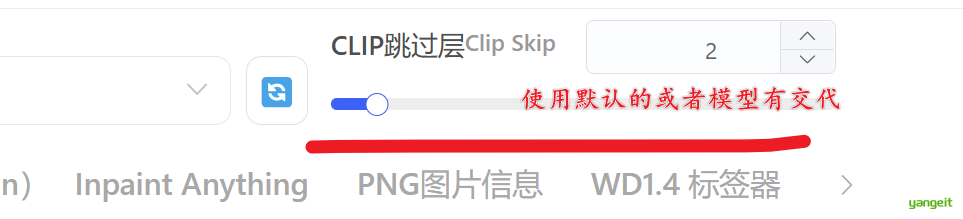
一般情况填写2就行,如果生成二次元类型的图片,填写1就行
4. 正向提示词 👇
正向提示词是指用户希望生成的图像所具有的特征,例如“高清”、“清晰”、“色彩丰富”等。这些提示词会被模型用来生成图像,以符合用户的期望。
采样方式:DPM++ 2M Karras
提示词如下:
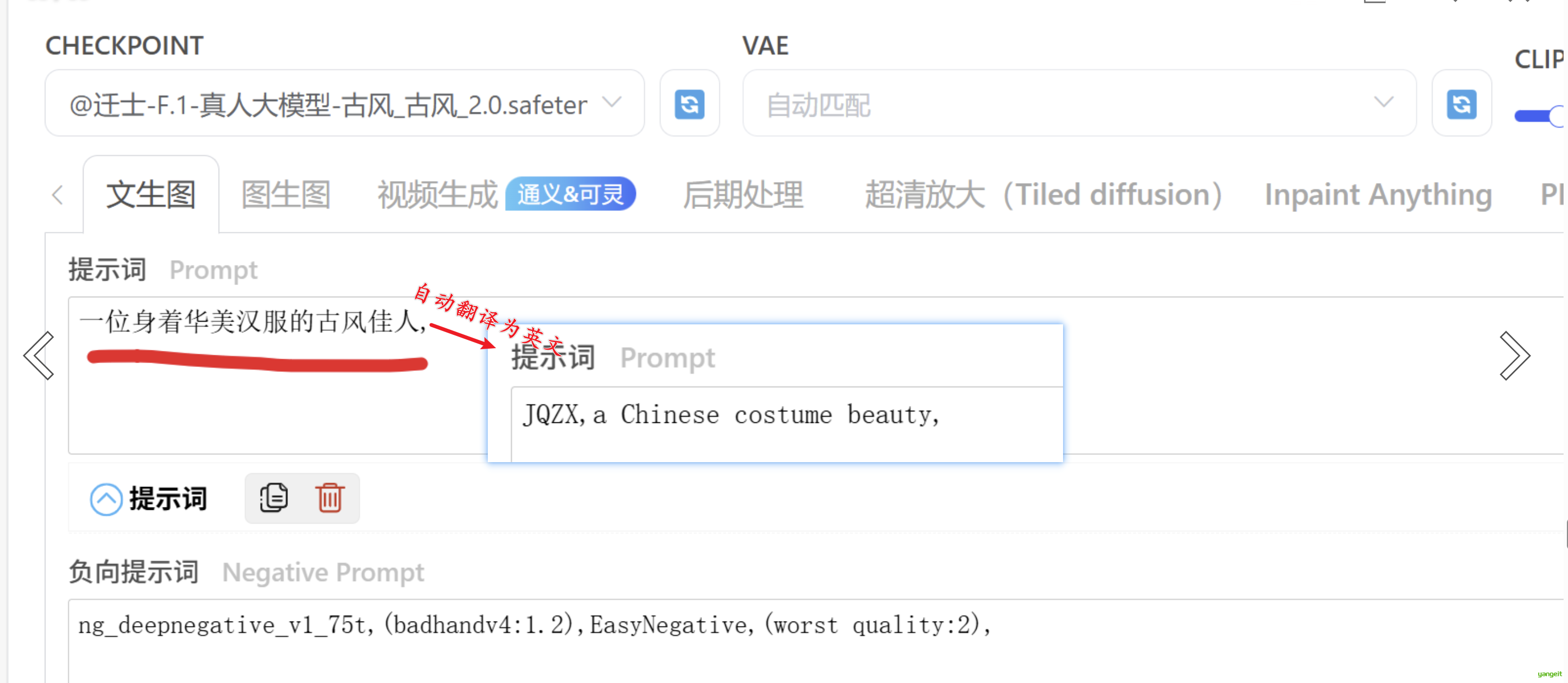
正向提示词:
一位身着华美汉服的古风佳人
负向提示词(暂时不用懂)
ng_deepnegative_v1_75t,(badhandv4:1.2),EasyNegative,(worst quality:2),
特点:👇
- 提示词的顺序很重要,越前面的权重越高 后期再说权重
- 提示词之间用逗号隔开
- 提示词的长度不要超过 75 个字符
- 提示词的权重不要超过 1.5
5. 负向提示词 👇
负向提示词是指用户希望生成的图像所不具有的特征,例如“模糊”、“低分辨率”、“不清晰的线条”等。这些提示词会被模型用来生成图像,以避免生成包含这些特征的图像。
负面提示词(需排除的元素):
“ng_deepnegative_v1_75t, (badhandv4:1.2), EasyNegative, (worst quality:2)
负向提示词解释:
ng_deepnegative_v1_75t - 深度抑制低质量版本1.75倍强度
(badhandv4:1.2) - 特别抑制手部畸形(v4模型,1.2倍强度)
EasyNegative - 基础负面标签库(自动过滤常见缺陷)
(worst quality:2) - 强烈排除最差质量(2倍权重)总结
课堂作业
- 在liblib的首页找一个你喜欢的模型,并尝试生成一张图片,看看效果如何?🎤
请尝试使用不同的提示词,看看生成的图片有什么不同?(初学者建议使用F.1基础模型 🎤
负向提示词的作用是什么?常见的负向提示词有哪些?🎤
6. SD基础界面介绍2
sd基础界面
代码操作

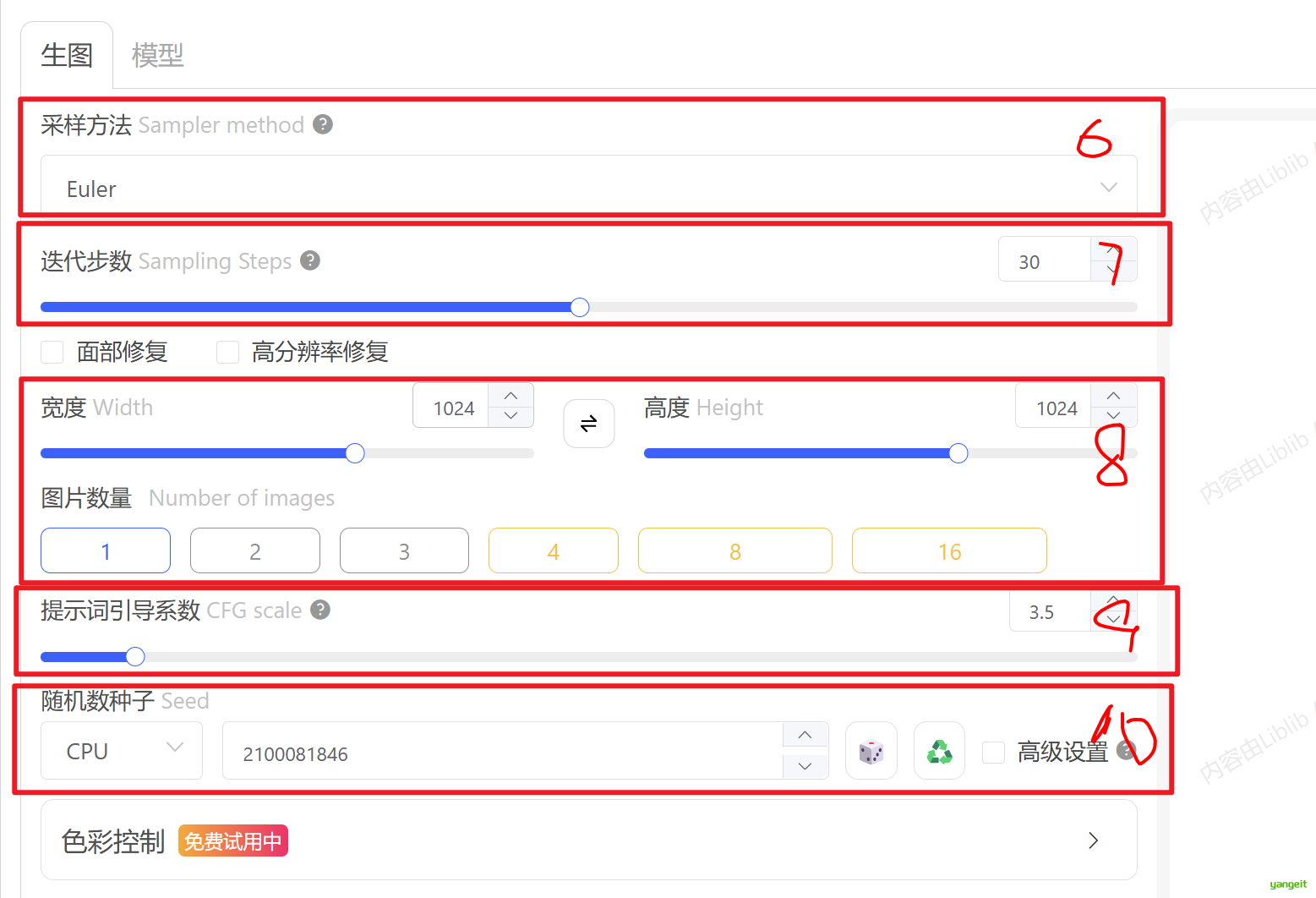
文生图的本质就从一张充满噪点的图片,模型会一步一步的去除与其无关的噪点,不同的采样方法只不过是去除噪点的方式不一样,有的采样方法是一点点的去除,有的采样方法是一整块一整块的快速去除,因此不同的采样方式会给生成效果带来细节上的差异。

上图,提示词一样,但是采样方法不一样,可以发现出图的细节也不一样,一般来说采样方法直接选择模型作者推荐的就行,如果没有说明,可以用Euler a,当然可以用DPM++ 2M Karras. Euler a为基础采样方式,效果普适性高;推荐体验DPM++ 2M Karras采样方式,更快更优质;

迭代步数(steps)指的是算法迭代更新图像的次数。每一次迭代,算法都会根据上一次的结果更新图像的像素值,直到达到预设的迭代步数为止,说白了就是去噪次数。去噪次数越少速度越快,质量越低,去噪次数越多,画面的细节就越精细,质量越高,但是过多也可能会导致画面失真,迭代步数直接选择模型作者推荐的就行。 建议25-35步之间最优,可以不断的尝试,40步以上提升有限。
如果画面模糊或者出现彩色的斑点,表示步数太少,可适当的增加步数,不建议一开始设置太高的迭代步数,影响观察出图的效果,花费时间较多

宽度高度
生成图片的宽高,模型不同,生成图片的宽高也不同,过大的宽高会导致生图变形,对于基础算法1.5系列的模型来说 ,初始宽高最好设置在512和768像素之间,最大不超过1024.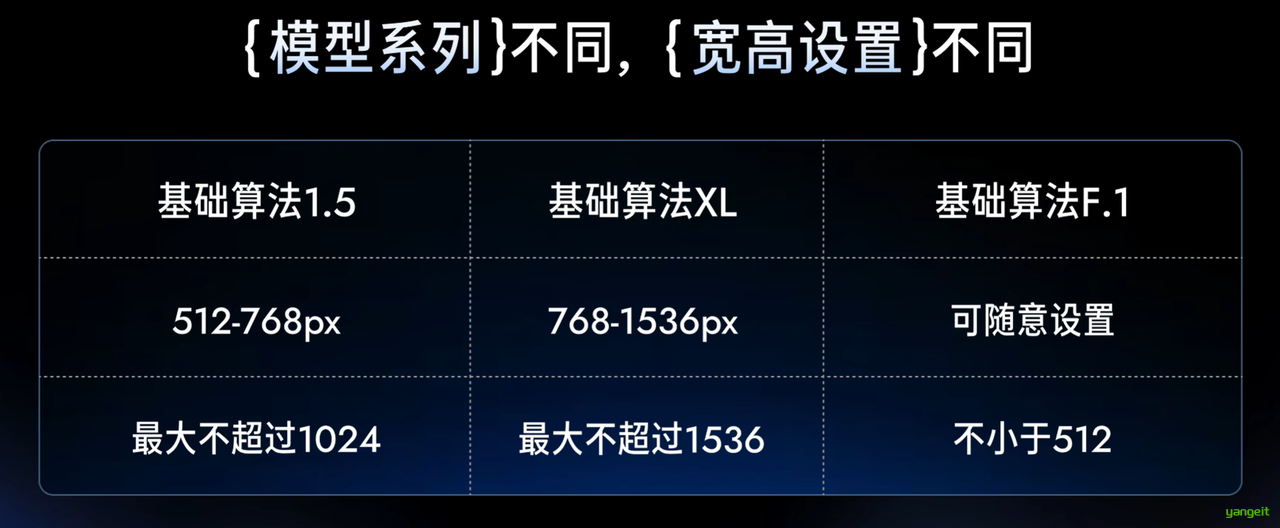
在范围以内,图片的尺寸也不要随便设置,建议使用64的倍数,如512,768,1024,1536等


图片数量
表示一次性生成多少图片,我们常常说抽卡,指的就是多生产就几张,然后挑出合适的
提示词引导系数
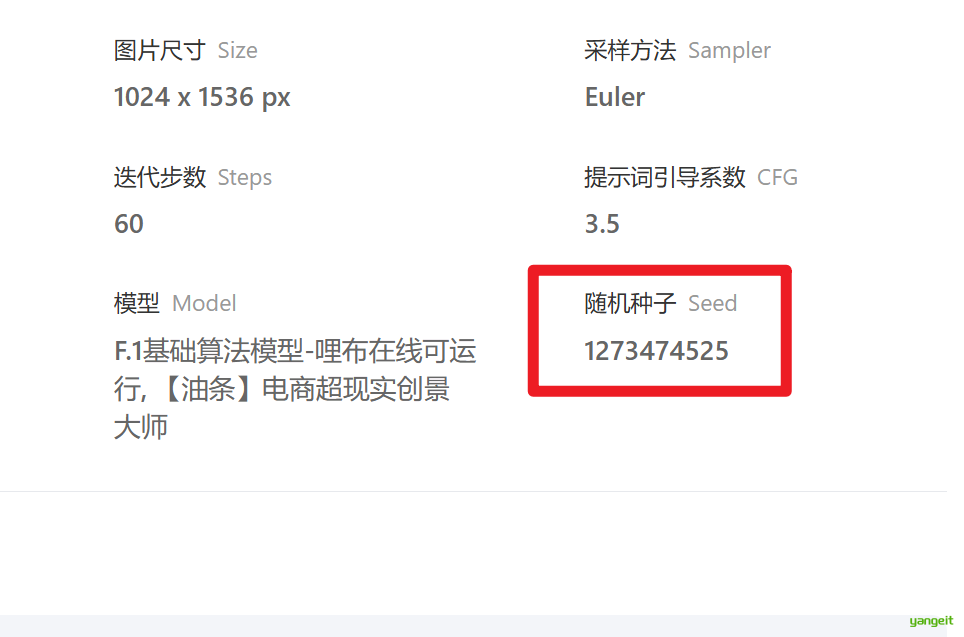
引导系数控制着生图过程对提示词的依赖程度,数值过高的时候,会严格遵循提示词,结果可能不够自然,数值低的时候,ai会自由发挥,画面可能会偏离主题,推荐使用模型详情页的说明,一般3.5~7.5。




每个种子都代表不同状态的噪点图,即使提示词,迭代步数,尺寸等信息完全一致,噪点的分布状态不同,最终生成的画面也会不同(文生图本质就是去噪的过程),种子值的默认值是-1,代表随机生成。如果想复刻别人的图片,除了提示词标点符号,生成参数这些信息要一样,最重要的随机数种子也要一样,这样才能生存一模一样的图像
总结
回答问题,巩固知识
- 采样方法的作用是什么?常见的采样方法有哪些?🎤
- 迭代步数的作用是什么?如何选择合适的迭代步数?🎤
- 尺寸数量如何设置?🎤
- 引导系数的作用是什么?🎤
- 随机数种子是什么?🎤
7. 这么多优质的Checkpoint,我们如何选择哪个尼?
这么多优质的Checkpoint,我们如何选择哪个尼?s
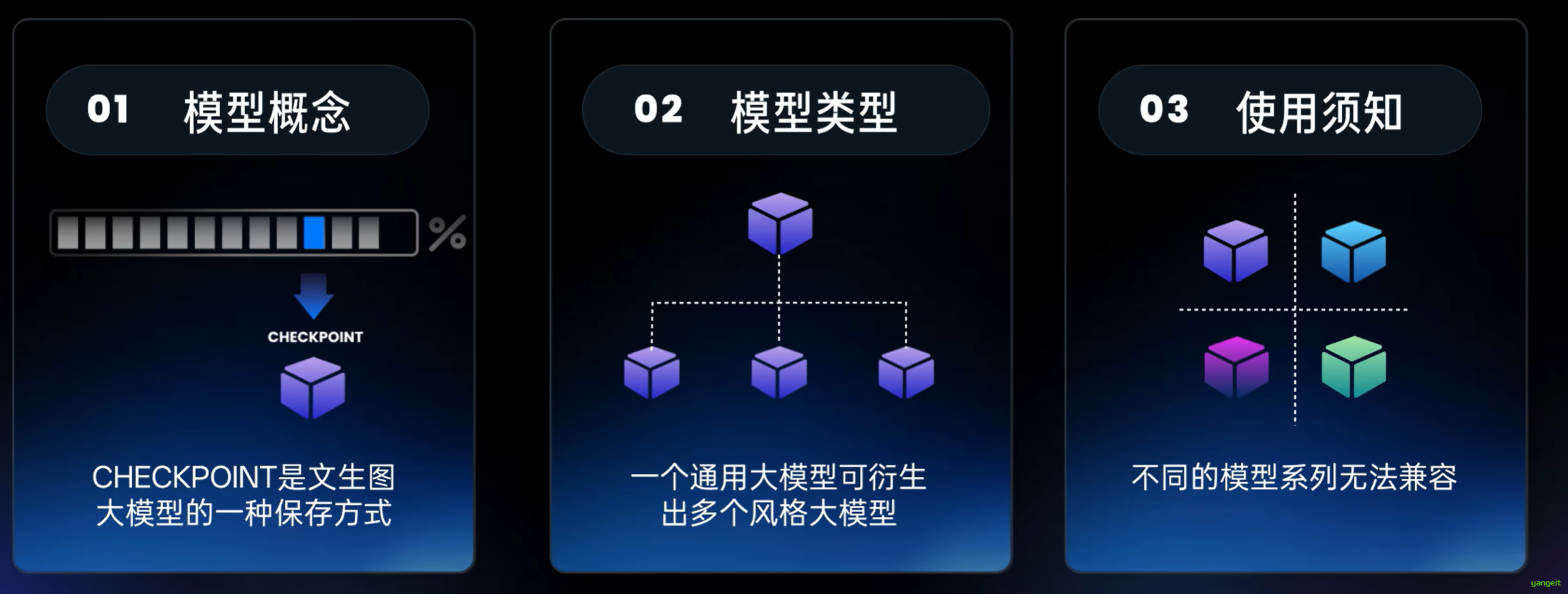
我们已经知道为什么有这么多的Checkpoint原因在这儿
那么我们如何选择这些Checkpoint呢? 👇 👇
1. 可以从大流,如最多下载的,最热门的,最新的等角度来选择
lib官网:https://www.liblib.art/
- 按照自己的需求来选择,比如我需要风格化,那么我就选择风格化相关的Checkpoint
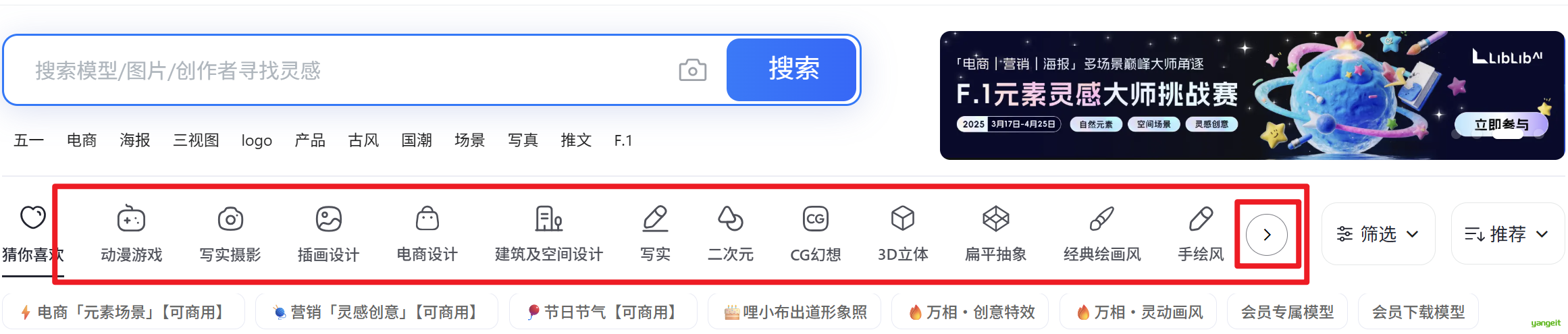
3. 直接在搜索栏,搜索关键字,比如我搜索“电商”,那么就会显示所有包含电商的Checkpoint
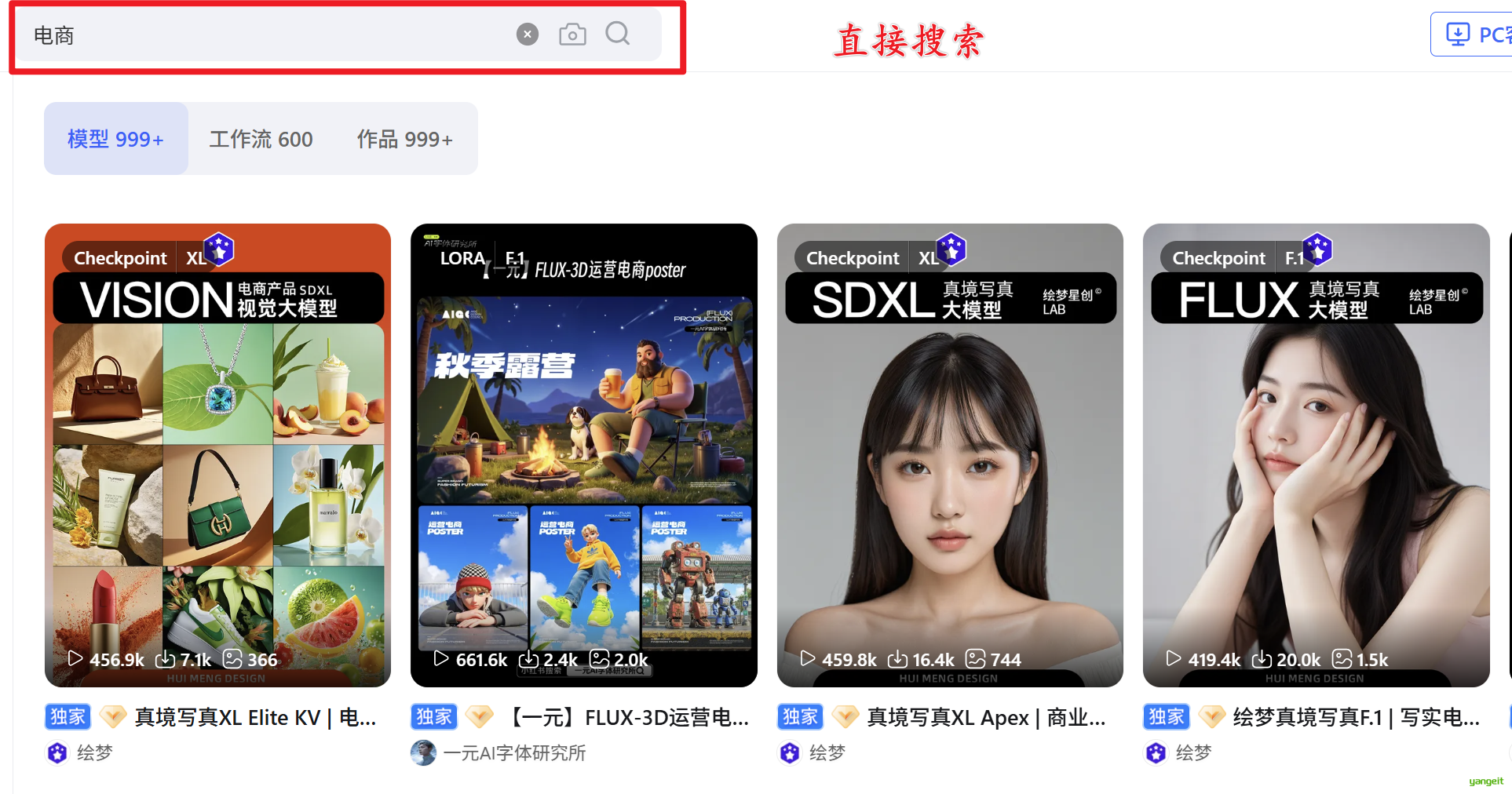
有钻石标记的需要专业版才能用,可以放到
上述的方法,都是通过一些指标,来筛选出优质的Checkpoint,但是这些指标,并不是绝对的,所以我们需要根据我们的需求,来选择合适的Checkpoint。然后我们可以收藏此模型,后续再用
注意
1. 专模专用。
如写实风格的大模型,无法通过提示词,来达到二次元的效果,所以我们需要选择对应风格化的模型,来达到风格化的效果。

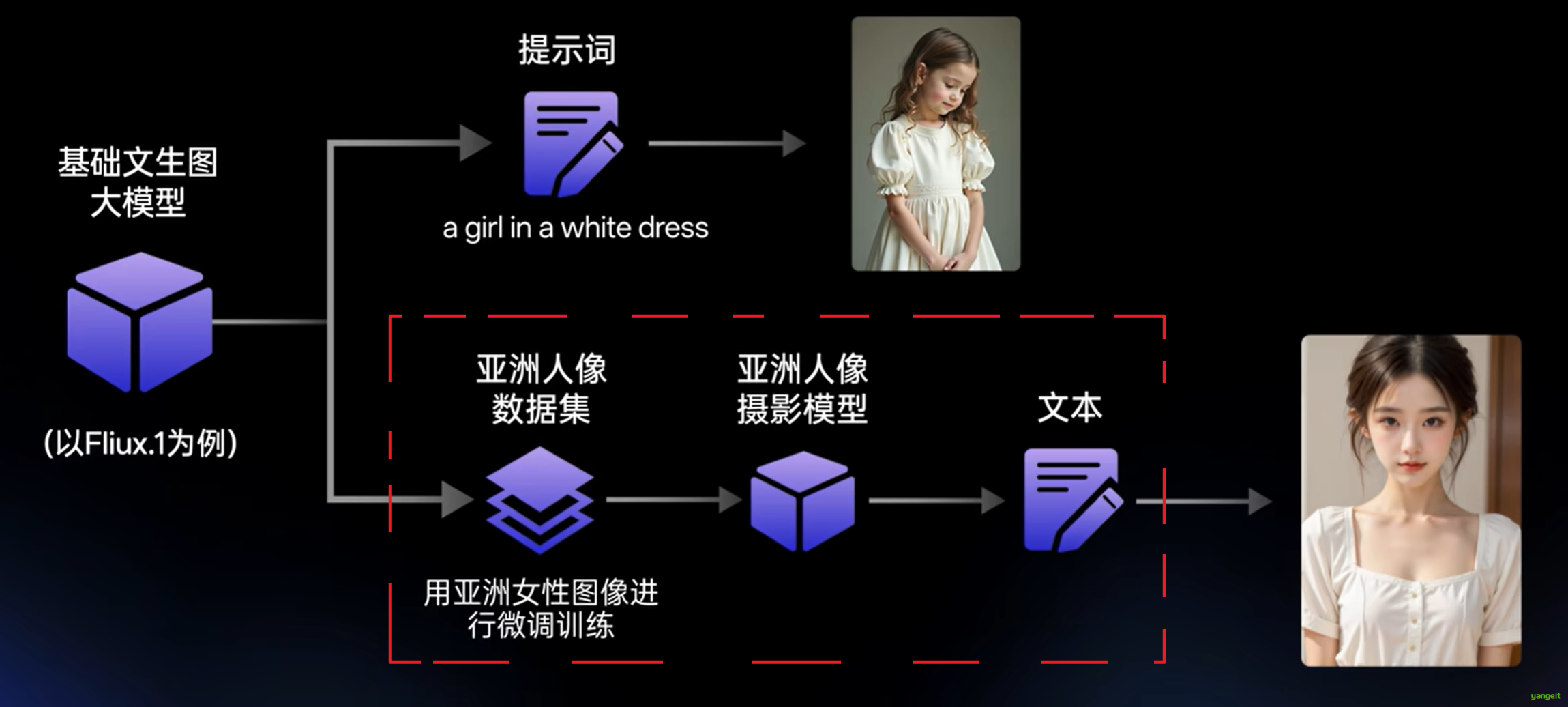
一个年轻的亚洲女人站在宁静的蓝色海洋背景下。她肤色白皙,深棕色的长发扎了一条宽松的侧辫子,几根松散的发辫勾勒出她的脸。
她的头发上装饰着一条大的米色发带,上面有花卉图案。
使用写实大模型,无法通过提示词,来达到二次元的效果
动画风格的小男孩的数字3D渲染,他有一头凌乱的粉色短发和一双充满表情的大眼睛。他穿着一件带黄色补丁的蓝色连帽衫。
背景是纯米色。男孩的表情中性,略显严肃,两只耳朵上都戴着银色的小耳环。这个设计充满活力和时尚。原因是:不同风格的模型 所需的 训练数据集 不一样。👇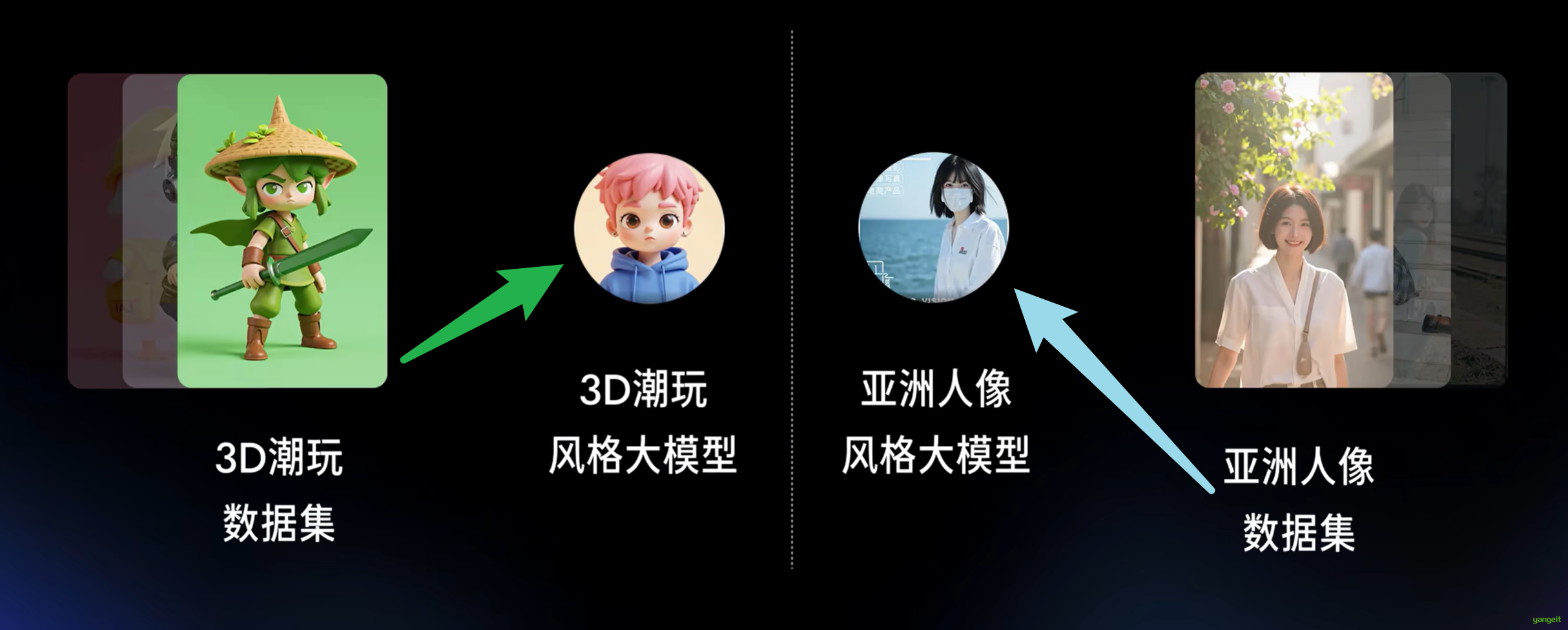
2. 专模专词。
比如我们使用二次元风格的大模型,那么我们就可以使用二次元风格的提示词,来达到二次元的效果。

提示词:
一位粉红色头发、戴着黑色VR耳机的女性正在弹一把粉红色的电吉他。她穿着一件黄色的t恤。
背景是一个带有复古风格的紫色瓷砖房间,包括一个"Sale!"的标志和一个发光的"618"销售图形。
周围是一台显示销售情况的笔记本电脑,一个"音乐"盒子和紫色扬声器。3. 风格大模型是基于通用大模型训练的,通用大模型目前分为基础算法1.5,基础算法XL,基础算法F.1.(越晚推出的模型,生图效果越好)
推出时间:F.1 晚于 XL 晚于 1.5
可以发现越新的模型,生图质量明显越好
练习提示词:
一位粉红色头发、戴着黑色VR耳机的女性正在弹一把粉红色的电吉他。她穿着一件黄色的t恤。
背景是一个带有复古风格的紫色瓷砖房间,包括一个"Sale!"的标志和一个发光的"618"销售图形。
周围是一台显示销售情况的笔记本电脑,一个"音乐"盒子和紫色扬声器。
总结
回答一下问题,看看你掌握了多少?
- 同样的数据集生成的Checkpoint,会一模一样吗?
- 如何选择诸多优质的Checkpoint?🍐
- 为什么二次元风格的大模型不能生成写实风格的图像?
- 选择Checkpoint的注意事项有哪些?🍐
- 使用同样的提示词,选择不同的基础大模型,测试一下他们的出图差异!✏️
参考提示词:课堂上,考虑生图费时间,练习1组就行
1. 森林精灵与晨光
提示词:
(大师级作品:1.2), 最佳画质, 高分辨率, 1位少女, 银发空灵精灵, 散发微光的翠绿眼眸, 叶片纹饰长裙, 伫立于阳光穿透的森林,
树冠洒落金色光束, 漂浮闪烁的尘埃粒子, 青苔覆盖的鲜艳岩石, 清澈溪流, 柔美虚化光斑, 幻想插画风格融合阿尔丰斯·慕夏与格雷格·鲁特科夫斯基
预期画面感:晨光穿透树冠洒在银发精灵身上,服饰上的叶片纹理与苔藓岩石交相辉映,空气中漂浮着光尘,溪流反射出粼粼波光,整体呈现新艺术运动风格的细腻插画感。
2. 未来赛博朋克都市
提示词:
赛博朋克都市景观, 霓虹灯下的雨夜, (未来主义摩天楼:1.3)与全息广告交织, 飞行汽车划过光轨,
黑色皮革风衣的亚裔女性, 散发冷光的机械义肢, 湿润路面的镜面倒影, 电影级光影, 超高精度8K细节,
ArtStation热门趋势风格, 致敬赛德·米德
预期画面感:霓虹灯与全息广告交织的雨夜,飞行汽车的光轨划过摩天大楼,女主角的机械臂发出冷光,雨水在街道上形成镜面倒影,画面充满《银翼杀手》式赛博朋克美学。
3. 水墨古风山水
提示词:
中国水墨画风格, 雾霭笼罩的山谷, 白袍文人伫立木桥, 水墨渲染的松林, 远处飞瀑,
云雾间穿行的鹤群, (浅金色点缀:1.1), 传统绢帛纹理质感, 留白与不对称平衡构图
预期画面感:淡墨渲染的云雾山涧,白衣文士立于木桥凝望飞瀑,鹤群穿云而过,画面留白处隐含绢帛纹理,金色点缀提升古典质感,呈现宋代山水画的空灵意境。
4. 奇幻魔法图书馆
提示词:
(悬浮古籍:1.4)环绕的宏伟哥特图书馆, 彩色玻璃窗投射斑斓光影, 长须老巫师研读古卷,
旋转发光的符文环, 蜡烛吊灯, 堆积的陈旧羊皮纸, 魔法光晕, 超精细3D渲染, 虚幻引擎5效果, 体积光雾
预期画面感:悬浮古籍环绕的哥特式图书馆,彩窗投下斑斓光影,老巫师的长袍与符文光效形成动态对比,蜡烛吊灯与羊皮纸堆营造神秘氛围,细节堪比虚幻引擎渲染。
5. 蒸汽朋克机械巨兽
提示词:
蒸汽朋克机械巨龙, 黄铜齿轮与铜制管道, 胸口发光的蓝色能量核心, 工业废墟中咆哮,
排气管迸发烟雾与火星, (精密铆钉细节:1.2), 仰视镜头构图, 戏剧性轮廓光, 雅库布·罗扎尔斯基概念艺术风格
预期画面感:黄铜齿轮与蒸汽管道构成的机械巨龙在废墟中咆哮,胸口蓝色能量核心与喷射的火星形成冷暖对比,仰视视角突显压迫感,细节致敬工业革命美学。
建议 :使用基础算法_F.1.safetensors模型,将上述的提示词填入试试效果
8. Checkpoint大模型调用技巧
Checkpoint大模型调用技巧
在liblib或者本机上使用模型,有以下技巧:
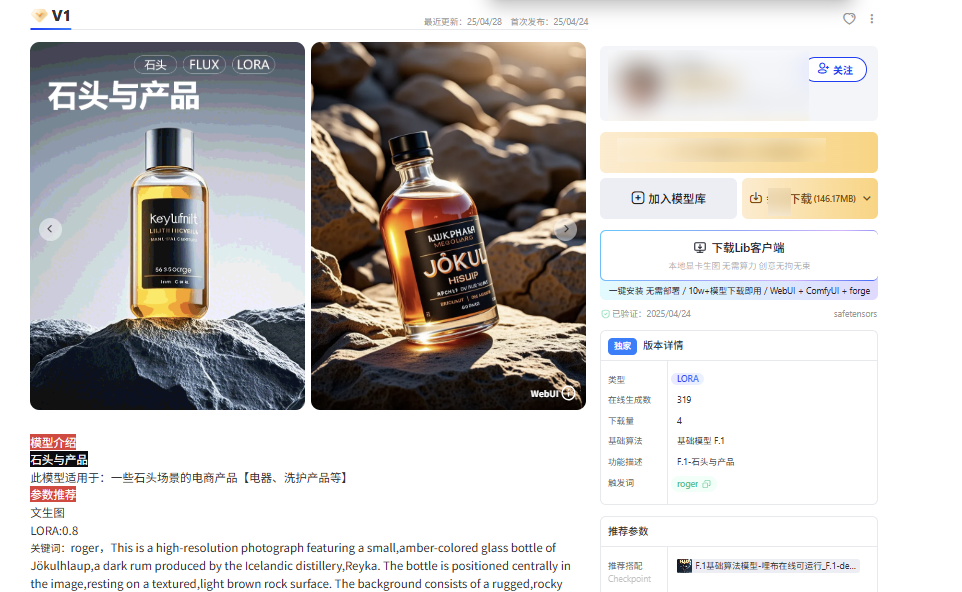
- 查看模型主页信息
- 模型系列:了解模型所属的系列(如写实、动漫等)。
- 推荐参数:包括采样算法、分辨率、提示词模板等。
- 商业许可:确认是否允许商用。
- 作者简介:重点关注:
- 模型特征提示词(如“magic realistic”适合写实风格)。
- 推荐生成参数(如采样器、CFG值)。
- 关联资源(如配套的LoRA或VAE)。
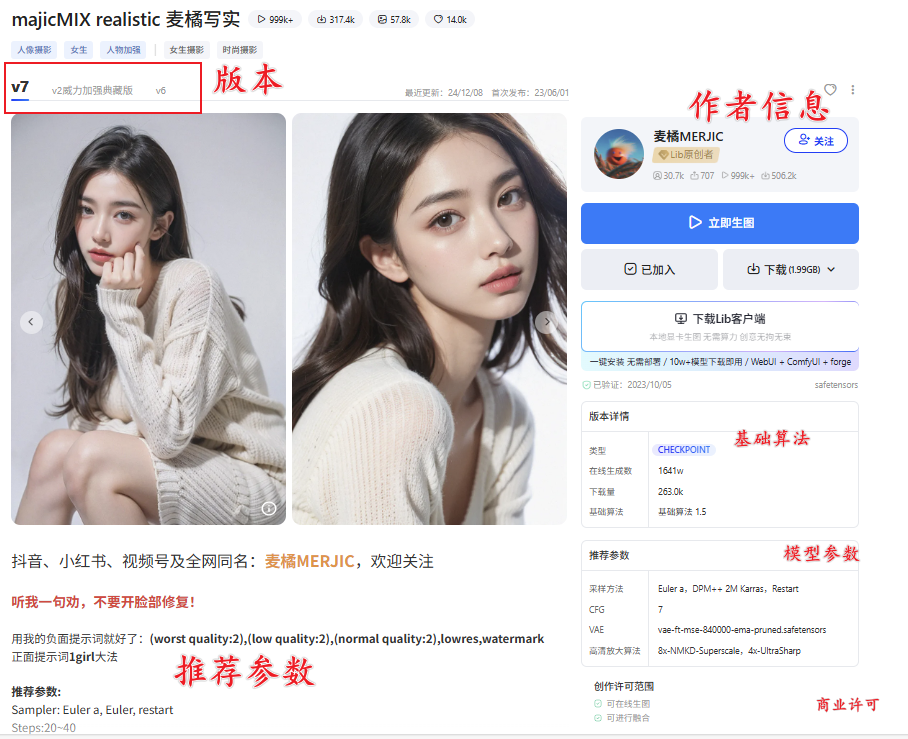
- 同一模型可能有多个版本,作者会通过以下方式优化:
1. 调整训练数据集。
1. 更新基础模型(如基于SDXL重新训练)。 - 建议:优先使用最新版本(通常质量更好),但若旧版效果更符合需求也可保留。
- 添加模型到Web UI
- 在模型主页点击“加入模型库”,模型会自动保存到生图页面的模型库中,方便调用。
- 手动刷新:若未显示,点击Web UI中的刷新按钮(↻图标)。
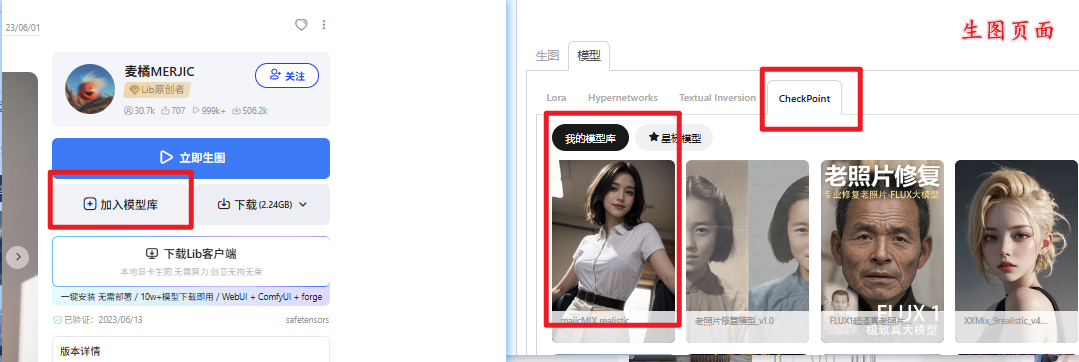
- 模型管理技巧
- 快速筛选:
- 在Checkpoint列表点击⭐标收藏常用模型,通过“星标模型”分类快速查找。
- 使用搜索框输入关键词(如“realistic”)。
- 删除模型:点击❌图标移除不常用的模型,节省空间。
- 快速筛选:
- 预览与加载
- 在模型区的Checkpoint分区可查看缩略图,点击直接加载。
- 点击❓图标跳转回模型主页查看详情。
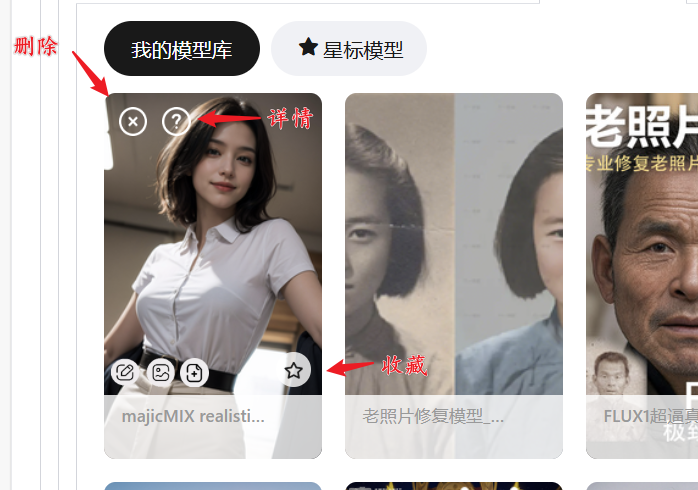
- 利用示例图
- 作者例图:判断模型适合的场景(如人物、风景)。
- 右下角带“Web UI”图标的示例图支持一键生成同款(含参数复制)。
- 用户返图:查看其他用户的生成效果,可能包含:
- 大模型直出效果。
- 大模型+LoRA的混合效果。
- 作者例图:判断模型适合的场景(如人物、风景)。

- 收藏与复用
- 对优质示例图点击❤️收藏,后续可在“个人中心-点赞图片”中查看,复用其参数。
- 多版本测试
- 如果生成效果不理想,尝试切换同模型的旧版本(如v1.2 vs v2.0)。
总结
课堂作业
- 根据上面的提示,熟悉一下Lib界面把!!🎤
9. 提示词
9.1 正向提示词
正向提示词
本章节我们来讲解正向提示词的实战案例,通过实战案例,来学习如何使用正向提示词,来达到我们想要的效果。
正向提示词:描述的是想要的内容 ,而负向提示词描述的是不想出现的内容 (或者说提升出图的质量)。
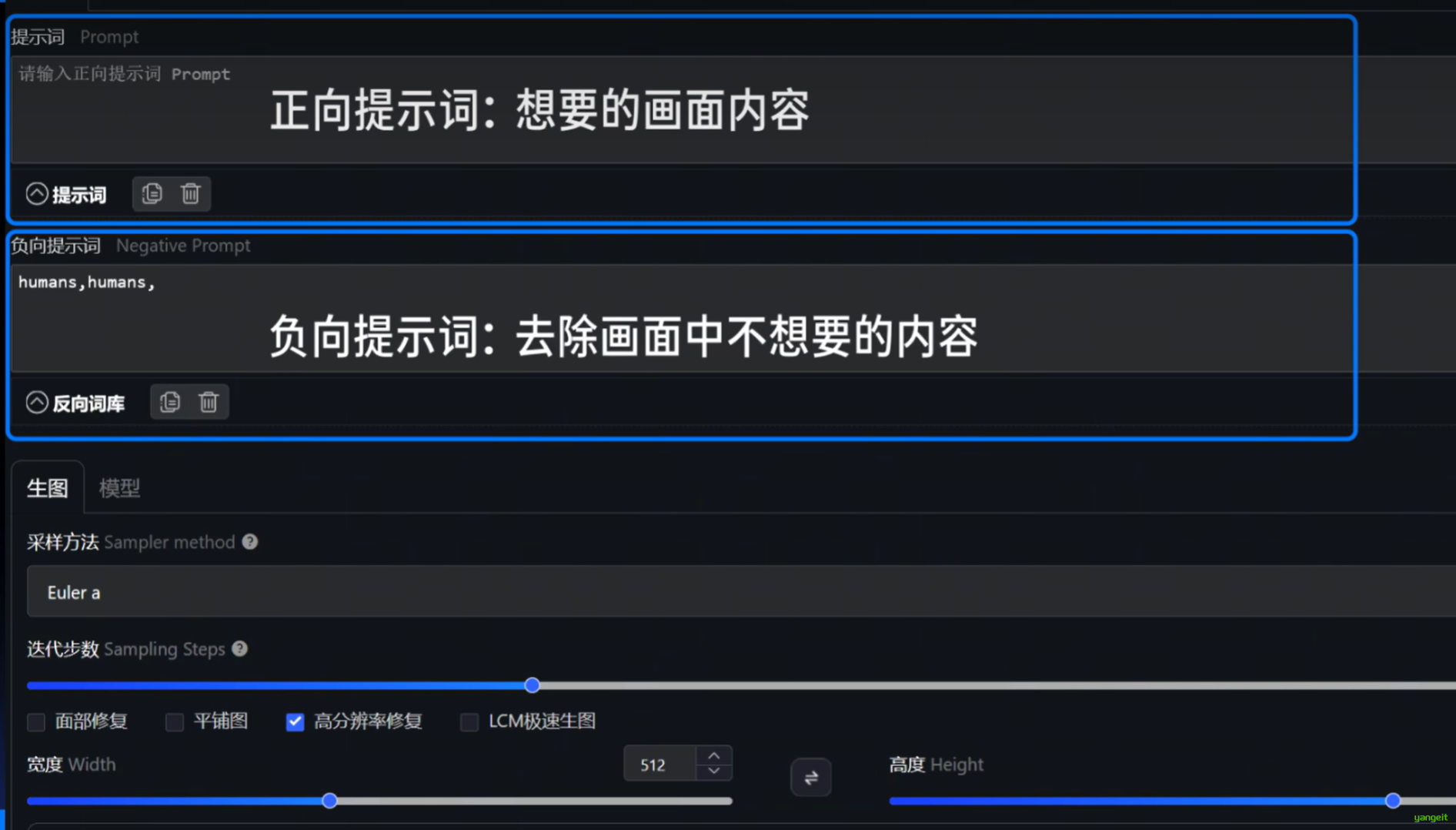
注意:
- webui中,正向提示词和负向提示词,是分开的,所以需要分开写,不能写在一起。且都是英文(除非自动翻译)
- 提示词其实就是约束,AI其实自由度很高,主要看你脑洞有多大,就可以出多大的效果
提示
下面通过案例,来说明正向提示词的使用技巧,以及权重分配技巧。
提示词:
一个穿花白裙子的女孩,被花朵和蝴蝶围绕注意:基础算法V1.5和Xl系列的模型,非常依赖负向提示词来改善画面质量(观察下下图),
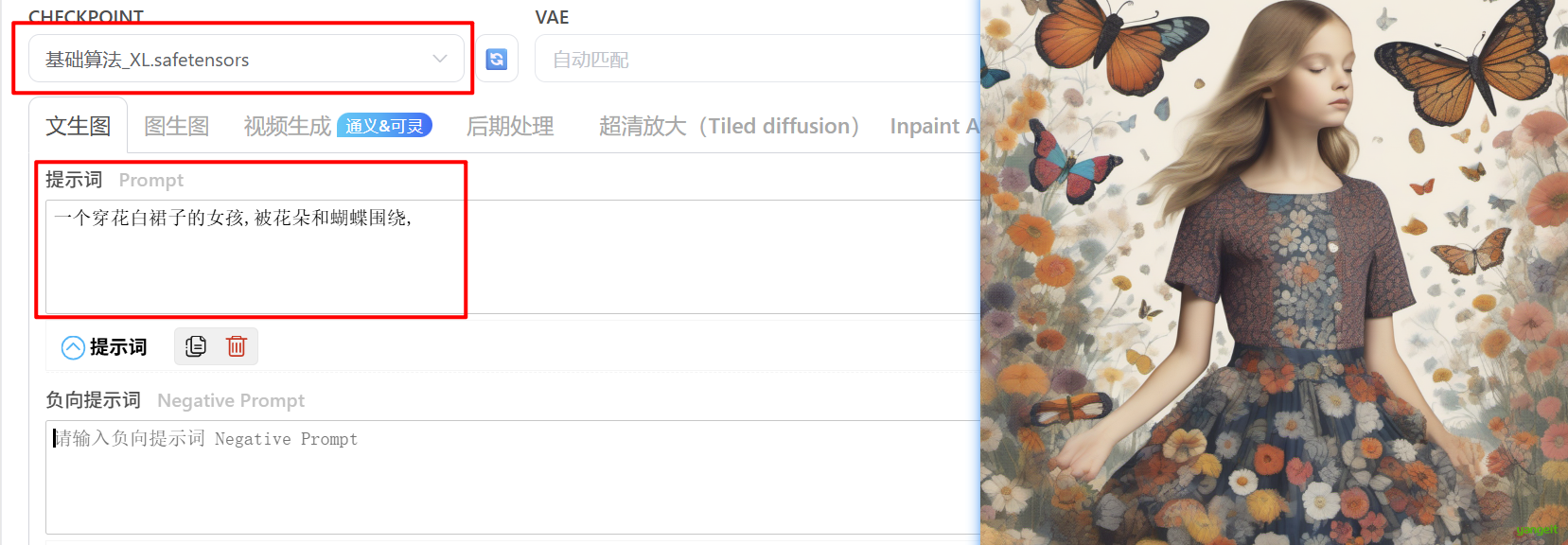
原始的sd的webui只能用英文单词, liblib可以用中文,会自动翻译为英文。 如果不知道英文的意思,可以使用腾讯翻译插件,这样就很方便了,点击安装翻译插件
如果使用F.1基础大模型,则不需要负向提示词,就可以达到很好的效果,如下图所示:
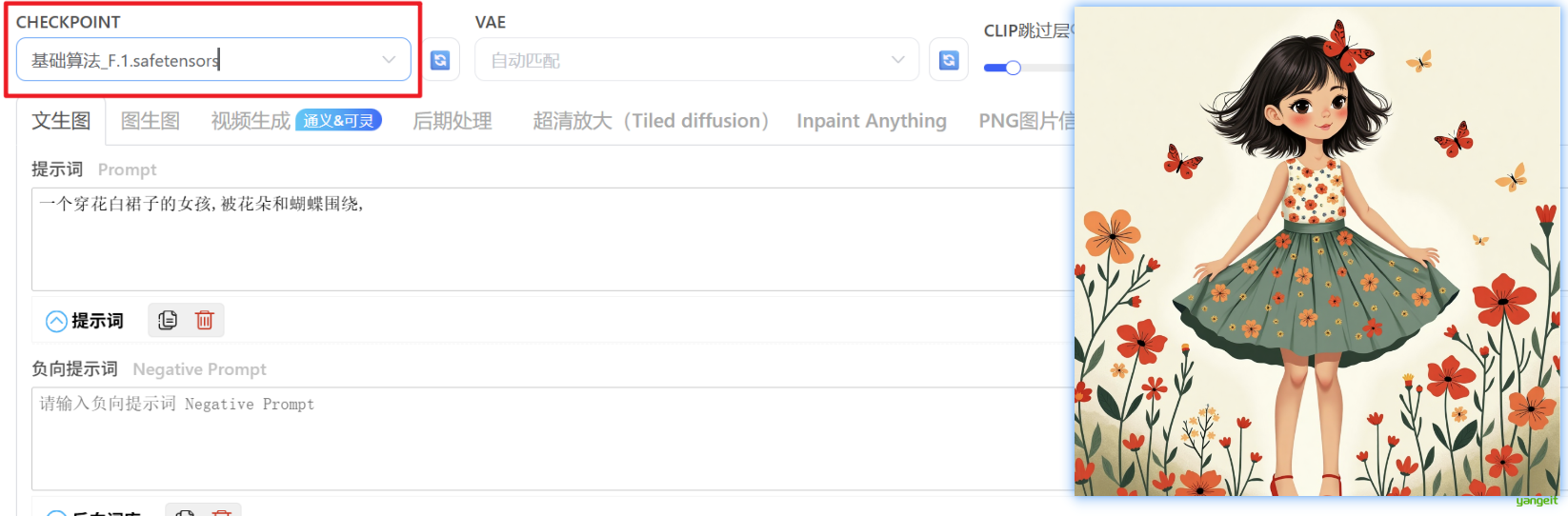
越晚推出的模型,生图效果越好
提示词权重指的是,提示词的权重越高,生成的图像就越符合提示词的描述。
权重的提升符号有2种👇

正向提示词中含有绿色 的头发,但是生成的图片中没有绿色的头发,因此可以增加绿色的权重

图片中可以看到头发没有绿色 的,可以增加头发的权重,来增加头发的绿色,如下图所示:

2个括号相当于1.1*1.1 =1.21比重
提示词:👇
girl,sea,white hair,green hair,white_shirt,要注意的是 :提示词如果太重了,会把其他的提示词压的很低,效果就很差了(如下图,权重4.1 显示的全部都是绿色头发了 ),所以需要根据实际情况来调整权重。

总结
回答一下问题,看看你掌握了多少?
- 正向提示词的作用是什么?🍐
- 使用基础算法V1.5和Xl系列的模型,F.1基础大模型,那个模型出图效果最好🍐
- 正向提示词的权重有什么作用?🍐
- 如果提示词设置太重,会导致什么效果
- 有没有发现,这个出图的质量和效果,不是自己想要的, 点击这张图看看
9.2 负向提示词
负向提示词
负向提示词:描述的是不想出现的内容,如模糊的,低分辨率的,丑陋的,肢体扭曲的等等不想出现的情况
基础算法V1.5和Xl系列的模型,非常依赖负向提示词来改善画面质量,这些提示词主要涉及画面提升,任务细节优化,无用元素排除,特别对于V1.5模型来说,负向提示词是必不可少的。查看图1 和图2


那负向提示词应该怎样写?

如果在上图2的基础上,增加负向提示词,效果如下:


发现面部发送了改善
其实:负面提示词其实越全越好,这样会避免出现不好的效果,但是每次都要写,太麻烦了,因此可以使用模板或者一键导入提示词。
我们可以使用Embeddings(就像给提示词(比如“模糊”或“畸形”)打包成一个压缩文件,让 AI 更快更准地理解你想避开的内容,省得手动写一堆负面词。)
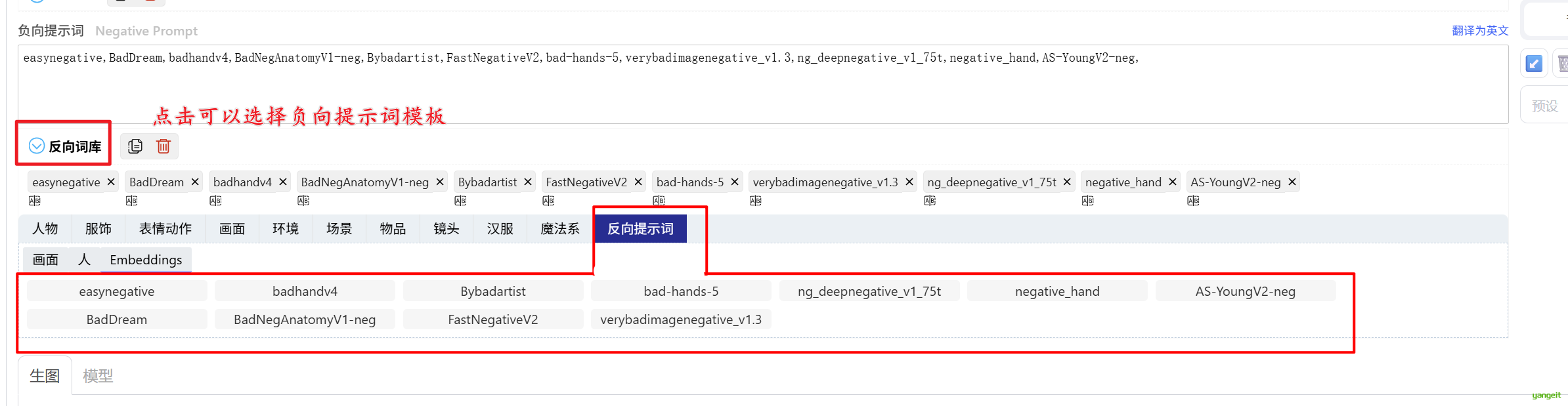
easynegative:基础通用过滤,处理模糊、低质等常见问题
BadDream:阻止诡异崩坏,防止扭曲五官和异常肢体生成
badhandv4:专项修正多指/关节错位等手部问题
BadNegAnatomyV1-neg:矫正全身肢体比例和骨骼异常
Bybadartist:提升艺术性,过滤低水平绘画效果
FastNegativeV2:快速消除塑料感和低多边形建模感
bad-hands-5:强化手部细节(指甲/掌纹等微结构)
verybadimagenegative_v1.3:综合提升材质/透视/噪点控制
ng_deepnegative_v1_75t:语义级过滤,阻止暴力/情色/政治敏感内容
negative_hand:优化手部与物体的交互逻辑(握持/穿透)
AS-YoungV2-neg:抑制幼态特征,过滤未成年人形象需要说明的是:Flux系列的大模型本身底子好,即使不用提示词,出图效果依然非常nice
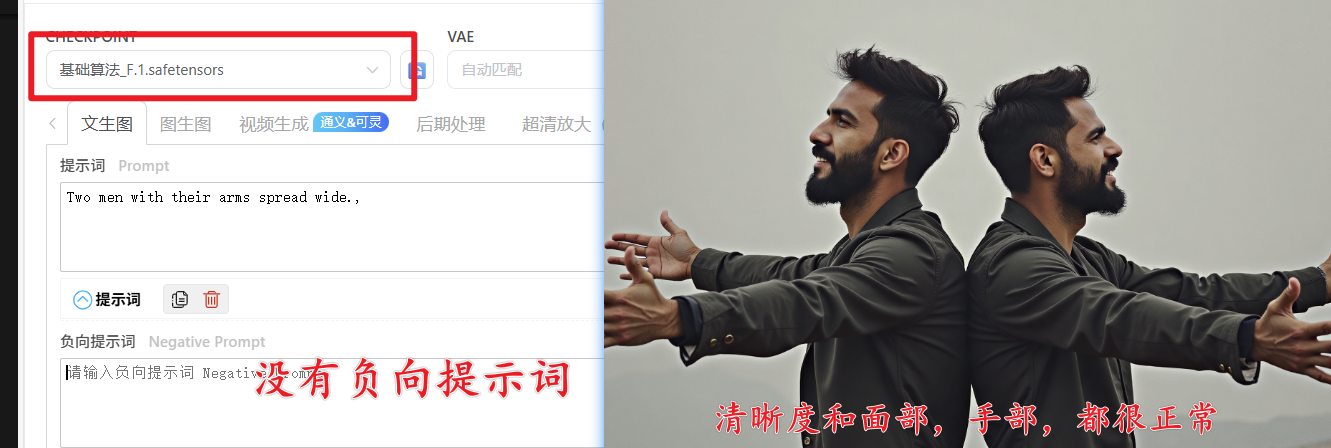
总结
回答一下问题,看看你掌握了多少?
- 负向提示词的作用是什么?🍐
- 负向提示词这么多不好记,有没有便捷的方式,能够整合某类型的负向提示词,比方说整合手部的提示词?🍐
- 生成好的效果,一定要填写负向提示词吗?🍐
10.风景类案例
风景类
风景类的摄影作品:以自然风光、城市景观、建筑等为主题,旨在展现自然之美、人文之美、建筑之美等。这类作品通常具有宽广的视野、丰富的细节、独特的构图和精美的色彩表现。

代码操作
模型:基础算法_F.1.safetensors
Vae:自动匹配
CLIP跳过层:2 (默认值)
提示词:
Nikon AF-S NIKKOR 14-24mm f/2.8G ED,
summer beach,rich in detail,
ultra low angle,
sunrise natural light,
Ultra HD,
high saturation,
bright and clean colors,8k,
反向提示词:
dark and muted colors, muddy colors, clashing colors, low resolution, blurry, pixelated, litter, ugly billboards, pollution, cartoon style, abstract style, gloomy style
种子:-1
采样方法:Euler 、DPM++ 2M Karras
引导系数:7
迭代步数:30
开启高清修复:
放大算法:8x-NMKD-Superscale
重绘采样步数:30 和迭代步数一致
重绘幅度:0.3
低重绘幅度意味着修正原图,越高的重绘幅度对放大后的图像改变越大。0 不会改变原图,0.3 以下会基于原图稍微修正,超过 0.7 会对原图做出较大改变,1 会得到一个完全不同的图像。提示词解释:
Nikon AF - S NIKKOR 14 - 24mm f/2.8G ED:尼康的这款超广角大光圈镜头,能以快速安静的对焦捕捉广阔场景,大光圈保障进光量,还能减少色差,让画面清晰且色彩还原度高,呈现出夏天海滩的宏大场面。
summer beach:明确画面场景是夏天的海滩,会展现出夏日海滩阳光明媚、沙滩金黄、海水湛蓝、椰林摇曳的典型特征,充满度假休闲氛围。
rich in detail:丰富的细节能展现出海浪的泡沫、椰树叶的脉络、远处船只的轮廓等,让海滩风景更加真实生动,经得起细看。
ultra low angle:超低角度拍摄,会夸张放大前景的沙滩、贝壳等元素,同时使海平面、天空在画面中形成独特的构图比例,增强画面的立体感和视觉冲击力。
sunrise natural light:日出时的自然光,为海滩披上温暖的橙红色调,柔和的光线能细腻地勾勒出沙滩的纹理、海浪的起伏,营造出浪漫而宁静的氛围。
Ultra HD:超高清画质让海滩上每一粒沙子、每一朵浪花的细节都能清晰呈现,带来身临其境般的视觉体验。
high saturation:高饱和度使沙滩的金色、海水的蓝色、天空的青色更加鲜艳夺目,让整个画面充满活力,吸引观众的目光。
bright and clean colors:画面色彩明亮纯净,没有杂质和暗沉,给人清新、舒适的视觉感受,凸显夏天海滩的明媚与清爽。
8k:8K 高分辨率确保图像拥有极高的清晰度和细腻度,即使放大观看,画面依然清晰锐利,完美呈现夏天海滩的美景。
反向提示词:
dark and muted colors, muddy colors, clashing colors, low resolution, blurry, pixelated, litter, ugly billboards, pollution, cartoon style, abstract style, gloomy style
反向提示词解释 👇
- 色彩方面:避免色彩过于暗淡或混乱,可使用 “dark and muted colors(暗淡且柔和的颜色)”“muddy colors(浑浊的颜色)”“clashing colors(冲突的颜色)”。
- 画质方面:排除低画质和模糊的效果,如 “low resolution(低分辨率)”“blurry(模糊的)”“pixelated(像素化的)”。
- 元素方面:去掉不相关或破坏美感的元素,例如 “litter(垃圾)”“ugly billboards(丑陋的广告牌)”“pollution(污染)” 。
- 风格方面:不想出现特定风格时,可写 “cartoon style(卡通风格)”“abstract style(抽象风格)”“gloomy style(阴暗风格)”

模型:基础算法_F.1.safetensors
Vae:自动匹配
CLIP跳过层:2 (默认值)
提示词:
Nikon AF-S NIKKOR 14-24mm f/2.8G ED,
潮湿的深山老林,山崖上生长着一株带着露水的粉红玫瑰,根部有一点青苔,还有几片绿色的叶子,特写,
ultra low angle,
sunrise natural light,
Ultra HD,
high saturation,
bright and clean colors,8k,
反向提示词:
dark and muted colors, muddy colors, clashing colors, low resolution, blurry, pixelated, litter, ugly billboards, pollution, cartoon style, abstract style, gloomy style
种子:-1
采样方法:Euler 、DPM++ 2M Karras
引导系数:7
迭代步数:30
开启高清修复:
放大算法:8x-NMKD-Superscale
重绘采样步数:30 和迭代步数一致
重绘幅度:0.3效果图:
