大约 9 分钟
1.词频统计案例
前言
定义
在仪表盘的下面完成词频统计
2.完成舆情系统的词频后端接口编码和测试
前言
定义
点击阿里云自然语言处理平台 开通基础班服务,关注情感分析-通用的API接口
点击进行API测试 👇
在情感基础上,完成以下修改:👇
更换 API 服务:当前用的是 GetSaChGeneral(情感分析),命名实体识别电商版要用对应的 NER 接口,比如 GetNerChEcom。
修改 Request 类:使用 GetNerChEcomRequest。
**调整 service_code:**对应 NER 服务的 service code(一般是 "alinlp"或具体如 "ner_ecom",需参考官方文档确认)。
解析返回结构:NER 返回的是实体列表,不是 sentiment。
可选设置行业/领域参数(电商基础版通常默认支持商品名、品牌、品类等实体类型)。
步骤:
- 获得AccessKey和AccessKeySecret
观看教学视频,或者直接官网教程
- 安装aliyun-python-sdk-alinlp
# pip安装命令
pip install alibabacloud_alinlp20200629安装好了,后重启jupyter
- 编写代码
import json
from alibabacloud_alinlp20200629.client import Client as AlinlpClient
from alibabacloud_alinlp20200629.models import GetNerChEcomRequest # 👈 换成 NER 电商请求类
from alibabacloud_tea_openapi.models import Config
# === 配置认证信息 ===
access_key_id = "your_access_key_id" # 替换为你的 AccessKey ID
access_key_secret = "your_access_key_secret" # 替换为你的 AccessKey Secret
ess_key_secret = "0HZxqzZ2POTJkUMJHLsxSlH7wP4IxZ" # 替换为你的 AccessKey Secret
config = Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
region_id='cn-hangzhou',
endpoint='alinlp.cn-hangzhou.aliyuncs.com'
)
client = AlinlpClient(config)
# === 构建请求 ===
request = GetNerChEcomRequest() # 👈 创建 NER 电商请求对象
request.text = "苹果iPhone15手机壳硅胶防摔保护套适用于苹果14ProMax" # 测试文本
request.service_code = "alinlp" # 有的版本要求填 "ner_ecom",根据文档确认
# === 发起调用 ===
try:
response = client.get_ner_ch_ecom(request) # 👈 调用命名实体识别电商版方法
# ✅ 获取原始 body
raw_body = response.body
# ✅ 判断类型并处理
if isinstance(raw_body, str):
result = json.loads(raw_body)
elif hasattr(raw_body, 'data'):
data = raw_body.data
if isinstance(data, str):
result = json.loads(data)
else:
result = data
else:
result = raw_body
# ✅ 打印完整结果
print(json.dumps(result, ensure_ascii=False, indent=2))
# ✅ 提取命名实体
# 常见返回结构:{"result": [{"type": "品牌", "word": "苹果"}, {"type": "产品", "word": "iPhone15"}]}
entities = result.get("result", [])
if entities:
print("\n识别出的实体:")
for ent in entities:
print(f"实体: {ent.get('word')}, 类型: {ent.get('type')}")
else:
print("\n未识别出实体")
except Exception as e:
print("调用失败:", str(e))- 运行代码
{
"result": [
{
"synonym": "",
"weight": "0.800000",
"tag": "品牌",
"word": "苹果"
},
{
"synonym": "",
"weight": "0.100000",
"tag": "普通词",
"word": "iPhone15"
},
{
"synonym": "手机套",
"weight": "1.000000",
"tag": "品类",
"word": "手机壳"
},
{
"synonym": "",
"weight": "0.600000",
"tag": "材质",
"word": "硅胶"
},
{
"synonym": "",
"weight": "0.600000",
"tag": "功能功效",
"word": "防摔"
},
{
"synonym": "保护壳",
"weight": "1.000000",
"tag": "品类",
"word": "保护套"
},
{
"synonym": "",
"weight": "0.100000",
"tag": "普通词",
"word": "适用于"
},
{
"synonym": "",
"weight": "0.800000",
"tag": "品牌",
"word": "苹果"
},
{
"synonym": "",
"weight": "0.400000",
"tag": "型号",
"word": "14Pro"
},
{
"synonym": "",
"weight": "0.100000",
"tag": "普通词",
"word": "Max"
}
],
"success": true
}
识别出的实体:
实体: 苹果, 类型: None
实体: iPhone15, 类型: None
实体: 手机壳, 类型: None
实体: 硅胶, 类型: None
实体: 防摔, 类型: None
实体: 保护套, 类型: None
实体: 适用于, 类型: None
实体: 苹果, 类型: None
实体: 14Pro, 类型: None
实体: Max, 类型: None3.完成舆情系统的词频接口改造二
前言
定义
import json
from collections import defaultdict
from alibabacloud_alinlp20200629.client import Client as AlinlpClient
from alibabacloud_alinlp20200629.models import GetNerChEcomRequest
from alibabacloud_tea_openapi.models import Config
class NERFrequencyAnalyzer:
def __init__(self, access_key_id, access_key_secret):
"""
初始化阿里云NER客户端
:param access_key_id: 阿里云AccessKey ID
:param access_key_secret: 阿里云AccessKey Secret
"""
config = Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
region_id='cn-hangzhou',
endpoint='alinlp.cn-hangzhou.aliyuncs.com'
)
self.client = AlinlpClient(config)
# 按tag分类的词频统计
self.tag_entity_counter = defaultdict(lambda: defaultdict(int))
# 总体词频统计
self.total_entity_counter = defaultdict(int)
def analyze_text(self, text):
"""
调用阿里云NER电商接口分析文本
:param text: 待分析文本
"""
request = GetNerChEcomRequest()
request.text = text
request.service_code = "alinlp"
try:
response = self.client.get_ner_ch_ecom(request)
raw_body = response.body
# 处理不同格式的返回结果
if isinstance(raw_body, str):
result = json.loads(raw_body)
elif hasattr(raw_body, 'data'):
data = raw_body.data
result = json.loads(data) if isinstance(data, str) else data
else:
result = raw_body
# 统计实体词频(按tag分类)
entities = result.get("result", [])
for ent in entities:
word = ent["word"]
tag = ent["tag"]
weight = float(ent["weight"])
# 只统计有意义的标签(排除"普通词"等低价值标签)
meaningful_tags = ["品牌", "品类", "材质", "功能功效", "型号", "产品", "风格"]
# 按tag分类统计
if tag in meaningful_tags:
self.tag_entity_counter[tag][word] += 1
# 总体词频统计(包含所有有效实体)
if tag != "普通词": # 排除普通词
self.total_entity_counter[word] += 1
except Exception as e:
print(f"NER分析失败: {str(e)}")
def get_tag_frequency(self):
"""
获取按tag分类的词频统计结果
:return: 按tag分类的词频字典 {tag: [(word, count), ...]}
"""
result = {}
for tag, counter in self.tag_entity_counter.items():
result[tag] = sorted(counter.items(), key=lambda x: x[1], reverse=True)
return result
def get_total_frequency(self):
"""
获取总体词频统计结果
:return: 按频次降序排序的实体列表[(word, count), ...]
"""
return sorted(self.total_entity_counter.items(), key=lambda x: x[1], reverse=True)
def get_all_tags_frequency(self):
"""
获取所有标签的词频汇总(用于前端词云)
:return: 按频次降序排序的所有实体列表[(word, count), ...]
"""
return self.get_total_frequency()
# 测试用例 - 模拟您提供的返回结果
def mock_ner_response():
"""模拟您提供的阿里云NER返回结果"""
return {
"result": [
{"synonym": "", "weight": "0.800000", "tag": "品牌", "word": "苹果"},
{"synonym": "", "weight": "0.100000", "tag": "普通词", "word": "iPhone15"},
{"synonym": "手机套", "weight": "1.000000", "tag": "品类", "word": "手机壳"},
{"synonym": "", "weight": "0.600000", "tag": "材质", "word": "硅胶"},
{"synonym": "", "weight": "0.600000", "tag": "功能功效", "word": "防摔"},
{"synonym": "保护壳", "weight": "1.000000", "tag": "品类", "word": "保护套"},
{"synonym": "", "weight": "0.100000", "tag": "普通词", "word": "适用于"},
{"synonym": "", "weight": "0.800000", "tag": "品牌", "word": "苹果"},
{"synonym": "", "weight": "0.400000", "tag": "型号", "word": "14Pro"},
{"synonym": "", "weight": "0.100000", "tag": "普通词", "word": "Max"}
],
"success": True
}
# 测试用Mock类(当没有真实API时使用)
class MockNERAnalyzer(NERFrequencyAnalyzer):
def analyze_text(self, text):
"""模拟NER分析过程"""
# 这里简化处理,直接使用预定义的测试结果
mock_result = mock_ner_response()
entities = mock_result.get("result", [])
for ent in entities:
word = ent["word"]
tag = ent["tag"]
weight = float(ent["weight"])
meaningful_tags = ["品牌", "品类", "材质", "功能功效", "型号", "产品", "风格"]
if tag in meaningful_tags:
self.tag_entity_counter[tag][word] += 1
if tag != "普通词":
self.total_entity_counter[word] += 1
# 测试用例
if __name__ == "__main__":
# 使用Mock类进行测试(避免真实API调用)
analyzer = MockNERAnalyzer("dummy_id", "dummy_secret")
# 模拟分析一条包含您提供结果的评论
test_comment = "苹果iPhone15手机壳硅胶防摔保护套适用于苹果14ProMax"
analyzer.analyze_text(test_comment)
print("=== 按Tag分类的词频统计 ===")
tag_frequency = analyzer.get_tag_frequency()
for tag, words in tag_frequency.items():
print(f"\n【{tag}】")
for word, count in words:
print(f" {word}: {count}")
print("\n=== 总体词频统计 ===")
total_frequency = analyzer.get_total_frequency()
for word, count in total_frequency:
print(f"{word}: {count}")
print("\n=== JSON格式输出(供前端使用)===")
output_data = {
"by_tag": {tag: [{"word": word, "count": count} for word, count in words]
for tag, words in tag_frequency.items()},
"total": [{"word": word, "count": count} for word, count in total_frequency]
}
print(json.dumps(output_data, ensure_ascii=False, indent=2))输出结果:
=== 按Tag分类的词频统计 ===
【品牌】
苹果: 2
【品类】
手机壳: 1
保护套: 1
【材质】
硅胶: 1
【功能功效】
防摔: 1
【型号】
14Pro: 1
=== 总体词频统计 ===
苹果: 2
手机壳: 1
硅胶: 1
防摔: 1
保护套: 1
14Pro: 1
=== JSON格式输出(供前端使用)===
{
"by_tag": {
"品牌": [
{
"word": "苹果",
"count": 2
}
],
"品类": [
{
"word": "手机壳",
"count": 1
},
{
"word": "保护套",
"count": 1
}
],
"材质": [
{
"word": "硅胶",
"count": 1
}
],
"功能功效": [
{
"word": "防摔",
"count": 1
}
],
"型号": [
{
"word": "14Pro",
"count": 1
}
]
},
"total": [
{
"word": "苹果",
"count": 2
},
{
"word": "手机壳",
"count": 1
},
{
"word": "硅胶",
"count": 1
},
{
"word": "防摔",
"count": 1
},
{
"word": "保护套",
"count": 1
},
{
"word": "14Pro",
"count": 1
}
]
}4.词频前端编码和后端接口调用
前言
定义
提示词如下:
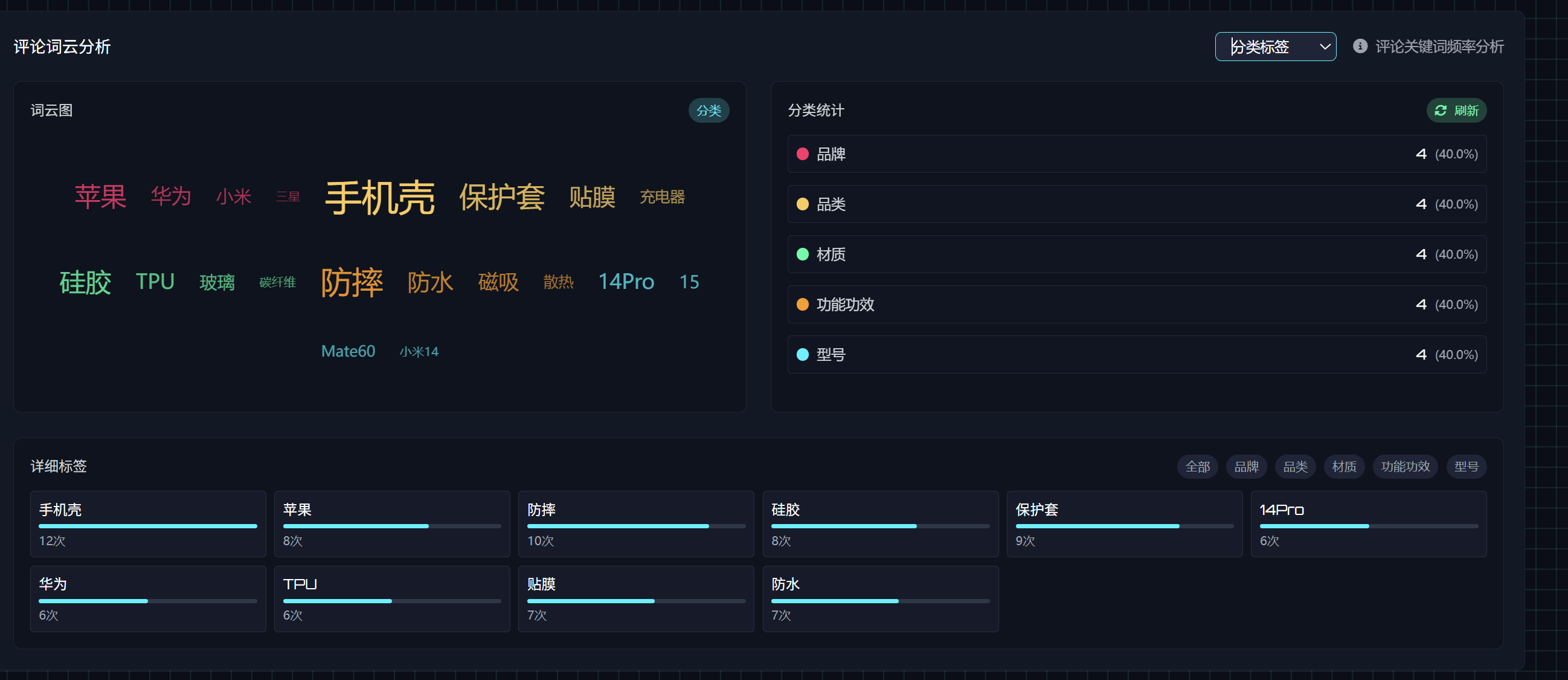
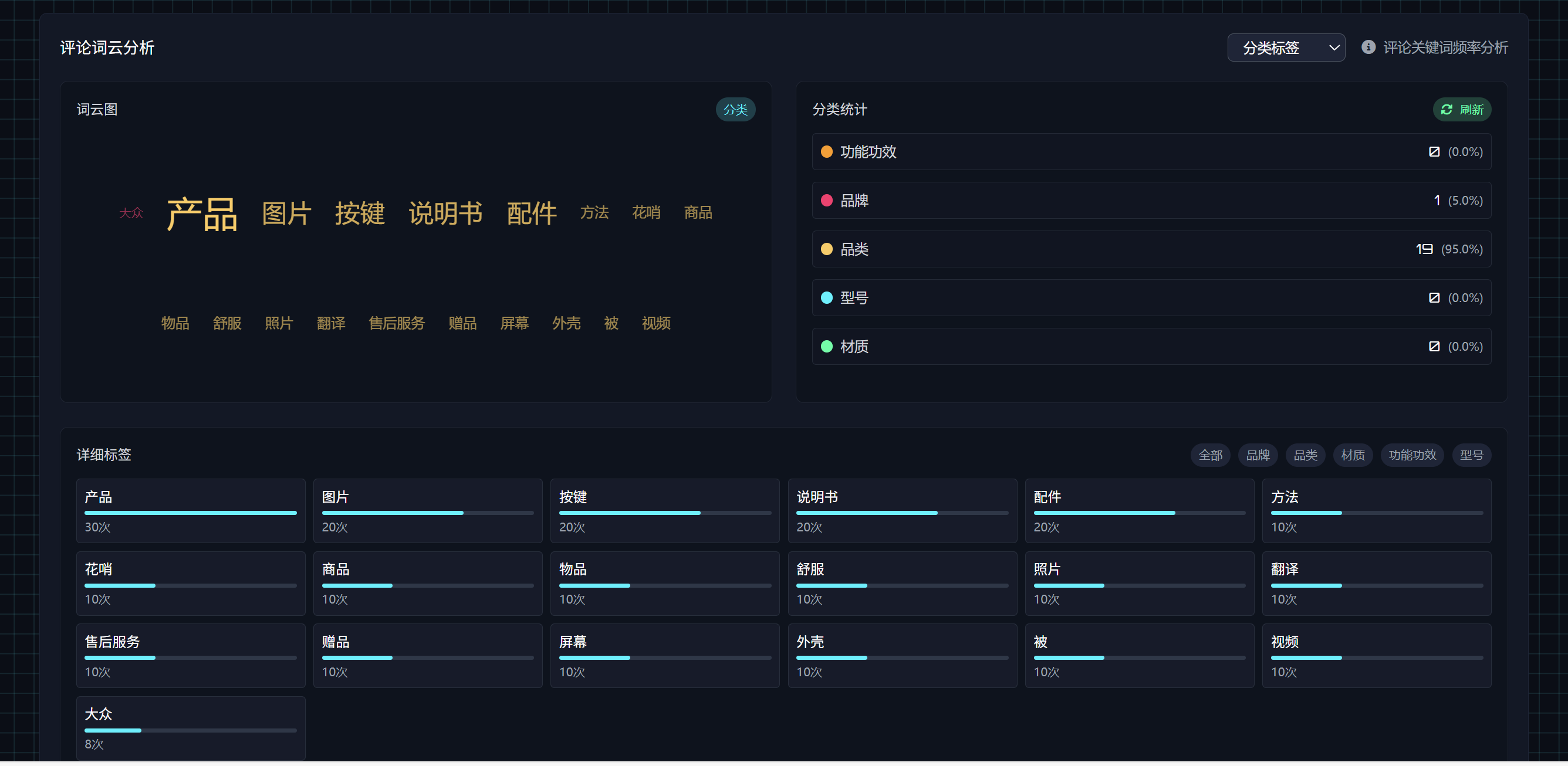
在在平台评论分布的下面,增加一个词云可视化区域,词云的接口返回数据如下:
{
"by_tag": {
"品牌": [
{
"word": "苹果",
"count": 2
}
],
"品类": [
{
"word": "手机壳",
"count": 1
},
{
"word": "保护套",
"count": 1
}
],
"材质": [
{
"word": "硅胶",
"count": 1
}
],
"功能功效": [
{
"word": "防摔",
"count": 1
}
],
"型号": [
{
"word": "14Pro",
"count": 1
}
]
},
"total": [
{
"word": "苹果",
"count": 2
},
{
"word": "手机壳",
"count": 1
},
{
"word": "硅胶",
"count": 1
},
{
"word": "防摔",
"count": 1
},
{
"word": "保护套",
"count": 1
},
{
"word": "14Pro",
"count": 1
}
]
}接下来,同步接口文档:👇
接下来,结合前端代码,完成后端代码编写:👇
后端依赖不需要增加,根据接口文档中的新增的 评论词云图表数据接口(/api/dashboard/wordcloud),完成后端代码编写。
逻辑:
1. 阿里云nlp识别实体的接口,识别评论中的实体后,需要保存到数据库中,然后再根据实体,进行统计,统计的结果需要保存到数据库中,以免下次重复识别。
2. 如果数据库表中的实体字段都存在,就不需要调用nlp接口,直接从数据库中获取实体字段,然后进行统计。
单条评论的 实体识别接口代码如下:
import json
from alibabacloud_alinlp20200629.client import Client as AlinlpClient
from alibabacloud_alinlp20200629.models import GetNerChEcomRequest # 👈 换成 NER 电商请求类
from alibabacloud_tea_openapi.models import Config
# === 配置认证信息 ===
access_key_id = "LTAI5tC7bVZUHrmRD2kRLd3j" # 替换为你的 AccessKey ID
access_key_secret = "0HZxqzZ2POTJkUMJHLsxSlH7wP4IxZ" # 替换为你的 AccessKey Secret
config = Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
region_id='cn-hangzhou',
endpoint='alinlp.cn-hangzhou.aliyuncs.com'
)
client = AlinlpClient(config)
# === 构建请求 ===
request = GetNerChEcomRequest() # 👈 创建 NER 电商请求对象
request.text = "苹果iPhone15手机壳硅胶防摔保护套适用于苹果14ProMax" # 测试文本
request.service_code = "alinlp" # 有的版本要求填 "ner_ecom",根据文档确认
# === 发起调用 ===
try:
response = client.get_ner_ch_ecom(request) # 👈 调用命名实体识别电商版方法
# ✅ 获取原始 body
raw_body = response.body
# ✅ 判断类型并处理
if isinstance(raw_body, str):
result = json.loads(raw_body)
elif hasattr(raw_body, 'data'):
data = raw_body.data
if isinstance(data, str):
result = json.loads(data)
else:
result = data
else:
result = raw_body
# ✅ 打印完整结果
print(json.dumps(result, ensure_ascii=False, indent=2))
# ✅ 提取命名实体
# 常见返回结构:{"result": [{"type": "品牌", "word": "苹果"}, {"type": "产品", "word": "iPhone15"}]}
entities = result.get("result", [])
if entities:
print("\n识别出的实体:")
for ent in entities:
print(f"实体: {ent.get('word')}, 类型: {ent.get('type')}")
else:
print("\n未识别出实体")
except Exception as e:
print("调用失败:", str(e))
输出结果如下:
{
"result": [
{
"synonym": "",
"weight": "0.800000",
"tag": "品牌",
"word": "苹果"
},
{
"synonym": "",
"weight": "0.100000",
"tag": "普通词",
"word": "iPhone15"
},
{
"synonym": "手机套",
"weight": "1.000000",
"tag": "品类",
"word": "手机壳"
},
{
"synonym": "",
"weight": "0.600000",
"tag": "材质",
"word": "硅胶"
},
{
"synonym": "",
"weight": "0.600000",
"tag": "功能功效",
"word": "防摔"
},
{
"synonym": "保护壳",
"weight": "1.000000",
"tag": "品类",
"word": "保护套"
},
{
"synonym": "",
"weight": "0.100000",
"tag": "普通词",
"word": "适用于"
},
{
"synonym": "",
"weight": "0.800000",
"tag": "品牌",
"word": "苹果"
},
{
"synonym": "",
"weight": "0.400000",
"tag": "型号",
"word": "14Pro"
},
{
"synonym": "",
"weight": "0.100000",
"tag": "普通词",
"word": "Max"
}
],
"success": true
}
5. 词频统计优化
前言
定义
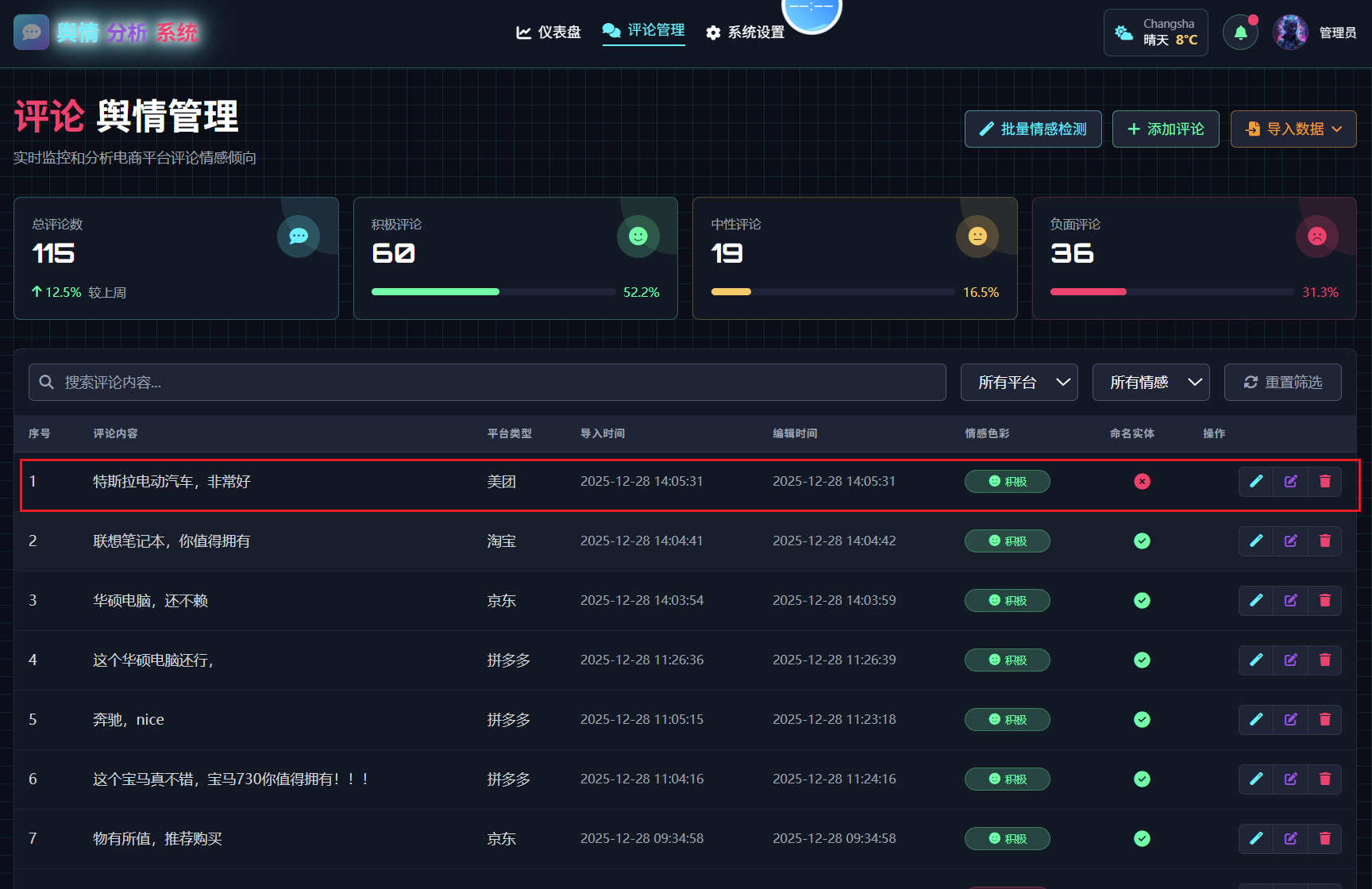
我们发现,重新增加评论评论后,词频统计的结果会不准确,需要优化,在评论列表中增加一个标识,方便查看哪些评论识别过,哪些评论没有识别过。
进行以下优化:
1. 在评论列表的情感色彩列和操作列之间,增加一个命名实体列,如果当前批量已经识别过,且信息存到了数据库,就给一个成功图标,如果还未标记则给一个失败图标。在操作栏的 点击情感识别的按钮事件中,增加命名实体识别。
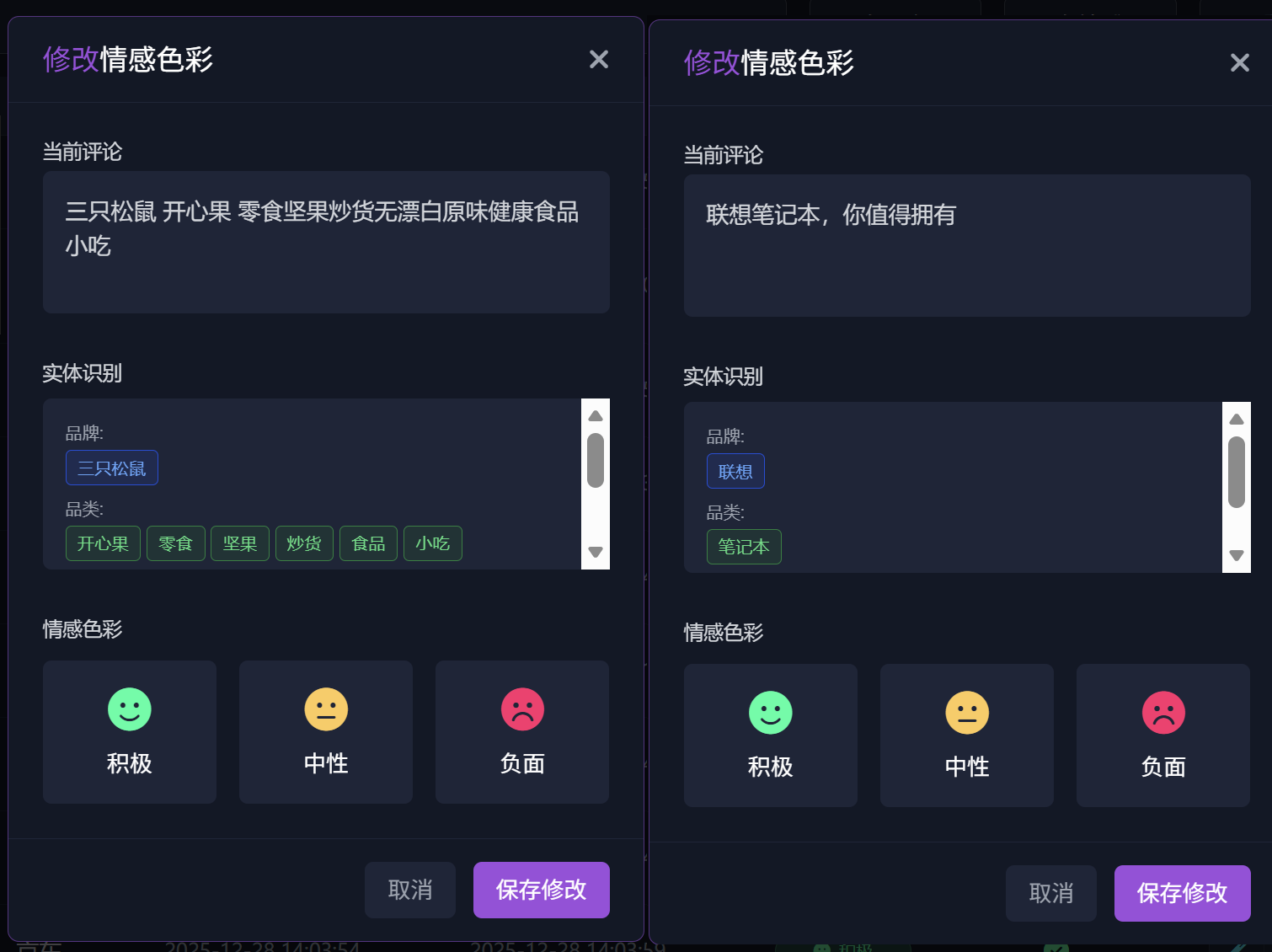
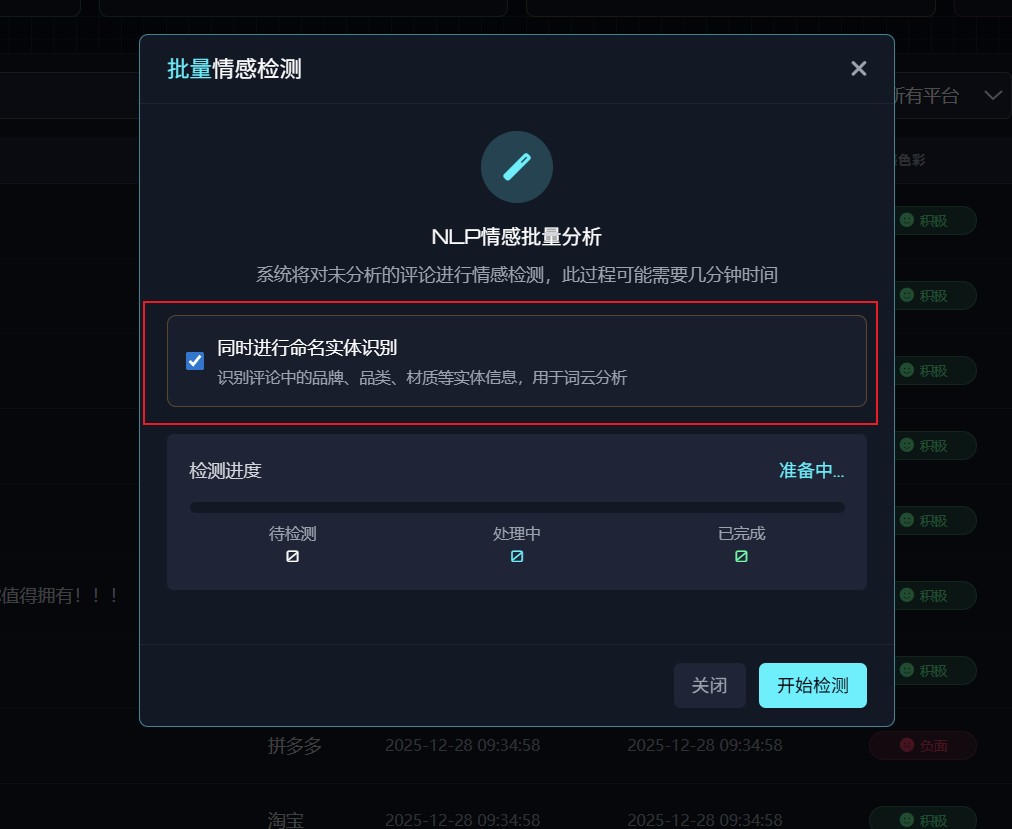
2. 点击批量情感检测,会弹出模态框,增肌一个勾选项,勾选后 同时进行未识别实体的评论 进行实体识别。
3. 在修改情感色彩模块框中,在当前评论和情感色彩之间,显示当前评论的实体命名的关键词和tag
4. 识别命名实体接口的核心步骤使用print输出日志,方便调试