1. 文本分类
前言
文本分类x是自然语言处理中的一项基本任务,它将文本数据分为不同的类别。文本分类在许多应用中都有广泛的应用,例如新闻分类、情感分析、垃圾邮件过滤等。在自然语言处理中,文本分类通常使用机器学习算法来实现,例如朴素贝叶斯、支持向量机、深度学习等。
创建项目
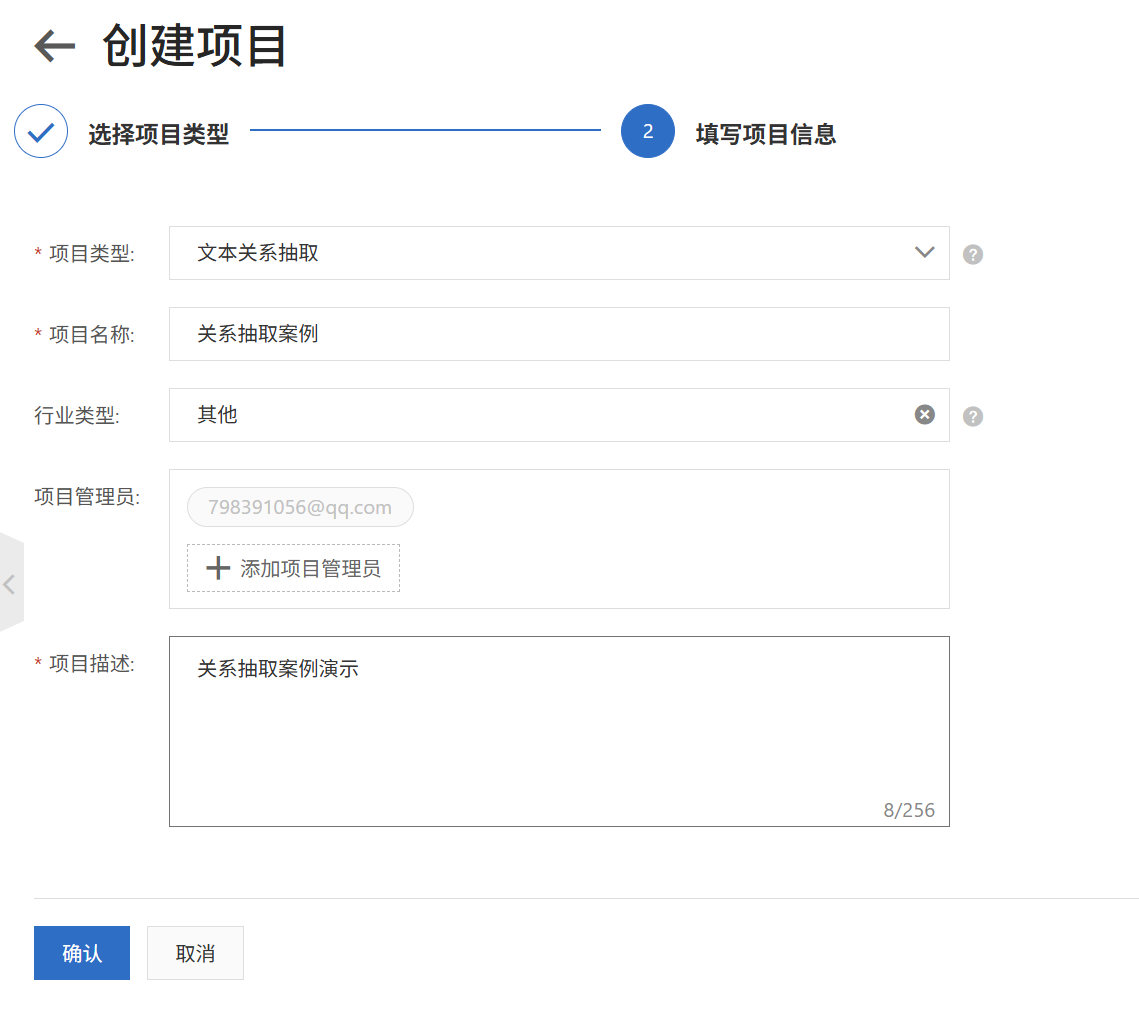
在NLP自学习平台中【点击进入自学习管控台】,支持多个基本项目和解决方案。在本教程中,我们将引导您掌握通过自学习平台创建一个文本分类的项目。进入“我的项目”或“创建项目”,选择“文本分类”算法点击“创建”。在接下来的页面填写项目名称和项目描述即可。

数据准备
由于模型需要通过标注数据来从中学习规律,我们首先要准备好一个标注数据集。以情感分析任务为例,我们的每一条数据为一个(文本,情感)对。例如:(“这个牌子的红枣很不错”,“正”)。情感一共有三种不同的类别:“正”,“中”,“负”。对于每一个不同的类别,我们建议至少准备500条训练数据再进行测试。训练数据需要按照NLP自学习平台定义好的格式进行处理,以JSON为例,您需要将每一条数据处理成如下格式:
{
"1": {
"content": "这个牌子的红枣很不错",
"records": {
"情感": "正"
}
}
}除了上述的单题目分类外,我们还可以有多题目,多标签,多层级,甚至更复杂的案例。官网笔记
数据标注
接下我们来训练一个属于自己的分类模型,按照上面的格式要求,我们准备500以上的已经标注好的数据,然后上传到平台中,进行训练。
如果没有标注好的数据,可以在平台上自行标注,500条以上,体会下标注的乐趣。
数据预处理
对于文本数据而言,通常文本数据里面会含有很多跟任务无关的噪音,这时应该进行文本的预处理。
在NLP自学习平台内置了一些预处理规则,如果您觉得有必要进行预处理,可以选择这些规则。我们内置的规则包括:
- 去除 URL 链接;
- 去除 emoji 表情符号;
- 英文大写转小写;
- 中文繁体转简体。
模型选择
在文本分类中,我们提供了多种模型进行选择,如果您不知道选哪个,可以选择CNN 进行尝试,兼顾了运行效率和最终结果。以下是模型的说明,您可以根据自己的具体场景,选择一个更适合的模型。
FastText 分类模型 速度快,计算资源要求低,适合样本数量大、类别标签多,适合不需要太多语义理解的任务。
CNN 分类模型 相比FastText 模型,CNN 适用复杂度更高的场景,可捕捉更多、更广、更细致的文本特征,适合需要一定语义理解的任务。对比FastText 通常效果要好一些,但训练时间也会更长。
Self-Attention 分类模型相比FastText 模型,Self-Attention 适应复杂度更高的场景,可捕捉更多、更广、更细致的特征;跟CNN 相比,能更好地捕捉文本里的长期依赖。适合需要一定语义理解的任务。训练时间跟效果跟 CNN 类似。
长文本分类融合模型 【推荐】 阿里巴巴达摩院自研的融合了CNN,FastText,Self-Attention等机制的集成学习模型,适用各类文本分类场景,包括篇幅较长的文体(如新闻、小说等),训练时间较长。
短文本分类融合模型 阿里巴巴达摩院自研的针对短文本分类的模型,适用于比如短信、微博、评论等文字字数小于150 字的场景,底层集成了朴素贝叶斯、FastText、支持向量机、随机森林等传统机器学习模型,优点是训练速度快。
BERT 小样本分类 阿里巴巴达摩院自研的针对小样本文本分类的模型,主要原理为使用 BERT模型 从大量无标注语料进行预训练。适用于标注语料有限的场景,训练和预测时间较长。
StructBERT 分类模型 【推荐】阿里巴巴达摩院自研的alicemind模型体系,主要原理为使用StructBERT模型 从大量无标注语料进行预训练,精度较高,推理速度较慢。
StructBERT小样本分类 :基于StructBert-base,在xnli数据集(将英文数据集重新翻译得到中文数据集)上面进行了自然语言推理任务训练
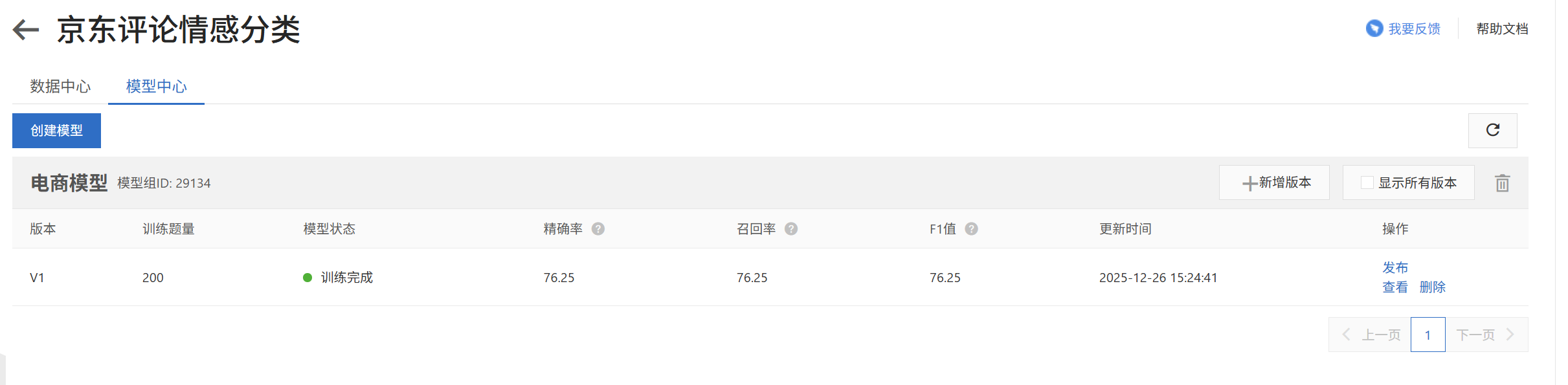
模型训练
训练完成后,查看效果(精确率,召回率,F1分数),如果效果不满意,可以继续进行训练,直到效果满意为止。
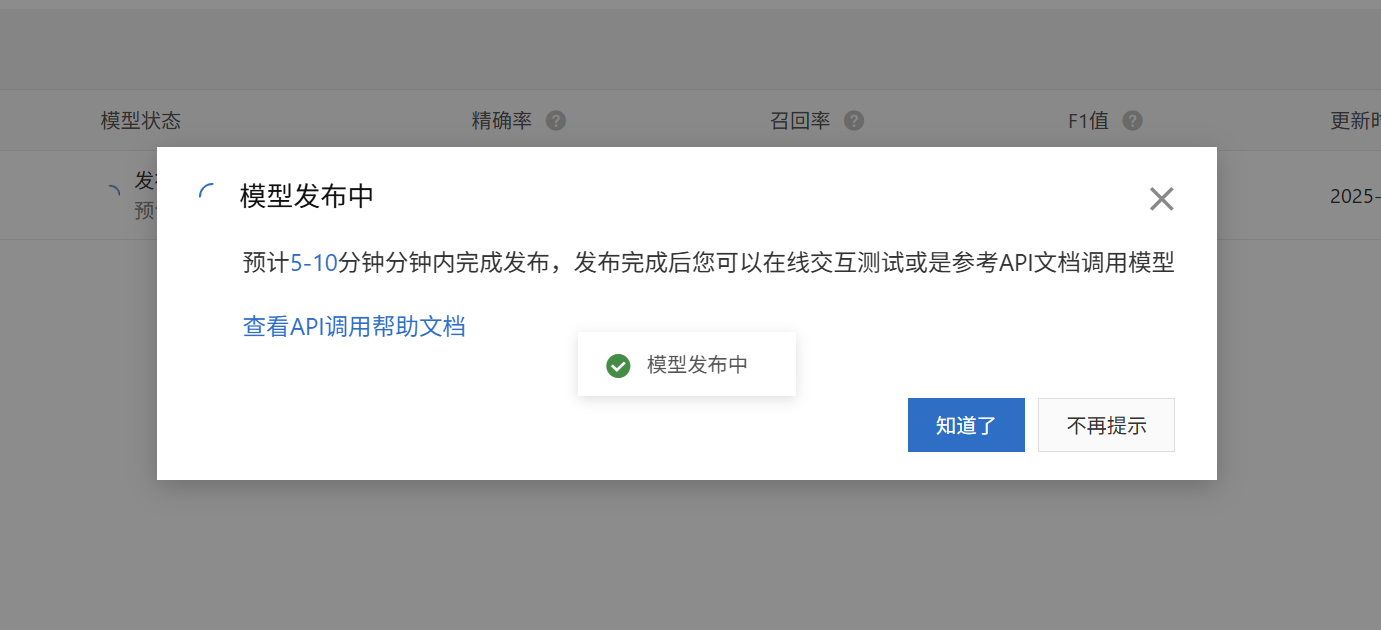
模型部署
模型训练完成后,可以部署到线上,进行预测。
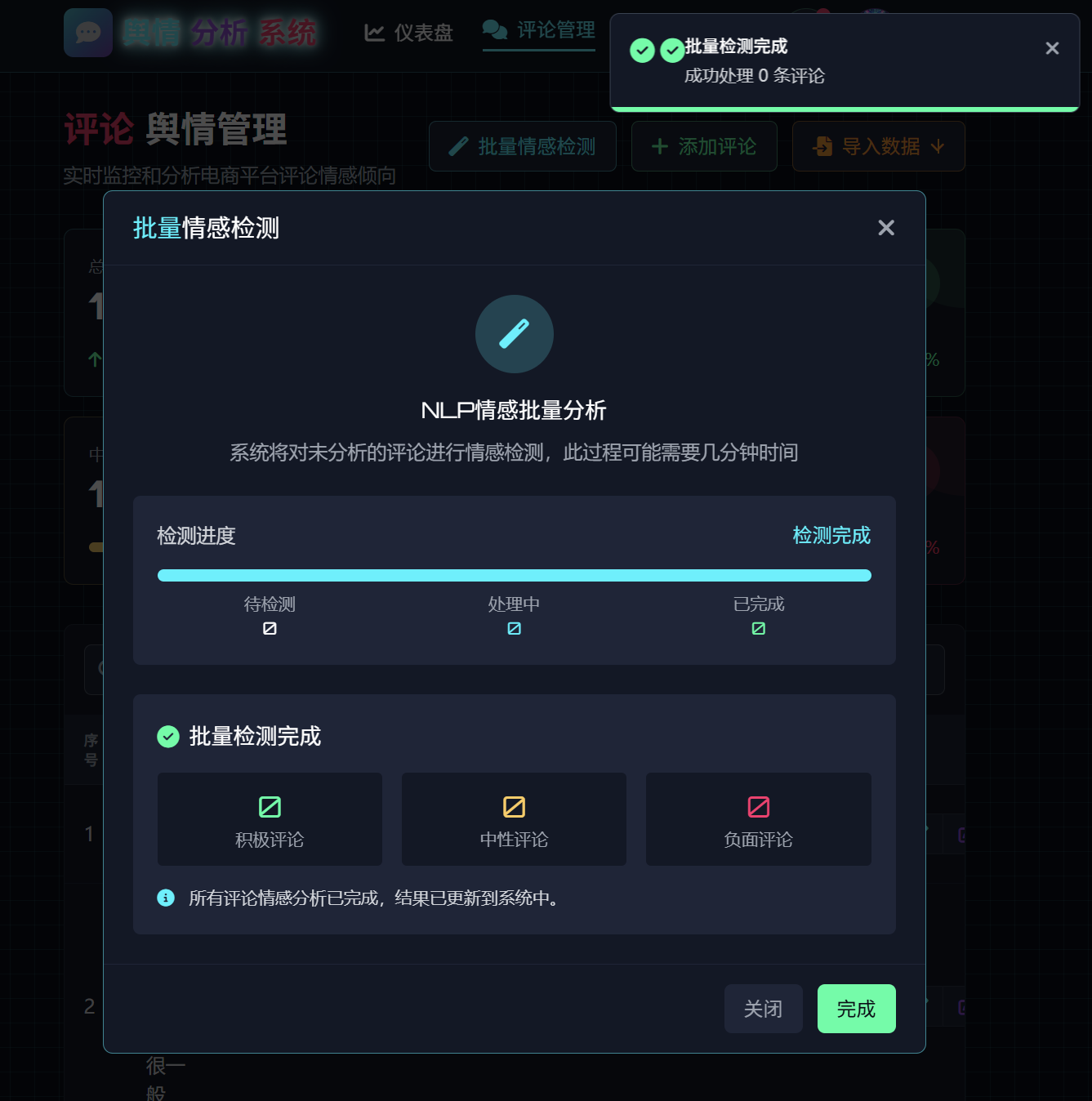
模型优化
对于模型的优化,我们提供如下几个建议:
- 换一个不同模型试试。不同的模型架构在不同的任务上表现可能不同,没有哪一个模型能够在所有任务中持续超出所有模型。所以,如果您发现 CNN效果不好,不妨换成 self-attention 试试看。
- 对于同一个模型调整模型的不同参数。即使是同一个模型,也会因为参数设置的不同而最终得到的效果不同。模型含有各种各样的超参数,为了减轻用户的负担,我们只开放了遍历次数和学习率两个参数。遍历次数一般不建议修改(除非您想快速训练完成),学习率参数有时对于模型的影响非常大,可以尝试在 0.001~0.0001 进行调整。
- 有时候上述对于模型的调整可能对于性能的提升都不是很大,这时可以考虑从数据层面来优化。比如数据的预处理阶段,尽可能去除掉对于结果无关的噪音。还可以尝试我们平台提供的数据增强功能,对数据集进行扩充。
- 分析 bad case,有针对性地补充数据。比如,您发现模型对于某一种类别经常分不对,很有可能是该类别数据量太少的原因,这时可以考虑补充该类别的数据。
模型测试
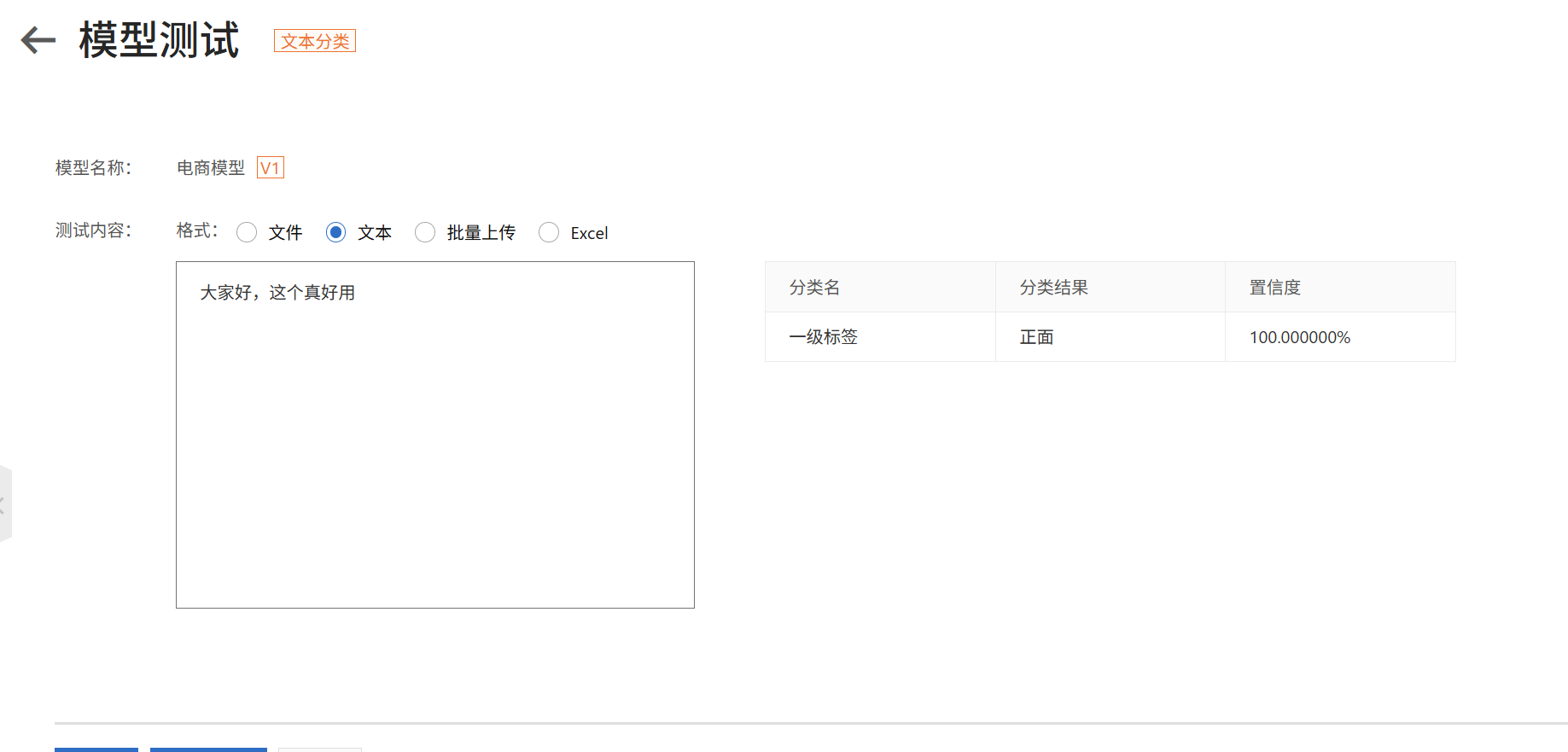
2. 文本关系抽取
前言
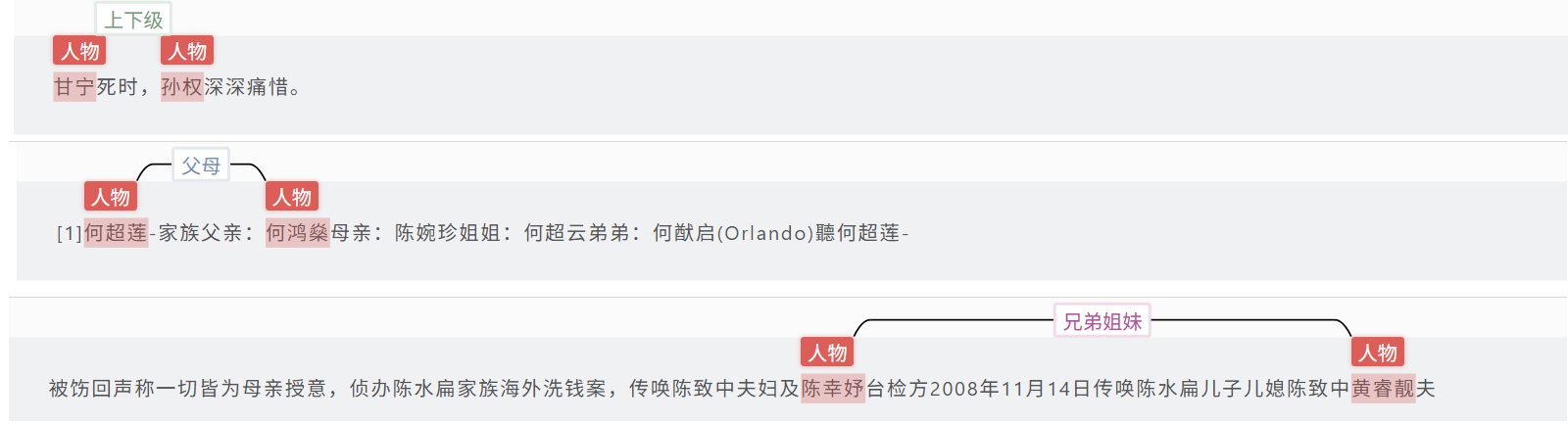
文本关系抽取: 抽取文本中的实体及对应的关系。标注数据越多,效果越佳。
创建项目
数据准备
创建标注任务(数据集)完成标注任务。

模型选择
关系抽取Bert:
基于BERT从大量无标注语料进行预训练的模型,加入融合实体对信息的模块进行关系分类模型训练。适用于标注数据比较干净,对效果要求较高,对训练时间/预测时间要求不是很高的主要内容是中文的场景。
关系抽取BertNoise:
基于BERT从大量无标注语料进行预训练的模型,加入融合实体对信息的模块以及抗噪模块进行关系分类模型训练。适用于标注数据不是很干净(带有一些标错或者噪声数据),对效果要求较高,对训练时间/预测时间要求不是很高的主要内容是中文的场景。
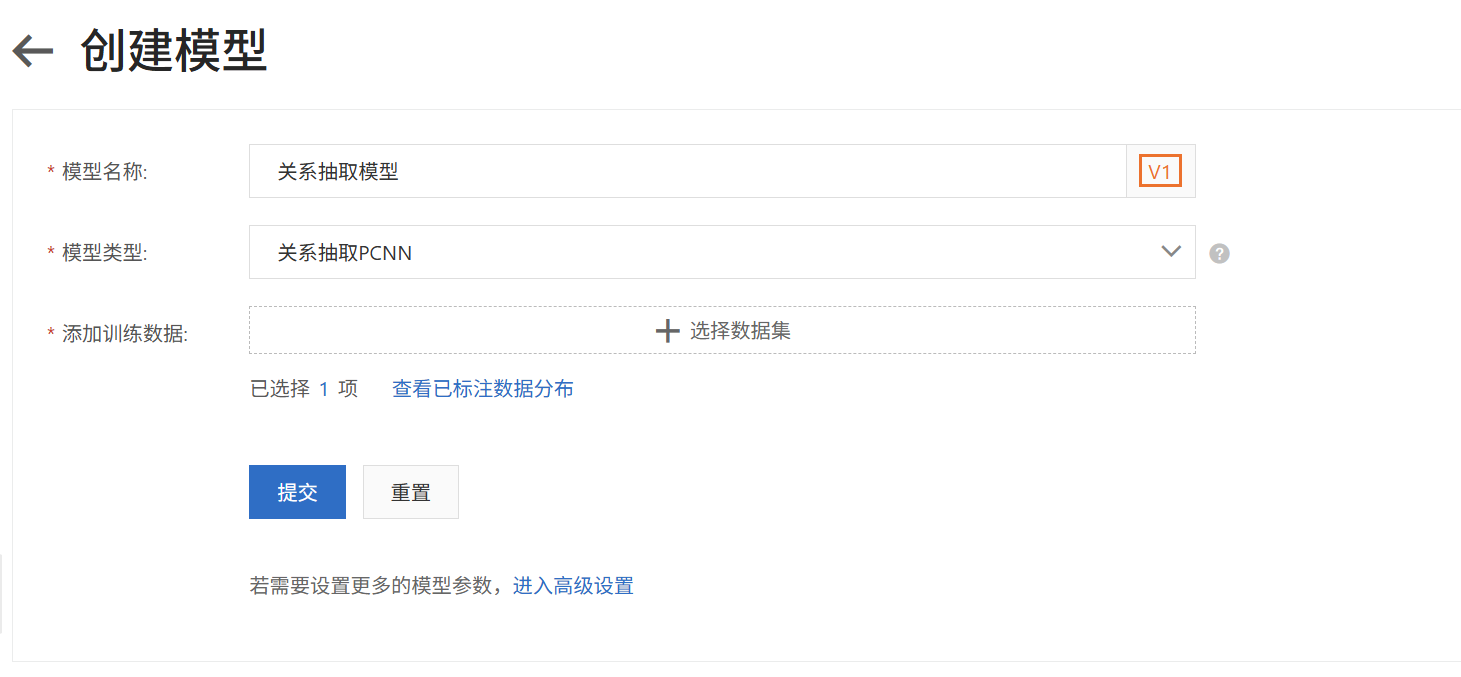
关系抽取PCNN:
基于PCNN (Piecewise Convolutional Neural Networks) 分类模型,加入noise converter抗噪模块进行关系分类模型训练,有一定的抗噪能力。相对于基于BERT而言,训练和预测都更快,适用于对效果和训练时间/预测时间要求比较均衡的主要内容是中文的场景。
StructBert:
基于阿里自研的Struct BERT,从大量无标注语料进行预训练的模型并且蒸馏后的模型,适合标注语料不足的中文任务。针对实体重叠问题进行了优化。建议一般用户选择该类模型。
更多信息请参考模型说明文档:https://help.aliyun.com/document_detail/162045.html
模型训练


模型部署和测试
3. 完成舆情接口测试案例
前言
点击阿里云自然语言处理平台 开通基础班服务,关注情感分析-通用的API接口
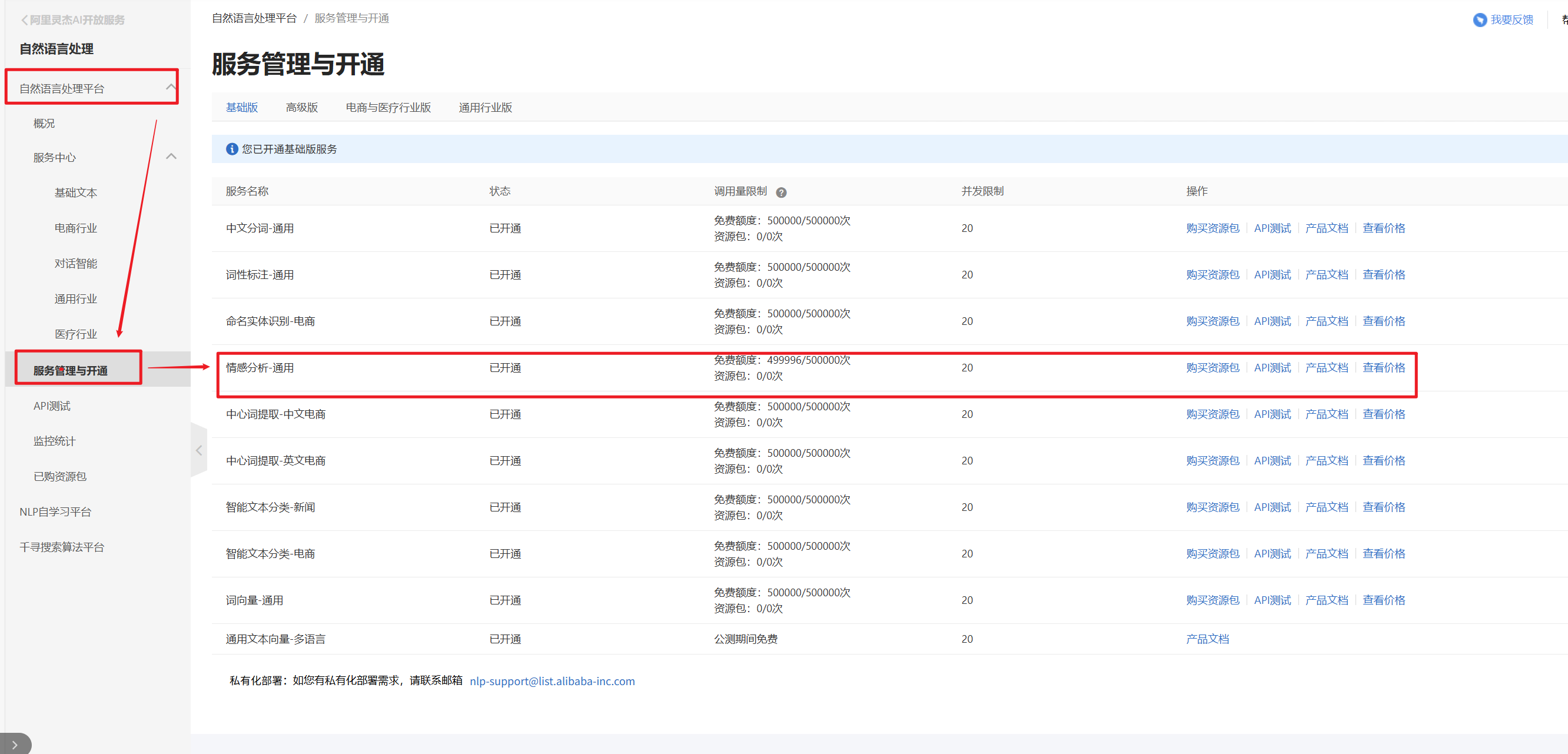
点击进行API测试 👇
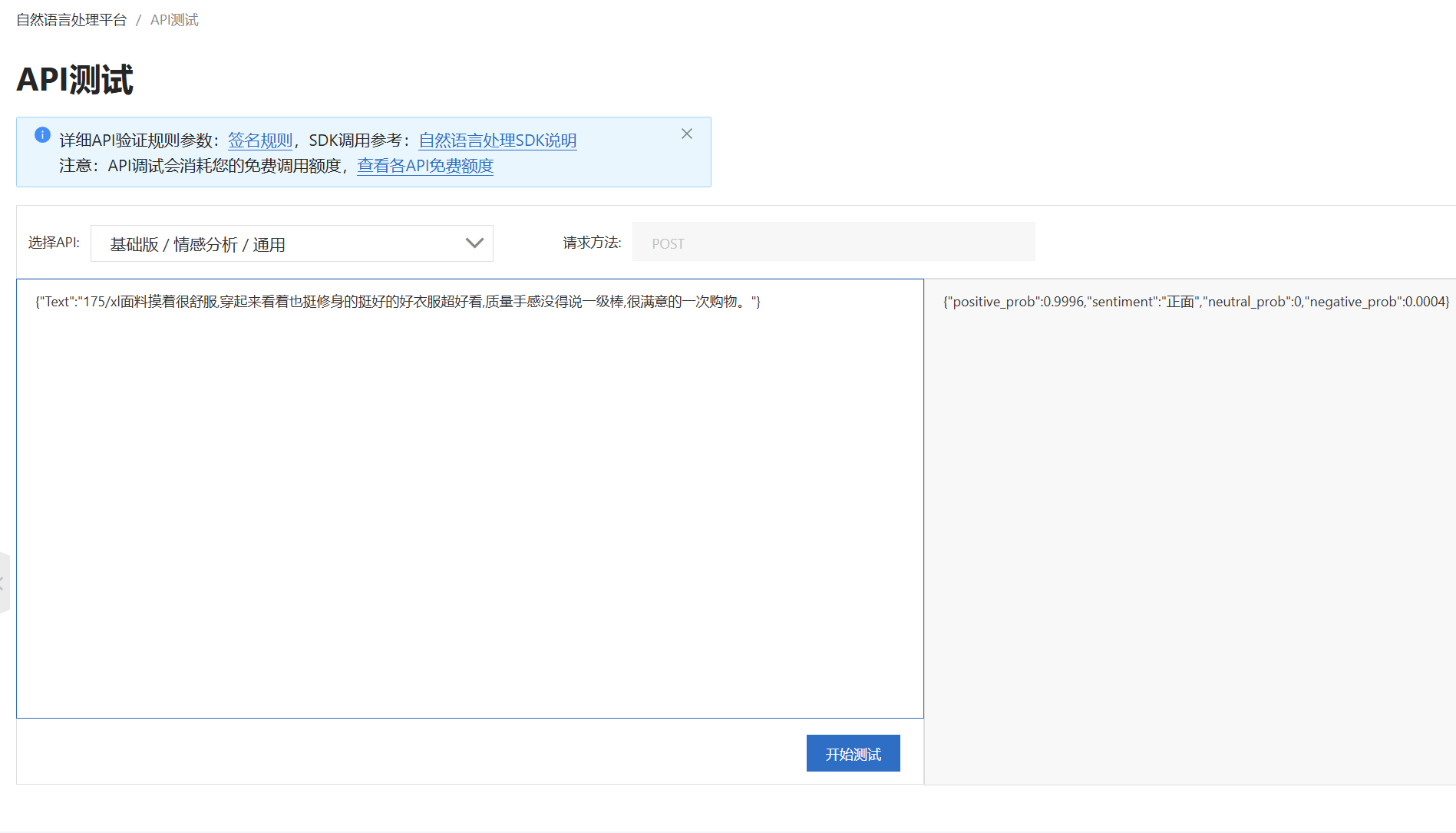
接下来,我们在Jupyter中进行测试
步骤:
- 获得AccessKey和AccessKeySecret
观看教学视频,或者直接官网教程
- 安装aliyun-python-sdk-alinlp
# pip安装命令
pip install alibabacloud_alinlp20200629安装好了,后重启jupyter
- 编写代码
import json
from alibabacloud_alinlp20200629.client import Client as AlinlpClient
from alibabacloud_alinlp20200629.models import GetSaChGeneralRequest
from alibabacloud_tea_openapi.models import Config
# === 配置认证信息 ===
access_key_id = "your_access_key_id" # 替换为你的 AccessKey ID
access_key_secret = "your_access_key_secret" # 替换为你的 AccessKey Secret
config = Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret,
region_id='cn-hangzhou',
endpoint='alinlp.cn-hangzhou.aliyuncs.com'
)
client = AlinlpClient(config)
# === 构建请求 ===
request = GetSaChGeneralRequest()
request.text = "这家店的服务非常好,产品质量也很棒,下次还会再来!"
request.service_code = "alinlp" # 👈 必须设置,否则报错 MissingServiceCode
# === 发起调用 ===
try:
response = client.get_sa_ch_general(request)
# ✅ 获取原始 body(可能是字符串或对象)
raw_body = response.body
# ✅ 判断类型并处理
if isinstance(raw_body, str):
# 如果是字符串,先转成 dict
result = json.loads(raw_body)
elif hasattr(raw_body, 'data'):
# 有些版本是对象,尝试取 data 属性
data = raw_body.data
if isinstance(data, str):
result = json.loads(data)
else:
result = data
else:
result = raw_body # 假设已经是 dict
# ✅ 现在可以安全使用 .get()
print(json.dumps(result, ensure_ascii=False, indent=2))
# ✅ 提取情感标签
sentiment = result.get("result", {}).get("sentiment")
if sentiment:
print(f"\n情感倾向:{sentiment}")
else:
print("\n未能获取情感结果")
except Exception as e:
print("调用失败:", str(e))- 运行代码
{
"result": {
"positive_prob": 0.9948,
"sentiment": "正面",
"neutral_prob": 0.0,
"negative_prob": 0.0052
},
"success": true,
"tracerId": "4dd18b3e-5e1a-4bdd-9e94-c932d486353c"
}
情感倾向:正面4.集成情感分类到舆情系统
前言
1.日志信息集成(最好是在前期)
考虑到AI编码后,有可能会出错,因此每一步需要输出日志信息,确保AI能够获取这些信息进行排错,因此需要让AI编程过程中,使用print方式输出日志信息,方便排错。
提示词
将核心的核心代码步骤,使用print输出中文日志信息,方便排错。2.集成情感分类到舆情系统
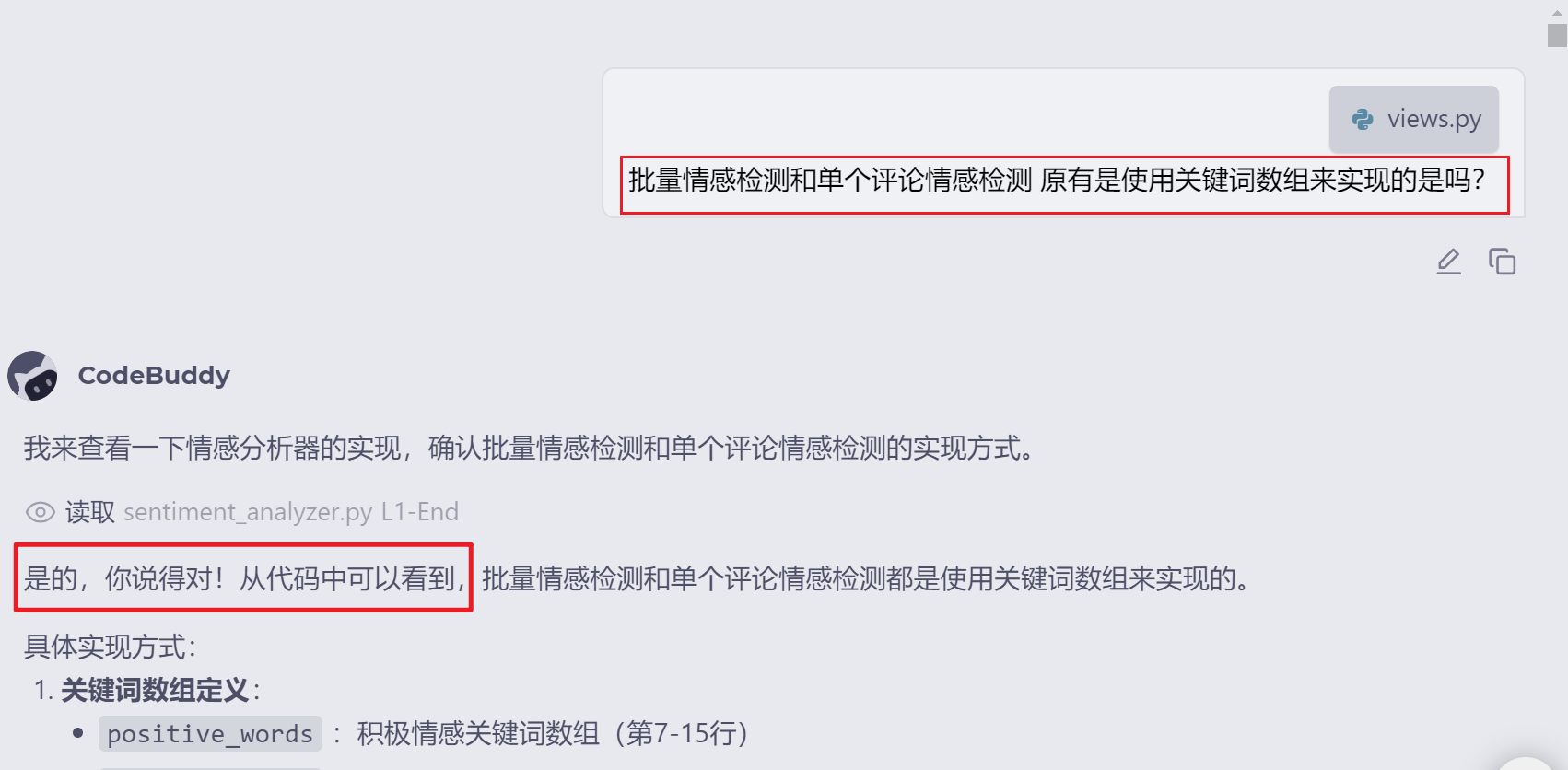
- 和AI沟通,确定Ai能理解现在代码的实现方式
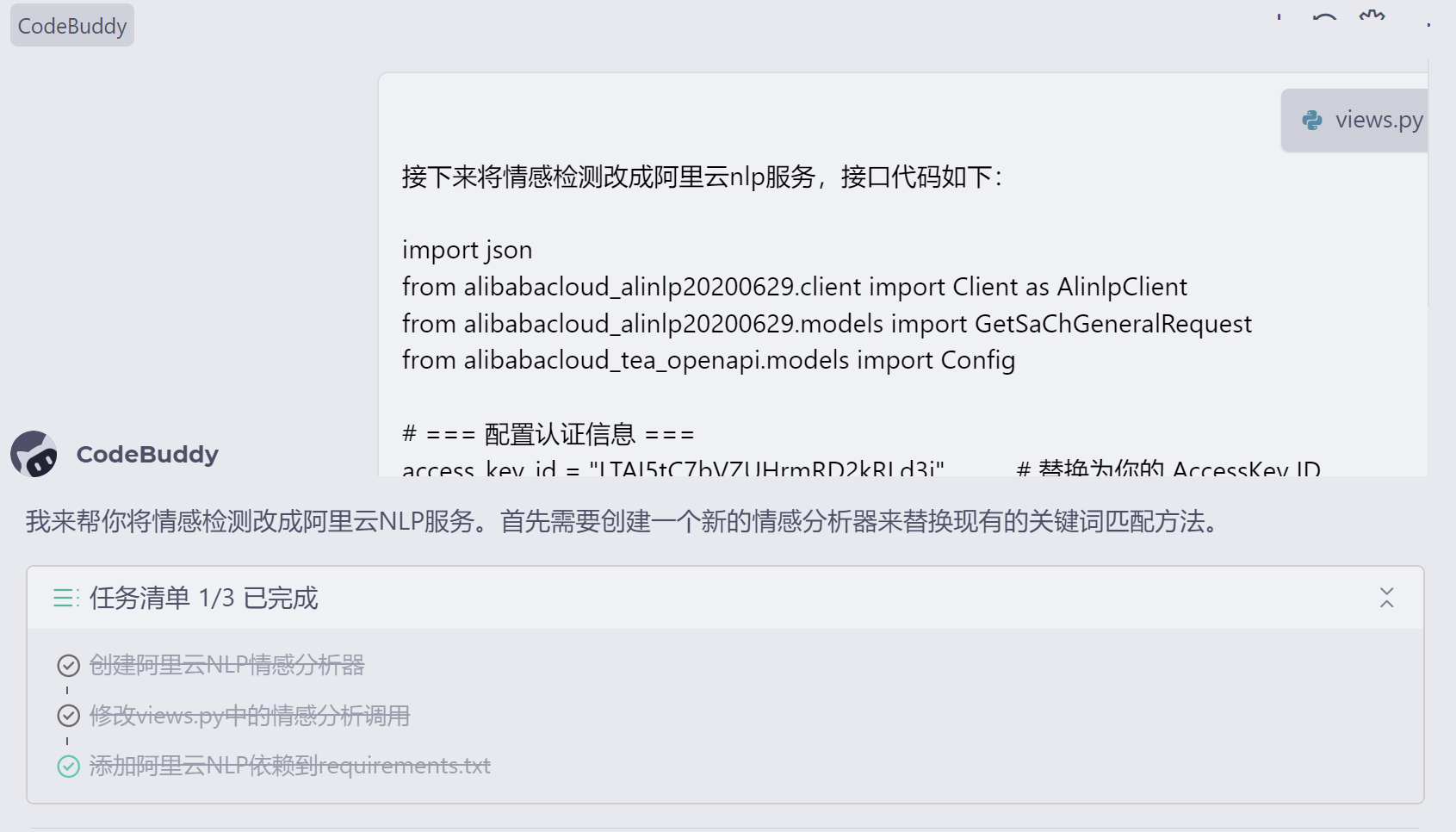
- 接着将案例代码和返回结果,以及需求发送给ai
- 可以使用云部署或者本地部署,如果有错,直接将错误信息发送给ai,ai会进行排错
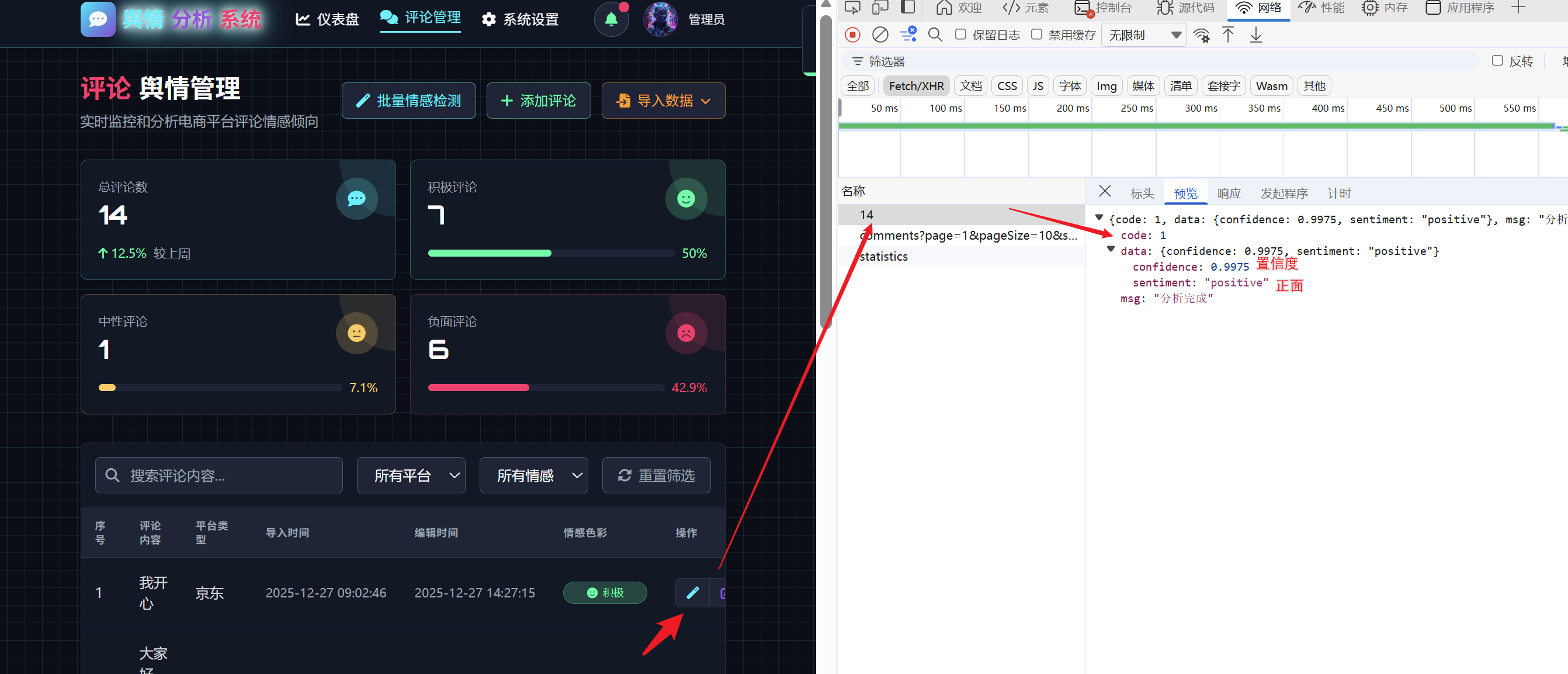
- 接着测试批量的