
1. 文本预处理
文本预处理及其作用
文本语料在输送给模型前一般需要一系列的预处理工作, 才能符合模型输入的要求, 如: 将文本转化成模型需要的张量, 规范张量的尺寸等, 而且科学的文本预处理环节还将有效指导模型超参数的选择, 提升模型的评估指标.
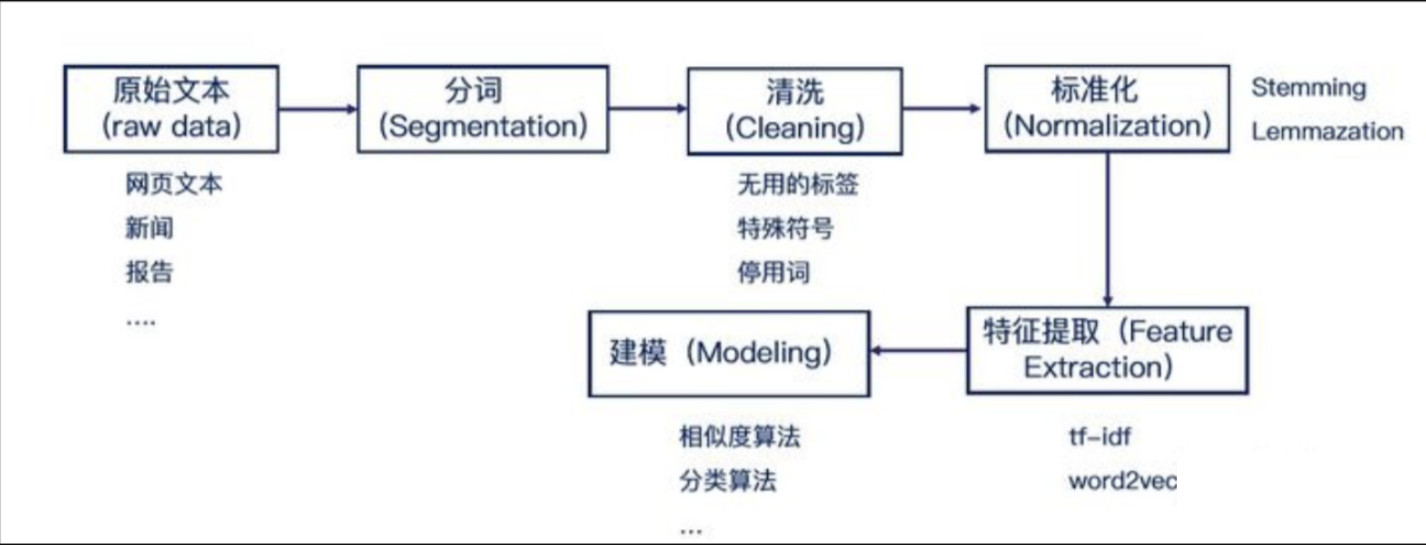
1. 文本处理的基本方法
前言
1. 分词
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符, 分词过程就是找到这样分界符的过程.
分词的作用:词作为语言语义理解的最小单元, 是人类理解文本语言的基础. 因此也是AI解决NLP领域高阶任务, 如自动问答, 机器翻译, 文本生成的重要基础环节.
举个栗子:
工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作
==>
['工信处', '女干事', '每月', '经过', '下属', '科室', '都', '要', '亲口',
'交代', '24', '口', '交换机', '等', '技术性', '器件', '的', '安装', '工作']中文分词常用:jieba
为什么英文不用分词,因为英文的分词是自然的空格分割
pip install jiebaimport jieba
content = "工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作"
jieba.lcut(content, cut_all=True)输出: 👇
['工信处',
'处女',
'女干事',
'干事',
'每月',
'月经',
'经过',
'下属',
'科室',
'都',
'要',
'亲口',
'口交',
'交代',
'24',
'口交',
'交换',
'交换机',
'换机',
'等',
'技术',
'技术性',
'性器',
'器件',
'的',
'安装',
'安装工',
'装工',
'工作']没有使用用户自定义词典前的结果:
import jieba
jieba.lcut("八一双鹿更名为八一南昌篮球队!")['八', '一双', '鹿', '更名', '为', '八一', '南昌', '篮球队', '!']使用了用户自定义词典后的结果:
userdict.txt 如下 :
云计算 5 n
李小福 2 nr
easy_install 3 eng
好用 300
韩玉赏鉴 3 nz
八一双鹿 3 nzn: 名词 nr: 人名 eng: 英文 nz: 机构团体名 5: 频次 300: 自定义词频
jieba.load_userdict("./userdict.txt")
jieba.lcut("八一双鹿更名为八一南昌篮球队!")['八一双鹿', '更名', '为', '八一', '南昌', '篮球队', '!']2. 命名实体识别
命名实体: 通常我们将人名, 地名, 机构名等专有名词统称命名实体. 如: 周杰伦, 黑山县, 孔子学院, 24辊方钢矫直机.
顾名思义, 命名实体识别(Named Entity Recognition,简称NER)就是识别出一段文本中可能存在的命名实体.
- 举个栗子:
鲁迅, 浙江绍兴人, 五四新文化运动的重要参与者, 代表作朝花夕拾.
==>
鲁迅(人名) / 浙江绍兴(地名)人 / 五四新文化运动(专有名词) / 重要参与者 / 代表作 / 朝花夕拾(专有名词)命名实体识别的作用: 同词汇一样, 命名实体也是人类理解文本的基础单元, 因此也是AI解决NLP领域高阶任务的重要基础环节.
import jieba.posseg as pseg
pseg.lcut("我爱北京天安门")
结果:
[pair('我', 'r'), pair('爱', 'v'), pair('北京', 'ns'), pair('天安门', 'ns')]
# 结果返回一个装有pair元组的列表, 每个pair元组中分别是词汇及其对应的词性, 具体词性含义请参照[附录: jieba词性对照表]()
r: 人名
v: 动词
ns: 地名3.词性标注
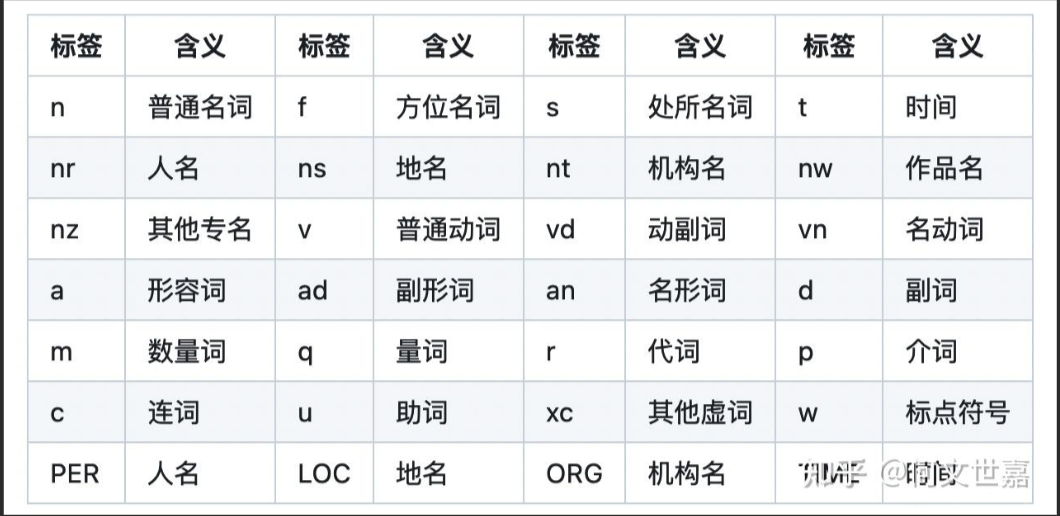
词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等.
顾名思义, 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性.
作用:词性标注以分词为基础, 是对文本语言的另一个角度的理解, 因此也常常成为AI解决NLP领域高阶任务的重要基础环节.
- 举个栗子:
我爱自然语言处理
==>
我/rr, 爱/v, 自然语言/n, 处理/vn
rr: 人称代词
v: 动词
n: 名词
vn: 动名词使用jieba进行中文词性标注:
import jieba.posseg as pseg
pseg.lcut("我爱北京天安门")输出:👇
[pair('我', 'r'), pair('爱', 'v'), pair('北京', 'ns'), pair('天安门', 'ns')]
# 结果返回一个装有pair元组的列表, 每个pair元组中分别是词汇及其对应的词性, 具体词性含义请参照[附录: jieba词性对照表]()2.文本张量表示方法
前言
文本张量表示:将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
举个栗子:
["人生", "该", "如何", "起头"]
==>
# 每个词对应矩阵中的一个向量
[[1.32, 4,32, 0,32, 5.2],
[3.1, 5.43, 0.34, 3.2],
[3.21, 5.32, 2, 4.32],
[2.54, 7.32, 5.12, 9.54]]文本张量表示的作用:将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作.
文本张量表示的方法:
- one-hot编码
- Word2vec
- Word Embedding
1. 什么是one-hot词向量表示?
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数.
["改变", "要", "如何", "起手"]`
==>
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
# 导入用于对象保存与加载的joblib
import joblib
# 导入keras中的词汇映射器Tokenizer
from tensorflow.keras.preprocessing.text import Tokenizer
# 假定vocab为语料集所有不同词汇集合
vocab = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"}
# 实例化一个词汇映射器对象
t = Tokenizer(num_words=None, char_level=False)
# 使用映射器拟合现有文本数据
t.fit_on_texts(vocab)
for token in vocab:
zero_list = [0]*len(vocab)
# 使用映射器转化现有文本数据, 每个词汇对应从1开始的自然数
# 返回样式如: [[2]], 取出其中的数字需要使用[0][0]
token_index = t.texts_to_sequences([token])[0][0] - 1
zero_list[token_index] = 1
print(token, "的one-hot编码为:", zero_list)
# 使用joblib工具保存映射器, 以便之后使用
tokenizer_path = "./Tokenizer"
joblib.dump(t, tokenizer_path)鹿晗 的one-hot编码为: [1, 0, 0, 0, 0, 0]
吴亦凡 的one-hot编码为: [0, 1, 0, 0, 0, 0]
陈奕迅 的one-hot编码为: [0, 0, 1, 0, 0, 0]
李宗盛 的one-hot编码为: [0, 0, 0, 1, 0, 0]
王力宏 的one-hot编码为: [0, 0, 0, 0, 1, 0]
周杰伦 的one-hot编码为: [0, 0, 0, 0, 0, 1]
['./Tokenizer']one-hot编码的优劣势: 👇
- 优势 :操作简单,容易理解.
- 劣势 :完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
正因为one-hot编码明显的劣势,这种编码方式被应用的地方越来越少,取而代之的是接下来我们要学习的稠密向量的表示方法word2vec和word embedding.
什么是word2vec
是一种流行的将词汇表示成向量的无监督训练方法, 该过程将构建神经网络模型, 将网络参数作为词汇的向量表示, 它包含CBOW和skipgram两种训练模式.
CBOW(Continuous bag of words)模式:
给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用上下文词汇预测目标词汇.
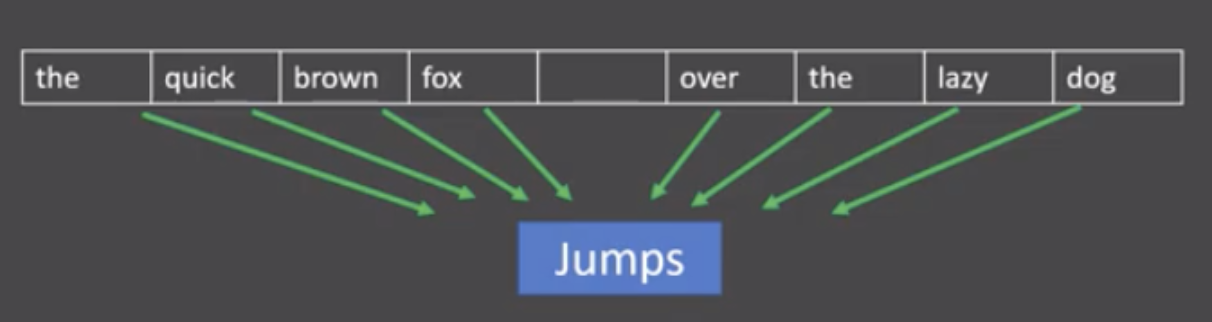
图中窗口大小为9, 使用前后4个词汇对目标词汇进行预测.
skipgram模式:
给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用目标词汇预测上下文词汇.
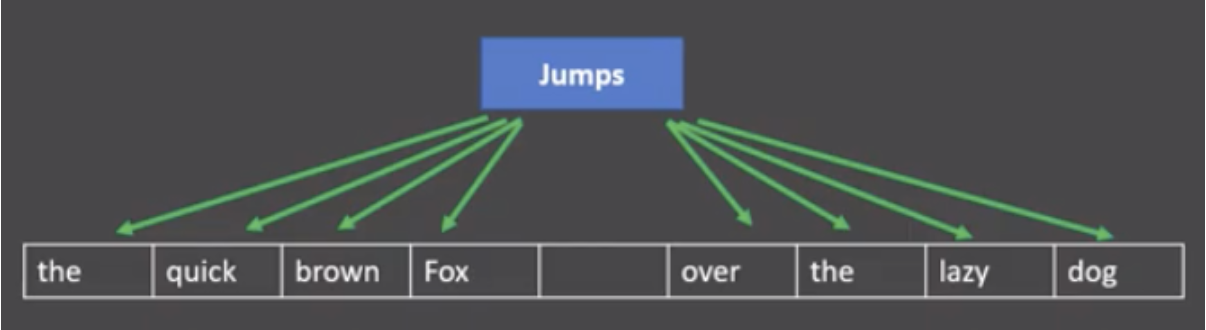
图中窗口大小为9, 使用目标词汇对前后四个词汇进行预测.
什么是word embedding
通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间.
- 广义的word embedding 包括所有密集词汇向量的表示方法,如之前学习的word2vec, 即可认为是word embedding的一种.
- 狭义的word embedding 是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.
word embedding的可视化分析: 👇
通过使用tensorboard可视化嵌入的词向量.
# 导入torch和tensorboard的摘要写入方法
import torch
import json
import fileinput
from torch.utils.tensorboard import SummaryWriter
# 实例化一个摘要写入对象
writer = SummaryWriter()
# 随机初始化一个100x50的矩阵, 认为它是我们已经得到的词嵌入矩阵
# 代表100个词汇, 每个词汇被表示成50维的向量
embedded = torch.randn(100, 50)
# 导入事先准备好的100个中文词汇文件, 形成meta列表原始词汇
meta = list(map(lambda x: x.strip(), fileinput.FileInput("./vocab100.csv")))
writer.add_embedding(embedded, metadata=meta)
writer.close()安装tensorboard
pip install tensorboard!python -m tensorboard.main --logdir runs --host 0.0.0.0 --port 6006
# 通过http://0.0.0.0:6006访问浏览器可视化页面浏览器展示并可以使用右侧近邻词汇功能检验效果:

3. 模型评价指标
前言
模型评价指标:
精确率(Precision),查准率,表示正确预测为正的占全部预测为正的比例。 对某一实体而言为正确预测为该实体的样本数与预测为该实体的总样本数之比,此处为整体精确率,操作区点击“查看”可查看每一个实体的精确率。
召回率(Recall),查全率,表示正确预测为正的占全部实际为正的比例。对某一实体而言为正确预测为该实体的样本数与该实体的总样本数之比,此处为整体召回率,操作区点击“查看”可查看每一个实体的召回率。
精确率和召回率的“调和”—— F度量 (F-Measure)
我们之前提到,精确率 (P) 和 召回率 (R) 经常是矛盾的,像一个跷跷板。
召回率:TP / (TP + FN)
精确率:TP / (TP + FP)
如果你想提高召回率(不漏掉一个病人),你就会倾向于“宁可错杀,不可放过”,把更多可疑的人都判断为生病(FP增加)。这会导致精确率下降(因为误诊的健康人变多了)。
如果你想提高精确率(确保你判断为生病的人一定是病人),你就会变得非常“保守”,只有证据非常充分时才判定为生病。这会导致召回率下降(因为很多真正的病人被漏掉了)。
那么问题来了: 如果一个模型的精确率是0.7,召回率是0.6;另一个模型的精确率是0.6,召回率是0.7。我们该选哪个?
这时候,我们需要一个单一的数字来综合衡量这两个指标。这就是F度量。
F1分数 是 精确率和召回率 的调和平均数。它给予较低的值更高的惩罚。
公式:F1 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
也可以写成:F1 = (2 * TP) / (2 * TP + FP + FN)
F1分数能有效惩罚那些在精确率和召回率上表现极度不平衡的模型,迫使模型寻找一个平衡点。F1分数的取值范围是[0, 1],越接近1,模型综合性能越好。
2.NLP应用
4. 自学平台之文本实体抽取
前言
文本实体抽取:抽取文本中具有特定意义的实体。例如合同审核场景中,需要抽取合同名称、甲方、乙方、收款账号等实体信息,用于快速将大量合同结构化。

点击这里进入官方文档:https://help.aliyun.com/document_detail/162024.html
资料在学习通中下载
5. 预训练模型调用
前言
