上下文工程和MCP
1.上下文工程
前言
在AI应用快速扩张的今天,大语言模型(LLM)已经不仅仅是“能说会写”的文本生成工具,它正在变成智能助手、对话中枢,甚至是企业自动化的核心引擎。然而,许多人忽视了一个关键问题:模型的聪明程度,往往取决于它“看到了什么”。
这就是上下文工程(Context Engineering) 正在兴起的原因。
如果说提示工程教会了我们如何向模型提问 ,那么上下文工程则让我们能够构建模型所需的“世界观 ”。它不只是写 prompt 的高级版本,而是s,正在成为 LLM 应用成功与否的分水岭。
本节将深入解析上下文工程的核心概念、关键模块、实际应用和未来趋势,带你看清这场“无提示胜有提示”的底层变革。
一. 上下文工程是什么?
随着大语言模型(LLM)的广泛应用,开发者越来越发现一个事实:模型性能的优劣,不仅取决于模型本身的规模和参数量,更取决于它在推理时“看见了什么”。这就催生了一个日益受到重视的工程领域——上下文工程(Context Engineering)。
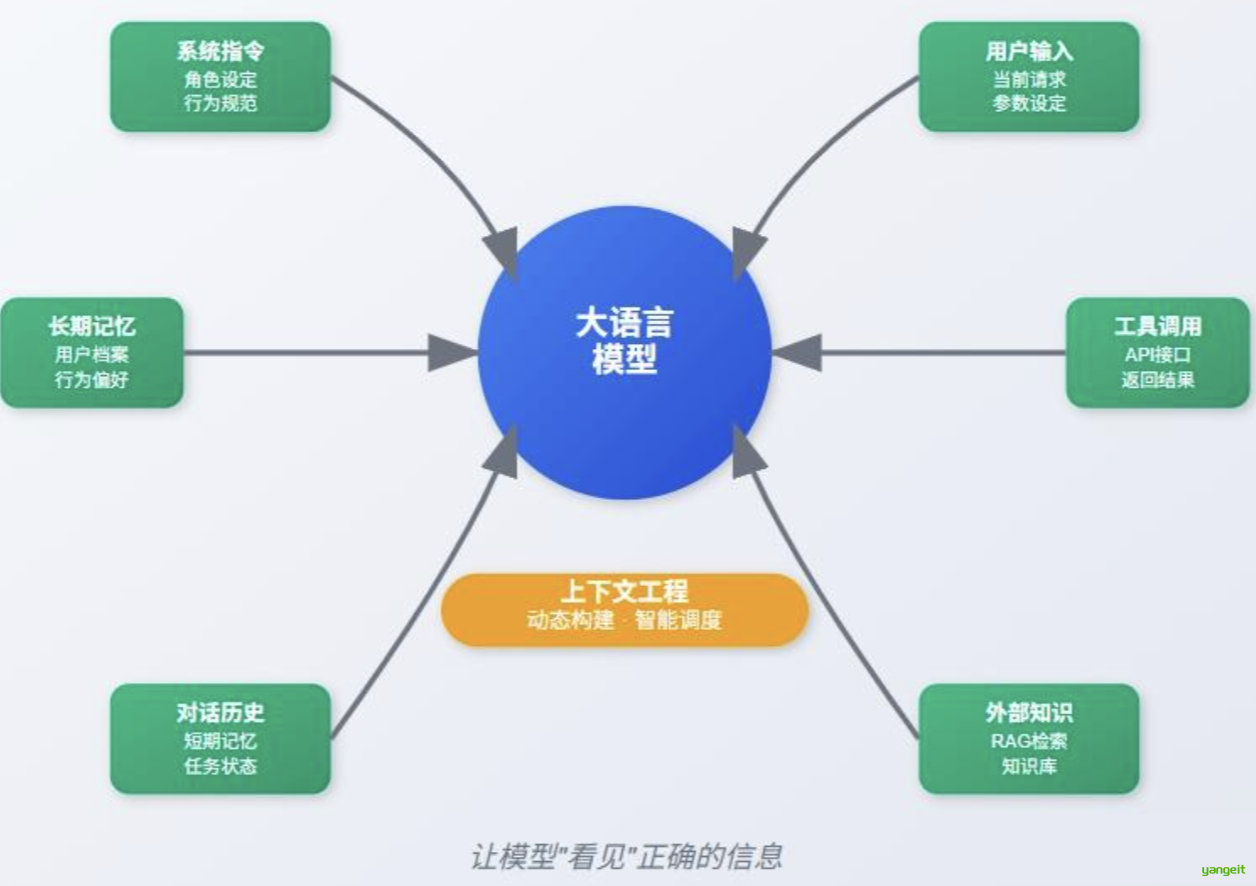
所谓上下文工程,是指围绕大模型输入上下文的设计、管理和动态构建技术体系,目的是让模型在每一次调用中都能获取最合适、最相关的背景信息、任务指令和外部工具接口,从而提升响应的准确性、稳定性和可控性。
简而言之: 👇
- 提示工程(Prompt Engineering)关注“怎么问”;
- 上下文工程关注“模型看到了什么 ”。
在实际应用中,这种“看到什么”对模型表现的影响,往往比提示词本身更为关键。
二、为什么上下文工程越来越重要?
1. 模型是无状态的,需要人为构建“记忆”
大多数大语言模型在调用时是无状态的,它们并不知道过去发生了什么,也无法理解上下文的变化,除非你明确地把这些信息放进输入中。这使得如何高效、结构化地传递背景知识和历史内容成为关键。
2. 提示工程的能力边界已逐渐暴露
虽然写好提示词依旧重要,但它往往解决不了任务分解、长对话记忆、动态检索等复杂问题 。例如:
- 多轮对话中如何让模型记住用户的偏好?
- 知识库检索的内容如何准确插入模型上下文?
- 工具调用返回的内容如何让模型理解并使用?
这些都是提示工程无法单独胜任的,而上下文工程正好补位。
3. 构建 AI Agent 的系统能力关键在上下文
AI Agent 要完成复杂任务,必须具备“记忆能力”、“工具调用能力”、“环境感知能力”等。而这些能力的背后,本质上都是动态构建和管理模型上下文的能力。也就是说,Agent 的大脑是 LLM,而上下文工程则是它的“神经网络”。
2.上下文工程的关键组成部分和提示词工程的区别
前言
上下文工程的关键组成部分和提示词工程的区别
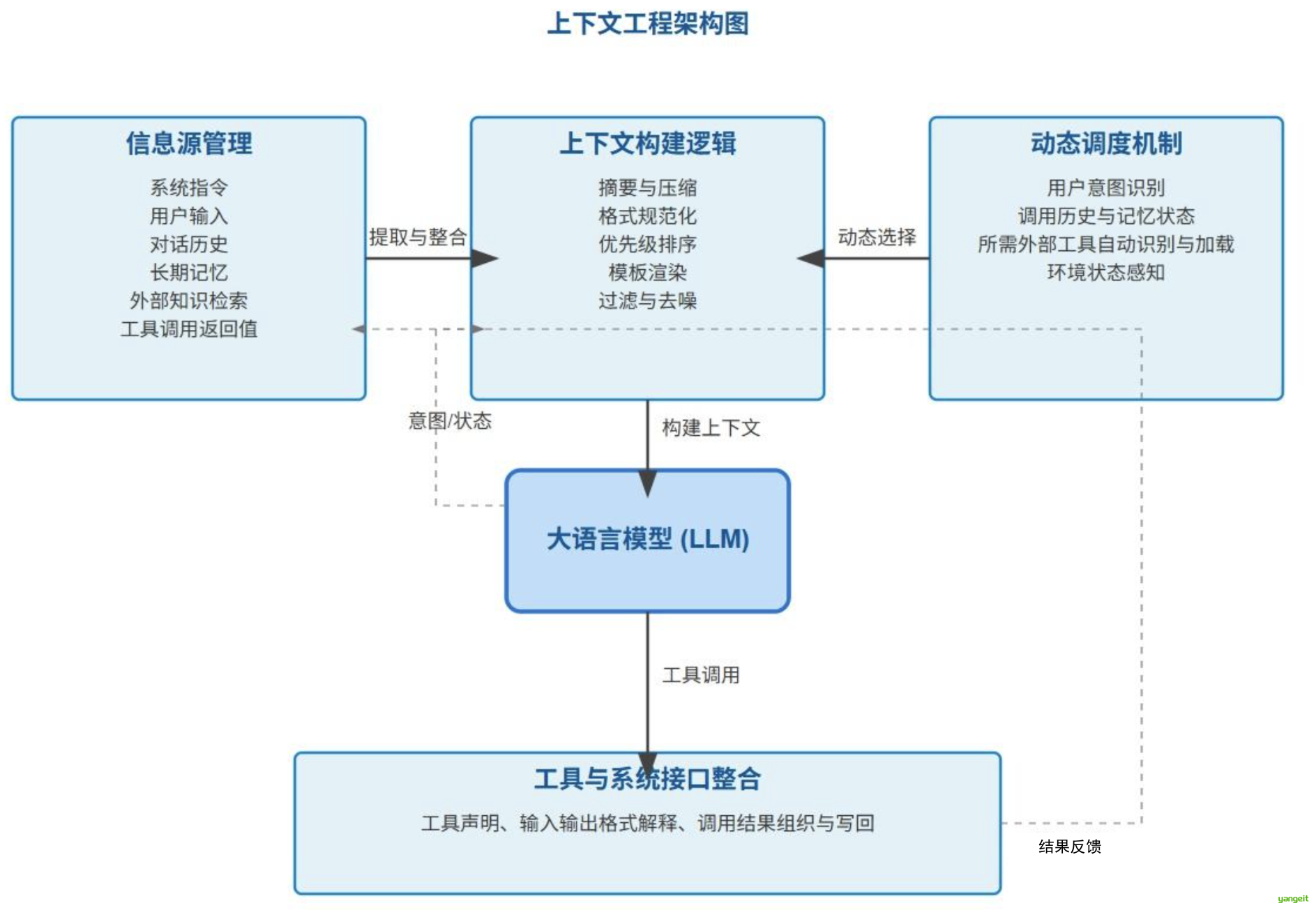
上下文工程可以被拆解为多个关键模块,每一块都是构建可靠 LLM 系统的支柱:
1. 信息源管理
上下文信息来源复杂多样,常见包括: 👇
- 系统指令:设定模型角色、风格、禁用内容等。
- 用户输入:当前请求、参数、偏好等。
- 对话历史:包括短期对话记忆和长时任务状态。
- 长期记忆:如用户档案、行为偏好、历史任务记录。
- 外部知识检索 :RAG 检索结果、文档摘要、数据库内容。
- 工具调用返回值 :如 API 接口调用、网页抓取结果等。
上下文工程的第一步,就是提取并整合这些来源的信息。
2. 上下文构建逻辑
提取的信息往往是原始的,必须经过预处理和组织结构:
- 摘要与压缩 :避免超过上下文窗口长度;
- 格式规范化 :如结构化 JSON、YAML、Markdown;
- 优先级排序 :重要内容靠前,控制 token 占比;
- 模板渲染 : 根据系统 prompt 模板将内容拼接组合;
- 过滤与去噪 :剔除冗余、无关或重复信息。
好的上下文不是“信息越多越好”,而是“信息越相关越有效”。
3. 动态调度机制
每次调用模型时,系统要根据任务内容和状态动态地选择构建哪些上下文,这依赖于:
- 用户当前意图识别;
- 调用历史和记忆状态;
- 所需外部工具的自动识别与加载;
- 对环境状态的感知(时间、空间、设备等);
上下文工程的核心价值,在于它能够让模型在“不同场景下,自动看见不同信息”。
4. 工具与系统接口整合
现代大模型系统通常需要配合工具调用、函数调用或插件能力。上下文工程要将这些工具:
- 声明在 prompt 中(让模型知道有哪些工具);
- 解释输入输出格式(通过 JSON schema 等);
- 组织调用结果并写回上下文(作为下一步的参考依据);
上下文工程让模型变得不仅“聪明”,而且“能动”。
与提示工程的区别与协同
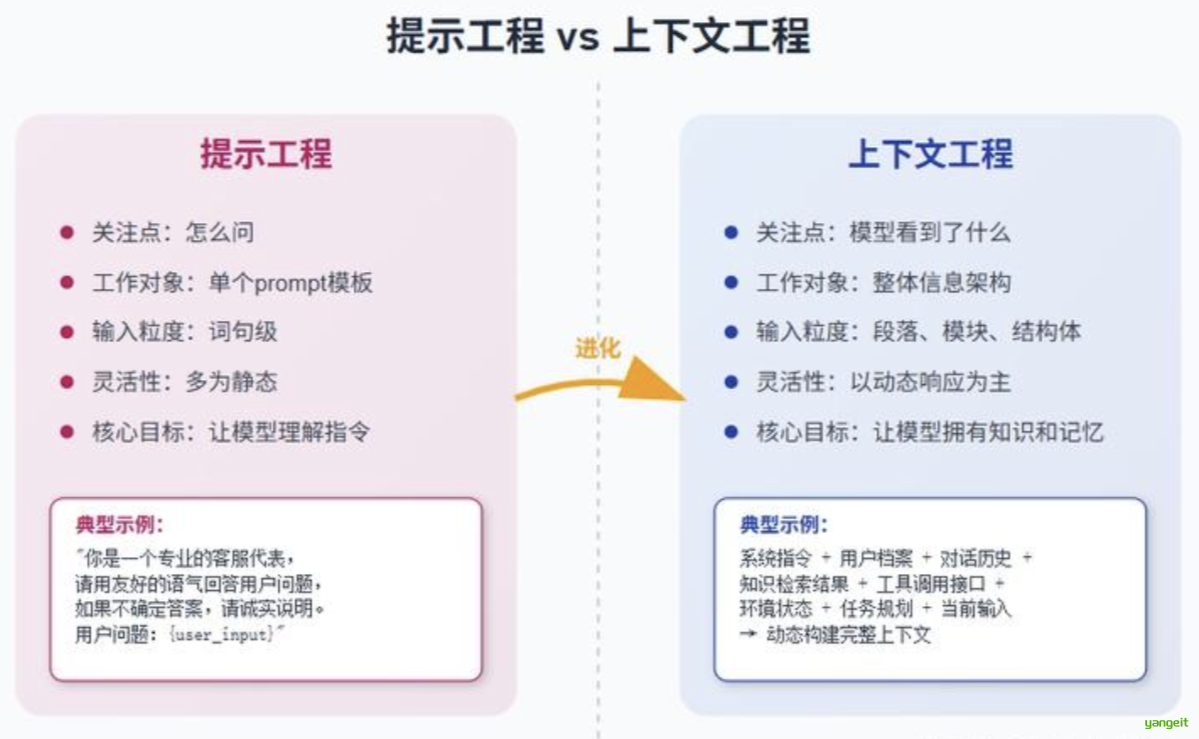
上下文工程包含并拓展了提示工程
3.典型应用案例
前言

1. 智能客服
通过上下文工程将用户历史问题、行为偏好、产品知识库等动态构建成输入,让客服机器人更懂用户。
2. 智能助理与 AI Agent
Agent 系统通过长期记忆模块、工具执行模块、规划器等构建复杂的上下文流,支撑多轮对话、任务拆解与执行。
Coze空间官网:https://space.coze.cn/space-intro
3. 文件与知识问答系统
在文档问答场景中,上下文工程调动检索模块找到相关段落,再进行压缩摘要,并插入到模型上下文,形成精准问答。
4. 多轮总结与报告生成
在会议纪要、法律文书等复杂任务中,通过“分段摘要 + 层级组织 + 长期记忆”构建上下文,实现长文控制和连贯性生成。
2.MCP
1.MCP 是什么
前言
What is MCP?
MCP 起源于 2024 年 11 月 25 日 Anthropic 发布的文章:Introducing the Model Context Protocol。

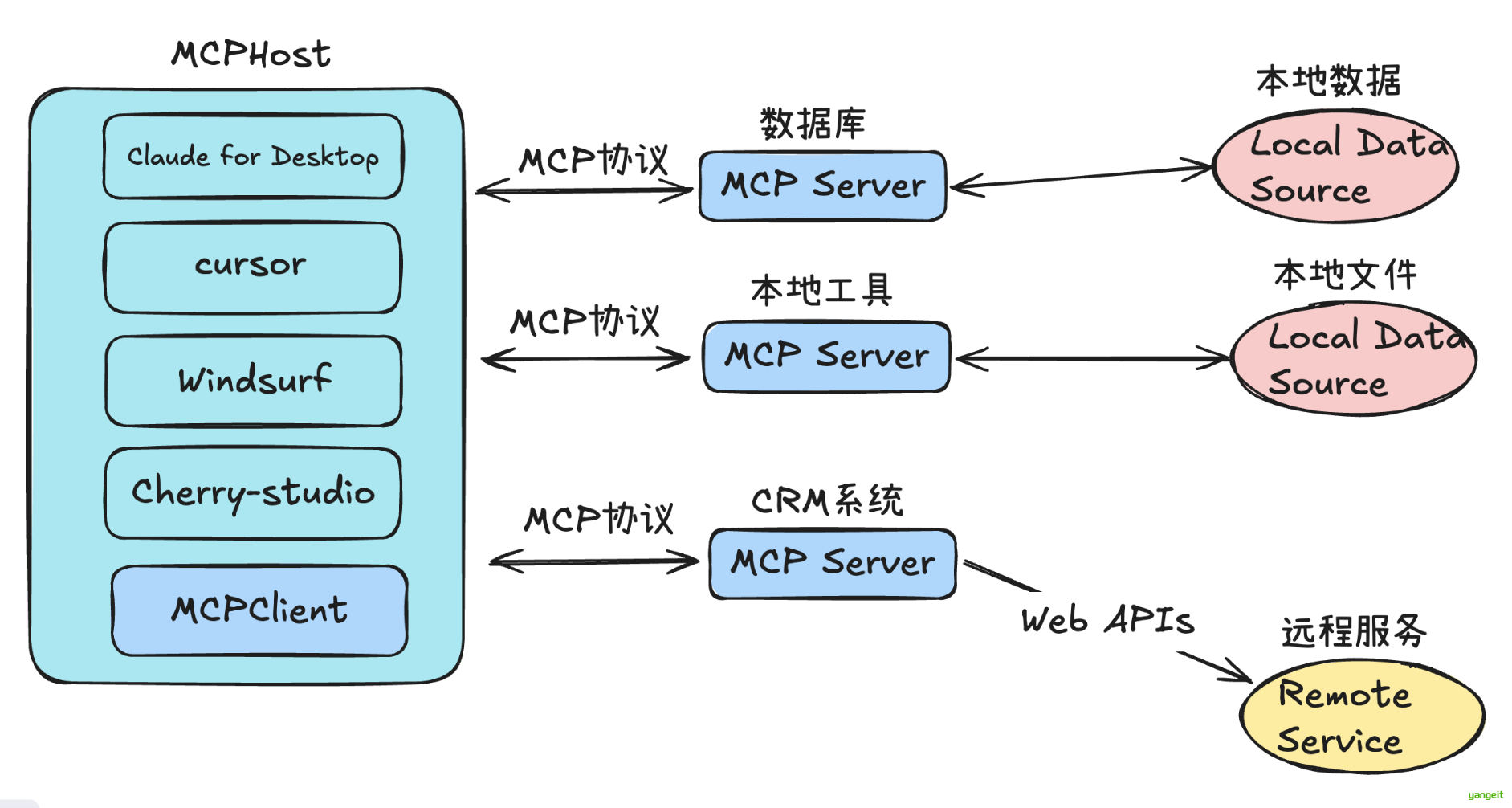
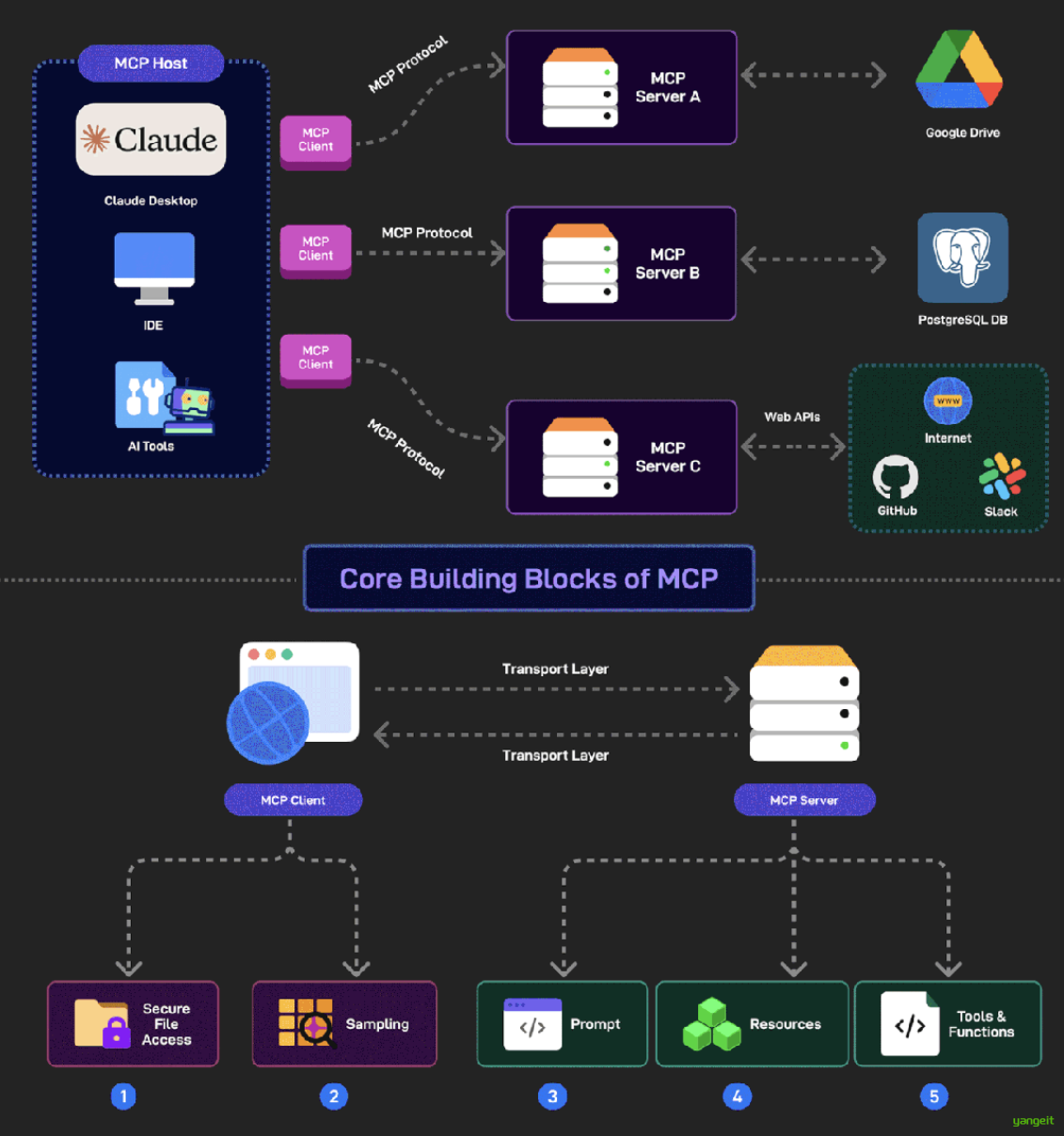
MCP (Model Context Protocol,模型上下文协议)定义了 应用程序和 AI 模型 之间交换上下文信息的方式。这使得开发者能够 以一致的方式将各种数据源、工具和功能连接到 AI 模型(一个中间协议层) ,就像 USB-C 让不同设备能够通过相同的接口连接一样。MCP 的目标是创建一个通用标准,使 AI 应用程序的开发和集成变得更加简单和统一。
所谓一图胜千言,这里引用一些制作的非常精良的图片来帮助理解:👇 👇 👇
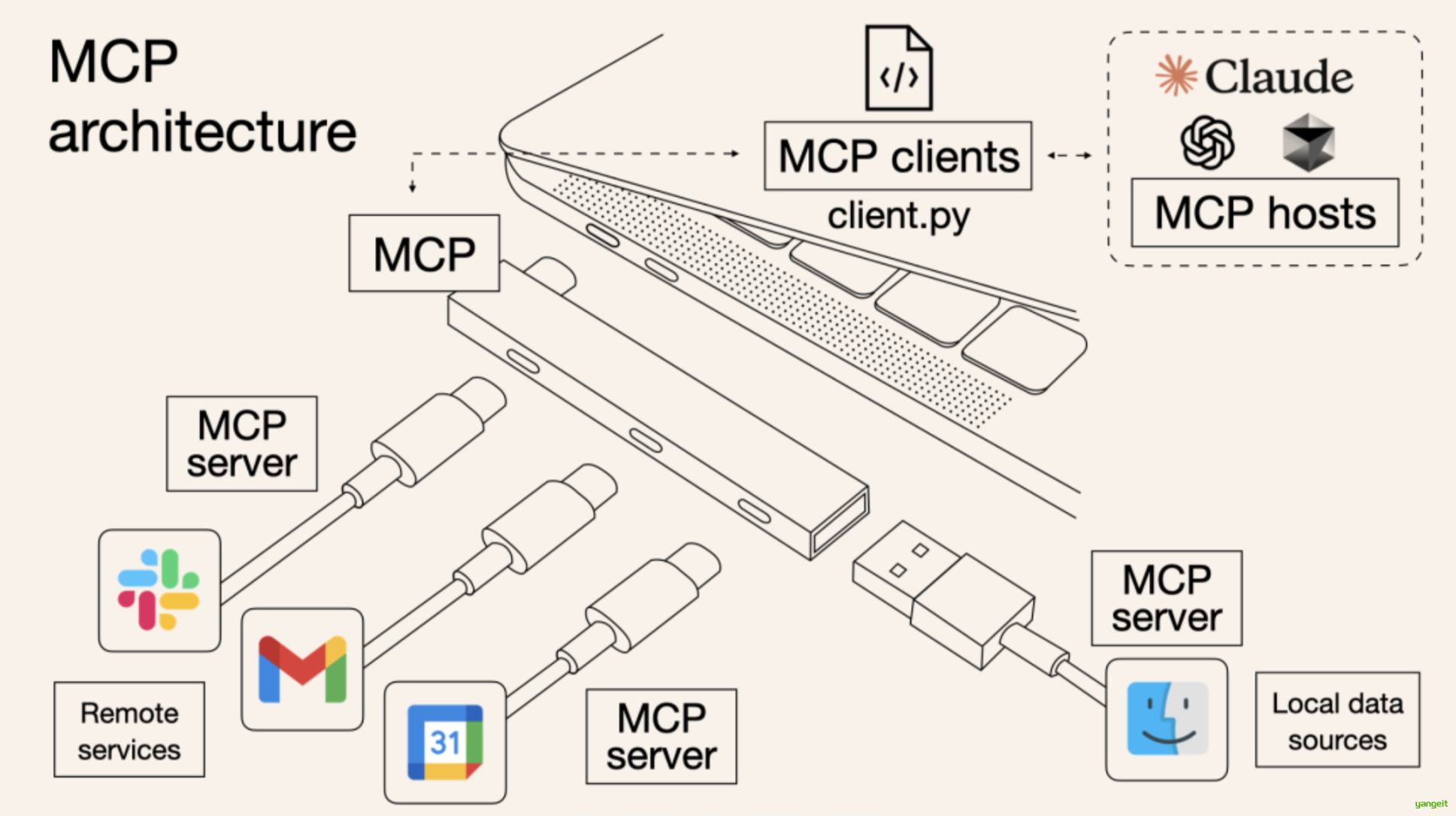
可以看出,MCP 就是以更标准的方式让 LLM Chat 使用不同工具,更简单的可视化如下图所示 👇,这样你应该更容易理解“中间协议层 ”的概念了。Anthropic 旨在实现 LLM Tool Call 的标准。
Anthropic是一家位于美国加州旧金山的人工智能股份有限公司,该公司由前OpenAI员工创建,旨在开发一种能够理解和生成人类语言的人工智能系统。该公司于2021年获得由Andreessen Horowitz领投的A轮融资,总融资额达到1.5亿美元。
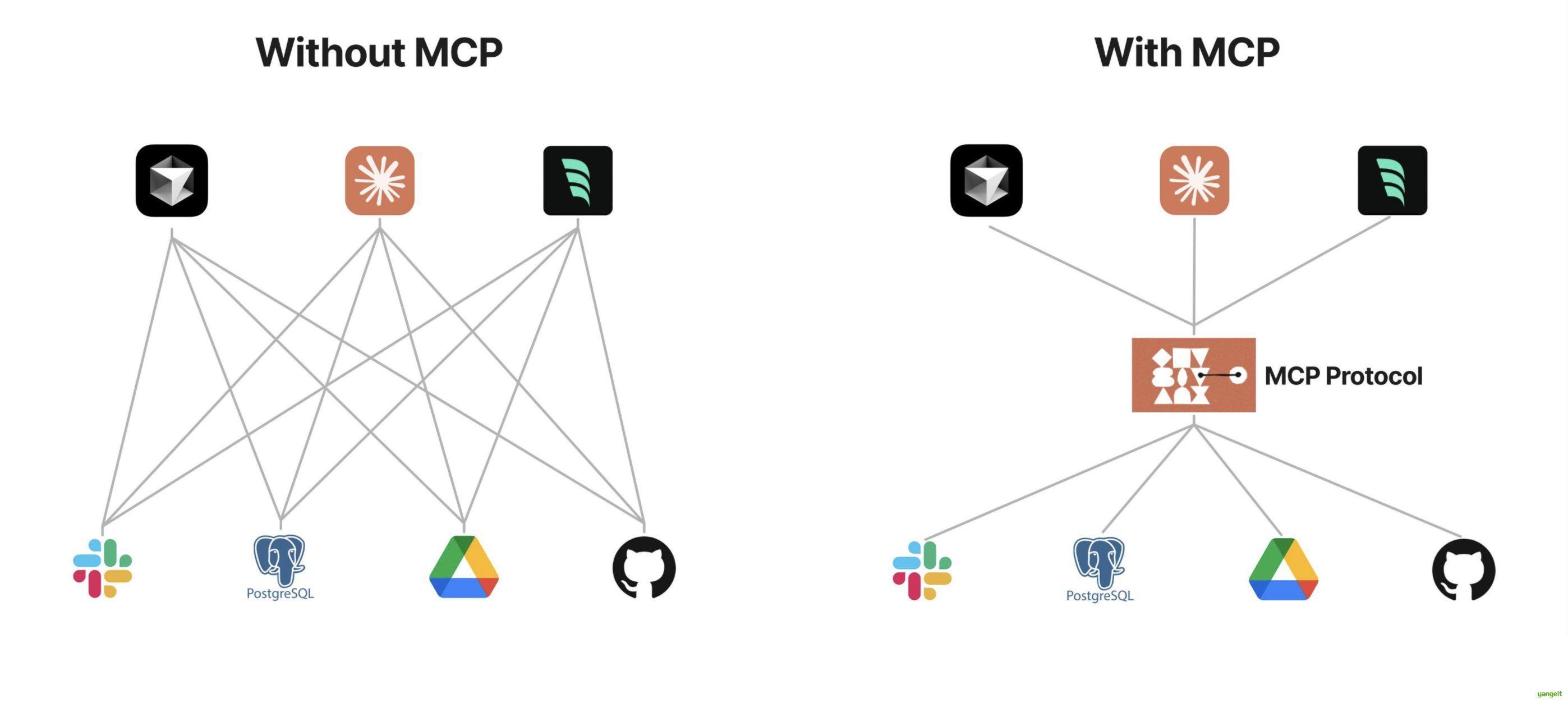
想象一下没有 MCP 之前我们会怎么做?
我们可能会人工从数据库中筛选或者使用工具检索可能需要的信息,手动的粘贴到 prompt 中。随着我们要解决的问题越来越复杂,手工把信息引入到 prompt 中会变得越来越困难。
为了克服手工 prompt 的局限性,许多 LLM 平台(如 OpenAI、Google)引入了 function call 功能。这一机制允许模型在需要时调用预定义的函数来获取数据或执行操作,显著提升了自动化水平。
但是 function call 也有其局限性, function call 平台依赖性强,不同 LLM 平台的 function call API 实现差异较大。例如,OpenAI 的函数调用方式与 Google 的不兼容,开发者在切换模型时需要重写代码,增加了适配成本。除此之外,还有安全性,交互性等问题。
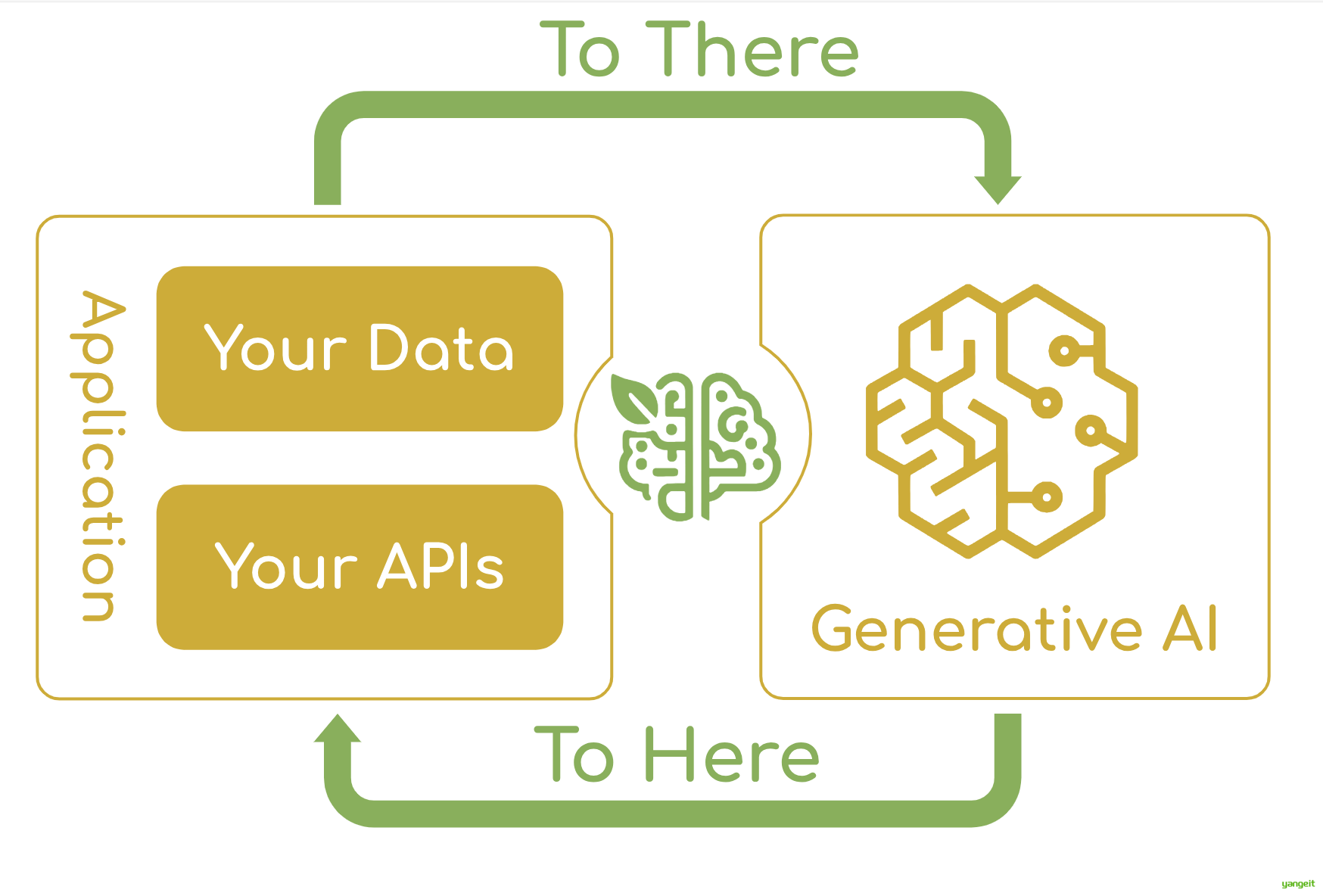
数据与工具本身是客观存在的, 只不过我们希望将数据连接到模型的这个环节可以更智能更统一。Anthropic 基于这样的痛点设计了 MCP,充当 AI 模型的"万能转接头",让 LLM 能轻松的获取数据或者调用工具。更具体的说 MCP 的优势在于:
- 生态 - MCP 提供很多现成的插件,你的 AI 可以直接使用。
- 统一性 - 不限制于特定的 AI 模型,任何支持 MCP 的模型都可以灵活切换。
- 数据安全 - 你的敏感数据留在自己的电脑上,不必全部上传。(因为我们可以自行设计接口确定传输哪些数据)
2.MCP 如何使用
前言
用户如何使用 MCP?
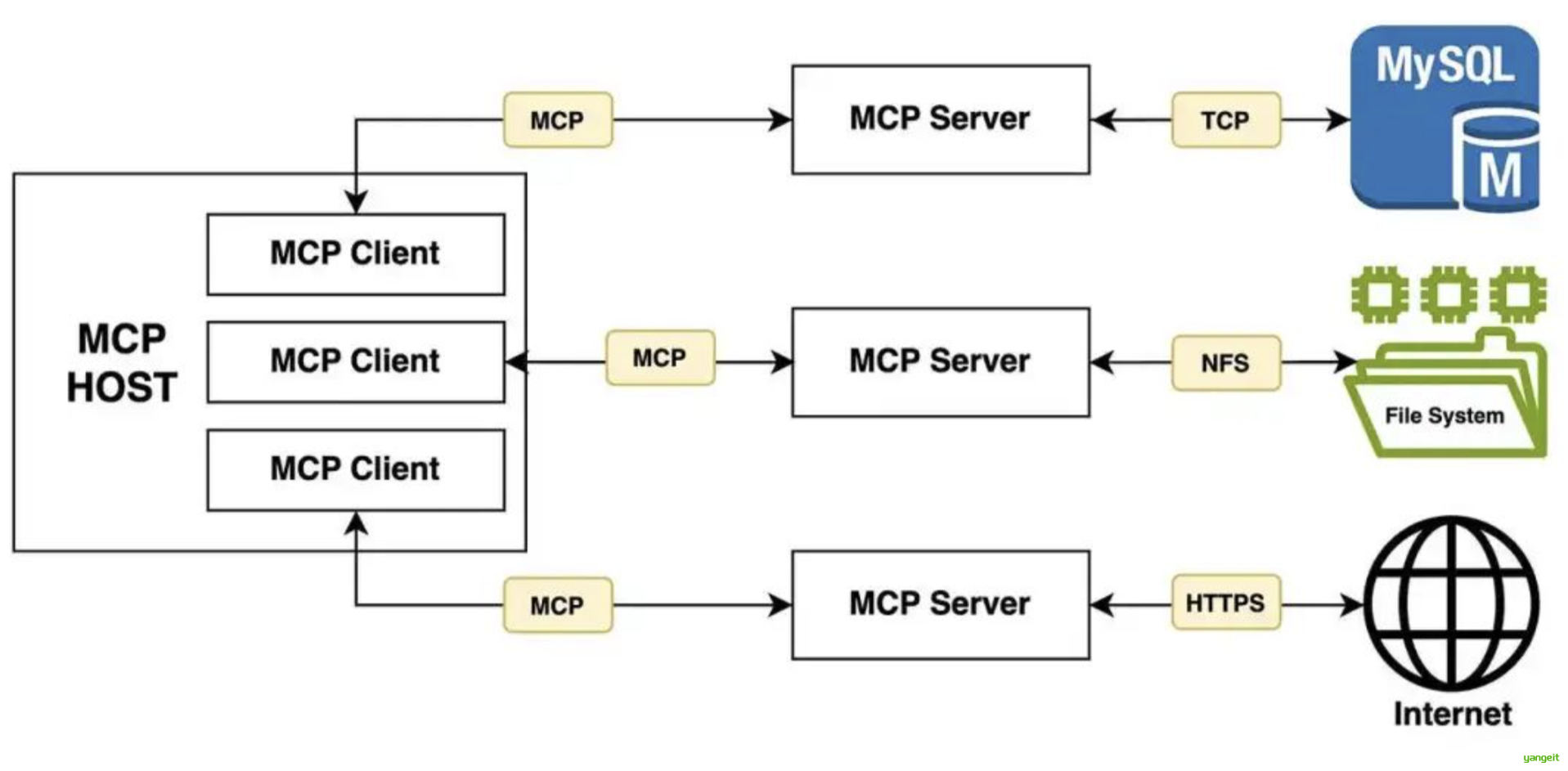
对于用户来说,我们并不关心 MCP 是如何实现的,通常我们只考虑如何更简单的用上这一特性---MCP如何与Agent进行结合?
Agent作为一个MCP Client(客户端),通过MCP协议与MCP Server(服务器)进行通信。
在 Visual Studio Code (VSCode) 中连接 MCP(Model Context Protocol)服务器,可以扩展编辑器功能,实现文件操作、API 调用等任务。
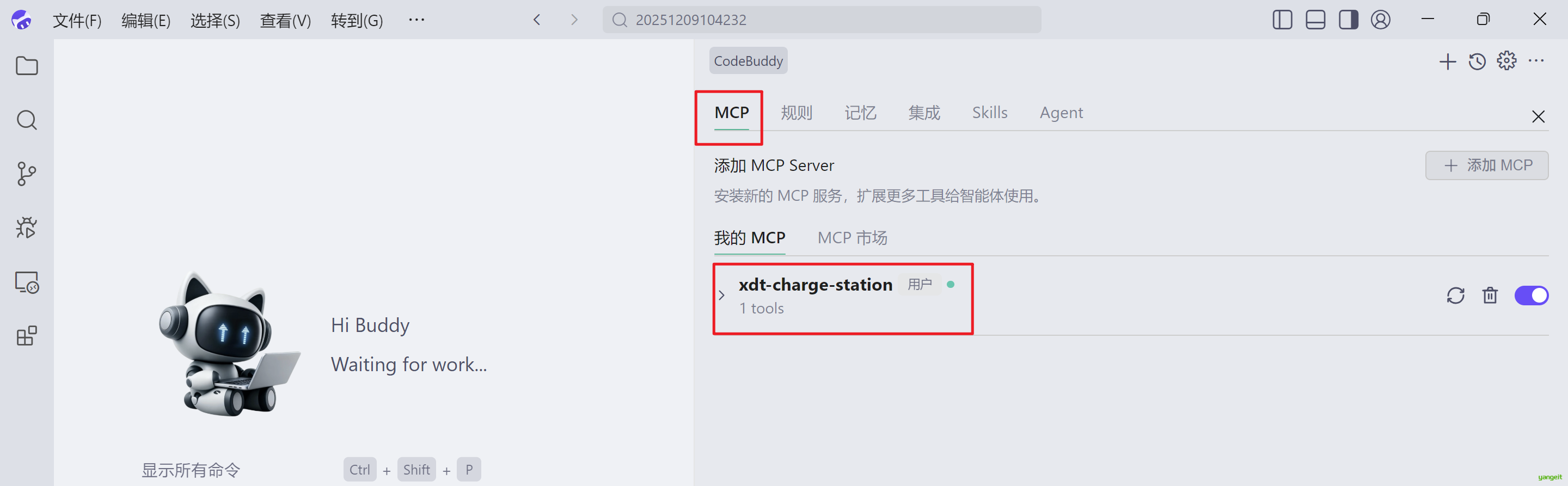
在腾讯的CodeBuddy中连接 MCP(Model Context Protocol)服务器,可以扩展编辑器功能,实现文件操作、API 调用等任务。
Coze中发布和调用MCP
这里为了方便演示MCP,我们采用Coze平台进行演示。
MCP(Model-as-a-Plugin) 是扣子空间实现能力无限拓展的关键。通过 MCP 的扩展集成,扣子空间可以调用各种外部工具和服务,从而无限拓展其 Agent 的能力边界。
Coze空间官网:https://space.coze.cn/space-intro
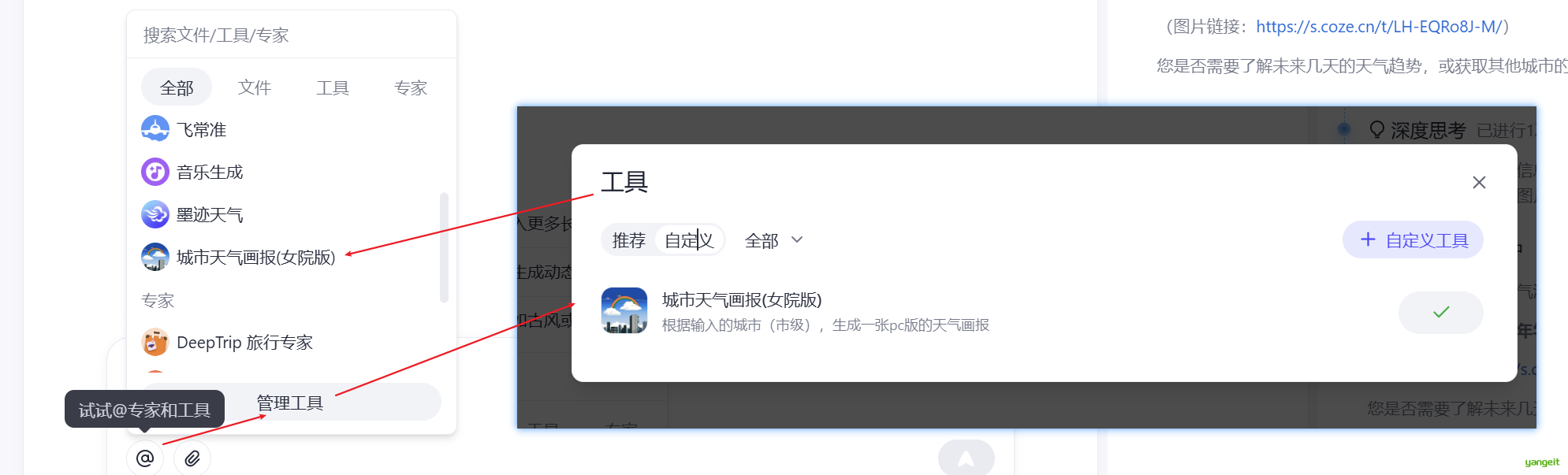
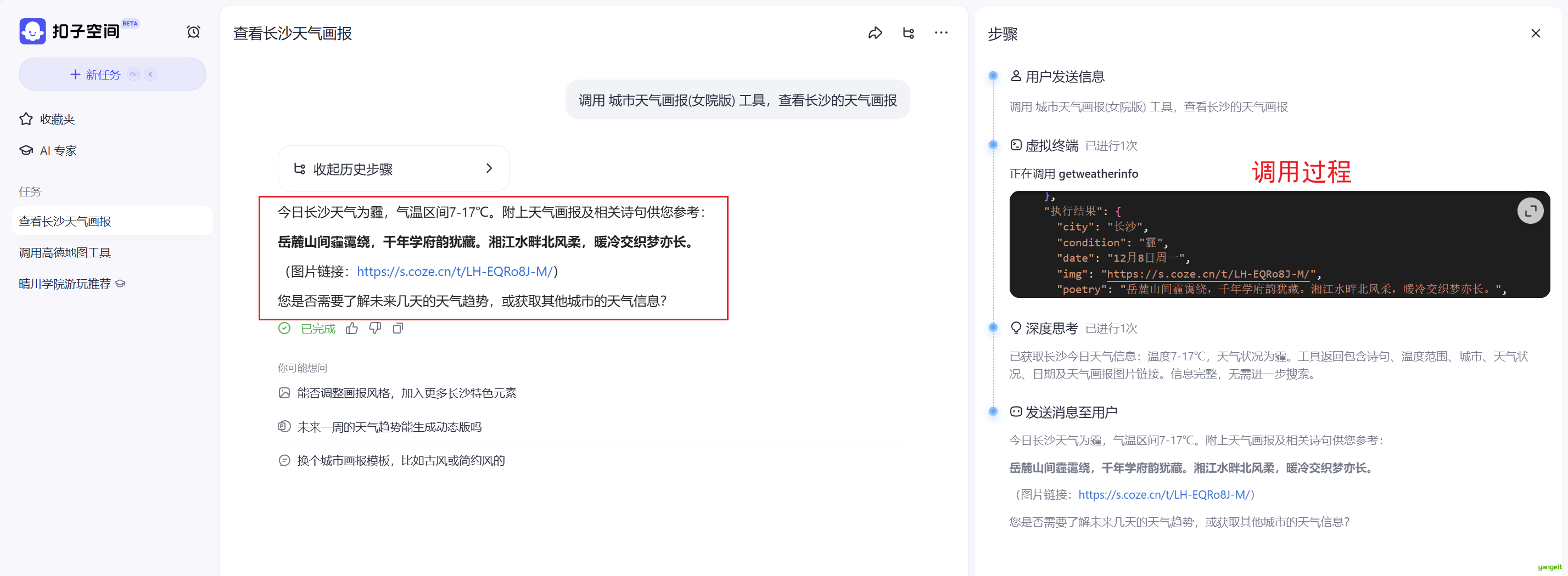
- 将之前做过的Coze应用
城市天气画报发布为MCP服务
- Coze空间的对话框中,就可以调用,我们刚刚发布的MCP服务了。