
第一天 Python基础回顾与大模型、LangChain入门
本日学习目标
- 补齐学习 LangChain 必备的 Python 基础语法。
- 建立对大语言模型、提示词、LangChain 的整体认知。
- 完成 Python 3.13 + 虚拟环境 + LangChain 基础依赖安装。
- 独立跑通第一个 LangChain 示例程序。
1. 大模型简介
前言
1.1 什么是大语言模型
大语言模型,英文通常写作 LLM,本质上是一个“根据上下文预测下一个词”的概率模型。它通过海量文本训练,学会了语言规律、知识模式和一定的推理能力。
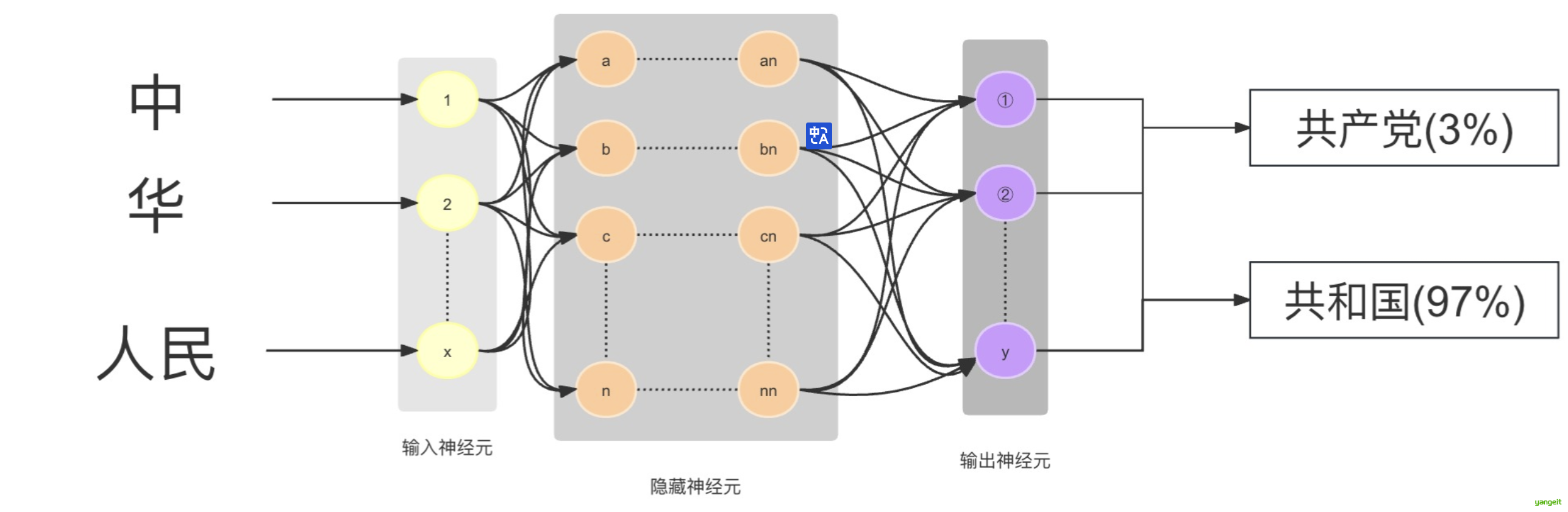
比如我们问将“中 华 人民 ”输入进去后,请大模型补充完整,可以想象是分散在整个网络中的十亿、上百亿参数依靠神经元相互连接,顺着这种连接就找到了下一个连接的词,然后给出概率,比如“共和国(97%) ”,就形成了“中华人民共和国”的完整句子。然后继续将“中华人民共和国”作为输入,继续依·靠神经元相互连接,顺着这种连接就找到了下一个连接的词,然后给出概率,比如“中华人民共和国 成立于1949年(98%) ”.
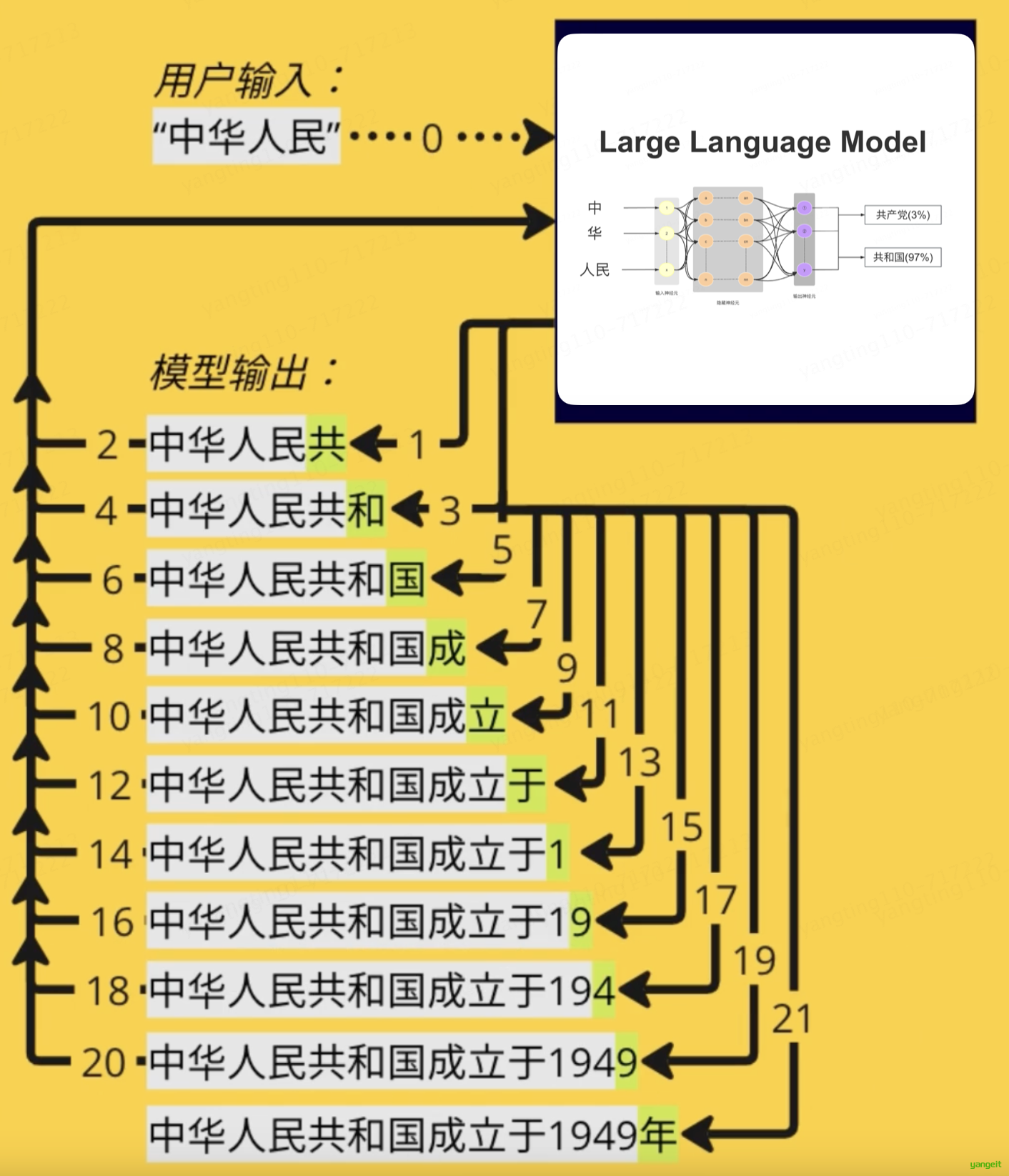
简单理解:
用户输入问题 -> 模型理解上下文 -> 逐步预测下一个词 -> 拼成完整回答1.2 大模型的核心能力
- 文本生成 :写文章、写总结、写邮件、写代码注释。
- 文本理解 :分类、提取、情感分析、关键词抽取。
- 推理能力 :做步骤分析、方案比较、错误定位。
- 多轮对话 :结合上下文连续交流。
1.3 大模型的核心特点
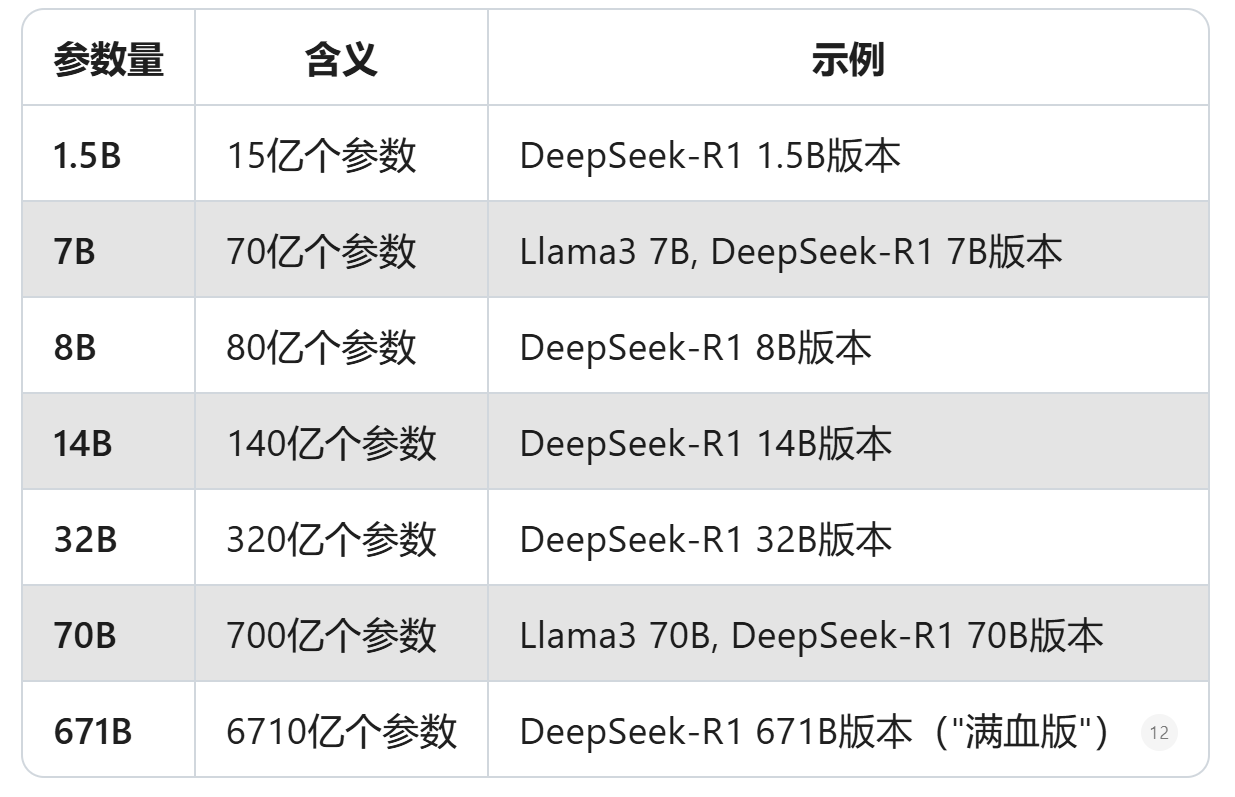
- 参数量巨大:从1.5B到671B不等
- 自监督学习:无需人工标注数据
- 多任务能力:文本生成、问答、翻译、编程等
- 上下文理解:能够理解长文本的语义
2. 参数量解析:1.5B、7B、14B...到底是什么意思?
B = Billion(十亿),这是国际通用的参数量表示方式。
1.4 大模型的局限性
不要把大模型理解成“绝对正确的搜索引擎 ”,它有明显边界:
- 可能出现幻觉,也就是“看起来很合理,但实际上是错的”。
- 对最新知识未必知道。
- 不同提问方式会直接影响回答质量。
- 没有外部工具和检索时,它只能依赖训练时学到的内容。
1.5 什么是提示词工程(Prompt Engineering)?
1.5.1 从技术视角看:提示词是模型的“上下文起点”
从大型语言模型的技术原理出发,提示词的本质是输入给模型的一串文本序列(Token Sequence)。
LLM的核心任务是“序列补全”或“下一个词元预测 ”(Next Token Prediction)。无论模型看起来是在回答问题、翻译文本还是创作诗歌,其底层机制都是在计算给定一串文本(即提示词)后,下一个最可能出现的文本序列是什么。
- 词元(Token):模型处理文本的基本单位。它可能是一个完整的单词(如 "apple"),也可能是一个词根、词缀或标点符号(如 "un-", "-ing", ",")。例如,句子 "I love prompt engineering" 可能会被分解为 "I", "love", "prompt", "engineer", "-ing" 这几个词元。
- 上下文(Context):您输入的提示词,构成了模型进行预测的全部初始信息。模型会将其转化为一个高维度的数学向量(Embedding),这个向量代表了提示词的语义信息。
- 预测过程:模型内部的Transformer架构通过其复杂的注意力机制 (Attention Mechanism 如下图),分析提示词向量中各个词元之间的关系和重要性,然后基于其在海量数据中学到的模式,生成一个概率分布,预测出最有可能紧随其后的词元。这个过程会不断重复,新生成的词元又会成为下一步预测的上下文的一部分,直到生成完整的回答或达到终止条件。
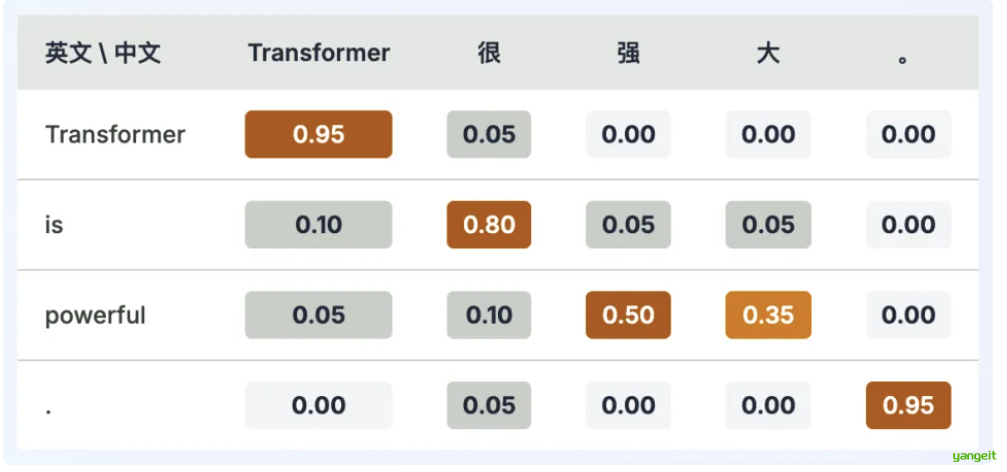
注:颜色越深表示注意力权重越大,数值代表注意力权重的概率分布
1.5.2 从用户视角看:提示词是与AI协作的“任务说明书
提示工程也叫「指令工程」
- Prompt 就是你发给大模型的指令,比如「讲个笑话」、「用 Python 编个贪吃蛇游戏」、「给男/女朋友写封情书」等
- 貌似简单,但意义非凡
- 「Prompt」是 AGI时代的「编程语言」
- 「Prompt 工程」是 AGI 时代的「软件工程」
- 「提示工程师」是 AGI时代的「程序员」
- 学会提示工程,就像学用鼠标、键盘一样,是 AGI时代的基本技能。
- 提示工程也是「门槛低,天花板高」,所以有人戏称 prompt 为 提示词工程师
- 但专门的「提示工程师」不会长久,因为每个人都要会「提示词」会让提示工程越来越简单1.6 主流模型与学习建议
课程学习阶段你不必纠结“哪个模型最强”,先理解三件事:
- 模型都有自己的接口规范和参数。
阿里云大模型列表:https://help.aliyun.com/zh/model-studio/models
硅基大模型列表:https://docs.siliconflow.com/quickstart/models
baseurl: http://doumi.luawool.com # 模型接口地址
key: sk-DPKguZcArqW9qE2JxFAggoPgnUEgZ2rj0DYEEpVh17G8 # 模型密钥
modelid:qwen-plus # 模型名称很多平台提供兼容 OpenAI 的调用方式。
LangChain 的价值就在于:帮你把这些差异封装起来,统一组织调用流程。
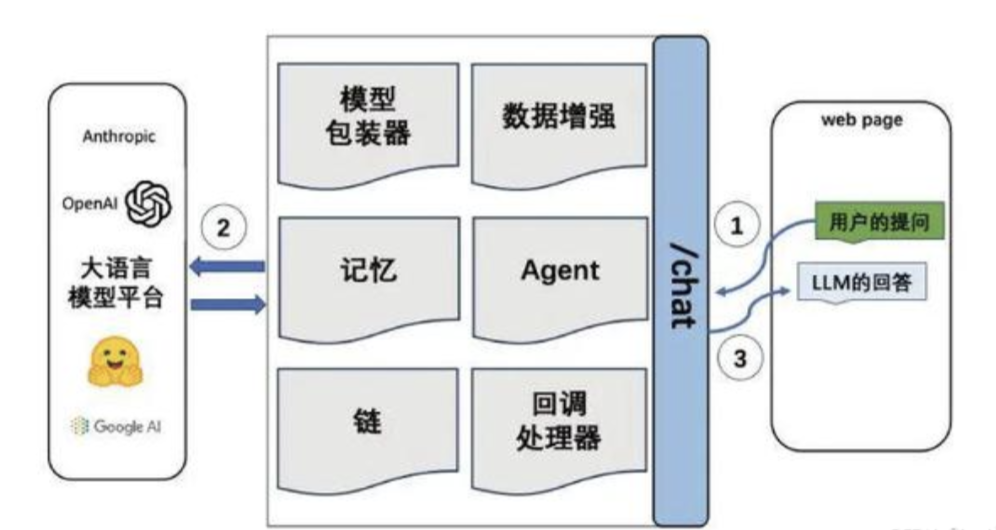
2. LangChain 是什么
前言
2.1 一句话理解

LangChain 是一个帮助我们开发大模型应用的框架,它把提示词、模型、输出解析、检索、工作流等能力组合起来,让“调用模型”变成“搭建应用”。
2.2 为什么需要 LangChain
如果只调用一次模型,直接写 API 也可以。但真实项目往往是这样的:
用户问题 -> 提示词模板 -> 模型调用 -> 输出解析 -> 数据校验 -> 检索文档 -> 再次生成 -> 返回结果当流程变复杂以后,如果没有框架,代码会很乱 。
LangChain 的作用就是:👈
- 统一组件组织方式。
- 让模型调用更模块化。
- 方便后续扩展 RAG、Agent、工具调用。
- 让代码更适合复用与维护。
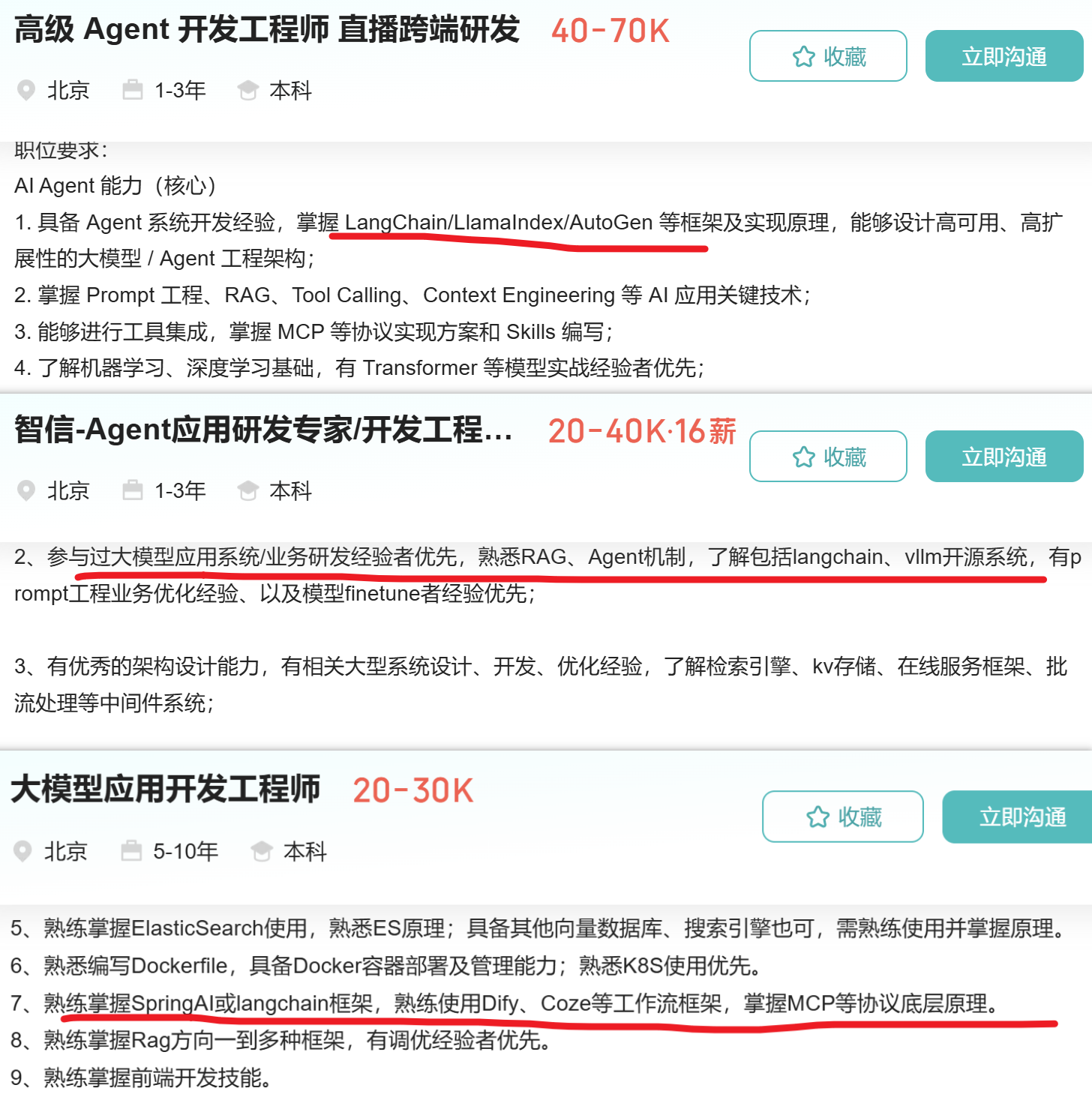
学会了langchain,找工作或者换工作,都是非常硬的技能点。
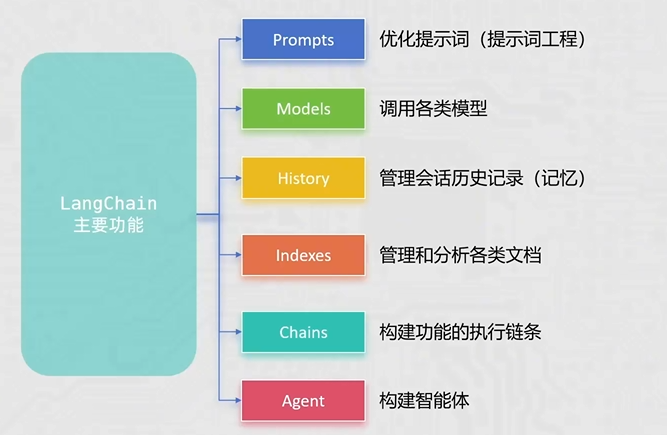
2.3 LangChain核心组件
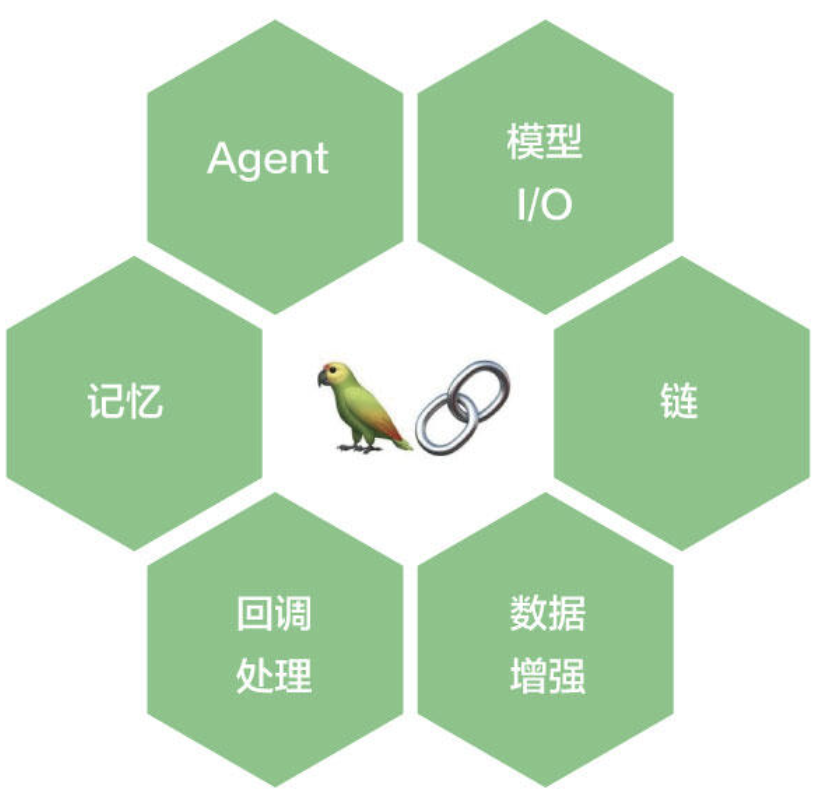
Prompt:提示词。Model:大模型。Output Parser:输出解析器。Chain:把多个步骤连起来。Memory:让对话保留上下文。Retriever:从知识库里找相关内容。Vector Store:保存向量数据,支持相似度检索。Agent / Tools:让模型会“调用工具”。
2.4 典型应用场景
- 智能客服
- 文档问答
- 读书笔记助手
- 内容生成助手
- 代码解释与开发辅助
3. 开发环境搭建
前言
安装以下软件:
- ✅Python 3.13
- ✅pip
- ✅PyCharm
3.1.安装 Python 3.13
- 下载 Python 3.13 安装包:https://www.python.org/downloads/windows/
- 双击下载好的安装包
- ⚠️ 务必勾选底部的两个选项:
- ✅ Add python.exe to PATH(添加到系统环境变量)
- ✅ Install launcher for all users(推荐)
- 点击 "Install Now"(立即安装),等待安装完成(约 3-5 分钟)
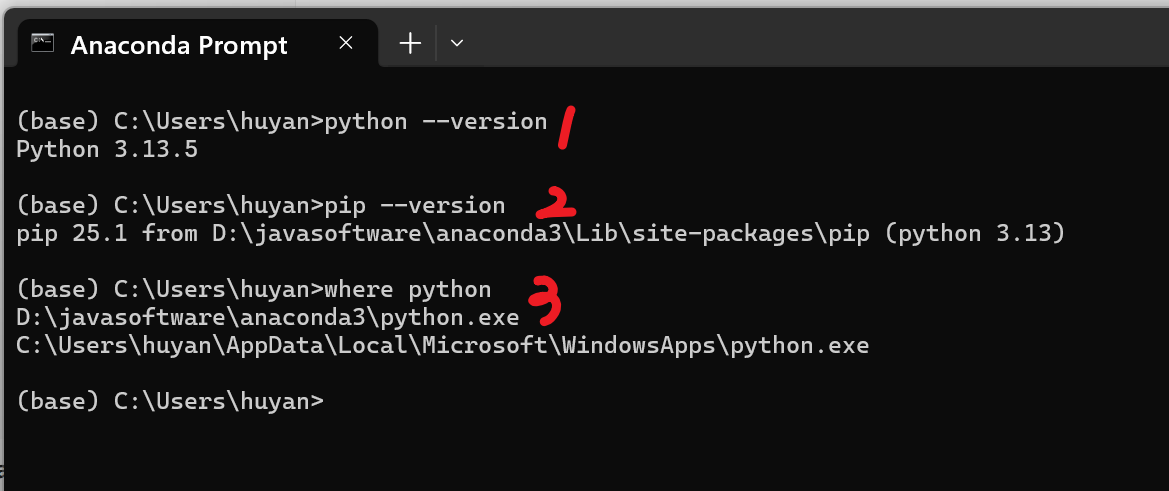
- 按下键盘Win+R组合键,输入cmd,点击 "确定" 打开命令提示符,输入以下三个命令:
python --version # 查看Python版本,应显示Python 3.10.15
pip --version # 查看pip版本,应显示pip 23.0.1及以上
where python # 查看Python安装路径,确认有多个路径(说明环境变量已配置)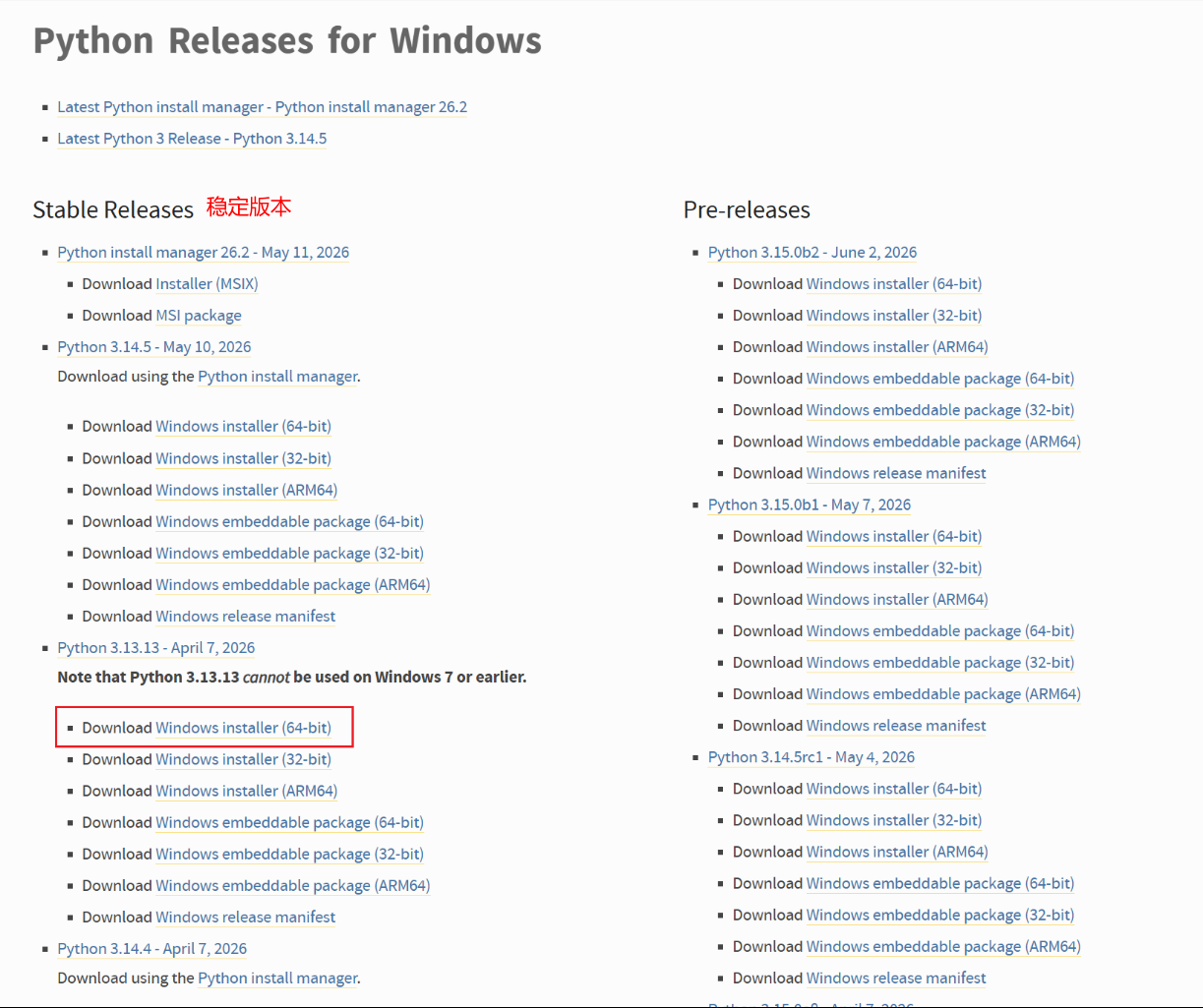
3.2.安装 PyCharm
这里选择社区版,因为它免费,功能够用。
- 打开浏览器访问 PyCharm 官方下载页:https://www.jetbrains.com/pycharm/download/
- 向下滚动找到Community(社区版),点击对应系统的 "Download" 按钮
- 双击下载好的安装包,一路点击 "Next"(下一步),直到看到 "Finish"(完成)按钮,点击即可
- 新建 LangChain 实训项目并配置 Python 环境(这里强烈建议使用虚拟环境,避免依赖冲突)
新建项目步骤如下:
- 打开 PyCharm,点击 "Create New Project"(创建新项目)
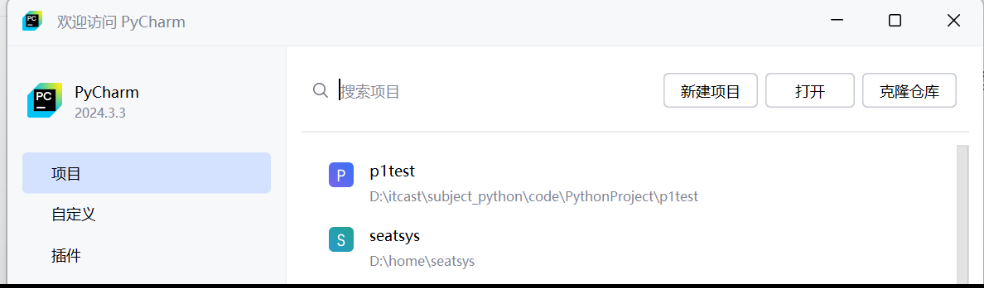
- 配置虚拟环境
- 验证环境配置是否成功
- 项目创建完成后,在左侧项目结构中可以看到venv文件夹(这就是虚拟环境)
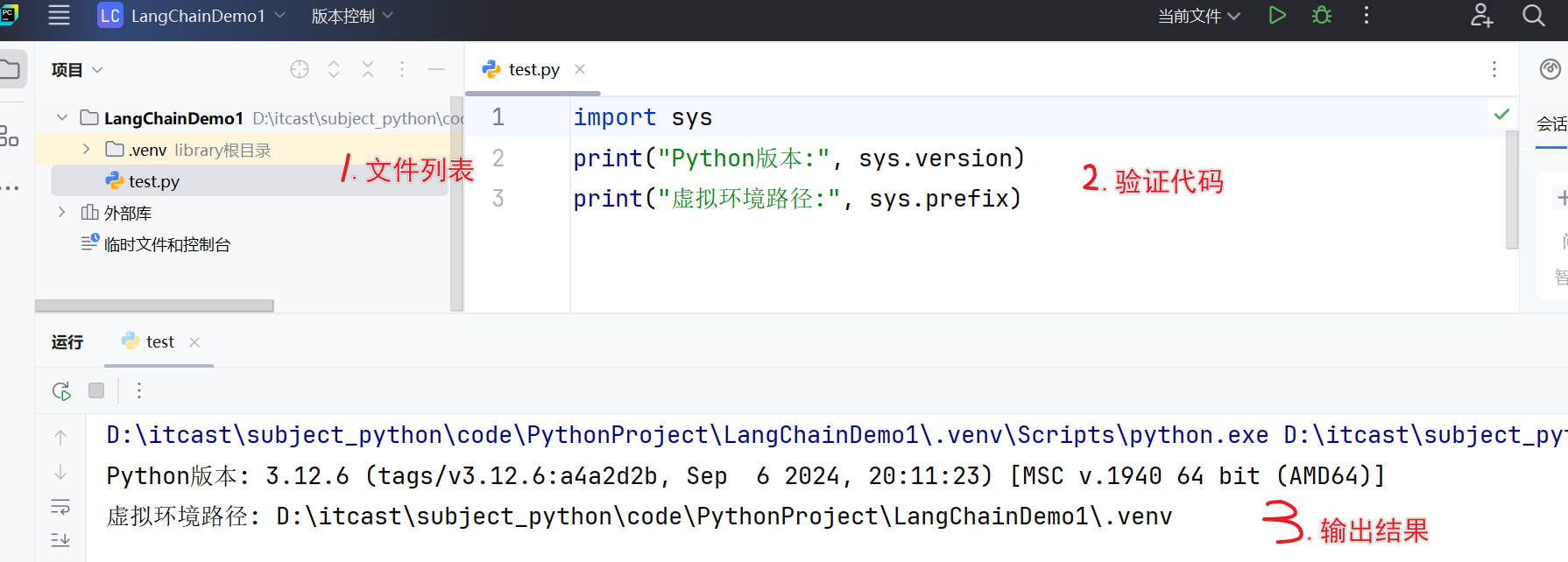
- 右键点击项目名称→"New"→"Python File",命名为test.py
- 在文件中输入以下代码:
import sys print("Python版本:", sys.version) print("虚拟环境路径:", sys.prefix)- 运行test.py文件,如果输出Python版本和虚拟环境路径,则说明环境配置成功
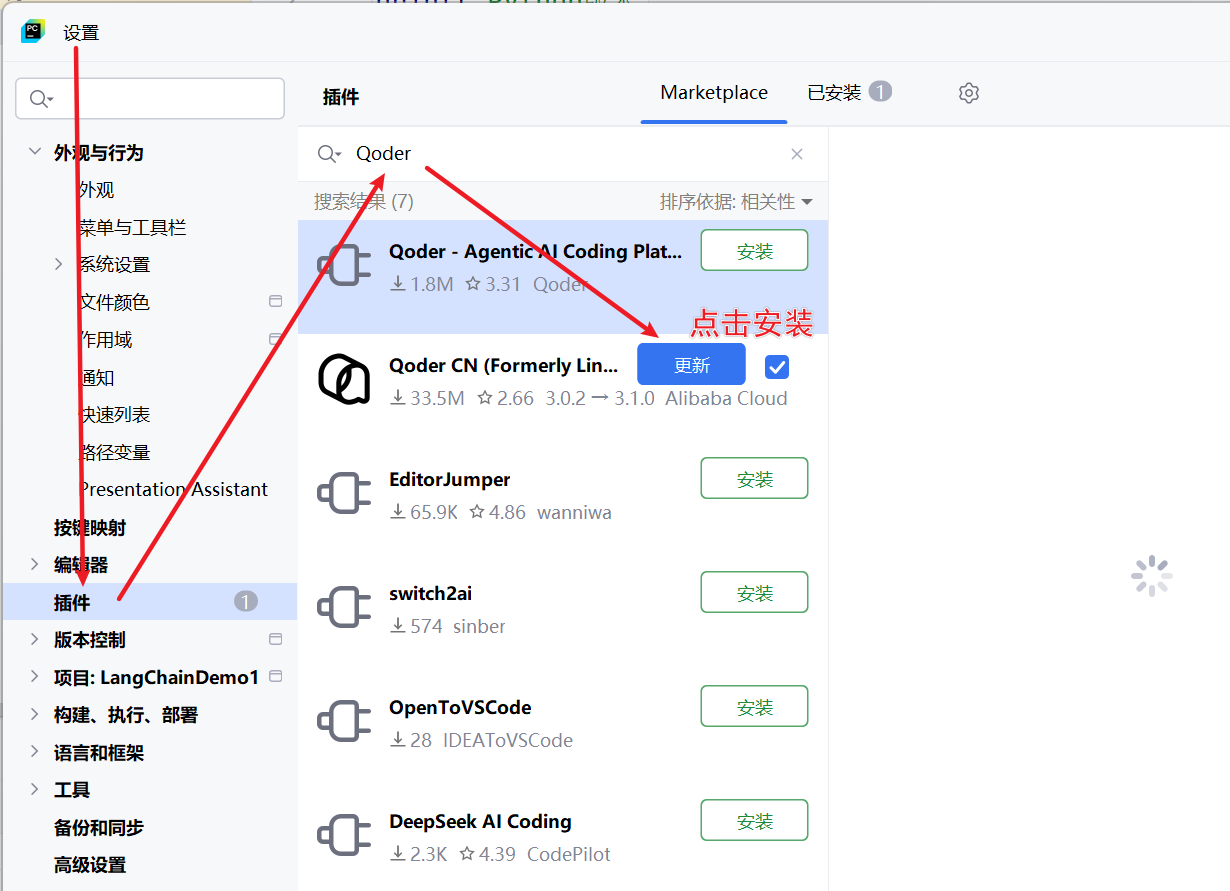
3.3.安装QoderCN插件
安装QoderCN插件,可以实现AI自动补全代码,提高开发效率。
4. LangChain 项目入门
前言
上面已经创建好了一个 LangChain 空项目,接下来我们开始编写第一个 LangChain 程序。在书写程序钱,需要安装一些依赖库。
PyCharm 内置了终端,可以直接在里面安装所有依赖包,无需切换到系统命令行
4.1 安装课程常用依赖
pip install langchain langchain-community langchain-ollama langchain-chroma dashscope chromadb bs4 jq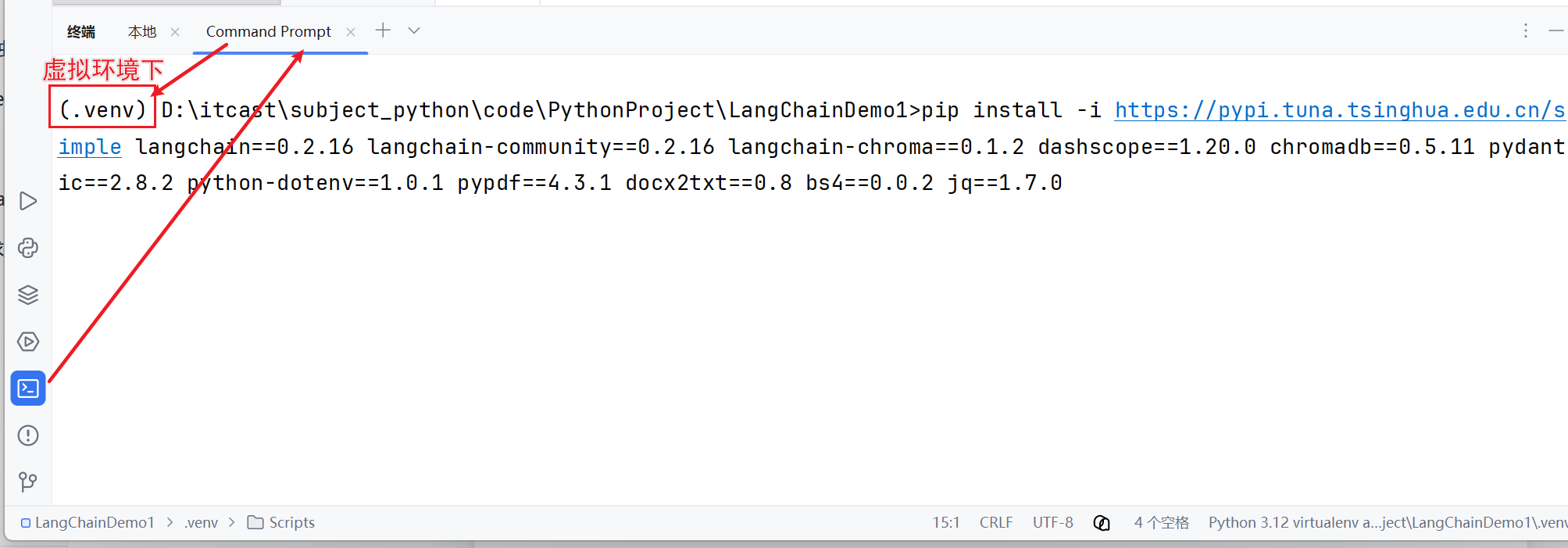
说明:
langchain:主框架。langchain-core:核心组件。langchain-openai:兼容 OpenAI 风格的模型接入。langchain-community:社区扩展组件。langchain-chroma:Chroma 向量库集成。langchain-text-splitters:后续做文本切分用。python-dotenv:读取.env环境变量文件。pypdf、docx2txt:后续做文档加载用。
验证代码:
import sys
print("Python版本:", sys.version)
print("虚拟环境路径:", sys.prefix)
import sys
import langchain
import chromadb
import dashscope
print(f"Python版本: {sys.version.split()[0]}")
print(f"LangChain版本: {langchain.__version__}")
print(f"ChromaDB版本: {chromadb.__version__}")
print("所有依赖安装成功!")结果:
Python版本: 3.12.6 (tags/v3.12.6:a4a2d2b, Sep 6 2024, 20:11:23) [MSC v.1940 64 bit (AMD64)]
虚拟环境路径: D:\itcast\subject_python\code\PythonProject\LangChainDemo1\.venv
Python版本: 3.12.6
LangChain版本: 1.3.4
ChromaDB版本: 1.5.9
DashScope版本: <module 'dashscope' from 'D:\\itcast\\subject_python\\code\\PythonProject\\LangChainDemo1\\.venv\\Lib\\site-packages\\dashscope\\__init__.py'>
所有依赖安装成功!4.2 配置环境变量
新建 .env 文件:
OPENAI_API_KEY=你的模型密钥
OPENAI_BASE_URL=你的模型接口地址
OPENAI_MODEL=qwen-plus说明:
- 如果你使用的是兼容 OpenAI 协议的平台,这种写法通常适用。
- 不同平台参数名可能不同,但课程学习阶段建议统一这种配置思路。
接下来,获取tongyi的模型密钥和接口地址:
- 打开浏览器,访问:https://bailian.console.aliyun.com/cn-beijing?tab=model#/model-market/(阿里云百炼 DashScope)
- 获取模型密钥和接口地址:
OPENAI_API_KEY=sk-0b68751a0e06497cccccc91db9cc1
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_MODEL=qwen3.7-plus4.3 先理解最小闭环
第一个程序一定要简单,目标只有一个:
准备模型配置 -> 发送提示词 -> 拿到返回结果 -> 打印输出4.4 Hello LangChain
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
load_dotenv() #把 `.env` 里的变量加载到当前程序环境中。
model = ChatOpenAI( #初始化聊天模型对象
model=os.getenv("OPENAI_MODEL", "qwen-plus"),
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL"),
temperature=0.7 #控制模型生成内容的随机性,0.7 表示随机性较高
)
response = model.invoke([ #发送一次请求给模型
HumanMessage(content="请你用100字以内介绍一下你自己。")
])
print(response.content) #取出模型返回的正文内容运行结果:
湖北工程学院位于湖北孝感,是一所公办普通本科院校。
学校始建于1943年,以工学为主,多学科协调发展。
学校秉承“严以治学、诚以立身”校训,致力于培养高素质应用型人才。invoke:会卡顿一下,然后出结果;如果要流式输出,可以用
stream方法。
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 加载环境变量
load_dotenv()
# 初始化模型(和你之前一模一样)
model = ChatOpenAI(
model=os.getenv("OPENAI_MODEL", "qwen-plus"),
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL"),
temperature=0.7,
streaming=True, # 开启流式
)
# 流式调用
for chunk in model.stream([
HumanMessage(content="请你用100字介绍一下人工智能。")
]):
# 逐字打印,不换行
print(chunk.content, end="", flush=True)输出的结果会逐字打印,而不是一次性输出完整内容。
总结
练习:让模型写一首春天的小诗
response = model.invoke([
HumanMessage(content="请写一首关于春天的四行小诗,语言清新自然。") #HumanMessage:人类消息
])
print(response.content)5. Python基础回顾
很多同学一看到 LangChain 就会直接找现成代码,但这样通常会卡在两个地方:
Python 语法不熟,看得懂一行,连不起来整体逻辑。不知道 LangChain 解决什么问题,代码抄完也不知道为什么这么写。
所以第一天的任务不是“堆很多高级 API”,而是把最基础的地基打稳。
大模型基础认知 -> LangChain作用理解 -> 环境搭建 -> Hello LangChain-> 回顾Python基础前言
配套素材:students.json
[
{"name": "张三", "age": 18, "score": 92},
{"name": "李四", "age": 19, "score": 88}
]在当前目录下创建一个 students.json 文件,内容如上。
5.1 变量与命名
新建 python_review.py,开始回顾Python基础语法
# ==============================================
# LangChain 实训课前 Python 快速复习
# 涵盖:变量、数据类型、列表、字典、函数、循环、文件、异常
# ==============================================
# -------------------- 2.1 变量与命名 --------------------
#
name = "张三"
age = 18
score = 92.5
is_pass = True
# 正确命名
student_name = "小明"
python_score = 88
# -------------------- 2.2 常见数据类型 --------------------
# 字符串 str
title = "LangChain入门"
text = "hello langchain"
print(text.upper())
print(text[0:5])
print(f"我正在学:{title}")
# 数字
count = 10
price = 19.9
# 列表 list 列表适合存放“一组有顺序的数据”。
students = ["张三", "李四", "王五"]
students.append("赵六")
print("学生列表:", students)
# 字典 dict 字典适合存放“键值对数据”,非常适合表示一条完整的信息。
student = {
"name": "张三",
"age": 18,
"score": 95
}
print("学生姓名:", student["name"])
# -------------------- 2.3 运算 --------------------
# 算术运算,比较运算,逻辑运算
a = 10
b = 3
print(a + b)
print(a // b) # 整除
print(a > 5) # True练习案例:学生信息管理
同时用到了变量、列表、字典、遍历和修改操作
students = [
{"name": "张三", "age": 18, "score": 92},
{"name": "李四", "age": 19, "score": 88},
{"name": "王五", "age": 18, "score": 95}
]
# 修改学生信息
students[1]["age"] = 20
# 输出所有学生姓名和年龄
for student in students:
print(f"姓名:{student['name']},年龄:{student['age']}")5.2 函数,条件判断,循环
# -------------------- 2.5 函数 --------------------
#函数就是把一段功能封装起来,后面要反复调用时直接使用。
def say_hello(name="小明"): #函数定义,name是参数,默认值是“小明”
return f"你好,{name}"
print(say_hello("小红"))
# -------------------- 2.6 条件判断 --------------------
def get_level(score):
if score >= 90:
return "A"
elif score >= 80:
return "B"
else:
return "C"
print("等级:", get_level(85))
# -------------------- 2.7 循环 --------------------
scores = [88, 91, 76, 95]
for s in scores:
print("分数:", s)
# -------------------- 2.8 综合案例:统计分数 --------------------
def get_score_info(scores):
total = sum(scores)
avg = total / len(scores)
return avg, max(scores), min(scores)
avg, max_s, min_s = get_score_info(scores)
print(f"平均分:{avg},最高分:{max_s},最低分:{min_s}")
# -------------------- 2.10 异常处理 --------------------
# 异常处理非常重要,因为调用大模型、读取文件、解析 JSON 都可能报错。
def parse_score(score_text):
try:
return float(score_text)
except:
print("输入不是数字!")
return None
print(parse_score("90"))
print(parse_score("abc"))
# -------------------- 2.11 读取 JSON 文件 --------------------
#后面会频繁处理配置文件、结构化输出,因此现在就要掌握 JSON
import json
# 先确保同目录有 students.json
try:
with open("students.json", "r", encoding="utf-8") as f: #r表示读取文件,encoding="utf-8"表示使用utf-8编码
data = json.load(f)
print("读取JSON成功:", data)
except Exception as e:
print("文件读取失败:", e)