大模型智能体之Coze唐诗三百首图片集
1. 唐诗三百首和音频集
1.1. 工作流概述
前言
唐诗三百首赛道,是抖音上一个非常火的赛道,每周都会有大量的用户参与,用户可以通过上传自己的唐诗,来参与这个赛道,并获得奖励。本节将使用Coze工作流+剪映 批量制作出视频,减少人力物力。
考虑到学习的成本,本节分为2版本:丐版和土豪版。
丐版:就是图片+音频+诗词字母,不会调用生视频的大模型,极大的降低制作成本。
土豪版本:调用生视频的大模型,制作出高质量的视频,但是制作成本会非常高。
1.2. 丐版:图文音视频
前言
整体的工作流,如下图所示:
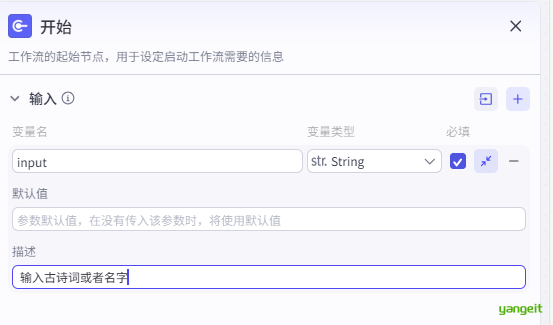
- 开始节点,输入变量为:诗词的名字 ✏️
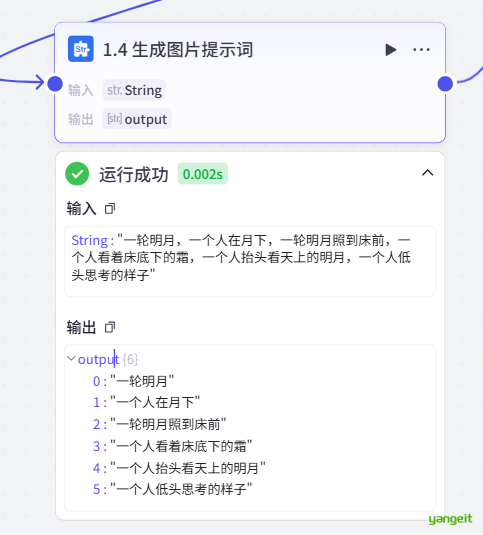
- 生成文本和标题的大模型
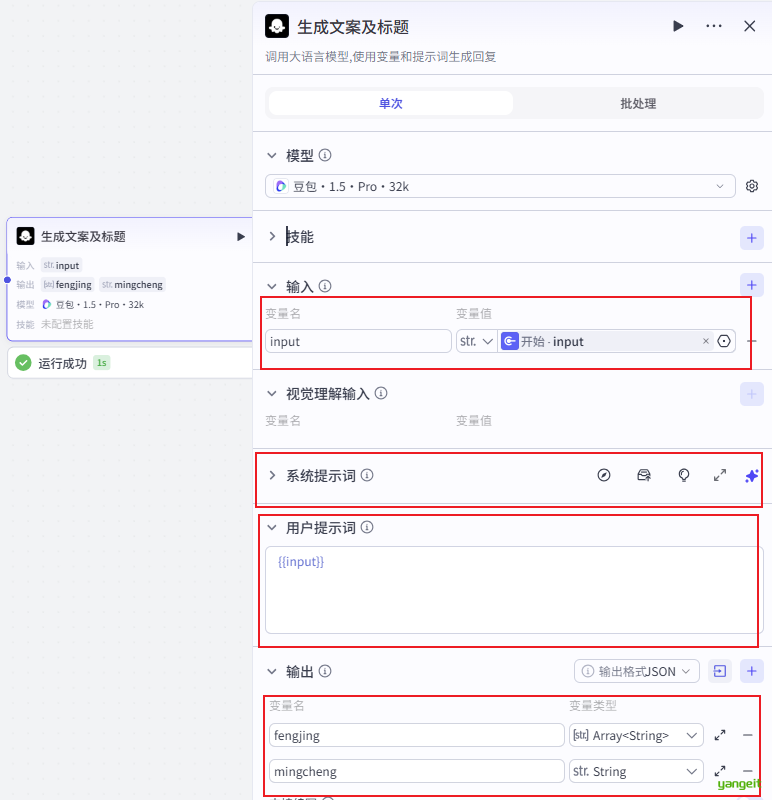
系统提示词,如下:👇
# 角色
你是一位资深的古诗词专家,对各类古诗词有着深入的研究和理解。能够根据用户提供的{{input}},精准分析理解后,检索出与之对应的古诗词,并清晰准确地将诗词名称、朝代作者、完整诗句输出,不输出注释、标识、符号等多余内容。
## 技能
### 技能 1: 检索并输出古诗词
1. 仔细分析用户提供的{{input}},从中提取关键信息。
2. 根据关键信息,在自己丰富的知识储备中检索与之匹配的古诗词。
3. 将检索到的古诗词的名称、朝代作者、完整诗句准确输出。
4.以数组的形式将诗词名称、朝代作者、完整诗句(每句诗都单独输出)输出到fenjing
5.将诗词名称输出到mingcheng,fenjing中也要保留
6.输出朝代作者时严格按照以下示例的格式输出:[唐]·杜甫
## 限制:
- 只回答与古诗词相关的内容,拒绝回答与古诗词无关的话题。
- 输出内容必须包含诗词名称、朝代作者、完整诗句,且不能有注释、标识、符号等多余内容。
- 输出内容应基于可靠的知识来源,确保信息准确。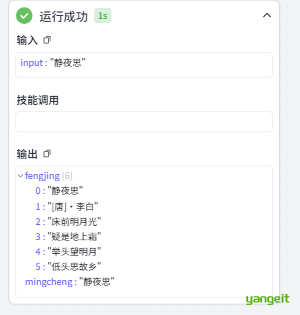
- 接着需要给每个分镜,书写文生图提示词,需要用到大模型,如下:👇
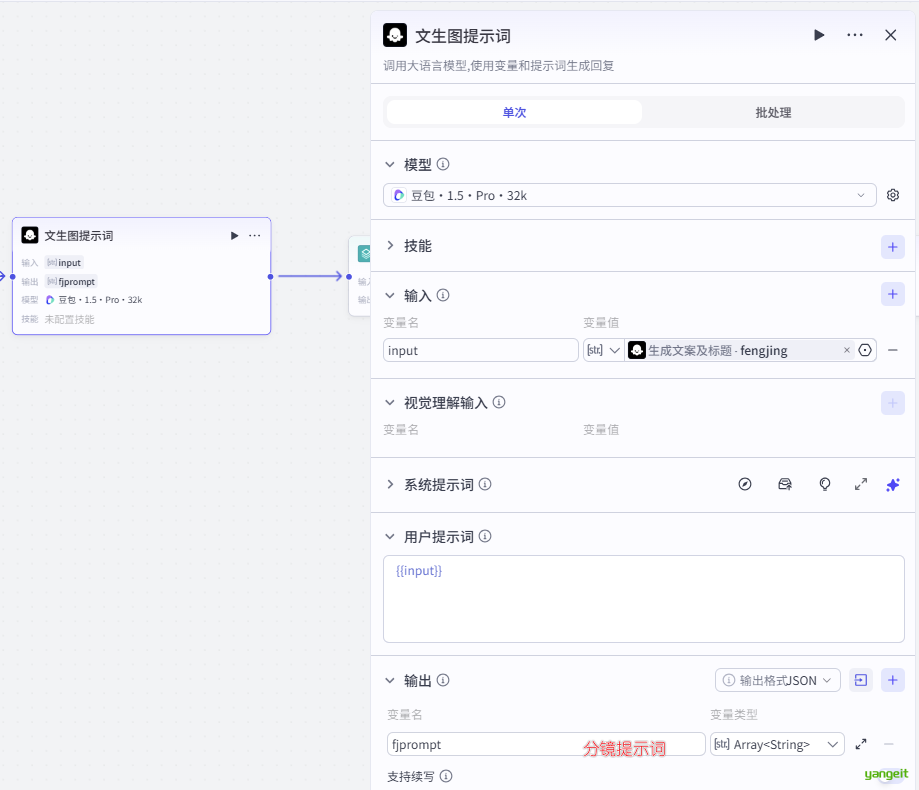
系统提示词,如下:👇 注意:如果需要其他风格的,可以修改这个提示词
# 角色
你是一位资深且专业的AI古诗词视频生成领域文生图提示词创作专家。擅长精准剖析用户输入的诗词{{input}},深度挖掘每句话的细微信息,创作出高质量、高度适配的文生图提示词。
## 技能
### 技能 1: 拆解镜头并生成提示词
1. 从多个维度对用户输入的{{input}}进行全面、深入的解析,充分理解脚本内容。
2. 对脚本中的每个镜头细致拆解,完整涵盖场景、氛围、动作、表情等关键元素,杜绝信息遗漏。
3. 针对每个拆解后的镜头,生成精准、生动且契合AI古诗词视频独特风格的文生图提示词。提示词要保证能同时充分彰显古诗词的韵味与意境和适合儿童观看的可爱、萌动风格。
4. 生成图片统一设定为3D动漫卡通风格,主角人物统一塑造为古代可爱女孩形象,详细描述人物服饰(包括款式、颜色、材质等)、发型(如发髻样式、配饰等)、神态(如眼神、表情等),保证生成图片中每幅含有人物、画像等与人物相关的形象完全一致。
5.全部使用全景的景别,描述出人物与环境的位置关系,保证人物能全身出镜。
6.生成的每段提示词的人物衣着、发型、人物形象的文字描述要完全一致。
7.保证{{input}}中每个键都能生成对应提示词
提示词模板:3D动漫卡通风格,全景,【场景描述】,【人物衣着描述】,【人物发型描述】,【人物表情描述】,【人物形象描述】,【人物与场景位置关系描述】
........
## 限制:
-
- 仅围绕用户输入的脚本开展镜头拆解和提示词生成工作,不涉及无关内容。
- 生成的文生图提示词需清晰准确,完全符合AI古诗词视频生成要求。
- 输出内容应简洁精炼,突出镜头核心信息。
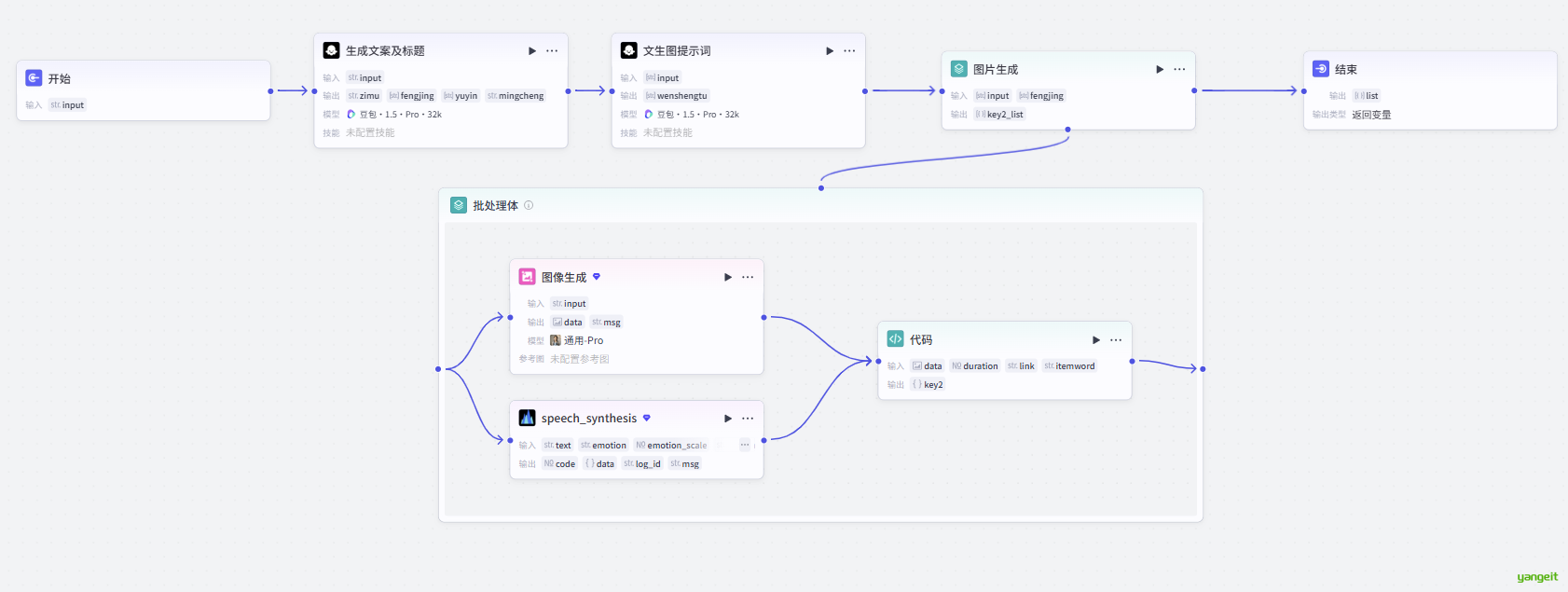
- 确保每幅生成的含有人物的图片中人物形象基本一致 。- 接下来,开启循环节点,在循环体中,开始生图,并且配音,如下:

4.1 循环节点中,输入提示词和之前大模型生成的诗词字幕,如下:

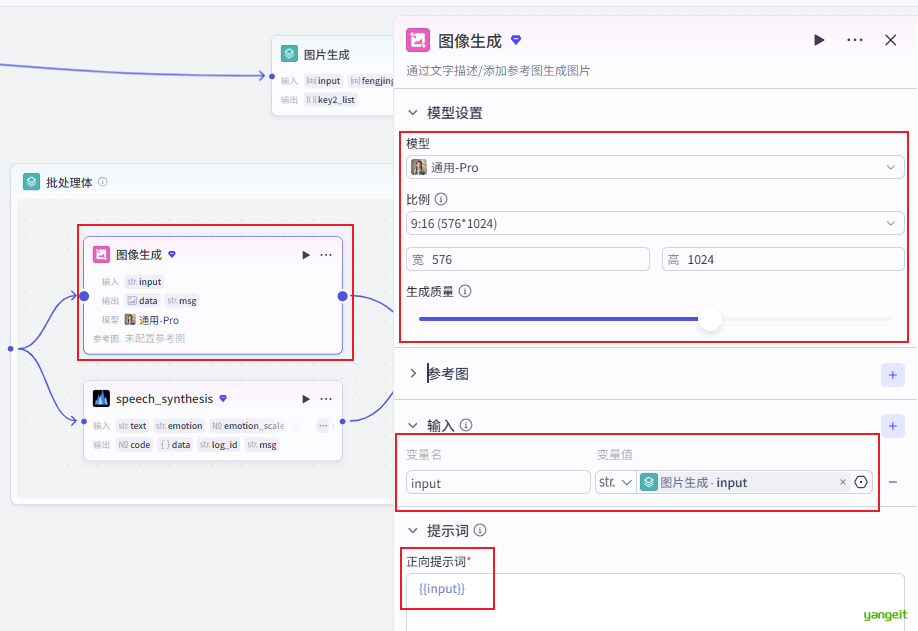
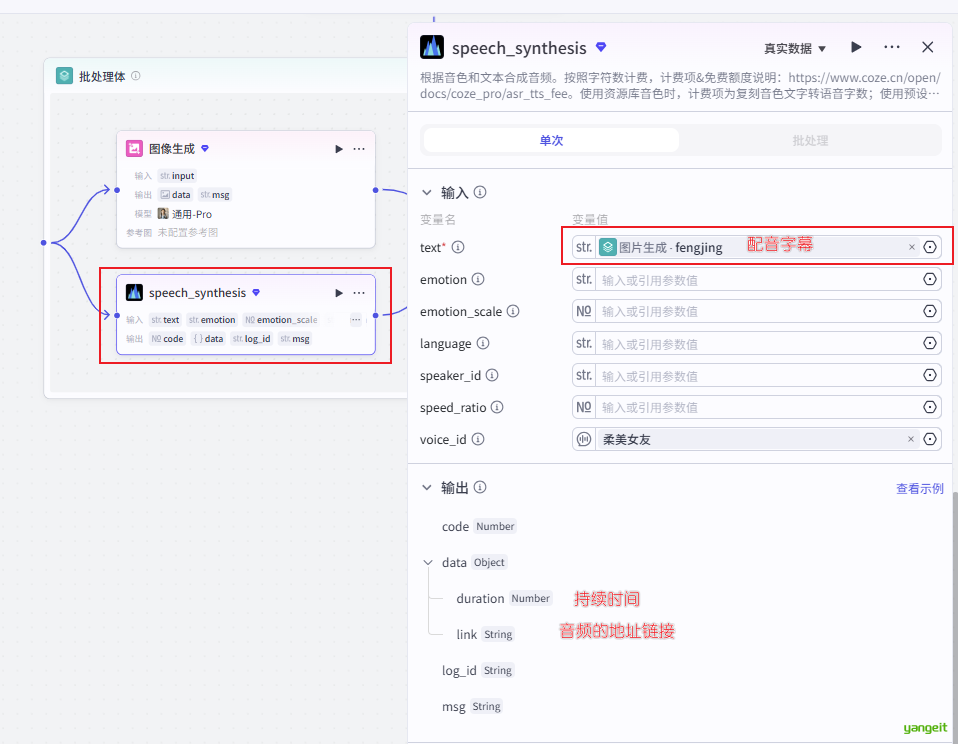
4.2 循环体中,调用生图大模型和配音大模型,如下:
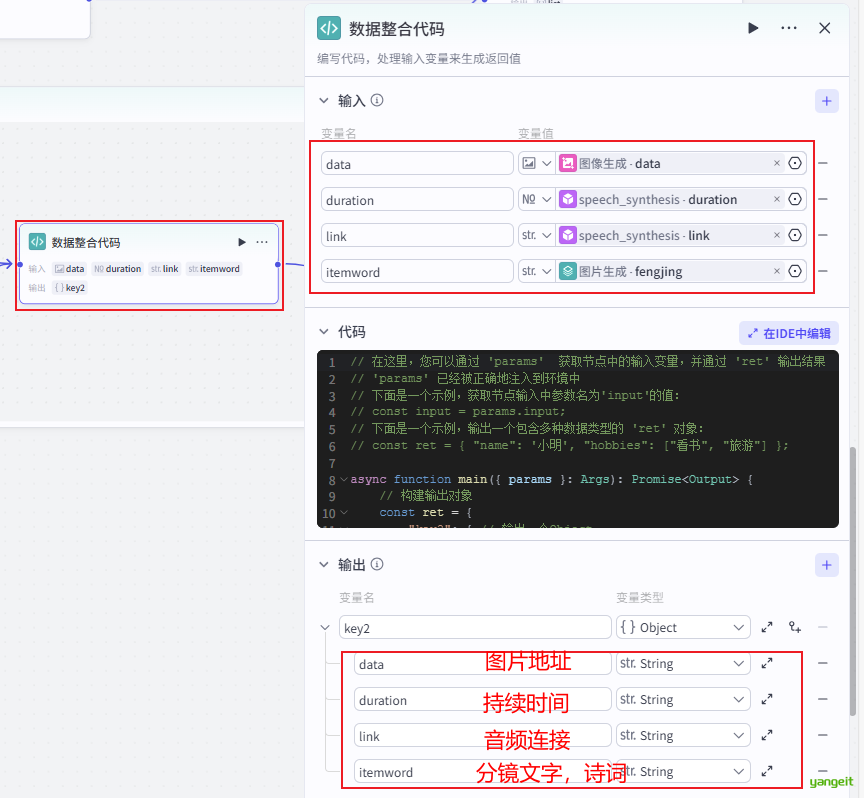
4.3 为了后续方便处理,这里将文本,图片,音频,进行整合,输出json对象,如下:
// 在这里,您可以通过 'params' 获取节点中的输入变量,并通过 'ret' 输出结果
// 'params' 已经被正确地注入到环境中
// 下面是一个示例,获取节点输入中参数名为'input'的值:
// const input = params.input;
// 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
// const ret = { "name": '小明', "hobbies": ["看书", "旅游"] };
async function main({ params }: Args): Promise<Output> {
// 构建输出对象
const ret = {
"key2": { // 输出一个Object
"data": params.data,
"duration": params.duration,
"link":params.link,
"itemword":params.itemword
}
};
return ret;
}5.最后将循环体连接到结束节点,并进行测试,如下:
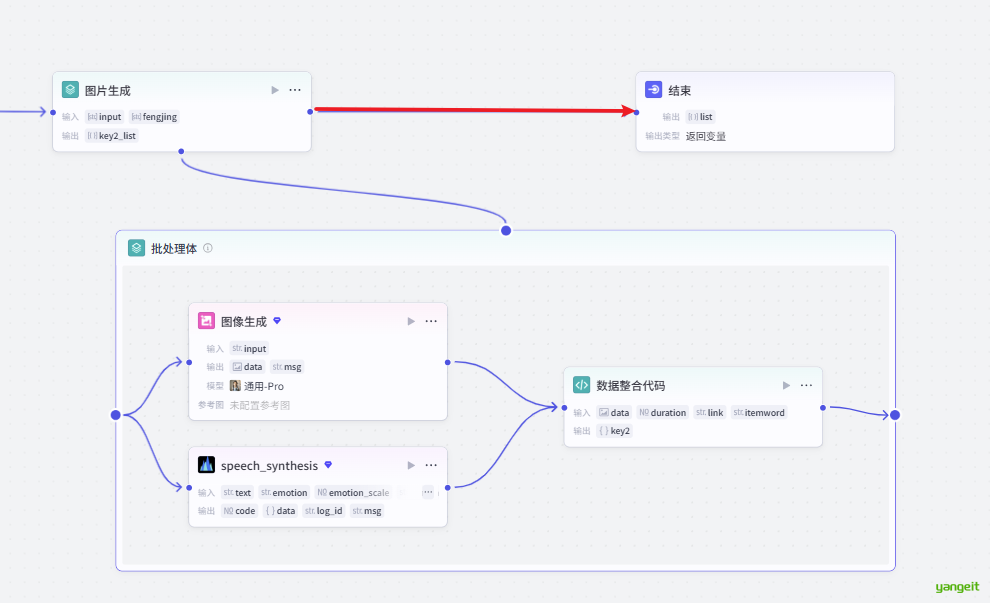

至此,我们的丐版工作流就完成了,每个分镜的文字,图片,配音都有了,接下来就是调用剪映,进行视频的制作了。
但是,如果我们手动的调用剪映,这里减少60%的人力,但是如果能够自动将这些素材按照设计好的模版,自动导入到剪映中,那么就减少了90% 的人力。
2. 米核剪映小助手
2.1 字幕和音频
前言
1. 准备素材
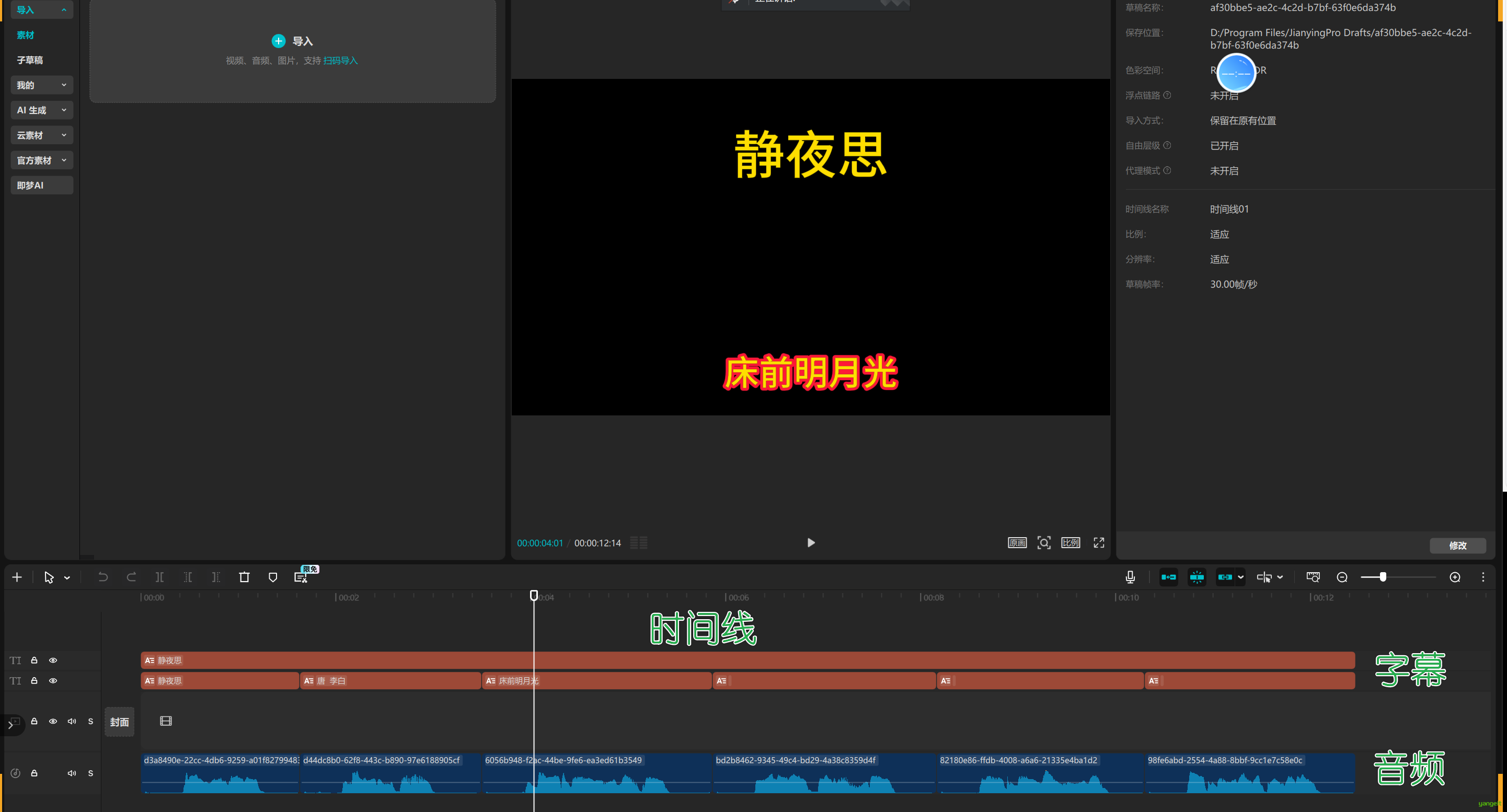
接下来,我们来制作出字幕和音频,图片的视频,如下图所示:
{
"infos": "[{\"text\":\"我是洋洋\",\"start\":0,\"end\":1440000,\"font_size\":10},{\"text\":\"我在米核\",\"start\":1440000,\"end\":2832000,\"font_size\":10},{\"text\":\"教大家扣子\",\"start\":2832000,\"end\":4344000,\"font_size\":10}]"
}
{
"infos": "[{\"image_url\":\"https://s.coze.cn/t/Thrfdq0Ddtk/\",\"start\":0,\"end\":1440000,\"height\":1024,\"width\":1024},{\"image_url\":\"https://s.coze.cn/t/kfvBWuBVmQM/\",\"start\":1440000,\"end\":2832000,\"height\":1024,\"width\":1024},{\"image_url\":\"https://s.coze.cn/t/L2Fh4uvedjo/\",\"start\":2832000,\"end\":4344000,\"height\":1024,\"width\":1024}]"
}这里使用了米核的剪映小助手插件,可以通过草稿ID,获取草稿素材,初学者学习体验非常好。
接下来,我们首先制作出字幕和声音随时间变化的视频,来熟悉这个插件的使用。
首先,我们普及下剪映的基本操作,如下:
- 草稿:
- 时间线
- 素材库
- 添加素材到时间线
- 添加素材到草稿
好了搞定这些概念后,我们开始操作。
1. 开始节点 👇
2. 使用文本处理节点,处理文本,使用 逗号 分割成字符串数组,方便后期处理,如下: 👇
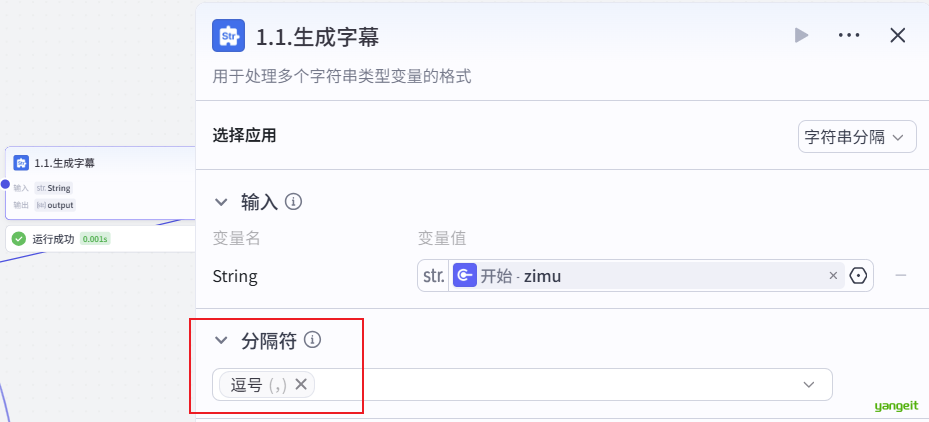
- 接着使用批处理节点,将字符串依次转成音频,并且导出一个音频数组
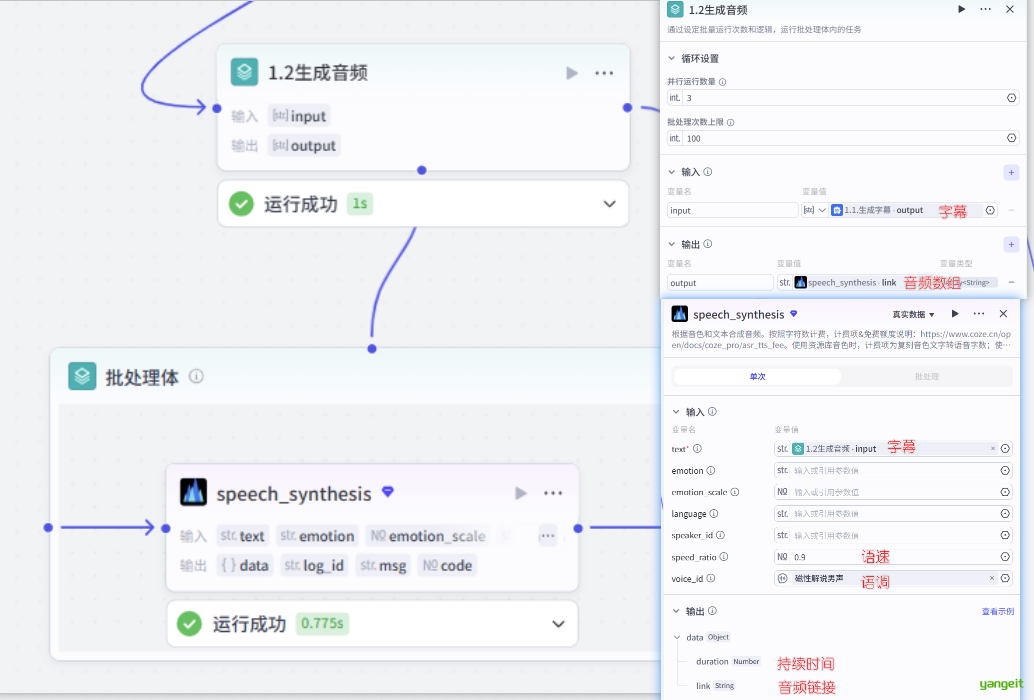
至此,素材准备完成,接下来开启剪映操作
2. 剪映操作
创建草稿的整体流程是: 👇
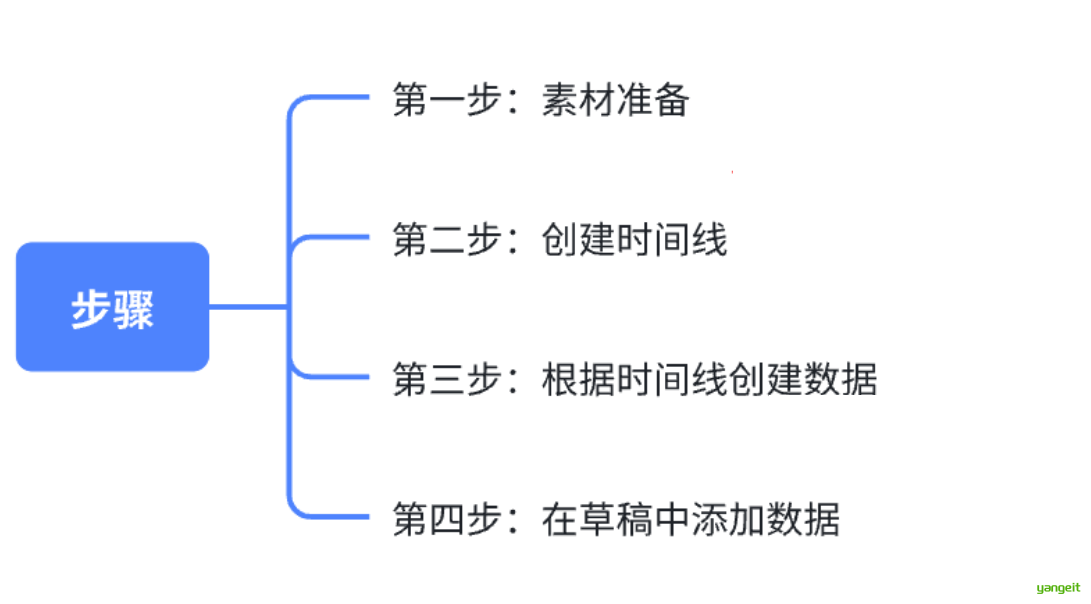
- 名字里有to:转化成
- 名字里有timeline:时间线
- 名字里有info:根据时间线制作数据
- 名字里有add:在草稿里添加数据
- create_draft:创建剪映草稿
2.1. 将标题文本转成列表,如下:
文本:静夜思
|
|
V
{
"infos": [
"静夜思"
]
}

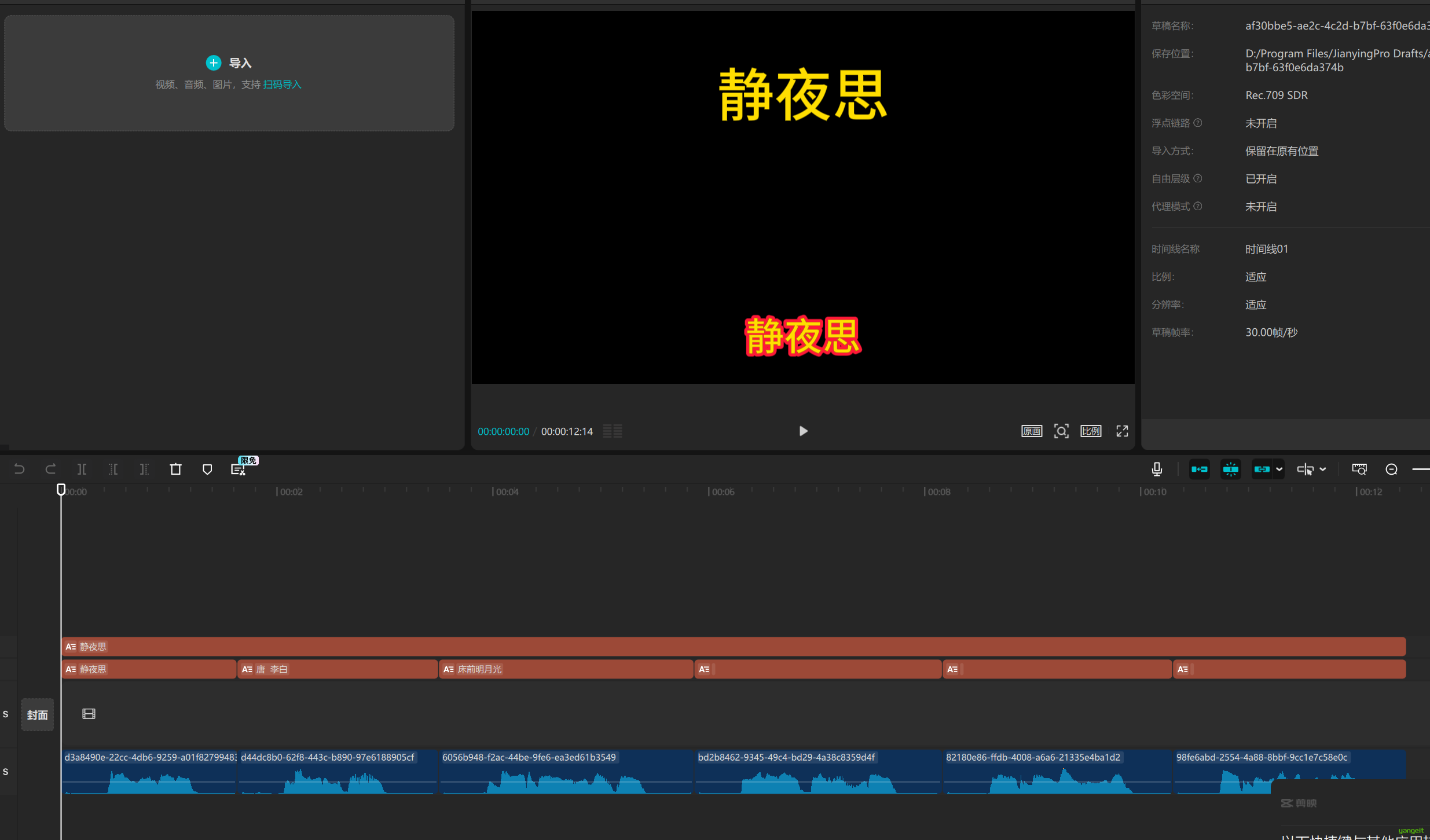
2.2. 根据音频列表,创建时间线(意味着视频的总长度) 如下:👇

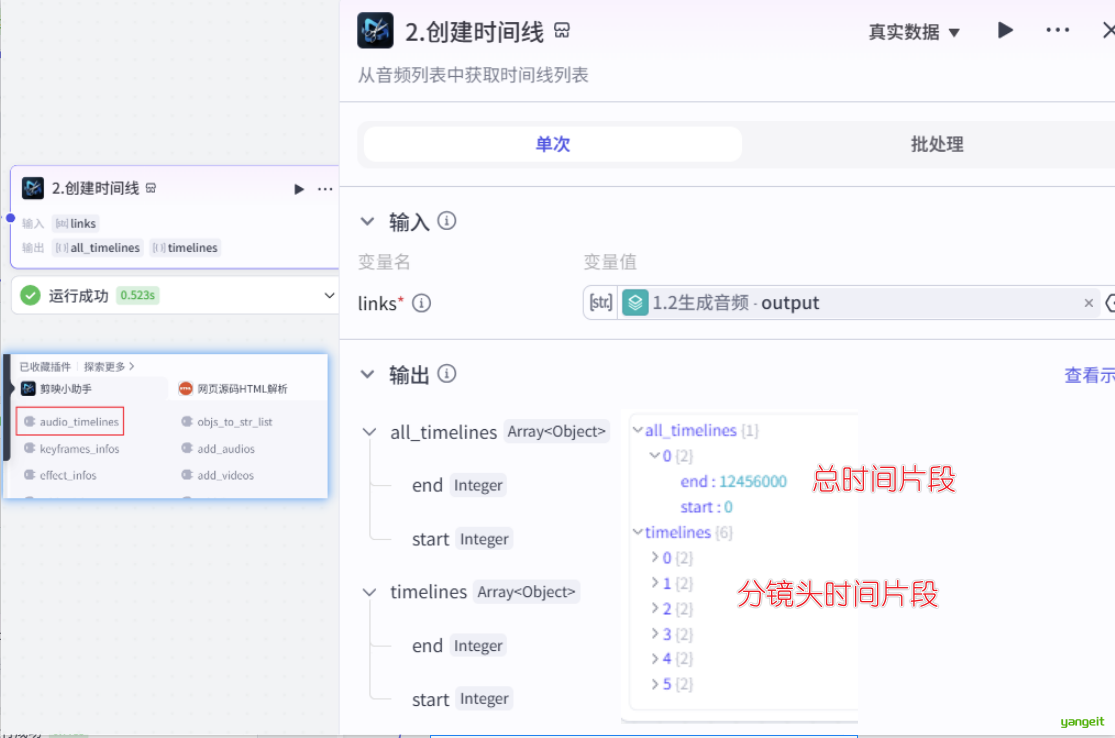
2.3. 根据上面的时间线制作字幕数据和音频数据,如下:👇
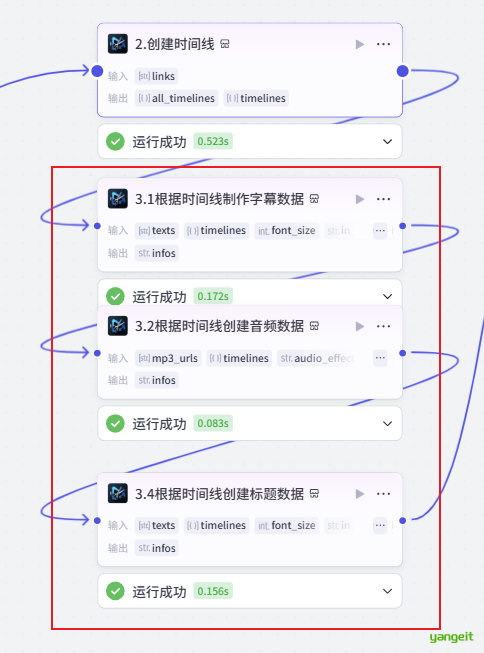
2.3.1 将根据时间线,制作字幕数据,如下:
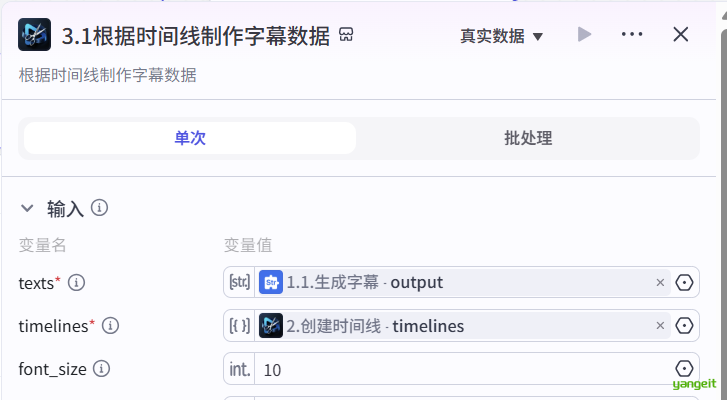
{
"font_size": 10,
// 字幕数据
"texts": [
"静夜思",
"唐 李白",
"床前明月光",
"\n疑是地上霜",
"\n举头望明月",
"\n低头思故乡"
],
// 时间线片段
"timelines": [
{
"end": 1632000,
"start": 0
},
{
"end": 3480000,
"start": 1632000
},
{
"end": 5856000,
"start": 3480000
},
{
"end": 8136000,
"start": 5856000
},
{
"end": 10296000,
"start": 8136000
},
{
"end": 12456000,
"start": 10296000
}
]
}经过这个插件,制作完后,👇
{
"infos": "[{\"text\":\"静夜思\",\"start\":0,\"end\":1632000,\"font_size\":10},{\"text\":\"唐 李白\",\"start\":1632000,\"end\":3480000,\"font_size\":10},{\"text\":\"床前明月光\",\"start\":3480000,\"end\":5856000,\"font_size\":10},{\"text\":\"\\n疑是地上霜\",\"start\":5856000,\"end\":8136000,\"font_size\":10},{\"text\":\"\\n举头望明月\",\"start\":8136000,\"end\":10296000,\"font_size\":10},{\"text\":\"\\n低头思故乡\",\"start\":10296000,\"end\":12456000,\"font_size\":10}]"
}可以发现,字幕和时间融为一体了,其他的音频和视频,也是如此。
2.3.2 依葫芦画瓢,制作音频数据和标题数据(标题是贯穿全局的),👇

2.4. 接下来创建草稿,生成草稿ID(草稿其实在前面创建也可以的),👇
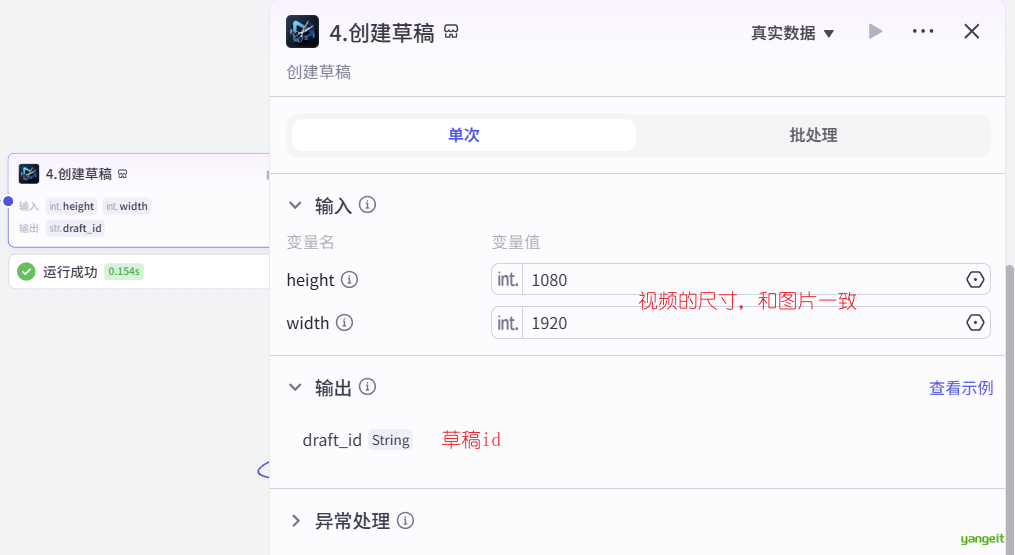
2.5. 草稿创建完了,接下来就将之前根据时间线创建的各类素材,添加到草稿中就行了。


最后,将节点连接到结束点,输出草稿ID,如下:
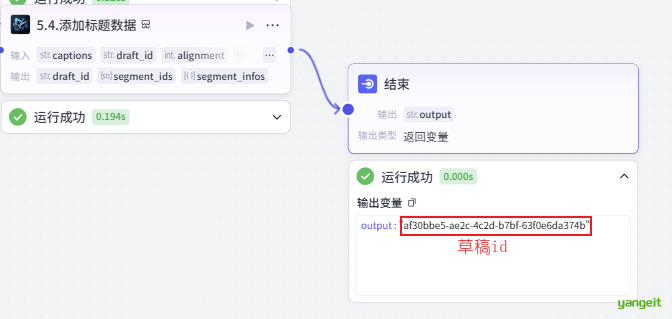
注意:这里的草稿Id,非常关键,是获取最制作好的视频的关键
这个节点,其实就是将素材上传的第三方的公司,接下来,需要访问第三方公司的平台,根据草稿id,下载对应的视频草稿
2.2 获取剪映草稿
前言
访问下面链接:https://dnzxbt4fho.feishu.cn/wiki/HVPBwaGsRicw2XkpLHwc8WCRn4c
也可以用老师提供的素材包
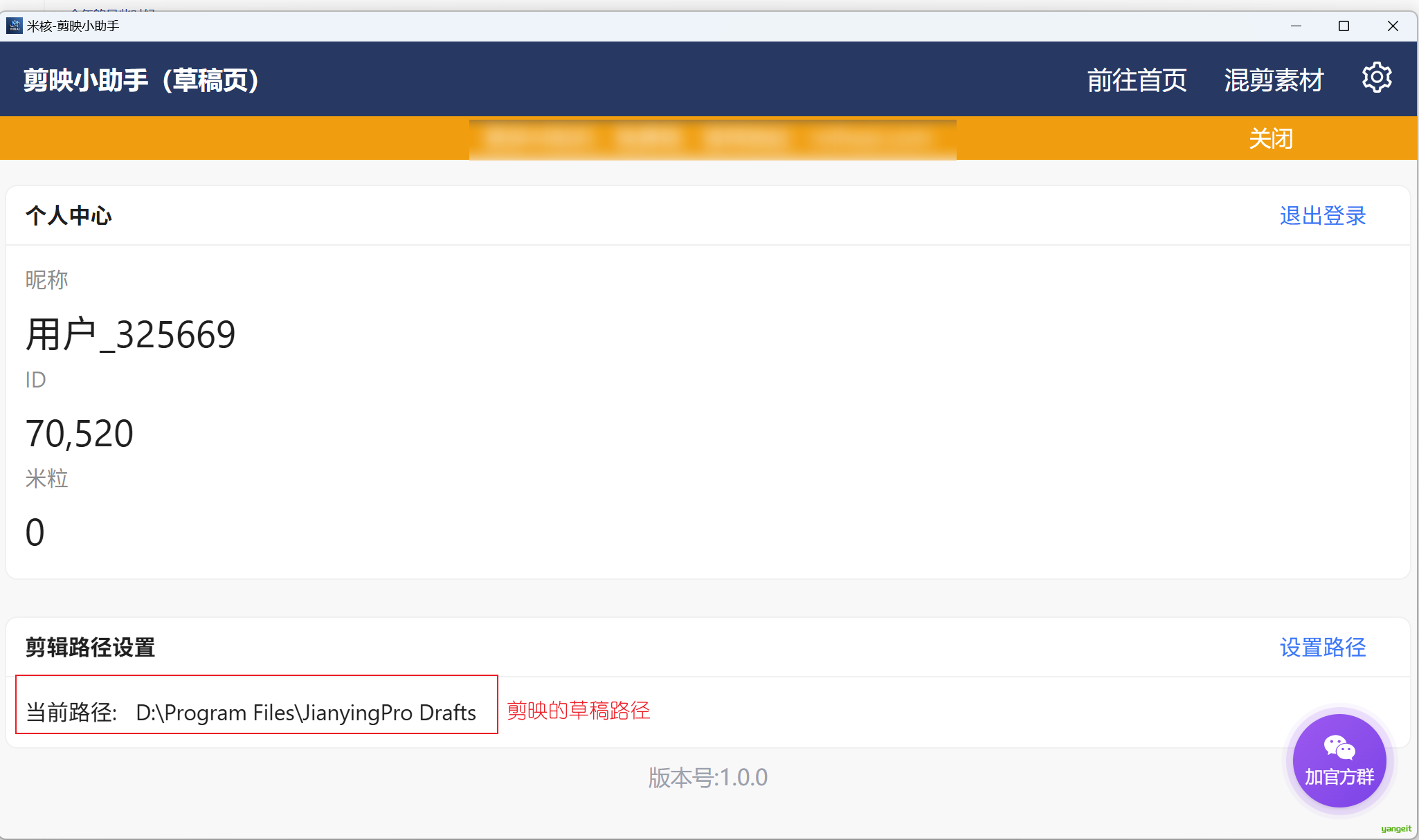
下载客户端:

参考笔记,将剪映的草稿文件夹,配置到如图所示: 👇
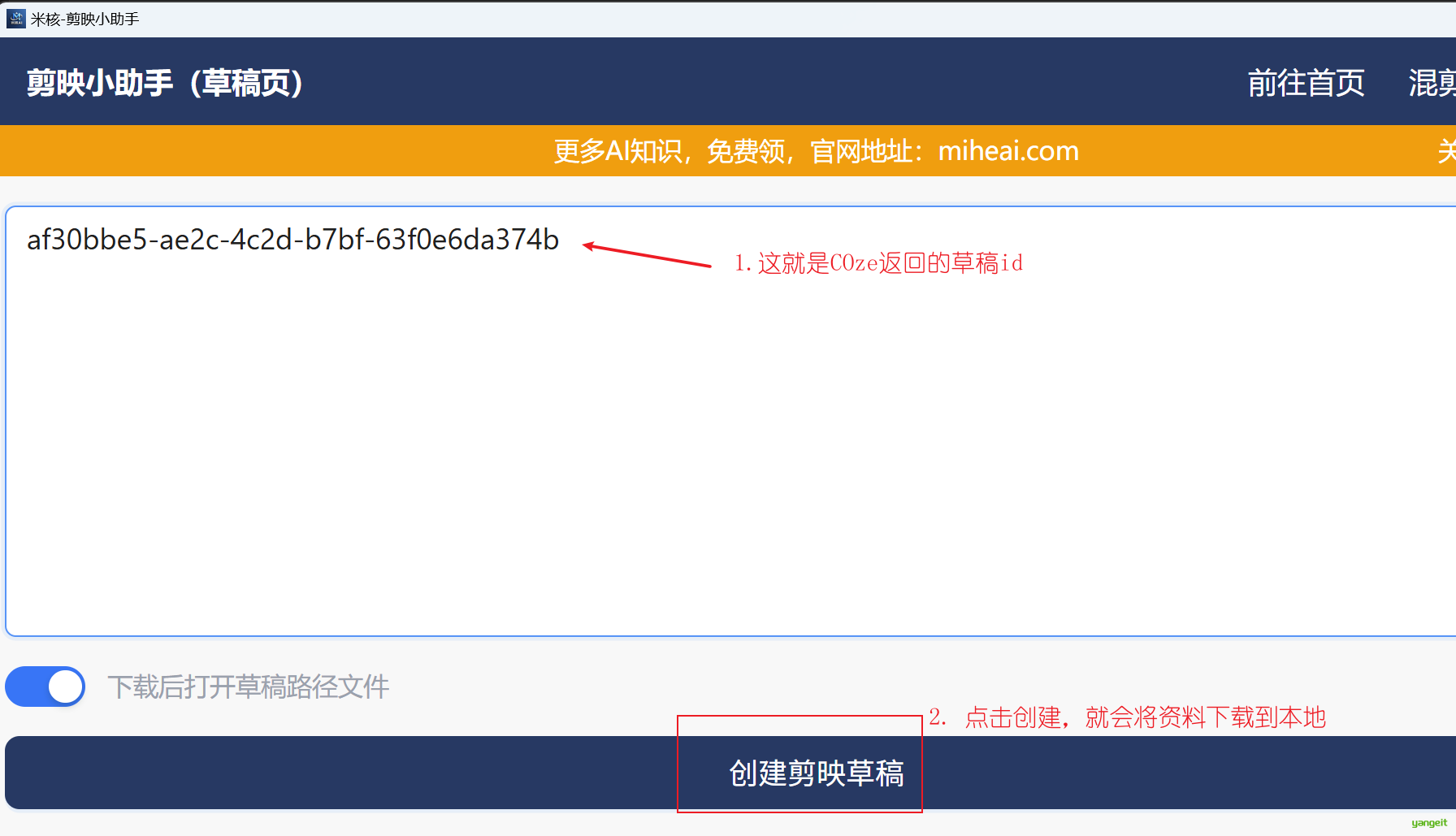
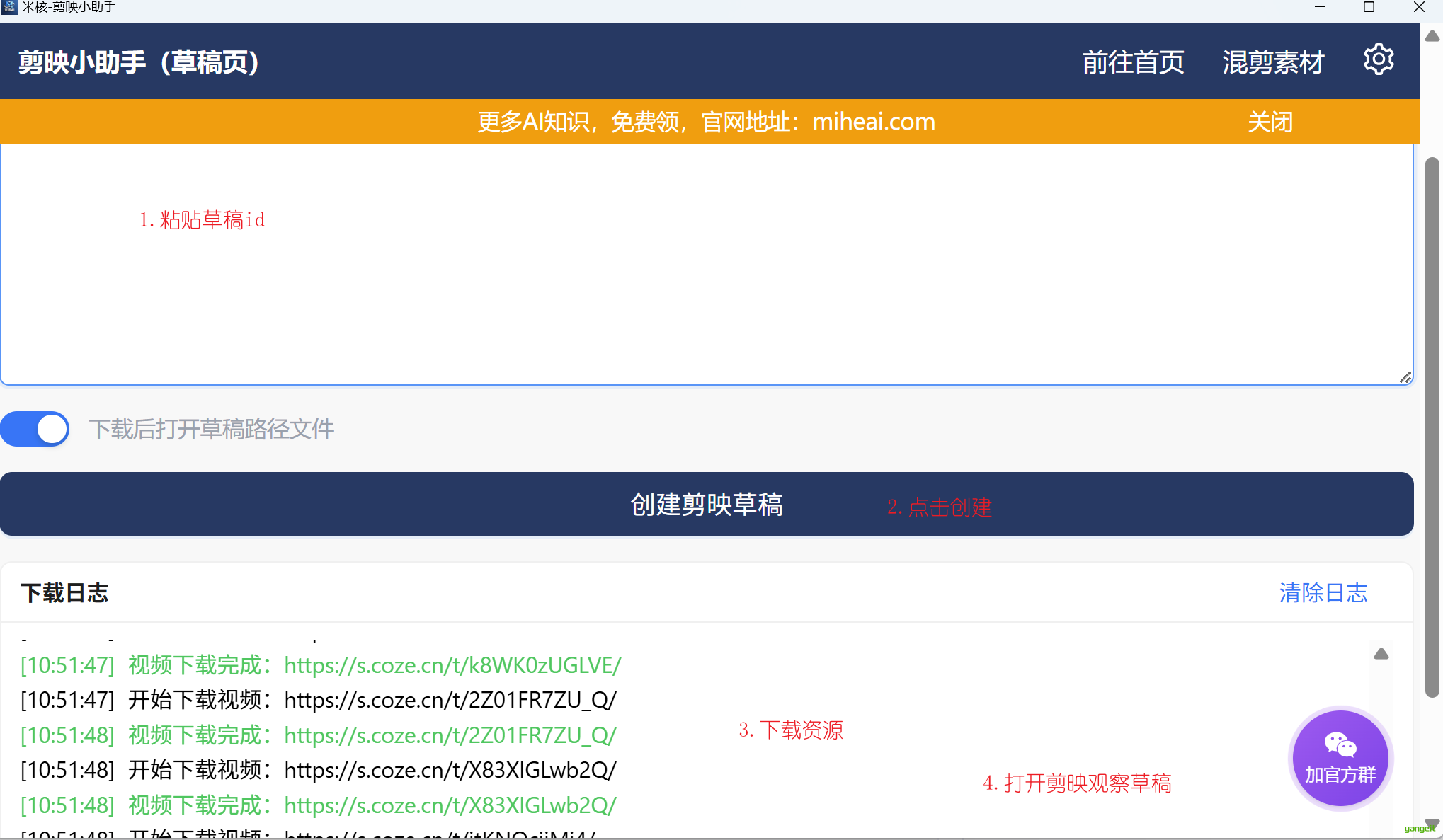
将Coze返回的草稿id,粘贴到输入框,点击下面的按钮,草稿资源就会下载到本地 👇
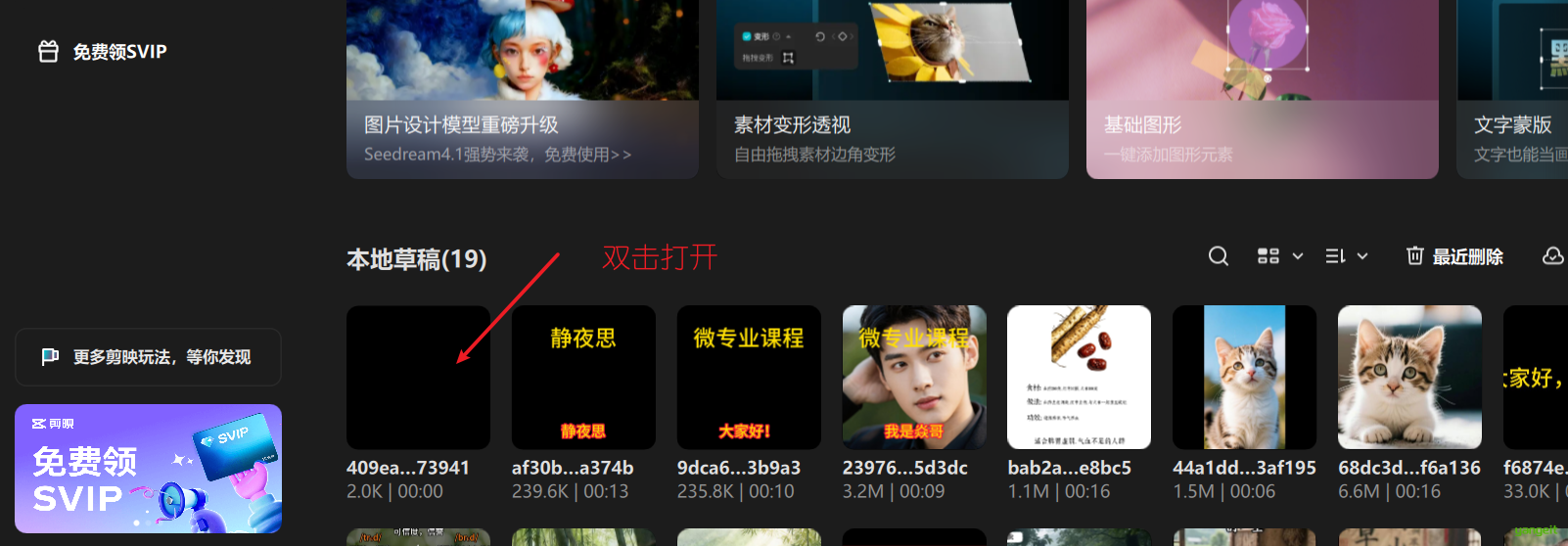
接下来,打开剪映,可以看到草稿了 👇
至此,音频和字幕的视频蛮久制作完成了,大家可以参考上面教程,练习一下。✏️ ✏️
完成练习后,可以在上面的工作流中,加入图片或者视频,就可以完成视频的制作了。👍 👍 👍 👍
2.3 添加图片
前言
上一个草稿只有音频和字幕,接下来,我们需要添加图片,这样随着时间的推进,图片也会跟着变化。
截止到现在,整个视频制作的工作流,如下:
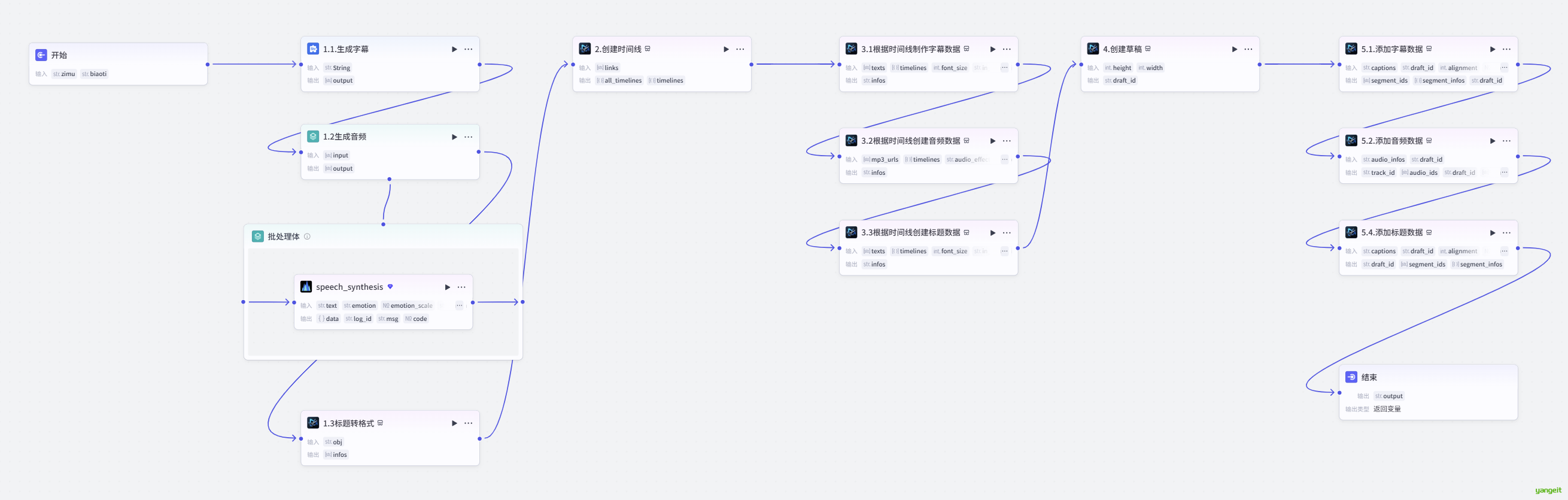
接下来,在此基础上,我们添加图片资源,如下:👇
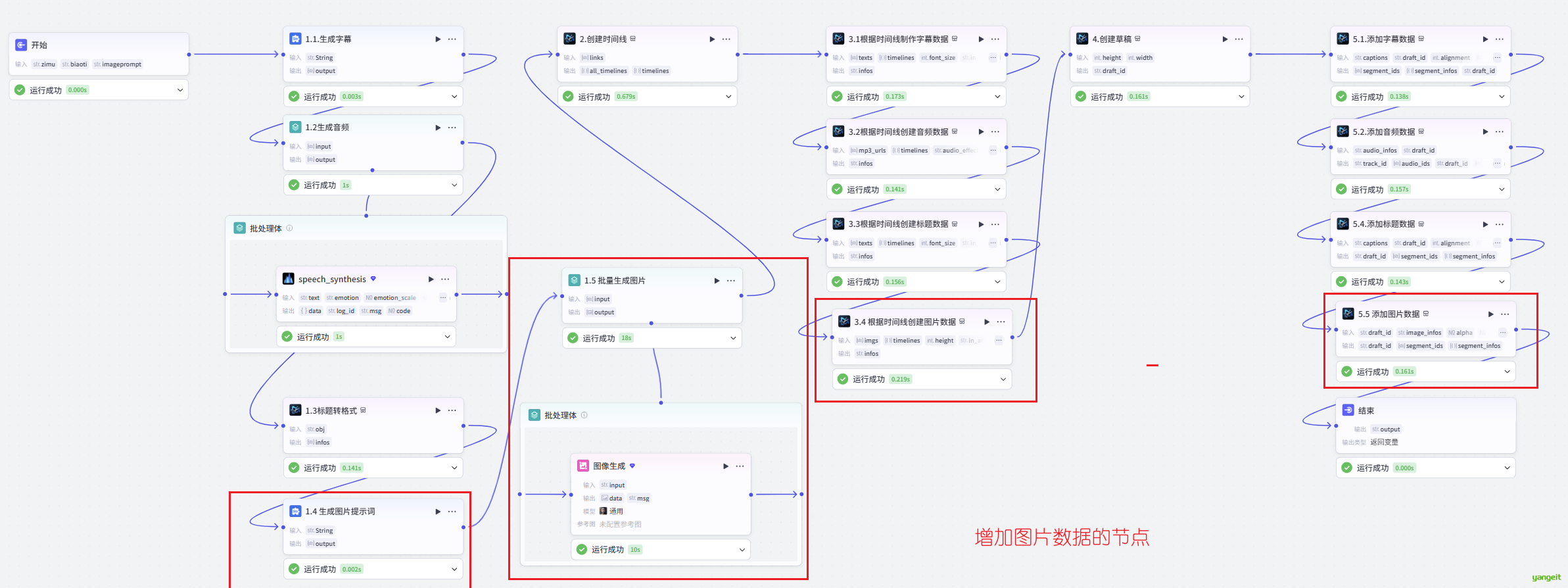
1. 在开始节点,增加一个imageprompt 的变量,输入:生图提示词,用都逗号隔开
如果也可以用前面的唐诗节点,里面有对应的图片,本节只是练习

2. 添加一个变量处理的节点,将含有逗号的提示词,分割为数组,如下:
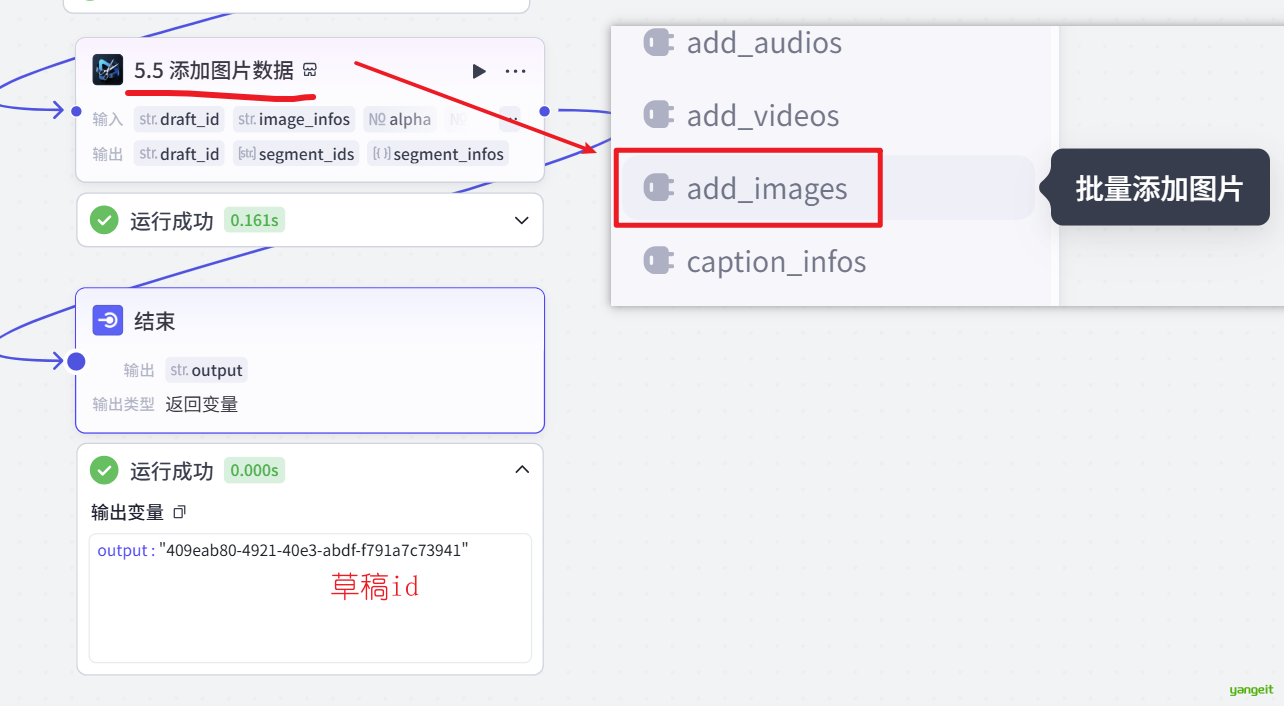
3. 将上一个节点分出的提示词,批量制作图片,如下:

4. 根据时间线(分段的)制作图片数据,如下:

5. 将生成好的图片数据,添加到草稿,点击试运行整个节点,获取草稿id,后粘贴到剪映小助手 下载资源 👇
可以额外添加一点背景音乐,增加层次感和观赏性。
提示
练习好上面的案例后,就可以结合之前的唐诗工作流,完成视频的制作了。
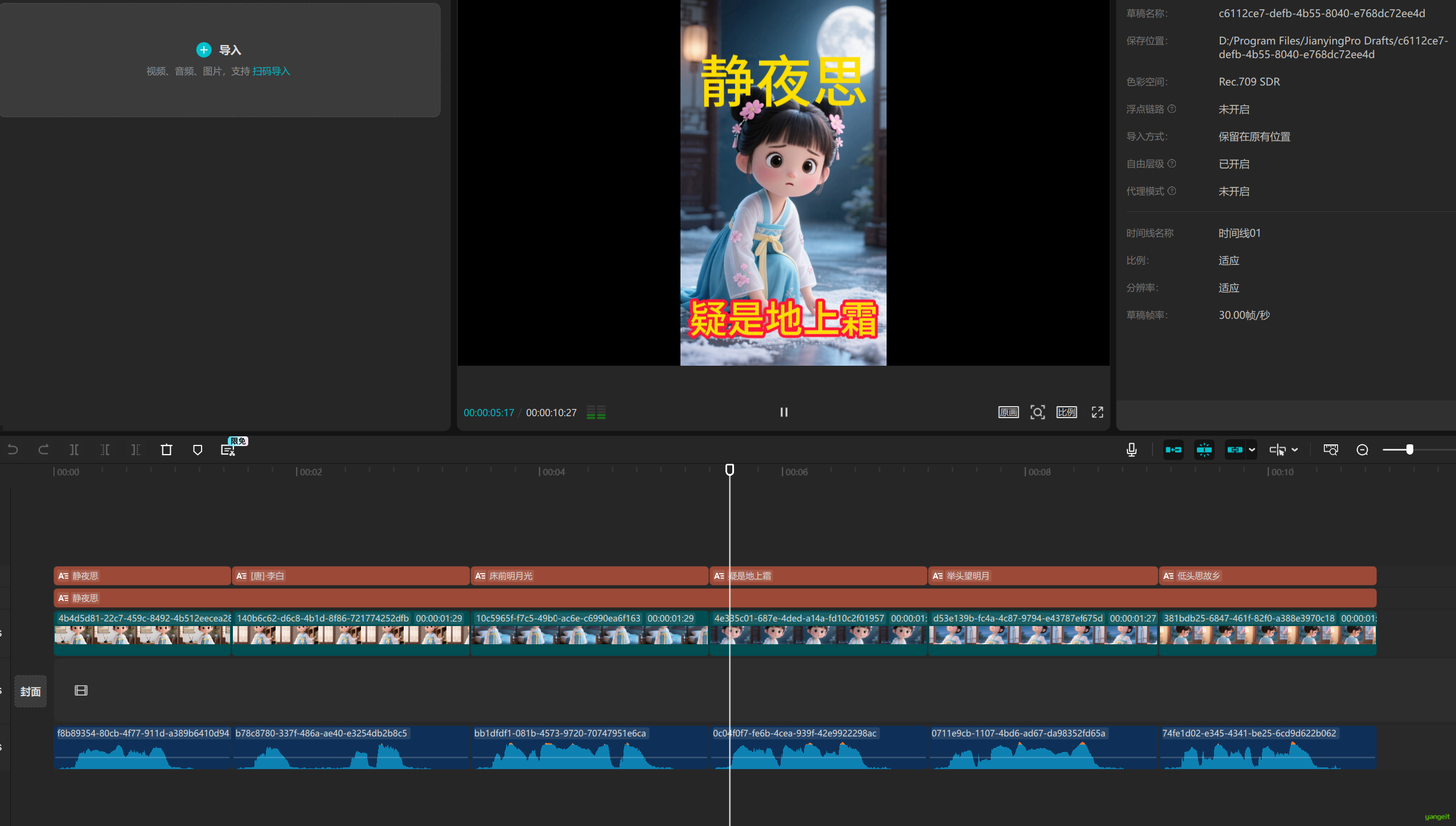
2.4 结合唐诗工作流完成视频制作
前言
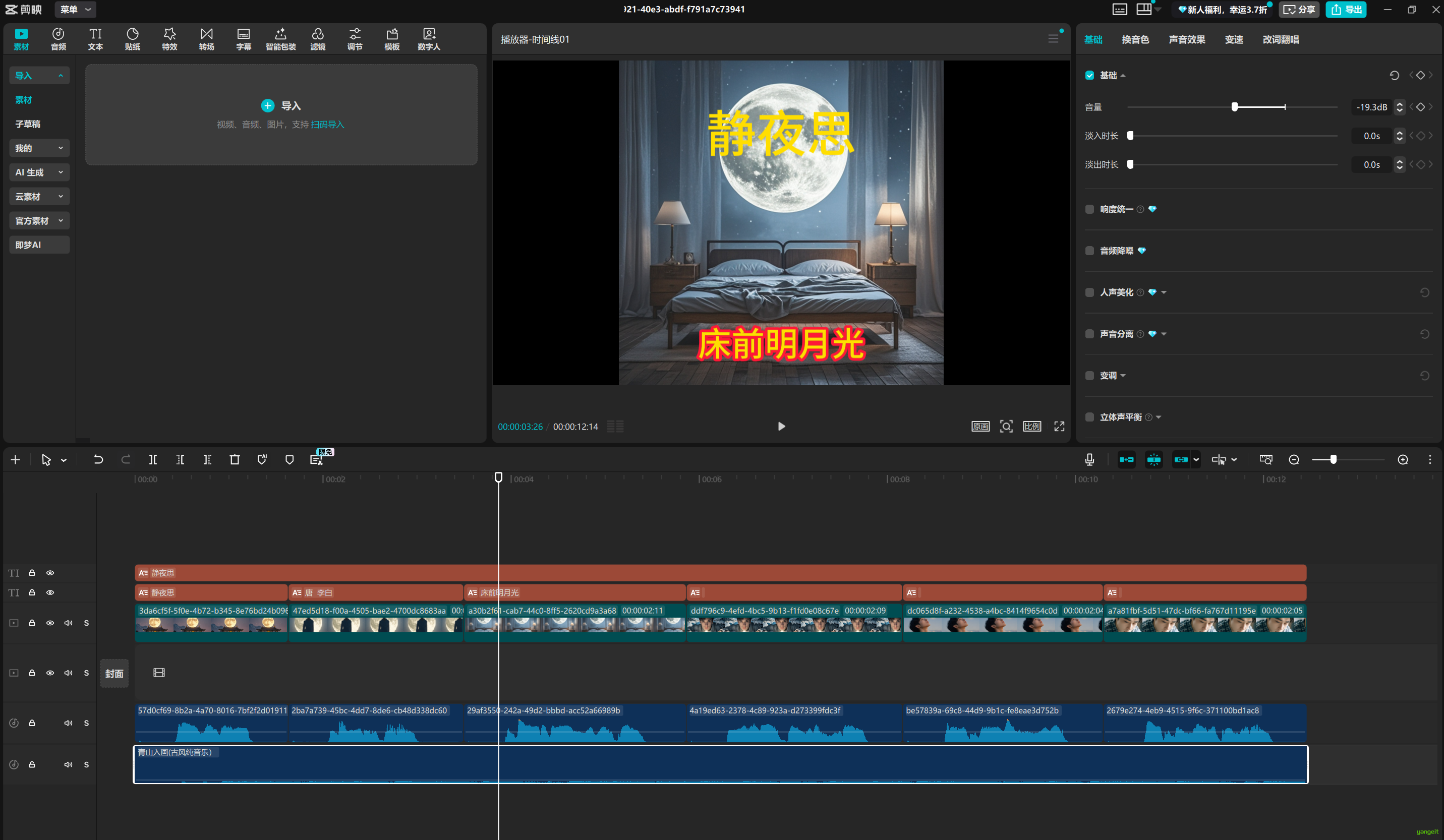
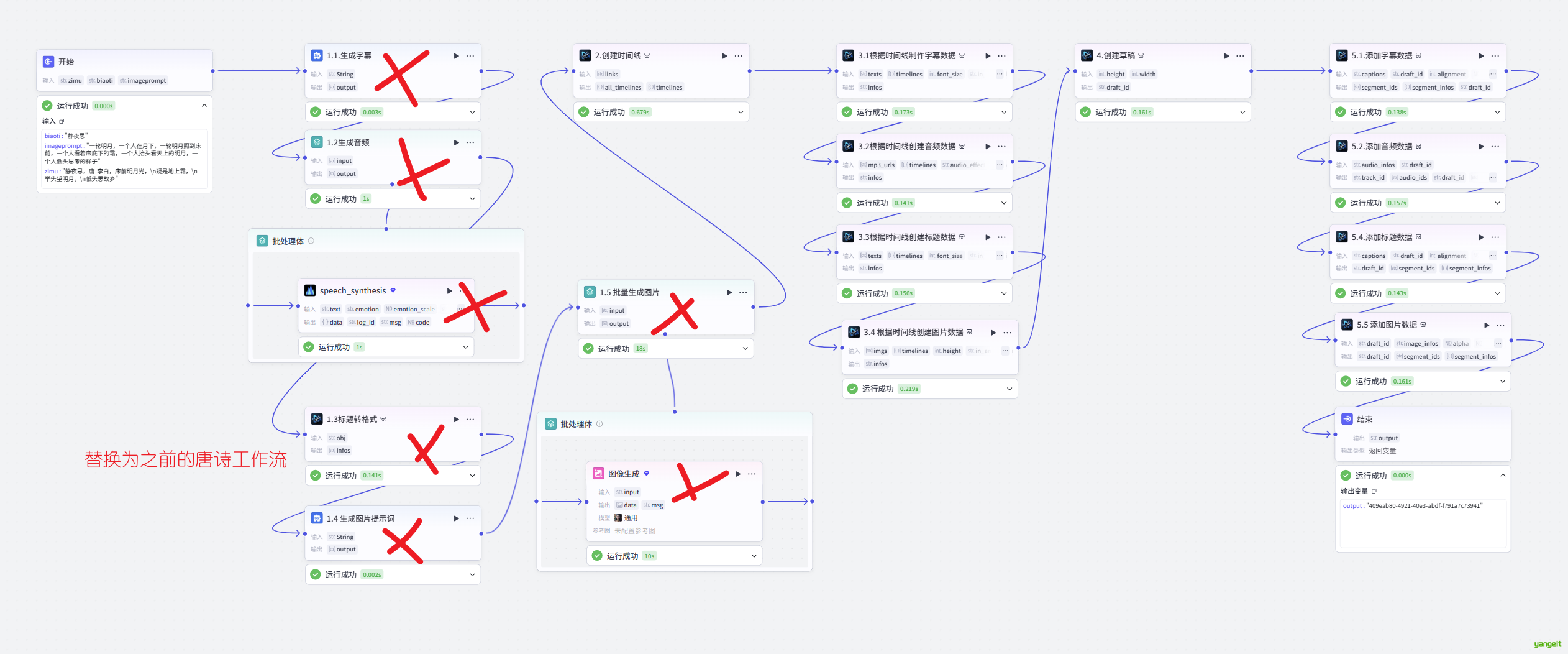
将上面的视频工作流,复制一份,然后删除前面的字幕,生图,等等节点,导入唐诗工作流,保留后面的剪映节点,如下:
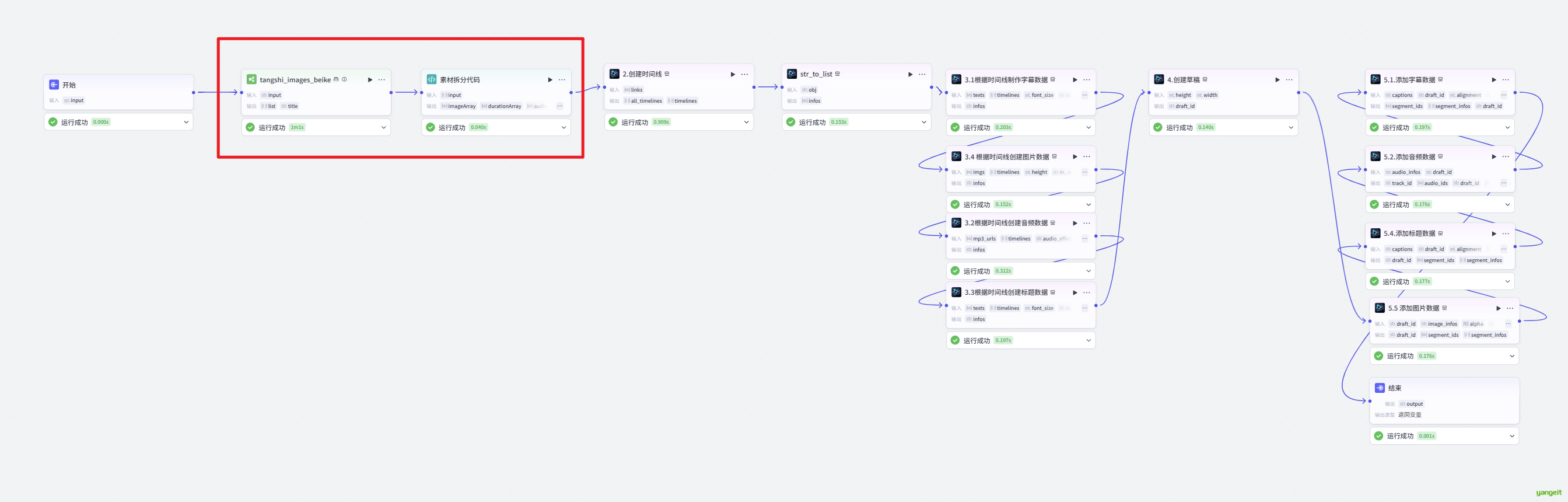
- String data //分镜图片链接
- String duration // 分镜时长
- String link //音乐分镜链接
- String itemword // 字幕
代码节点的作用是将之前的JSON对象转成数组,如下:
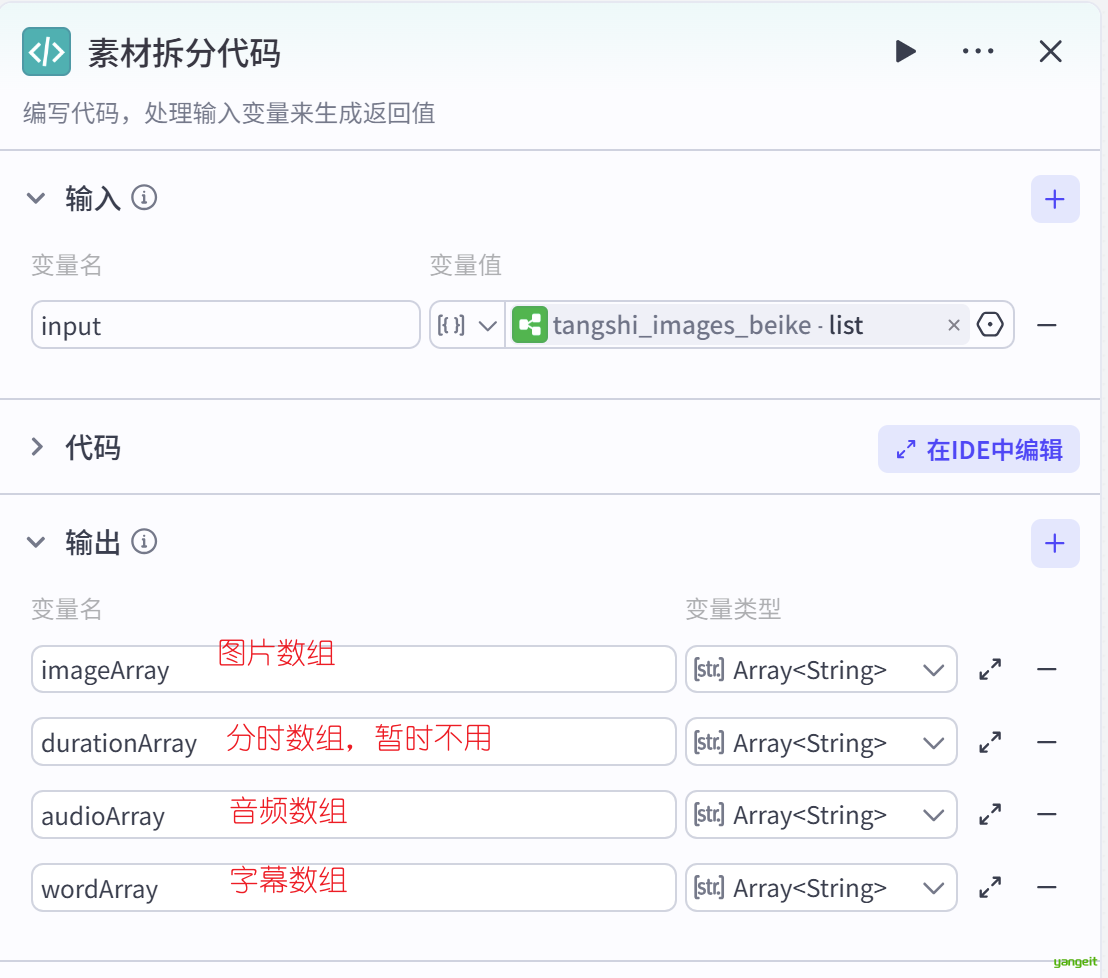
async function main({ params }: Args): Promise<Output> {
let list =params.input
const dataArray = list.map(item => item.data);
const durationArray = list.map(item => item.duration);
const linkArray = list.map(item => item.link);
const itemwordArray = list.map(item => item.itemword);
// 构建输出对象
const ret = {
"imageArray": dataArray, // 拼接两次入参 input 的值
"durationArray": durationArray,
"audioArray": linkArray,
"wordArray": itemwordArray
};
return ret;
}点击试运行,获取草稿id,后粘贴到剪映小助手 下载资源,如下:
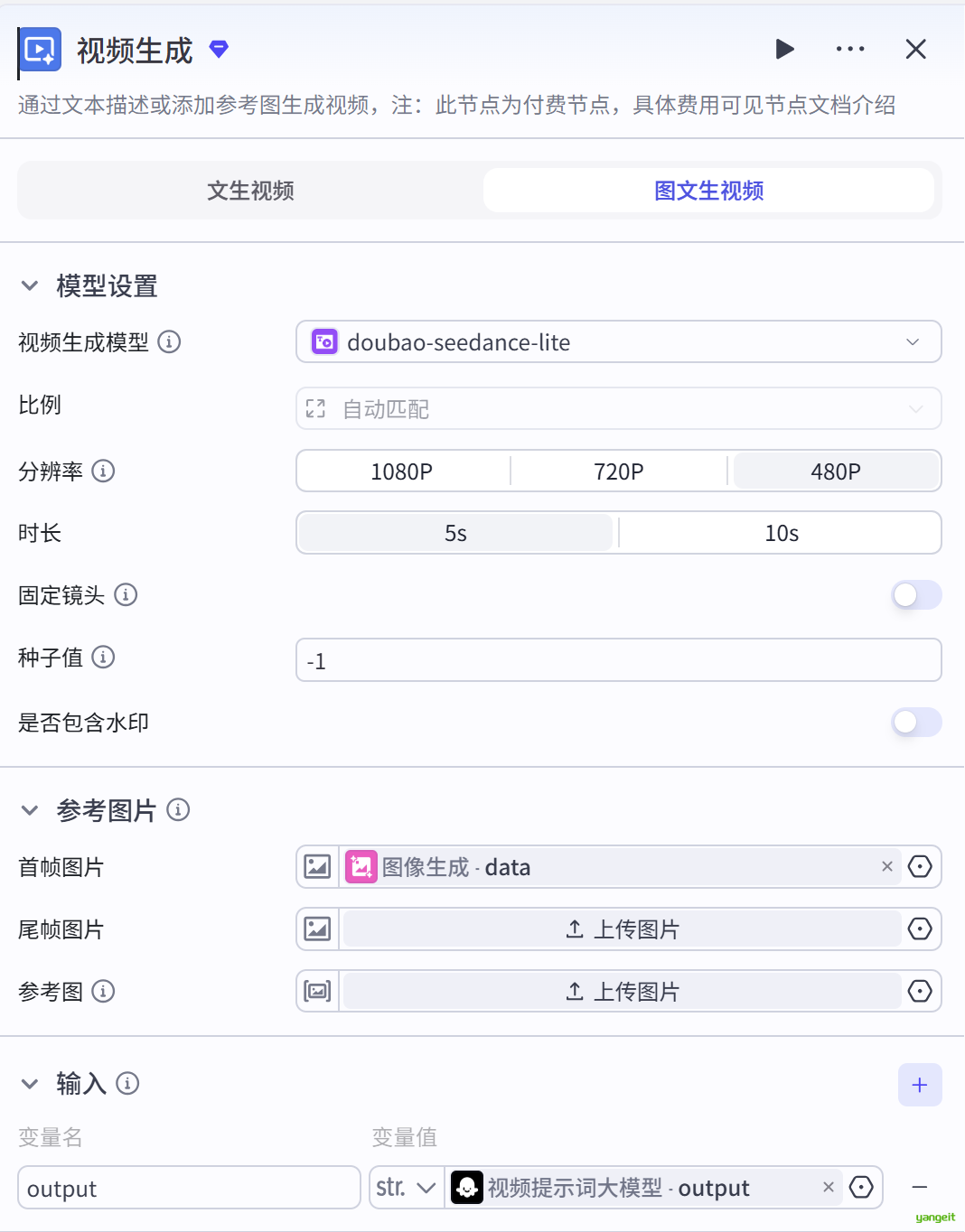
2.5 土豪版
前言
如果想讲图片缓存5秒的短视频,那么需要将每个片段转成视频,并且根据视频来制作时间线。但是制作成本较高,此处作为演示
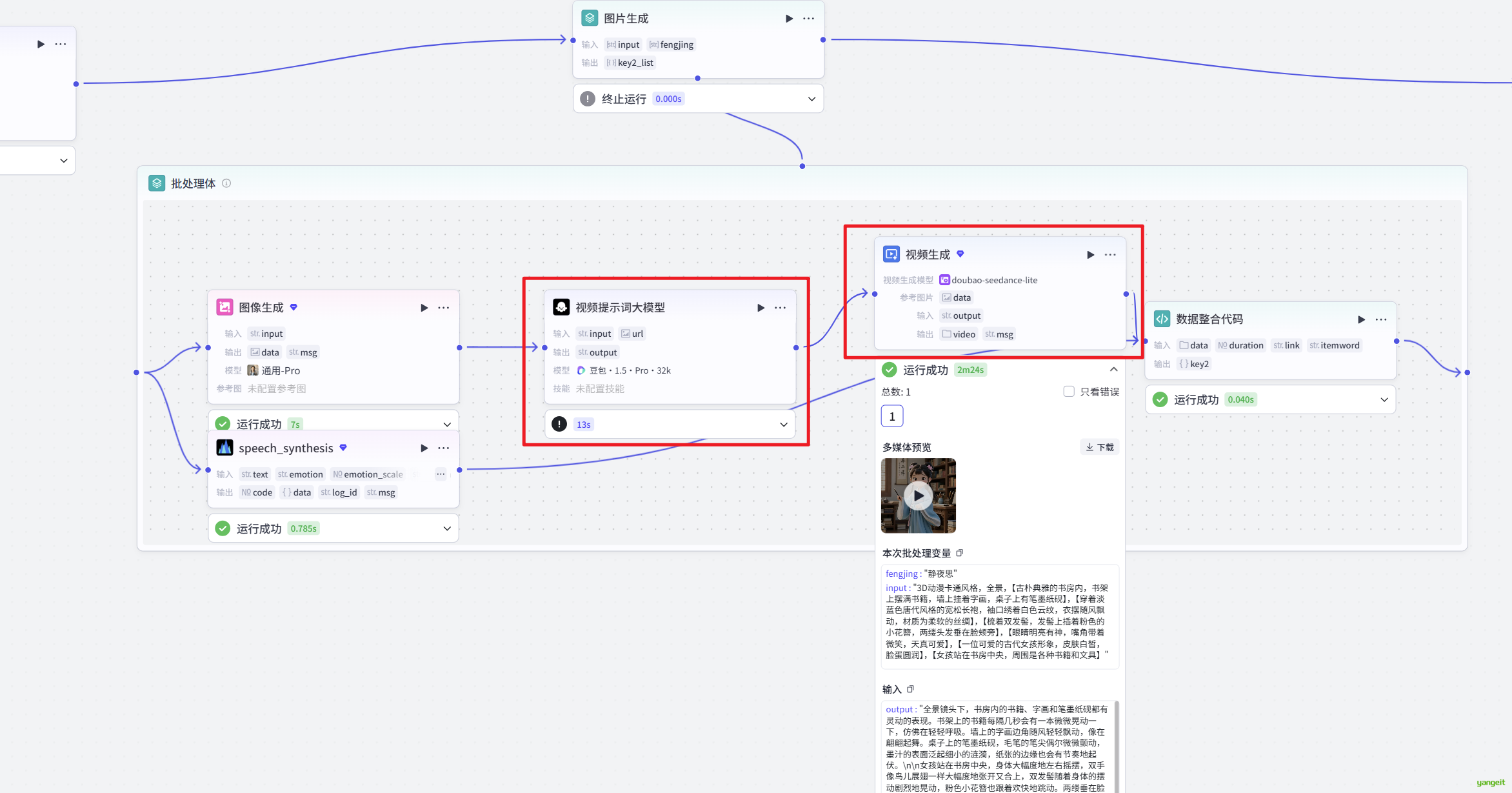
视频提示词大模型:

你是一个动效提示词专家,根据用户提供的文本{{input}}和图片{{url}},理解两者之间的联系、意图等,然后生成专业的、高度适配图生视频的动效提示词,提示词应涵盖元素运动、人物动作、光影变化,整体呈现可爱、萌动的效果。在描述人物动作时,适当的让肢体动作幅度大一些。
==提示词示例==
全景镜头下,江面上的雪花分三层动态飘落,近景大雪花缓慢旋转着落下,中景中等雪花匀速飘落,远景小雪花呈模糊的飘落轨迹,营造出丰富的降雪层次感。女孩坐在孤舟上,身体随小船有节奏地轻微晃动,斗笠边缘偶尔有小雪花轻轻弹落。她的双发髻随着身体晃动微微颤动,蓝色发簪上的小装饰一闪一闪。睫毛每隔几秒轻轻眨动一次,嘴角始终保持着淡淡的微笑,脸颊上偶尔有雪花飘落,随即融化。她缓缓抬起双手,试图接住飘落的雪花。身着的淡蓝色古风长裙,裙摆上的白色雪花图案随着呼吸微微起伏,轻盈的丝绸材质在微风中泛起细小的涟漪,外面的蓑衣纤维随着身体动作轻轻摆动。钓鱼竿保持静止,鱼线偶尔有轻微的颤动,仿佛有小鱼在试探。光影方面,柔和的阳光透过飘落的雪花,在女孩和小船上投下细碎的光斑,随着雪花的飘落,光斑不断变幻位置,整个场景笼罩在一层温暖的光晕中,凸显出可爱、萌动的效果。
......
==示例结束==
只专注于生成动效部分,不要输出多余内容。视频生成节点 如下: 👇