
第九章 图像描述和特征提取
3. 常用的特征提取算法
前言
一、回顾与引入:我们已经学了什么?
在前几节课中,我们围绕图像的描述展开了学习,包括:
- 灰度图像描述 :如何用统计量(如均值、方差)描述一幅灰度图的亮度分布;
- 边界描述 :通过边缘检测提取图像中物体的轮廓,并用链码、傅里叶描绘子等进行表示;
- 区域描述 :利用连通区域分析图像内部结构,借助形状描述子(如周长、面积、圆形度)刻画目标形状;
- 纹理描述 :用统计和结构的方法描述图像表面的重复模式,如灰度共生矩阵(GLCM)等。
🧠思考一下:这些描述方法帮助我们“看懂”了图像的不同侧面,但当我们想让计算机“识别图中的猫”或“判断图中是否有人”时,我们需要一种更有效的手段 👇 👇
特征提取 :把图像中有用的信息压缩成一组便于比较和分析的数据。
二、特征提取算法
接下来我们介绍四种经典的、广泛应用于实际项目中的特征提取方法,它们各有侧重,互为补充。
| 特征算法 | 主要描述对象 | 核心优势 | 典型应用 | 与前期知识的联系 |
|---|---|---|---|---|
| HOG | 边缘与形状 | 强形状表达能力,抗光照变化 | 行人检测 | 基于梯度 → 深化边界描述 |
| LBP | 纹理 | 简单高效,适合实时纹理分类 | 人脸识别 | 扩展纹理描述的统计方法 |
| Haar-like | 区域灰度差 | 快速计算,适合结构化目标检测 | 人脸检测 | 区域统计量的结构化组合 |
| DoG | 多尺度关键点 | 尺度不变性,定位稳定特征点 | 图像匹配、SIFT | 辅助边界/区域分析的定位工具 |
1. HOG(Histogram of Oriented Gradients)—— 方向梯度直方图
核心思想: 图像的边缘和形状包含了物体的重要结构信息。HOG通过统计局部区域内像素梯度的方向分布,来描述物体的轮廓特征。
🛠 实现步骤:
- 将图像分成若干小单元格(cell);
- 在每个cell内计算像素的梯度大小和方向;
- 根据方向统计梯度强度的直方图;
- 将多个cell合并成块(block),做归一化,增强光照鲁棒性;
- 拼接所有块的直方图,形成最终特征向量。
import matplotlib.pyplot as plt
from skimage import data, color, exposure
from skimage.feature import hog
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负
# ========================
# 1. 加载示例图像(转为灰度)
# ========================
gray_image = cv2.imread(r'./img/dog.png', 0)
# gray_image = cv2.imread(r'./img/car5.jpg', 0) 将这个注释打开,可以看到车辆的效果
print(f"原始图像尺寸: {gray_image.shape}")
# ========================
# 2. 调用 hog() 函数提取特征
# ========================
# 参数说明(初学者友好版):
# - orientations: 梯度方向划分的区间数(默认9,即每20°一个bin)
# - pixels_per_cell: 每个“单元格”的像素大小(如(8,8)表示8x8像素为一个cell)
# - cells_per_block: 每个“块”包含多少个cell(如(2,2)表示2x2个cell组成一个block,用于归一化)
# - visualize=True: 返回HOG图像(可视化用)
features, hog_image = hog(
gray_image,
orientations=9, # 方向分9个区间
pixels_per_cell=(8, 8), # 每个cell为8x8像素
cells_per_block=(2, 2), # 每个block为2x2个cell
block_norm='L2-Hys', # 归一化方式(常用标准)
visualize=True, # 生成HOG可视化图像
feature_vector=True # 输出为一维特征向量(默认)
)
# ========================
# 3. 打印特征信息
# ========================
print(f"HOG特征向量长度: {len(features)}")
# 计算过程:
# 图像大小:
# cell大小: 8x8 → 共有 (512/8)=64 个cell(宽和高)→ 64x64=4096个cell
# 每个block是2x2个cell → 块数量: (64-1) x (64-1) ≈ 63x63? 实际会向下取整滑动窗口
# 更准确:skimage会自动分块并归一化,最终特征数是:n_blocks × n_cells_per_block × orientations
# 但我们可以直接看输出:
print(f"实际提取的特征维度: {features.shape}")
# ========================
# 4. 可视化结果
# ========================
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6), sharex=True, sharey=True)
# 显示原始灰度图
ax1.axis('off')
ax1.imshow(gray_image, cmap='gray')
ax1.set_title('原始灰度图像')
# 显示HOG特征图(增强对比度以便观察)
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10)) # 调整显示范围
ax2.axis('off')
ax2.imshow(hog_image_rescaled, cmap='gray')
ax2.set_title('HOG特征可视化')
plt.tight_layout()
plt.show()🧠 HOG特征图解读:
- 白色线条表示强烈的梯度方向(如边缘、轮廓);
- 线条的方向代表梯度方向(例如垂直边→竖线,水平边→横线);
- 颜色越亮,说明该方向的梯度越强;
- 这张图不是原始图像,而是“结构特征”的抽象表示!


案例2:行人检测
行人的HOG特征特性
| 身体部位 | 典型梯度方向 | HOG响应特点 |
|---|---|---|
| 躯干 | 垂直方向(80-100°) | 强垂直梯度集中 |
| 四肢 | 水平/斜向(0-30°, 150-180°) | 水平边缘明显 |
| 头部 | 圆形边缘→多方向混合 | 梯度方向分散 |

import cv2
import numpy as np
def hog_pedestrian_detection(image_path):
"""
使用HOG特征进行行人检测
参数:
image_path: 输入图像路径
返回:
image_with_boxes: 标注了检测结果的图像
confidences: 每个检测框的置信度分数
"""
# 初始化HOG描述符
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector()) # 使用默认行人检测器
# 读取图像
image = cv2.imread(image_path)
if image is None:
raise ValueError(f"无法读取图像文件: {image_path}")
# 图像预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转为灰度图
# 使用正确的参数名进行检测
(boxes, weights) = hog.detectMultiScale(
gray,
winStride=(4, 4), # 滑动窗口步长 (4, 4)表示每4个像素滑动一次
padding=(8, 8), # 填充 8,8 表示在图像周围填充8个像素
scale=1.05, # 比例因子
hitThreshold=0, # 检测阈值,默认0 表示所有检测框都返回
groupThreshold=2 # 最终阈值(正确的参数名)
)
# 过滤低置信度检测
filtered_boxes = [] # 过滤后的检测框
confidences = [] # 对应的置信度
for i, (x, y, w, h) in enumerate(boxes):
if weights[i] > 0.7: # 只保留高置信度检测
filtered_boxes.append((x, y, w, h))
confidences.append(weights[i])
# 绘制检测框
image_with_boxes = image.copy()
for (x, y, w, h), conf in zip(filtered_boxes, confidences):
cv2.rectangle(image_with_boxes, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示置信度
cv2.putText(image_with_boxes, f"{conf:.2f}", (x, y-5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
return image_with_boxes, confidences
# 测试代码
if __name__ == "__main__":
# 测试图像路径
test_image_path = "./img/streetpeople.png"
try:
# 运行检测
result_img, confidences = hog_pedestrian_detection(test_image_path)
print("检测到的行人置信度:", confidences)
# 显示结果
cv2.imshow("Pedestrian Detection", result_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
except Exception as e:
print(f"检测过程中发生错误: {str(e)}")
📌 特点:
- 擅长描述边缘和形状(如人、车的轮廓)
- 对光照变化不敏感
- 常与SVM分类器(支持向量机)配合使用(用 HOG + SVM 实现行人检测)
实际应用场景:
- 行人检测(如监控系统)
- 手势识别
- 工业产品质量检测
- 交通标志识别
- 生物特征识别
4. MNIST 手写数字识别系统
前言
图像处理系统的一般处理流程: 👇
- 图像采样
- 图像预处理(包括去噪、复原、校正等)
- 图像分割
- 生成训练数据集和测试数据集
- 特征提取
- 建立模型对像(分类、聚类、回归等)
- 训练模型
- 测试模型
- 模型评价
MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28*28像素的灰度手写数字图片。MNIST有四个文件 :
- train-labels-idx1-ubyte:训练集标签
- train-images-idx3-ubyte:训练集样本
- t10k-labels-idx1-ubyte:测试集标签
- t10k-images-idx3-ubyte:测试集样本


在机器学习、深度学习领域,手写数字识别是一个很经典的学习例子。本节通过MNIST手写数字识别来介绍图像识别的一般处理流程,通常包括以下几个步骤:
① 读取训练集和测试集;
② 图像特征提取;
③ 建立并训练模型对像(分类、聚类、回归等);
④ 用模型进行图像识别;
⑤ 模型评价。
# 导入必要的库
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 绘图库
from sklearn.datasets import fetch_openml # 从OpenML获取数据集
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.preprocessing import StandardScaler # 数据标准化
from sklearn.svm import LinearSVC # 线性支持向量机分类器
from skimage.feature import hog # HOG特征提取
from sklearn.metrics import accuracy_score # 准确率计算
import os, math, cv2, struct, time,joblib # 系统、数学、OpenCV、二进制结构、时间相关库
# 设置matplotlib显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为SimHei
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 定义MNIST数据加载函数
def load_mnist(path, labelfile, datafile):
"""
从指定路径加载MNIST数据集
参数:
path: 数据文件夹路径
labelfile: 标签文件名
datafile: 图像数据文件名
返回:
images: 图像数据(二维数组)
labels: 对应标签
"""
# 拼接标签文件完整路径
labels_path = os.path.join(path, labelfile)
# 拼接图像文件完整路径
images_path = os.path.join(path, datafile)
# 读取标签文件
with open(labels_path, 'rb') as lbpath:
# 读取文件头信息(魔数和标签数量)
magic, n = struct.unpack('>II', lbpath.read(8))
# 读取标签数据
labels = np.fromfile(lbpath, dtype=np.uint8)
# 读取图像文件
with open(images_path, 'rb') as imgpath:
# 读取文件头信息(魔数、图像数量、行数、列数)
magic, num, rows, cols = struct.unpack(">IIII", imgpath.read(16))
# 读取图像数据并reshape为(样本数, 784)的形状
images = np.fromfile(imgpath, dtype=np.uint8).reshape(len(labels), 784)
return images, labels
# 1. 加载MNIST数据集
print("正在加载MNIST数据集...")
# 调用自定义函数加载训练集
X, y = load_mnist(r"./mnist", 'train-labels-idx1-ubyte', 'train-images-idx3-ubyte')
# 为了加快演示,只取前10000个样本
X = X[:10000] # 取前10000张图像
y = y[:10000] # 取对应的10000个标签
# 2. 划分训练集和测试集
# 前9000个样本作为训练集,后1000个作为测试集
X_train, X_test = X[:9000], X[9000:10000]
y_train, y_test = y[:9000], y[9000:10000]
# 3. 将图像数据reshape为28x28的二维数组
X_train_img = X_train.reshape(-1, 28, 28) # 训练集reshape
X_test_img = X_test.reshape(-1, 28, 28) # 测试集reshape
# 4. 定义HOG特征提取函数
def extract_hog_features(images):
"""
从图像中提取HOG(方向梯度直方图)特征
参数:
images: 图像数据(三维数组)
返回:
features: 提取的HOG特征数组
"""
features = []
for img in images:
# 提取HOG特征
# orientations: 方向数设为8
# pixels_per_cell: 每个cell的像素数为4x4
# cells_per_block: 每个block的cell数为2x2
# block_norm: 块归一化方法使用L2-Hys
feat = hog(img, orientations=8, pixels_per_cell=(4, 4),
cells_per_block=(2, 2), block_norm='L2-Hys', visualize=False)
features.append(feat)
return np.array(features)
# 提取训练集和测试集的HOG特征
print("正在提取HOG特征...")
X_train_hog = extract_hog_features(X_train_img) # 训练集HOG特征
X_test_hog = extract_hog_features(X_test_img) # 测试集HOG特征
# 5. 标准化特征数据(SVM对特征尺度敏感)
scaler = StandardScaler() # 创建标准化器
X_train_hog = scaler.fit_transform(X_train_hog) # 训练集标准化(同时计算参数)
X_test_hog = scaler.transform(X_test_hog) # 测试集标准化(使用训练集参数)
# 6. 训练线性SVM分类器
print("训练SVM分类器...起始时间:", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
svm = LinearSVC(max_iter=2000) # 创建线性SVM分类器,最大迭代次数2000
svm.fit(X_train_hog, y_train) # 训练模型
print("训练SVM分类器...结束,耗时:", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 如果joblib不存在,则创建joblib文件夹
if not os.path.exists('./joblib'):
os.makedirs('./joblib')
# 7.保存模型
joblib.dump(svm, './joblib/mnist_svm.joblib')
joblib.dump(scaler, './joblib/mnist_scaler.joblib')
print("模型已保存为 mnist_svm.joblib 和 mnist_scaler.joblib 到joblib文件夹")
# 8. 预测与评估
y_pred = svm.predict(X_test_hog) # 在测试集上进行预测
acc = accuracy_score(y_test, y_pred) # 计算准确率
print(f"HOG + SVM 测试准确率: {acc:.4f} ({acc*100:.2f}%)") # 打印准确率
# 9. 可视化部分预测结果
plt.figure(figsize=(10, 4)) # 创建10x4英寸的图形
for i in range(10): # 展示前10个测试样本
plt.subplot(2, 5, i+1) # 创建2行5列的子图
plt.imshow(X_test_img[i], cmap='gray') # 显示图像(灰度)
plt.title(f"真实:{y_test[i]}, 预测:{y_pred[i]}") # 设置标题(真实标签和预测结果)
plt.axis('off') # 关闭坐标轴
plt.tight_layout() # 调整子图间距
plt.show() # 显示图形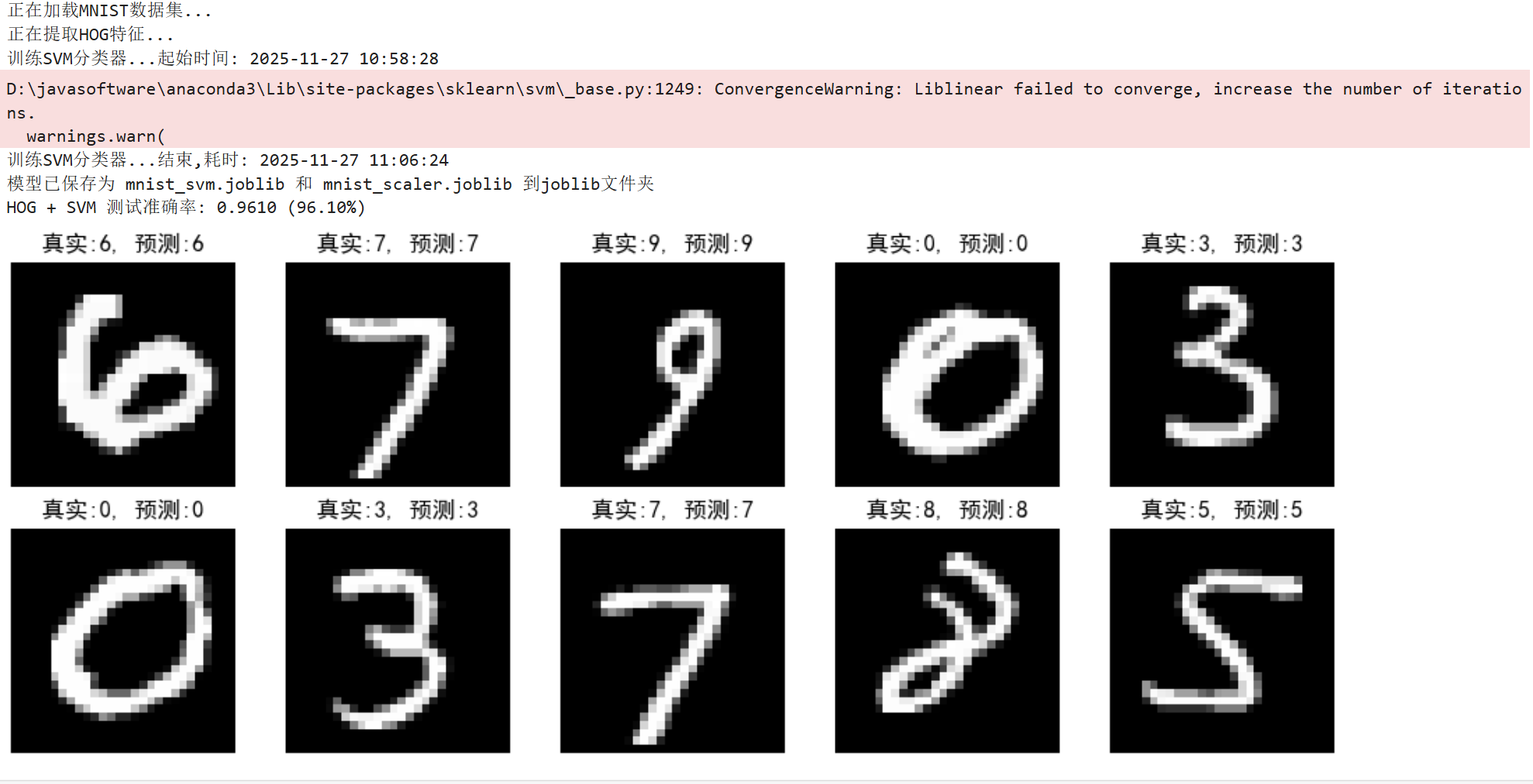
上面训练了数据集并保存模型到了本地,可以看到在原有测试集上,准确率达到了96.1%,这已经非常不错了,但是我们还可以进一步提升准确率
那怎么应用模型来识别我们写的数字尼? 👇 👇

import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 绘图库
from sklearn.preprocessing import StandardScaler # 数据标准化
from sklearn.svm import LinearSVC # 线性支持向量机分类器
from skimage.feature import hog # HOG特征提取
import os, math, cv2, struct, time,joblib # 系统、数学、OpenCV、二进制结构、时间相关库
# 2. 图片识别函数
def recognize_digit(image_path):
# 加载模型 下载资料包包中的资料 jupyter_资料包(图片和模型).zip ,导入到当前目录
svm = joblib.load('./joblib/mnist_svm.joblib')
scaler = joblib.load('./joblib/mnist_scaler.joblib')
# 读取并预处理图片
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
if img is None:
raise ValueError("无法读取图片,请检查路径是否正确")
# 反色处理(如果背景是白色)
img = 255 - img
# 调整大小并标准化
img = cv2.resize(img, (28, 28), interpolation=cv2.INTER_AREA)
img = (img * 255.0 / img.max()).astype(np.uint8)
# 提取HOG特征
feature = hog(img, orientations=8, pixels_per_cell=(4, 4),
cells_per_block=(2, 2), block_norm='L2-Hys')
# 标准化特征并预测
feature = scaler.transform([feature])
prediction = svm.predict(feature)
# 显示处理后的图片
plt.imshow(img, cmap='gray')
plt.title(f"预测数字: {prediction[0]}")
plt.axis('off')
plt.show()
return prediction[0]
# 使用示例
if __name__ == "__main__":
# 首次使用时需要先训练模型(只需运行一次)
# train_and_save_model()
# 识别手写数字图片
# 分别试试 2.png 4.png 6.png 7.png ,7s.png等图片 观察结果
image_path = "./img/7s.png" # 替换为您的图片路径
try:
digit = recognize_digit(image_path)
print(f"识别结果: {digit}")
except Exception as e:
print(f"发生错误: {str(e)}")
注意: 如果识别错误,会不会是你的图片分辨率太大了尼??而训练的参数cell和block设置的太小了尼?
其实除了传统的方法,深度学习方法也非常适合做图像识别,但是深度学习方法的训练速度比较慢,而且需要GPU加速,所以在实际应用中,深度学习方法通常用于图像识别的初级阶段,用于理解图像识别的流程和原理,然后再逐步迁移到实际应用中。👇
| 项目 | 传统方法(HOG + SVM) | 深度学习方法(CNN) |
|---|---|---|
| 特征提取 | 手工设计(HOG) | 自动学习(卷积层) |
| 准确率 | ~90% | ~99% |
| 训练速度 | 快(尤其线性SVM) | 慢(需GPU加速) |
| 可解释性 | 强(知道用了边缘方向) | 弱(“黑箱”模型) |
| 适合教学阶段 | ✅ 初级阶段,理解流程 | ⚠️ 进阶阶段,需一定数学基础 |
| 实际应用 | 嵌入式设备、资源受限场景 | 高性能识别系统 |