
数据仓库与数据挖掘
1. 神经网络与深度学习
神经网络与深度学习
1.人工智能技术演变
不管你关不关注技术,近两年一定被一个词儿深刻地改变了,那就是AI 。但你有没有发现啊,AI圈的新词越来越多了,从DeepSeek、ChatGPT、MidJourney到Transformer、RAG、Agent、MCP,一个个技术术语层出不穷。
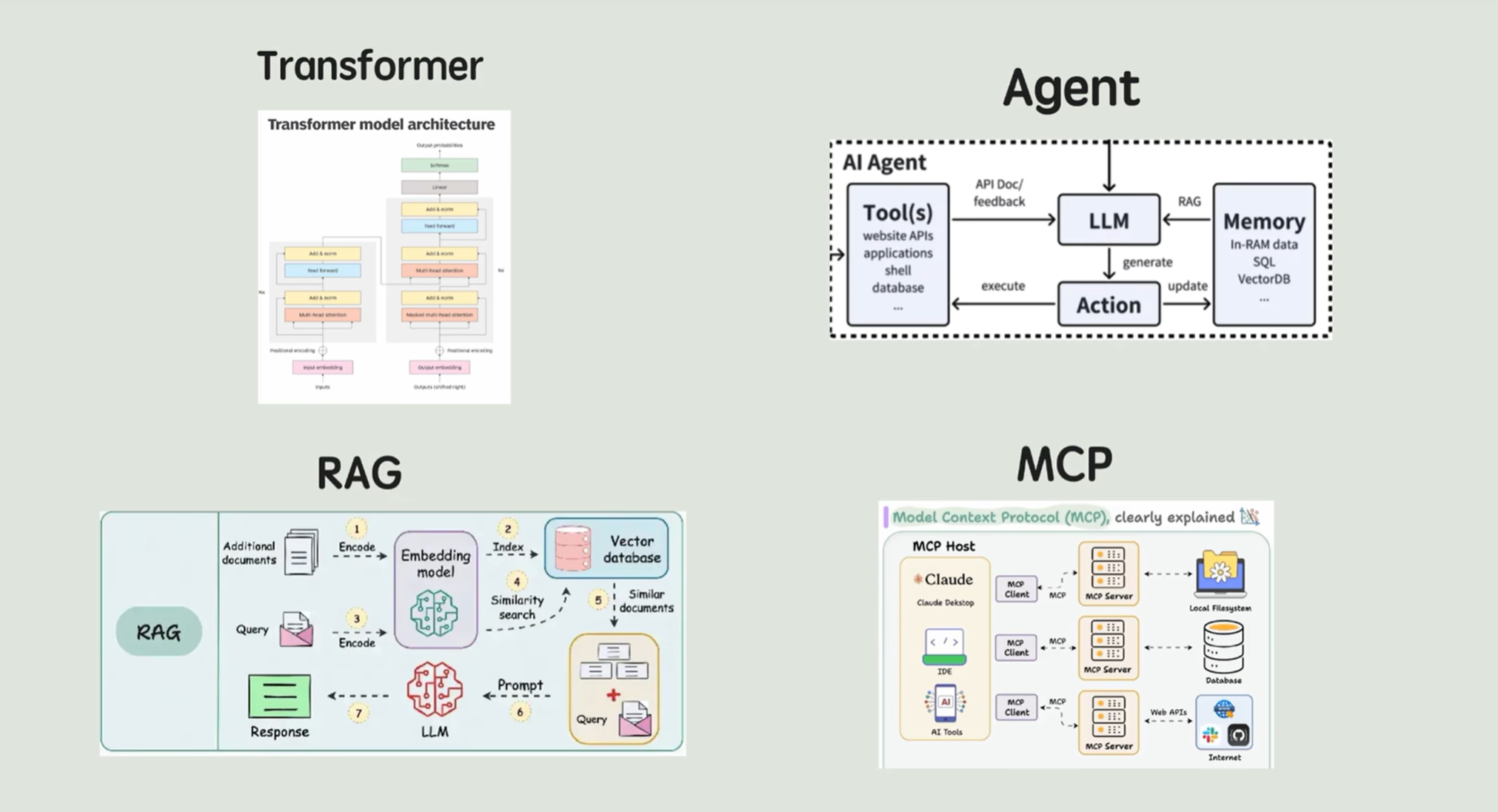
整个AI知识体系实在是太庞大了,接下来我争取用最通俗、最易懂、最直白的语言,给同学们梳理人工智能大模型领域的关键概念、基本原理、底层逻辑,给面向应用的同学做一些必要的技术知识补充。
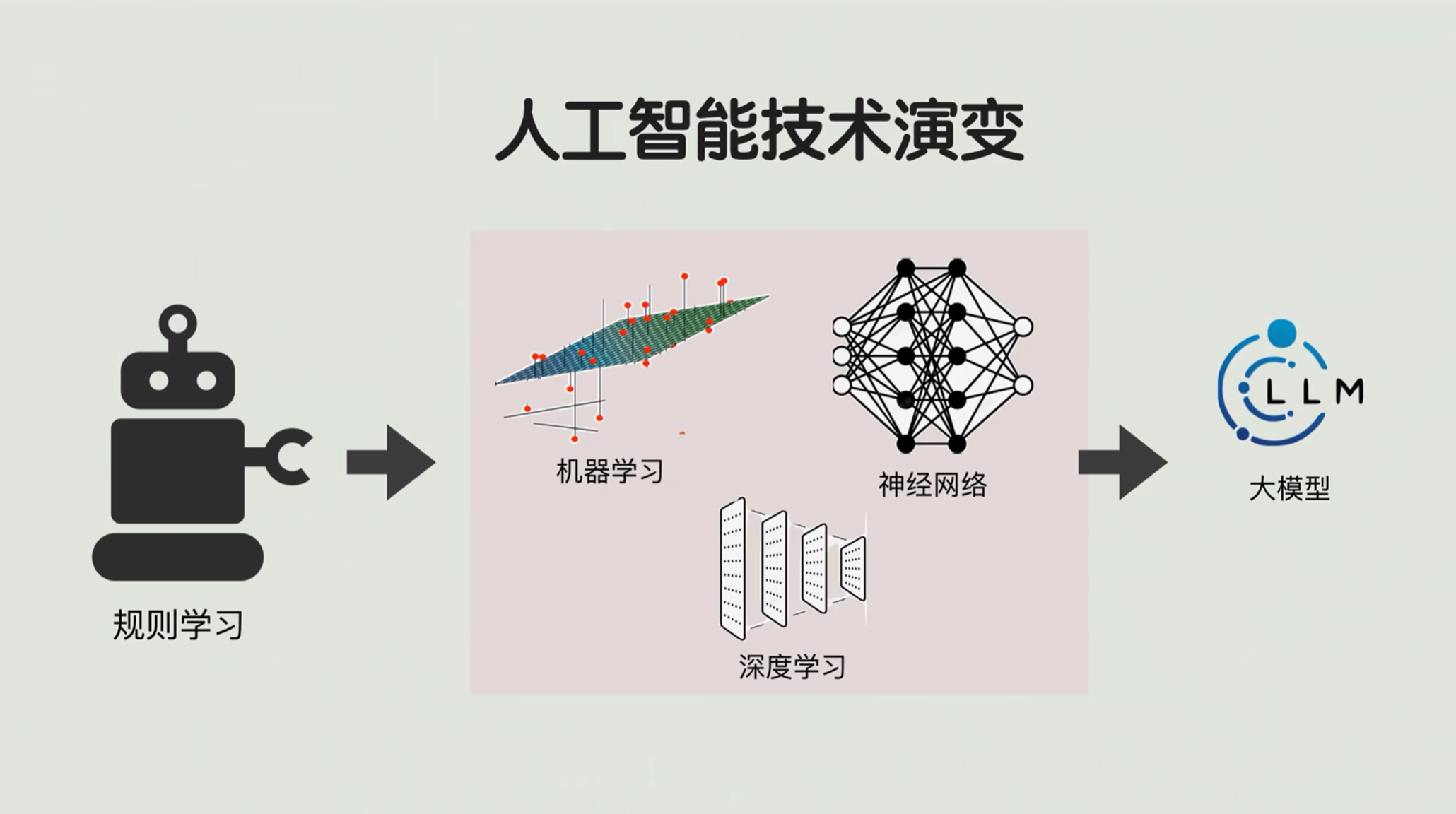
我们从现代人工智能的分水岭——大模型的基础架构深度学习 讲起,扒一扒它的前世今生。相信大家学完以后,会对人工智能、机器学习、神经网络以及深度学习这几个概念有更深的理解。

我们现在所热议的大模型,它实际上是人工智能 的一种。在早期人工智能开始的时候啊,实际上根本没啥智能,更多的就是一个听话的、严格按照规则来走的机器人。

后来随着数据量开始增多,我们的机器学习、神经网络,包括后面的深度学习出现,这些算法才显得越来越智能。等到后面大模型,这个智能的层次一下子就提升了。
接下来,回到早期的人工智能时代,盘盘这一路怎么就从规则识别、机器学习、神经网络,最后演化到深度学习,它每一类算法擅长什么,最后为啥又不行了,我给大家从头说起。
2.早期的人工智能
早期的人工智能,比较机械化。工程师想让他干活,得写非常明确的规则。比如说什么条件下做什么事,做这件事总共需要几步,都要完完全全写明白,一步都不能少。

比如:早年让机器做垃圾邮件识别,工程师就要逐条写规则:
- 含“中奖”算垃圾,
- 提“转账”要标记风险。 🚨
有了这些规则呢,程序就能帮我们抓一部分坏人了。👮

但是要是有另外一些骗子,比如说今天让你去领补贴,明天说有免费体检,那机器还是识别不出来。那么这个规则永远赶不上套路 ,这就是早期的人工智能,虽然能替人做事了,但是举一反一,非常死板。😭

3. 机器学习
这时候机器学习就站起来了,说别写规则了,让我自己学。他的本事就是从数据里面自己找规律。💪 💪 💪
给他一堆垃圾邮件和正常邮件的数据,他就能够总结出哪些特征的邮件是垃圾邮件,哪些是好邮件、正常邮件,那比人写规则可灵活多了,一下子是不是就智能多了? 😍😍

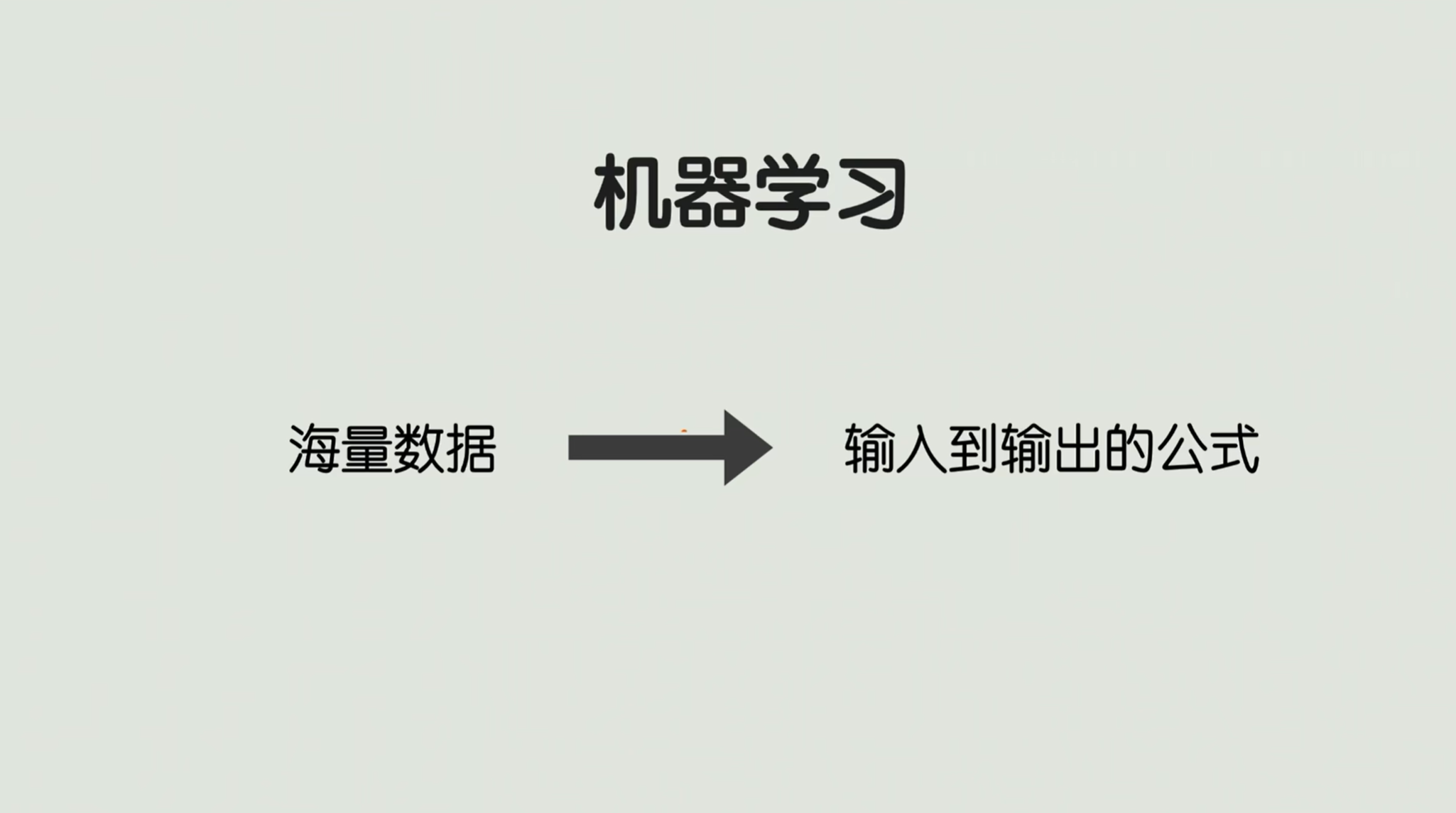
机器学习的本质就是从海量数据里面要学出一个输入到输出的预测公式。 👈 👈
拿演唱会门票价格预测举个例子。比如说你想蹲一蹲你偶像的演唱会的二手票,但是又怕被黄牛坑。就想知道这个内场后排、开场前三天、个人粉丝转手的票 大概多少钱?。

这里就有一些影响票价的信息,比如说座位区域是内场还是看台,距离开场是剩一天、三天还是一周,卖家是个人粉丝还是黄牛,那么输出就是这张票的一个合理的价格。
机器学习就是去广泛地搜集数据,扒遍过去几年同类型演唱会的几万条数据,包括座位区域、剩余时间、卖家类型,以及每一张票最终的实际成交价格。
有了这些数据,它会自动地去算出这些信息和票价的关系。比如我们算出这样一个公式:👇
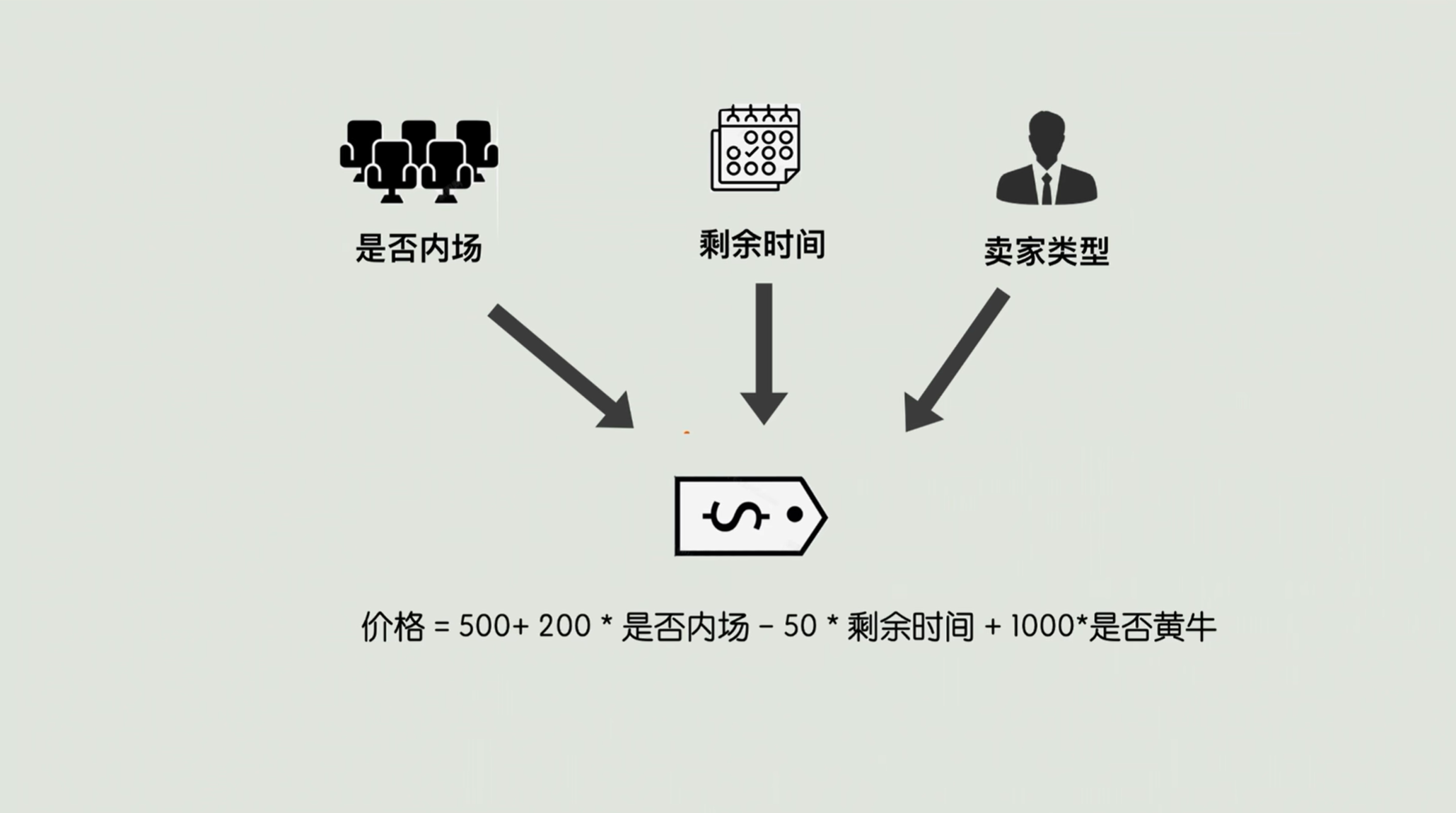
有了这个公式,把特征条件放进去以后,就能算一个大概价格。比如内场、剩余三天、个人粉丝,那么价格就是550。

4.有监督学习
这里给大家举的这个例子,实际上它还有另外一个称呼,叫有监督学习。机器学习一般分为两类:
- 有监督学习
- 无监督学习
那么它们有什么区别呢?
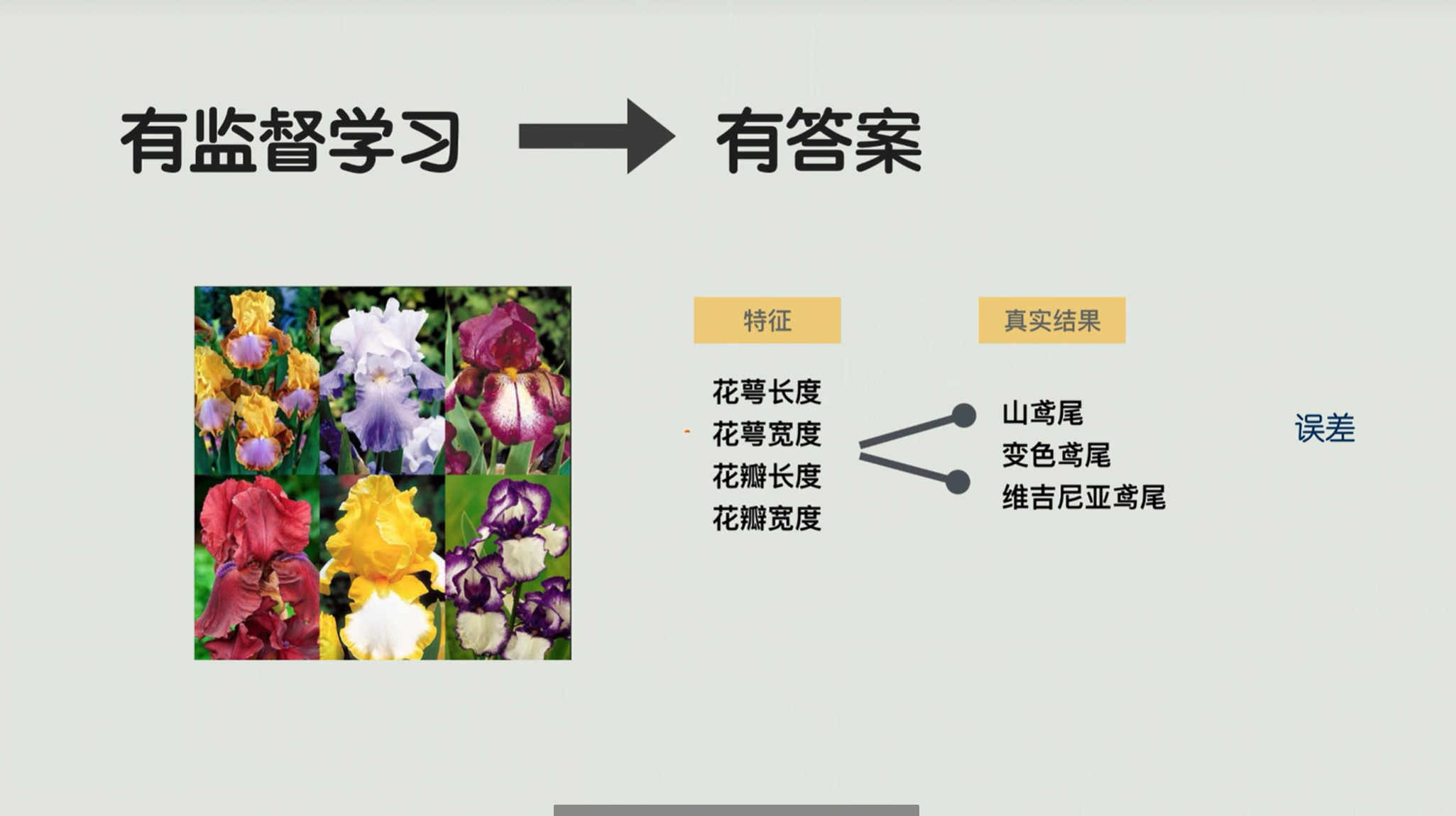
有监督学习最重要的特点就是有答案。

比如说我们搜集了很多花的特征,测量了很多鸢尾花的花萼长度、宽度,花瓣长度、宽度,然后呢还有这些花具体属于哪一种,比如山鸢尾、变色鸢尾、维吉尼亚鸢尾。那么我们这样的数据,它有特征,有真实结果,这就叫做有答案。那么基于这样的数据所训练出的算法,由于有真实的结果,我们就能够给每一个样本去计算一个很明确的误差。
有监督学习,因为有误差的指导,它在调参或者在参数的识别调整方面就非常高效,因为它有答案。
5.无监督学习
另外一个方法叫做无监督学习。相当于我们做思考题,没有答案。典型的无监督学习包括聚类、降维,还有关联规则识别。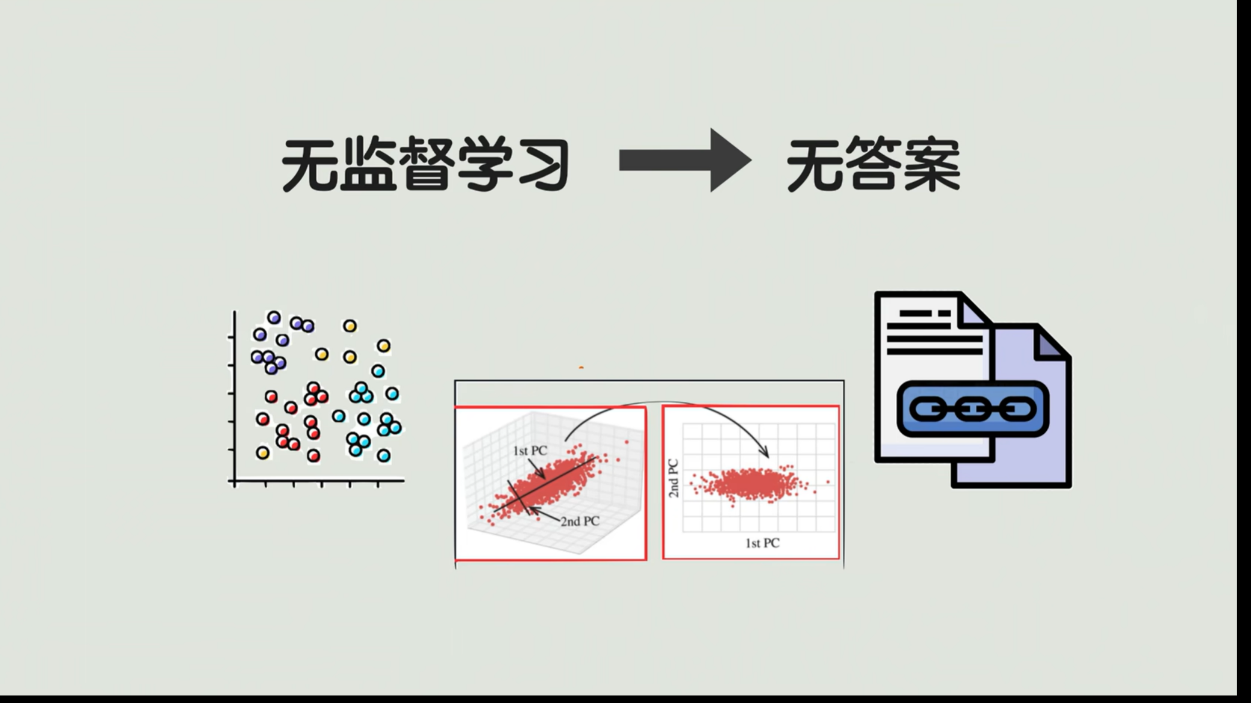
举一个现实中能够用到无监督学习、切实地去产生商业价值的例子。
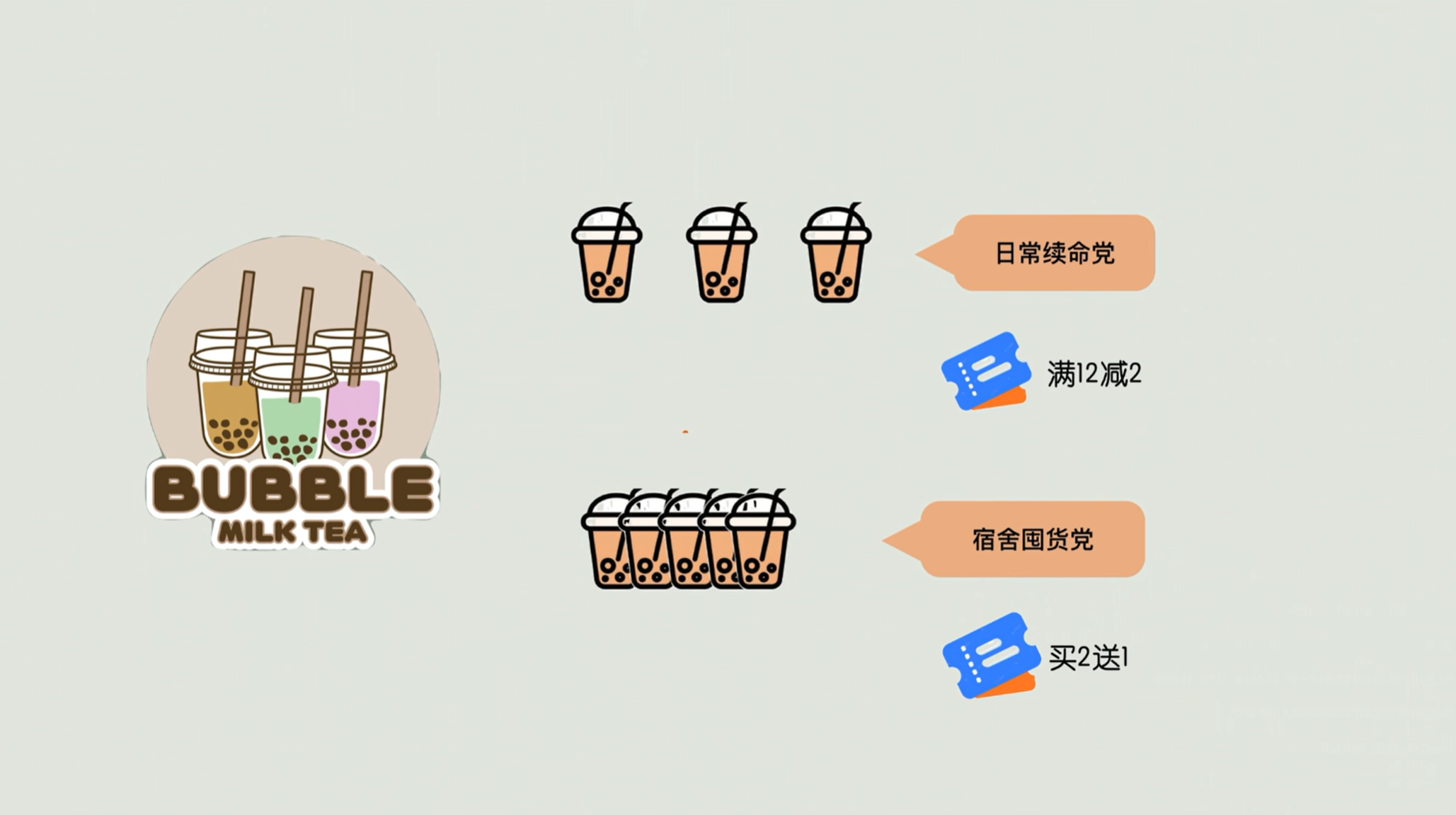
比如你楼下开了一家奶茶店,最近那个电商平台出了很多优惠措施,大家都喜欢去这个奶茶店买奶茶,这个奶茶店就积累到了一堆订单数据。然后他就发现:
- 有些人喜欢每周买三次,每次只点十五元,只点一杯珍珠奶茶;
- 那有另外一些人可能每个月只买一次,但每次就能点五十块钱的全家福套餐。
那机器人就会自动地把上面的两类消费行为归为两类人:
- 第一种叫“日常续命党”,
- 第二种叫“宿舍囤货党”。
那么老板就靠这个信息可以搞精准优惠:
- 比如说给日常续命党一个满十二减二的优惠券,让他们天天想来;
- 宿舍囤货党,有一个买二送一的套餐券,让他们一次就多带几杯,生意直接火到排队。
这就是无监督学习,是聚类分析在商业的一个非常经典的应用。
机器学习看起来够智能,但慢慢的他再见大世面就又不行了。传统的机器学习有一个明显的短板,就是它只能处理结构化数据。
结构化数据就是那种能放在Excel里面规规整整的数据,有横行有竖列,横行表示我们很多对象或者是很多观测,纵列来表示这个对象多个维度的特征。
随着图像数据、音频数据、视频、文本这些数据出现的时候,机器学习的这个短板就很明显了。比如一张猫的照片,全是密密麻麻的像素点啊;那么一段语音,都是一些波动的声波信号,就很难再去提取这特征一和特征二。
那要让我们传统的机器学习来处理这些数据,就得靠人手动提取特征,比如说我们用图像来识别猫,你得去自己告诉猫有没有尖耳朵,有没有圆眼睛,把这些特征再转换成数值。这种手动提取特征,不仅慢,而且容易漏掉关键信息,比如说猫的毛色深浅、胡须长短,我们人可能没注意,但对于机器认猫来说特别重要。
那这时候,传统的机器学习就非常局限 。

5.神经网络
此时大名鼎鼎的神经网络就出现了。它就是传统机器学习的一个升级版,主打让机器自己提取特征,不用人瞎掺和 。

顾名思义,就是模仿咱们人脑中的神经元结构去进行模式识别和特征提取。它自动能够从我们原始的图像数据中提取特征,最终能够输出对于这幅图像的一个判断。

那么具体它是怎么做的呢?我们用这样一幅图来为大家解释原理👇
首先我们会将猫或者狗的图像输入到神经网络里,图像在计算机里面一般会被转化为一种数值矩阵,比如像素值的矩阵,作为网络的初始输入数据。
然后中间会经过若干个隐藏层,自动地去把特征进行提取和转化。比如:
- 低层的隐藏层,可以提取图像的基础特征,例如猫或者狗的毛发、边缘、轮廓、线条、纹理等等;
- 中间的隐藏层,可以去在底层的基础上提取更复杂的特征,比如说猫的耳朵形状啊、狗的脸型轮廓等等;
- 高层的隐藏层,则一般进一步会整合中间层的特征,提取更抽象、更具有区分性的特征,例如猫的一个整体形态,或者是狗的一个外貌特征,例如这个狗的鼻子形状,或者是它的耳朵的一个下垂状态。
这些隐藏层通过大量的参数调整 ,就能不断的学习出怎么样区分出猫和狗的那些关键特征。
最后进入到输出层,就会基于前面提取的特征,给出是猫还是狗的一个判断结果。

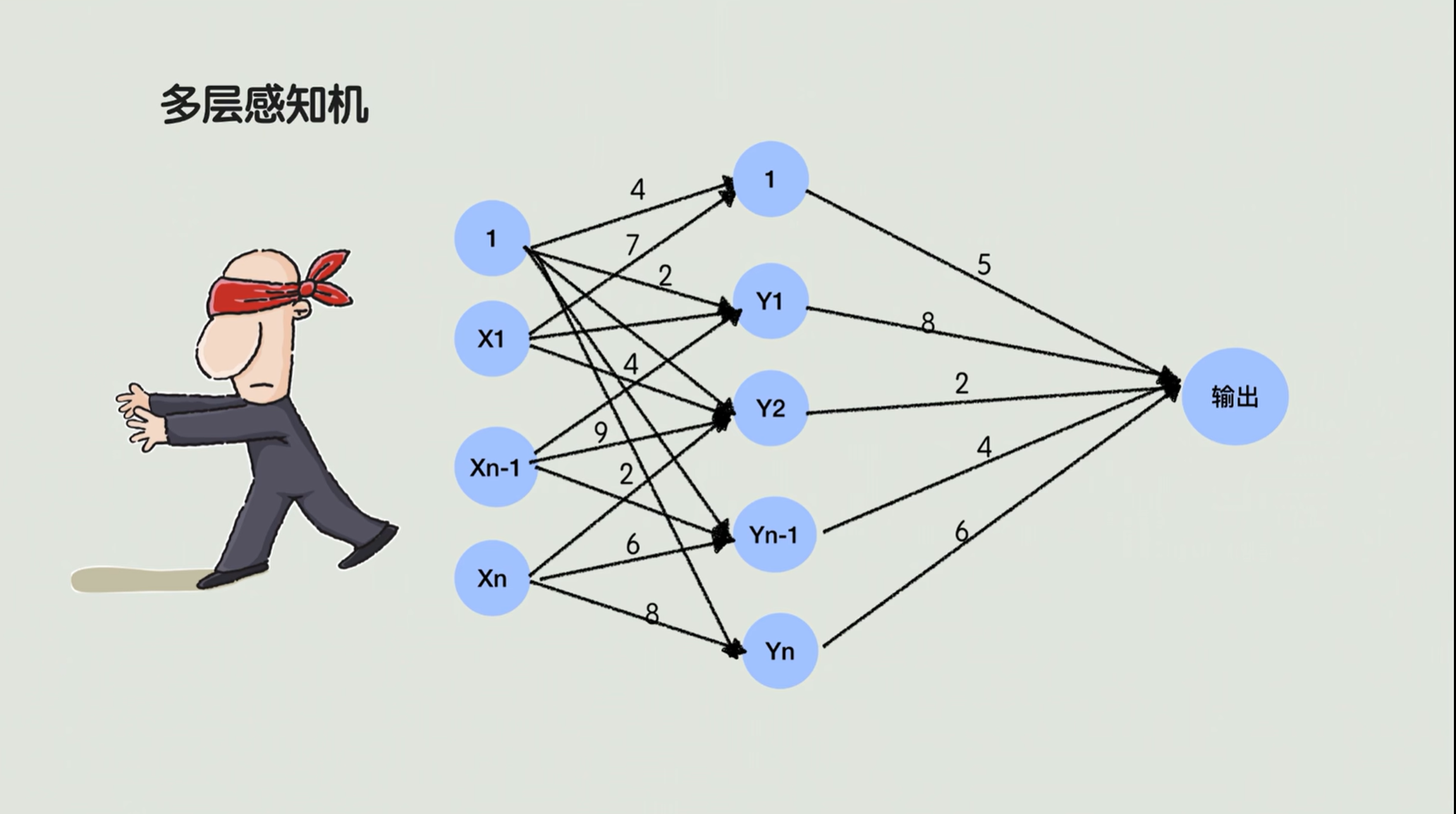
6.单层感知机
现在的神经网络是非常的智能,但是早期的时候其实特别菜。最早叫单层感知机 ,也就只有一层神经元。这几个神经元工作就是把输进来的特征量通过一个线性加权做一个求和,然后输到一个激活函数里面,把这个线性求和最后转化成一个0 /1 的二元结果。
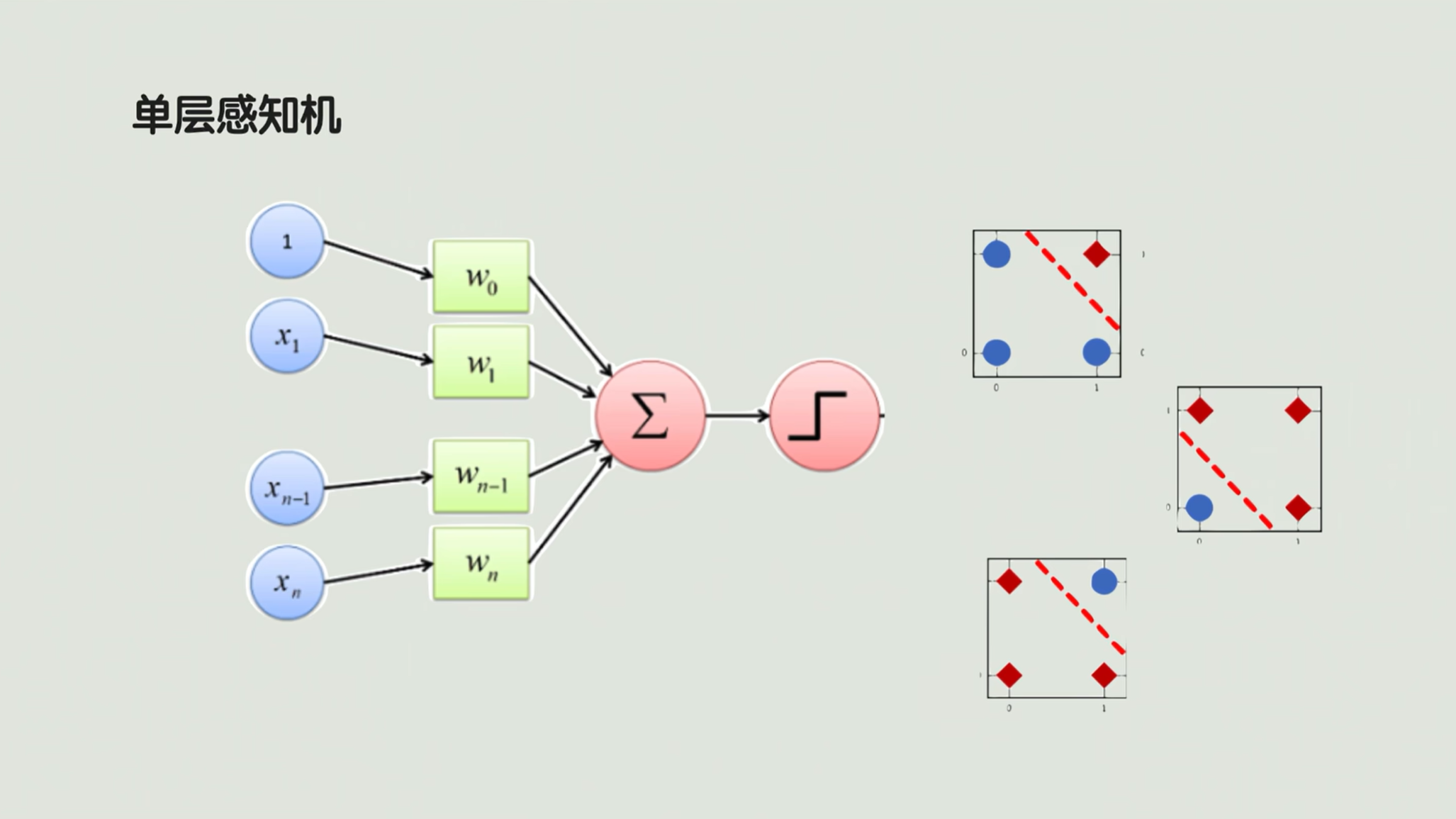
单层感知机其实更擅长的是做一个线性分类,也就说它只能解决线性可分的问题。
如果我们遇到异或问题 ,如下图👇,如果出现这样的聚类模式,我们线性就很难给它区分开了,用一条直线很难画出来。那怎么办呢?
有些人就想了,我能不能做一个变换,把这些难分的点呢去换一下它的位置,比如把红色点往上移,把蓝色的点往下移,这时候再用一条直线是不是就可以轻松分开了? 但是这个拉点 的操作,单层感知机是做不了,因为他没有处理点位置的中间环节。
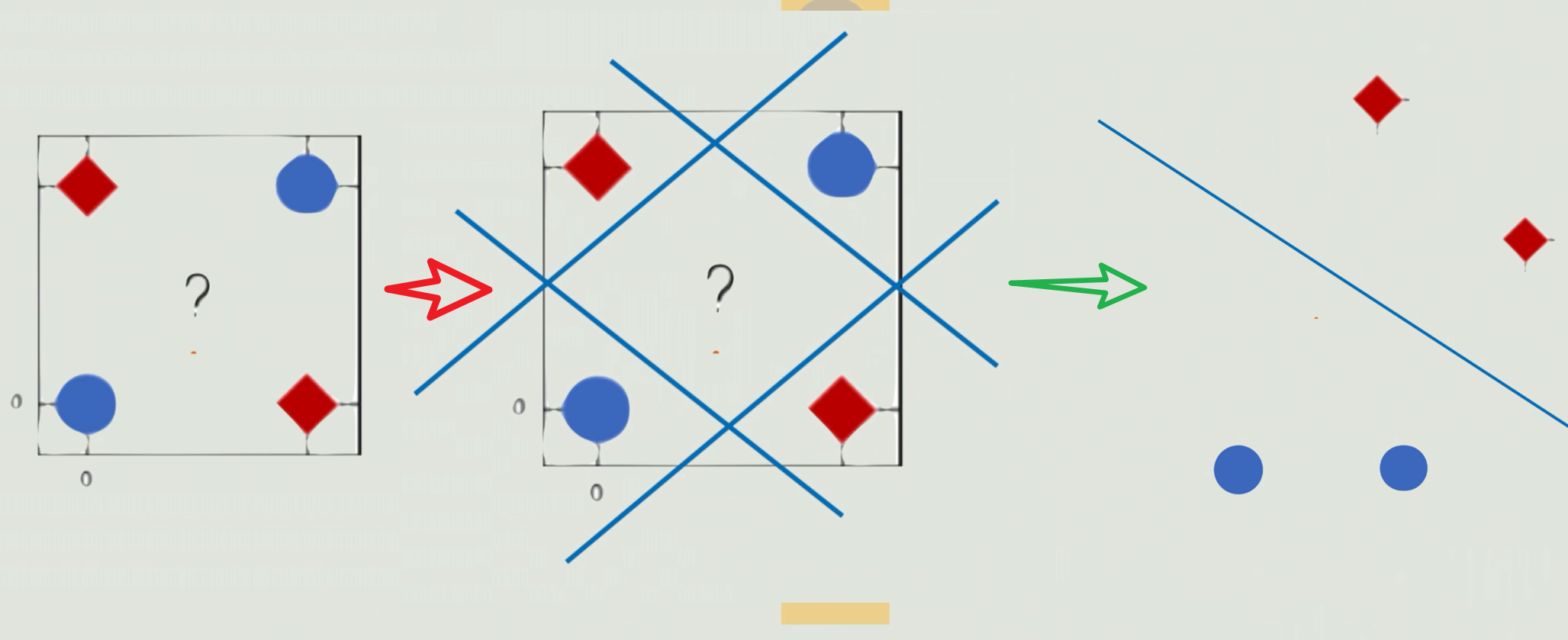
这时候多层感知机就提出来了,因为他加了一个隐藏层。就专门做我们刚才说这个拉点 的活。在单层的感知机中间呢会加入一个隐藏层,把原始的特征做进一步的转化,然后才进入到最后的输出。比如把原始的x、y转换成x+y、x-y这样的新特征,那就相当于把它映射到了一个新坐标系下面,然后再用一条直线在新的坐标系去划分,完美!这就是多层感知机的一个雏形。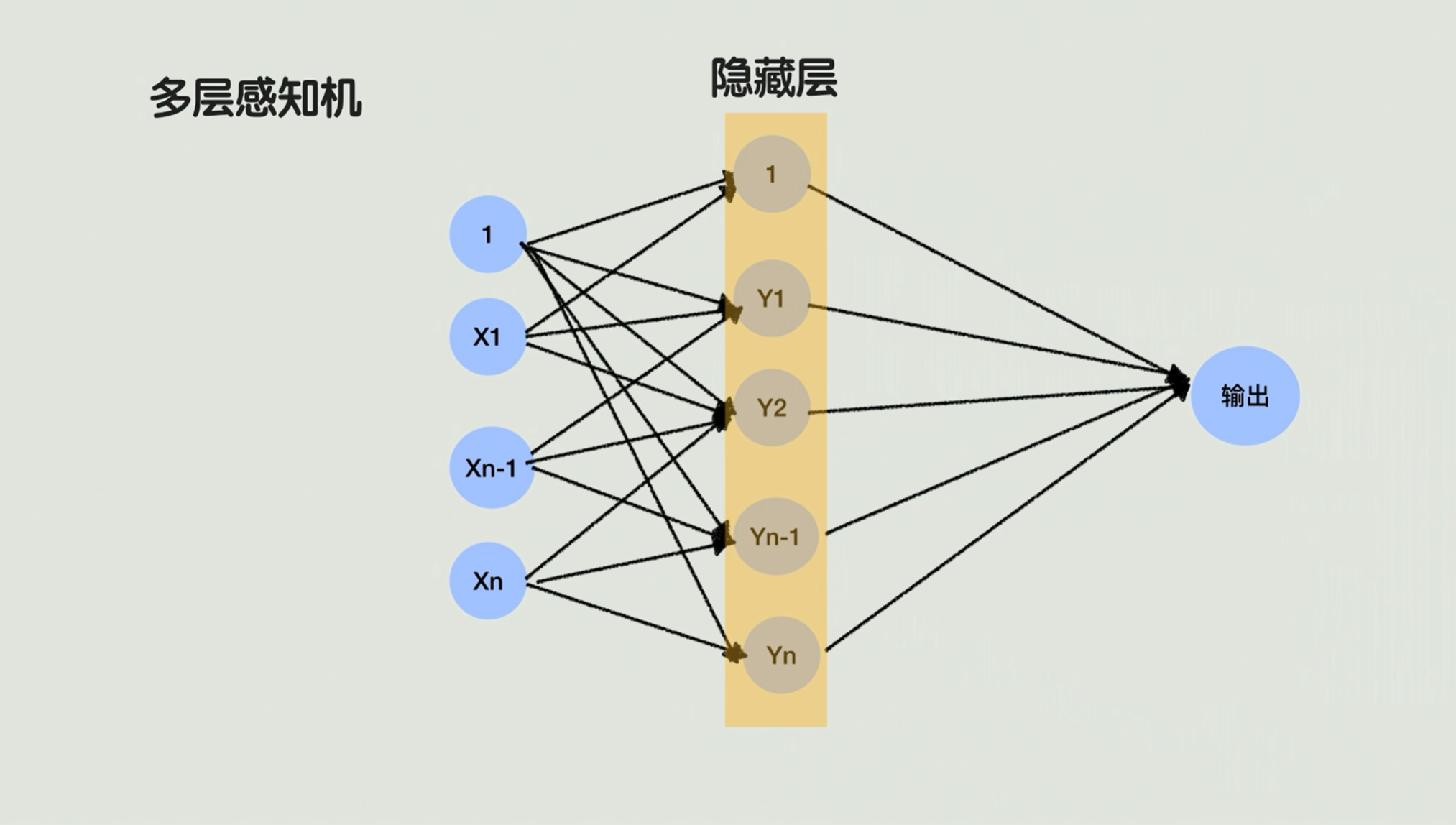
7.多层感知机
有了多层感知机的这个架构,现在想问的是,不同层级的权重怎么估?这个权重相当于什么呢?
可以理解为:做题时候的一个解题步骤啊,它要确定我们怎么样去变换原始的特征。比如说第一步要算x+y,第二步要x2,第三步要-1,
那么每个步骤的系数就都是权重,那要让模型算对,就得让这些权重刚好能凑出那个能分对异或点的步骤。s
早期的调权啊,全靠瞎蒙。比如说我们先随机设了一组权重,算出来发现没有分区分开,算错了。那我们并不知道是x加y这步错了,还是乘以二这步错了啊,那我只能再换一组权重。
就像学生做错题了,不知道哪一步,只能从头瞎改。哪怕只有几十组权重的一个简单多层感知机,要想能正确划分出结果,试出那个权重,也得耗费大量时间,就更别说后来几百几千组权重的模型了。大大地限制了这个多层感知机的一个应用。
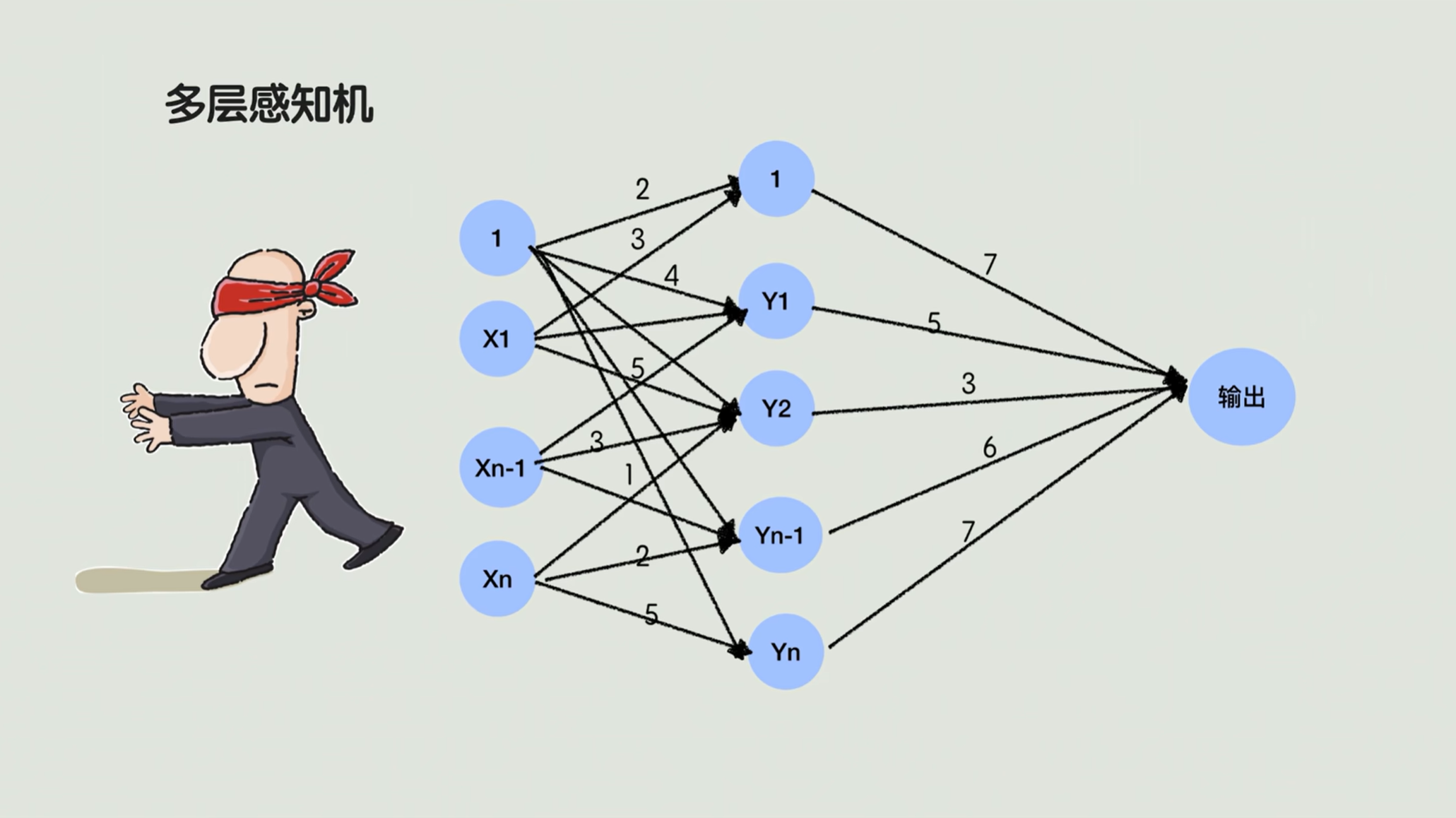
8.BP算法
直到一个人的出现,号称我们深度学习之父的杰弗里·辛顿(Hinton),一九八六年提出重磅的反向传播,也就是BP算法
- 反复去做这个三步,直到误差小到可以接受,权重就固定了,我们整个模型就训练好了。

它的核心就是给调权重加了个导航,相当于给我们刚才那个步骤加了一个错题的批改指南。
简单点的说:
- 第一步要先随机设定一个权重,做正向计算。比如说我们要预测一个房价,你发现按照你这个随机的权重,预测出来是一百万,但真实的房价是一百二十万,那么我们第一步要算出这个误差是二十万。
- 第二步反向传播,把二十万的误差往输入层去传啊,就像我们老师批改作业,从后一题往回找错因,看看是哪个权重导致了这个误差。
- 第三步,就要调节权重,让权重去往这个能减少误差的方向去变。比如某个权重能让误差变大,那就调小它;某个权重能让误差变小,就调大它。

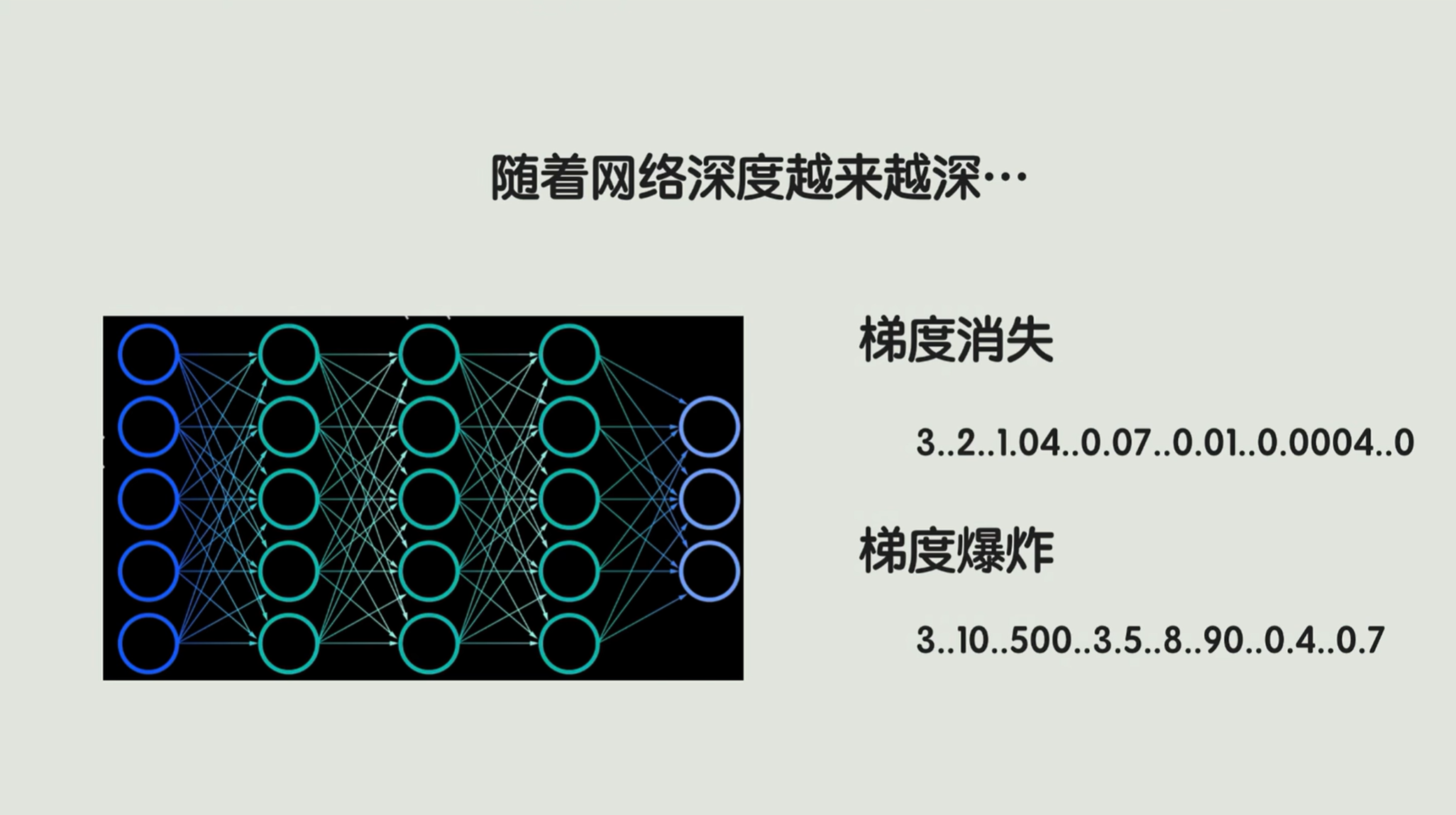
有了这个算法,神经网络的权重的效率就大大提升,能够训练的网络层数也越来越深。这让科学家们很兴奋,就网络层数给不断地上,网络节点给狠加加加,没别的,就是越整越复杂。
可是呢,随着训练的网络深度越来越深,诡异的事情发生了. =====> 当神经网络增加到一定层数的时候,会突然遇到一种叫做梯度消失或者梯度爆炸 的问题。
啥是梯度?简单理解就是调整我们权重的一个方向和幅度。刚才误差反向传播的时候,其实就是在传梯度。所谓梯度消失,就是梯度传着传着变成零了,最后的权重都变成零了,没法调,模型就摆烂了。
那梯度爆炸跟他正好相反,就是模型会变得特别不稳定,权重变得特别大,那预测结果也跟着乱跳。比如说预测房价,输入稍微变一点,输出就能从一百万跳到一个亿,那非常不准确,根本没法用。
9.深度信念模型
因为梯度消失和梯度爆炸的问题,科学家们又蔫了啊。因为如果我们网络深度训练不深的话,其实会大大地限制我们可以解决问题的难度。
那么时间又过了十年,还得是这位Hinton,提出了几乎拯救神经网络架构的算法——深度信念网络(现在叫Deep Learning)。这个训练算法的提出,让我们神经网络可以搭载的层级直线上升,彻底突破前面BP算法的一个复杂度限制 。
他是怎么估计的呢?简单来说,就是一个预训练加微调的技术。了解过一点大模型知识的同学,是不是对这两个词并不陌生?
具体是这么做的:
- 这是一个神经网络,要把训练过程分为两步。第一步,要先给神经网络做一个逐层预训练,那就像我们盖楼,要先把每一层架构单独搭稳。把深度网络拆成一个个小模块,比如说十层网络,我们先练输入层和第一层隐藏层,用无监督学习让这两层练会抓数据基础特征,比如说去认我们猫的头像,先去学它的边缘线条。然后把第一层练熟之后当做新输入,再和第二层模块接着练,一层一层垒地基,就避免一上来全部训练、全部层一起训练权重就乱掉。
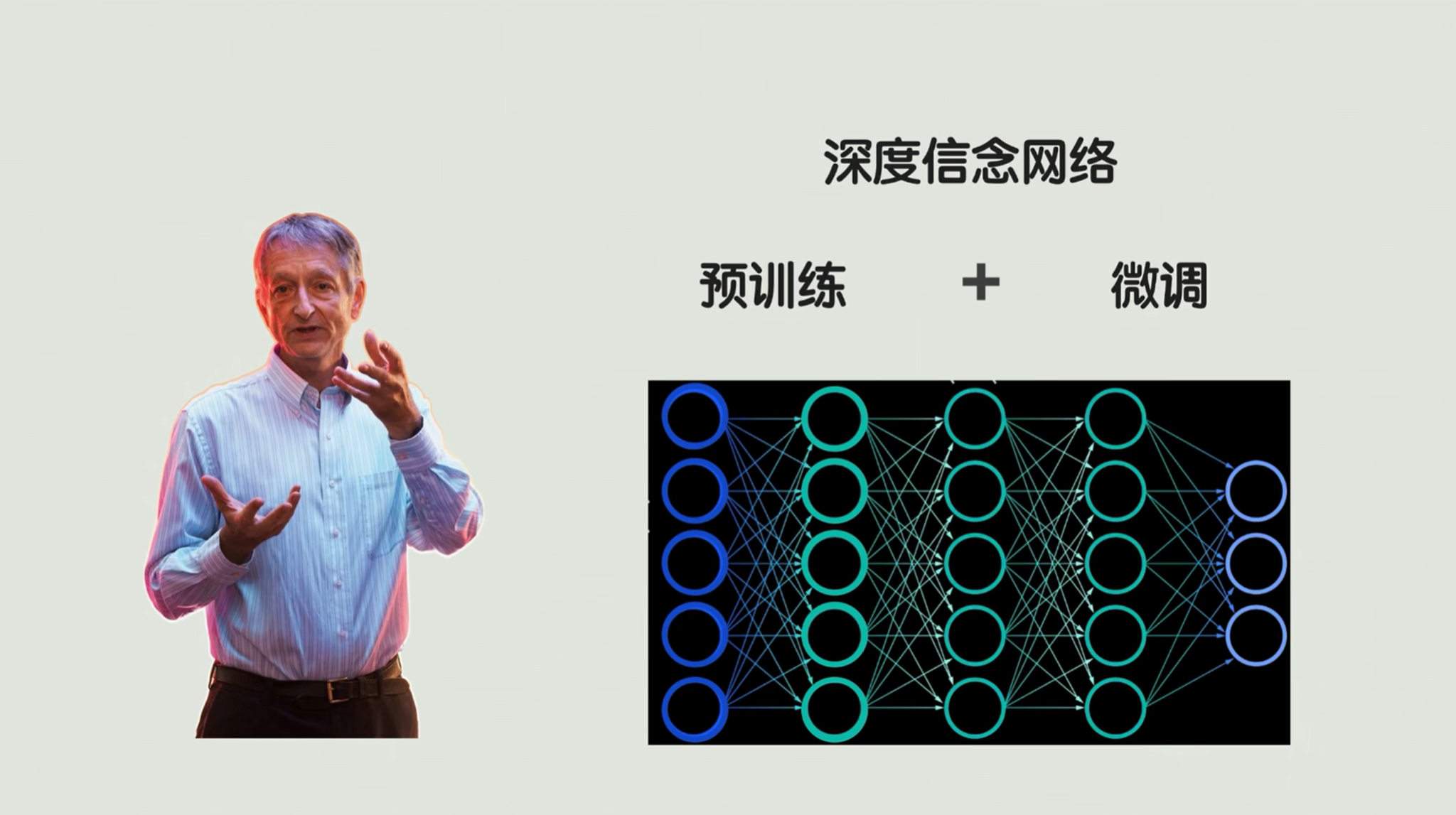
等每一层都扎实了,再用BP算法去整体微调。那么此时,由于我们权重有了一个比较靠谱的初始值,梯度就不容易产生消失或者是爆炸的问题,能够精准调参。这个时候,就能让网络扛住十层、一百层的深度,深度学习这概念也正式诞生。👍
我们可以用它处理做人脸识别、语音识别,还有智能客服。那么我们现在这些比较普及的应用,其实背后全是深度学习在干活。
咱们已经把AI、人工智能、机器学习、深度学习的关系理得明明白白了。我们总结了一下:
- 人工智能 是一个最广泛的概念,它的目标是让机器人能够模拟人类的感知、推理和学习等智能行为;
- 传统的机器学习 是一类擅长处理规规整整的、有明确特征的结构化数据;
- 神经网络 是一种新型的机器学习方法,一种能够从图像、音频这种非结构化数据中提取特征的模型结构;
- 深度学习 是现在机器学习的一个主流方向,它的核心就是去构建一个深层的神经网络,层层递进去挖掘数据里面更复杂、更抽象的特征,让机器越来越智能。

10.擅长领域
深度学习这么强,最擅长的领域还是图像识别。有一个比赛大家可能听过,号称图像识别领域的奥林匹克大赛——ImageNet.
这个比赛用的数据集非常庞大,包括了超过一千四百万张图像和两万多个类别,而且它有一个非常高质量的标注,也就说它有一个很明确的监督信号,因此成为各种深度学习算法、机器学习算法所测试它性能的一个非常有名的比赛。二零一二年以前,大家所测试的各种算法在这个数据集上表现平平,这个模型的识别精度非常有限,误差率居高不下。直到二零一二年,Hinton带着他的学生团队,推出AlexNet,它作为一种深度卷积神经网络,在当年的大赛里面直接杀疯了,成绩比第二名高出41%,误差率大幅降低。这一个架构的提出,直接就让深度学习在图像领域C位出道。那么各大科技公司也开始重视深度学习,并广泛应用起来。

说到这儿,可能有同学有疑惑:既然早期深度学习在图像领域封神,怎么后来突然就能够读报纸、写报告,甚至能批改作业,在文本领域也爆火了呢?

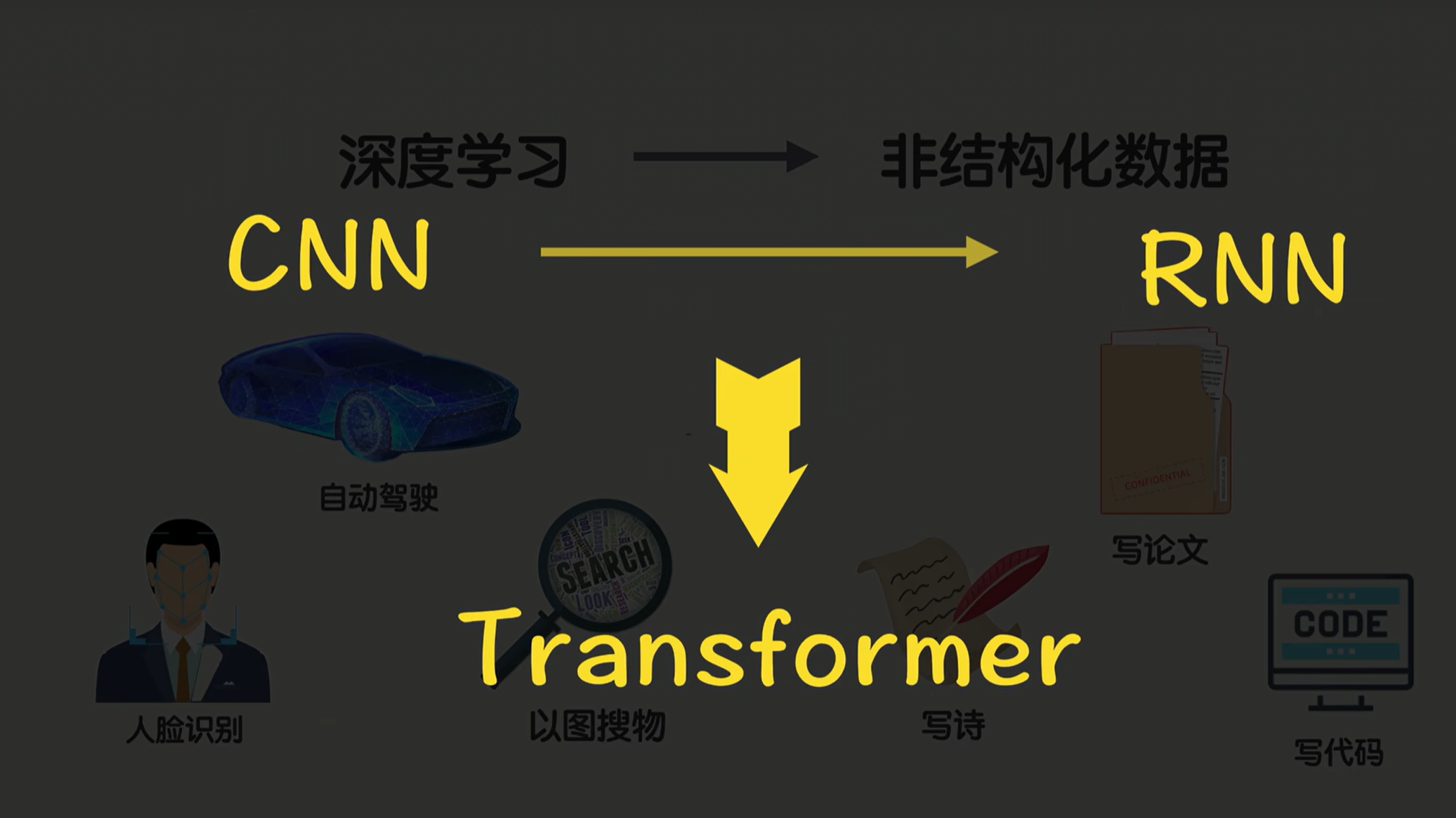
我们有时间就带大家聊一聊深度学习是针对图像、文本的不同特点设置专属模型的,两大明星网络CNN、RNN分别是什么,后来又是怎么引发改变AI格局,也就是当今GPT的底层架构Transformer强势崛起的。

2. CNN和RNN
前言
1.引言
上一次我们学习了深度学习解决了非结构化数据的特征提取问题,开启了AI发展的新阶段。但大家有没有发现一个奇怪的现象,AI最早是在图像数据上火起来的,人脸识别、自动驾驶、以图搜物,这些应用已经不知不觉地融入了我们生活。可直到这几年,AI才突然变得会聊天了,写诗、写论文、写代码样样都行。
那问题来了,为什么图像AI早早就崛起了,而会写字说话的AI却来的这么晚呢?
接下来揭开这个谜底,带你从CNN、RNN一路走到Transformer,看看AI到底怎么一步一步学会听懂人话的。👍
2.CNN
先来看一张照片,它本质就是像素的排列,但我们人眼为什么一看就知道这是猫啊?因为我们能抓住关键特征,比如说我看到尖耳朵、圆眼睛、毛茸茸啊。

那么AI就也学会了这一招,于是CNN卷积神经网络就诞生了。首先他像一个抓特征的猎人,用一个个的小探测器在图片上划来划去,这些小探测器的学名叫卷积核 。比如有个探测器专门找边缘,有个探测器专门找眼睛,有个探测器专门去找毛发纹理。他每划到一个地方,就要打个分,比如说这里像耳朵吗?这里像眼睛吗?匹配度高的话呢,它就亮红灯,匹配度低呢它就灭灯。那这个过程就叫卷积 x,他用小窗口扫描全局,去抓局部特征。

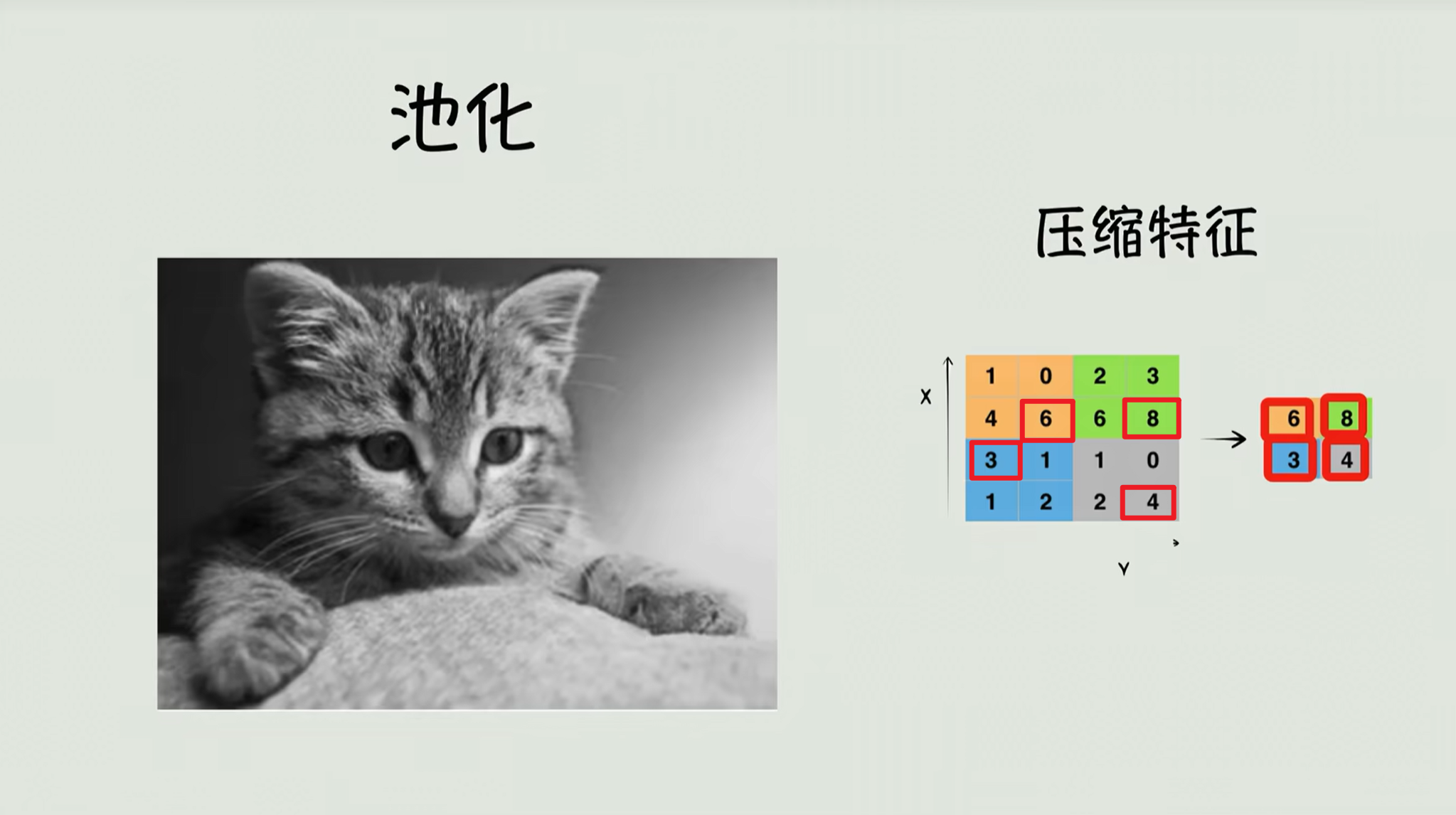
卷积神经网络还有另外一个操作叫池化 ,简单说来就是压缩照片。比如我们把像素矩阵的四个格子缩小成一个,只保留那个最亮的值,这样呢图片变小了,计算也变快了,但关键信息还都还在。就这么2个步骤。
CNN的经典网络AlexNet在2012年的ImageNet大赛上,直接把错误率干到了15.3%,大家知道,这个错误率可是比我们人眼识别照片的错误率都还要低。手机里的美颜、扫码自动对焦,背后都是他在干活。

但是CNN有一个致命的问题:看不懂文字 。为什么?

因为我们的文字它不是局部特征的组合,而是顺序决定意义。比如说我们看“我吃苹果”和“苹果吃我”,词一模一样,但顺序一换,意思天差地别。前面就是一个正常的剧情,后面就是一个科幻甚至恐怖的剧情。

CNN是不管顺序,他会把一个句子当做一个词袋子来处理,自然就傻了。于是专门为序列设计的RNN ,循环神经网络上场了。

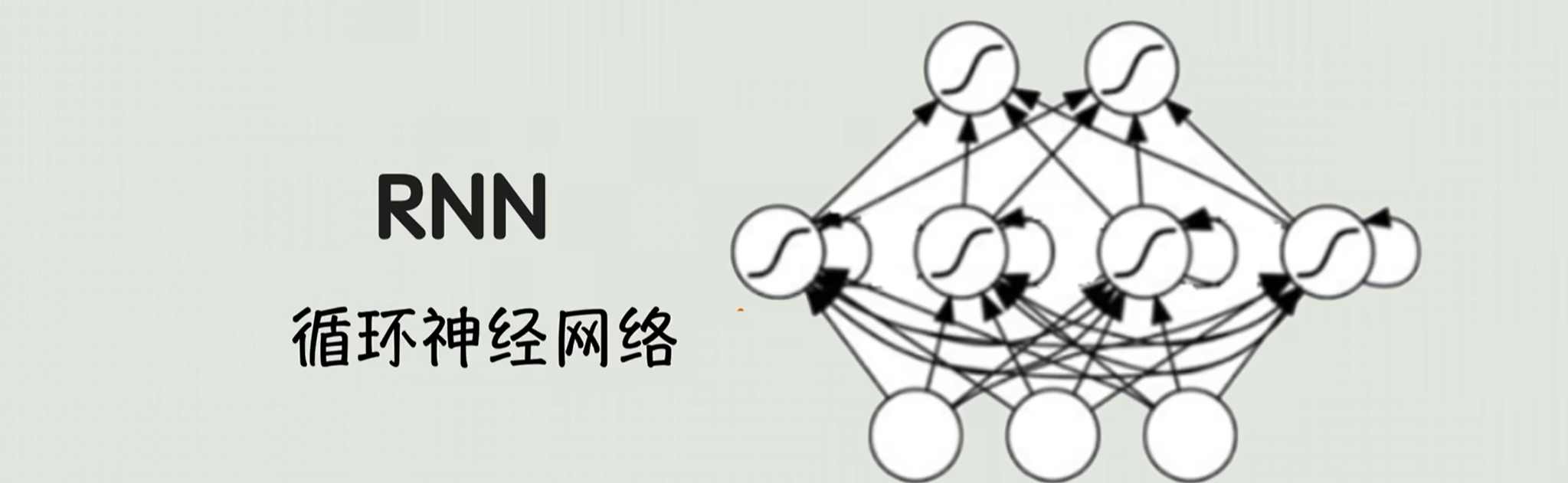
3.RNN
循环神经网络RNN的核心思想特别像人一边读一边记笔记。
比如他看到“我吃苹果”,那就先读“我”哎就记下来,就主语是我;
再看到“吃”,结合前面的笔记,就知道是我在吃;
最后看到“苹果”,他就继续推我吃的对象是苹果。
那么这个笔记的学名叫隐藏状态。

RNN在处理文本时,它会按照词的顺序一个一个算,每处理一个词呢,就把这个词的信息存到隐藏状态里,下一个词的计算必须要用到这个隐藏状态。所以我们的RNN可以干摘要、翻译、写摘要、判断情感,早期NLP就全靠它。

但是RNN也有两个大毛病。第一太慢了 ,它必须一个词儿一个词儿算,不能并行计算 。1000个字的文章,它必须得等前面999个词儿算完,才能推到第1000个,这扛不住大数据啊!!!

第二个特点就是记性差 ,这个太长的句子,它开头的信息传到结尾就忘了。比如这句话:“他昨天去超市买了牛奶,因为他孩子喜欢喝什么啊?”那他看到“喝”,等到要填的时候,他可能早就忘了孩子是谁,就填不出牛奶。
这个问题叫做长距离依赖问题 ,也就是说RNN,记不住前因,所以文本的AI就一直被卡在这里。

4.Transformer
直到2017年一个王炸出现,当年谷歌就甩出一篇论文《Attention is All You Need》,也是现在学大模型的一个奠基性的文章。那么他就提出了一个全新的架构Transformer ,直接解决了RNN的两大难题,还成了现在所有大语言模型的地基,相当于我们AI界的奠基石了。 666666

为什么这么牛?注意力 。Transformer提出了一种叫做注意力机制的这样一种设计。就我们人在看一幅图或者一段文字的时候,是不是会一眼就抓住关键部位,从而快速的进行模式识别,比如说认出这个是个兔子。而注意力机制让机器会像人一样抓重点,能够给更重要的词更高的关注度的权重。
比如说谈到一句话“我爱中国,你呢?”
比如说翻译“爱”这个词的时候,注意力会先计算“爱”和其他词的关联度。
比如说他看“爱”和“我”相关吗?相关还是主谓关系,就是高分;
那“爱”和“中国”相关吗?相关它是动宾关系,它是爱的对象,高分;
那“爱”和“你”相关吗?这关系不太大,所以低分。
这样一来,我们机器在翻译“爱”的时候,就会重点关注“我”和“中国”,然后给其他无关的词语它的权重就更小。

注意力机制还支持并行计算。
比如说处理“我爱中国”这四个词儿,他能一次性算出“我”和“爱”“中国”的关联度,“爱”和“我”“中国”的关联度,以及“中国”和“我”“爱”的关联度啊,不用等前一个词儿算完。
就好像是这个从单窗口办事,变成多窗口同时办公啊,这是计算机领域的最多跑一次,这个文本处理速度直接提升好几个量级。RNN这个无法并行的问题被Transformer解决了。

但又一个问题来了,如果所有的位置一起算,怎么知道顺序?
比如怎么样避免“我吃苹果”和“苹果吃我”这个没有办法区分的困境呢?
这样一来机器算的又快又准,直接就解决了RNN的痛点。

Transformer给的办法很巧妙,他会给每个词加一个座位号。比如说“我吃苹果”这个短语,他会给“我”编一个位置,给它一个编码,比如说0.01、0.9就是一串数字;“吃”处于位置二,给他另外一个编码,0.3、0.7,另外一个位置向量;“苹果”呢处于位置三,有一个新的位置编码。
他会给每一个词一个独特的位置编码,最后模型会把词的语义信息和位置编码打包一起,输入到网络里去训练。这样一来机器既能并行去算词的关联度,又能够通过位置标签知道---是我在吃苹果,不是苹果在吃我。
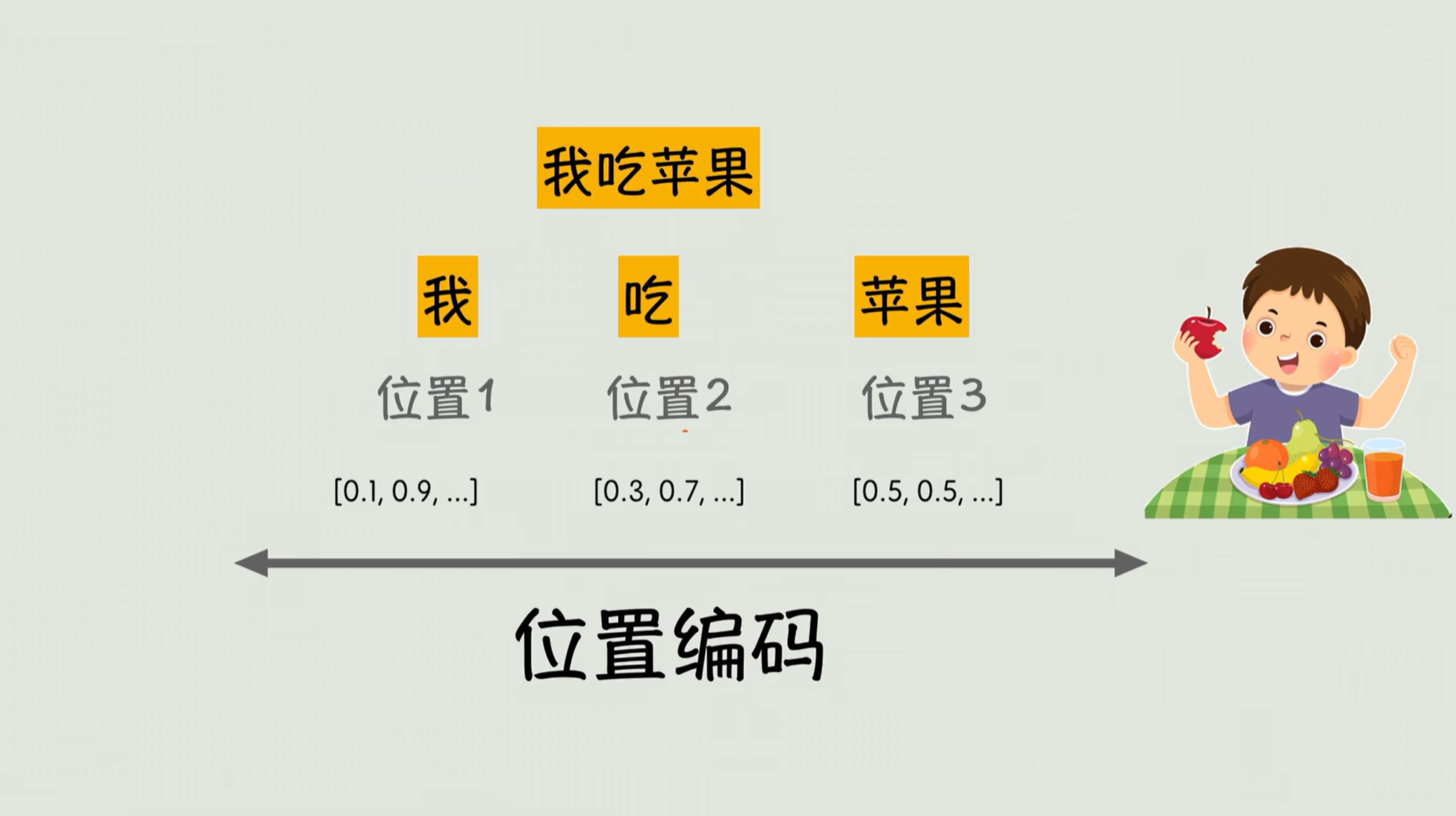
我们来总结一下:👇

5.BERT和GPT
Transformer怎么成为当前各大主流大模型的基础架构呢?
这来源于Transformer的整体架构设计。Transformer整体上可以分为编码器和解码器 两部分,各自负责不同的任务。现在大家使用的各种大模型,基本就是沿着其中的某一个分支演化的,也有部分少量的模型是两侧都考虑。
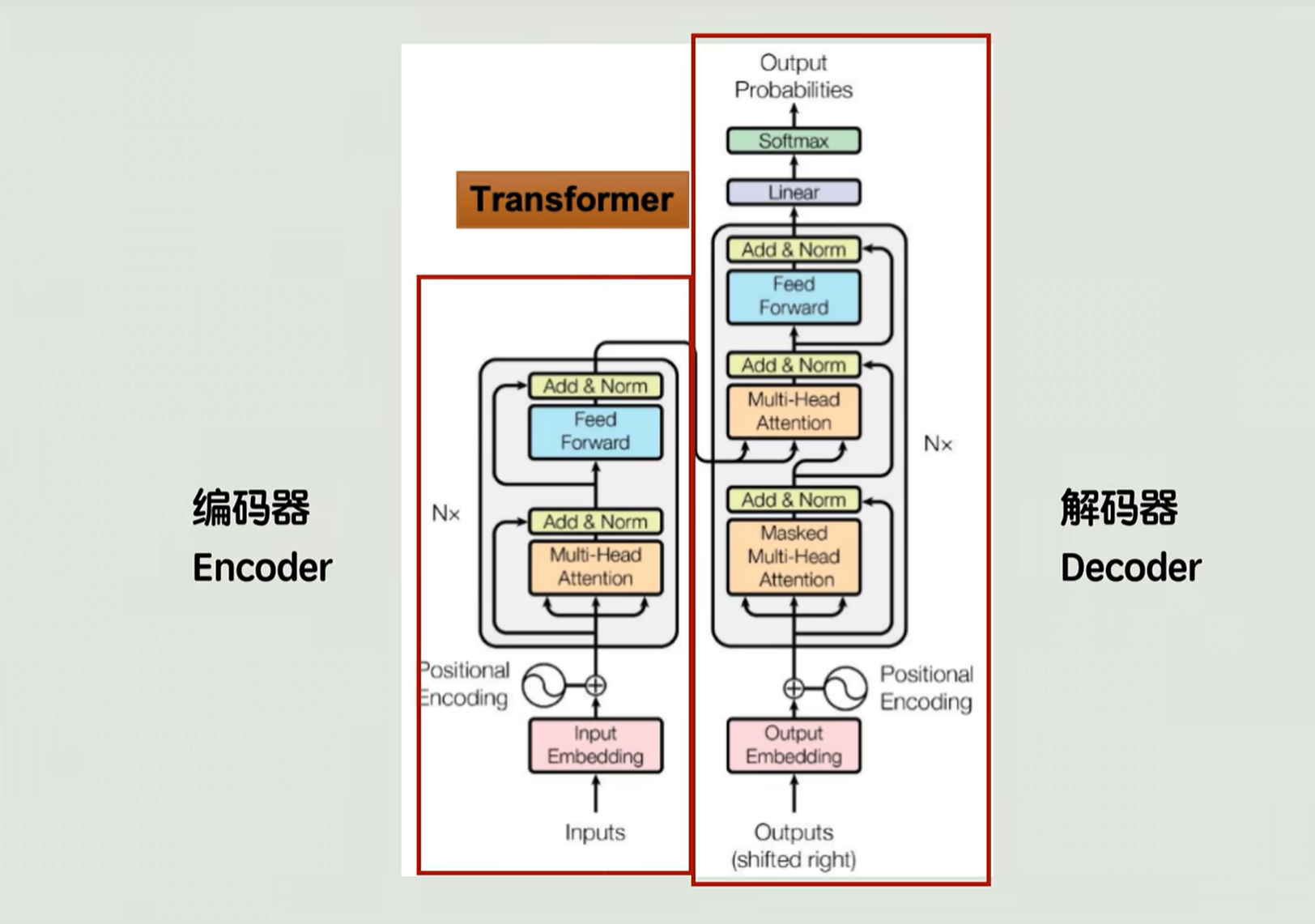
- 像BERT以及后续的一系列变体,它主要关注的就是编码器侧的优化,还在模型轻量化的方向上不断突破,就使得模型的这个语义理解能力越来越厉害。
- GPT系列主要选择的就是解码器的路线,它主要突破的是这个模型的规模,不断优化训练数据的质量,将文本的生成能力打磨到了出神入化的境界。像在咱们中国火出圈的DeepSeek,其实也是GPT系列的分支,完全基于的是Transformer的解码器的堆叠。
下面就具体结合BERT和这个GPT的介绍,让大家了解一下编码器和解码器在处理文本上思路上的区别。

BERT就像一个语言的理解大师,只用Transformer的编码器部分,特点就是在解析文本时可以双向看上下文。

比如说他要填空“他在哪里吃午餐?”,那么这个BERT呢就会同时看左边“他有”,在右边有“吃午饭”,那猜测他可能是在公司或者是家里。这就是双向看上下文功能。
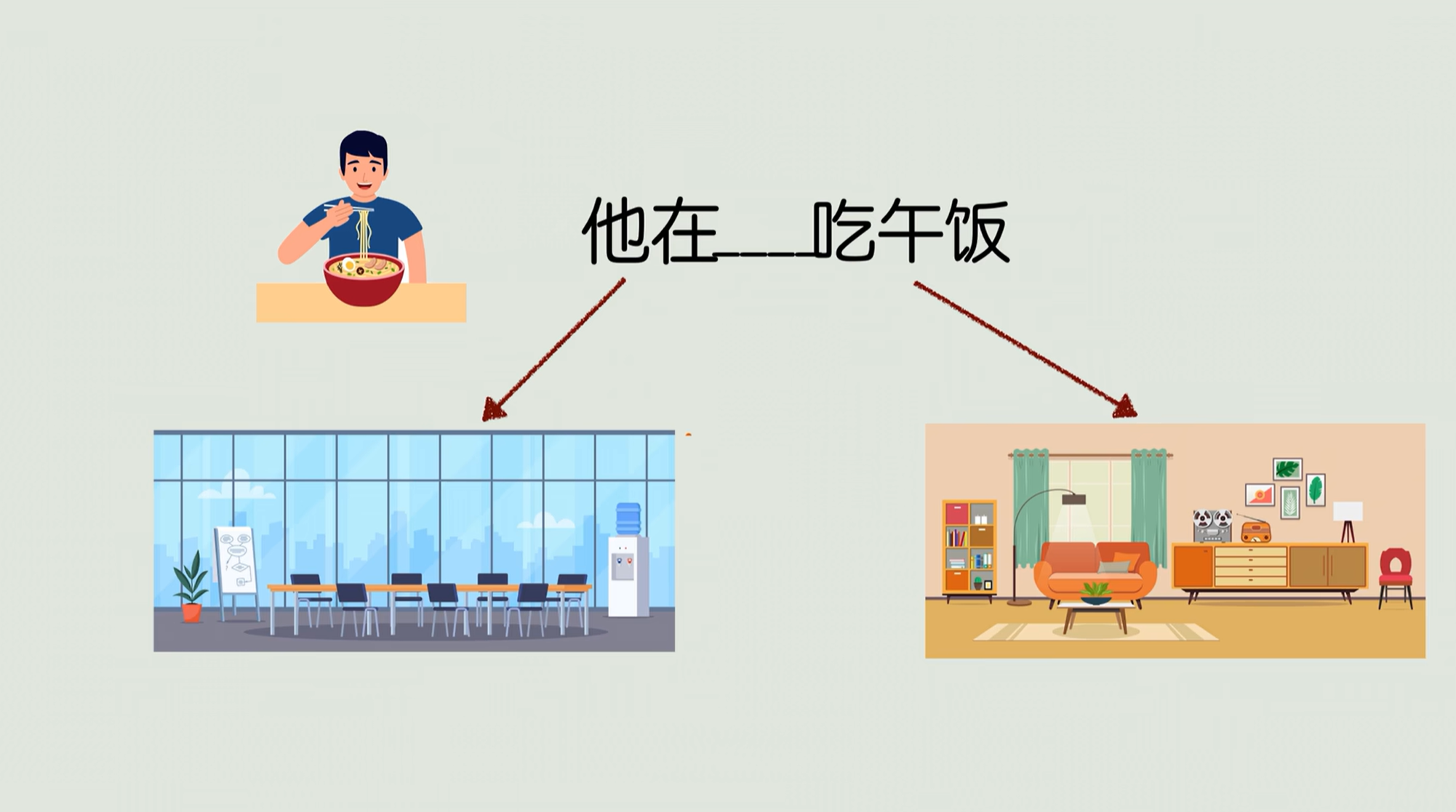
有了这个功能,在这种大段文本的理解方面就很强,所以他很擅长文本分类,比如说看看一段文字是体育新闻,还是财经报道,然后关键词提取以及语义匹配方面就非常强。语义匹配就是比如说要区分“我是想买手机”和“推荐手机”它是不是一回事。
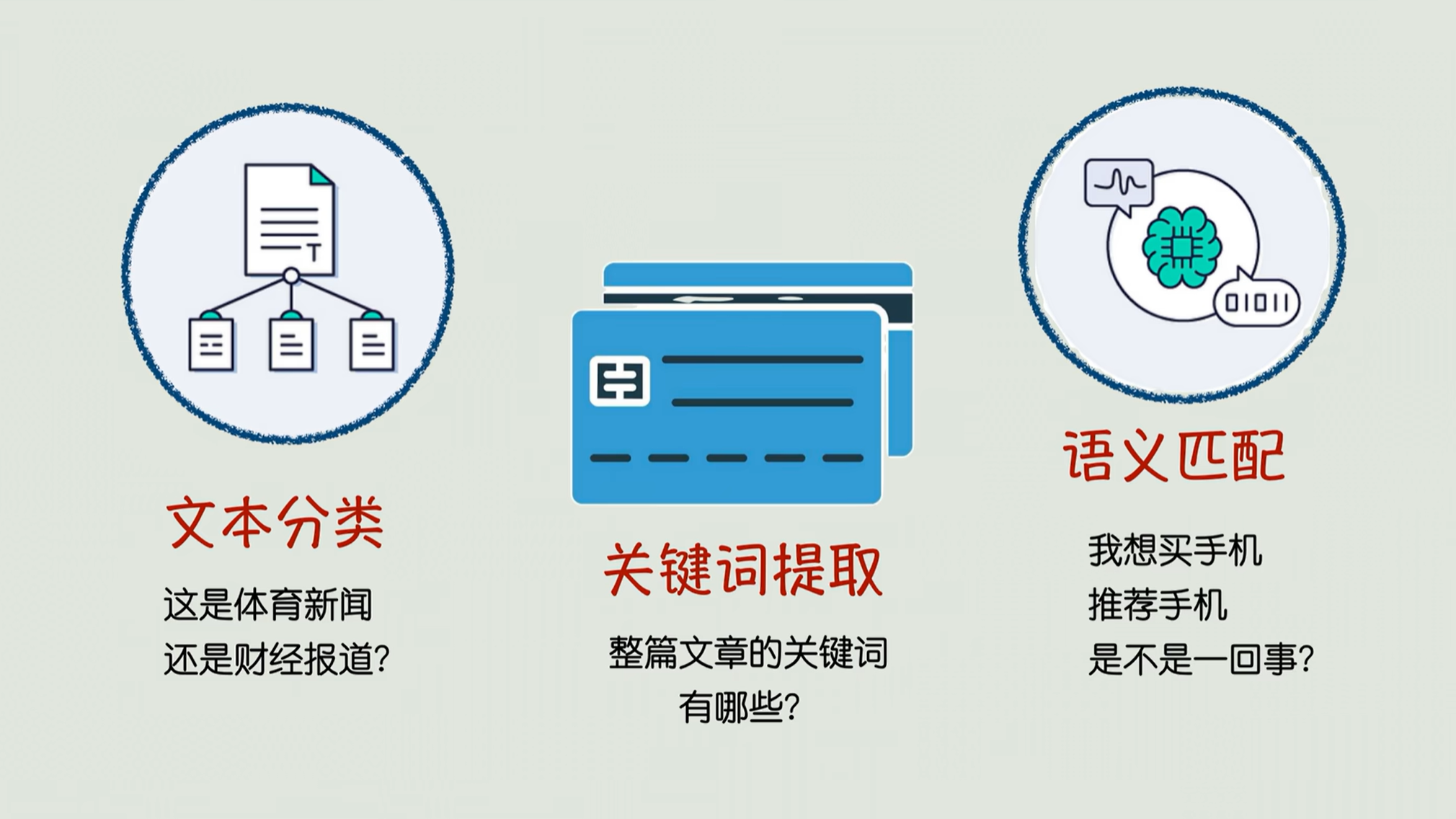
GPT主要则侧重于解码器侧,他更像一个文本生成的大师,特点是单向生成,不能看未来。

一方面它主要用的是单向注意力,也叫因果注意力去生成当前的词。那么它的特点就是,当你可生成当前这个词的时候,只能看前面已经生成的词,不能提前看后面。比如说你写一个句子“我今天要去啊”,那你只能根据“我今天要去”来推导下一个词是“图书馆”还是“操场”,总不能先知道后面要写“复习高数”,
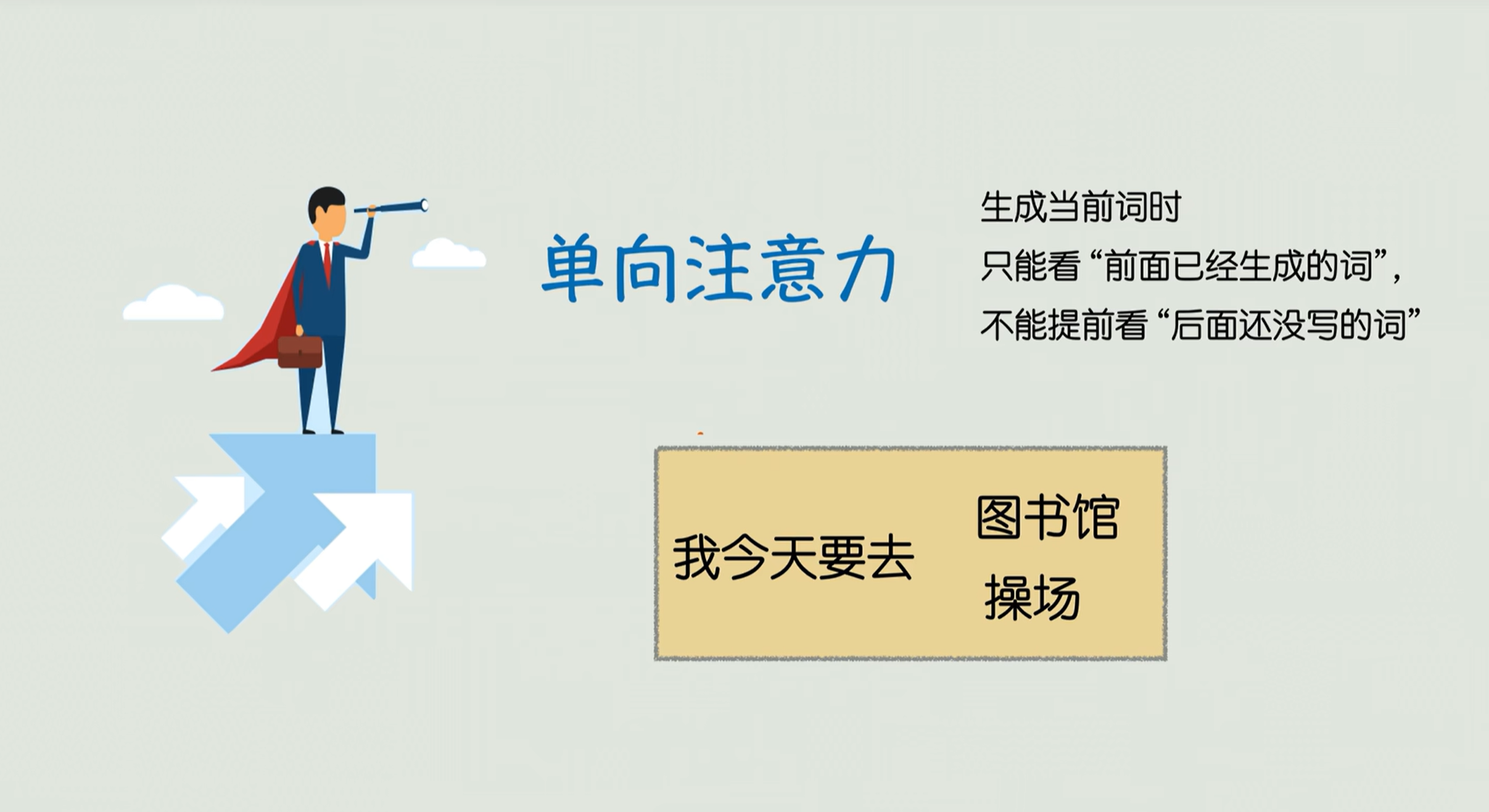
另一方面,这个解码器还有一个掩码机制,专门去屏蔽未来的词儿,确保整个文本的生成它符合时序的逻辑 ,就不会出现说我先写“考了100分”,然后再写“我今天考试”这种颠倒因果的情况。

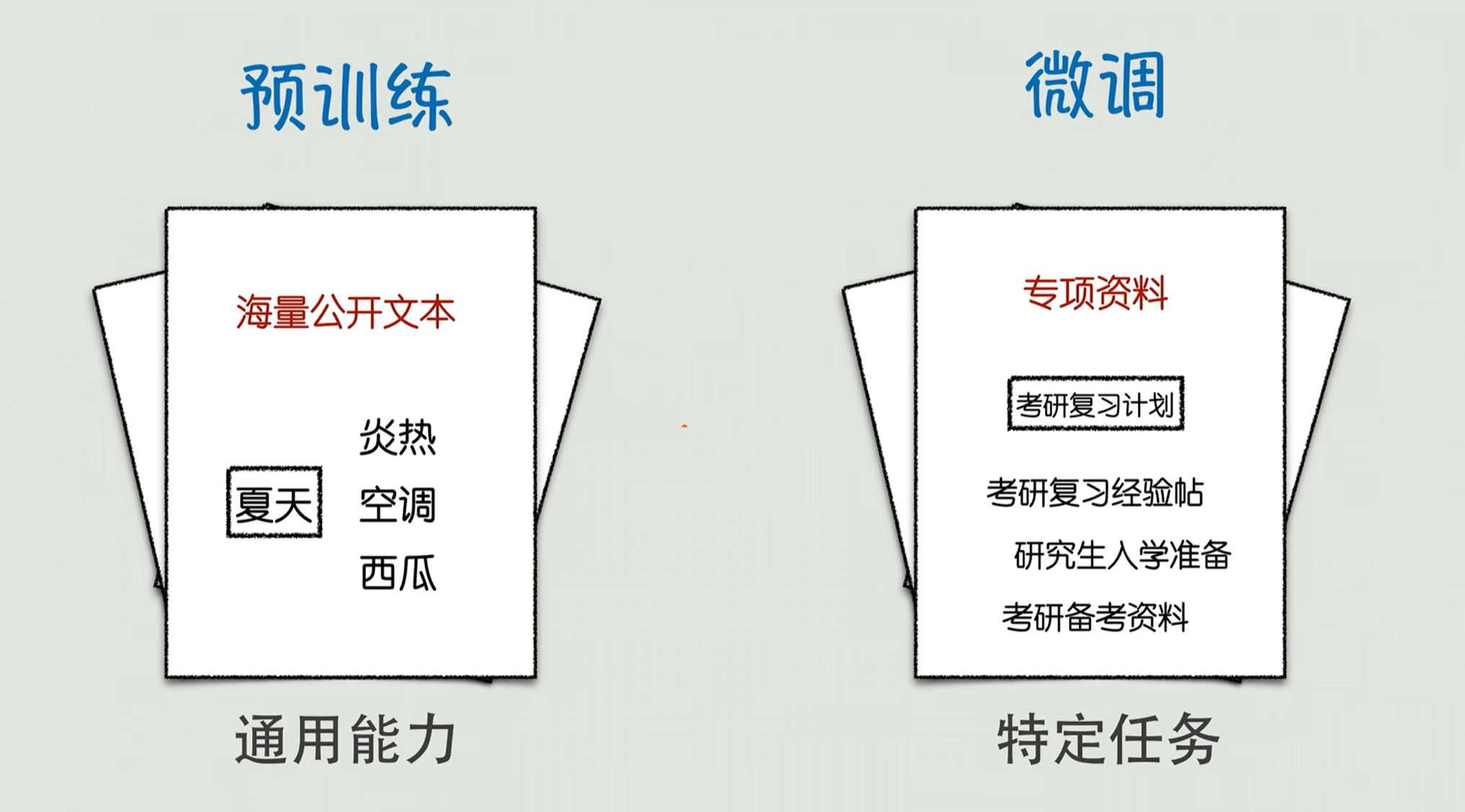
当然GPT这么厉害,还离不开这个预训练加微调的经典模式。
在预训练阶段,工程师会用海量的文本数据,比如说互联网的书籍呀、论文、网页去给GPT喂饭,他主要去学习一般性的词语搭配、语法规则、常规知识。通过训练知道,夏天经常和炎热、空调、西瓜一块出现,毕业论文可能就跟摘要、目录、参考文献一块出现。这个阶段给GPT就训练出来通用能力了,让他能够具备基本的知识储备和文本生成能力。
到了微调阶段,主要是针对具体任务给GPT在做专项训练。比如说你想让他去帮你写考研复习计划,你可能就用大量的这个考研复习贴、考研备考资料哈、研究生入学准备这样的数据去做微调;想让他改代码,就需要用GitHub上面的开源代码去做微调。
通过这种方式,GPT就能够快速适配不同的特殊场景,既保留了预训练的通用能力,又在特定任务上表现出色。
从GPT1到现在的GPT4,模型的进化是一个规模变大和能力变强的过程。
比如说早期GPT1的参数量只有1.17个亿,他就只能写简单的短句;
到GPT3参数量直接就突破1750个亿。奥特曼他们就发现,模型参数量的数量直接决定最终模型性能的一个表现,所以他就把参数量一下子堆到非常的高。那这个时候他不仅能够写完整的诗歌论文,还能够解数学题、去分析就这个段落的因果关系。
GPT4更厉害了,参数有2000多个亿,新增了多模态的能力,比如除了处理文本之外,还能看图片。

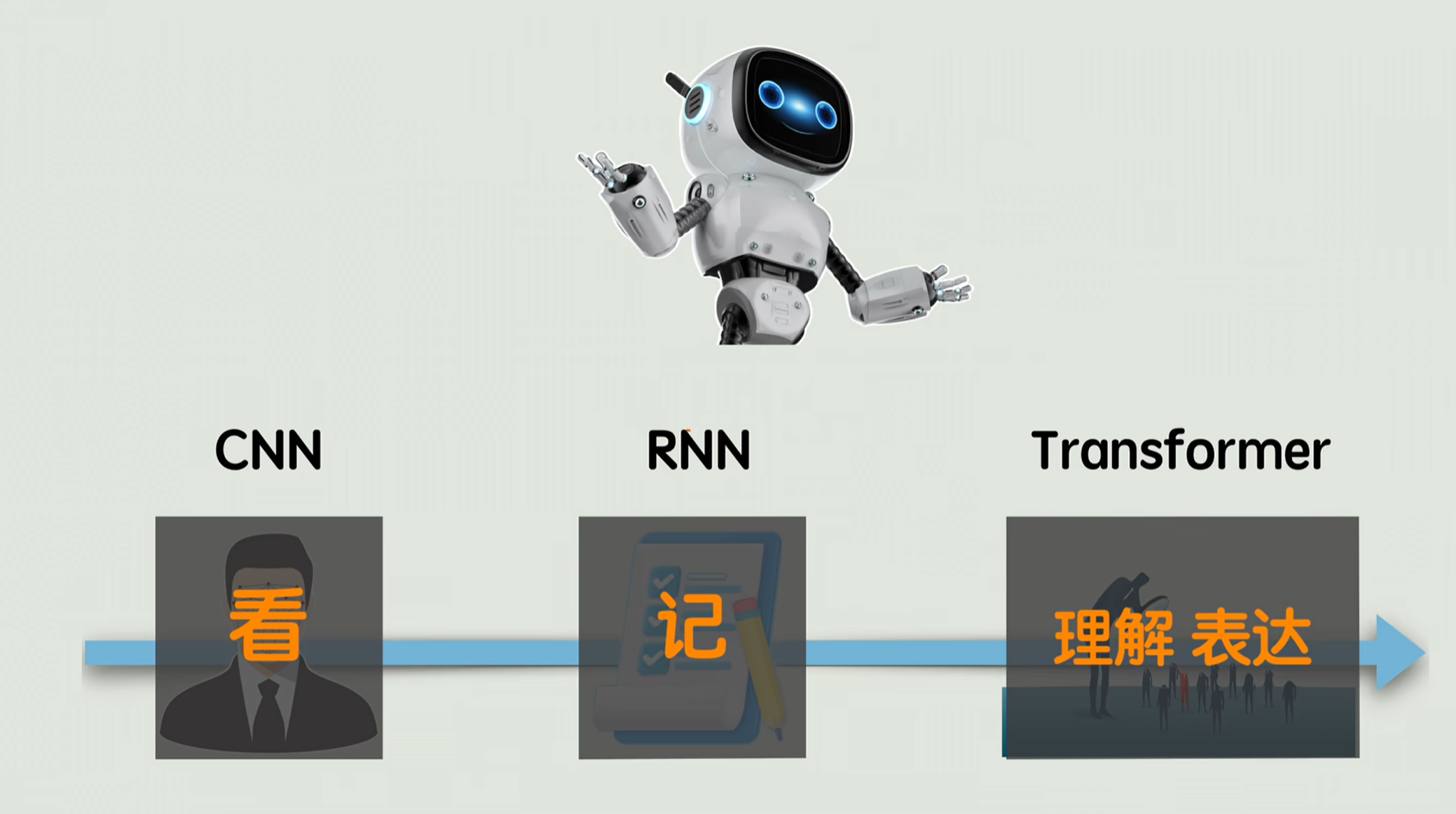
5.总结
AI不是一夜变聪明的,是靠CNN学会了看,再靠RNN学会了记,最后用Transformer的注意力机制,终于学会了理解和表达。
用AI我写个周报,完成作业,帮我解释一下量子力学,写首周杰伦风格的歌,就知道它背后,是一场长达十多年的技术接力,是无数工程师在模型结构上的精雕细琢、精益求精!!!
3. 离群点检测
离群点检测
1. 离群点与噪声的区别
离群点:是数据集中明显偏离其他数据的数据点,它可能是真实存在的、有意义的异常情况(比如在监测系统中,某个设备突然出现的异常高读数,可能反映设备故障等真实事件),并非数据采集或处理过程中的错误。
噪声:通常是由于数据采集设备故障、数据传输错误或者人为录入失误等原因产生的无意义干扰数据,是不符合真实情况的错误数据,对数据分析没有积极作用,需要尽可能消除或降低其影响。
2. 全局离群点、条件离群点和集体离群点的含义
全局离群点:在整个数据集中,该数据点显著偏离其他所有数据点,不考虑数据的任何子结构或条件限制。例如,在一组正常范围为1−100的数值中,出现了1000
这个数值,它相对于整个数据集的所有数据都是异常的。
条件离群点:也称为上下文离群点,是在特定的上下文或子集中表现为异常的数据点,在全局范围内可能并不异常。比如在分析不同季节的气温数据时,冬季某一天的气温远高于该冬季其他天的气温(但和夏季气温相比是正常的),那么这个气温数据在冬季这个上下文里就是条件离群点。
集体离群点: 是一组数据作为一个整体,显著偏离数据集中的其他数据组,但组内的单个数据点可能并不异常。例如,在超市销售数据中,某一天所有商品的销量都远高于平时(没有特殊促销等合理原因),这一组销量数据就构成集体离群点,组内每个商品的销量单独看可能在正常波动范围内,但整体却异常。
3. 离群点的类型及常用的检测方法
基于统计的方法 :假设数据服从某种分布(如正态分布),计算数据点与分布的偏离程度(如计算 Z - 分数,当 Z - 分数的绝对值大于一定阈值时,认为是离群点)。
基于距离的方法 :计算数据点与其他数据点的距离,若一个数据点到其k个最近邻的平均距离大于阈值,则判定为离群点(如k- 近邻离群点检测)。
基于密度的方法 :考虑数据点周围的密度,若一个数据点周围的密度远低于其他点,则为离群点(如局部离群因子 LOF 算法,通过比较数据点的局部密度与邻居点的局部密度来判断离群程度)。
基于聚类的方法 :先对数据进行聚类,那些不属于任何聚类或者属于非常小的聚类的数据点被视为离群点。