
数据仓库与数据挖掘-第一章节
模块三之回归分析
1.回归分析概述
回归分析概述
1.回归分析的定义
在大数据分析中,回归分析是一种预测性的建模技术 ,它研究的是因变量(目标) 和自变量(预测器) 之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。
例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究方法就是 回归。通常使用曲线拟合数据点,然后研究如何使曲线到数据点的距离差异最小. 👇
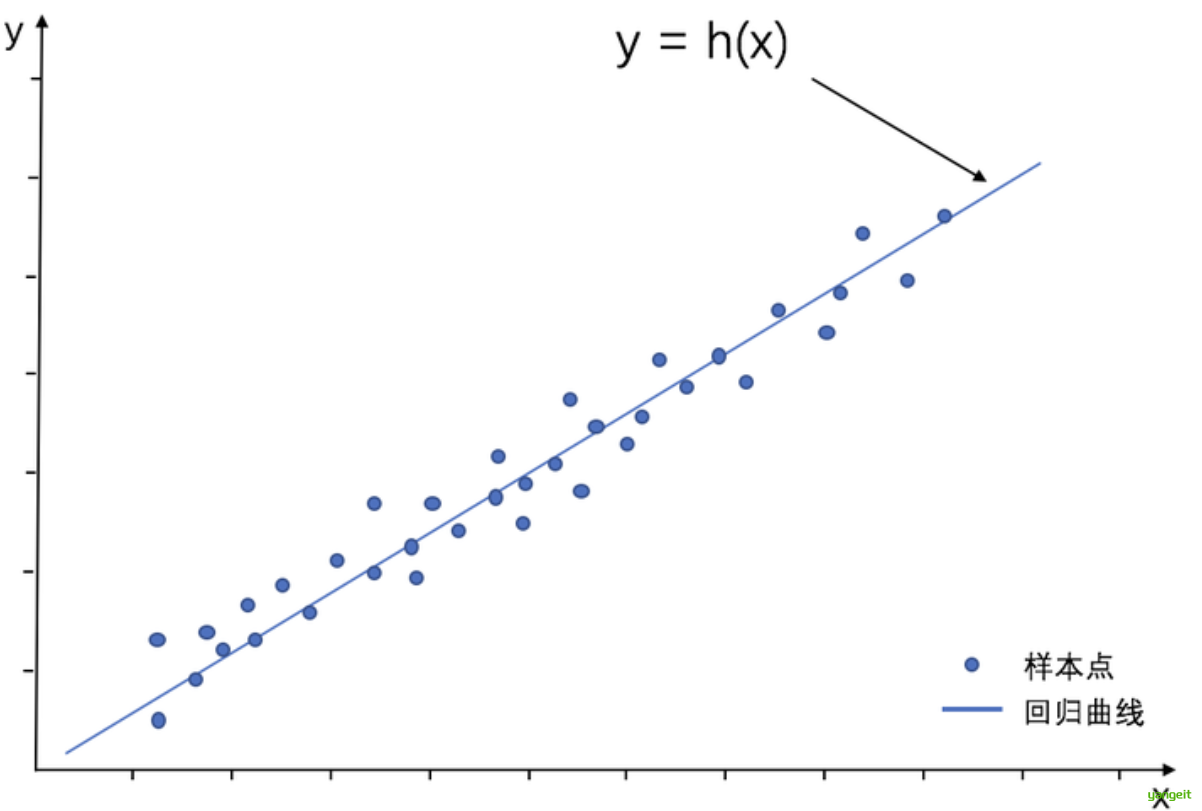
2. 为何用回归分析?
如上所述,回归分析估计了两个或多个变量之间的关系。下面,让我们举一个简单的例子来理解它:👇
比如说,在当前的经济条件下,你要估计一家公司的销售额增长情况。现在,你有公司最新的数据,这些数据显示出销售额增长大约是经济增长的2.5倍。那么使用回归分析,我们就可以根据当前和过去的信息来预测未来公司的销售情况。
使用回归分析的好处良多。具体如下: 👇
- 它表明自变量和因变量之间的显著关系;
- 它表明多个自变量对一个因变量的影响强度。
回归分析也允许我们去比较那些衡量不同尺度的变量之间的相互影响,如价格变动与促销活动数量之间联系。这些有利于帮助市场研究人员,数据分析人员以及数据科学家排除并估计出一组最佳 的变量,用来构建 预测模型 。
3.我们有多少种回归技术?
有各种各样的回归技术用于预测。这些技术主要有三个度量(自变量的个数,因变量的类型以及回归线的形状)
常用回归技术对比
| 回归技术 | 核心描述 | 主要特点 | 经典示例 |
|---|---|---|---|
| 一元线性回归 | 使用一个自变量预测一个因变量,拟合一条直线 y = β₀ + β₁x。 | 模型简单,结果直观易懂。 | 根据学习时长预测考试分数。 |
| 多元线性回归 | 使用多个自变量预测一个因变量,拟合一个超平面 y = β₀ + β₁x₁ + ... + βₙxₙ。 | 可以衡量多个因素对结果的影响。 | 根据面积、卧室数量、地段预测房价。 |
| 逻辑回归 | 用于解决二分类问题,预测事件发生的概率,因变量是类别型。 | 输出值在0和1之间,通过Sigmoid函数映射。 | 根据年龄、收入、历史行为预测用户是否会购买(是/否)。 |
| 多项式回归 | 线性回归的扩展,通过添加自变量的幂次项(如 x², x³) 来拟合非线性关系。 | 可以捕捉数据中的曲线趋势,但仍是线性模型。 | 根据温度预测电力负荷(关系通常呈U型或倒U型曲线) 。 |
正则化回归(用于解决过拟合和多重共线性)
| 回归技术 | 核心描述 | 正则化方式 | 主要特点 | 经典示例 |
|---|---|---|---|---|
| 岭回归 | 在线性回归的损失函数中增加L2正则化项(系数平方和)。 | L2正则化 | 惩罚大的系数,使其趋近于0但不等于0,适用于特征较多且存在共线性的情况。 | 预测房价时,特征包含面积和平方米数(高度相关),岭回归可稳定系数估计。 |
| Lasso回归 | 在线性回归的损失函数中增加L1正则化项(系数绝对值之和)。 | L1正则化 | 可以将不重要的特征系数直接压缩至0,从而实现特征选择。 | 基因数据分析,从上万个基因特征中筛选出与疾病最相关的几十个基因。 |
| 弹性网络回归 | 结合了L1和L2两种正则化项,是岭回归和Lasso回归的折中方案。 | L1 + L2 正则化 | 在有多重共线性且特征数量非常多时,表现通常比单独使用一种更好。 | 基因或文本数据(特征维度极高),且特征组内存在相关性。 |
特征选择方法(自动选择显著自变量)
| 回归技术 | 核心描述 | 工作方式 | 主要特点 | 经典示例 |
|---|---|---|---|---|
| 逐步回归 | 一种通过自动选择显著自变量来构建模型的算法。 | 迭代地添加或移除变量,基于预定的统计标准(如AIC, p-value)。 | 自动化特征选择过程,但可能不是全局最优解,现已较少使用。 | 在临床医学中,从大量可能的生理指标中筛选出与某种疾病最相关的几个指标来构建诊断模型。 |
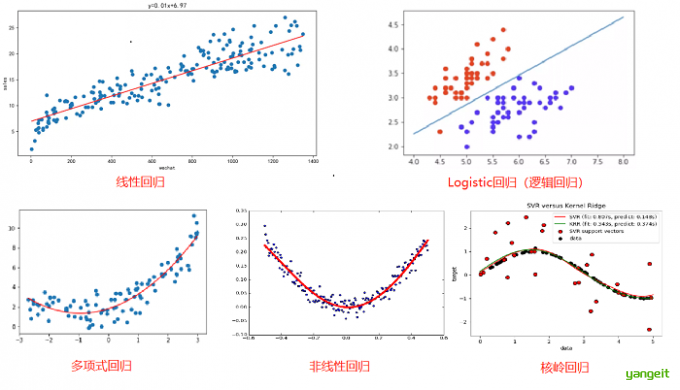
2.线性回归
2.1 线性回归概述
线性回归概述
1. 什么是线性回归?
想象一下,你是一位房产估价师。你的经验告诉你:“房子越大,通常就越贵”。这个直观的感受,其实就是线性回归的核心思想:寻找一个或多个特征(如“面积”)与一个目标值(如“房价”)之间的线性关系。
1. 核心思想:
用一个(或一组)自变量 X 来预测一个因变量 y 。我们假设它们之间的关系可以用一条直线(或一个平面/超平面)来拟合。
2. 数学模型:
[]
一元线性回归 (Simple Linear Regression):
y = β₀+β₁x + ε
- y: 要预测的目标(如:房价)
- x: 用来预测的特征(如:房间数量)
- β₁: 权重(Weight),也叫斜率。表示 x 每增加一个单位,y 会平均变化多少。
- β₀: 偏置(Bias),也叫截距。表示当 x=0 时 y 的基准值。
- ε: 误差(Error),也叫残差。表示实际值 y 和预测值 ŷ 之间的差距。
多元线性回归 (Multiple Linear Regression):
y = β₀ + β₁x₁ + β₂x₂ + ... + βₙxₙ
x₁, x₂, ..., xₙ: 多个特征(如:房间数量、犯罪率、离市中心的距离等)。
β₁, β₂, ..., βₙ: 每个特征对应的权重,代表了该特征对预测结果的重要性。
3. 如何找到最佳直线?—— 最小二乘法
我们画一条直线,不可能让所有点都落在上面。那么,哪条线才是“最佳”的呢?
答案:找到一条直线,使得所有数据点到这条直线的 误差 的平方和最小。
这个 误差 就是实际值 y 和预测值 ŷ 之间的差距。最小化这个平方和的过程,就叫做 最小二乘法。

总结
课堂作业
回答下列问题,来验证上述知识点的掌握情况:
- 回归分析的主要目的是什么?
- 一元线性回归模型的基本形式是什么?
- 如何使用最小二乘法找到最佳拟合直线?
2.2 线性回归实战准备
数据仓库概要
眼过千遍,不如手过一遍,我们来动手做一做,加深对上述知识的了解。
工欲善其事,必先利其器。我们先来了解一下今天要用到的数据集。
波士顿房价数据集 (Boston Housing Dataset):
这是一个经典的机器学习入门数据集,该数据集包含美国人口普查局收集的美国马萨诸塞州波士顿住房价格的有关信息, 数据集很小,只有506个案例。
- 目标 (y): MEDV - 房屋的自住中位数房价(单位:千美元)。
- 特征 (X): 有13个,我们挑几个容易理解的:
- RM - 每处住宅的平均房间数。 (这是我们一元回归的主角)
- LSTAT - 低收入人群的百分比。
- CRIM - 城镇的人均犯罪率。
- AGE - 1940年之前建成的自住单位比例。
- PTRATIO - 城镇的师生比例。
1. 数据集的获取
让我们用 Python 把它加载进来看看:
# 导入必备工具库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import pandas as pd
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data"
names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
boston_df = pd.read_csv(url, delim_whitespace=True, names=names)
print(boston_df)
# 将其转换为Pandas的DataFrame,更方便操作
boston_df = pd.DataFrame(boston_df)运行这段代码,你会看到数据的全貌,它有506条记录,没有缺失值,非常干净,非常适合零基础同学入门。
2. 一元线性回归-分析房价与房间数量的关系
现在,我们来验证最开始的直觉:房间越多,房价真的越高吗?
2.1 可视化探索关系
首先,我们画个散点图看看。
如果是Juytpyter Notebook,
# 绘制房间数量(RM)与房价(MEDV)的散点图
plt.figure(figsize=(10, 6)) # 设置画布大小, 单位是英寸
plt.scatter(boston_df['RM'], boston_df['MEDV'], alpha=0.6) #RM 和 MEDV 的散点图,alpha让点变透明,方便观察密度
plt.xlabel('Average number of rooms (RM)')# 设置x轴标签
plt.ylabel('House price (MEDV) / $1000')# 设置y轴标签
plt.title('Relationship between RM and MEDV')# 设置标题
plt.show() # 显示图形你会看到一个明显的正相关趋势:点的大致分布是向右上方走的 ,说明 RM 增加,MEDV 也倾向于增加。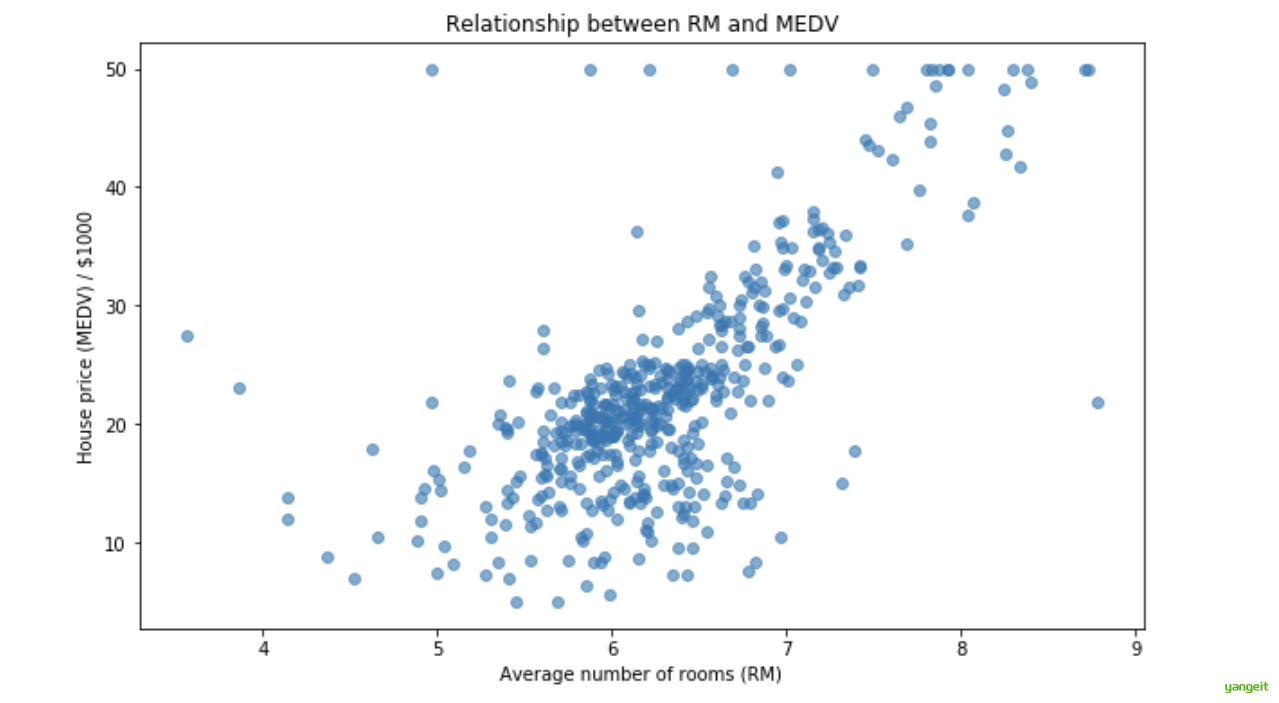
2.2 构建并训练模型
接下来,我们让机器学习库 scikit-learn 来帮我们找到那条最佳拟合直线(使用的就是最小二乘法)。
# 第一步:准备数据
# 特征 (X) 需要是二维数组,所以用双重括号。目标 (y) 是一维数组。
X = boston_df[['RM']] # 选择 RM 特征
y = boston_df['MEDV'] # 目标值是房价
# 第二步:划分数据集
# 为了检验模型效果,我们不会使用全部数据来训练。
# 通常按 80% 训练,20% 测试的比例来随机划分。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# X_train: 训练集的特征
# X_test: 测试集的特征
# y_train: 训练集的目标
# y_test: 测试集的目标
# random_state 设定随机种子,保证每次运行代码的分区结果一致,便于教学复现。
# 第三步:创建并训练模型
model = LinearRegression() # 创建一元线性回归模型
model.fit(X_train, y_train) # 在训练集上训练模型,寻找最佳 β₁ 和 β₀
# 第四步:查看学到的参数
print(f"截距 (β₀): {model.intercept_:.2f}")
print(f"系数 (β₁ for RM): {model.coef_[0]:.2f}")输出:
- 截距 (β₀): -36.25
- 系数 (β₁ for RM): 9.35
将系数代入到公式中:y = β₀+β₁x + ε 解读模型参数:
我们得到的模型是:MEDV = 9.35* RM -36.257
- 系数 (β₁ = 9.35): 意味着平均房间数每增加1间,预测的房屋价格会增加约 9.35 * 1000 = 9,350 美元。这符合我们的直觉。
- 截距 (β₀ = -36.25): 理论上,当 RM=0 时,房价是 -36.25千美元,这显然没有现实意义。这提醒我们,截距有时只是数学上的基准点,模型在数据范围外可能不适用(不会有房间数为0的房子)。
2.3. 模型评估与可视化
模型训练好了,我们来看看它在我们没见过的测试集上表现如何。(本案例中就是那20%的数据,进行预测,然后和真实值对比,观察误差)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 评估指标
# 均方根误差 (RMSE): 预测值与真实值之间的典型误差(单位与y相同,易于理解)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
# R² 决定系数: 表示模型捕捉了多少数据中的方差。越接近1越好。
r2 = r2_score(y_test, y_pred)
print(f"RMSE: {rmse:.2f}")
print(f"R² Score: {r2:.2f}")
# 可视化结果
plt.figure(figsize=(10, 6))
# 画测试集的散点
plt.scatter(X_test, y_test, alpha=0.6, label='Test Data')
# 画拟合的直线
plt.plot(X_test, y_pred, color='red', linewidth=2, label='Regression Line')
plt.xlabel('Average number of rooms (RM)')
plt.ylabel('House price (MEDV) / $1000')
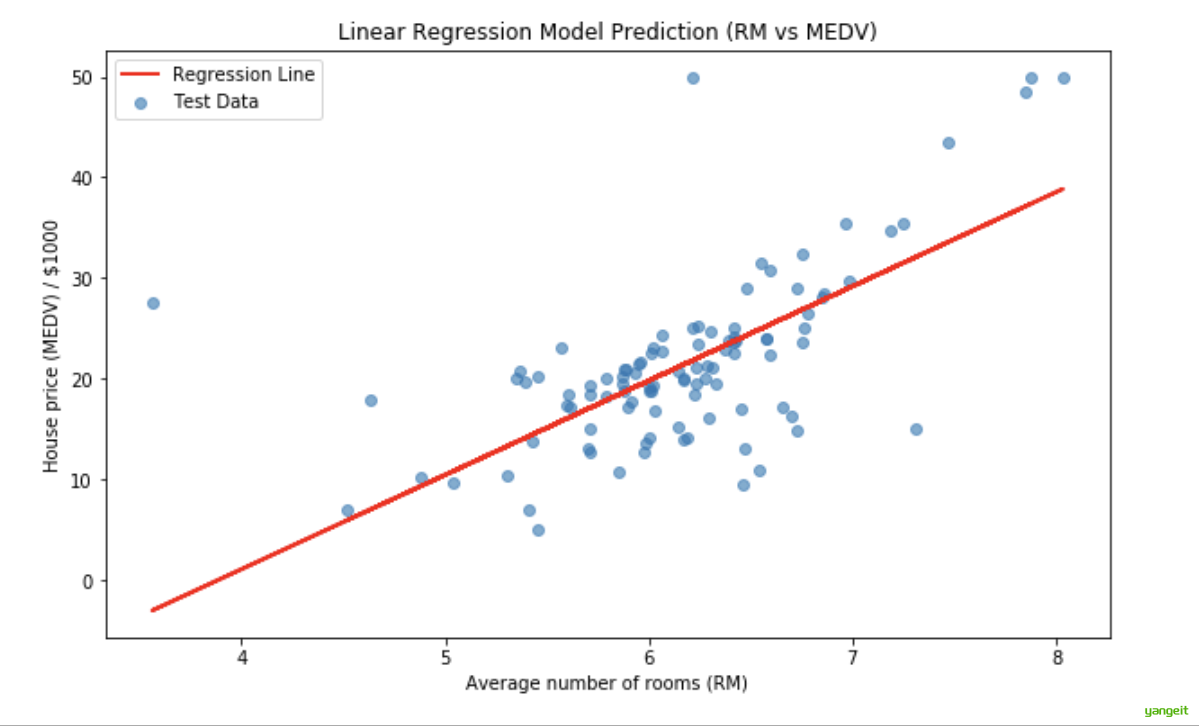
plt.title('Linear Regression Model Prediction (RM vs MEDV)')
plt.legend()
plt.show()运行结果:👇
RMSE:6.79: 意味着模型的预测价格平均来看,和真实价格相差大约 $6790。
R²:0.37,意味着房间数量这个特征解释了房价大约37%的波动。还有63%的波动是 RM 无法解释的,这引出了多元回归的必要性。
补充说明: 👇 👇 🍐
1️⃣ RMSE 的全程是 Root Mean Squared Error,中文叫均方根误差
公式:👇
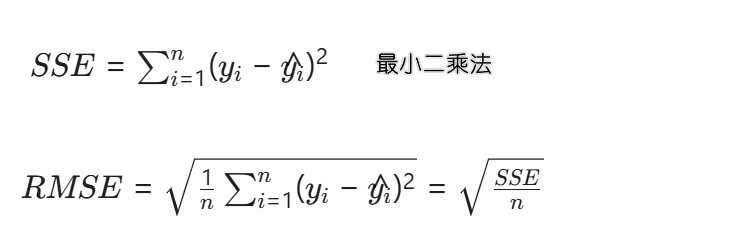
让我们在测试集的结果上画图。每个点的“误差”,就是其真实y值到预测y值(红线)的垂直距离。
- 那些灰色的虚线,就代表了每个预测的误差。有的线长,说明误差大;有的线短,说明误差小。
- RMSE 的值(比如 5.0)可以看作是这些灰色虚线“典型长度”的一种衡量。
- 因为它和房价单位相同,我们可以直接解释:“我们这个模型的预测,平均来看,会和真实房价相差大约 $6,793 美元。”
- 目标: 我们希望这些灰色的误差线尽可能的短,即让RMSE尽可能小。
一句话总结:RMSE 越小,模型预测越准。
2️⃣ R² :中文叫决定系数。
它的思想更有趣:它不关心具体的误差值,而是关心 你的模型 比一个 最简单的蠢模型 强多少。
这个最简单的蠢模型 就是均值模型 ——即不考虑任何特征 X,对所有情况的预测都是目标 y 的平均值 ȳ。
公式:👇
R² = 已解释的波动 / 总波动 = SSR / SST 或者说: R² = 1 - (无法解释的波动 / 总波动) = 1 - (SSE / SST)
- SSE:Sum of Squared Errors,即所有误差的平方和。
- SST:Sum of Squared Total,即所有真实值的平方和。
如果:
- R² = 1,则模型完美拟合数据,没有任何误差。
- R² = 0,则模型完全不相关,没有任何预测能力。
- R² < 0,则模型比均值模型更差-这种情况说明模型完全错误 。
一句话总结:R² 越接近1,模型解释数据的能力越强。
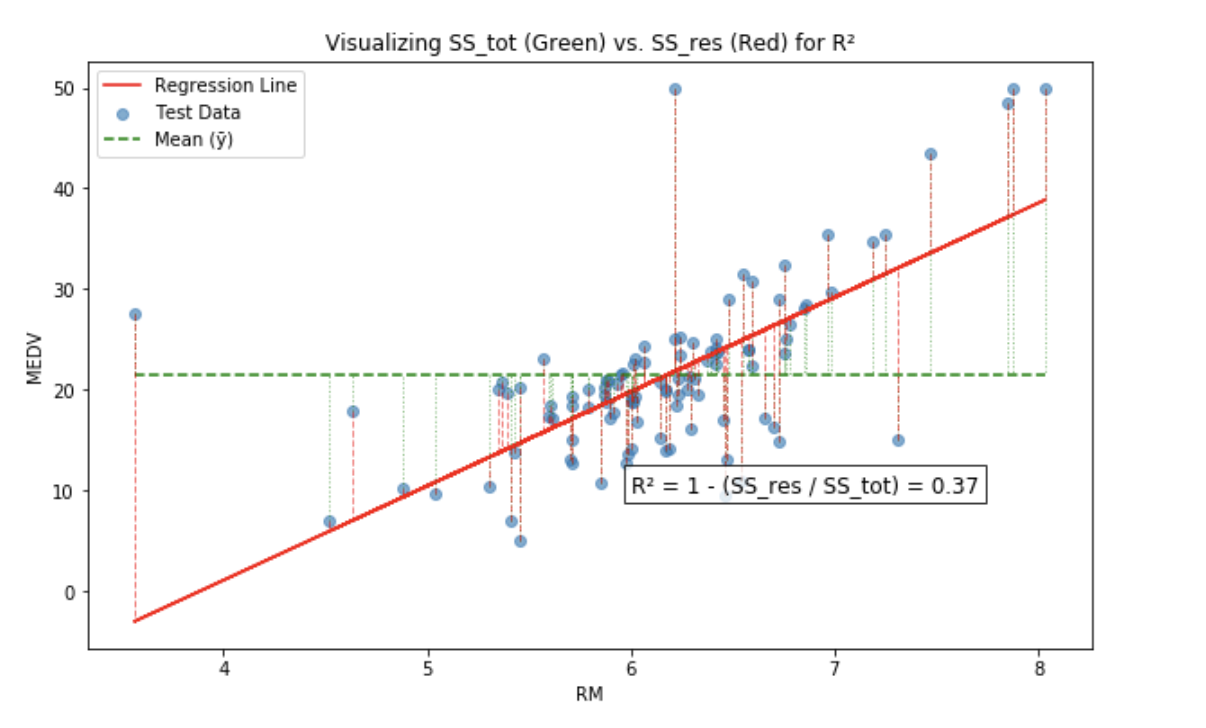
绿色的虚线代表了数据的总波动 SST (SS_tot)。红色的虚线代表了我们的模型剩下的未解释的波动 SSE (SS_res)。
如果模型完美,SSE = 0,R² = 1。说明绿色虚线完全被红线覆盖,模型完美解释了所有波动。
一元回归效果有限,因为房价显然不止由房间数决定。犯罪率、学区、房龄等都是重要因素。现在,我们使用所有特征来构建一个更强大的模型。
1. 构建多元模型
代码流程和一元回归惊人地相似,这体现了 scikit-learn 接口的一致性。
# 第一步:准备数据 (这次使用所有特征,除了目标列MEDV)
X_multi = boston_df.drop('MEDV', axis=1) # 特征是所有列,除了MEDV
y_multi = boston_df['MEDV'] # 目标值是房价
# 第二步:划分数据集
X_train_m, X_test_m, y_train_m, y_test_m = train_test_split(X_multi, y_multi, test_size=0.2, random_state=42)
# X_train_m: 训练集的特征
# X_test_m: 测试集的特征
# y_train_m: 训练集的目标
# y_test_m: 测试集的目标
# test_size=0.2 表示测试集占20%,训练集占80%
# random_state 设定随机种子,保证每次运行代码的分区结果一致,便于教学复现。
# 第三步:创建并训练多元模型
multi_model = LinearRegression()
multi_model.fit(X_train_m, y_train_m)
# 第四步:查看学到的参数(现在有13个系数+1个截距)
print(f"截距 (w₀): {multi_model.intercept_:.2f}")
# 将系数和特征名对应起来,看得更清楚
coeff_df = pd.DataFrame({'Feature': X_multi.columns, 'Coefficient': multi_model.coef_})
print(coeff_df.sort_values(by='Coefficient', ascending=False))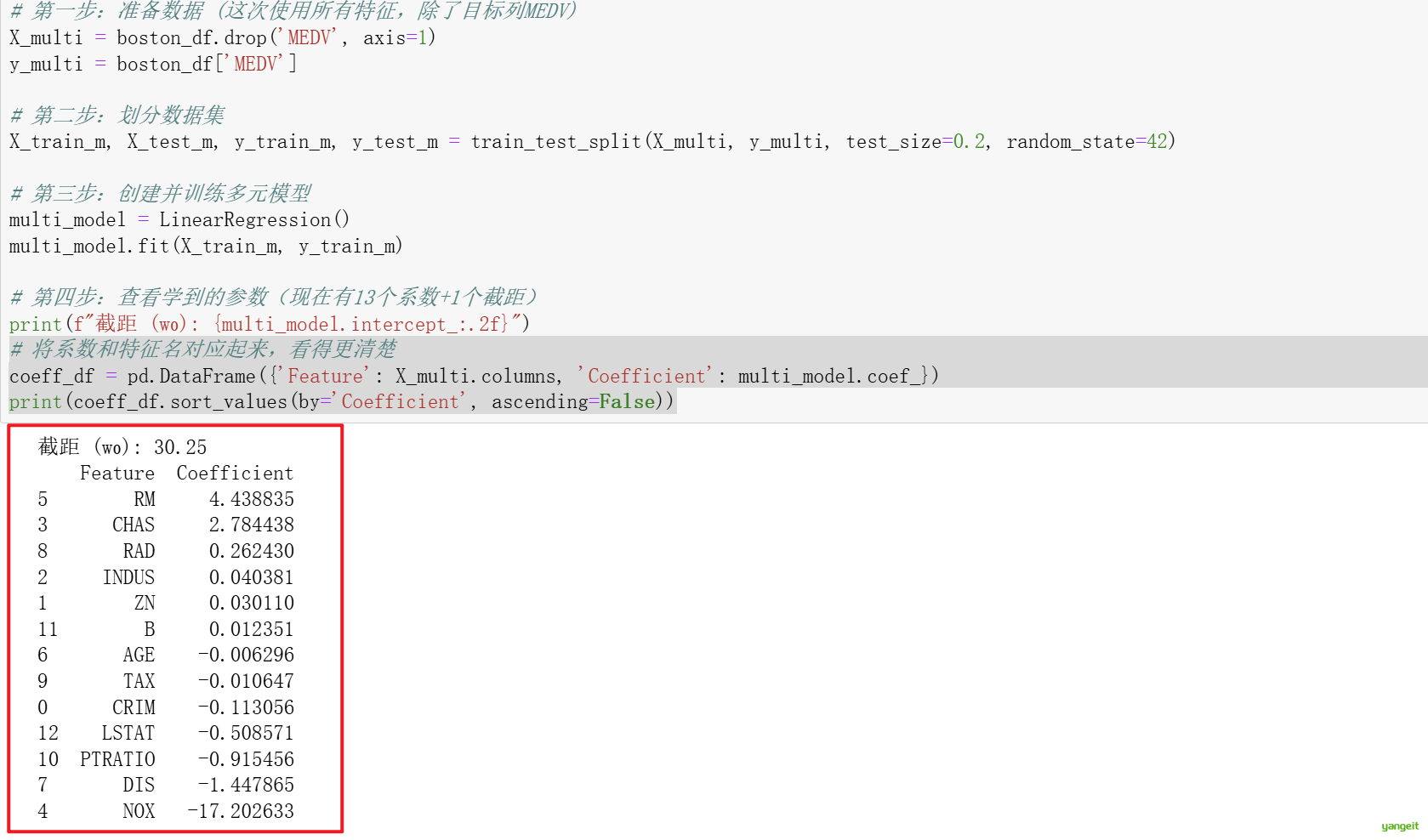
解读系数:
- RM 的系数仍然是最大的正数之一,印证了它的重要性。
- LSTAT(低收入人群比例)是负系数,意味着该比例越高,房价越低。
- NOX(氮氧化物浓度)和 CRIM(犯罪率)也是负数,说明这两个特征越高,房价越低。
重要提示:在比较权重大小时,必须确保所有特征都在相同的尺度上(通常通过数据标准化实现)。由于本数据集特征尺度不一,这里的系数大小比较仅供参考。
2. 评估多元模型
# 在测试集上进行预测
y_pred_m = multi_model.predict(X_test_m)
# 评估指标
rmse_m = np.sqrt(mean_squared_error(y_test_m, y_pred_m)) # 均方根误差
r2_m = r2_score(y_test_m, y_pred_m) # 决定系数
# 输出多元模型的评估指标
print(f"Multivariate Model - RMSE: {rmse_m:.2f}")
print(f"Multivariate Model - R² Score: {r2_m:.2f}")
# 对比一元模型
print(f"\nUnivariate Model (RM only) - RMSE: {rmse:.2f}")
print(f"Univariate Model (RM only) - R² Score: {r2:.2f}")输出:
- Multivariate Model(多元模型) - RMSE: 4.93
- Multivariate Model(多元模型) - R² Score: 0.67
- Univariate Model (一元模型,只用RM) - RMSE: 6.79
- Univariate Model (一元模型,只用RM) - R² Score: 0.37
结果分析: 👇
你会发现多元模型的 R² 显著提高(例如从0.37提升到0.67),而 RMSE 显著降低。
这说明综合考虑多个特征,极大地提升了我们对房价的预测能力!模型捕捉到了更多数据中的信息。
总结
上一节我们系统地学习了线性回归:
- 概念:理解了线性回归是寻找特征与目标之间线性关系的模型。
- 一元回归:深入理解了权重 w₁ 和截距 w₀ 的现实意义,并学会了用散点图和拟合直线来可视化。
- 多元回归:明白了为什么需要多元回归,以及如何解释不同特征的权重(重要性)。
- 评估:掌握了 RMSE 和 R² 这两个至关重要的评估指标。
- 实战:全程使用 Python 和 scikit-learn 完成了从数据加载、探索、建模到评估的全流程。
课堂作业
- 根据多元模型的系数表,你认为哪个特征对推高房价最有利?哪个特征对抑制房价最严重?
- 多元模型的 R² 为什么没有接近1?可能的原因是什么?(提示:非线性关系、其他未包含的特征等)
3.逻辑回归
数据仓库概要
好的,同学们!我们刚刚成功用线性回归预测了连续值(房价)。现在进入一个更有趣的领域:预测类别。比如,
- 根据医学数据判断一个肿瘤是良性还是恶性,
- 根据财务数据判断一笔交易是否欺诈,
- 根据考试成绩判断一个学生能否被录取。
这就是逻辑回归 (Logistic Regression) 大显身手的地方。
别看名字里有“回归”,它是不折不扣的分类算法,而且是解决二分类问题的利器。
案例:学生录取预测
假设你是一所大学的招生官。有往届学生的历史数据,包含两个特征:
- exam1_score: 第一次考试成绩
- exam2_score: 第二次考试成绩 和一个目标(是否被录取):
- admitted: 是否被录取 (0 = 未录取, 1 = 录取)
你的任务是:建立一个模型,根据申请者 两次考试的成绩,来预测他/她被录取的“概率”。
1.思考过程:
线性回归的局限性:
- 如果我们直接用线性回归 y = β₁x₁ + β₂x₂ + β₀ 来拟合,y 的预测值可能远大于1或远小于0,这无法被解释为概率(概率必须在0到1之间)。
逻辑回归的妙招:逻辑回归在线性回归的基础上,加了一个函数,把这个无限的直线输出( y = β₁x₁ + β₂x₂ + β₀)压缩到 (0, 1) 的区间内 ,这个值就可以被解释为 属于录取的概率。
这个神奇的“压缩函数”叫做 Sigmoid 函数(或 Logistic 函数)。
Sigmoid 函数公式:g(z) = 1 / (1 + e^-z)
它的图形是一个漂亮的“S”型曲线:
当 z 趋近于正无穷时,g(z) 趋近于1;
当 z 趋近于负无穷时,g(z) 趋近于0。
当 z = 0 时,g(z) = 0.5。这个0.5就是“决策边界”,也就是我们需要的“录取概率”。
2.实战准备——学生录取数据集
# 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 假设我们从一个CSV文件加载数据
# 数据格式:exam1_score, exam2_score, admitted
data = pd.read_csv('student_admission.csv') # 你需要替换为实际文件路径
print(data.head())
print("\n数据基本信息:")
print(data.info())
print("\n标签分布:")
print(data['admitted'].value_counts())
# 可视化数据:绘制散点图,按是否录取着色
plt.figure(figsize=(10, 6))
sns.scatterplot(x='exam1_score', y='exam2_score', hue='admitted', data=data, palette=['red', 'blue'], alpha=0.7)
plt.xlabel('Exam 1 Score')
plt.ylabel('Exam 2 Score')
plt.title('Student Admission Decision')
plt.legend(title='Admitted', loc='upper right') # 图例
plt.grid(True) # 显示网格
plt.show()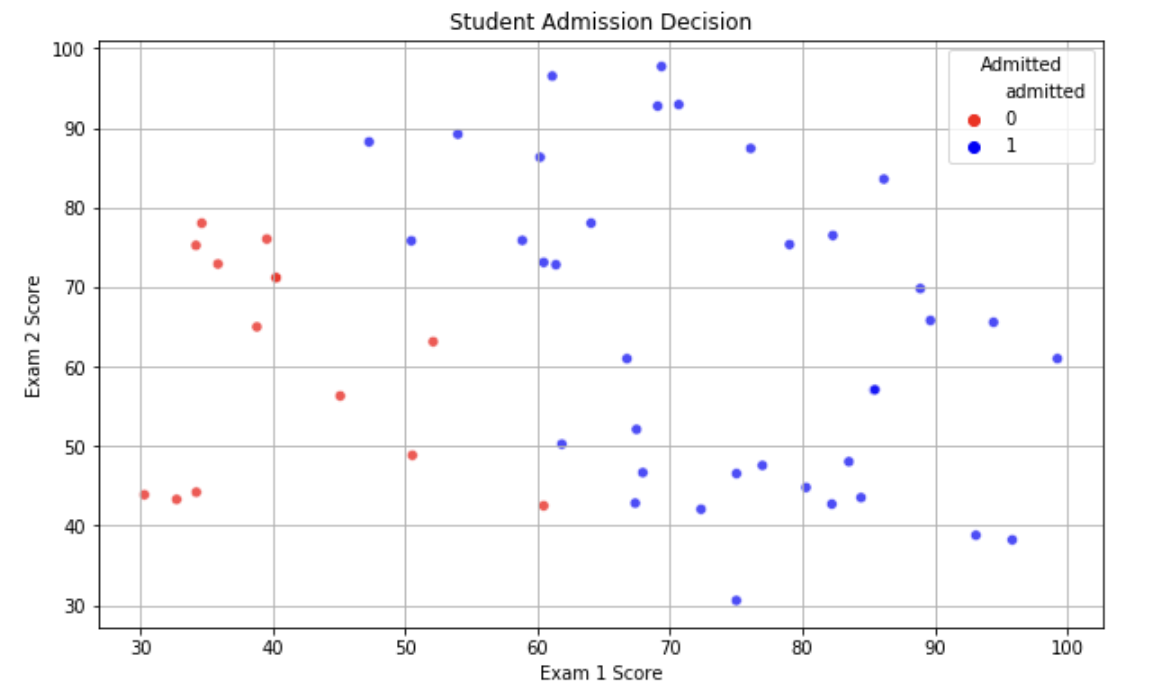
观察: 从图中可以清晰地看到,被录取(蓝色)和未被录取(红色)的学生被一条清晰的决策边界大致分隔开了。我们的目标就是让逻辑回归模型学会这条边界。
3. 构建与训练逻辑回归模型
代码和线性回归非常相似,这要感谢 scikit-learn 统一的API设计。
# 1. 准备特征 (X) 和目标 (y)
X = data[['exam1_score', 'exam2_score']]
y = data['admitted']
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) #test_size 设定测试集占20%,训练集占80%
# 3. 创建并训练逻辑回归模型
# 注意:这里用的是 LogisticRegression
logistic_model = LogisticRegression()
logistic_model.fit(X_train, y_train)
# 4. 查看学到的参数
print(f"模型截距 (β₀): {logistic_model.intercept_}")
print(f"模型系数 (β₁, β₂): {logistic_model.coef_}")
# 学到的模型其实是: z = β₁*exam1 + β₂*exam2 + w₀
# 然后 P(admit=1) = sigmoid(z)输出:
模型截距 (w₀): [-72.09940037]
模型系数 (w₁, w₂): [[0.8875101 0.37811319]]
将上述数据使用可视化工具绘制出决策边界:👇
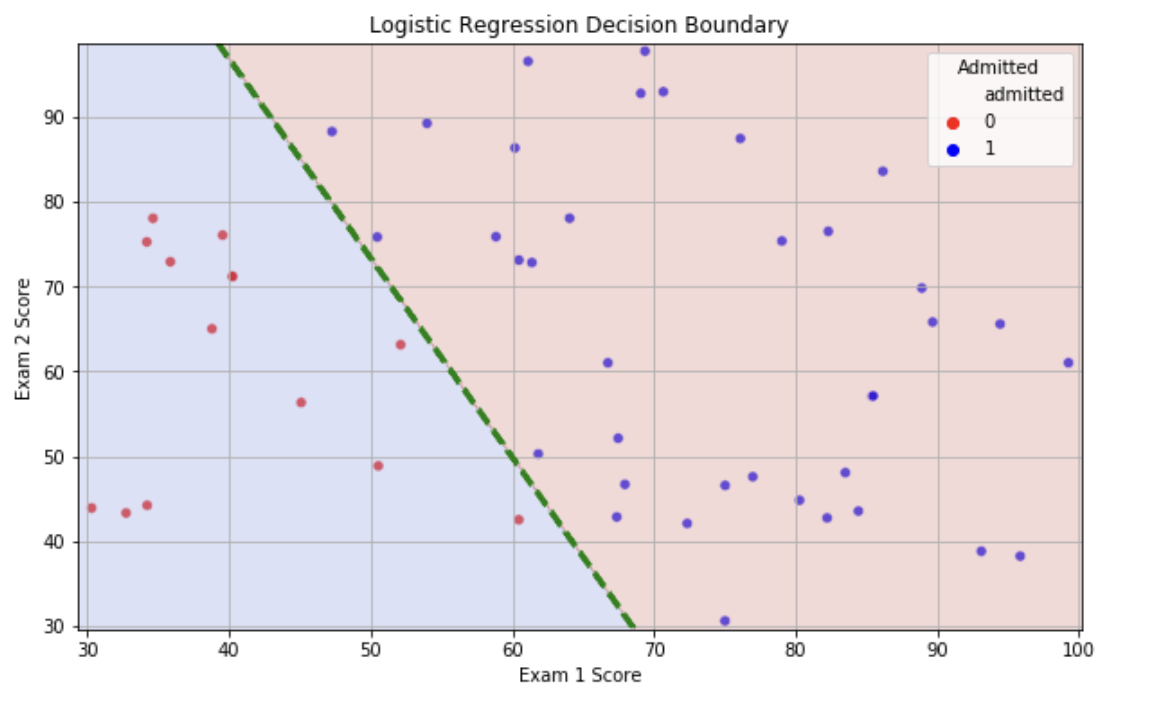
那条绿色的虚线 就是模型学到的决策边界。它的方程其实就是 w₁x₁ + w₂x₂ + w₀ = 0。
在绿色线 的右上方,模型预测 P(admit=1) > 0.5,属于“录取区”。
在绿色线 的左下方,模型预测 P(admit=1) < 0.5,属于“拒绝区”。
可以看到,模型成功地从数据中学习到了这条合理的分界线。
4. 模型评估
对于分类问题,准确率(Accuracy) 是最直观的指标。
# 在测试集上进行预测
y_pred = logistic_model.predict(X_test) # 这个可以得到预测值
y_pred_proba = logistic_model.predict_proba(X_test) # 这个可以得到概率值
# 计算准确率
accuracy = accuracy_score(y_test, y_pred) # 这个是sklearn自带的函数, 可以直接计算准确率
print(f"模型准确率: {accuracy:.2%}")线性回归和逻辑回归的区别 👇
| 方面 | 线性回归 | 逻辑回归 |
|---|---|---|
| 任务类型 | 回归(预测连续值) | 分类(预测离散类别) |
| 输出 | 任意实数 | 0 到 1 之间的概率 |
| 核心函数 | 无 | Sigmoid 函数 |
| 输出解释 | 直接是预测值 | 属于正类的概率 |
| 几何意义 | 一条最佳拟合直线 | 一条决策边界(直线、平面或曲线) |
总结
课堂作业
- 参考上述讲义完成:学生录取预测的实战代码。
- 逻辑回归的主要含义和主要过程
5.其他回归方式 了解内容
1. 多项式回归
多项式回归
1.多项式回归 - 拟合非线性关系
- 核心思想与解决的问题
问题:现实世界的关系往往是曲线的,而不是直的。比如,灯光亮度与距离的关系是二次的,技术学习的进步速度可能是指数或对数的。
解决方案:多项式回归不是用新的预测变量,而是将现有特征进行升维(比如平方、立方),从而用线性模型的方法来拟合非线性关系。
数学模型:👇
- 线性回归:y = β₁x₁ + β₂x₂ + β₀
- 多项式回归(2次):y = β₁x₁² + β₂x₂² + β₃x₁x₂ + β₀
- 多项式回归(n次):y = β₁x₁ⁿ + β₂x₂ⁿ + ... + βₙx₁x₂...xₙ + β₀
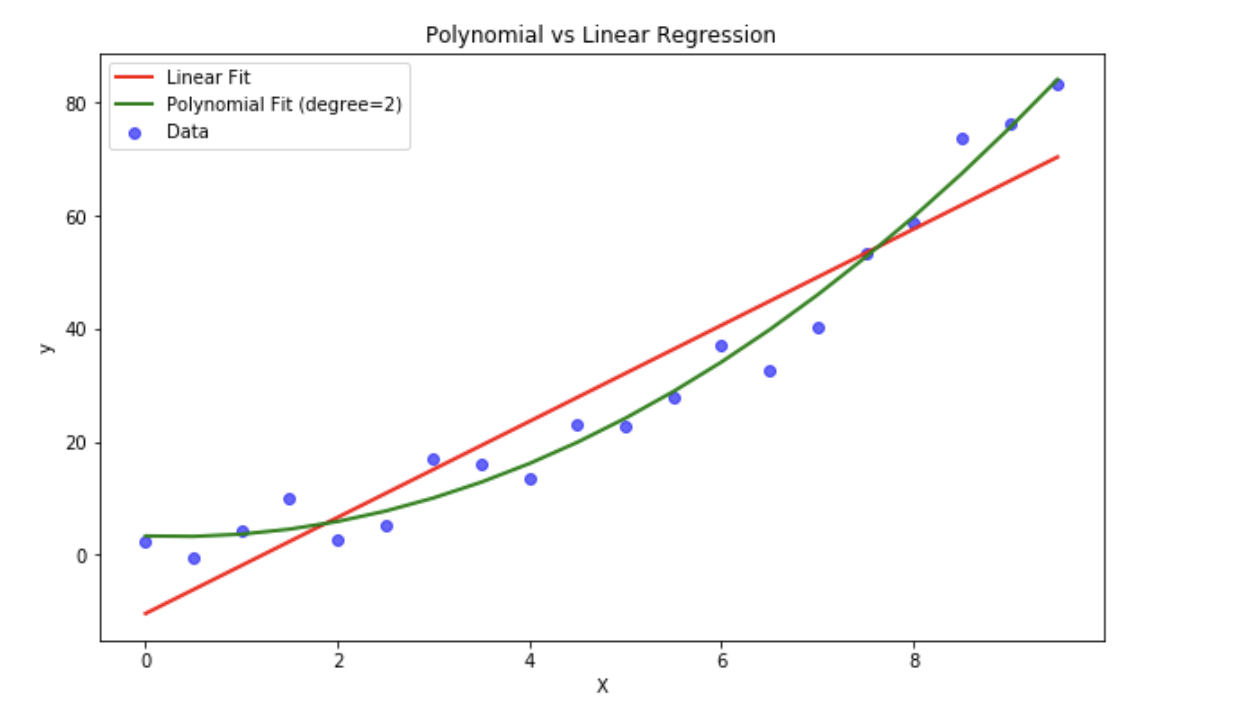
结果解读:
红色 的直线(线性回归)完全无法捕捉数据的真实趋势。
绿色 的曲线(多项式回归)完美地拟合了数据的非线性分布,MSE(均方误差) 非常小。
多项式的最大优点是可以增加X的高次项,对实测点进行逼近,直到满意为止,但是过高次数的多项式会导致过拟合,直观表现是模型在训练集上表现很好,但是在测试集上表现很差。如下图👇
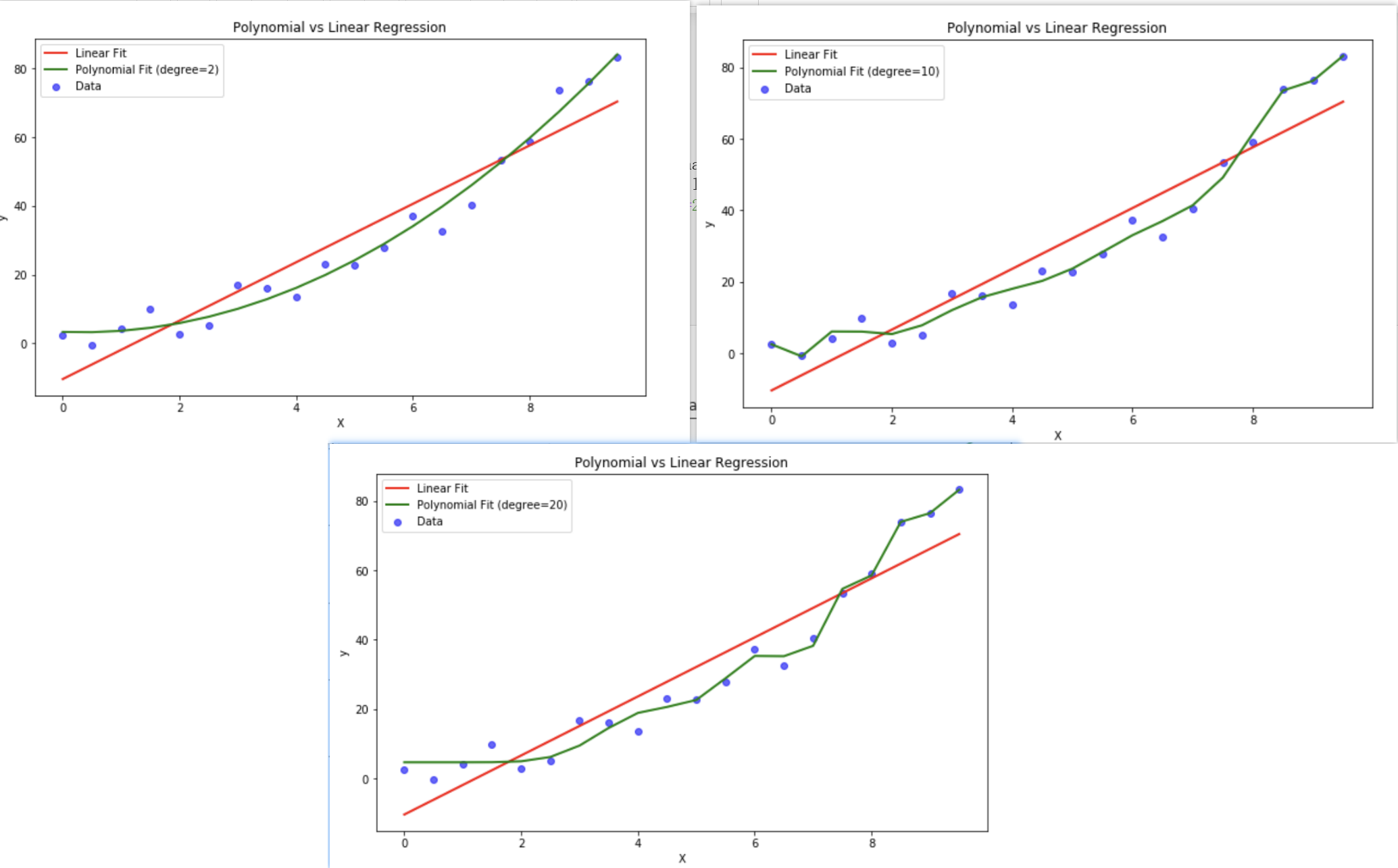
注意:degree(阶数)是超参数。阶数太低会欠拟合,太高会过拟合(疯狂抖动以穿过每一个点)。
案例对比:👇
案例对比
1. 准备数据
import numpy as np
import matplotlib.pyplot as plt # 绘图
x = np.random.uniform(-3,3, size=100) # 产生100个随机数
X = x.reshape(-1,1) #将x变成矩阵,1行1列的形式
y = 0.5 * x**2 +x +2 + np.random.normal(0,1,size=100) # 产生y,y是x的平方加上x再加上2,再加上一个正态分布的噪声
#数据中引入噪声
plt.scatter(x,y) #绘制散点图
plt.show()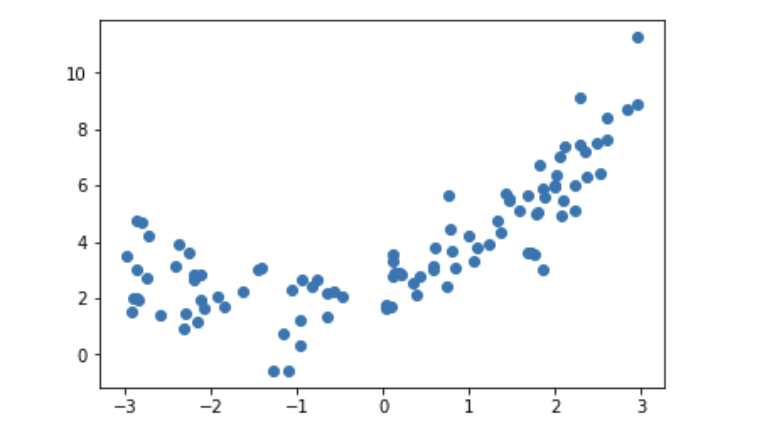
2. 线性回归
from sklearn.linear_model import LinearRegression
#线性回归
lin_reg = LinearRegression() #创建线性回归对象
lin_reg.fit(X,y)# 训练
y_predict = lin_reg.predict(X) # 预测
plt.rcParams['font.family']=['SimHei'] # 中文显示
plt.rcParams['axes.unicode_minus']=False # 负号显示
plt.title('线性回归') # 标题
plt.scatter(x,y) # 散点图
plt.plot(x,y_predict,color='r') # 拟合线
plt.show() # 显示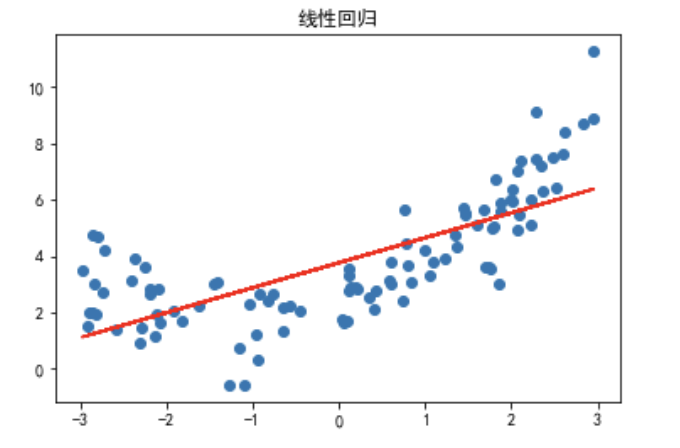
3.多项式回归(2次)
from sklearn.preprocessing import PolynomialFeatures # 引入多项式特征
from sklearn.linear_model import LinearRegression # 引入线性回归
poly = PolynomialFeatures(degree=2) # 创建多项式对象,degree为2次
#设置最多添加几次幂的特征项
poly.fit(X)
x2 = poly.transform(X) # 转换
#接下来的代码和线性回归一致
lin_reg2 = LinearRegression() # 创建线性回归对象
lin_reg2.fit(x2,y)#
y_predict2 = lin_reg2.predict(x2) #预测
plt.scatter(x,y)# 散点图
plt.plot(np.sort(x),y_predict2[np.argsort(x)],color='r') # 拟合线
plt.title('多项式回归 (degree=2)')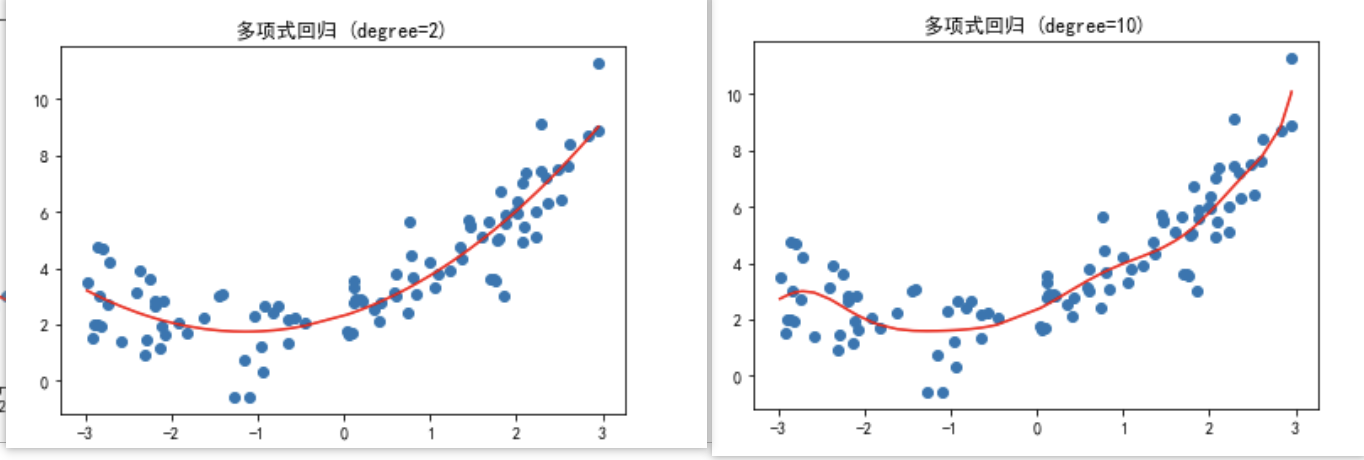
好了,通过案例,我们直观的发现,多项式回归可以拟合非线性关系,但是过高次数的多项式会导致过拟合,直观表现是模型在训练集上表现很好,但是在测试集上表现很差。
总结
课堂作业
- 多项式回归的高次越高越好,因为可以拟合非线性关系,这样就很准了,这句话对吗?。🎤
2. 岭回归
前言
岭回归是一种专用于处理多重共线性 数据的线性回归正则化技术。它通过在标准线性回归的损失函数中添加一个L2正则化惩罚项(所有系数平方和)来工作。
多重共线性就是多个特征高度相关(比如“身高”和“体重”),导致线性回归模型系数估计混乱(可能出现“体重越重,价格越低”这种荒谬结论)
在scikit-learn中,损失函数为 (1/N)MSE + alpha·∑ω²,其中N是样本数量,MSE是均方误差,alpha是正则化参数(统计学中叫λ,和α 一个意思),∑ω²是所有系数的平方和。
from sklearn.linear_model import Ridge
model = Ridge(alpha=0.1) # alpha即公式中的λ,损失函数为 (1/N)MSE + alpha·∑ω²岭回归解决思路:通过惩罚大系数λ(也叫alpha),强制压缩相关特征的系数绝对值,让它们“和平共处”,避免极端值,最终得到稳定、合理的系数(比如“身高和体重均正向影响价格”)。
简单说:让相关特征不再“争抢”贡献,而是“共同分担”,解决系数忽大忽小、符号异常的问题, 最终,得到一个“稳健”的模型。
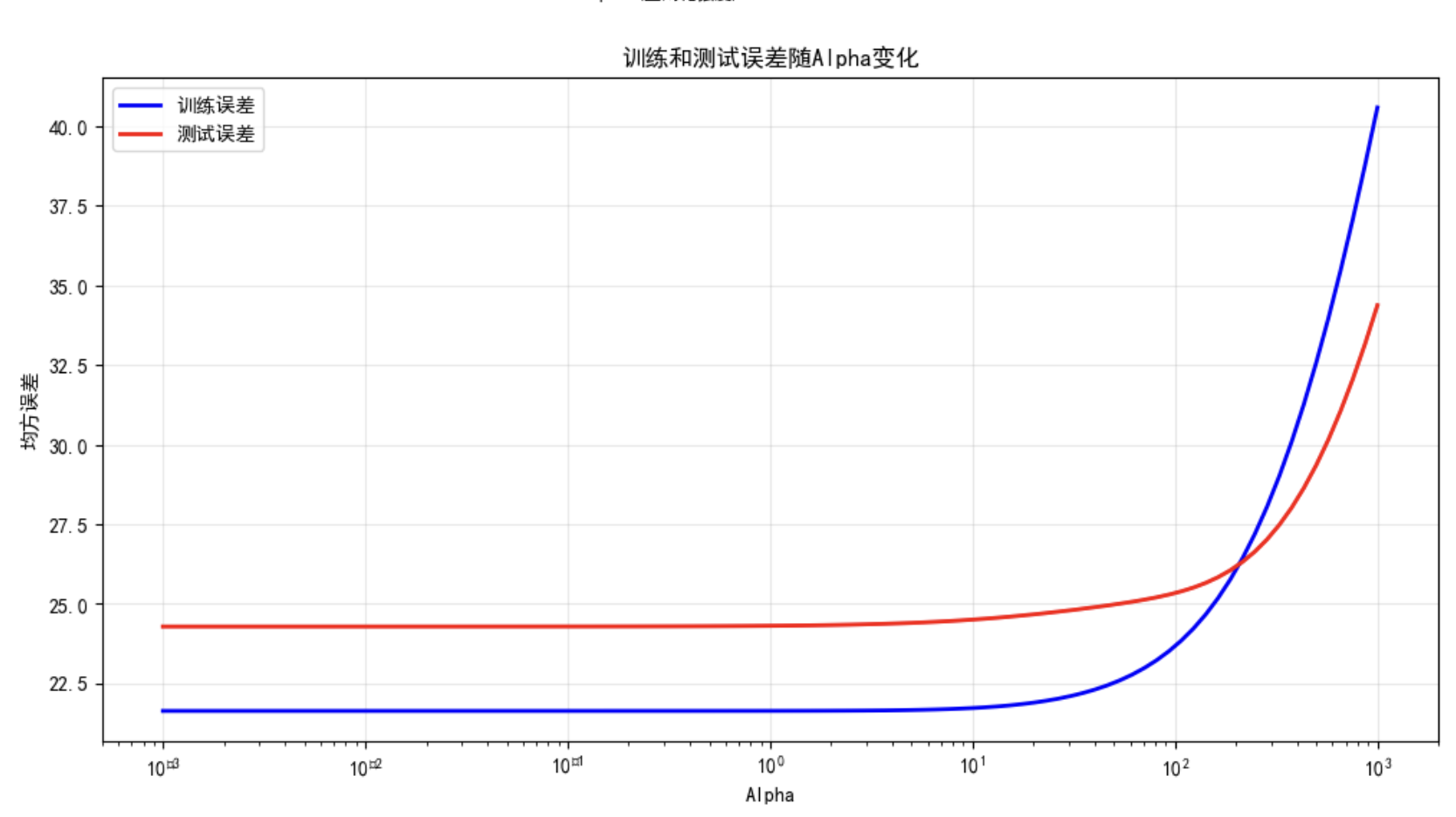
在最优 alpha 区间内,岭回归的系数是稳定的,训练误差和测试误差都趋于稳定的最小值。但是超过这个区间,岭回归的系数会变得不稳定,训练误差会继续下降,但测试误差会上升。
因此如何选择 alpha 值?---->在代码中使用交叉验证来选择最优的 alpha 值。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge,RidgeCV
# Ridge岭回归,RidgeCV带有广义交叉验证的岭回归
data=[
[0.07,3.12],[0.41,3.82],[0.99,4.55],[0.73,4.25],[0.98,4.56],
[0.55,3.92],[0.34,3.53],[0.03,3.15],[0.13,3.11],[0.13,3.15],
[0.31,3.47],[0.65,4.12],[0.73,4.28],[0.23,3.48],[0.96,4.65],
[0.62,3.95],[0.36,3.51],[0.15,3.12],[0.63,4.09],[0.23,3.46],
[0.08,3.22],[0.06,3.19],[0.92,4.63],[0.71,4.29],[0.01,3.08],
[0.34,3.45],[0.04,3.16],[0.21,3.36],[0.61,3.99],[0.54,3.89] ]
#生成X和y矩阵
dataMat = np.array(data)
X = dataMat[:,0:1] # 变量x
y = dataMat[:,1] #变量y
#可以使用Ridge手动设置alpha值
# model = Ridge(alpha=0.1) # 岭回归,设置alpha值为0.1
# 岭回归 # RidgeCV可以设置多个参数,算法使用交叉验证获取最佳参数值
# model = RidgeCV(alphas=[0.1, 1.0, 10.0]) # 岭回归,设置三个alpha值,算法使用交叉验证获取最佳参数值
model.fit(X, y) # 线性回归建模
print('系数矩阵:',model.coef_)
print('线性回归模型:\n',model)
# print('交叉验证最佳alpha值',model.alpha_)
# 只有在使用RidgeCV算法时才有效
# 使用模型预测
predicted = model.predict(X)
# 绘制散点图 参数:x横轴 y纵轴
plt.scatter(X, y, marker='o')
plt.plot(X, predicted,c='r')
# 绘制x轴和y轴坐标
plt.xlabel('x')
plt.ylabel('y')
# 显示图形
plt.show()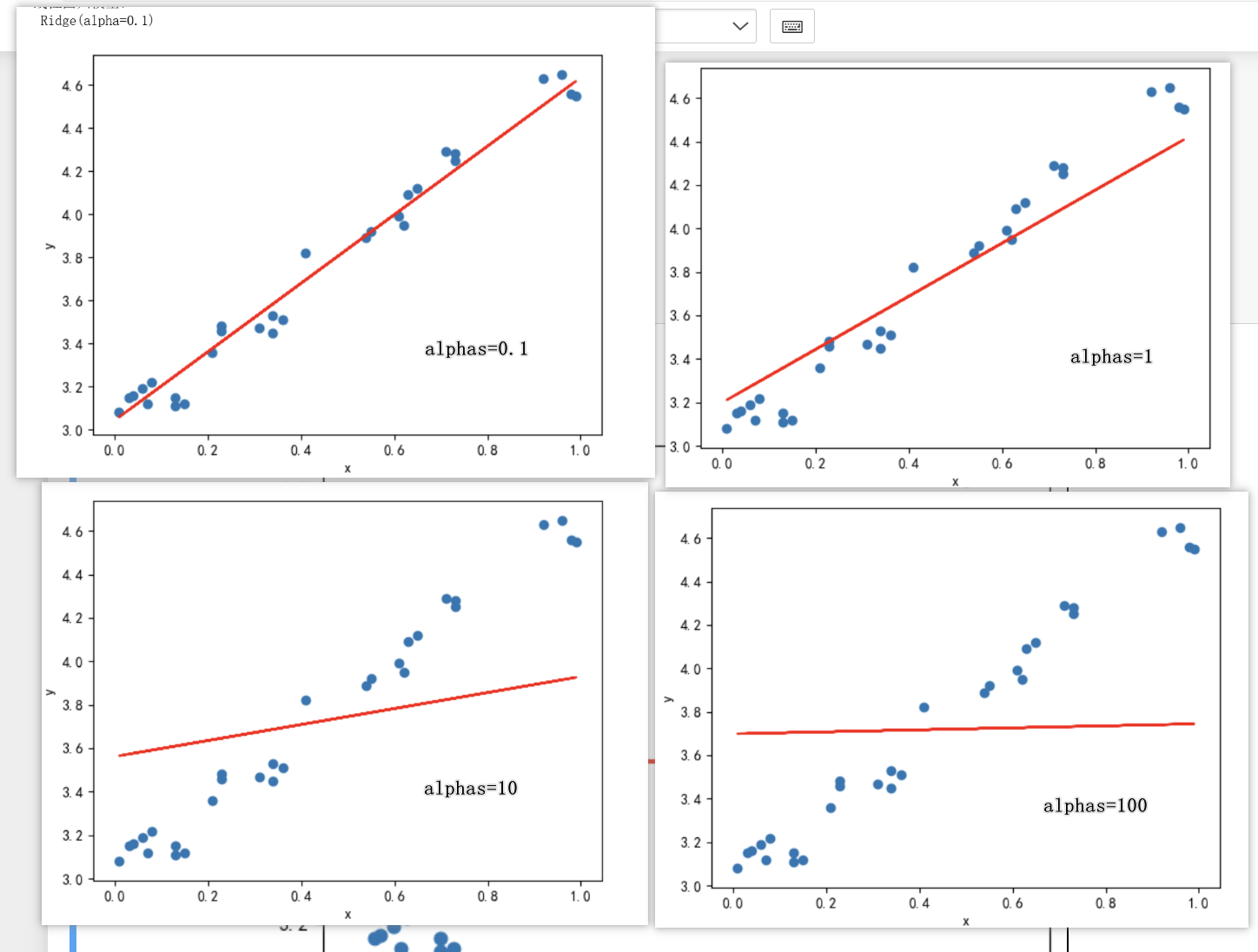
图中展示了不同alpha值下的模型效果,可以看到,当alpha值较小时,模型对噪声较为敏感,当alpha值较大时,模型对噪声不敏感,导致欠拟合。因此,选择合适的alpha值是岭回归的关键。
3. Lasso 回归
前言
相关信息
你在做一个电商转化率模型,有这些特征:
年龄、性别、浏览页数、加购次数、是否用iPhone、是否夜间访问、访问时长、点击banner的次数..等等
前前后后一共50个变量
用了线性回归:整个式子p值作废,大量VIX显示存在多重共线性;
用了岭回归:p值通过,但50多个变量都保留下来了,模型超复杂;
用了套索回归(Lasso):只保留了5个变量,且效果还准确;
岭回归无法剔除变量(特征) ,Lasso 回归可以剔除变量(特征) ,Lasso 回归是线性回归的正则化版本,它通过在标准线性回归的损失函数中添加一个L1正则化惩罚项(所有系数绝对值之和)来工作。
在scikit-learn中,损失函数为: (1/N)MSE + alpha·∑|ω|,其中N是样本数量,MSE是均方误差,alpha是正则化参数(统计学中叫λ,和α 一个意思),∑|ω|是所有系数绝对值之和。
记住:👇
- 岭回归:让权重“变小但都保留”, 是“温柔的压缩”:让相关特征系数和平共处,解决共线性;
- Lasso 回归:让权重“变小并剔除(删除特征)” 是“残酷的筛选”:直接剔除不重要特征,实现自动降维和特征选择。。
两者没有绝对优劣,而是 互补工具——实际应用中,可根据是否需要“特征选择”决定:需要精简模型选Lasso,需要保留全部特征选岭回归
案例:👇
下面的代码通过 “模拟高维稀疏数据”→“Lasso回归训练”→“系数可视化” 的流程,验证了Lasso的核心能力:在大量无关特征中,自动将90%的无关特征系数压缩至0,仅保留10个真实重要的特征,最终实现高精度预测(R²接近1)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import r2_score
#def main():
# 生成一个 “特征数量远多于样本量”(100个特征,50个样本)的高维稀疏数据集
np.random.seed(42) # 设置随机数种子,以便于结果可重现
n_samples, n_features = 50, 100 #50个样本,100个特征(典型高维数据:特征 >> 样本)
X = np.random.randn(n_samples, n_features) # 生成标准正态分布的特征矩阵(50行×100列)
# randn(...)产生的是正态分布的数据
coef = 3 * np.random.randn(n_features) # 生成真实系数(100个值,服从N(0,9)分布)
# 每个特征对应一个系数
inds = np.arange(n_features) # [0,1,2,...,99](特征索引)
np.random.shuffle(inds) # 打乱索引顺序(随机选择哪些特征是“重要特征”)
coef[inds[10:]] = 0 # 仅保留前10个打乱后的索引对应的系数,其余90个系数强制设为0!
y = np.dot(X, coef) # 计算真实目标值:y = X·coef(仅10个特征起作用)
# 添加噪声:零均值,标准差为 0.01 的高斯噪声
y += 0.01 * np.random.normal(size=n_samples) # 添加微小噪声(模拟真实数据的随机性)
# 把数据划分成训练集和测试集
n_samples = X.shape[0] # 50(样本量)
X_train, y_train = X[:n_samples // 2], y[:n_samples // 2] # 前25个样本作为训练集
X_test, y_test = X[n_samples // 2:], y[n_samples // 2:] # 后25个样本作为测试集
# 训练 Lasso 模型
from sklearn.linear_model import Lasso
alpha = 0.1 # 正则化强度(控制系数压缩程度)
lasso = Lasso(alpha=alpha) # 创建 Lasso 模型
y_pred_lasso = lasso.fit(X_train, y_train).predict(X_test) # 训练模型,并预测测试集的目标值
r2_score_lasso = r2_score(y_test, y_pred_lasso) # 计算预测的 R^2 得分
print("r^2 on test data : %f" % r2_score_lasso) # R²值:越接近1,模型拟合越好
plt.plot(lasso.coef_, color='gold', linewidth=2,label='Lasso coefficients')
plt.title("Lasso R^2: %f" % r2_score_lasso) # 输出测试集R²(通常接近1,因为Lasso能正确筛选特征)
plt.show()Lasso核心作用:在100个特征中,自动识别出那10个“真实非零系数的特征”,并将其余90个无关特征的系数压缩至0。
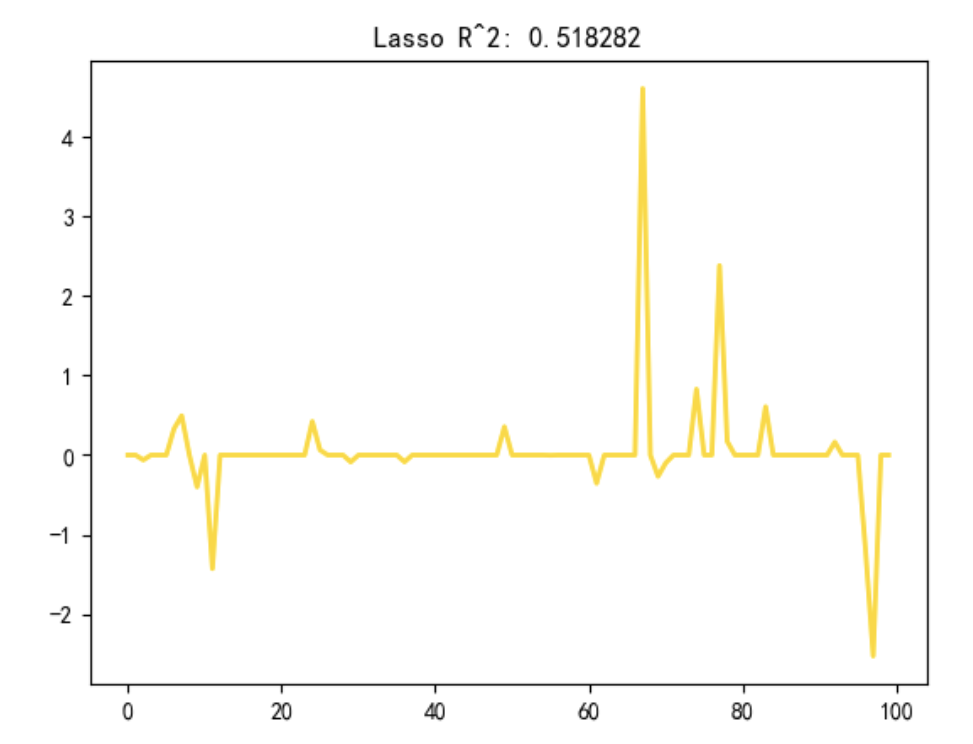
Lasso成功了,它会将90个“真实系数为0的特征”的模型系数压缩至0,只保留10个“真实非零系数的特征”的模型系数(非零) ——验证Lasso成功实现了“稀疏解”和“特征选择”
案例有点像:像老师设计“考试”,检验学生是否“真会”
注意事项
套索回归(Lasso Regression),注意事项:
- 变量在不同尺寸下不公平,需要进行标准化(Standardization)
- 对lamada非常敏感,千万别自己调。
4. 弹性网络回归
前言
弹性网络回归(Elastic Net Regression):
岭回归比较稳定,套索回归比较敏感,弹性网络回归是两者的结合,既有岭回归的稳定性,又有套索回归的敏感性,换句话说:即想挑变量,又不想删过头,就可以结合起来,这就是弹性网络回归。
比如:你有1000个变量,但是只有200个样本。如果用了套索回归,会把变量删的不合理了,如果用了岭回归不删有太臃肿了,弹性网络回归就是一个很好的选择,选掉多余的,又保留了关键特征。
总结
课堂作业
题目1:
你拿到一个数据集,有10个变量,样本只有200个,而且变量之间有不少明显相关性,你并不想删变量
请问你该用哪个回归方法?
- A. Ridge 岭回归
- B.Lasso 套索回归
- C.Elastic Net 弹性网络
A正确
题目2:

先看R平方,越大越好,再看测试集和训练集,差距越小越好,表示越稳