
数据仓库与数据挖掘-第一章节
通过本课的学习,学生应该掌握如下知识:
第五周,4个课时,第4张数据仓库、ETL与OLAP技术之理论第8课时
模块三之数据仓库ETL与OLAP技术
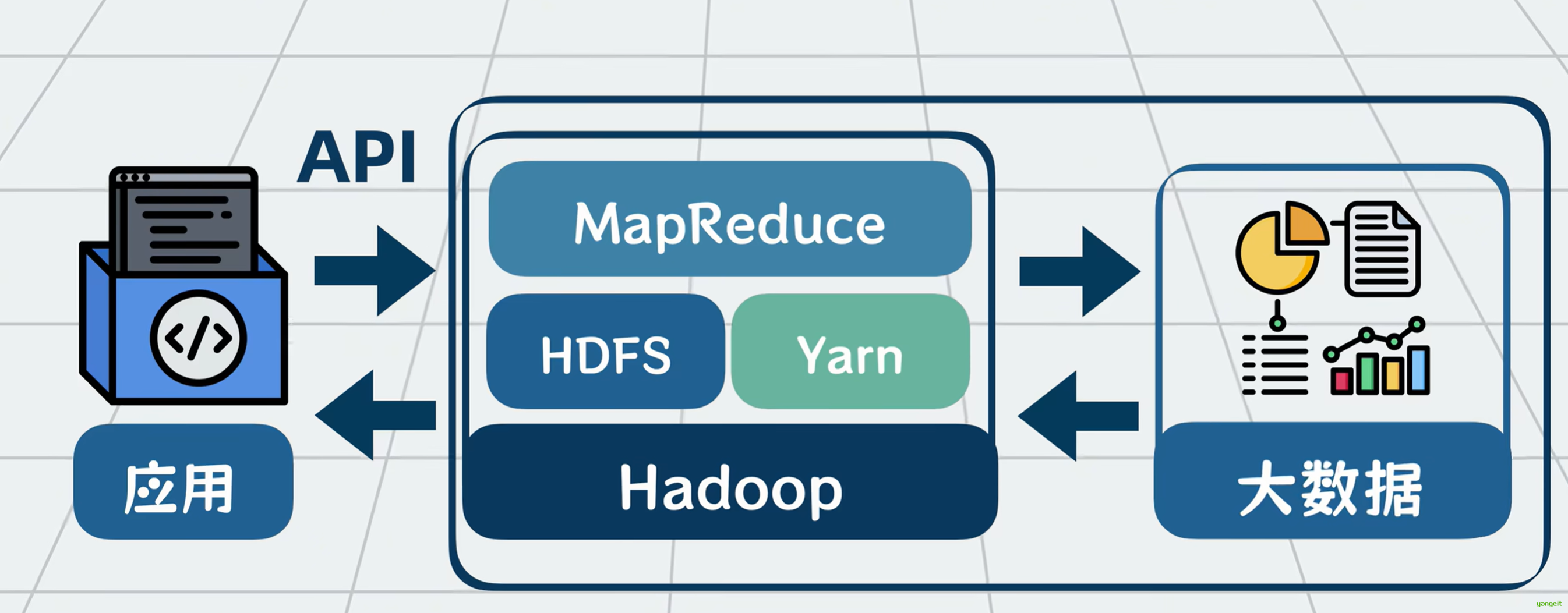
1.Hadoop的生态结构
数据仓库的发展
1. 大数据处理的背景
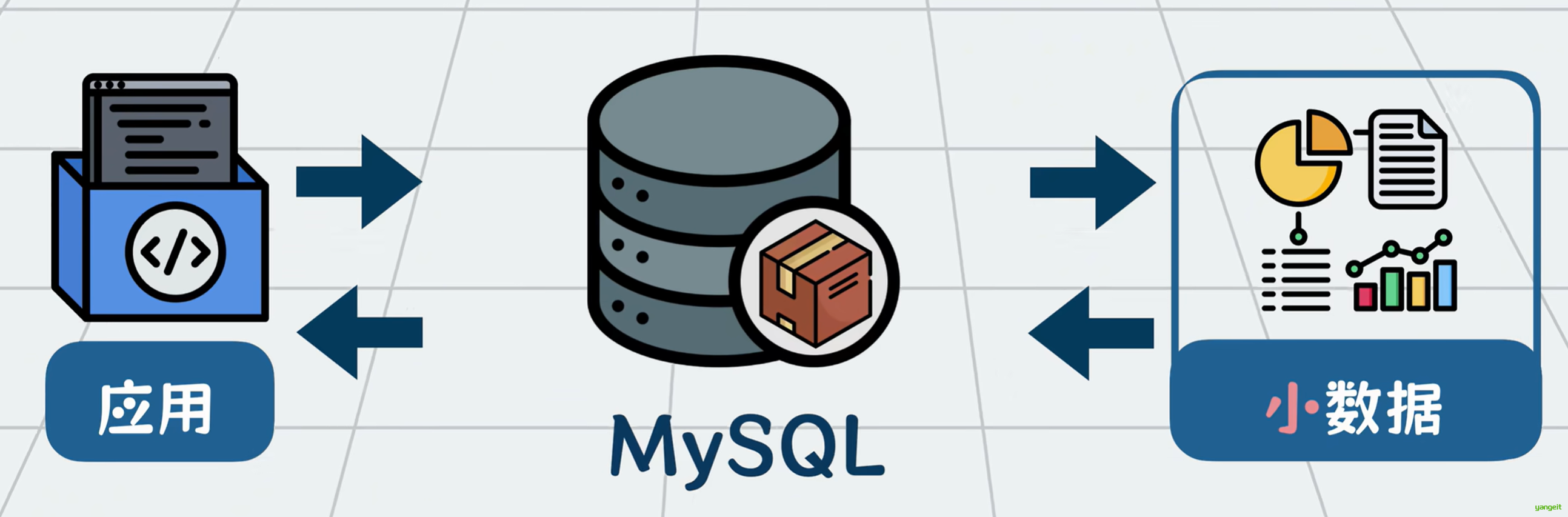
如果使用MySQL数据库将这海量的数据存起来,在执行sql执行统计,大概率会直接卡si。
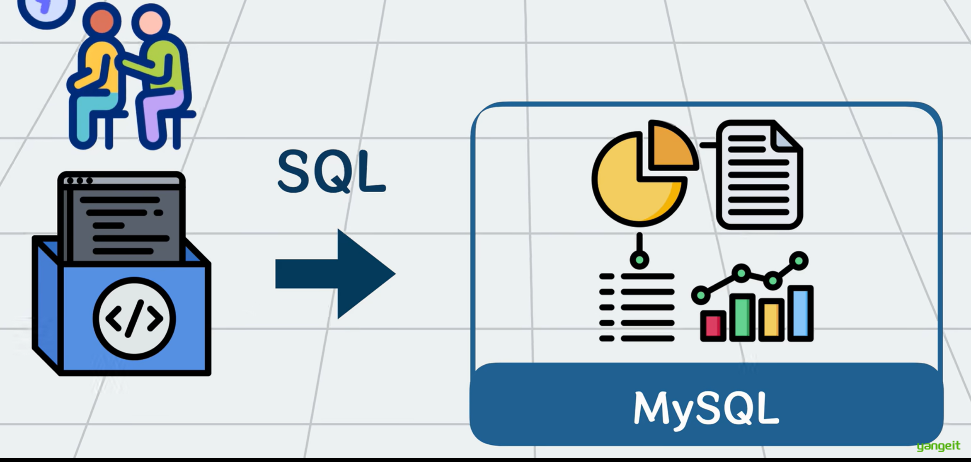
那怎么解决这个问题呢?可以加一个中间层(可以加上Hadoop全家桶和他的朋友们)
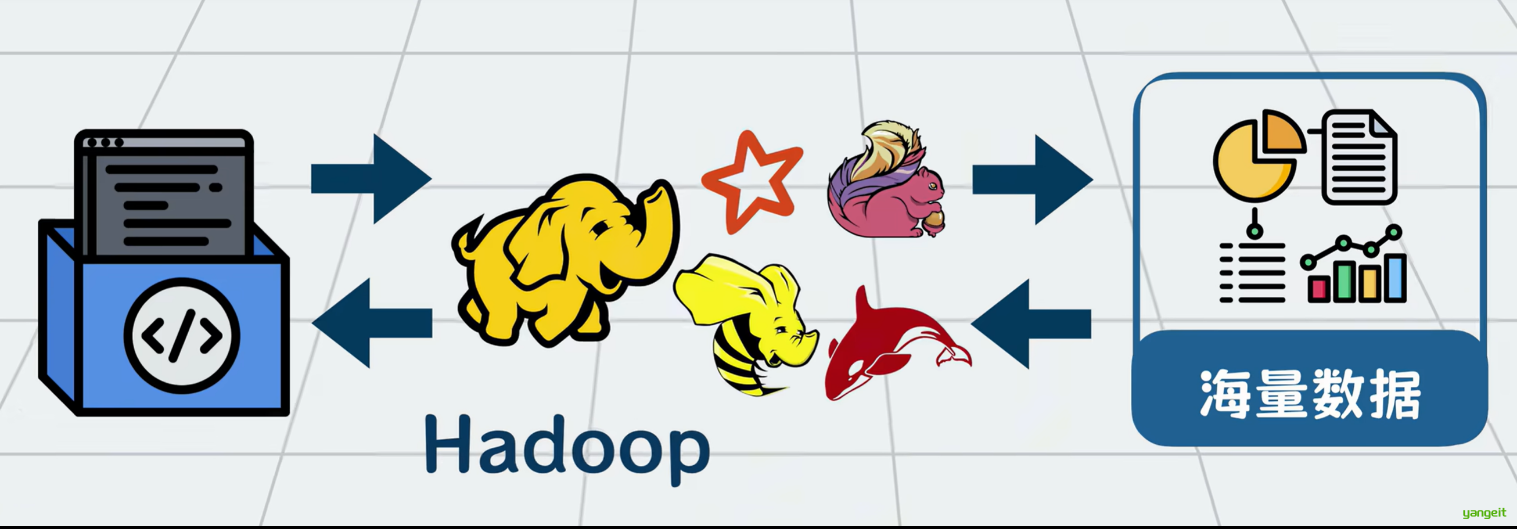
2.Hadoop是什么?
像我们平时用的MySQL处理个几百G数据就已经比较极限了,如果数据再大点,比如tb pb这样的规模,我们就称它为大数据。

它不仅数据规模大,增长速度也非常快,MYSQL根本扛不住。所以需要有专门的工具做处理。
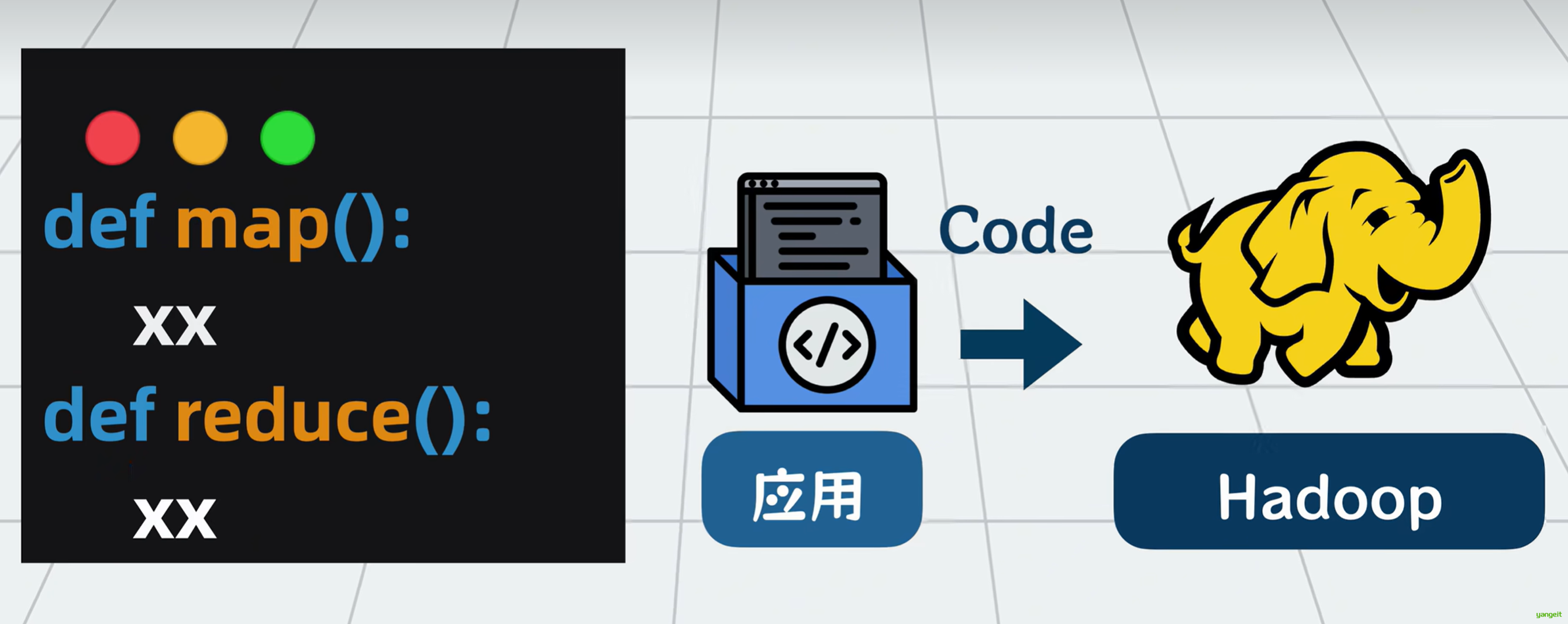
Hadoop就是一套专门用于大数据处理的工具,内部由多个组件构成,你可以将它理解为应用和大数据之间的一个中间层。
以前数据量小的时候,应用程序读写MYSQL,现在数据量大了,应用程序就改为读写Hadoop全家桶。
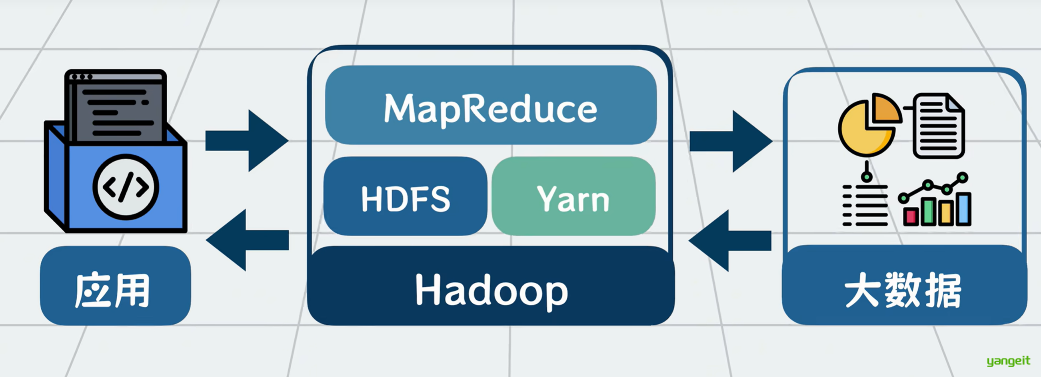
Hadoop为应用程序屏蔽了大数据的一些处理细节,对外提供一系列的读写API应用,通过调用API实现对大数据的处理。
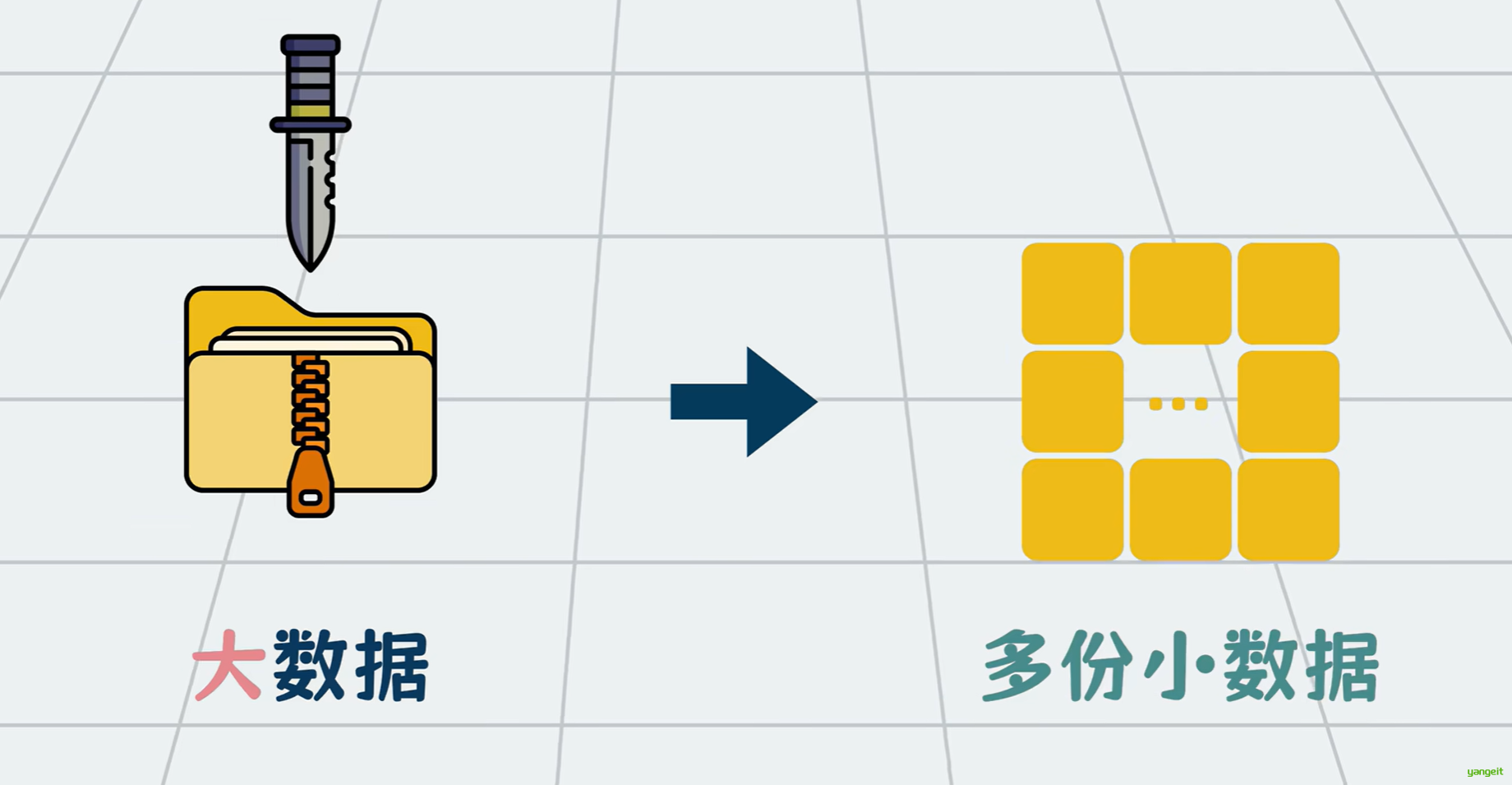
大数据之所以难处理,本质原因在于它大,所以解决思路也很简单,核心只有一个字那就是切 ,将处理不过来的大数据切分成一份份处理得过来的小数据,对小份数据进行存储计算等一系列操作。
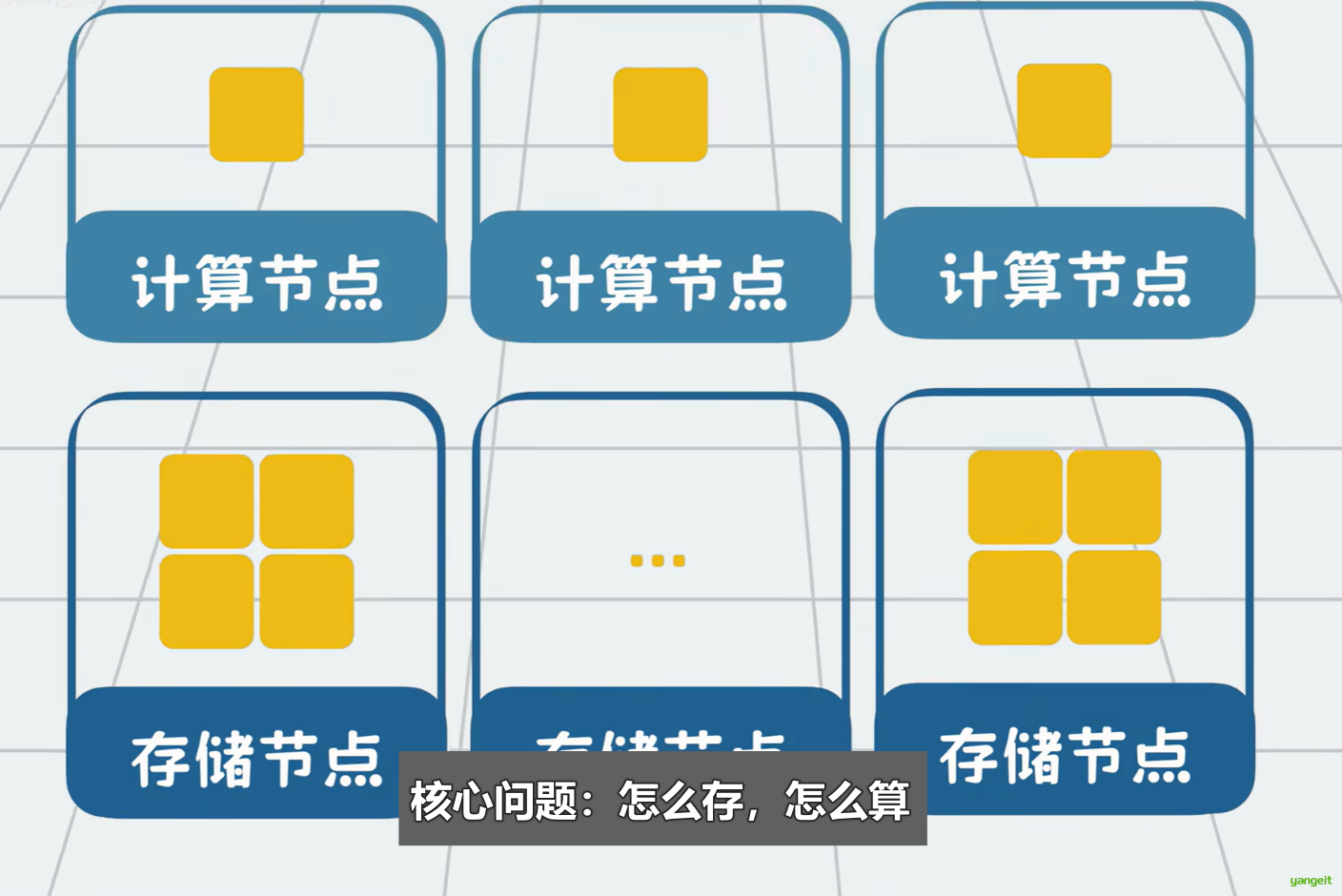
所以Hadoop要解决的核心问题就是怎么存,怎么算?
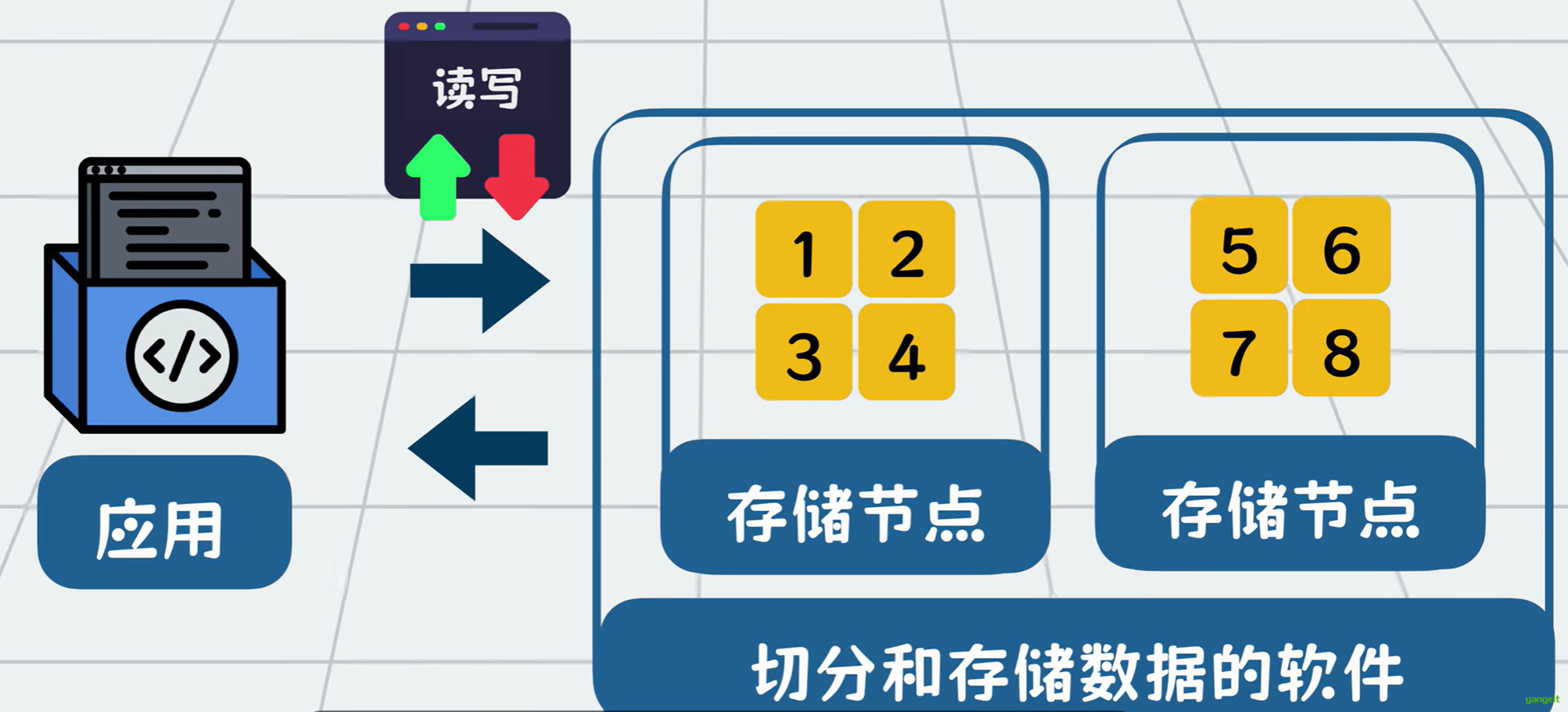
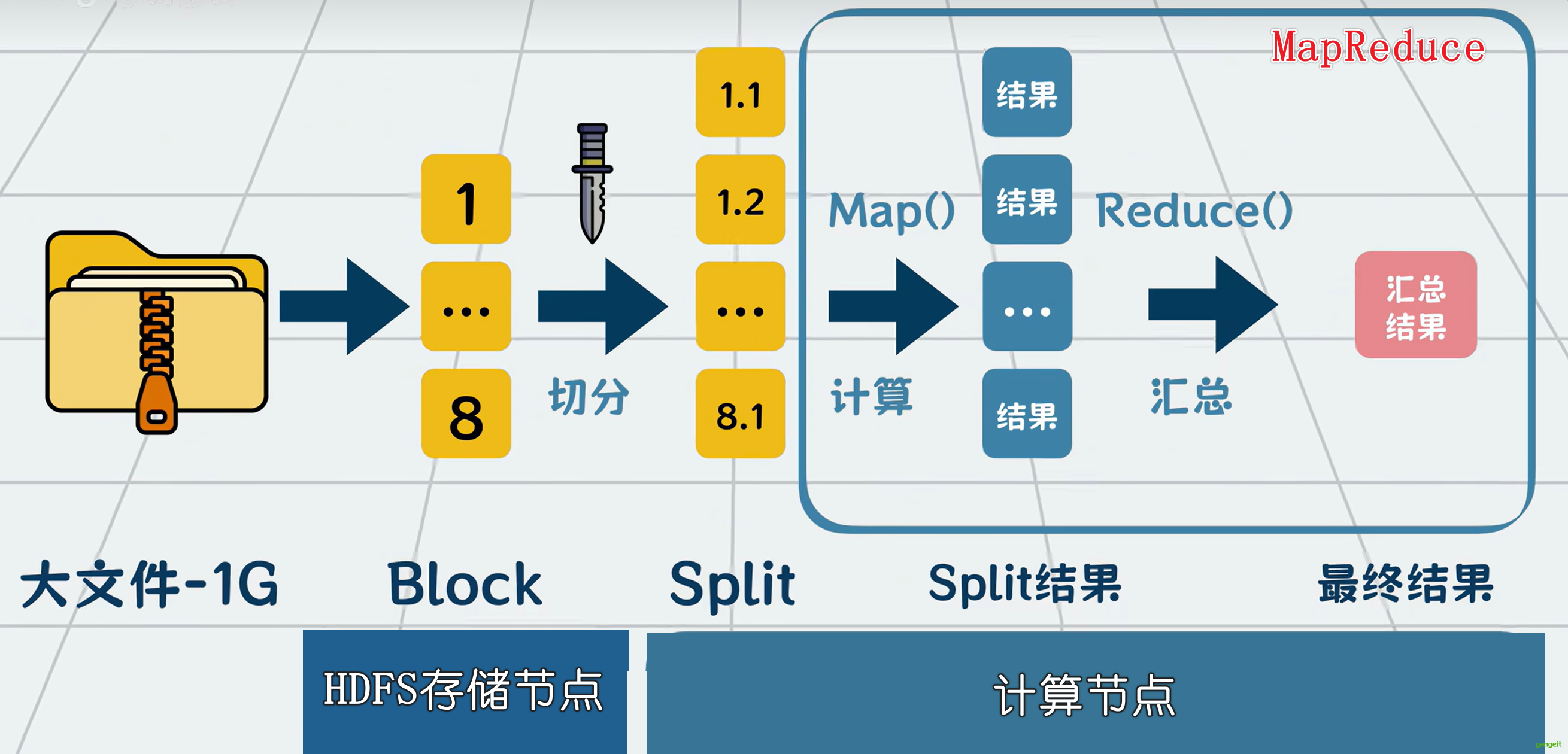
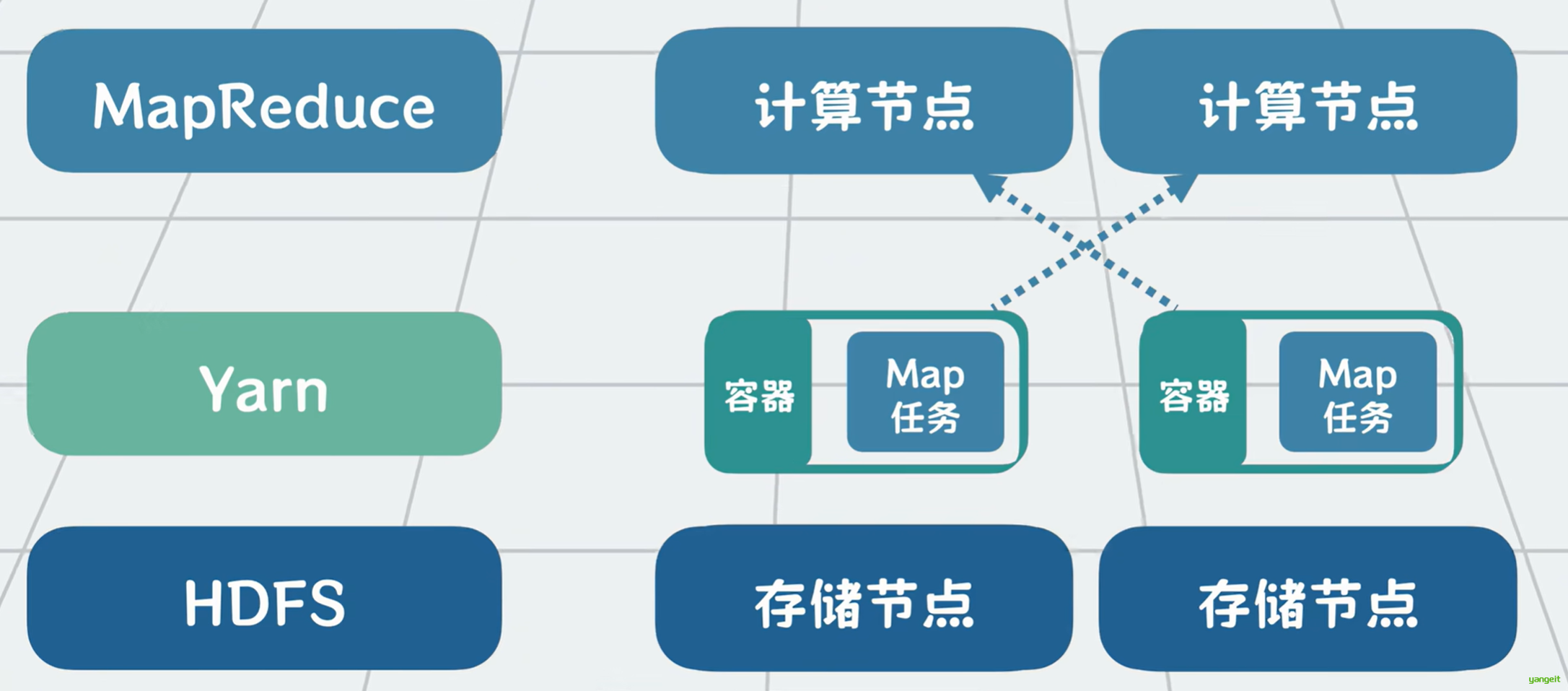
对于tb pb级别的大数据,一台服务器的硬盘装不下,我们就用多台服务器的硬盘来装。文件太大,那就切,我们可以将大文件切分成一个个128兆的数据块,也就是block放到多台服务器硬盘上。怕一台数据崩了,影响数据完整性,那就多复制几份数据,在多台服务器备份。这些存放数据的服务器就叫DataNode 。以前我们只需要从一台服务器里读写数据,现在就变成了需要在多台服务器里读写数据。因此需要有一个软件为我们屏蔽多台服务器的读写复杂性,这个负责切分和存储数据的分布式软件就叫HDFS(HDP的分布式文件系统)。
**大数据的存储问题是解决了,那怎么对大数据进行计算呢?**比如我们需要统计商城所有用户订单的性别和消费金额。假设商城的全部订单数据共1280G,想从HDFS全部加载到内存中做计算,没有一台服务器扛得住。有解法吗?有的,跟存储类似,也将数据切分为很多份,每份叫一个分片,也就是split ,分给多个服务器做计算,然后再将结果聚合(Reduce)起来就好啦。
但每个服务器怎么知道该怎么计算分片数据呢?当然是由开发者来告诉他们。我们需要定义一个map函数,告诉计算机每个分片数据里的每行订单数据该怎么算,再定义一个reduce函数,告诉计算机map函数算好的结果怎么汇总起来,计算最终结果。
这个从HDFS中获取数据,再切分数据为多个分片执行计算任务,并汇总的过程非常通用。用户只需要自定义里面的map和reduce函数,就能满足各种定制化需求。所以我们可以抽象为一个通用的代码库,它就是所谓的MapReduce 。
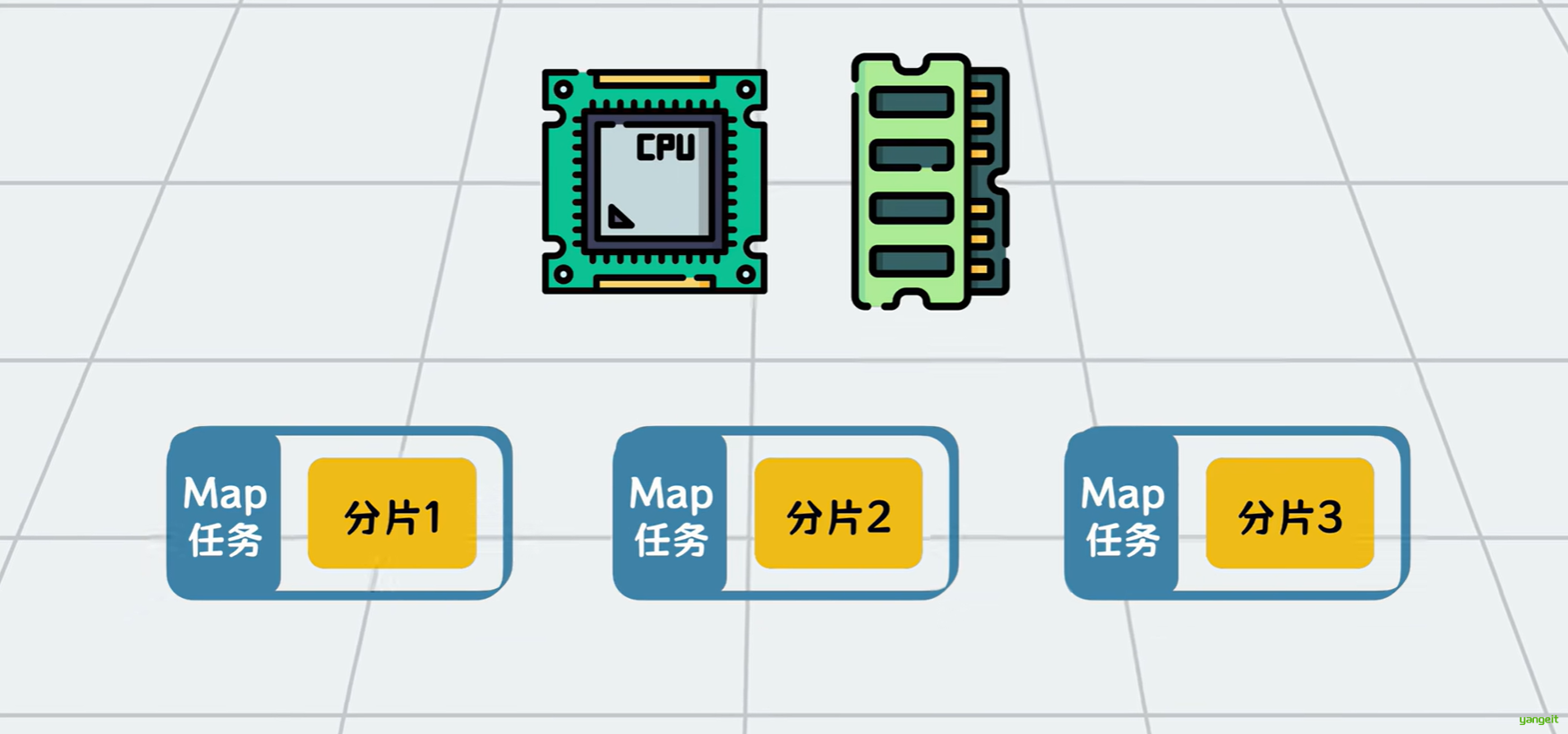
MapReduce的计算任务数量都这么多,每个任务都需要CPU和内存等服务器计算资源,怎么管理和安排这些计算任务到哪些服务器节点跑数据呢?
很容易想到,我们可以在计算任务和服务器之间加一个中间层,也就是大名鼎鼎的YARN(全名Yet Another Resource Negotiator),让他来负责资源的管理。
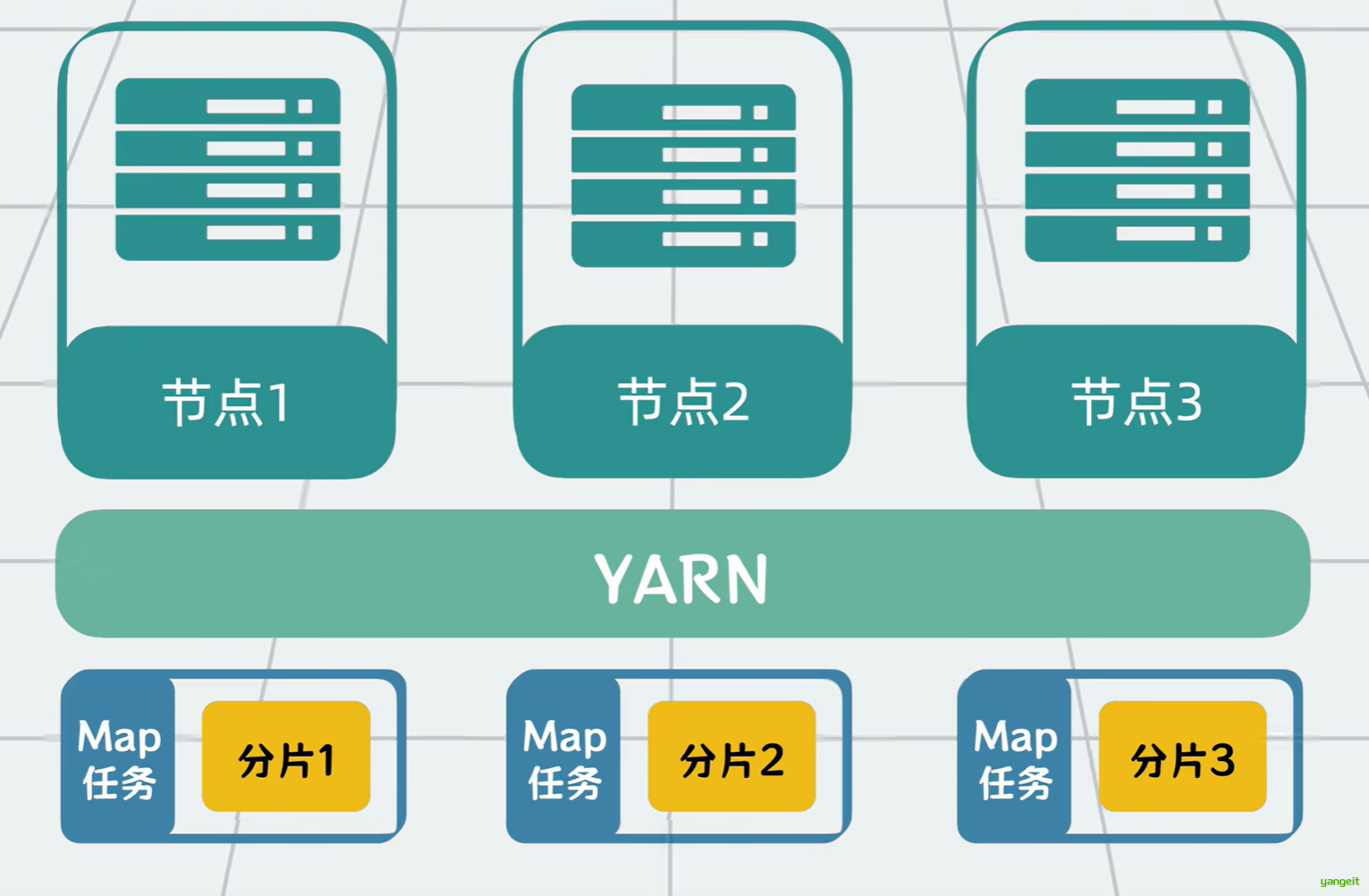
YARN会根据MapReduce这类计算框架的需求,分配容器资源,再由计算框架将计算任务调度到已分配的服务器容器上运行。通过一系列的资源申请加协调调度,完成Map和Reduce的计算任务,并最终得到计算结果。
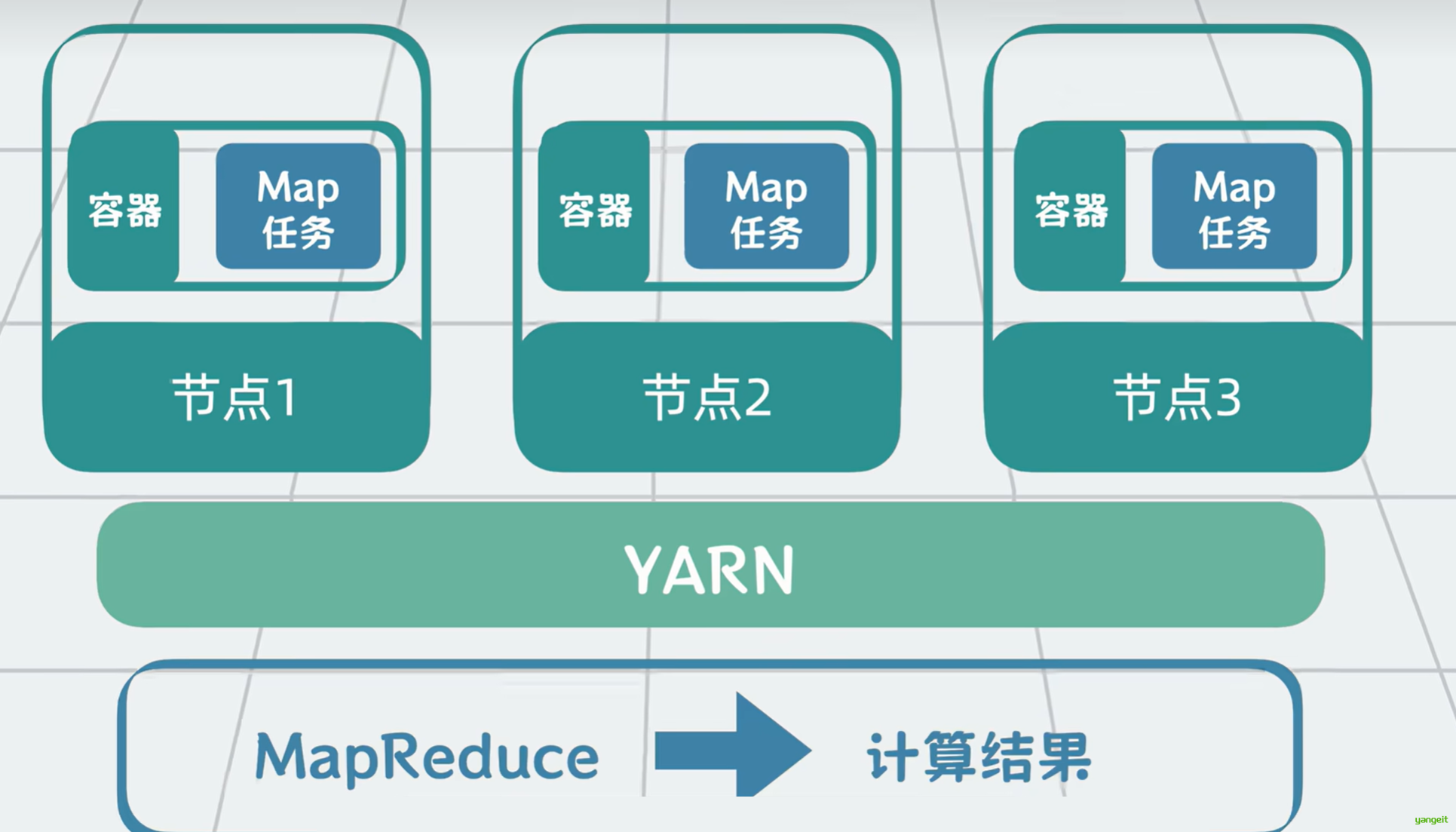
到这里,我们用HDFS解决了大数据的存储问题,用MapReduce解决了大数据计算问题,用YARN解决了MapReduce的计算资源管理问题。他们三个核心组件共同构成了Hadoop大数据处理框架 。
3.Hive是什么?
以前数据存在MySQL的时候,我想统计一下数据,做下数据分析只需要写点SQL。而现在在大数据场景下,却要我写那么多Map和Reduce函数,你搁这跟我开玩笑呢?这不变相逼着产品运营学编程吗?
那该怎么办呢?
为了让数据分析人员能够像使用SQL一样方便地查询大数据,我们需要一个工具来简化这个过程,它就是Hive 。
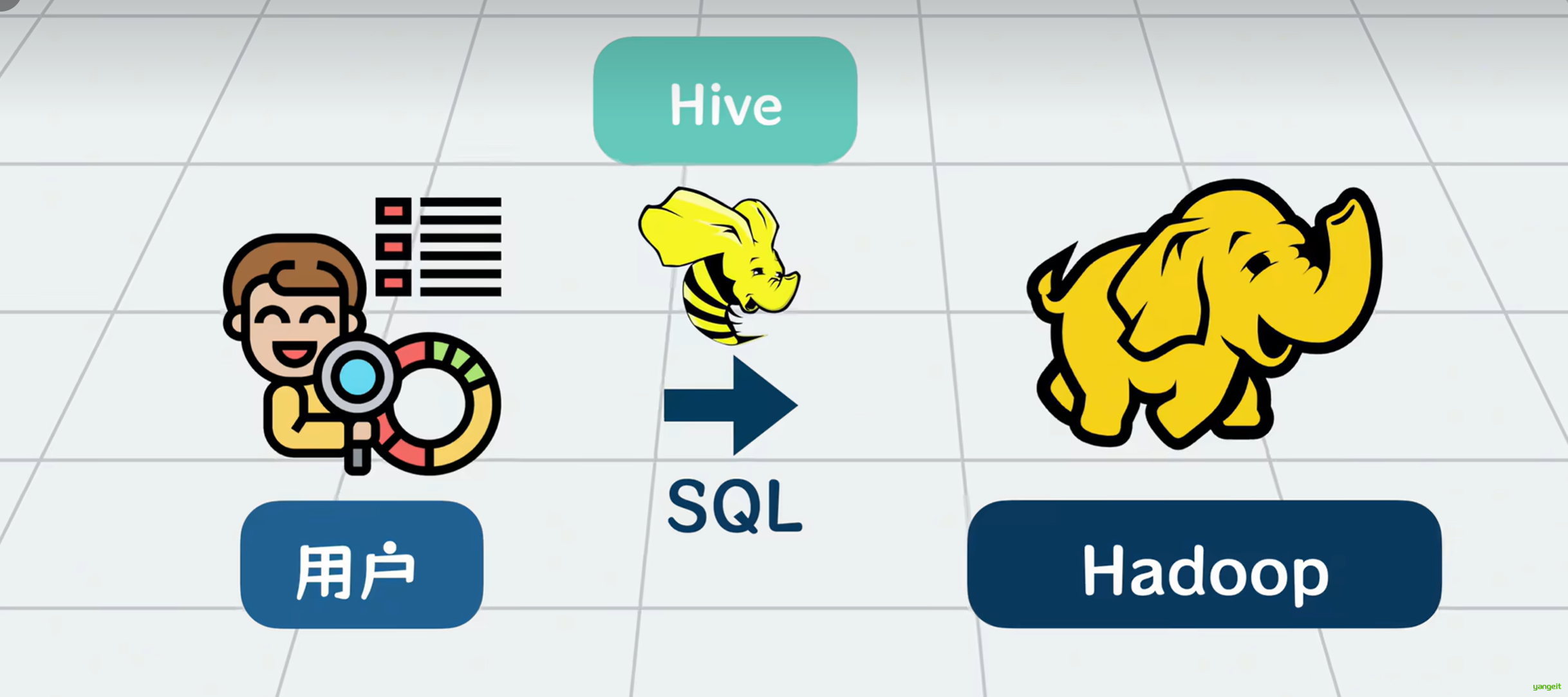
你可以将它理解为SQL和MapReduce的一个中间层------> 它可以将用户输入的类似SQL的查询语句 解析,转换成一个个复杂的MapReduce任务运行,并最终输出计算结果。这样,不会写代码的人,也可以通过写SQL来读写大数据了。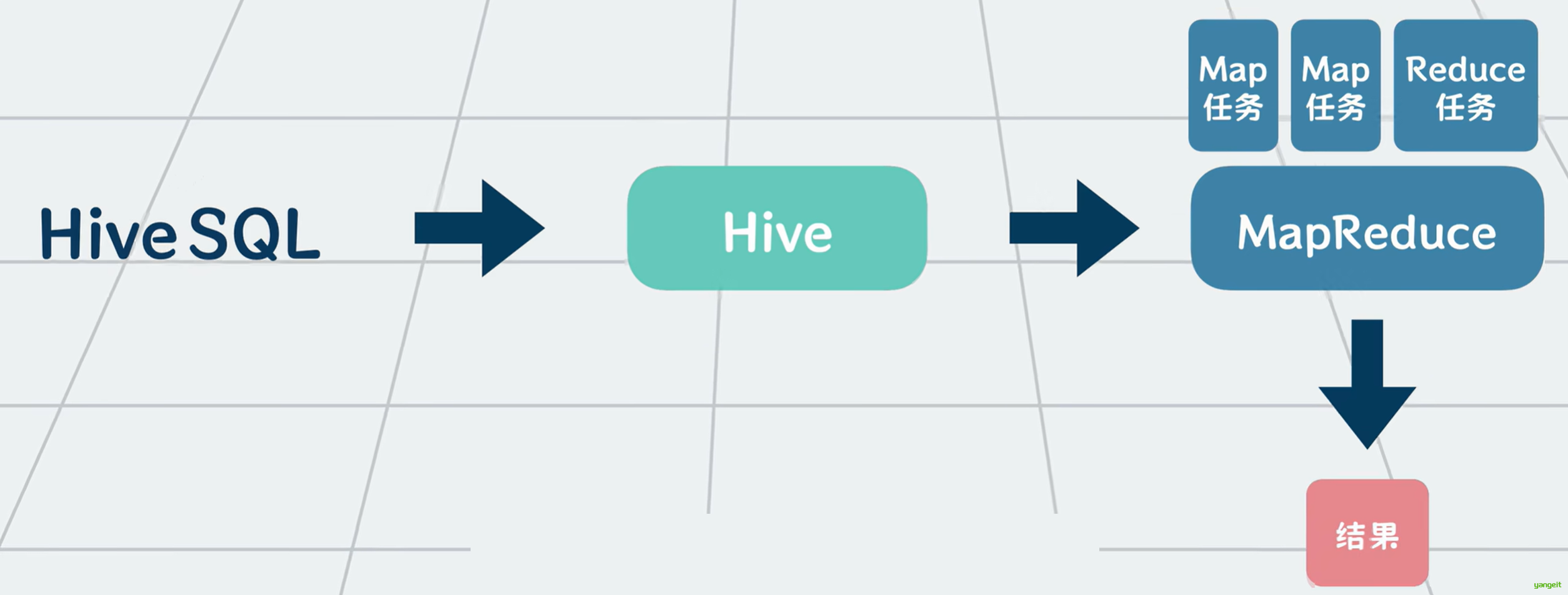
学到这里,请问Hive是数据仓库吗?
其实不是的,Hive不能存储数据,它只是一个数据仓库的查询引擎,它只负责将用户输入的SQL语句转换成MapReduce任务,并最终输出计算结果,你可以把他简单理解一个数据查询的客户端。
总结
课堂作业
- 简述Hadoop的生态结构,以及每个组件的功能。
- Hive是什么?他的主要功能是什么?他能存数据吗?
2. 虚拟机和Docker以及Docker Compose安装
虚拟机和Docker以及Docker Compose安装
接下来我们来安装Hive,这里我们使用虚拟机+docker的方式来安装,因为虚拟机安装比较简单,而且docker安装比较方便,而且我们使用docker安装,可以方便的在虚拟机中安装,也可以在物理机中安装。
1. 安装虚拟机
提前安装好VMware Workstation 16 Pro虚拟机软件,然后将老师提供的压缩包,解压到非中文目录,然后双击CentOS 7 64 位.vmx文件,进入wmware页面。
启动虚拟机后,可以输入用户名:root,密码:1234,进入系统。
可以使用 ip addr 查看ip地址 以及 ping wwww.baidu.com 查看网络是否连接。
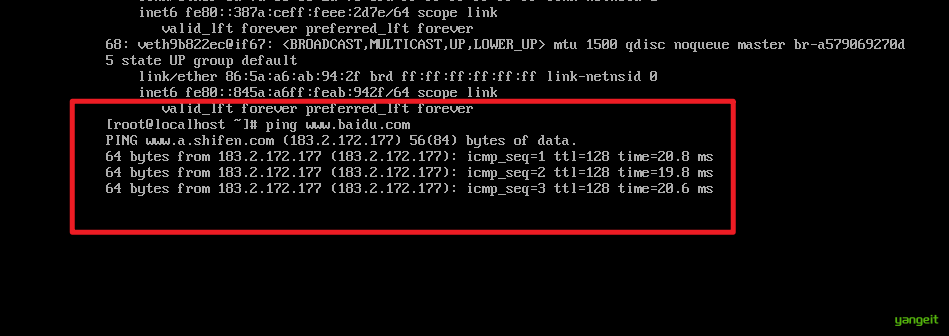
如果网络连接正常,接下来可以安装Docker了。
2. 安装Docker

docker安装非常简单,只需要在终端中输入以下命令即可安装。
置于Docker是什么?,这里不做过多解释,简单来说就是实用docker安装软件非常方便,如果感兴趣,可以自行学习。
焱哥笔记地址:http://www.yangeit.cn:21010/springcloud2023/Docker_basic.html
Docker CE 支持 64 位版本 CentOS 7,并且要求内核版本不低于 3.10, CentOS 7 满足最低内核的要求,所以我们在CentOS 7安装Docker。
1. 如果之前安装过旧版本的Docker,可以使用下面命令卸载:
# 卸载旧版本
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine \
docker-ce卸载后执行docker --version 如果出现未识别命令,则说明卸载成功。
2. 安装docker
2.1 首先需要大家虚拟机联网,安装yum工具
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2 --skip-broken2.2 然后更新本地镜像源:
yum-config-manager \
--add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repo
yum makecache fast2.3然后输入命令进行安装
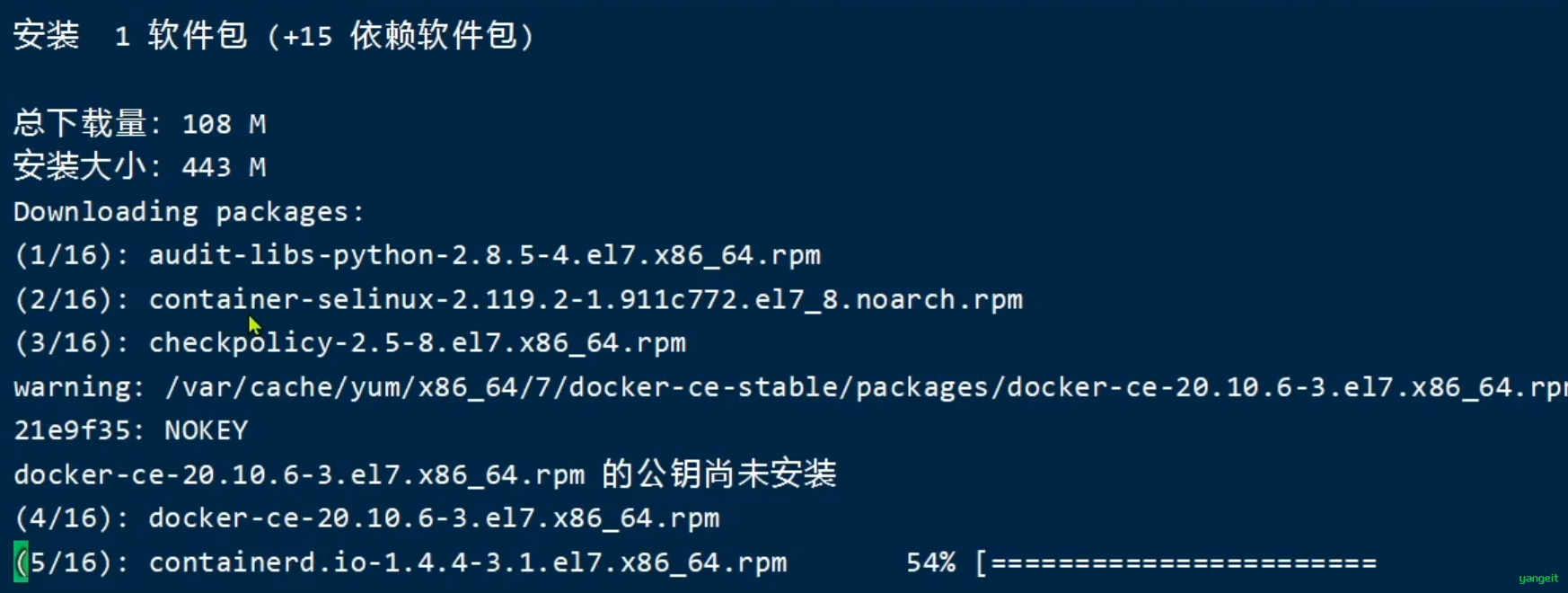
yum install -y docker-cedocker-ce为社区免费版本。稍等片刻,docker即可安装成功。
3. 启动Docker
Docker应用需要用到各种端口,逐一去修改防火墙设置。非常麻烦,因此建议大家直接关闭防火墙!
启动docker前,一定要关闭防火墙后!!
# 关闭
systemctl stop firewalld
# 禁止开机启动防火墙
systemctl disable firewalld
# 查看防火墙状态 如果为inactive 则表示关闭成功
systemctl status firewalld通过命令启动docker:
systemctl start docker # 启动docker服务
systemctl stop docker # 停止docker服务
systemctl restart docker # 重启docker服务
docker -v # 查看docker版本
4. 配置镜像加速
docker官方镜像仓库网速较差,我们需要设置国内镜像服务:
参考阿里云的镜像加速文档:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://am2ldpcg.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker注意 :一行一次执行,参考阴影
5. 安装docker基本指令不做要求,可以自行学习
好,到此,docker安装完成,接下来,我们了解下docker的基本指令
# 查看docker版本
docker version
# 查看镜像
docker images
# 查看容器
docker ps -a
# 启动容器
docker start 容器id
# 停止容器
docker stop 容器id
# 删除容器
docker rm 容器id
# 查看容器日志
docker logs 容器id
# 进入容器
docker exec -it 容器id bash
# 查看容器信息
docker inspect 容器id
# 查看docker服务状态
systemctl status docker
# 启动docker服务
systemctl start docker
# 重启docker服务
systemctl restart docker6. 安装docker-compose

docker-compose是用于定义和运行多容器Docker应用程序的工具。使用Compose,您可以使用YAML文件来配置您的应用程序服务。然后,使用一个命令就可以从配置中创建并启动所有服务。
说人话:就是如果要安装多个软件,可以使用docker-compose来一键安装,非常方便。
1. 下载或者导入docker-compose
因为docker-compose下载地址在外网,非常缓慢,可以使用课前资料提供的
docker-compose文件:
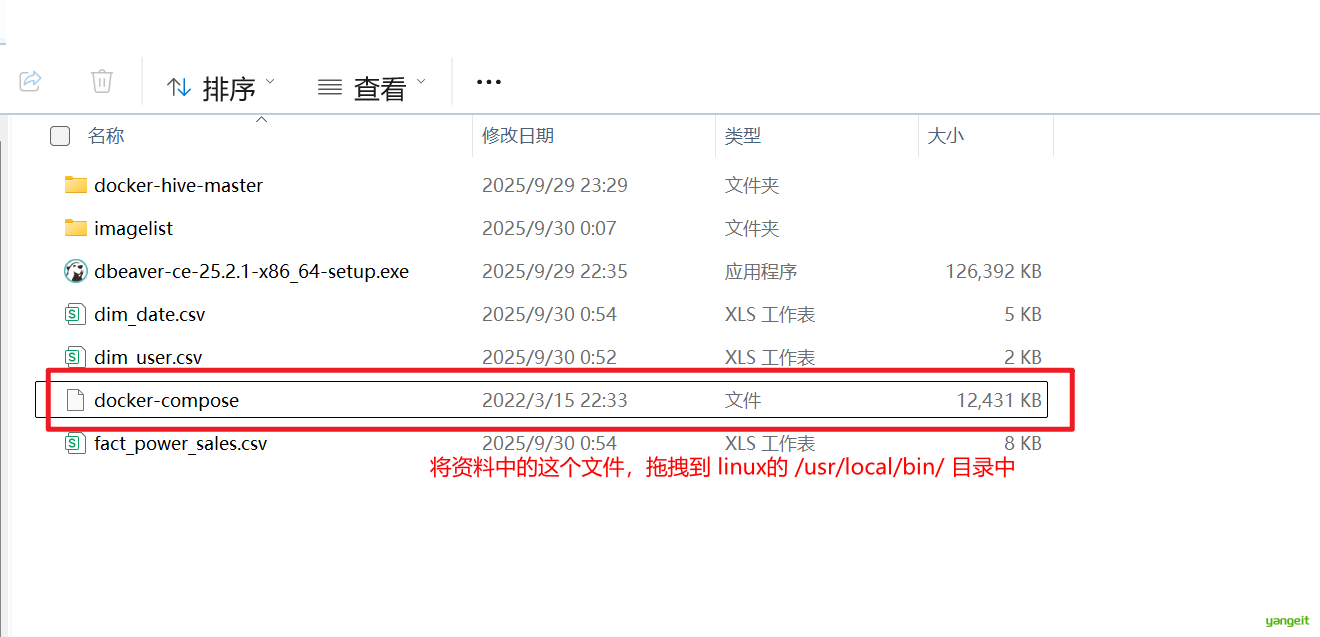
上传到/usr/local/bin/目录也可以。
2..修改文件权限
修改文件权限:
# 修改权限
chmod +x /usr/local/bin/docker-compose3.Base自动补全命令:
# 补全命令
curl -L https://raw.githubusercontent.com/docker/compose/1.29.1/contrib/completion/bash/docker-compose > /etc/bash_completion.d/docker-compose如果这里出现错误,需要修改自己的hosts文件:
echo "199.232.68.133 raw.githubusercontent.com" >> /etc/hosts注意: 如果安装不了,可以不安装
至此,我们已经安装好了docker和docker-compose,接下来,我们来安装Hadoop和hive测试环境。
总结
课堂作业
- 为什么要使用Docker来安装软件?🎤
- 参考上述教程,在自己的电脑上安装Docker和Docker-Compose,并测试成功。🎤
3. 安装Hadoop和Hive并测试
前言
首先,将课前资料中的docker-hive-master文件夹,拖拽到linux下的home目录下
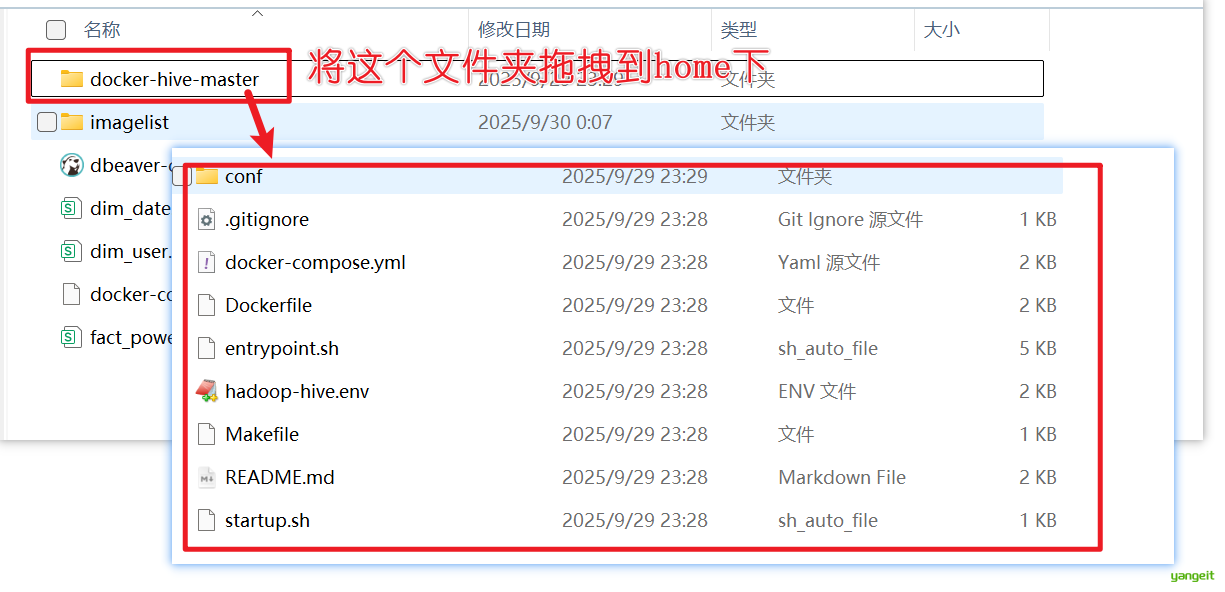
接下来在linux下 cd 到这个目录docker-hive-master
然后开始导入镜像文件(.tar文件),考虑到镜像比较大,下载很费时间,因此这里老师提供好各个软件的镜像压缩文件,大家导入到本地即可。如下图
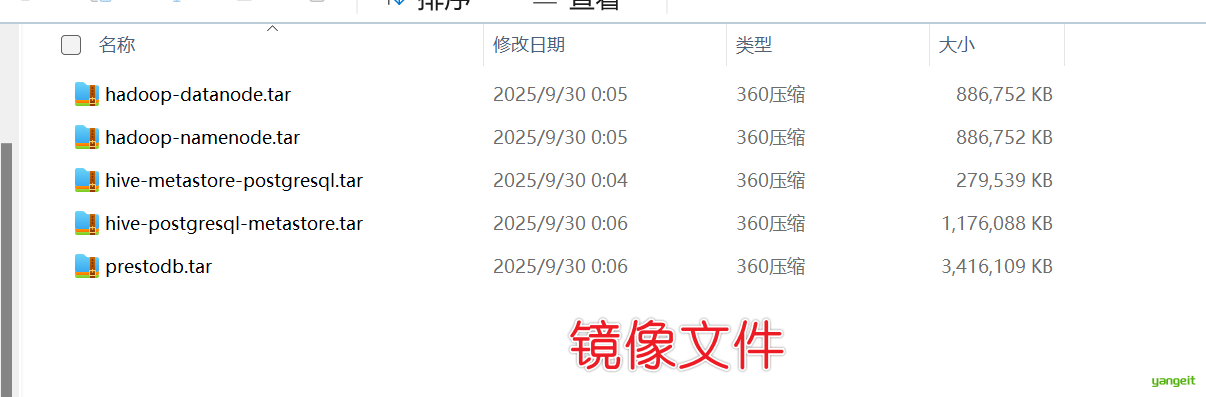
# 将资料文件拖拽到当前目录和docker-compose.yml文件同一目录
# 执行load命令将镜像导入到本地(镜像比较大,需要执行一个等待完成,在执行下一个)
docker load -i hadoop-datanode.tar
docker load -i hadoop-namenode.tar
docker load -i hive-metastore-postgresql.tar
docker load -i hive-postgresql-metastore.tar
docker load -i prestodb.tar
# 执行查看镜像 ,观察是否已经导入
docker images
导入完成后,我们来启动容器,并测试是否安装成功。👇
# 执行启动命令
docker-compose up -d
等待一下。。。。。
# 查看容器 是否如下图
docker-compose ps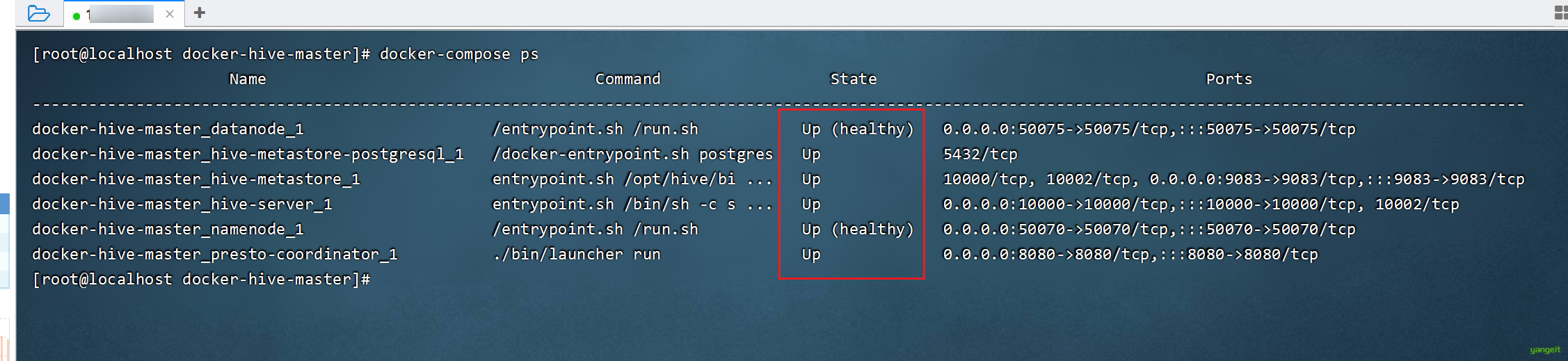
至此,Hadoop和Hive安装完成,接下来,我们来测试Hadoop和Hive是否安装成功。
使用Hive命令行
# 进入hive-server 这里命令要在docker-compose.yml文件同一目录下执行
docker-compose exec hive-server bash
# 使用beeline客户端连接
/opt/hive/bin/beeline -u jdbc:hive2://localhost:10000
# 执行SQL。这两句是可以直接执行的,镜像带了example文件
CREATE TABLE pokes (foo INT, bar STRING);
LOAD DATA LOCAL INPATH '/opt/hive/examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
# 查询
select * from pokes;如果结果如下图:
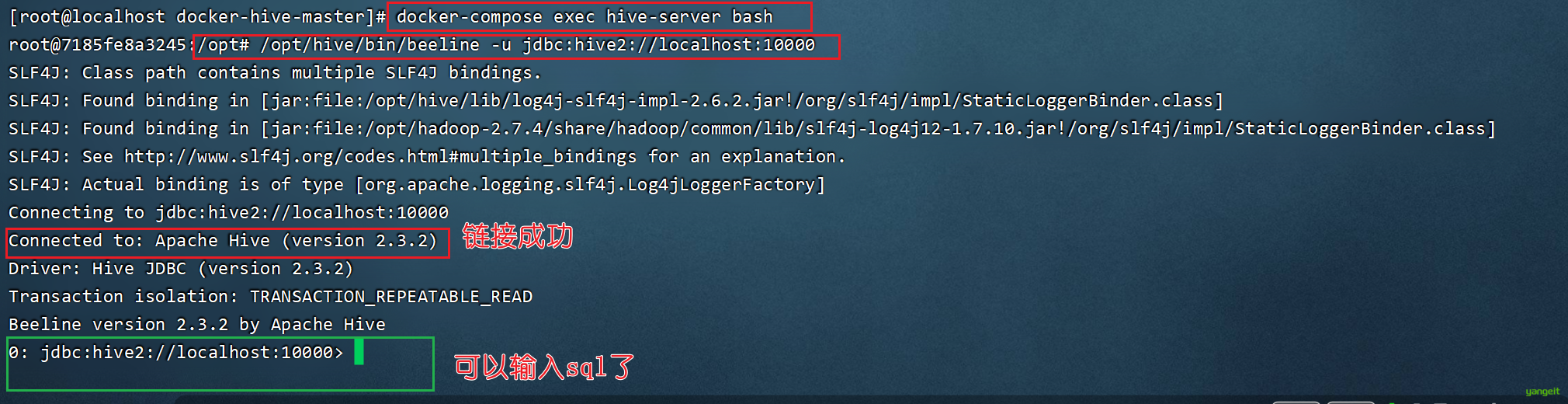
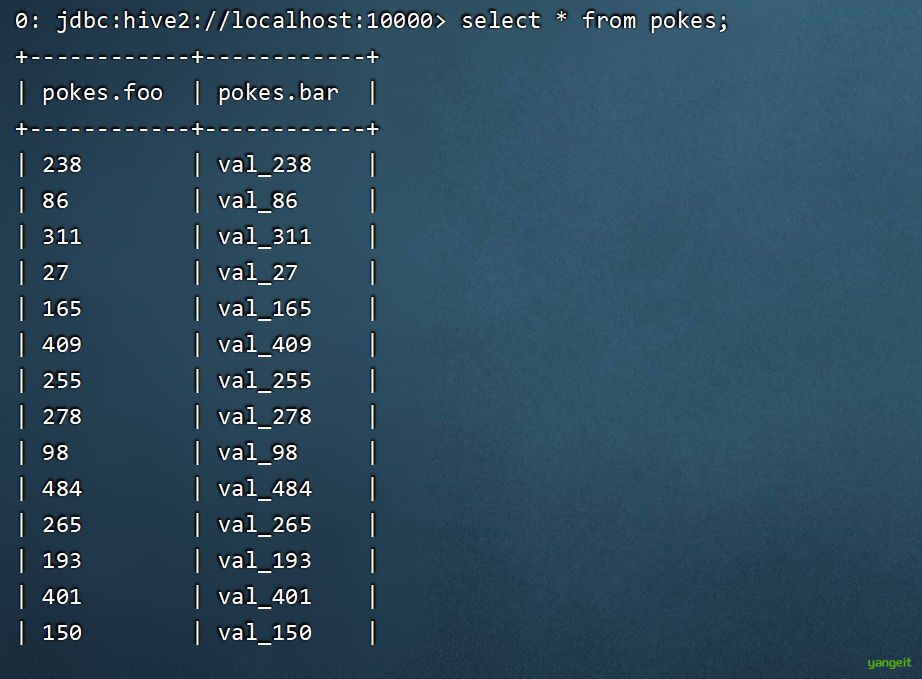
至此,就可以开始愉快的写Hive SQL了。
注意
注意啦:以后重启linux后,只要执行以下命令就可以使用hive了
# 启动docker服务
systemctl start docker
# cd 到 /home/docker-hive-master目录下
cd /home/docker-hive-master
# 先执行停止命令
docker-compose stop
# 执行启动命令
docker-compose up -d
# 等待30秒左右,执行以下命令 docker-compose ps 观察是否启动成功(都是up或者healthy)
docker-compose ps总结
课堂作业
- 参考上述教程,在自己的电脑上安装Hive,并测试成功。🎤
提交你在电脑上安装Hive的截图,作为作业证明。
4.基于Hive的数据仓库实现实操
基于Hive的数据仓库实现实操
1. Hive的基本操作

为了操作方便,安装DBeaver客户端,免费的,下载地址:https://dbeaver.io/download/
2. 利用Hive实现数据仓库
使用DBeaver连接Hive,使用可视化工具,实现数据仓库的实现。
2.1 创建数据库
-- 创建数据库
CREATE DATABASE IF NOT EXISTS power_sales_dw;
-- 展示数据库
SHOW DATABASES;
-- 使用数据库
USE power_sales_dw;
执行完后,可以刷新数据库,可以看到数据库已经创建成功了。
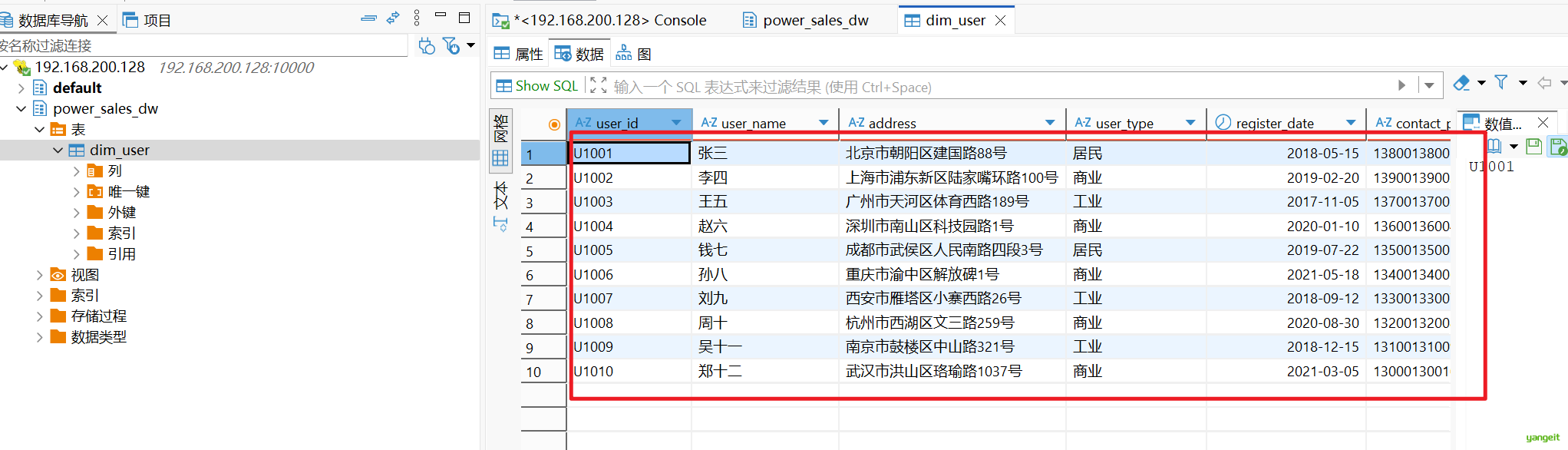
2.2 创建用户维表并导入数据
-- 创建用户维表
CREATE TABLE IF NOT EXISTS dim_user (
user_id STRING COMMENT '用户ID',
user_name STRING COMMENT '用户姓名',
address STRING COMMENT '用户地址',
user_type STRING COMMENT '用户类型(居民/商业/工业)',
register_date DATE COMMENT '注册日期',
contact_phone STRING COMMENT '联系电话'
) COMMENT '用户维度表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
导入数据,直接使用软件操作,将数据导入到hive中。
资料文件,老师已经提供好了,大家可以直接使用。缺图
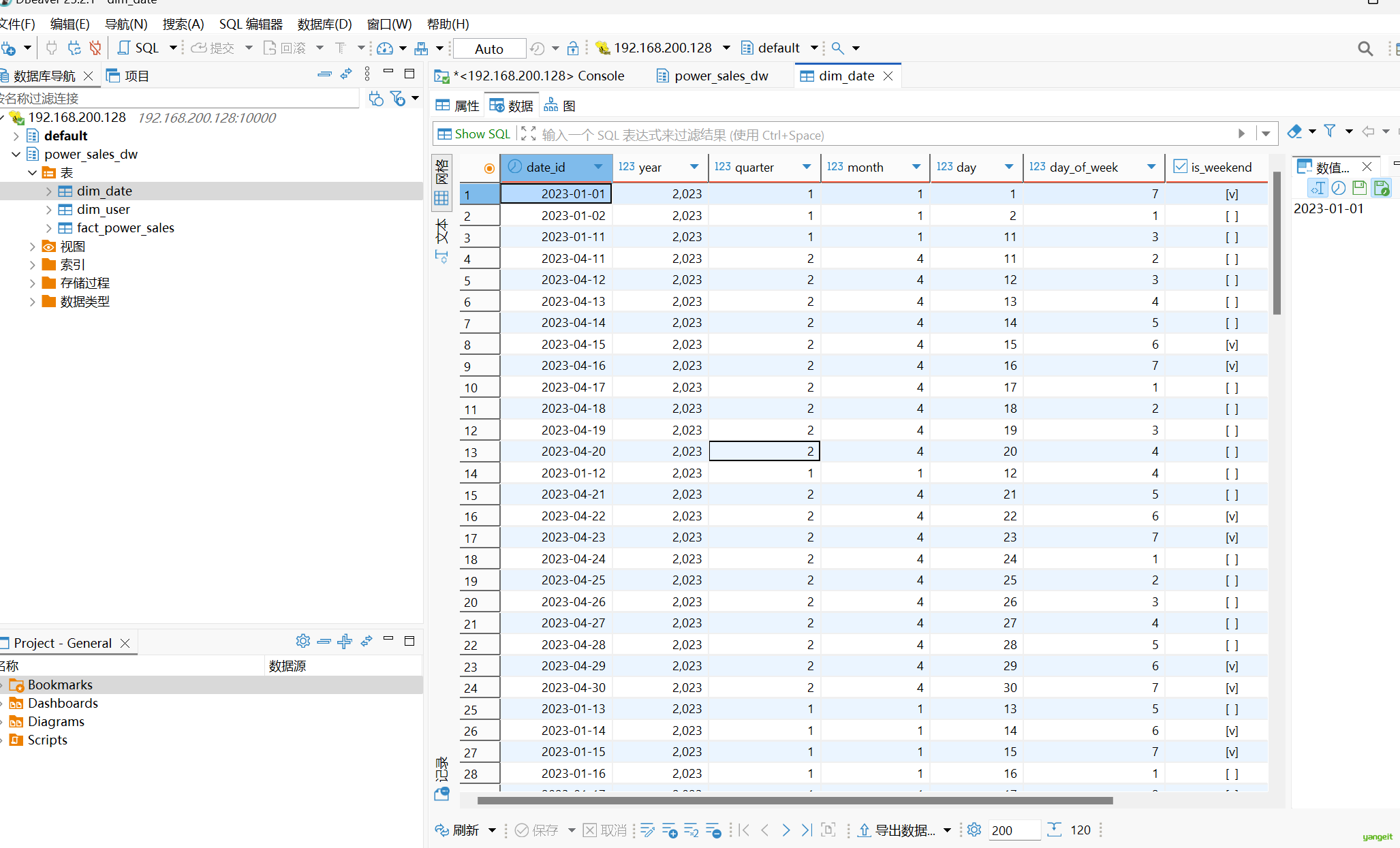
2.3 创建时间维表并导入数据
时间维度表是数据仓库中非常重要的维度表,用于时间分析。
CREATE TABLE IF NOT EXISTS dim_date (
date_id DATE COMMENT '日期ID',
year INT COMMENT '年份',
quarter INT COMMENT '季度',
month INT COMMENT '月份',
day INT COMMENT '日',
day_of_week INT COMMENT '星期几(1-7)',
is_weekend BOOLEAN COMMENT '是否周末',
is_holiday BOOLEAN COMMENT '是否假日'
) COMMENT '时间维度表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;示例数据 (dim_date.csv)导入:
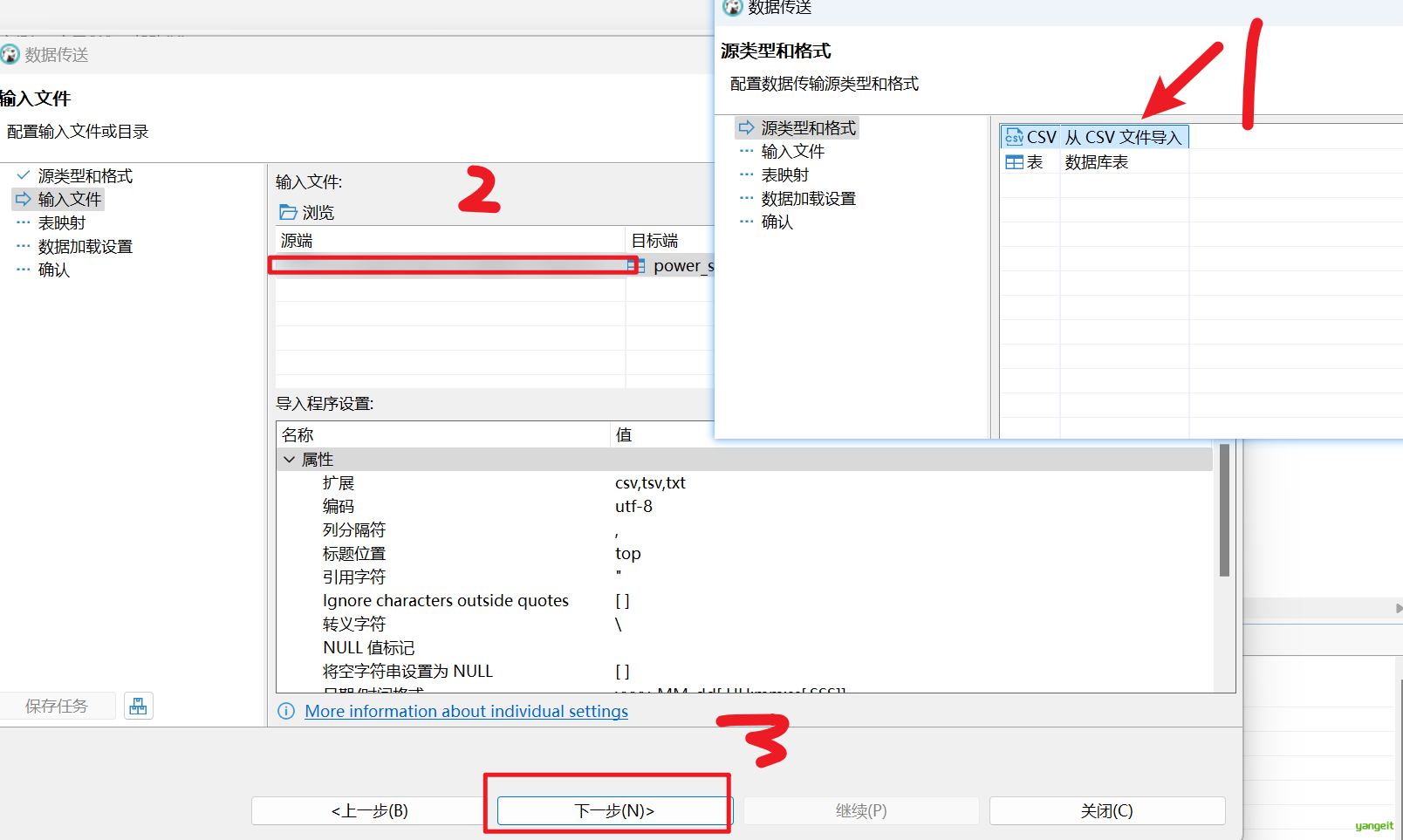
导入等待中,,,,
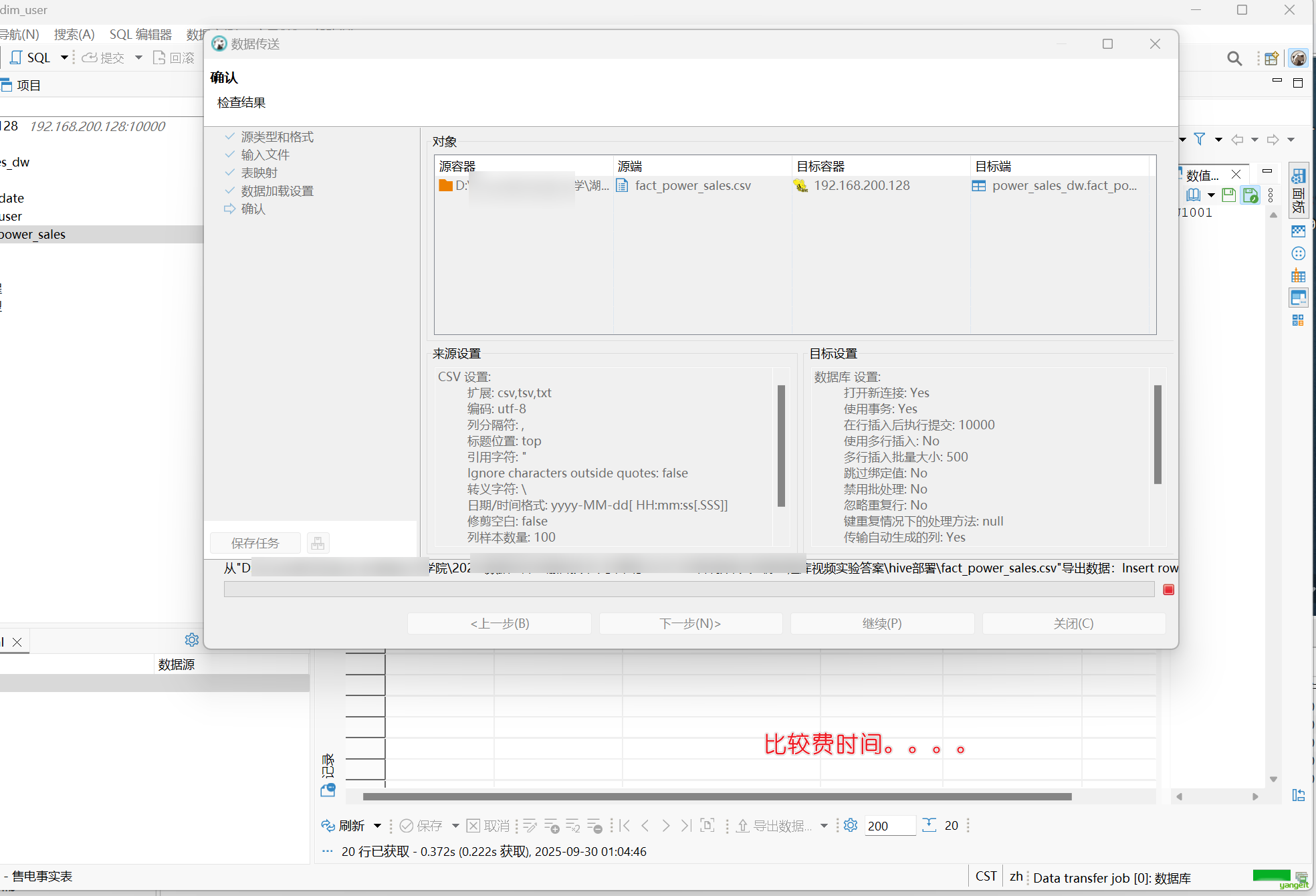
2.4 创建售电事实表并导入数据
售电事实表记录了电力销售的核心事实数据。
CREATE TABLE IF NOT EXISTS fact_power_sales (
sale_id STRING COMMENT '销售ID',
user_id STRING COMMENT '用户ID',
date_id DATE COMMENT '日期ID',
power_amount DECIMAL(10,2) COMMENT '用电量(千瓦时)',
amount DECIMAL(10,2) COMMENT '金额(元)',
peak_power DECIMAL(10,2) COMMENT '高峰用电量',
valley_power DECIMAL(10,2) COMMENT '低谷用电量',
payment_method STRING COMMENT '支付方式',
is_paid BOOLEAN COMMENT '是否已支付'
) COMMENT '售电事实表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;示例数据 (fact_power_sales.csv) 导入:
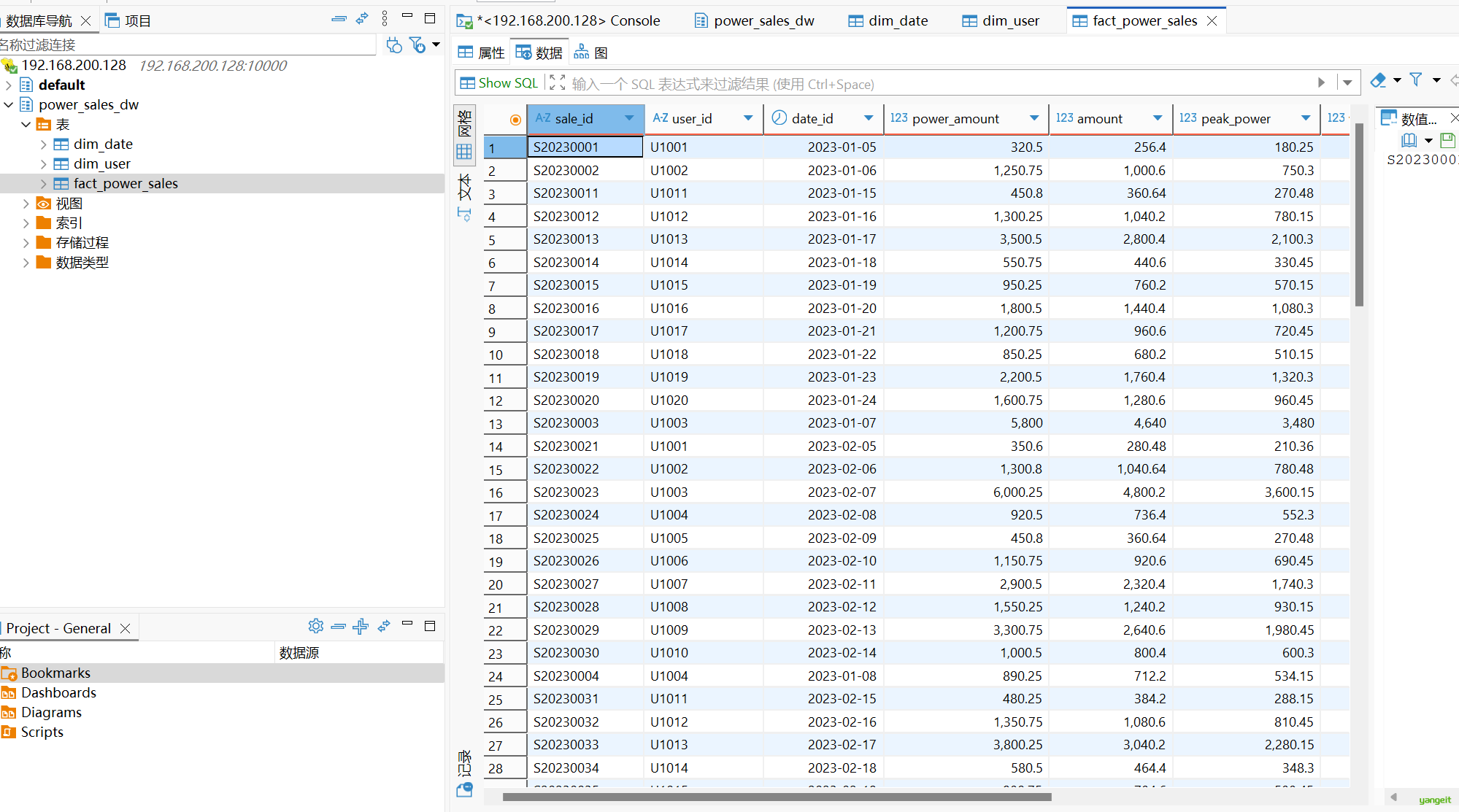
2.5 查询售电数据及具体时间
SELECT
s.sale_id,
u.user_name,
d.date_id,
d.year,
d.month,
d.day,
s.power_amount,
s.amount
FROM
fact_power_sales s
JOIN
dim_user u ON s.user_id = u.user_id
JOIN
dim_date d ON s.date_id = d.date_id
ORDER BY
d.date_id DESC, s.amount DESC运行结果:👇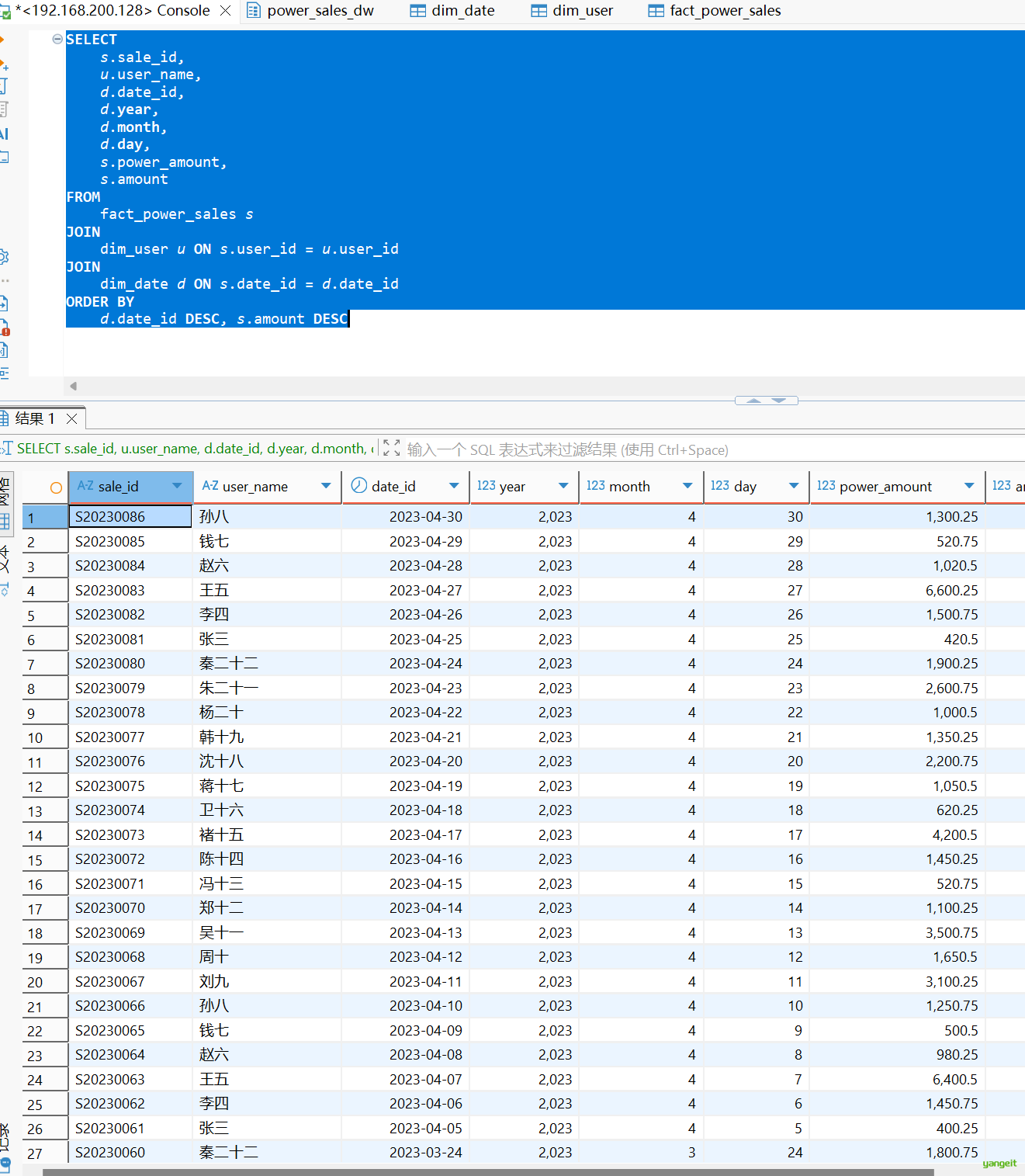
2.6 查询售电量及对应的用户地址
SELECT
u.user_id,
u.user_name,
u.address,
SUM(s.power_amount) AS total_power,
SUM(s.amount) AS total_amount
FROM
fact_power_sales s
JOIN
dim_user u ON s.user_id = u.user_id
GROUP BY
u.user_id, u.user_name, u.address
ORDER BY
total_power DESC;运行结果:👇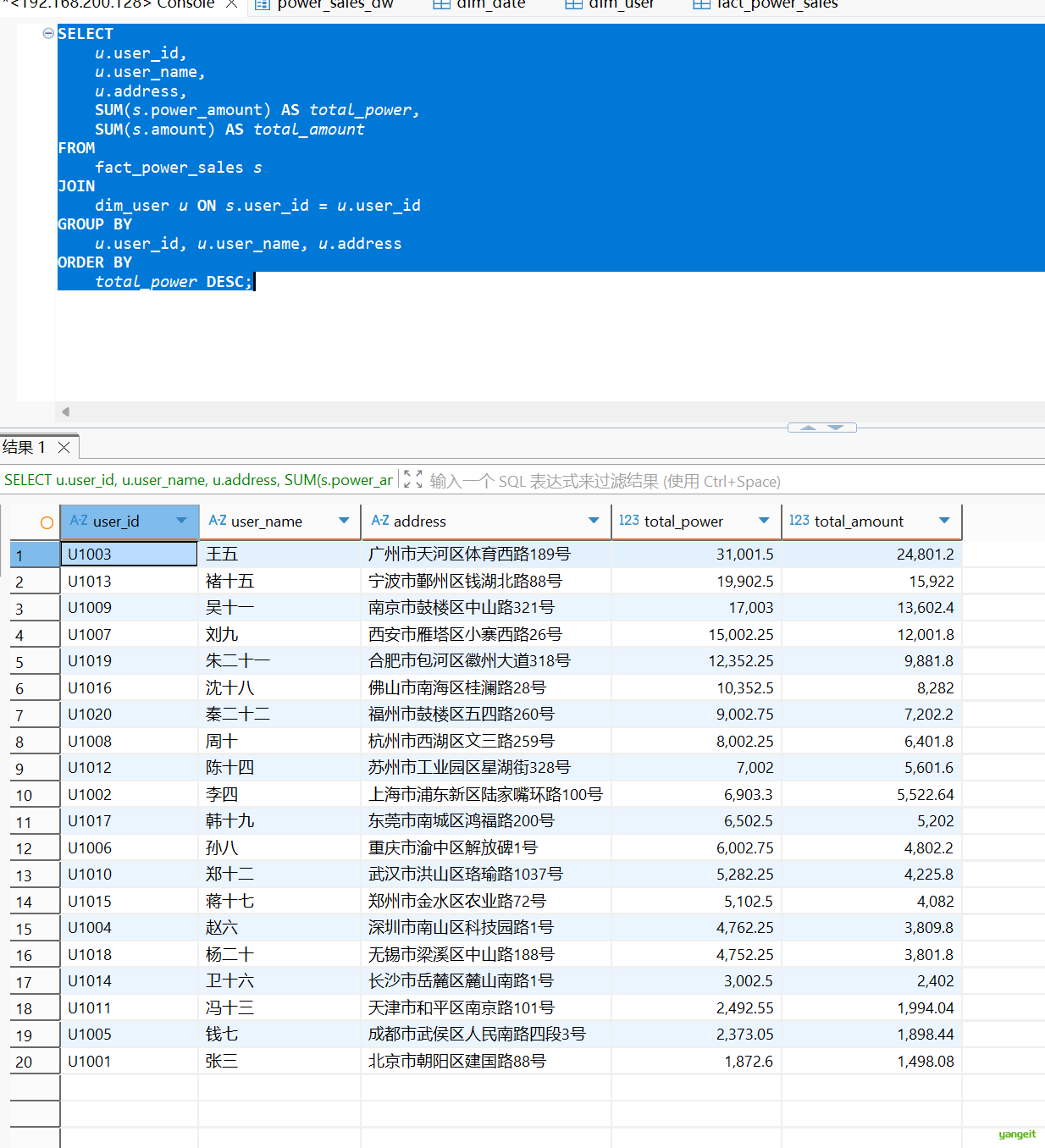
2.7 查询并输出售电量最大的10个用户
SELECT
u.user_id,
u.user_name,
u.user_type,
u.address,
SUM(s.power_amount) AS total_power,
SUM(s.amount) AS total_amount
FROM
fact_power_sales s
JOIN
dim_user u ON s.user_id = u.user_id
GROUP BY
u.user_id, u.user_name, u.user_type, u.address
ORDER BY
total_power DESC
LIMIT 10;运行结果:👇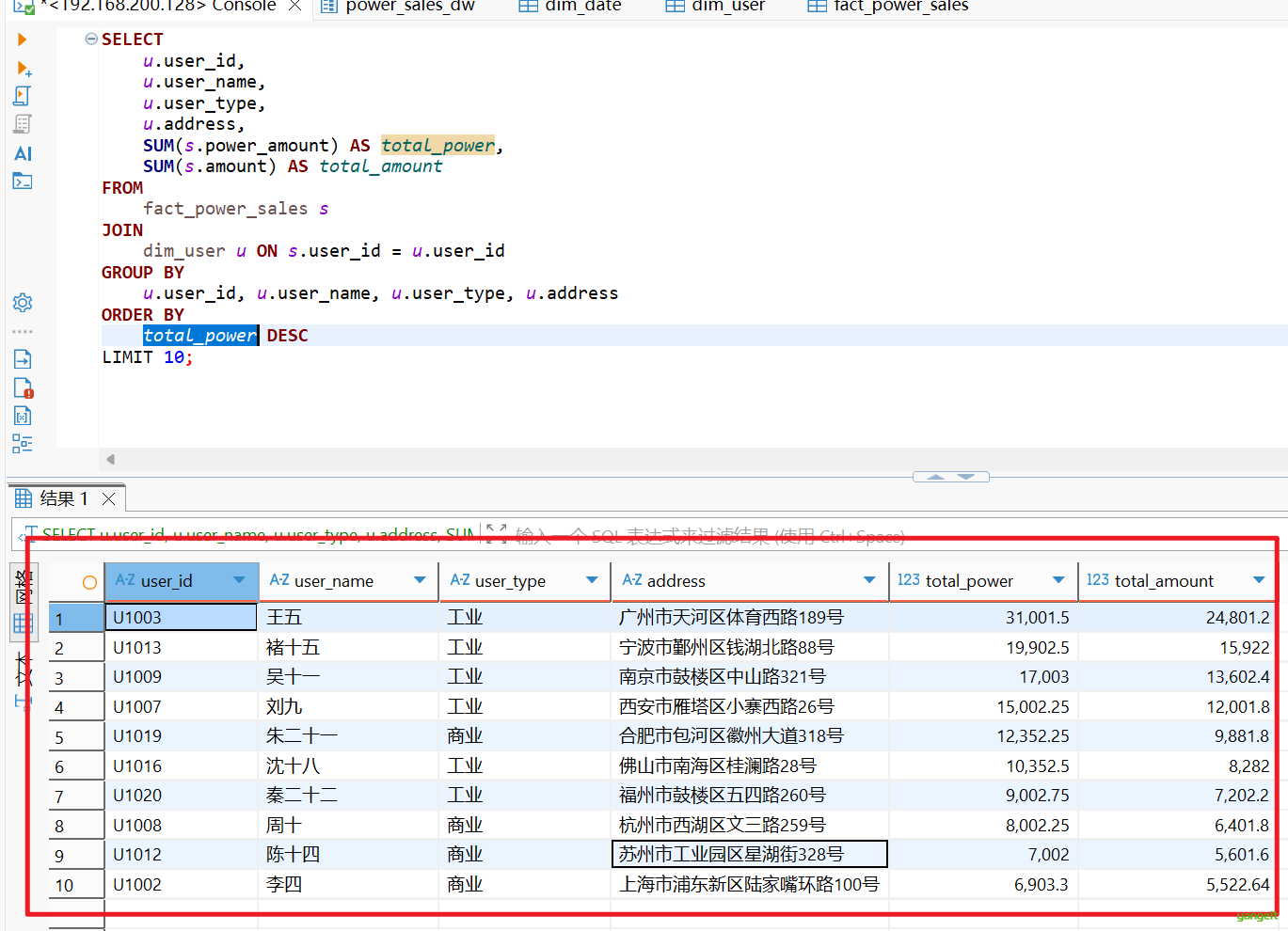
# 关闭hive相关服务
docker-compose kill
# 关闭docker
systemctl stop docker
# 下课啦总结
课堂作业
- 简述数据仓库设计的步骤🎤
- 简述维表和事实表的含义
- 简述Hive的基本操作