
数据仓库与数据挖掘-第一章节
模块三之数据仓库ETL与OLAP技术
0.一步讲解完怎样创建数据仓库
前言
数据仓库到底是个啥?怎么一步步设计出来?
现在这数字时代,数据确实是企业的宝贝。但数据量太大、太分散,管不好、用不起来,价值就出不来。这时候,“数据仓库”就成了解决问题的关键工具。那它到底是什么?设计起来分几步?今天咱们就掰开揉碎了,一次讲清楚。
1.数据仓库:干啥用的?
1.数据仓库是啥?
简单来说,数据仓库就是一个专门存历史数据、帮企业做分析决策的大仓库。它把企业里各处散落的数据(不同系统、不同来源)都归拢过来,经过清洗、整理、整合,变成一个统一、好用、稳定的数据集合。听着是不是很熟?它可不是随便堆数据的地方,而是精心设计、有组织的,专门按着企业分析决策的需求来存数据、管数据。
2.数据仓库有啥大用?
- 给决策撑腰:把不同部门、不同系统的数据整合到一起,消除不一致和重复,给你一个全面、准确、统一的数据视图。领导层做决定,心里就有底了。
- 发现规律趋势:它存大量历史数据,让你能分析市场变化、客户行为这些规律,及时调整策略。说白了,就是帮你看清过去,预判未来。
- 提升干活效率:把复杂的分析活儿从日常业务系统里挪出来,让业务系统跑得更快更稳,专心处理交易。分析的事儿,交给仓库来。
在建数据仓库的过程中,数据集成(把各处数据归拢到一起)是个基础又特别费劲的活儿。这时候,数据集成工具就能帮上大忙。它能比较高效地把不同来源的数据(比如各种数据库、文件啥的)接进来、清理干净、整理明白,然后稳稳当当地送到数据仓库里去。数据集成工具能对接的数据源种类挺多,操作界面也直观,点点拖拖就能搞定数据怎么抽、怎么转、怎么存,实实在在地提高了数据整合的效率和质量,给建好仓库打牢基础。这步做不好,后面分析全是白搭。
二、设计之前:准备啥?
1.搞清楚业务要啥
千万别一上来就开干!
- 得先摸清楚企业各个部门 到底想用数据仓库解决啥问题?
- 决策时需要哪些数据支持?
- 想看什么样的分析结果?
同时,得吃透公司的战略重点 。我一直强调,比如公司重点抓客户满意度,那仓库设计就得重点围绕客户数据(买啥、投诉啥的)来搞。
2.摸清数据家底
好好盘一盘企业现在有哪些数据源 :是数据库?文件?日志?
弄清楚它们的格式、质量(准不准?全不全?)、能不能用、更新多快、数据量多大。如果数据源本身质量不行(比如一堆错误),就得在集成清洗时重点处理。
3.划好仓库边界
基于前面的了解,明确仓库的范围 :主要管哪些业务主题?存哪些数据?数据回溯多久?细化到什么程度(比如按天还是按月)?还得想好它怎么跟其他系统对接 ,定好安全规矩 (谁能看啥数据?怎么加密?)。
三、概念设计:搭框架
1.定好主题域
主题域就是按业务核心领域 来给数据分门别类。根据业务需求和数据特点来定。
简单来说,比如零售公司,可能就有“销售”、“客户”、“商品”这几个大主题域。每个主题域里放相关的数据,专门解决这个领域的分析问题。
2.分清维度和事实
- 维度 :就是你分析数据的角度,比如时间(哪年哪月)、地点(哪个区域)、客户(哪类人)。
- 事实 :就是你要分析的具体业务数字,比如卖了多少(销售量)、赚了多少钱(销售额)。这一步要明确这些维度和事实是啥,它们之间啥关系。维度有哪些层次(时间:年->季->月->日)?事实怎么算?
3.画出概念模型
这就像仓库的蓝图,用图(比如维度建模图)把前面定的主题域、维度、事实以及它们的关系直观地画出来 。让老板和技术团队一看就明白仓库要搞成啥样,为后面详细设计指方向。


四、逻辑设计:定细节
1.设计维度表和事实表
• 维度表 :存维度信息。比如“时间维度表”存年、季、月、日这些字段。
• 事实表 :存事实数字,并通过ID关联到维度表。比如“销售事实表”存销售额、销售量,并关联到时间、商品、门店等维度。要确定每个表有哪些字段、什么类型,怎么关联。还要考虑建哪些索引能让查数据更快。
2.想好怎么存数据
数据怎么存直接影响查得快不快。要考虑:
• 分区:把数据按时间或其他规则分块存(比如按年月分区),查起来更快。
• 索引:选合适的索引类型(比如B树索引、位图索引),加速查找。
• 压缩:对不太常用的数据压缩一下,省点存储空间和成本。
3.定好安全规矩
仓库里都是重要数据,安全马虎不得!要规定:
• 用户认证 :谁才能登录仓库?
• 权限管理 :不同的人能看、能改哪些数据?(比如销售只能看销售数据)
• 数据加密 :对敏感信息(客户身份证号)加密存储和传输。
五、物理设计:落地实施
1.选好数据库软件
用啥软件来实现仓库?得看仓库规模、性能要求、预算。
• 关系型数据库(如Oracle,MySQL) :擅长管规整的表格数据,事务处理强。
• 非关系型数据库(如HBase) :适合半结构化或灵活多变的数据,扩展性好。
2.优化数据库性能
选好软件后,还得调优 :
• 设计好表空间、索引、分区。
• 调整内存、缓存等参数,让它跑得更快。
• 定好备份恢复计划 ,防止数据丢了抓瞎。
3.部署上线
把设计好的仓库装到服务器和存储设备上 ,配置好网络和安全。最后,把历史数据导进去 ,仓库就可以开始“进货”了。
六、实施与测试:跑起来
1.ETL:灌数据
这是把数据从各个源头搬进仓库的核心过程(抽取->转换->清洗->加载)。要写脚本或用工具来实现这个过程。用过来人的经验告诉你,这一步要盯紧数据质量,保证进去的数据又准又全。

2.全面测试
仓库建好了,得好好试试:
• 功能测试:查数对不对?分析结果准不准?报表能不能看?
• 性能测试:数据量大了卡不卡?很多人一起查慢不慢?
• 安全测试:权限管用吗?加密有效吗?会不会泄密?发现问题赶紧改,确保仓库稳定可靠。
总结
课堂作业
Q:设计个数据仓库要搞多久?
A:时间真没个准谱儿。简单来说,看公司大小、数据多复杂、要求多高。小公司可能几个月到半年,大集团搞个一年甚至更久也正常。说白了,还受内部配合效率、数据底子好坏影响。
Q:仓库建好就完事了吗?
A:哪能啊!得一直维护。业务在变,数据在涨,仓库也得跟着变。要定期更新数据,监控性能看要不要优化,根据新情况调整安全策略。我一直强调,这是个持续投入的活儿。
Q:设计仓库需要哪些能人?
A:需要一帮子人配合:
• 业务分析师:懂业务要啥。
• 数据架构师:负责设计仓库骨架(概念、逻辑、物理设计)。
• DBA(数据库管理员):管数据库软件,调性能,做备份。
• ETL开发:搞定数据抽取、清洗、加载。
• 数据分析师&测试员:一个负责验证分析结果,一个负责找bug。
注意
了解了数据仓库的创建过程,接下来,我们来深入学习一些概念!!!
1.数据仓库概要
数据仓库概要
数据仓库体系结构通常包括 数据源,数据存储和管理,数据服务,数据应用四部分组成.👇
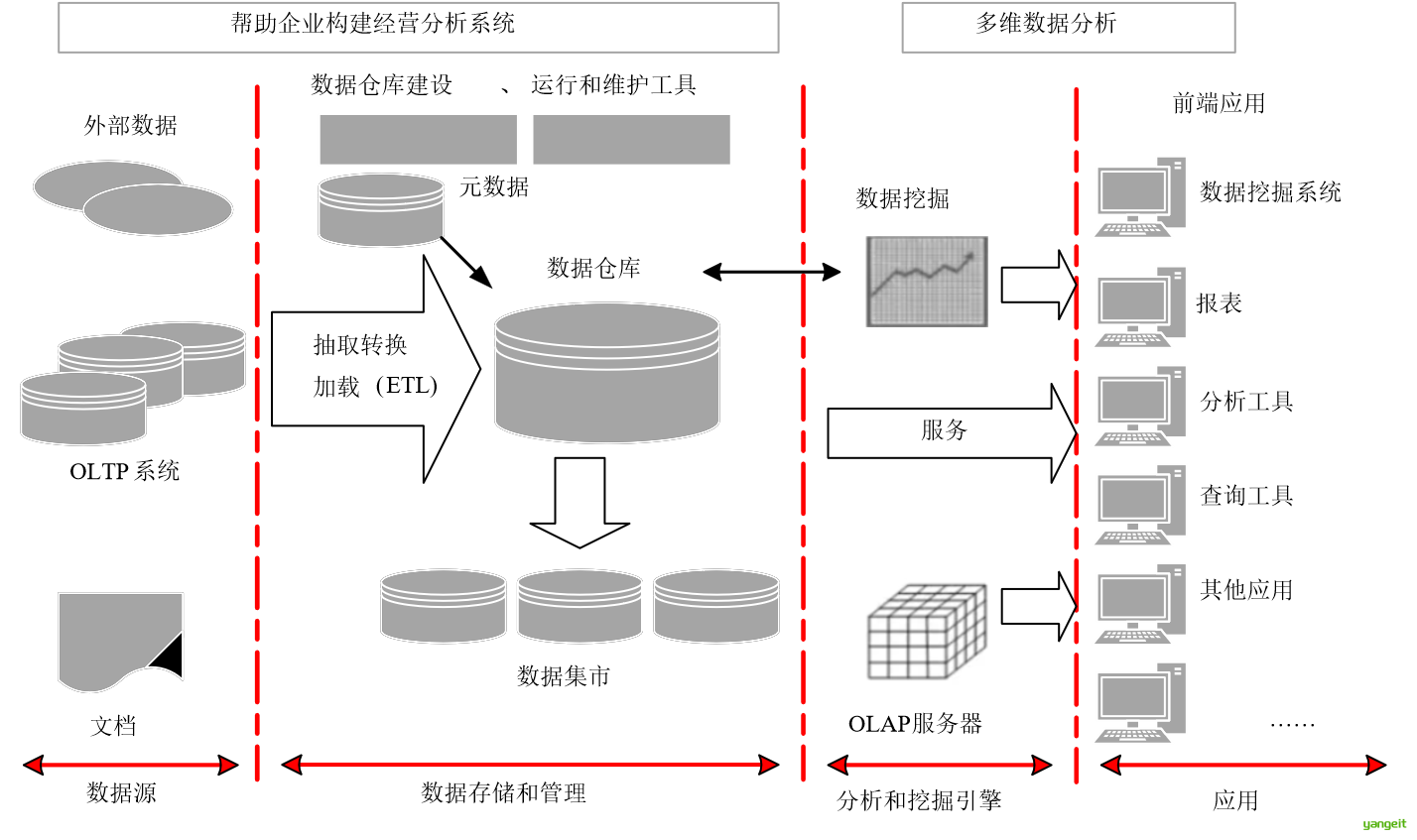
1. 数据源
数据源是数据仓库的核心,如下图所示:
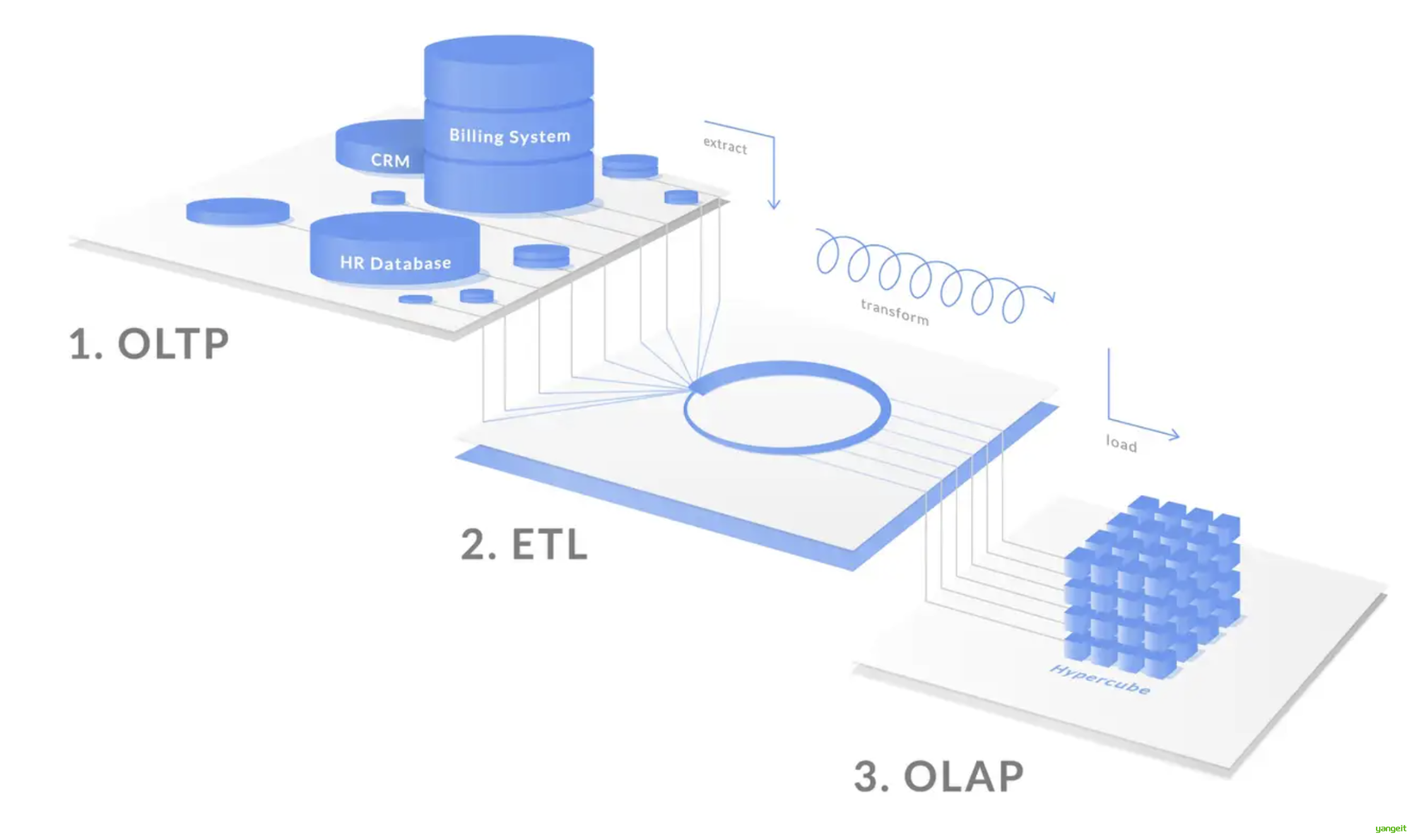
2. 数据ETL
数据ETL即数据抽取、转换和加载的过程。由于在建设数据仓库时,需要集成多个数据源,这些数据源可能来自不同的设备,不同的操作系统,以不同的存储格式存储, 因此需要对数据进行抽取、转换和加载,以便于后续的数据分析和应用。
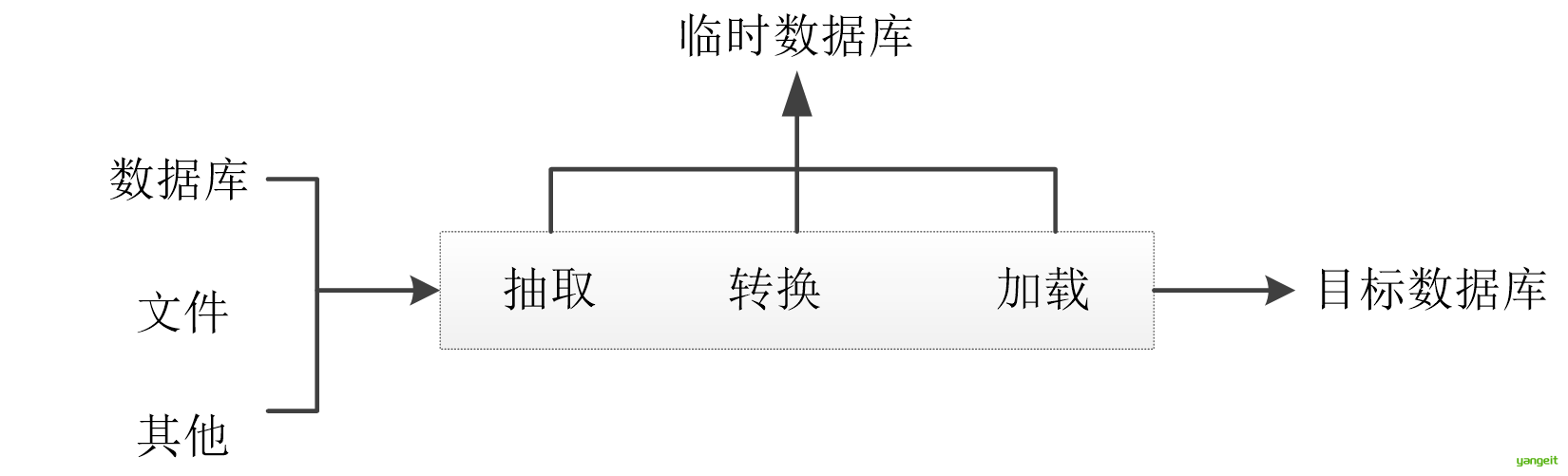
- 抽取:从数据源中提取数据,并将其存储到数据仓库中。
- 转换:对数据进行清洗、转换和标准化,以便于后续的分析和应用。
- 加载:将数据加载到数据仓库中,以便于后续的分析和应用。
3. 数据集市
数据集市是为特定用户组服务的小型数据仓库。它通常是为一个特定部门(如营销或财务)创建的,包含该部门所需的所有相关数据。数据集市可以从主数据仓库复制数据,也可以从多个来源获取数据,然后进行整合。数据集市的优点在于能够快速地为特定用户提供所需的信息,而无需等待整个组织范围的数据仓库完成更新。
举一个案例便于理解:
某全国性连锁超市"优鲜超市"拥有:
200家门店遍布全国
5大业务部门:采购、物流、营销、财务、人力资源
中央数据仓库存储所有业务数据(10TB+)
**营销部门面临分析困境:**
1. 每次做促销分析需要从中央数据仓库提取海量数据()
2. 财务数据、库存数据等营销无关信息造成干扰
3. 分析响应速度慢(平均4小时生成报表)
**解决方案:建立营销数据集市**
1. 数据范围选择
- 从中央数据仓库抽取营销相关数据子集:
- 销售交易数据(仅保留最终销售记录,不含退货处理流程)
- 会员信息
- 促销活动数据
- 商品基础信息(仅需品类、价格带等营销属性)
- 门店基础信息(仅需区域、面积等级等营销相关属性)
2. 数据更新机制
- 每晚23:00从中央仓库增量更新
- 关键指标每小时刷新(当日促销业绩)
**效果对比:**
查询促销商品销售趋势:需关联15张表,包含无关字段 -----> 只需关联4张优化后的表
分析会员促销参与率: 需要从2亿条交易记录筛选 -----> 直接使用预计算的会员促销行为标签
生成周促销报告:需IT部门协助,平均耗时6小时 -----> 业务人员自助完成,平均20分钟4. 元数据管理
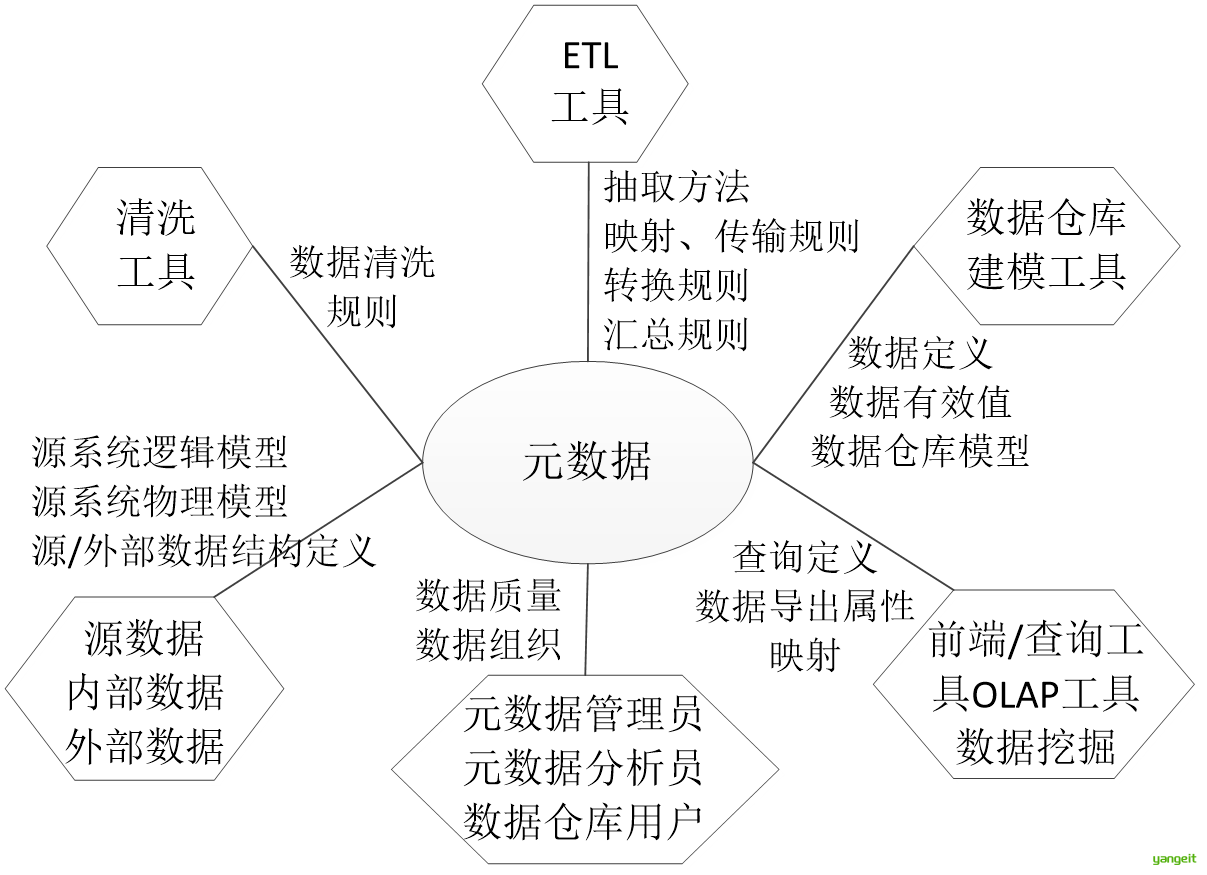
元数据(Metadata)是“提供其他数据信息的数据”,即“关于数据的数据”。元数据主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及ETL的运行状态。
安装Hive时需要安装MySQL主要是为了提供一个可靠、可扩展的元数据存储解决方案,以替代Hive自带的Derby数据库,特别是在多用户和生产环境场景下。
元数据根据使用情况不同,可以分为业务元数据和技术元数据。
根据状态不同,元数据可以分为静态元数据和动态元数据。
总结
课堂作业
- 简述数据仓库系统的体系结构🎤
- 简述数据ETL的含义和过程
- 简述数据集市的含义
2.多维数据模型和OLAP
多维数据模型和OLAP
OLAP的优势是基于数据仓库面向主题、集成的、保留历史及不可变更的数据存储,以及多维模型多视角多层次的数据组织形式,如果脱离的这两点,OLAP将不复存在,也就没有优势可言。
1.多维数据的相关概念
粒度
粒度(Granularity)指多维数据集中数据的详细程度或级别。数据越详细,粒度越小,级别越低,如地址数据中的“北京市海淀区”比“北京市”粒度要小。在传统的操作型数据库系统中,对数据处理和操作是在最小粒度上进行,但是在数据仓库中由于主要进行分析型处理,需要在不同的粒度级别上进行数据分析。
| 粒度级别 | 适用分析场景 |
|---|---|
| 最小粒度(单商品项) | 用户行为分析、商品推荐、库存管理、交易明细查询 |
| 中等粒度(订单级别) | 订单分析、用户消费能力评估、客单价统计、退货率计算 |
| 较高粒度(天+省份) | 销售趋势分析、地区市场策略、业绩报表、大区销售对比 |
| 最高粒度(全国月度) | 战略决策分析、年度财报、市场占有率统计、公司级KPI评估 |
先看全国月度销售额(高粒度),发现异常后
下钻到某省份的日销售额(中粒度),再查看具体订单(最小粒度)找原因。
维度 ❤️
维度就是看待问题的角度,分析业务数据,从什么角度分析,就建立什么样的维度。所以维度就是要对数据进行分析时所用的一个量,比如你要分析产品销售情况,你可以选择按商品类别来进行分析,这就构成一个维度,把所有商品类别集合在一起,就构成了维度表。
- 示例场景:电商订单分析
假设我们要分析电商平台的销售数据,常见的维度包括:
时间维度(年、月、日、季度)
商品维度(类别、品牌、价格区间)
用户维度(年龄、性别、会员等级)
地域维度(国家、省份、城市)
| 表类型 | 特点 | 示例字段 | 数据变动频率 | 表关系 |
|---|---|---|---|---|
| 维度表 | 存储描述性属性(静态) | 商品ID、商品名称、类别、品牌、价格区间 | 低(缓慢变化) | 被事实表关联 |
| 事实表 | 存储业务度量值(动态) | 订单ID、销售金额、数量、折扣、时间戳、商品ID(外键) | 高(频繁更新) | 关联多个维度表 |
维度表是“标签”,事实表是“数字”。用标签分类数字,就是维度建模的核心思想。一般维度表比较稳定,不会经常变动,所以维度表一般是静态的,而事实表是动态的,事实表中存储的是业务数据,比如商品的销售情况,用户的购买情况,用户的注册情况等。
维属性和维成员
一个维通过一组属性描述,如时间维有日期、月份、季度和年份。维成员就是一个维在某个维层次上的一个具体取值。如在时间维度上,2020年1月和2021年1月就是在时间维“月”的层次上的两个维成员。
度量或事实
度量(Measure)也称为事实,是数据分析中可量化、可计算的数值型数据,是业务分析的核心指标。例如:
- 销售金额
- 订单数量
- 用户访问次数
- 库存数量
订单事实表(fact_orders)
| order_id | product_id | user_id | date_id | quantity | amount | discount | payment_method |
|---|---|---|---|---|---|---|---|
| 1001 | P001 | U101 | 20231001 | 2 | 13998 | 500 | 支付宝 |
| 1002 | P002 | U102 | 20231002 | 1 | 8999 | 0 | 微信支付 |
核心作用:事实表通过度量值+维度关联,实现"用数字说话"的业务分析能力。
多维数据集
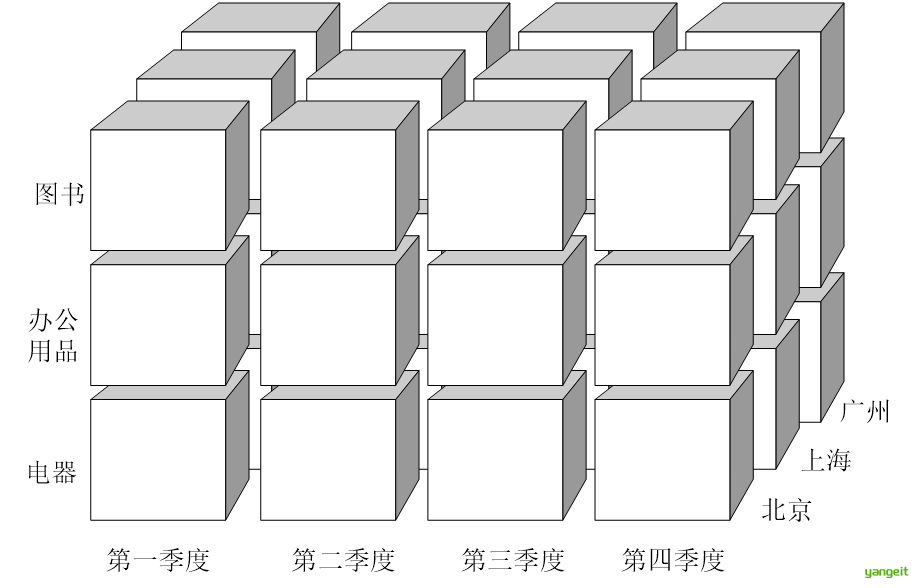
多维数据集(又称数据立方体)是数据仓库的核心分析结构,通过 维度(Dimension)和度量(Measure) 的组合,实现多角度数据透视分析。
我们现实是分三维,x,y,z三个坐标决定的空间。而数据库,可能会包含很多维度,只是在我们的认知中无法想像超越三维的事物,这只是个概念。可见,Cube是依赖于维度的。所以在我们建立Cube的时候,需要理解下面的维度是什么。每个Cube依赖哪些维度来做统计,就需要在这里建。虽然在创建立方的时候会自动帮我们创建维度,但是有时候他创建的维度并不能达到我们的目的。所以,我们先建Dimension,再建Cube。
多维数据集其特点包括:
立方体结构:三维(或更高维)数组表示(如时间×商品×地区)
预聚合计算:提前计算各维度组合的汇总值,提升查询性能
OLAP操作支持:支持上卷(Roll-up)、下钻(Drill-down)、切片(Slice)、切块(Dice)等操作
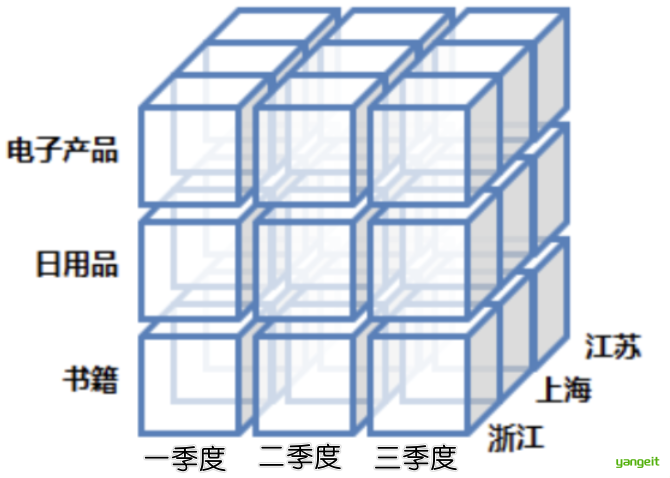
立方体维度:时间 × 商品类别 × 地区 。如下图👇
| 时间 | 商品类别 | 地区 | 销售额(万元) | 订单量 |
|---|---|---|---|---|
| 一季度 | 电子产品 | 江苏 | 1200 | 8500 |
| 一季度 | 日用品 | 上海 | 800 | 12000 |
| 一季度 | 书籍 | 浙江 | 1500 | 11000 |
| 二季度 | 电子产品 | 江苏 | 1000 | 7000 |
| 二季度 | 日用品 | 上海 | 1000 | 10000 |
| 二季度 | 书籍 | 浙江 | 1000 | 10000 |
| 三季度 | 电子产品 | 江苏 | 1000 | 6000 |
| 三季度 | 日用品 | 上海 | 1000 | 10000 |
| 三季度 | 书籍 | 浙江 | 1000 | 10000 |
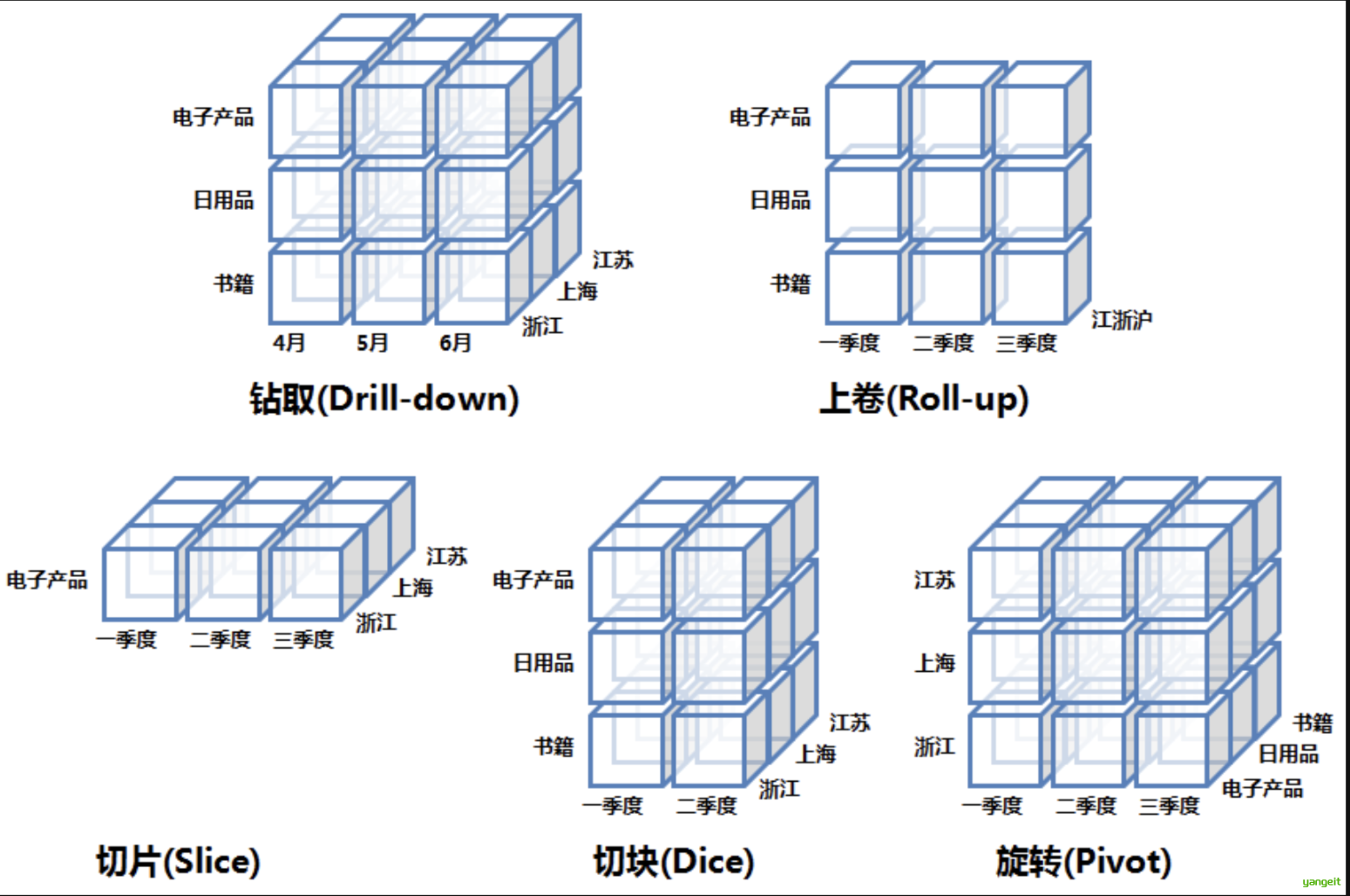
2.OLAP的基本操作
在多维数据模型中,数据组织在多维空间,每维包含由概念分层定义的多个抽象层。这些组织为用户从不同角度观察与分析数据提供了灵活性。OLAP服务工具支持这类操作,提供了切片、切块、旋转、上卷和下钻等基本的分析操作。
- 上卷(Roll-up)
- 从细粒度汇总到粗粒度
- 例:上海,江苏,浙江销售额 → 江浙沪销售额
- 下钻(Drill-down)
- 从粗粒度分解到细粒度
- 例:二季度销售额 → 二季度各月销售额
- 切片(Slice)
- 固定一个维度值观察数据
- 例:只看"电子产品"的数据
- 切块(Dice)
- 选择维度值的子集
- 例:分析"第一季度和第二季度"的"的数据
- 旋转(Pivot)
- 切换行列维度展示方式
- 例:将"地区"从行转列
3. 多维数据模型的实现
多维数据模型的物理实现主要采用多维数据库(Multi-Dimensional DataBase, MDDB)、关系数据库以及两种数据库结合的方法。
| 特性 | ROLAP | MOLAP | HOLAP |
|---|---|---|---|
| 全称 | Relational OLAP | Multidimensional OLAP | Hybrid OLAP |
| 存储方式 | 数据存储在关系型数据库中 | 数据存储在专用多维数组中 | 混合存储(部分关系型+部分多维) |
| 计算方式 | 实时执行SQL查询计算 | 预计算所有维度组合 | 高频维度预计算,低频维度实时计算 |
| 查询性能 | 较慢(依赖实时JOIN和聚合) | 极快(直接读取预计算结果) | 中等(平衡预计算和实时计算) |
| 存储开销 | 低(仅存原始数据) | 高(存储所有维度组合的预计算结果) | 中等(部分预计算) |
| 灵活性 | 高(支持动态维度调整) | 低(维度固定需重建立方体) | 中(预计算部分维度固定) |
| 维度处理 | 支持无限维度(受限于SQL能力) | 通常支持10-15个维度 | 折中方案(关键维度预计算) |
| 适用场景 | 大数据量、维度频繁变化、即席查询 | 固定维度、高频分析、快速响应需求 | 需要平衡性能与灵活性的场景 |
| 代表工具 | Snowflake、Redshift、传统数据仓库 | SSAS Multidimensional、Essbase | SSAS Hybrid Mode、Power BI |
优缺点对比
| 类型 | 优点 | 缺点 |
|---|---|---|
| ROLAP | 节省存储、支持复杂查询、维度灵活 | 查询速度慢、高并发压力大 |
| MOLAP | 亚秒级响应、适合高频分析 | 存储膨胀、维度变更需重建立方体 |
| HOLAP | 平衡性能与存储、部分维度灵活 | 实现复杂、需权衡预计算策略 |
选择建议
- 选 ROLAP:数据量大+维度多变(如用户行为分析)
- 选 MOLAP:固定维度+追求极致性能(如财务报表)
- 选 HOLAP:既要部分实时分析又要历史快照(如销售趋势仪表盘)
4. 数据仓库维度建模概述
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,可将常见的模型分为星型模型和雪花型模型。
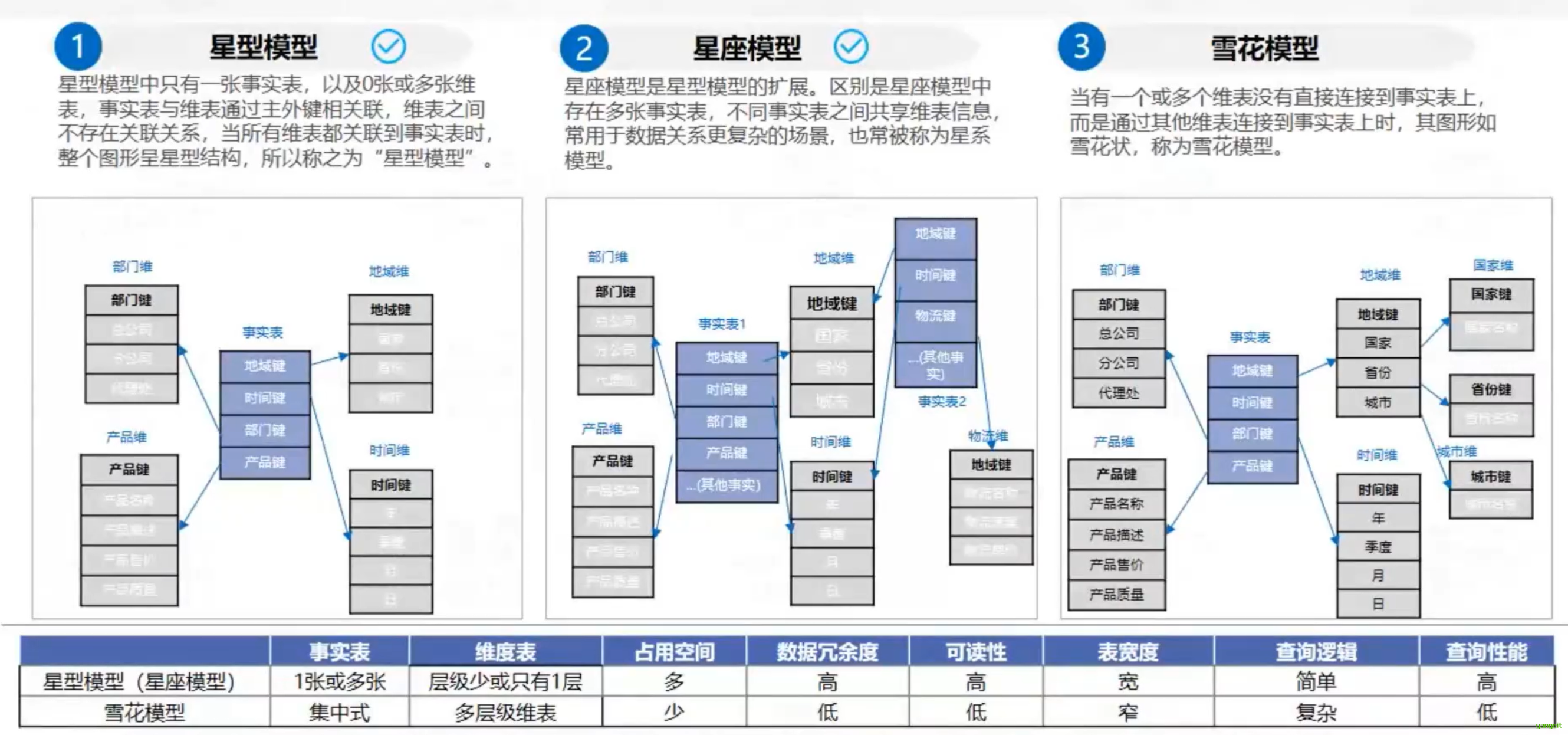
备注:
- 星型模型:只有一张事实表,0张或者多张维度表,维表之间不存在关联关系。
- 星座模型:是星型模型的拓展,有多个事实表,共享维度表。
- 雪花型模型:当一个或者多个维度表没有直接连接到事实表时,就形成了雪花型模型。
- 数据分析更适合使用星型模型来构建,通过数据冗余来减少关联次数以提高查询效率,并灵活支撑上层应用
一般生产,星型模型就可以了,而雪花模型比较复杂
- 简述多维数据模型的主要内容
- 简述OLAP的主要操作类型
3.数据仓库的发展
数据仓库的维度模型
动态数据仓库
21世纪初随着互联网时代的到来,数据量暴增,大数据时代到来。Hadoop生态群及衍生技术慢慢走向“舞台”,Hadoop是以HDFS为核心存储,以MapReduce(简称MR)为基本计算模型的批量数据处理基础设施,围绕HDFS和MR,产生了一系列的组件,不断完善整个大数据平台的数据处理能力。这个时期,在企业信息化的过程中,随着信息化工具的升级和新工具的应用,数据量变的越来越大,数据格式越来越多,决策要求越来越苛刻,数据仓库技术在大数据场景中被广泛使用。
离线数据仓库:👇
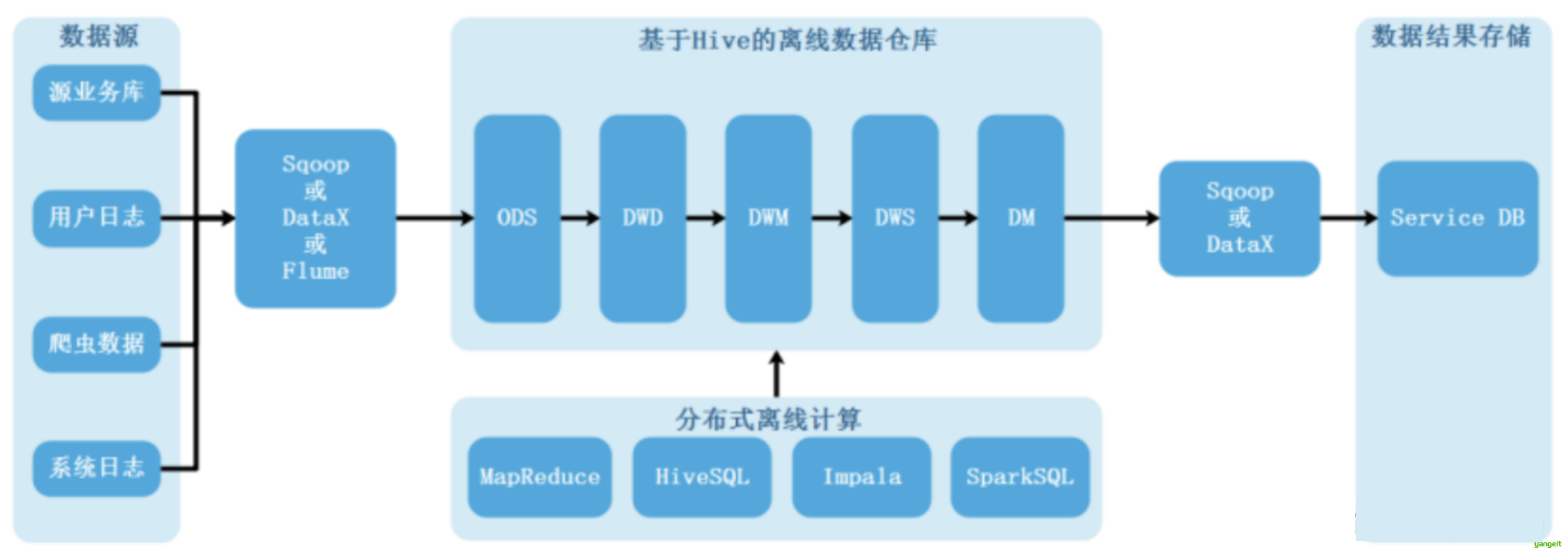
随着数据处理能力和处理需求的不断变化,越来越多的用户发现,批处理模式无论如何提升性能,也无法满足一些实时性要求高的处理场景,流式计算引擎应运而生,例如Storm、Spark Streaming、Flink等。
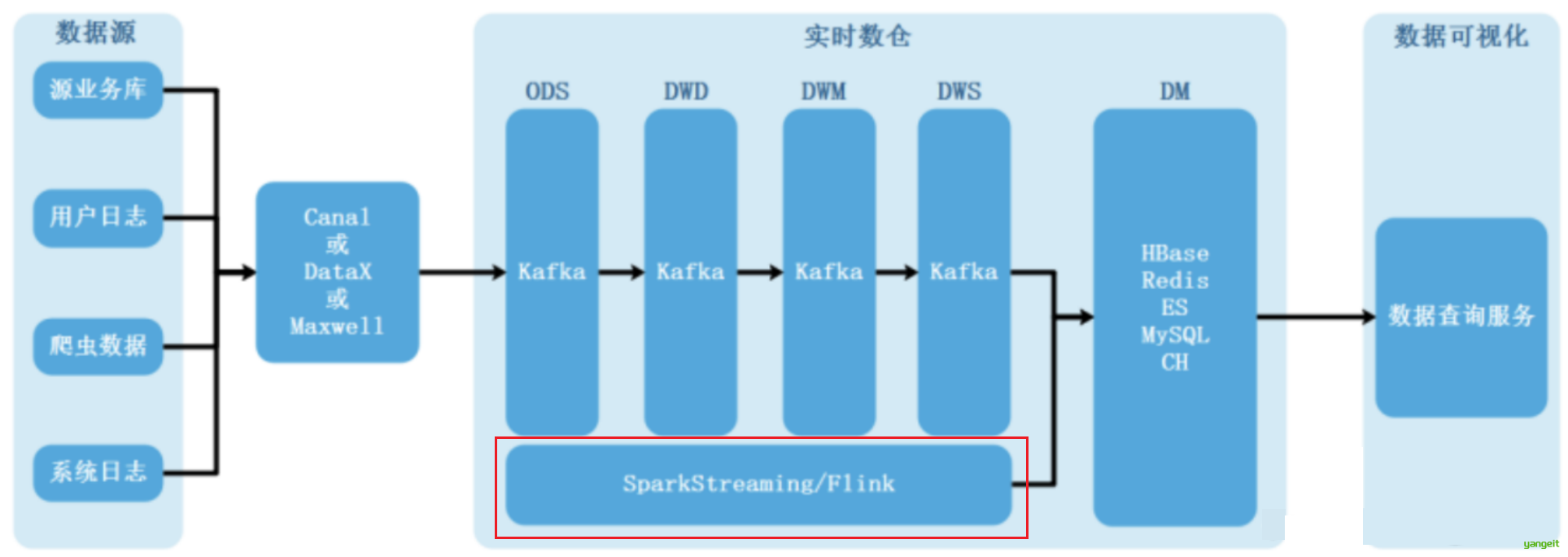
典型业务场景:
| 应用场景 | 动态数据仓库(实时) | 离线数据仓库(批处理) |
|---|---|---|
| 数据时效性要求 | 秒级/分钟级延迟 | 小时/天级延迟 |
| - 实时监控 | 电商大屏、IoT设备状态监控 | 无 |
| - 即时决策 | 金融反欺诈(识别异常交易)、物流动态调度 | 无 |
| - 事件响应 | 用户行为实时推荐(如短视频下一跳推荐) | 无 |
| - 操作型分析 | 客服查询最新订单 | 无 |
| - 趋势分析 | 无 | 月度销售报表、年度同比分析 |
| - 深度挖掘 | 无 | 用户画像构建(聚类分析)、市场策略制定 |
| - 合规审计 | 无 | 财务年报、数据归档 |
| - 回溯计算 | 无 | A/B测试全量分析 |
补充说明
- 混合架构建议:
- 关键业务指标(如GMV:电商中商品交易总额)同时部署实时+离线双链路,互相校验
- 使用Lambda架构或Kappa架构统一处理流批数据
数据中心
构建数据中心,可以建立符合DT(数据技术)标准的创新、灵活的业务机制。相对于比较复杂的集成系统,可以在数据中心的基础上建立业务中心,而对于政府和中小企业来说,则不需要建设商务中心。数据中心的构建,更适应渐进式实施战略,可以分阶段实施大数据中心,如尝试规划三到五年的长期发展战略。此外,大数据中心需要选择更复杂的基础架构和实施团队。


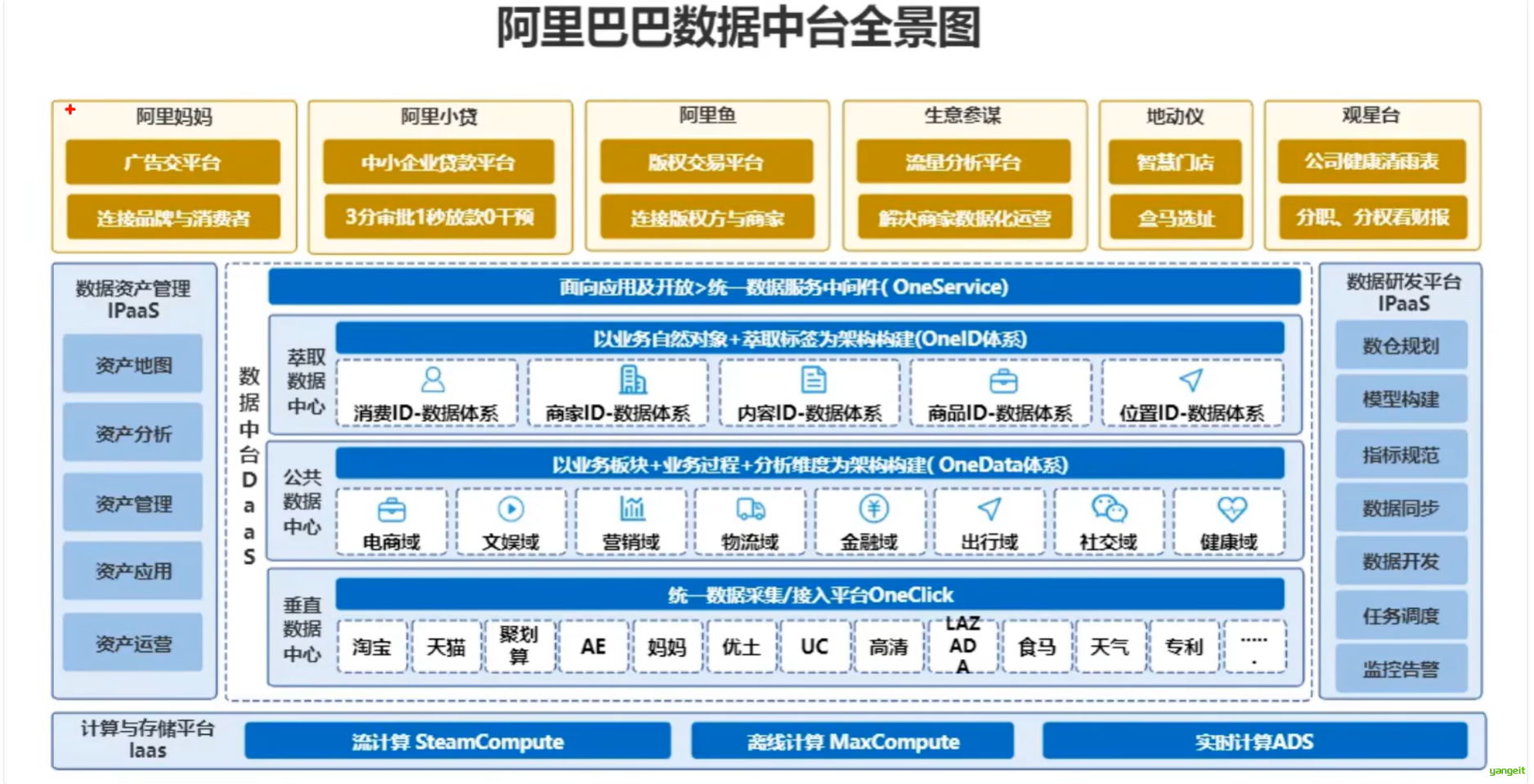
数据中台
数据仓库是一个用于存储和分析企业历史数据的系统,它通过集成和清洗来自不同源的数据,为决策支持提供结构化的信息。而数据中台则是一个更广泛的平台概念,它不仅包含数据仓库的功能,还涵盖了数据治理、数据服务化和数据应用的构建,旨在通过数据API的形式将数据直接服务于业务应用,提升数据的实时可用性和业务敏捷性。
总结
课堂作业
- 简述动态数据仓库和离线数据仓库的应用场景🎤
- 简述数据中台和数据中心🎤
4.数据仓库的设计
前言
1. 数据仓库设计概述
数据仓库的设计是以业务和需求为中心,由数据来驱动。数据仓库的设计具有以下几个特点: 👇
1.1. "数据驱动"的设计
核心逻辑:以数据本身的特性和关系为主导,而非完全遵循业务系统的原始结构
具体表现:
- 强调整合多源异构数据(如ERP日志、IoT传感器数据、外部爬虫数据)
- 通过数据剖析(Data Profiling)发现隐藏的关联规则(例如通过购物篮分析发现"啤酒与尿布"的关联)
- 采用 数据编织(Data Fabric) 架构自动识别数据血缘和语义关系
设计影响:
- 需要构建企业级数据字典和业务术语表
- 典型示例:电信运营商通过用户通话记录、位置信令等原始数据重构"客户行为主题域"
1.2. "决策驱动"的设计
核心逻辑: 设计始终服务于高层战略决策而非操作层事务
- 实现方式:
- 逆向设计法:从高管驾驶舱的KPI指标反向推导所需数据模型
- 建立决策树映射(例如:客户流失分析→需要历史订单、服务投诉、登录行为等数据)
- 采用**假设分析(What-if)**模式设计沙箱环境
- 典型矛盾:
- 业务部门要求"快速看到销售额报表"(维度建模优先)
- 数据团队坚持"先建统一客户主数据"(范式建模优先)
- 解决方案:混合方法(ODS层保留原始数据,DWD层做整合,DWS层按决策场景聚合)
1.3. "需求模糊"的设计
本质原因: 决策需求本身具有探索性和不确定性
- 应对策略:
- 迭代式建模:先交付最小可行模型(如客户基础维度表),后续逐步增加客户分群标签、生命周期状态等属性
- 数据超市模式:构建宽表(如包含200+字段的用户全景宽表),让业务方自行选择字段组合
- ABI(Augmented Business Intelligence):通过机器学习自动推荐可能需要的维度(如突然需要"疫情封控"作为新的时间维度)
- 典型案例:
- 初期仅要求"统计销售额",后期衍生出"分析促销活动对高净值客户复购率的影响"等复杂需求
1.4. "螺旋周期"的设计
**演进过程:**需求→原型→反馈→重构的持续循环
实施方法论:
- Data Vault 2.0:通过中心表(Hub)、链接表(Link)、卫星表(Satellite)实现模型弹性扩展
- 锚建模(Anchor Modeling):采用第六范式(6NF)实现无损变更
- 版本控制:像管理代码一样管理数据模型(使用dbt、SchemaCrawler等工具)
2.数据仓库设计与业务系统模型设计的区别
面向OLTP的事务型系统模型设计和面向OLAP的分析型的数据仓库设计,在设计目标和方法等方面都有很多的不同。
3.数据仓库构建模式

在数据仓库领域,有两位大师,一位是“数据仓库”之父 Bill Inmon,一位是数据仓库权威专家 Ralph Kimball,两位大师每人都有一本经典著作,Inmon 大师著作《数据仓库》及 Kimball 大师的《数仓工具箱》,两本书也代表了两种不同的数仓建设模式,这两种架构模式支撑了数据仓库以及商业智能近二十年的发展。今天我们就来聊下这两种建模方式——范式建模和维度建模。
3.1范式建模
范式建模是数仓之父 Inmon 所倡导的,“数据仓库”这个词就是这位大师所定义的,这种建模方式在范式理论上符合 3NF,这里的 3NF 与 OLTP 中的 3NF 还是有点区别的:关系数据库中的 3NF 是针对具体的业务流程的实体对象关系抽象,而数据仓库的 3NF 是站在企业角度面向主题的抽象。
Inmon 模型从流程上看是自上而下 的,自上而下指的是数据的流向,“上”即数据的上游,“下”即数据的下游,即从分散异构的数据源 -> 数据仓库 -> 数据集市。以数据源头为导向,然后一步步探索获取尽量符合预期的数据,因为数据源往往是异构的,所以会更加强调数据的清洗工作,将数据抽取为实体-关系模型,并不强调事实表和维度表的概念。
3.2 维度建模
Kimball 模型从流程上看是自下而上 的,即从数据集市-> 数据仓库 -> 分散异构的数据源。Kimball 是以最终任务为导向,将数据按照目标拆分出不同的表需求,数据会抽取为事实-维度模型,数据源经 ETL 转化为事实表和维度表导入数据集市,以星型模型或雪花模型等方式构建维度数据仓库,架构体系中,数据集市与数据仓库是紧密结合的,数据集市是数据仓库中一个逻辑上的主题域。
3.3 以电商举例,对比2种建模方式 👈
大家都网购过,知道购买物品的流程,因此以电商购物为例,更易于大家的理解。
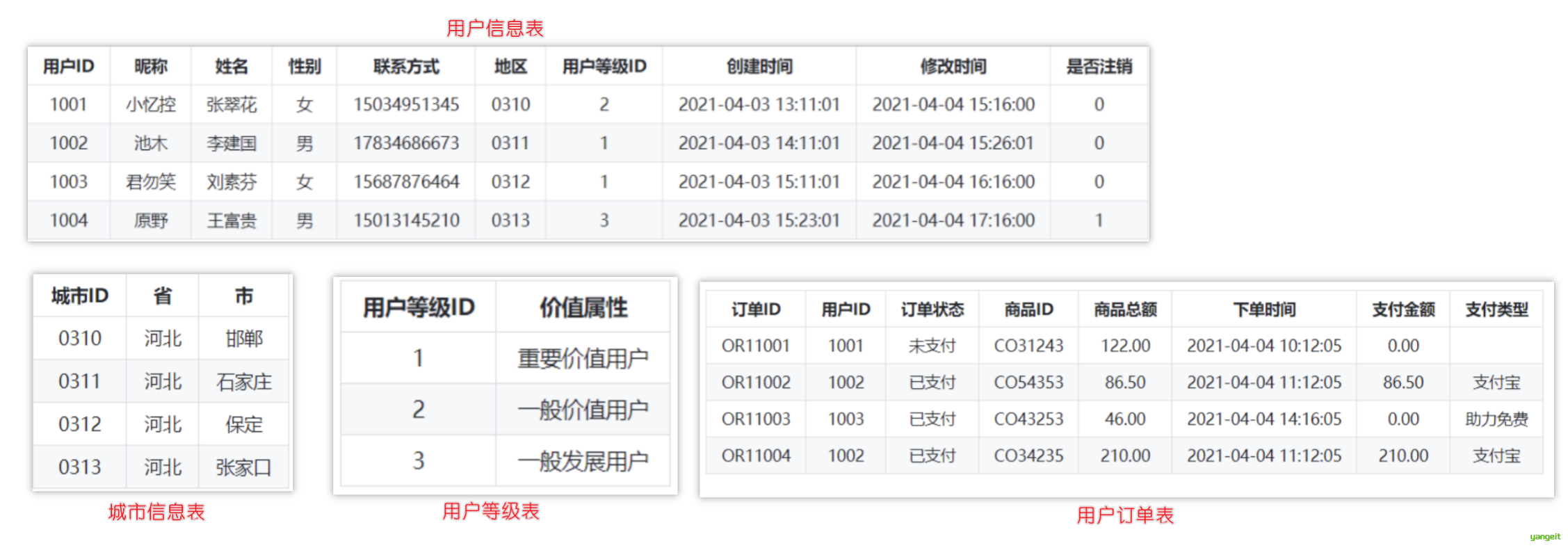
1. 源表的结构及数据
对于我们大数据平台来说,源表指的电商系统中后台数据库中的表,这种表一般都是 OLTP 类型的表:
2. 使用 Inmon 模式建模自上而下
使用 Inmon 模式对以上源表数据进行建模,需要将数据抽取为实体-关系模式,根据源表的数据,我们将表拆分为:用户实体表,订单实体表,城市信息实体表,用户与城市信息关系表,用户与用户等级关系表等多个子模块:
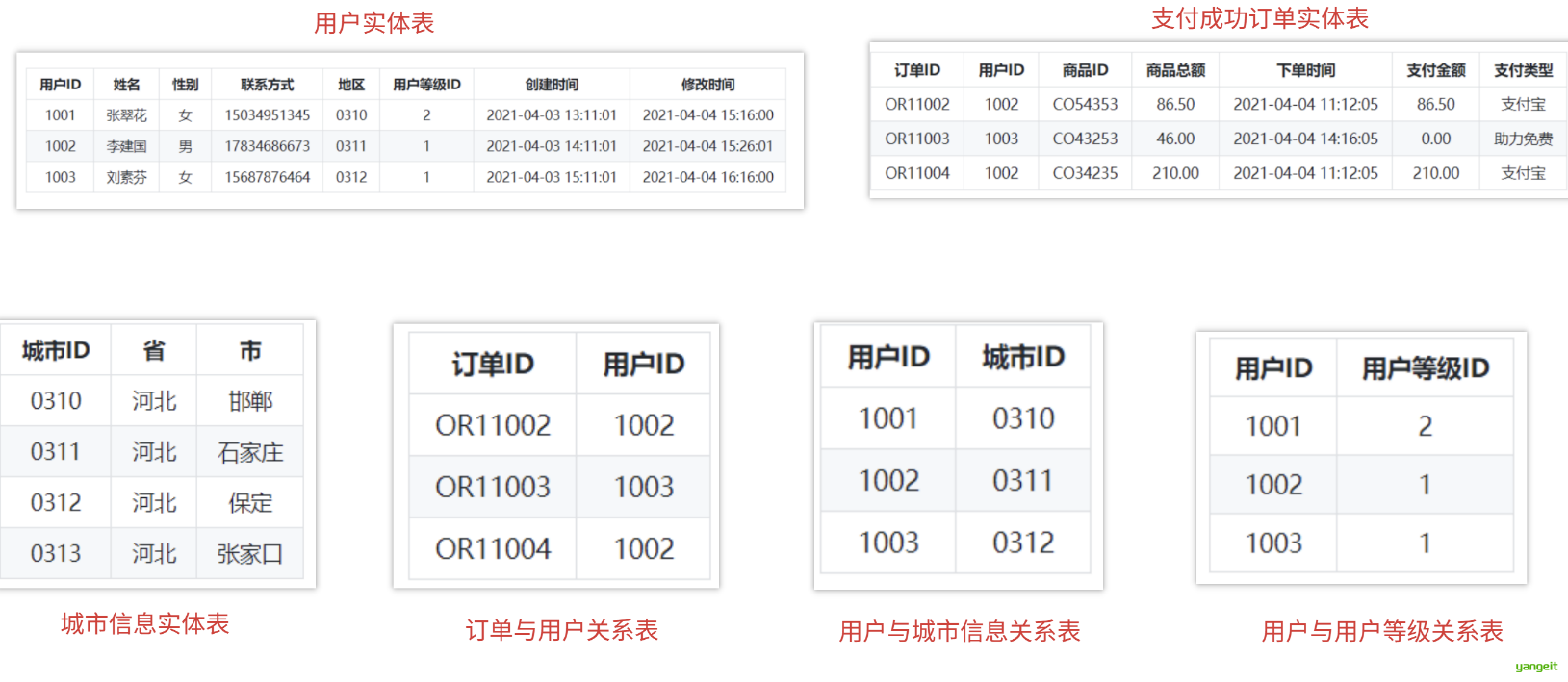
通过以上我们可以发现,范式建模就是将源表抽取为实体表,关系表,所以范式建模即是实体关系(ER)模型。数据没有冗余,符合三范式设计规范。
3. 使用 Kimball 模式建模自下而上
使用 Kimball 模式,需要将数据抽取为事实表和维度表 ,根据源表数据,我们将表拆分为:订单事实表,用户维度表,城市信息维度表,用户等级维度表。
可以看出,在 Kimball 的维度建模中,不需要单独维护数据关系表,因为关系已经冗余在事实表和维度表中。
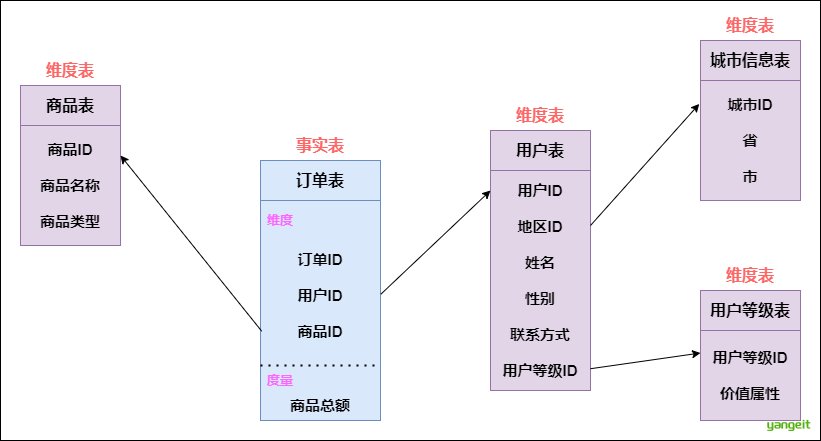
根据上图,我们发现什么,这不就是典型的雪花模式嘛,其特点就是维度表可以拥有其他维度表。
2两种建模方式的区别:

- 在传统企业数仓中,业务相对稳定,以范式建模为主。 如电信、金融行业等
- 互联网公司的业务一般是周期比较短需求变化快,并且迭代频繁,如果精心设计 Inmon 实体-关系的模式似乎并不能满足快速迭代的业务需要。所以,互联网公司更多场景下趋向于使用 Kimball 维度-事实的设计反而可以更快地完成任务。
总结
课堂作业
- 简述2种数据仓库设计模式的区别🎤
- 简述数据仓库设计的特点