
数据仓库与数据挖掘-第一章节
通过本课的学习,学生应该掌握如下知识:
第二周,4个课时,第三章数据预处理上
- 数据预处理概述
- 数据清理 🍐
- 数据清洗实操 🍐 ❤️ ✏️
- 数据清洗之异常检测实操 ✏️ 🍐 ❤️
- 数据集成 🍐❤️ ✏️
- 数据标准化 🍐❤️ ✏️
第三章数据预处理
1.数据预处理概述
数据预处理概述
1.数据预处理的目的和意义
现实世界中的数据大多都是“脏”的,原始数据通常存在着噪声、不一致、部分数据缺失等问题。 缺失值导致模型训练中断,异常值扭曲预测结果(如房价数据中的极端值),噪声数据增加模型学习难度。
核心目标:将原始数据转化为适合建模的格式,提高模型准确性和效率.
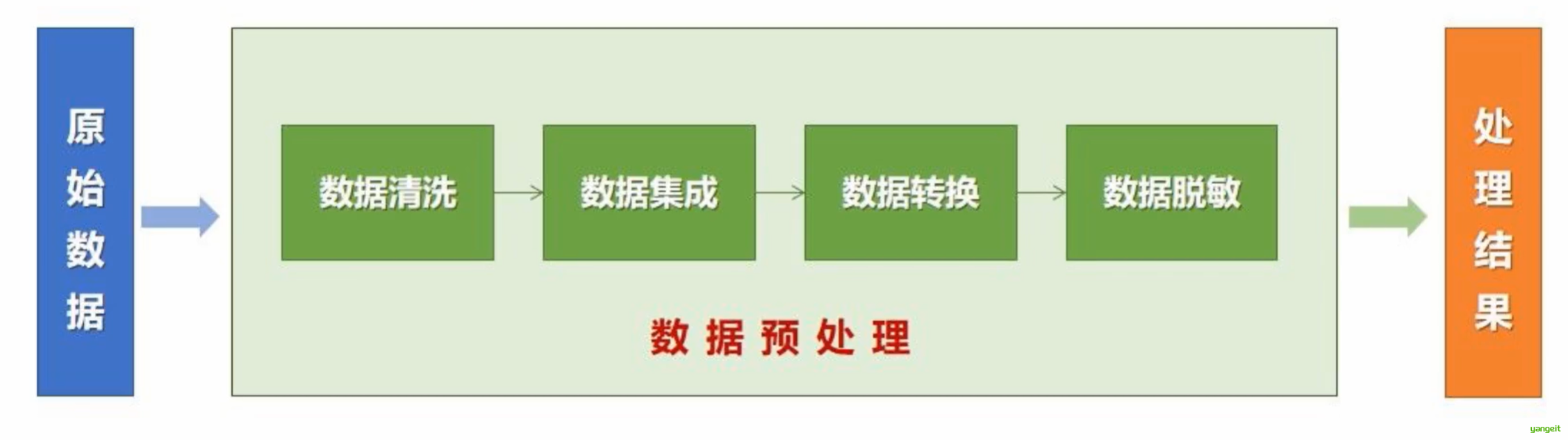
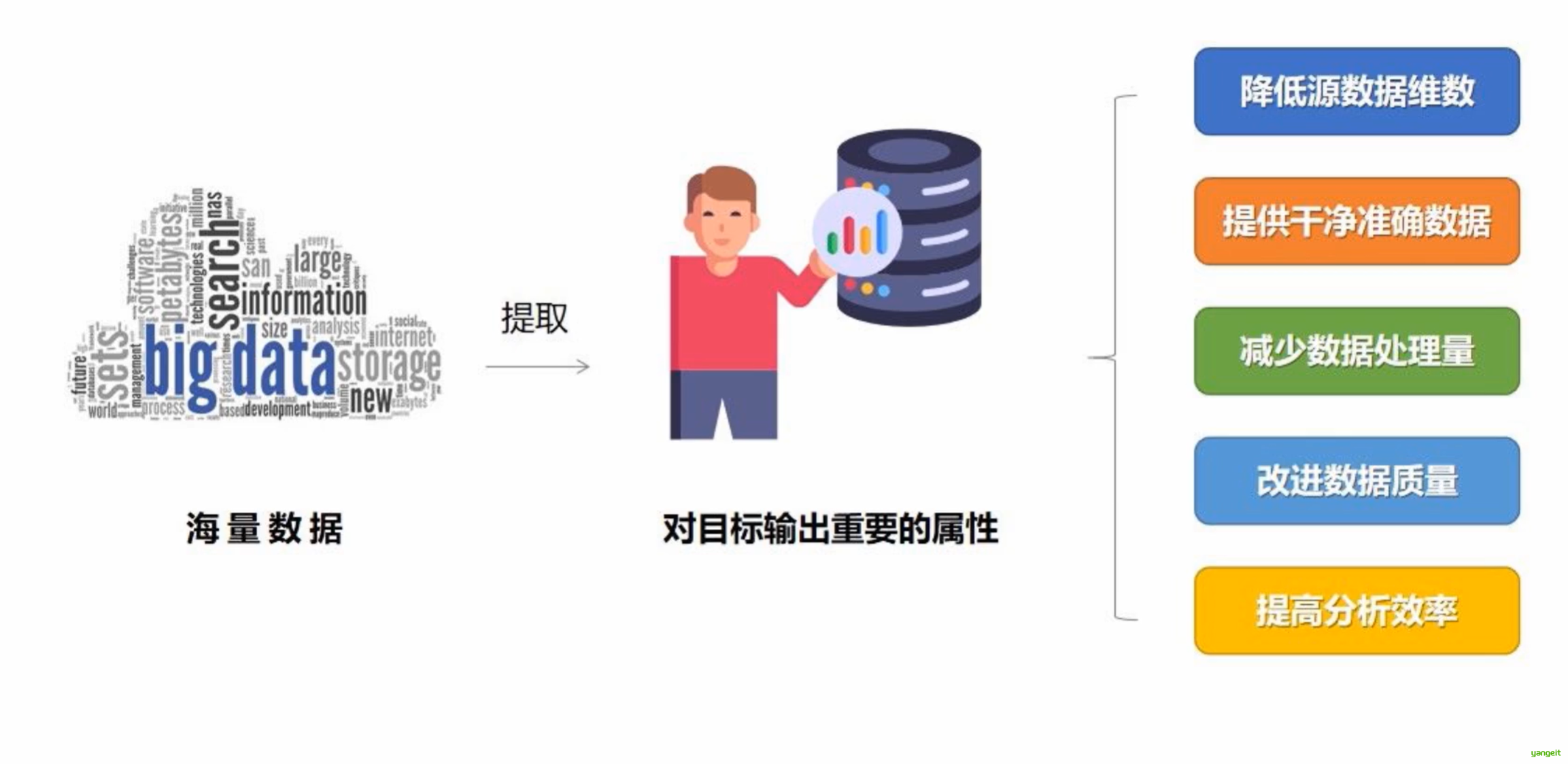
数据是数据挖掘的目标对象和原始资源,对数据挖掘最终结果起着决定性的作用。低质量的数据导致低质量的数据挖掘结果.因此,数据预处理是数据挖掘中必不可少的环节,也是数据挖掘中最为耗时的部分。
主要有数据清洗、数据集成、数据标准化,数据归约,数据变换,数据离散化等。
2. 数据质量要求
数据挖掘需要的数据必须是高质量的数据,即数据挖掘所处理的数据必须具有准确性(Correctness)、完整性(Completeness)和一致性(Consistency)等性质。此外,时效性(Timeliness)、可信性(Believability)和可解释性(Interpretability)也会影响数据的质量。
| 数据质量特性 | 定义 | 典型问题案例 |
|---|---|---|
| 准确性 | 数据值与真实世界对象的属性一致 | 用户年龄输入错误(实际30岁填为130岁) |
| 完整性 | 数据包含所有必要信息,无缺失字段或记录 | 客户表中10%记录缺失"联系方式"字段 |
| 一致性 | 同一数据在不同系统/时间点的表示一致 | 订单表中"性别"字段同时存在"男/女"和"1/0" |
| 时效性 | 数据的时间戳与实际业务发生时间一致,满足决策的时间要求 | 用去年的用户行为数据预测今年消费趋势 |
| 可信性 | 数据来源可靠,采集过程可追溯,用户对数据真实性的信任程度 | 第三方爬虫数据存在大量重复或虚假信息 |
| 可解释性 | 数据的含义清晰明确,字段名称和值易于理解,有配套的元数据说明 | 表中"flag"字段未说明其代表"是否激活" |
2.数据清理
数据清理
1. 为什么要进行数据清洗?
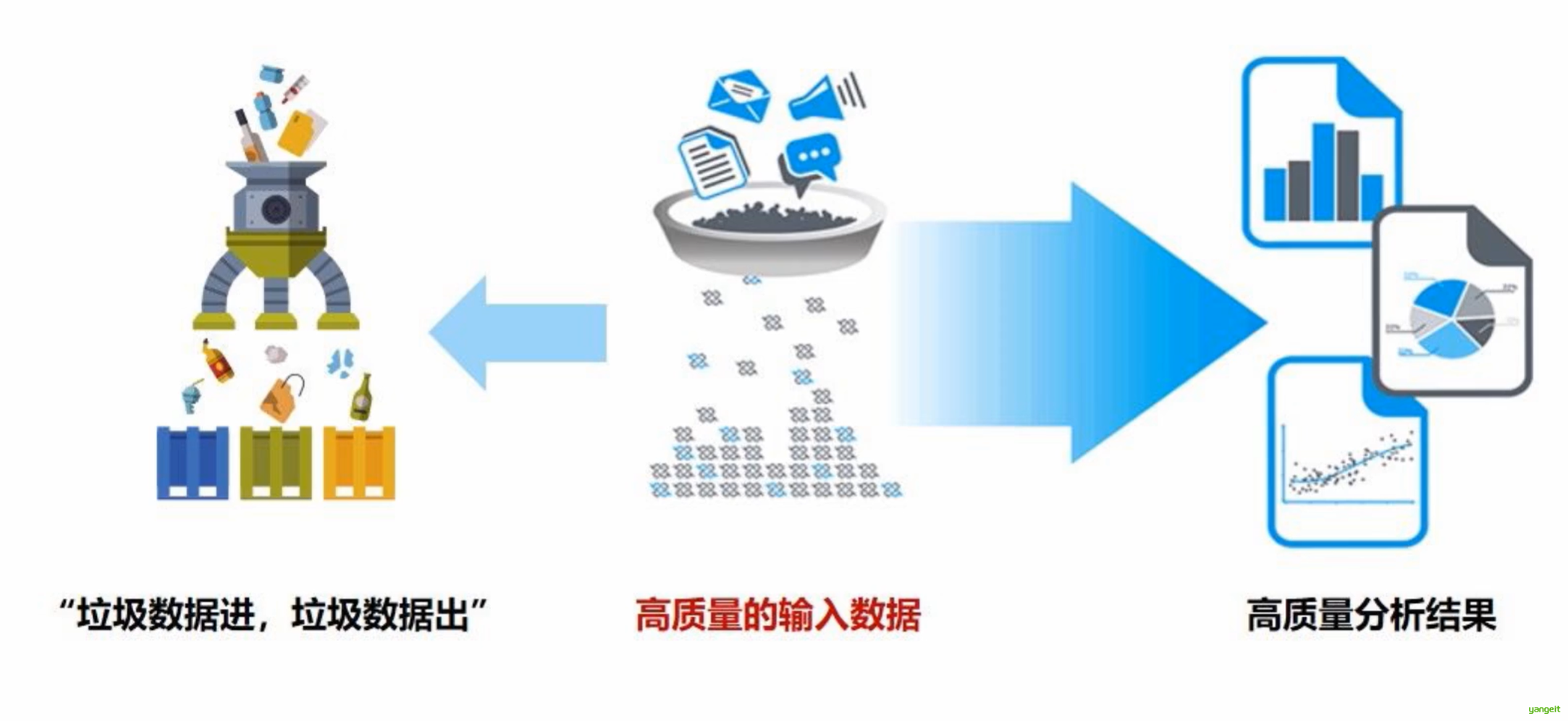
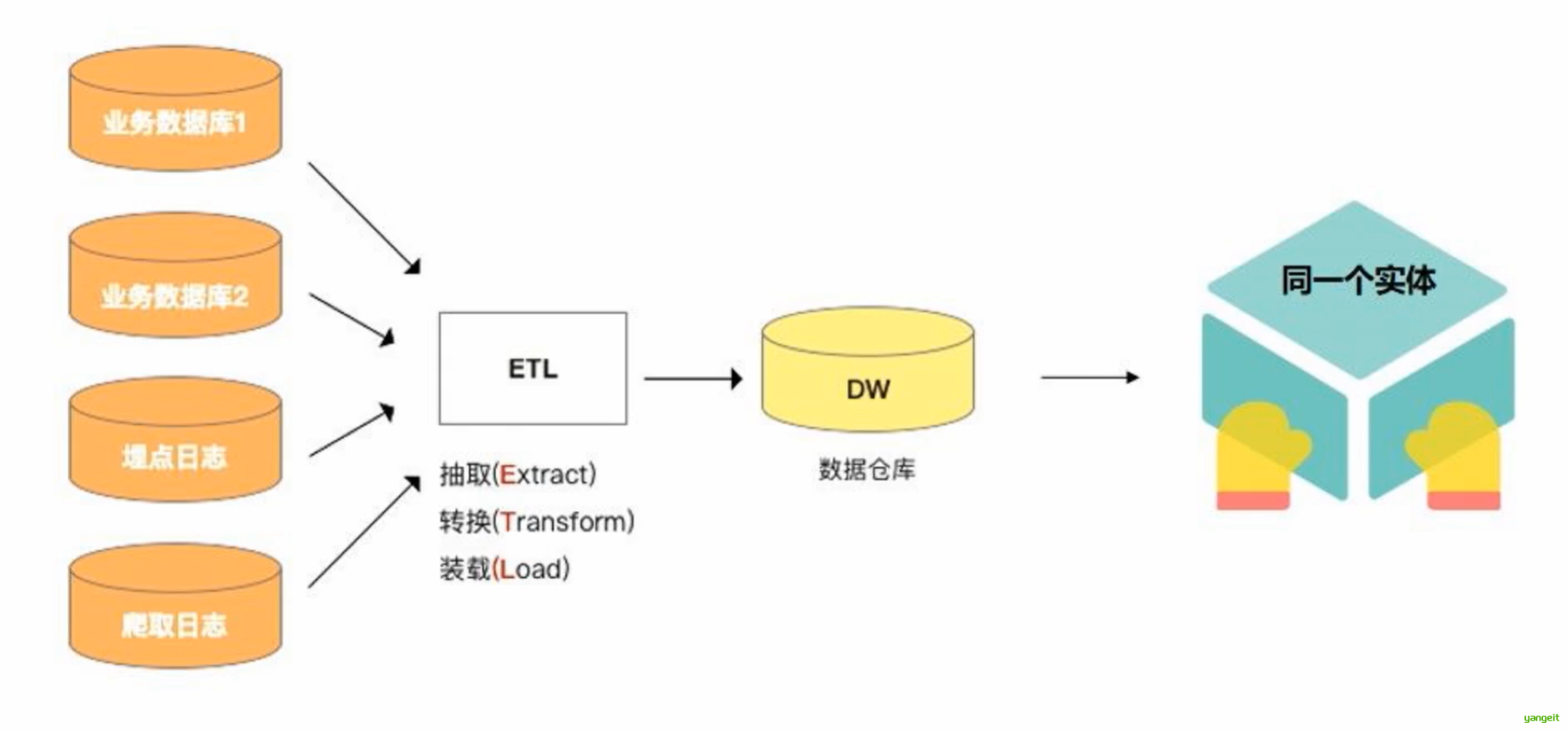
数据仓库中的数据是从多个业务系统中抽取,按照一定规则把脏数据 洗掉
数据清洗就是将数据仓库中的数据进行清洗,使其符合数据仓库的数据模型。
2. 数据清洗的应用场景
合并后的数据库中会出现重复的记录需要识别和消除(图1)
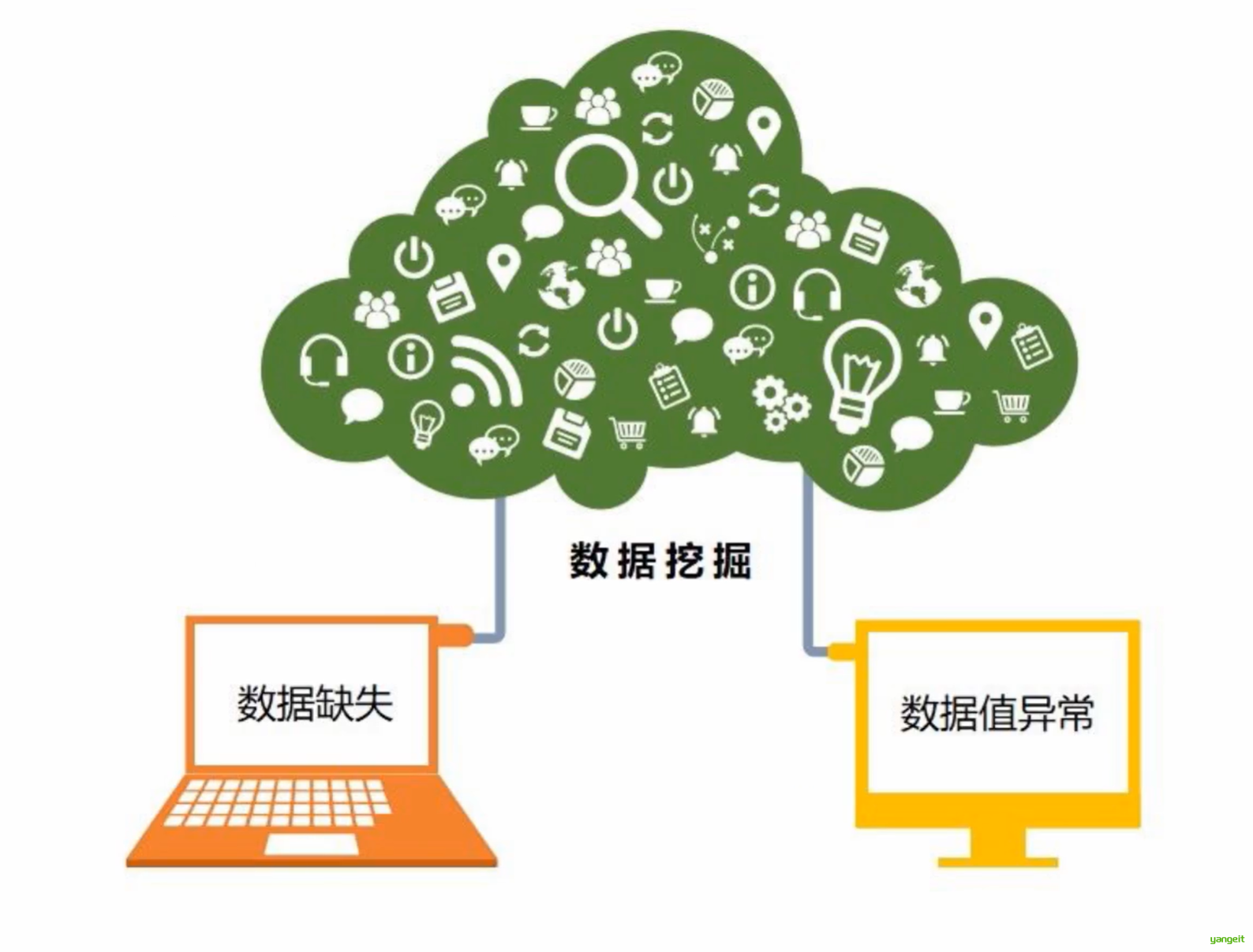
在数据挖掘中存在一些异常值,需要识别和消除(图2)
3. 数据清洗方式
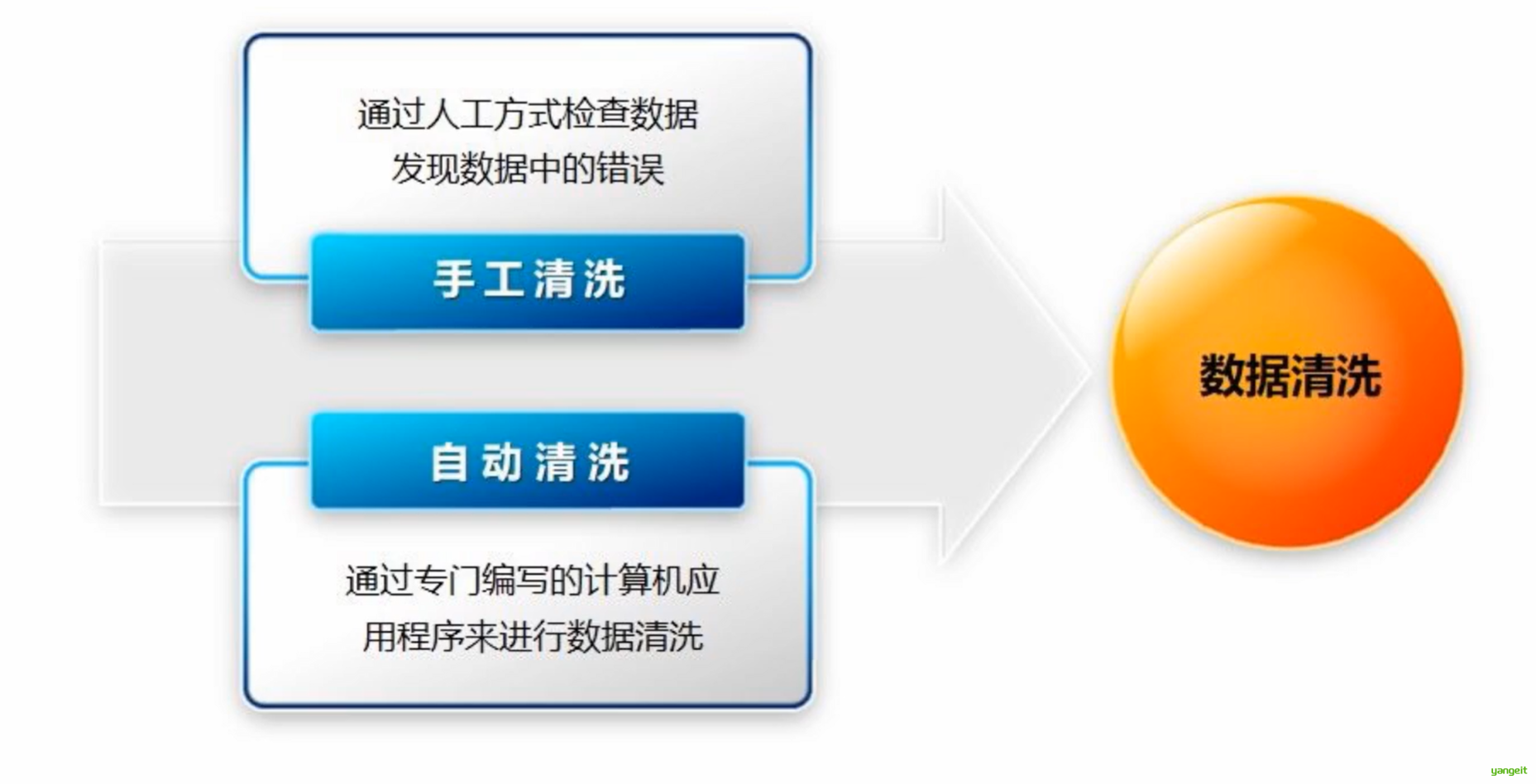
人工清洗:人工识别和消除异常值和重复记录,但效率低,且容易出错。
自动清洗:通过机器学习算法自动识别和消除异常值和重复记录。
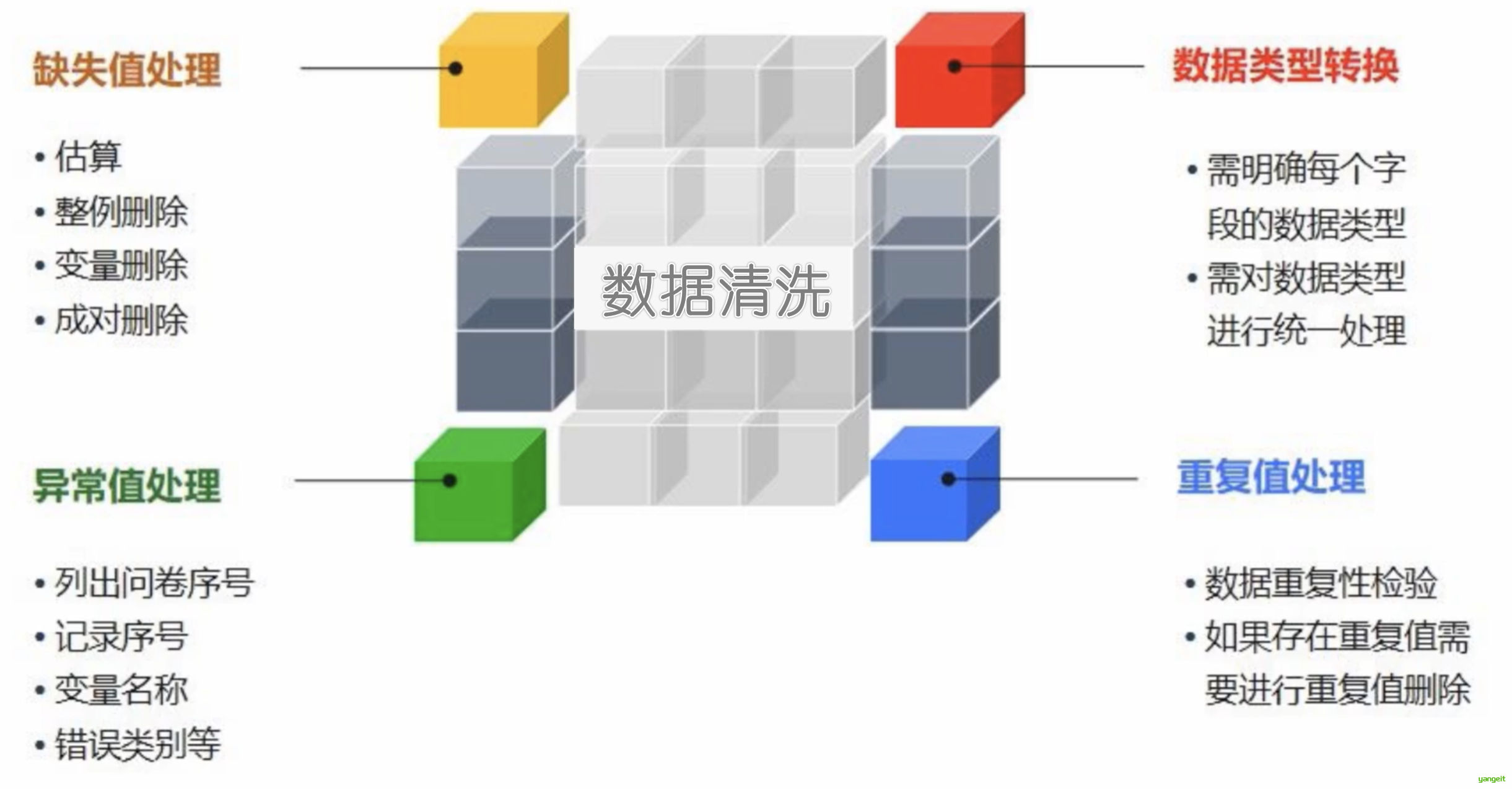
4.数据清洗的内容:
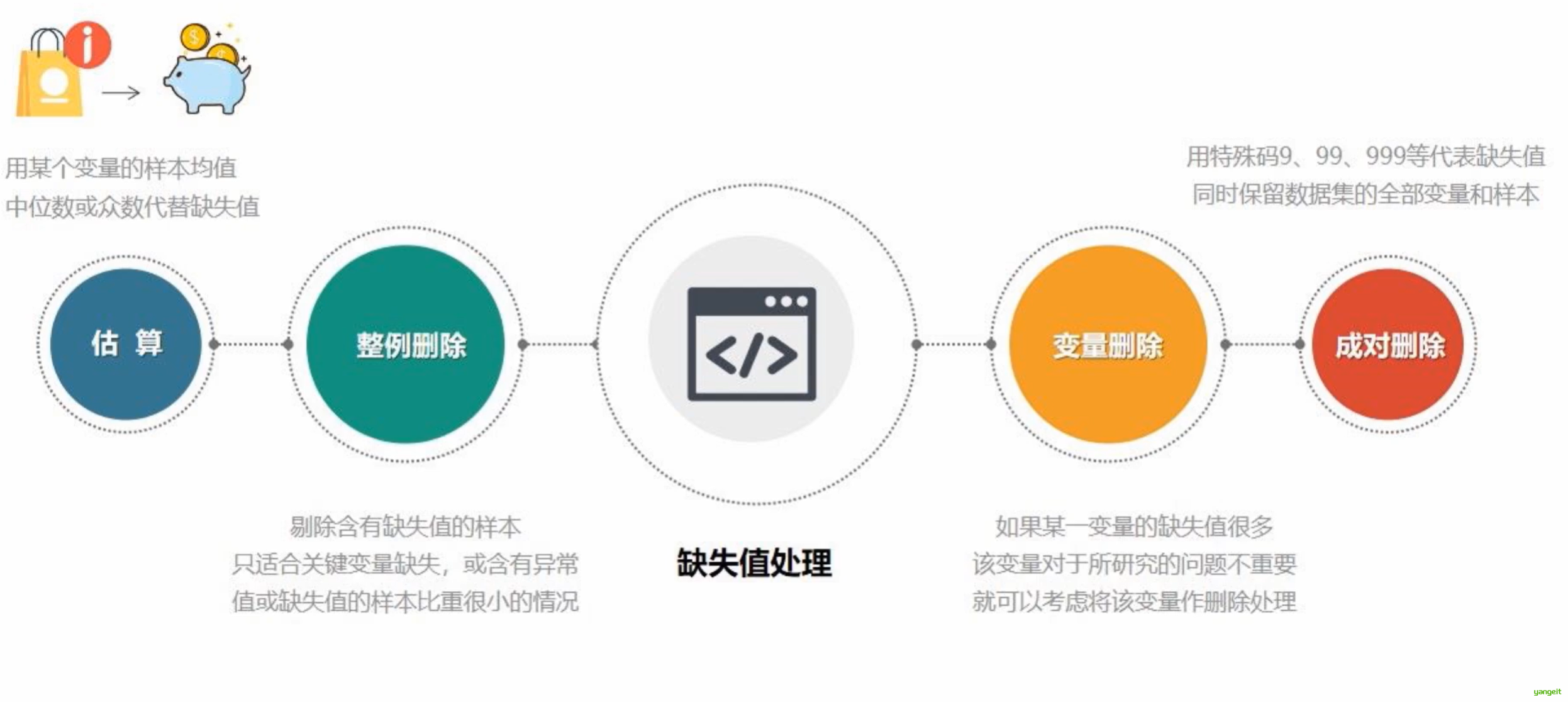
5.异常值检测:

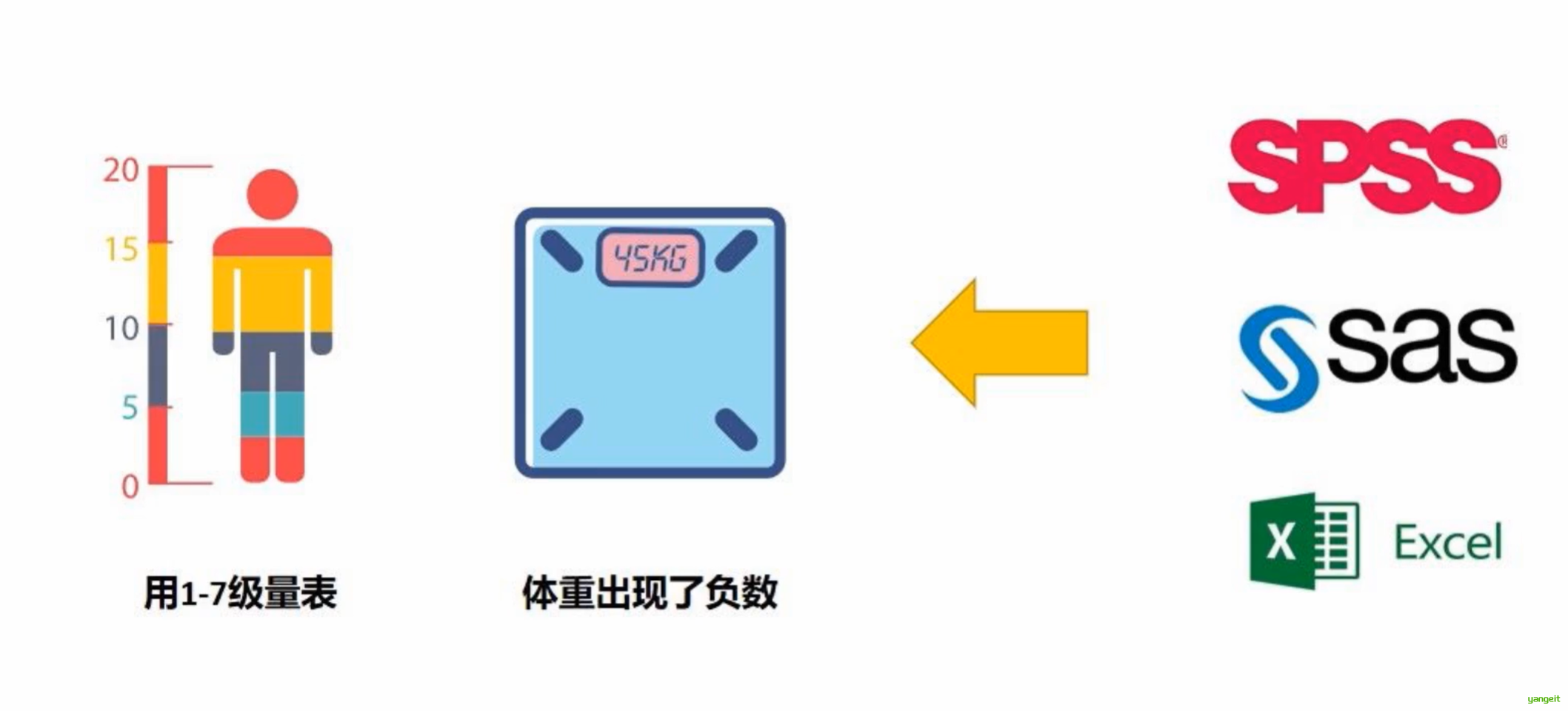
6.数据清洗注意事项
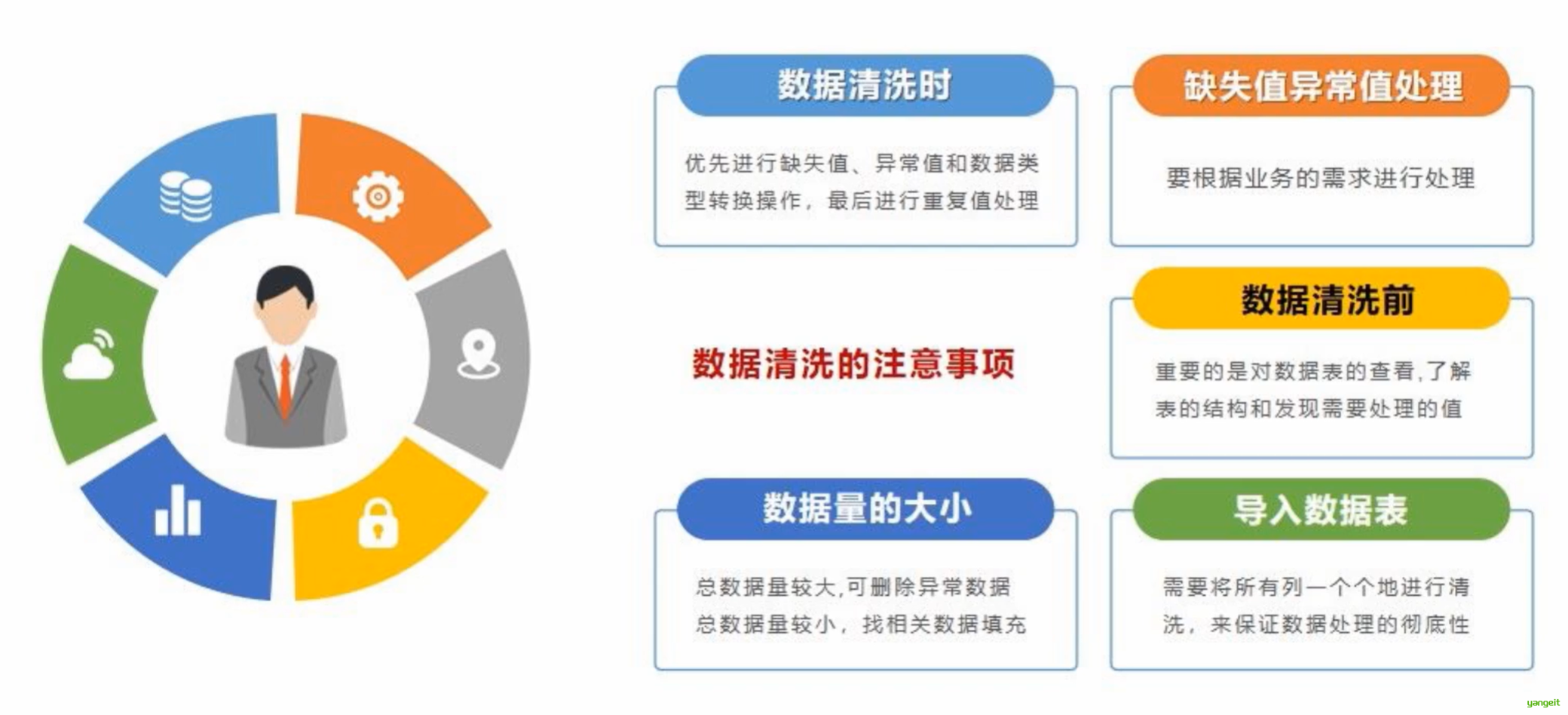
总结
课堂作业
- 在数据清洗中,处理数据缺失值的方法有哪些?如何去掉数据的噪声?
- 数据清洗的注意事项有哪些?
3. 数据清洗实操
前言
DataFrame 是 Python 中 pandas 库的核心数据结构,它是一种二维的、表格型的数据结构(类似于 Excel 表或 SQL 表),可以存储多种类型的数据(数值、字符串、布尔值等),并提供了丰富的数据操作方法。
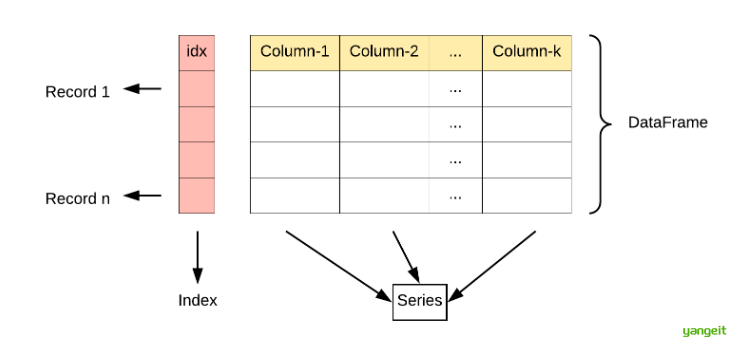
1. 检测和处理缺失值
isnull() 和 notnull() 函数可以用来检测缺失值,而 fillna() 和 dropna() 函数则可以用来处理缺失值。
案例1:利用isnull()和notnull()函数检测缺失值
# 导入 pandas 库,通常用于数据处理和分析,并用 pd 作为别名
import pandas as pd
# 创建一个 pandas Series 对象,Series 是 pandas 中的一维数据结构,类似于带标签的数组
# 这里传入一个包含字符串和 np.nan(表示缺失值)的列表
string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
# 打印这个 Series
print(string_data)
# 使用 isnull() 方法检查 Series 中的每个元素是否为缺失值(NaN)
# 返回一个布尔型 Series,True 表示对应位置是缺失值,False 表示不是
string_data.isnull()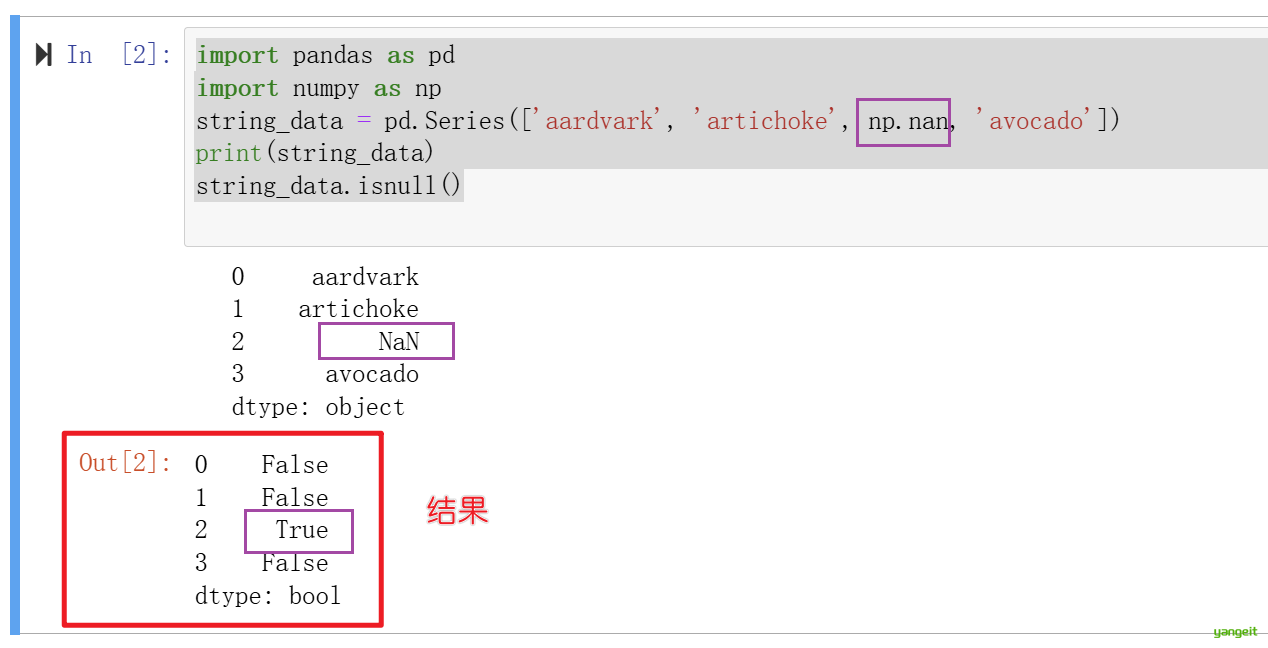
在Pandas中,缺失值表示NA(Not Available),即缺失值,而Python内置的None表示空值,也被当做NA处理。
案例2:利用sum统计缺失值的数量
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于数值计算
import numpy as np
# 创建一个 DataFrame:
# - 使用 np.arange(12) 生成 0 到 11 的数组,然后 reshape(3,4) 转换为 3 行 4 列的二维数组
# - 列名设置为 ['A', 'B', 'C', 'D']
df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A','B','C','D'])
# 使用 iloc 选择第 3 行(索引为 2),并将该行所有列的值设置为 NaN(缺失值)
df.iloc[2,:] = np.nan
# 新增一列,列名为 3(整数),并将该列所有值设置为 NaN
df[3] = np.nan
# 打印 DataFrame,查看当前数据
print(df)
# 使用 isnull() 检测 DataFrame 中的缺失值(NaN),然后 sum() 统计每列的缺失值数量
df.isnull().sum()
2. 缺失值的处理
缺失值的处理方法:删除和填充。
案例3:利用dropna()函数删除缺失值
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于数值计算
import numpy as np
# 创建一个 DataFrame:
# - 使用 np.arange(12) 生成 0 到 11 的数组,然后 reshape(3,4) 转换为 3 行 4 列的二维数组
# - 列名设置为 ['A', 'B', 'C', 'D']
df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A','B','C','D'])
# 使用 iloc 选择第 3 行(索引为 2),并将该行所有列的值设置为 NaN(缺失值)
df.iloc[2,:] = np.nan
# 新增一列,列名为 3(整数),并将该列所有值设置为 NaN
df[3] = np.nan
# 打印 DataFrame,查看当前数据
print(df)
print("----开始删除缺失值---")
# 参数演示1:默认情况下,dropna() 会删除所有包含缺失值的行
cleaned=df.dropna()
print(cleaned)
# 参数演示2:传入how='all',表示仅仅删除所有列值都为缺失值的行
#print(df.dropna(how='all'))
# 参数演示3:传入axis=1,how='all',表示仅仅删除所有行值都为缺失值的列
#print(df.dropna(axis=1, how='all'))
# 参数演示4:传入thresh=N,表示一行中至少有 N 个非缺失值,才保留该行
#print(df.dropna(thresh=2))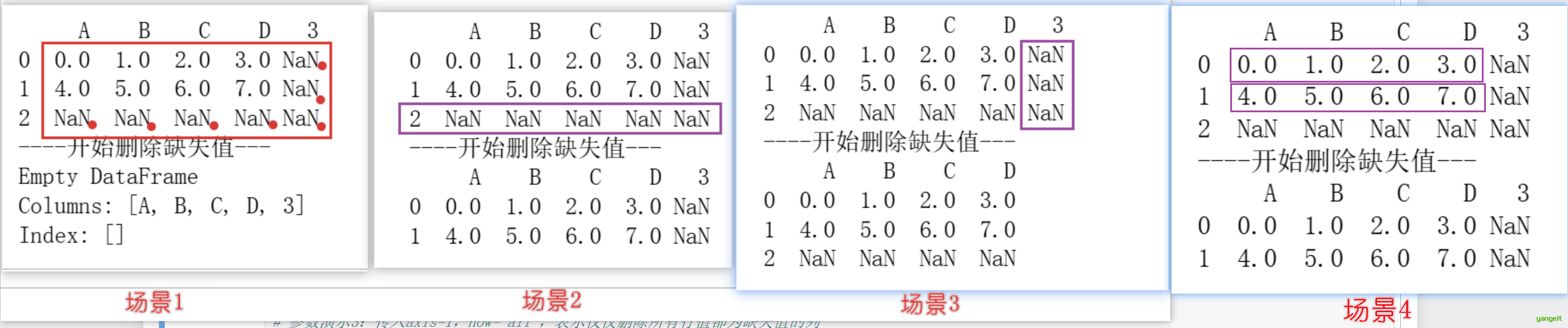
案例4:利用fillna()函数填充缺失值
借用上面的数据,填充缺失值
fillna函数格式:
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
参数说明:
value:填充值,可以是单个值,也可以是列表或字典,用于指定每个列的填充值
method:填充方法,可以是'ffill'、'bfill',用于指定填充方式
axis:填充轴,可以是0或1,用于指定填充方向,默认是0,即按列填充
inplace:是否就地修改,默认为False,如果为True,则直接修改原数据,否则返回新数据
limit:填充限制,用于指定填充的最大次数
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A','B','C','D'])
df.iloc[2,:] = np.nan
df[3] = np.nan
print(df)
print("----开始填充缺失值---")
# 参数演示1:默认情况下,fillna() 会填充所有缺失值
# cleaned=df.fillna(0)
# print(cleaned)
# 参数演示2:传入value参数,指定每个列的填充值
# cleaned=df.fillna(value={'A':11, 'B':22, 'C':33, 'D':44})
# print(cleaned)
# 参数演示3:传入method参数,指定填充方法
# cleaned = df.fillna(method='ffill') # 用前一个非空值填充
# cleaned = df.fillna(method='bfill') # 用后一个非空值填充
# print(cleaned)
# 参数演示4:利用Series的均值填充
# cleaned=df.fillna(df.mean())
# print(cleaned)
# 参数演示5:利用DataFrame的均值填充
# df['B']=df['B'].fillna(df['B'].mean())
# print(df)
# 参数演示6:利用DataFrame的中位数填充(如果数量是偶数,则取中间两个数的平均值)
# df['A']=df['A'].fillna(df['A'].median())
# print(df)
- 数据值的替换以及利用函数或映射进行数据值的替换
使用replace函数进行数据值的替换
使用map函数进行数据值的替换
案例5:利用replace函数进行数据值的替换
data = {'姓名':['张三','小明','马芳','国志'],'性别':['0','1','0','1'],
'籍贯':['北京','甘肃','','上海']}
df = pd.DataFrame(data)
print(df)
print("-----开始替换----")
# 参数演示1:默认情况下,replace() 会替换所有匹配的值
# cleaned=df.replace('','不详') # 将所有空值替换为'不详'
# print(cleaned)
# 参数演示2:多值替换,可以指定多个值进行替换
cleaned=df.replace(['不详','甘肃'],['兰州','兰州']) # 将'不详'和'甘肃'分别替换为'兰州'和'兰州'
print(cleaned)
# 参数演示3:传入字典进行多值替换
# cleaned=df.replace({'1':'男','0':'女'}) # 将'1'替换为'男',将'0'替换为'女'
# print(cleaned)
案例6:利用map函数进行数据值的替换
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 创建一个字典 data,包含学生信息:
# - '姓名':学生姓名列表
# - '性别':学生性别列表('0'表示女,'1'表示男)
# - '籍贯':学生籍贯列表
data = {
'姓名': ['张三', '小明', '马芳', '国志'],
'性别': ['0', '1', '0', '1'],
'籍贯': ['北京', '兰州', '兰州', '上海']
}
# 将字典转换为 DataFrame
df = pd.DataFrame(data)
# 新增一列 '成绩',并赋值给学生成绩
df['成绩'] = [58, 86, 91, 78]
# 打印 DataFrame,查看当前数据
print("原始数据:")
print(df)
# 定义一个函数 grade,用于根据成绩返回等级:
# - 90分及以上:'优'
# - 70-89分:'良'
# - 60-69分:'中'
# - 60分以下:'差'
def grade(x):
if x >= 90:
return '优'
elif 70 <= x < 90:
return '良'
elif 60 <= x < 70:
return '中'
else:
return '差'
# 使用 map 方法将 grade 函数应用到 '成绩' 列,生成新列 '等级'
df['等级'] = df['成绩'].map(grade)
# 打印处理后的 DataFrame
print("\n处理后数据(带等级):")
print(df)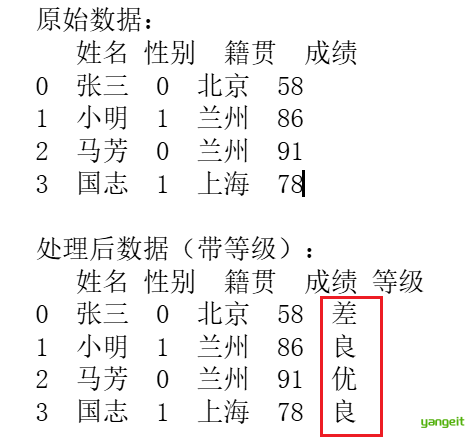
总结
课堂作业
- 在jupyter中,完成上述案例,了解数据清洗的基本操作
4. 数据清洗之异常检测实操
前言
5. 异常值的检测
上一周的课程,我们学习了数据的散布度量,其中学习了利用四分位数和箱型图来检测异常值。本节课我们将使用代码来演示异常值的检测。
首先,我们学习使用散点图来检测异常值。
案例7:利用散点图检测异常值
# 创建一个 DataFrame,列名为 'W',数据为 0 到 19 的整数序列
wdf = pd.DataFrame(np.arange(20), columns=['W'])
# 新增一列 'Y',其值为 'W' 列的值乘以 1.5 再加 2(线性变换)
wdf['Y'] = wdf['W'] * 1.5 + 2
# 使用 iloc 修改特定位置的数值:
# - 将第 4 行(索引为 3)的 'Y' 列(第 2 列,索引为 1)的值改为 128
wdf.iloc[3, 1] = 128
# - 将第 19 行(索引为 18)的 'Y' 列的值改为 150
wdf.iloc[18, 1] = 150
print("---打印表格---")
print(wdf)
# 绘制散点图:
# - kind='scatter' 指定图表类型为散点图
# - x='W' 指定横轴数据列为 'W'
# - y='Y' 指定纵轴数据列为 'Y'
wdf.plot(kind='scatter', x='W', y='Y')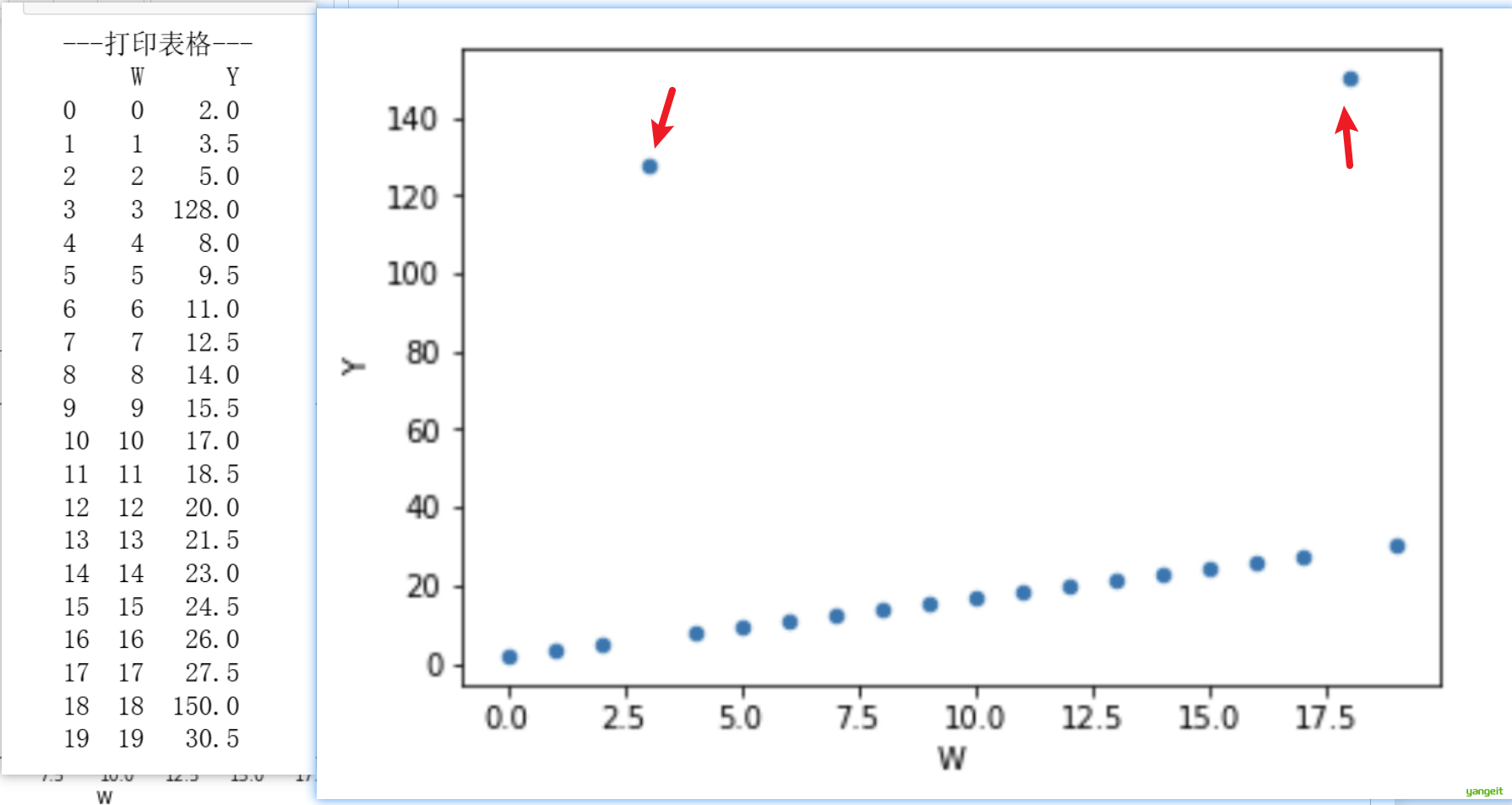
如果使用人工可视化的方式,很容易发现异常值,但是如果数据量非常大,人工可视化的方式就不太可行了。
所以,我们需要使用代码来进行异常值的检测。
案例8:利用3sigma原则检测异常值
- 如果数据服从正太分布,使用3sigma原则来检测异常值棒棒的,因为在正太分布中,99.73%的数据点都位于平均值的±3个标准差范围内。
- 3sigma原则是指: 👇
- 如果某个数据点与平均值的偏差超过3个标准差,则认为是异常值。

# 定义检测异常值的函数 outRange,输入参数 S 是一个 Pandas Series
def outRange(S):
# 计算布尔掩码 (boolean mask),标记哪些数据点是异常值:
# 条件1: 数据点 S < 均值 - 3倍标准差 (左侧异常值)
# 条件2: 数据点 S > 均值 + 3倍标准差 (右侧异常值)
# 两个条件用 | (或) 连接,满足任一条件即为异常值
blidx = (S.mean() - 3*S.std() > S) | (S.mean() + 3*S.std() < S)
# 获取异常值的行索引:
# np.arange(S.shape[0]) 生成从0到Series长度的序列
# [blidx] 用布尔掩码筛选出True对应的索引
idx = np.arange(S.shape[0])[blidx]
# 通过索引获取异常值数据
outRange = S.iloc[idx]
# 返回异常值Series
return outRange
# 调用函数检测 wdf['Y'] 列的异常值
outier = outRange(wdf['Y'])
# 打印异常值结果
print(outier)运行结果:
18 150.0
Name: Y, dtype: float64通过3sigma原则,我们发现150这个数据点是异常值。但是我们使用散点图发现128和150这两个数据点是异常值,但是3sigma原则只发现了150这个数据点是异常值,上述的异常范围:(-89.77, 136.07) 。
这是因为3sigma原则是基于正太分布的,如果数据分布不是正太分布,则3sigma原则就失效了。
案例9:利用箱线图检测异常值
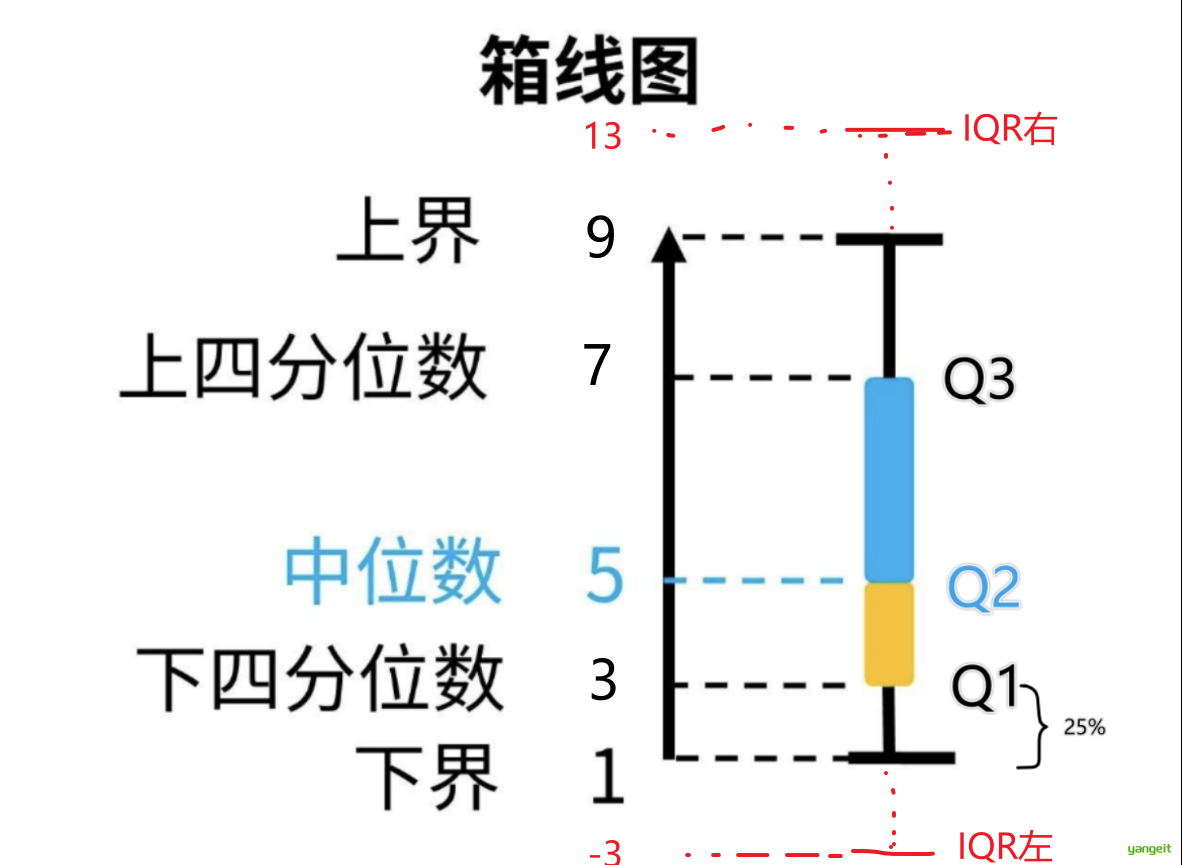
其中IQR左=Q1-1.5IQR,IQR右=Q3+1.5IQR,Q1和Q3是四分位数,IQR是四分位距。如果数据点在IQR左和IQR右之外,则为异常值。
代码示例:
# 绘制箱线图:
# - kind='box' 指定图表类型为箱线图
# - x='W' 指定横轴数据列为 'W'
# - y='Y' 指定纵轴数据列为 'Y'
wdf.plot(kind='box', x='W', y='Y')
# 获取IQR左和IQR右
Q1 = wdf['Y'].quantile(0.25) # 获取下四分位数
Q3 = wdf['Y'].quantile(0.75) # 获取上四分位数
IQR = Q3 - Q1 # 获取四分位极差
IQR_left = Q1 - 1.5 * IQR # 获取IQR左
IQR_right = Q3 + 1.5 * IQR # 获取IQR右
# 获取异常值
outlier = wdf[(wdf['Y'] < IQR_left) | (wdf['Y'] > IQR_right)]
print("异常值:")
print(outlier)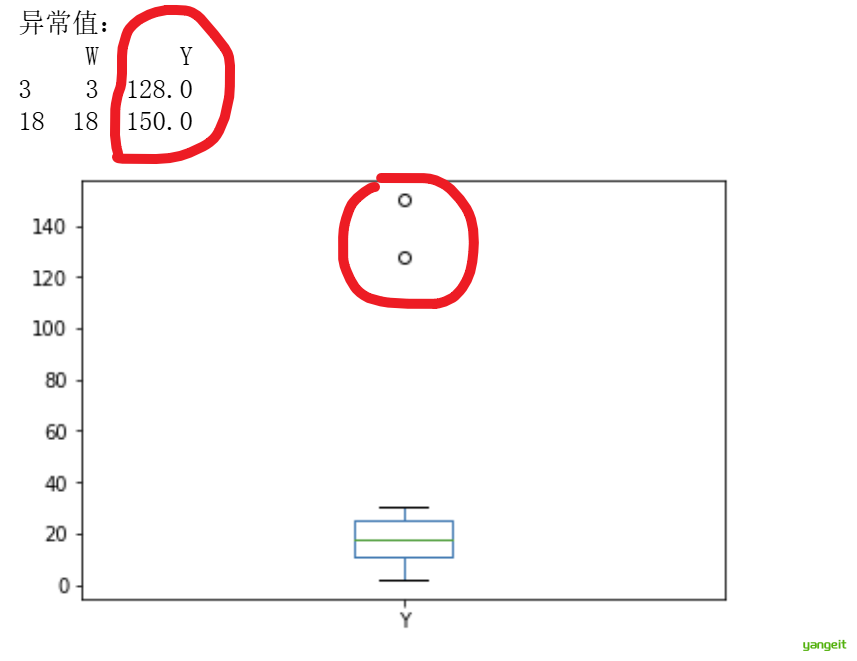
使用箱线图以及IQR左和IQR右,可以很容易的发现异常值,这种方式适合检测数据分布偏科以及存在极端的数据点。
总结
课堂作业
- 开始练习吧!!🎤
- 在jupyter中,完成上述案例,了解异常值检测的基本操作
5.数据集成
数据集成
1. 数据集成简介
在当今数字化时代,几乎所有企业都在谈“数据价值”,但实际操作中,很多企业都卡在同一个坎上:数据散在各处,财务的数据锁在ERP里,销售的数据存在CRM里,库存的数据躺在WMS里,想做一次完整的业务分析,得登好几个系统、导好几份表格,凑在一起还发现格式对不上、字段不统一,最后要么分析不了,要么分析结果跟实际情况差很远。
其实,解决这个问题的核心工具就是 数据集成
简单来说,数据集成就是把来自不同数据源的数据,经过处理后整合到一起,形成一个统一、连贯的数据集合。它不是“数据的简单堆砌”,而是要解决“数据分散、格式不统一、无法互通”的问题。
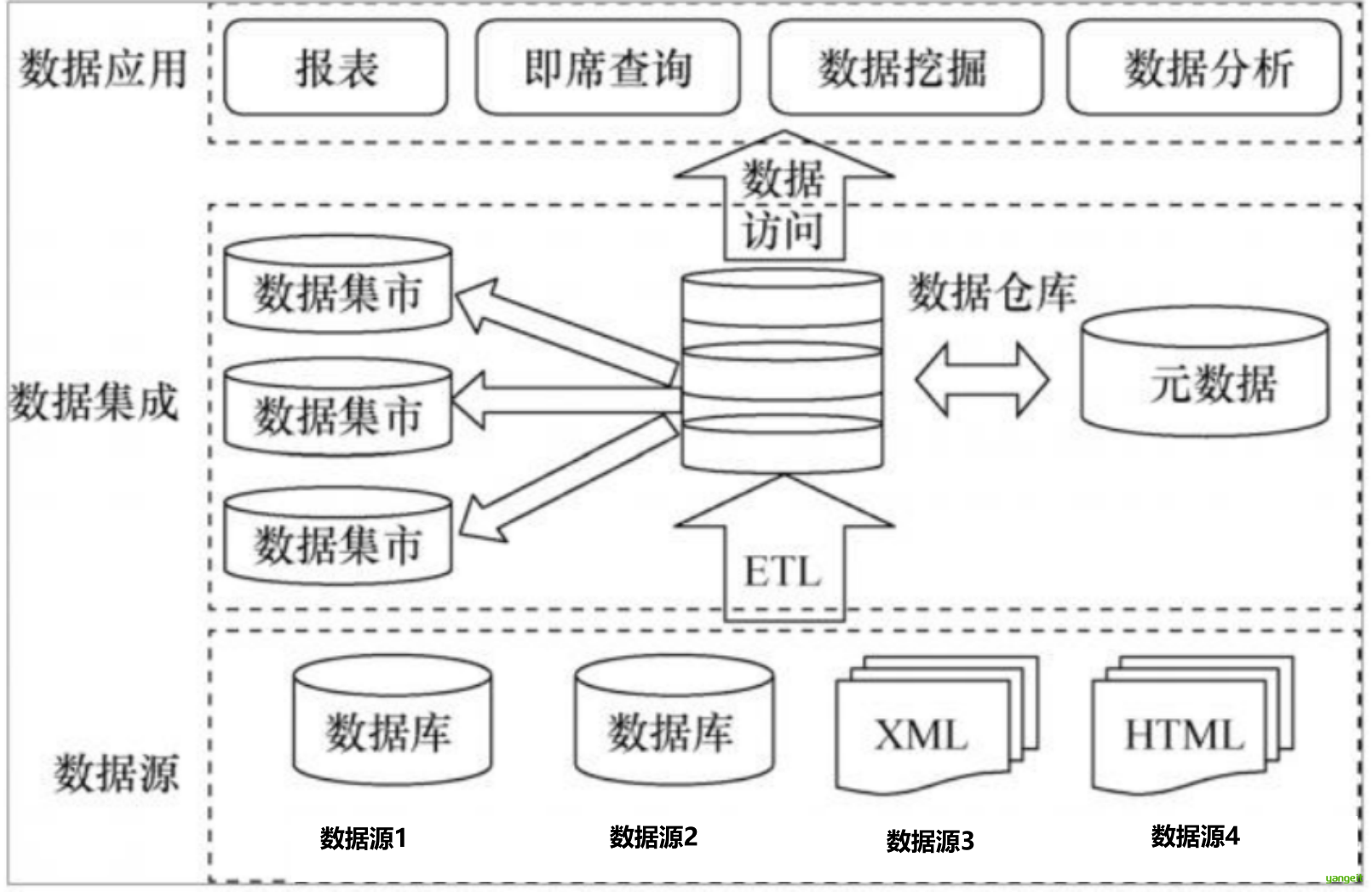
数据集成过程中的问题: 实体识别,数据冗余和相关分析,元组重复,数据值冲突检测和处理。
2.利用Panda合并数据
在实际的数据分析中,可能有不同的数据来源,因此,需要对数据进行合并处理。我们可以使用Pandas中三个函数来实现数据的合并:
- 需要关联两个表的列数据 →
merge() - 需要垂直或水平堆叠相同结构的表 →
concat() - 需要用另一个表补充缺失值 →
combine_first()
案例1:利用merge()合并数据
merge()函数格式:👇
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
# 看起来很复杂,其实一点也不简单o(╥﹏╥)o,我们一个一个来分析:
# left:左表
# right:右表
# how:合并方式,默认为inner,即内连接,可选值为inner、outer、left、right
# on:合并列,默认为None,即根据索引合并,如果指定了on,则根据指定的列合并
# left_onon:左表索引列,默认为False,如果为True,则根据索引合并
# right_index:右表索引列,默认为False,如果为True,则根据索引合并
# sort:是否排序,默认为False,如果为True,则根据索引排序
# suffixes:合并列后缀,默认为('_x', '_y'),如果指定了suffixes,则根据指定的后缀合并
# copy:是否复制,默认为True,如果为False,则不复制
# indicator:是否添加合并标记,默认为False,如果为True,则添加合并标记
# validate:验证方式存在2张表,需要合并,效果如下: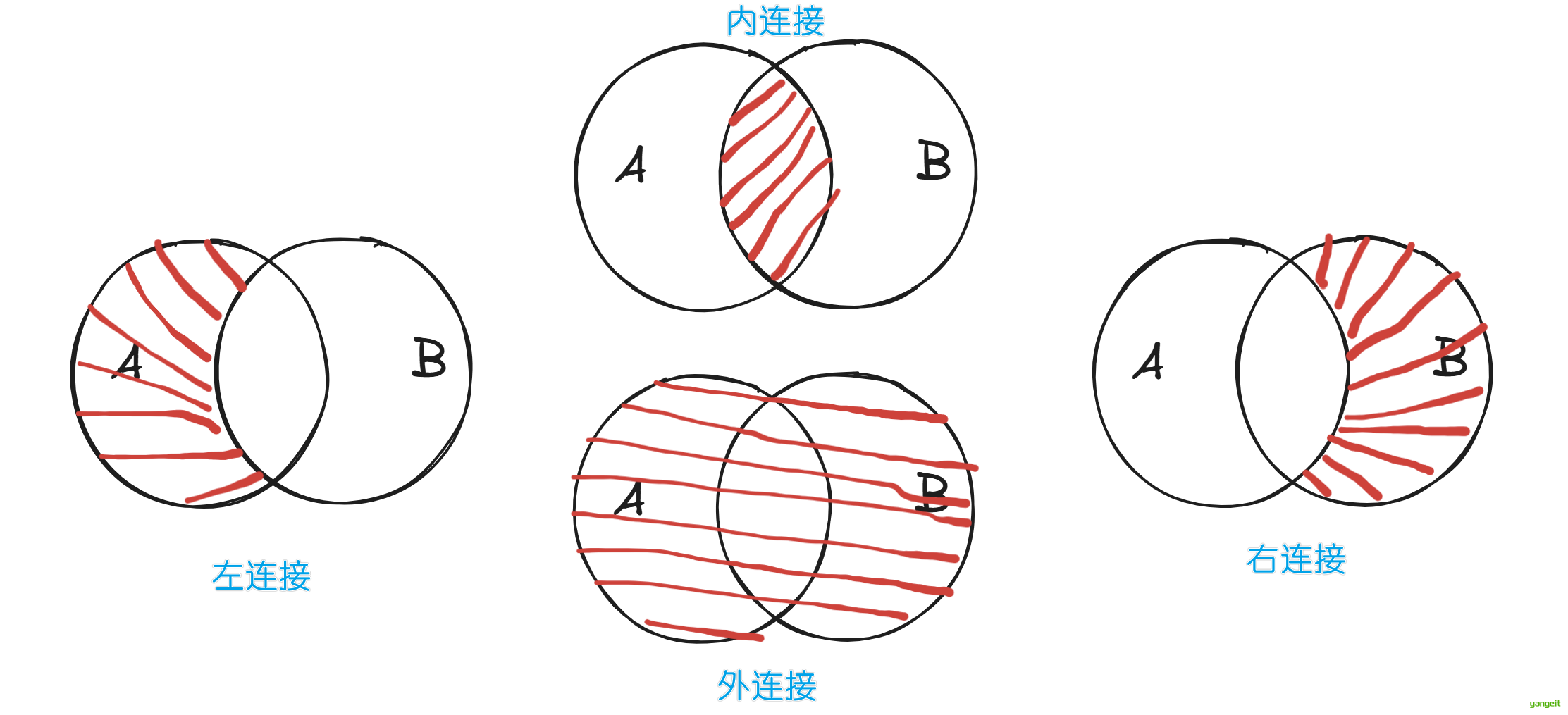
import pandas as pd
# 定义2个DataFrame
# price:水果价格表
price = pd.DataFrame({'fruit':['apple','grape',
'orange','orange','strawberry'],'price':[8,7,9,11,40]})
display(price)
# amount:水果数量表
amount = pd.DataFrame({'fruit':['apple','grape',
'orange','pear'],'amout':[5,11,8,6]})
display(amount)
print("----内连接-----")
# 场景1:合并2个DataFrame 默认是内连接(inner)如下图
display(pd.merge(price,amount))
print("----左连接-----")
# 场景2:合并2个DataFrame 左连接(left)如下图
display(pd.merge(price,amount,how='left'))
print("----右连接-----")
# 场景3:合并2个DataFrame 右连接(right)如下图
display(pd.merge(price,amount,how='right'))
print("----外连接-----")
# 场景4:合并2个DataFrame 外连接(outer)如下图
display(pd.merge(price,amount,how='outer'))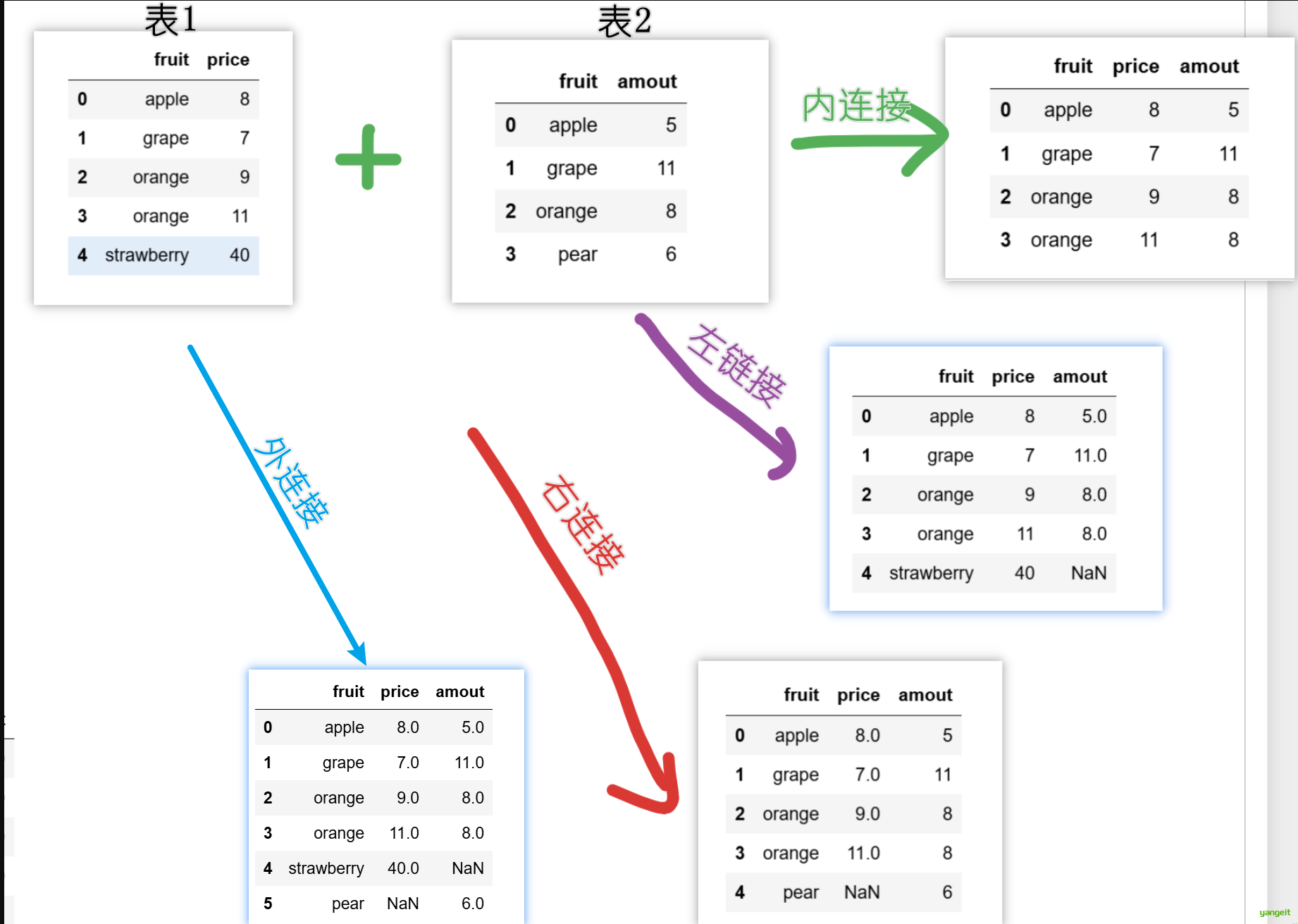
上面的案例中,合并的是2个DataFrame,且2个DataFrame的列名是一样的,也就是存在键连接的,但是如果不存在键连接,那就不能用merge进行合并了,该怎么办呢?
我们可以使用concat()函数来实现数据的合并。
案例2:利用concat()合并数据
concat()函数格式:👇
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, sort=False, copy=True)
# 看起来很复杂,其实一点也不简单o(╥﹏╥)o,我们在案例中学习常用的搭配,详细参数如下:
# objs:合并对象,可以是DataFrame、Series或其他可迭代对象
# axis:合并轴,默认为0,即纵轴,可选值为0、1
# join:合并方式,默认为outer,即外连接,可选值为inner、outer
# join_axes:合并轴,默认为None,如果指定了join_axes,则根据指定的轴合并
# ignore_index:是否忽略索引,默认为False,如果为True,则忽略索引
# keys:合并键,默认为None
# levels:合并级别,默认为None
# names:合并名称,默认为None
# verify_integrity:是否验证完整性,默认为False
# sort:是否排序,默认为False
# copy:是否复制,默认为True
看到这个 不用慌,我们通过案例来学习几个常用的搭配就可以啦! O(∩_∩)O~存在2个Series,需要连接,效果如下:
# 导入pandas库
import pandas as pd
# 创建第一个Series
# 数据:[0, 1]
# 索引:['a', 'b']
s1 = pd.Series([0, 1], index=['a', 'b'])
# 创建第二个Series
# 数据:[2, 3, 4]
# 索引:['a', 'd', 'e']
s2 = pd.Series([2, 3, 4], index=['a', 'd', 'e'])
# 创建第三个Series
# 数据:[5, 6]
# 索引:['f', 'g']
s3 = pd.Series([5, 6], index=['f', 'g'])
print("合并前:")
print(s1)
print(s2)
print(s3)
# 使用pd.concat()函数将三个Series按行方向合并
# 合并时会保留所有原始索引
combined_series = pd.concat([s1, s2, s3])
# 打印合并后的结果
print("合并后的Series:")
print(combined_series)
上面是2个Series,下面是2个DataFrame,效果如下:

import pandas as pd
# 创建第一个DataFrame
# 使用numpy的arange函数生成0-5的整数,reshape为2行3列
# 列名为'a','b','c'
data1 = pd.DataFrame(np.arange(6).reshape(2,3), columns=list('abc'))
# 创建第二个DataFrame
# 生成20-25的整数,reshape为2行3列
# 列名为'a','y','z'
data2 = pd.DataFrame(np.arange(20,26).reshape(2,3), columns=list('ayz'))
# 使用pd.concat按行方向(axis=0)合并两个DataFrame
# 合并时会自动对齐相同列名的列,不同列名的列会被保留
data = pd.concat([data1, data2], axis=0,sort=True)
# 显示三个DataFrame
print("DataFrame data1:")
display(data1)
print("\nDataFrame data2:")
display(data2)
print("\n合并后的DataFrame data:")
display(data)
案例3:利用combine_first()合并数据
如果需要合并的2个DataFrame存在相同的列名,也就是存在重复的索引,那么上面学的2个函数就不能用了,这个时候就需要用到combine_first()函数了,案例如下: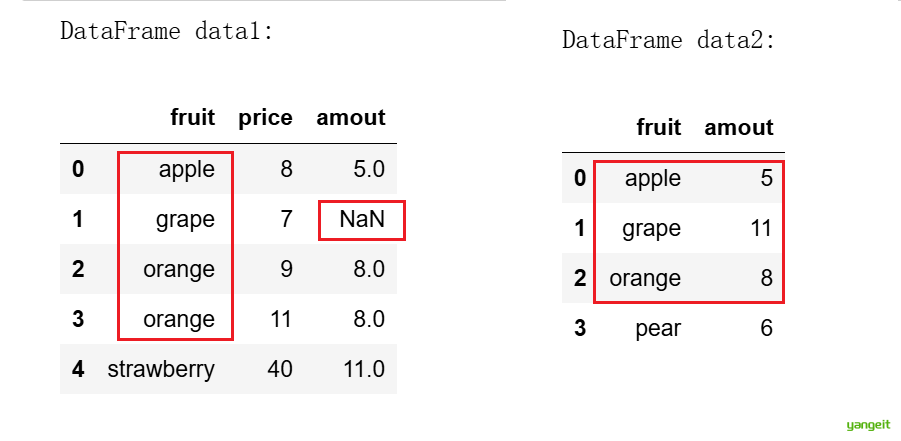
代码如下:👇
import pandas as pd
# 创建第一个DataFrame
data1 = pd.DataFrame({'fruit':['apple','grape','orange','orange','strawberry'],'price':[8,7,9,11,40],'amout':[5,NA,8,8,11]})
# 创建第二个DataFrame
data2 = pd.DataFrame({'fruit':['apple','grape','orange','pear'],'amout':[5,11,8,6]})
# 使用pd.concat按行方向(axis=0)合并两个DataFrame,这是简单的垂直堆叠,保留所有行会保留所有数据,包括 pear不同列会用NaN填充
data = pd.concat([data1, data2], axis=0,sort=True)
# 使用combine_first()函数合并两个DataFrame,效果如下图
data3 = data1.combine_first(data2) # 这不是用来合并不同结构的DataFrame的 它是用来用另一个DataFrame填充当前DataFrame中的缺失值,它不会新增行,只会新增列
#使用merge()函数合并两个DataFrame
data4 = pd.merge(data1,data2,how='outer')
# 显示3个DataFrame
print("DataFrame data1:")
display(data1)
print("\nDataFrame data2:")
display(data2)
print("\n concat合并后的DataFrame data:")
display(data)
print("\n merge合并后的DataFrame data:")
display(data4)
print("\n combine_first合并后的DataFrame data:")
display(data3)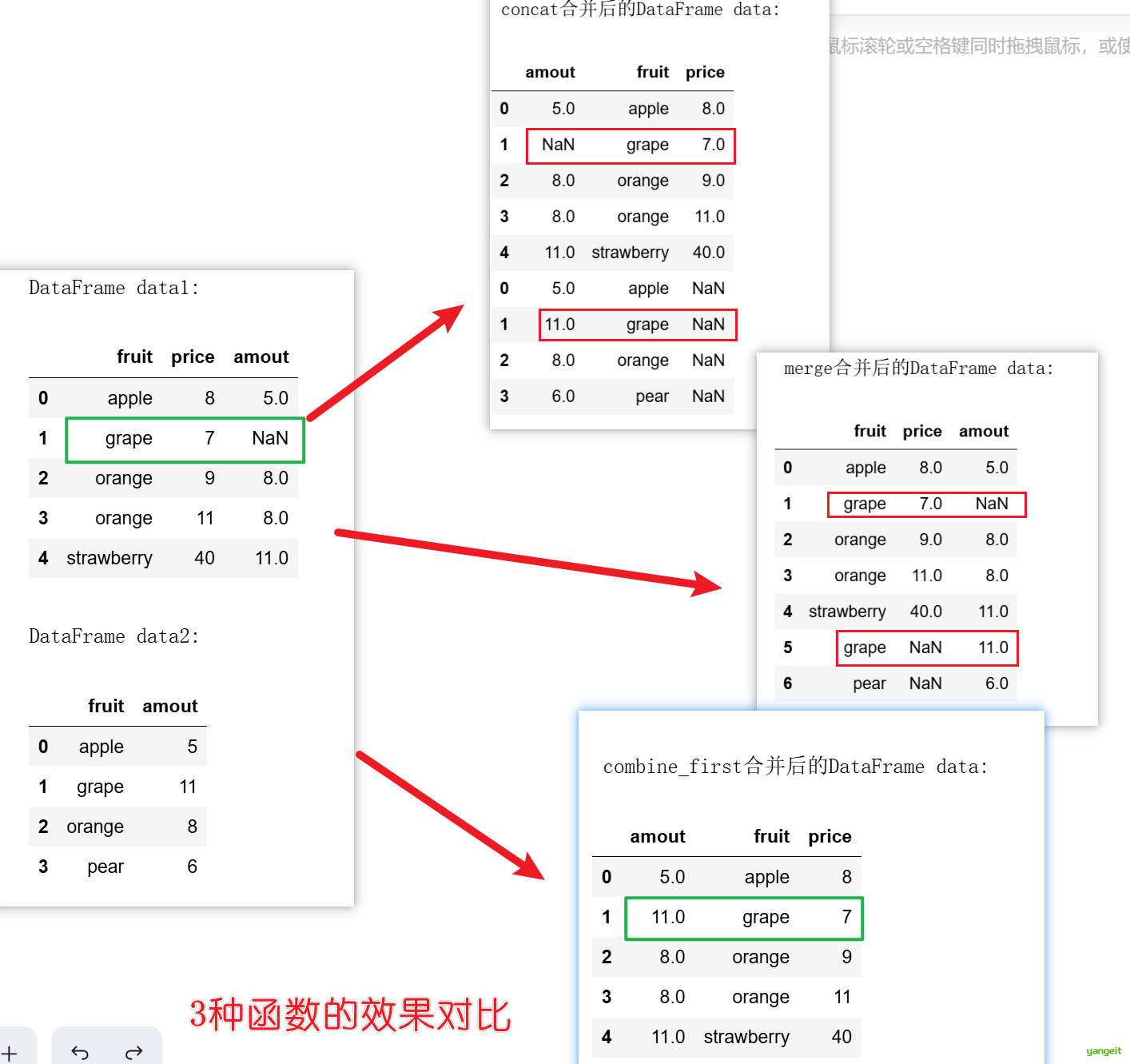
总结
课堂作业
- 开始练习吧!!🎤
- 在jupyter中,完成上述案例,了解数据合并的基本操作
6.数据标准化
前言
数据标准化(归一化)
为什么要进行数据标准化和归一化?
- 样本不同的特征属性所在的数值范围差异巨大,导致训练不收敛或其他问题
- 所有数据在相同的取值空间更容易处理,方便模型的统一化和规范化
- 更容易发现数据的本质规律
数据的归一化
归一化是将数据映射到[0,1]区间。
归一化的计算方法:x=(x-min)/(max-min),其中x为原始数据,min为最小值,max为最大值。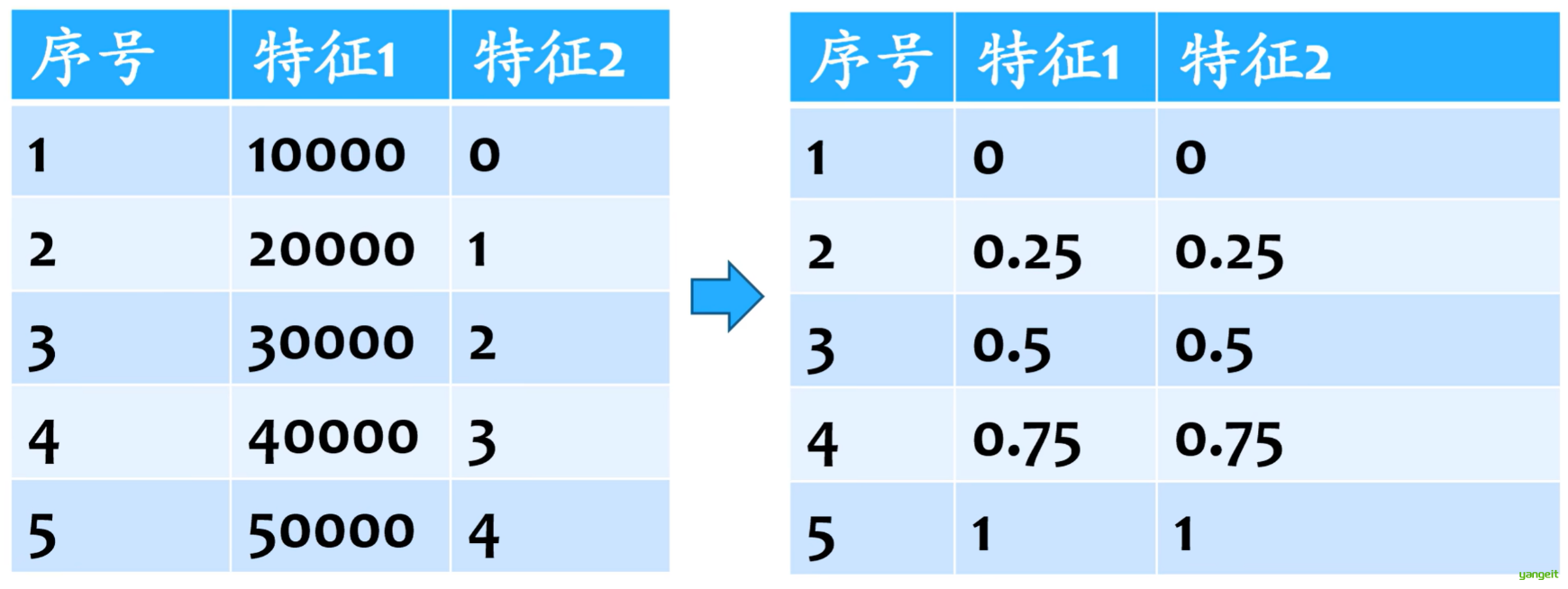
数据的标准化
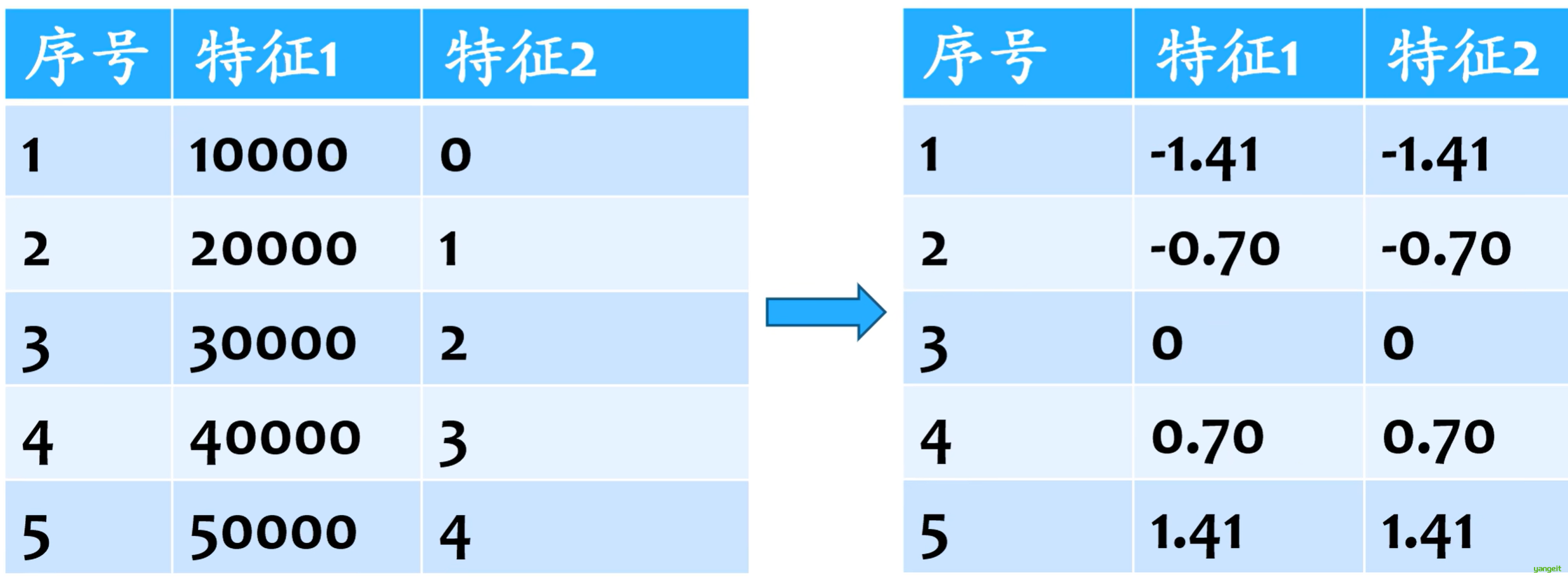
数据的标准化就是将数据转换到0值附近,标准差为1的区间。
标准化的计算方法:x=(x-mean)/std,其中x为原始数据,mean为均值,std为标准差。
在机器学习中,2者其实是等价的,因为机器学习中,很多模型都需要距离计算,如KNN、PCA等,而距离计算的本质是欧式距离。
数据归一化/标准化的目的是为了获得某种“无关性”,如偏置无关、尺度无关、长度无关等。当归一化/标准化方法背后的物理意义和几何含义与当前问题的需要相契合时,则会对解决该问题有正向作用,反之,会起反作用。因此,如何选择标准化方法取决于待解决的问题。
一般来说,涉及或隐含距离计算 以及损失函数中含有正则项的算法,比如K-means、KNN、PCA、SVM等,需要进行数据标准化,距离计算无关的概率模型和树模型,如朴素贝叶斯、决策树和随机森林等,则不需要进行数据标准化。
总结
课堂作业
- 数据归一化和标准化有什么区别?
- 为什么要进行数据归一化和标准化?
- 在jupyter中,完成上述案例,了解数据标准化的基本操作