
数据仓库与数据挖掘-第一章节
通过本课的学习,学生应该掌握如下知识:
🍐 理解 # ❤️ 重点 # ✏️ 动手操作 #🚀 了解
1.数据仓库
2.数据挖掘
5.Anaconda平台 ✏️ ❤️
6.Jupyter Notebook ✏️ ❤️
第二章 认识数据
1.认识数据
2.数据可视化
3.数据对象的相似性度量
第一章 绪论
1.数据仓库
数据仓库概要
1. 数据仓库(Data Warehouse)技术是为了有效地把 操作型数据 集成到统一的环境 中以提供决策型数据访问的各种技术和模块的总称。 🍐
其目的是构建面向分析的集成化数据环境,为企业提供决策支持。

被誉为数据仓库之父的美国著名信息工程学家William H.Inmon 将数据仓库定义为:
一个面向主题(subject oriented)的、集成(integrated)的、随时间变化(time variant)的、但信息本身相对稳定(non-volatile)的数据集合,用于对管理决策过程的支持。
操作型数据是指在企业日常运营过程中实时产生、用于支持业务操作和事务处理的数据。这类数据通常来自业务系统(如ERP、CRM、交易系统)
2. 数据仓库的四个核心特征:🍐 ❤️
面向主题(Subject-Oriented)
数据仓库围绕业务主题(如客户、销售、产品等)组织数据 ,而非围绕业务流程或操作功能。这种设计支持针对特定主题的分析和决策,与事务型数据库的流程导向形成对比。
事务型数据库稍后会讲解 👇
集成性(Integrated)
数据仓库通过整合来自多个异构源系统(如ERP、CRM等)的数据,消除命名、格式或计量单位的不一致性,确保数据的一致性和全局视角。例如,统一“性别”字段的编码为“M/F”或“0/1”。
非易失性(Non-Volatile)
数据一旦进入仓库,通常不会被修改或删除,仅支持批量加载和查询操作。这一特性保障了历史数据的稳定性,便于追踪变化和分析长期趋势。
时变性(Time-Variant)
数据仓库存储历史数据并记录时间维度(如按日、月、年等),支持时间序列分析。用户可以查询过去某一时点的数据状态,而事务系统通常仅维护当前数据。
总结 :这四个特征共同使数据仓库成为 面向分析的历史数据存储系统,适用于复杂的业务智能场景,与高频事务处理的OLTP系统形成互补(如下图 👇)。
3. 数据仓库和操作性数据库的关系 🍐 ❤️
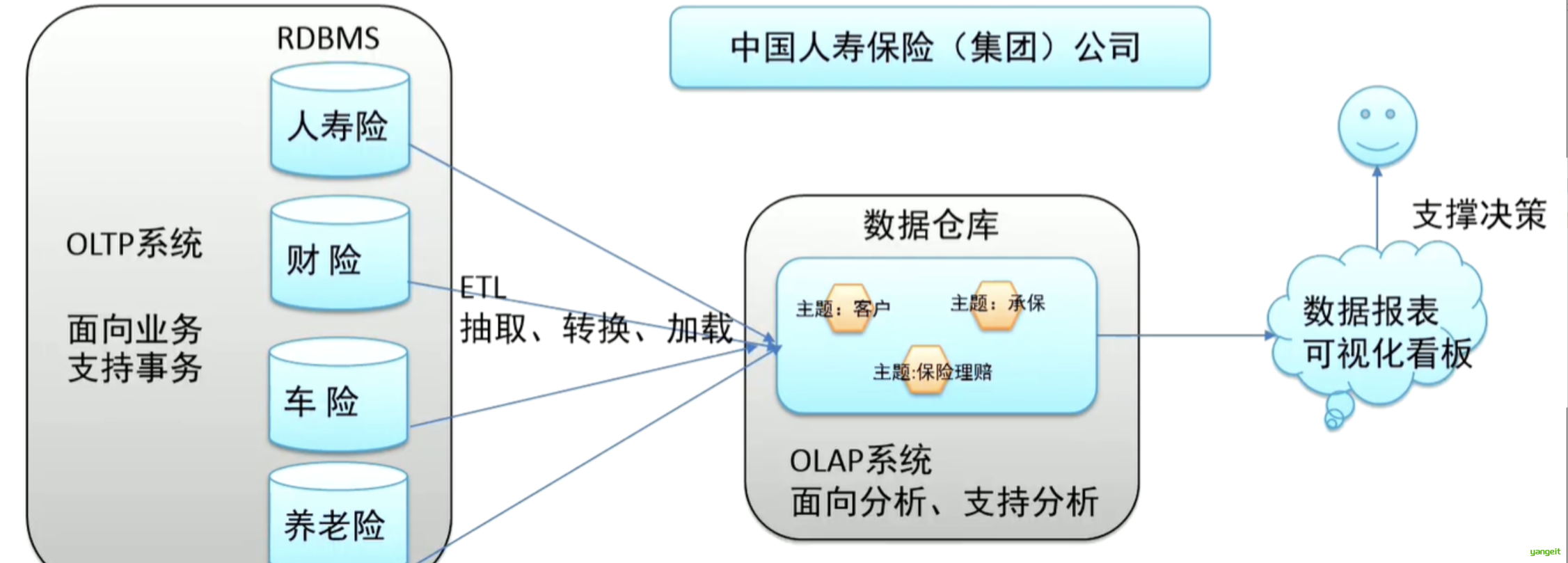
ETL(Extract-Transform-Load)是数据仓库的核心处理流程,指从数据源抽取数据,经过清洗转换后加载到目标系统的过程
数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
以银行业务为例。数据库是事务系统的数据平台,客户在银行做的每笔交易都会写入数据库,被记录下来,这里,可以简单地理解为用数据库记账。数据仓库是分析系统的数据平台,它从事务系统获取数据,并做汇总、加工,为决策者提供决策的依据。比如,某银行某分行一个月发生多少交易,该分行当前存款余额是多少。如果存款又多,消费交易又多,那么该地区就有必要设立ATM了
显然,银行的交易量是巨大的,通常以百万甚至千万次来计算。事务系统是实时的,这就要求时效性,客户存一笔钱需要几十秒是无法忍受的,这就要求数据库只能存储很短一段时间的数据。而分析系统是事后的,它要提供关注时间段内所有的有效数据。这些数据是海量的,汇总计算起来也要慢一些,但是,只要能够提供有效的分析数据就达到目的了。
3.1. OLTP(Online Transaction Processing,联机事务处理)
定义:OLTP是传统关系型数据库 的主要应用模式,用于支持日常业务的实时事务处理,如订单提交、支付交易、库存变更等。
核心用途:
- 处理高频、简单的事务操作(增删改查),确保数据的实时性和准确性。
- 支持业务流程的正常运转,如银行转账、电商下单、物流跟踪等。
- 保证事务的ACID特性(原子性、一致性、隔离性、持久性),避免数据异常。
3.2.OLAP(Online Analytical Processing,联机分析处理)
定义:OLAP是数据仓库 的核心应用模式,用于对大量历史数据进行复杂分析,支持决策制定,如销售趋势分析、用户行为挖掘等。
核心用途:
- 通过多维度分析(如时间、地域、产品)挖掘数据价值,生成统计报表或可视化结果。
- 支持业务决策,如市场策略调整、风险预测、营收目标制定等。
- 处理聚合计算(如求和、平均值、占比)和复杂查询,揭示数据背后的规律。
3.3.OLTP与OLAP的核心区别
| 对比维度 | OLTP(事务处理) | OLAP(分析处理) |
|---|---|---|
| 数据基础 | 以关系型数据库为基础 | 以数据仓库为基础 |
| 数据特性 | 细节性数据(原始业务记录) | 综合性数据(汇总、聚合后的数据) |
| 时间范围 | 当前数据(关注实时状态) | 历史数据(关注长期趋势) |
| 数据更新 | 高频增删改(实时更新) | 不更新但周期性刷新(批量加载) |
| 处理数据量 | 一次处理数据量小(单条/少量记录) | 一次处理数据量大(百万/亿级记录) |
| 响应时间 | 要求毫秒级响应(用户体验依赖速度) | 响应时间合理(分析耗时可接受) |
| 用户对象 | 操作人员(如客服、柜员) | 决策人员(如管理者、分析师) |
| 设计目标 | 面向应用,事务驱动(支持业务流程) | 面向分析,分析驱动(支持决策制定) |
3.数据仓库的组成 🍐
在讲解数据仓库的组成之前,我们先举个例子,方便理解!!!
典型场景示例:
当顾客想买"西红柿"时:
- 数据源:需要知道西红柿来自哪个农场(数据来源)
- 仓储管理:检查是否新鲜(数据清洗)、放在蔬菜区(分层存储)
- 分拣系统:提前打包成盒(预聚合)、放在显眼位置(查询优化)
- 销售终端:显示价格(报表)、推荐搭配菜品(分析应用)
这种类比帮助理解:数据仓库就像超市的"后勤大脑",让原始数据变成可用的"商品信息"。
好,理解了上述的流程,接下来,我们参考上述的流程,来讲解数据仓库的组成。
总结:
数据仓库的组成:
- 数据源:数据来源,包括业务数据库、日志文件、外部API、Excel/CSV等
- 数据存储与管理:ETL工具、数据仓库、数据湖、元数据管理
- OLAP服务器:预计算引擎、查询加速、语义层
- 前端工具与应用:数据分析工具、报表工具、查询工具、数据挖掘、定制应用
4.数据仓库的应用 🍐
应用场景:
"当电商平台通过客户分类识别出高价值用户后,可以通过市场自动化系统定向推送优惠券,同时决策支持系统会监控促销活动的投资回报率ROI表现
ROI = [(收益 - 成本)/成本] × 100%
5. 当前流行的基于分布式系统架构的数据仓库工具有Hive和SparkSQL:🍐
数据仓库是一种解决方案,在真正实现时,必须依赖于数据工具平台,目前主流的分布式系统架构有Hadoop和Spark,因此,基于分布式系统架构的数据仓库工具有Hive和SparkSQL。

| 对比项 | Hive | SparkSQL |
|---|---|---|
| 计算引擎 | 基于磁盘(MapReduce) | 基于内存(Spark Core) |
| 速度 | 慢(分钟级响应) | 快(秒级响应) |
| 实时性 | 仅支持批处理 | 支持实时+批处理 |
| 使用场景 | 超大规模离线分析 | 交互式查询+实时计算 |
| 学习成本 | SQL简单易用 | 需了解Spark生态 |
从长远看,Hive适合处理海量历史数据,进行数据多维度查询,SparkSQL适合需要快速响应的实时分析。
常见的组合方案:
ETL(Extract-Transform-Load)是数据仓库的核心处理流程,指从数据源抽取数据,经过清洗转换后加载到目标系统的过程
总结
课堂作业
- 给出下列英文缩写,并解释其含义
- OLAP ,ETL,OLTP,DW
- 从数据库发展到数据仓库原因是什么? 二者有哪些本质差别?
- 简述数据仓库的定义和特征
2.数据挖掘
数据挖掘
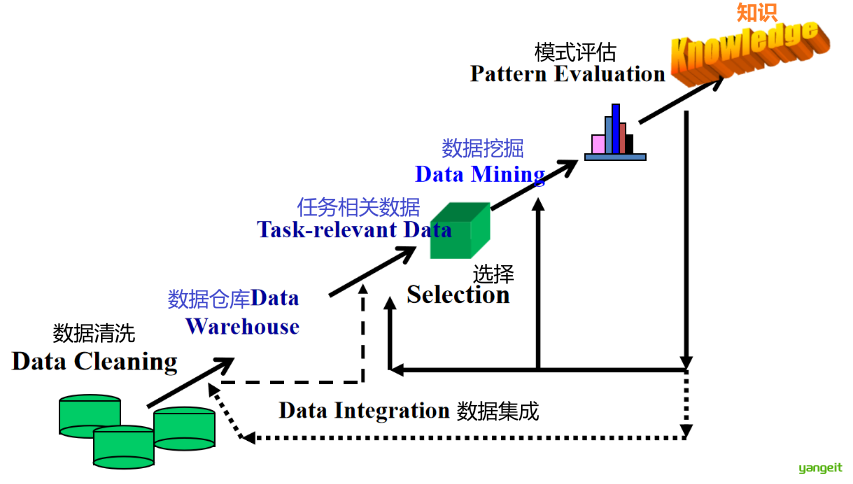
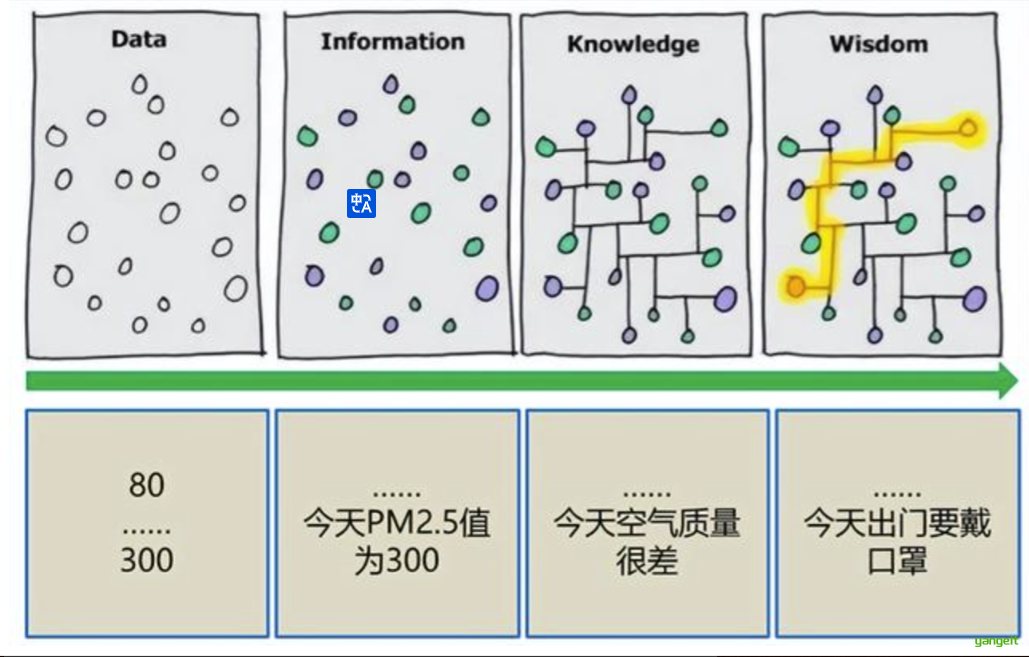
1. 知识和数据

We are drowning in data, but starving for knowledge! --- 我们淹没在数据中,却渴望知识!知识是人类对客观世界的观察和了解,是人类对客观世界是什么、为什么、应该怎么做的认知,知识推动人类的进步和发展。人类所作出的正确判断和决策,以及采取正确的行动都是基于智慧和知识。
数据是反映客观事物的数字、词语、声音和图像等,是可以进行计算加工的“原料”。数据是对客观事物的数量、属性、位置及其相互关系的抽象表示,适合于保存、传递和处理。
面对大量的数据,迫使人们不断寻找新的工具,对规律进行探索 ,为决策提供有价值的信息。
数据挖掘 有助于发现趋势,揭示已知的事实,预测未知的结果。
人们迫切希望能够对海量数据进行分析挖掘,发现并提取隐含在数据中的有价值信息。
解决方案: 🍐 ❤️
- 数据仓库(Data Warehouse)和在线分析处理(OLAP)--发生了什么?
- 数据挖掘—在大量数据中发现有用的知识、模式、规律、约束等---为什么发生?或 未来会怎样?
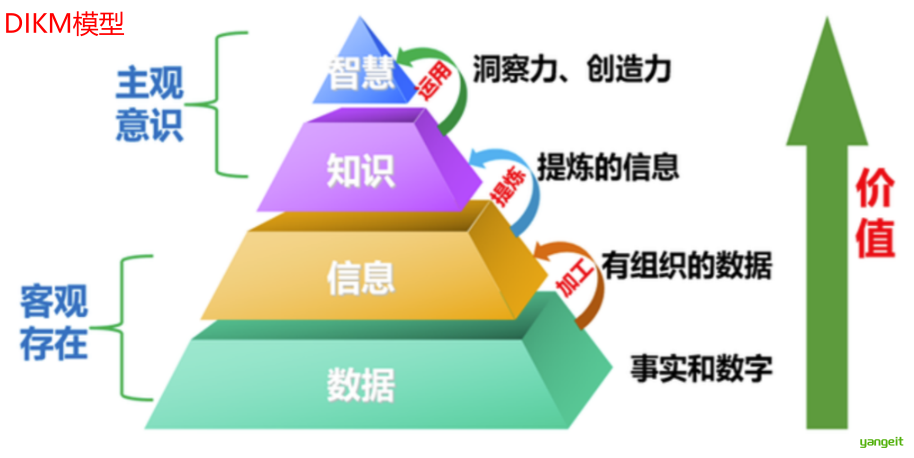
2.数据挖掘
2.1 定义
数据挖掘(Data Mining,DM),是从大量的、有噪声的、不完全的、模糊和随机的数据中,提取出隐含在其中的、人们事先不知道的、具有潜在利用价值的信息和知识的过程 。 🍐 ❤️
这个定义包含以下几层含义: 🍐 ❤️
- 数据源必须是真实的、大量的、含噪声的;
- 发现的是用户感兴趣的知识;
- 发现的知识要可接受、可理解、可运用;
- 不要求发现放之四海皆准的知识,仅支持特定的问题
2.2 数据挖掘和数据分析的区别:
在学习中,很容易将数据挖掘和数据分析混淆,其实它们是两个不同的概念,数据挖掘和数据分析的区别如下:
| 对比维度 | 数据挖掘 | 数据分析 |
|---|---|---|
| 目标 | 发现隐藏模式与未知规律 | 解释现状与验证假设 |
| 方法 | 机器学习/统计建模 | 描述性统计/可视化 |
| 输出 | 预测模型或关联规则 | 洞察报告或可视化图表 |
| 数据量 | 通常需要大数据量 | 小样本也可进行 |
| 自动化程度 | 高(算法自动学习) | 低(依赖人工解读) |
| 典型问题 | "未来会发生什么?" | "过去发生了什么?" |
典型场景示例
2.3 数据挖掘核心特征对照表
| 特征 | 数据挖掘示例 | 非数据挖掘对比示例 |
|---|---|---|
| 模式发现 | 发现"买奶粉的用户常买尿布" | 查询"尿布销量TOP10" |
| 预测性 | 预测下月客户流失率 | 统计上月客户流失人数 |
| 自动化 | 自动识别欺诈交易(算法) | 人工检查大额交易记录 |
快速判断口诀: 能直接查到的,人工定规则的,仅描述现状的 → 非挖掘; 要猜测未来的,是挖掘
3.数据挖掘的主要任务和数据源
数据挖掘是通过分析每个数据,从大量数据中寻找其规律的技术,知识挖掘的核心。
主要任务:关联分析,数据建模预测,聚类分析,离群点检测。
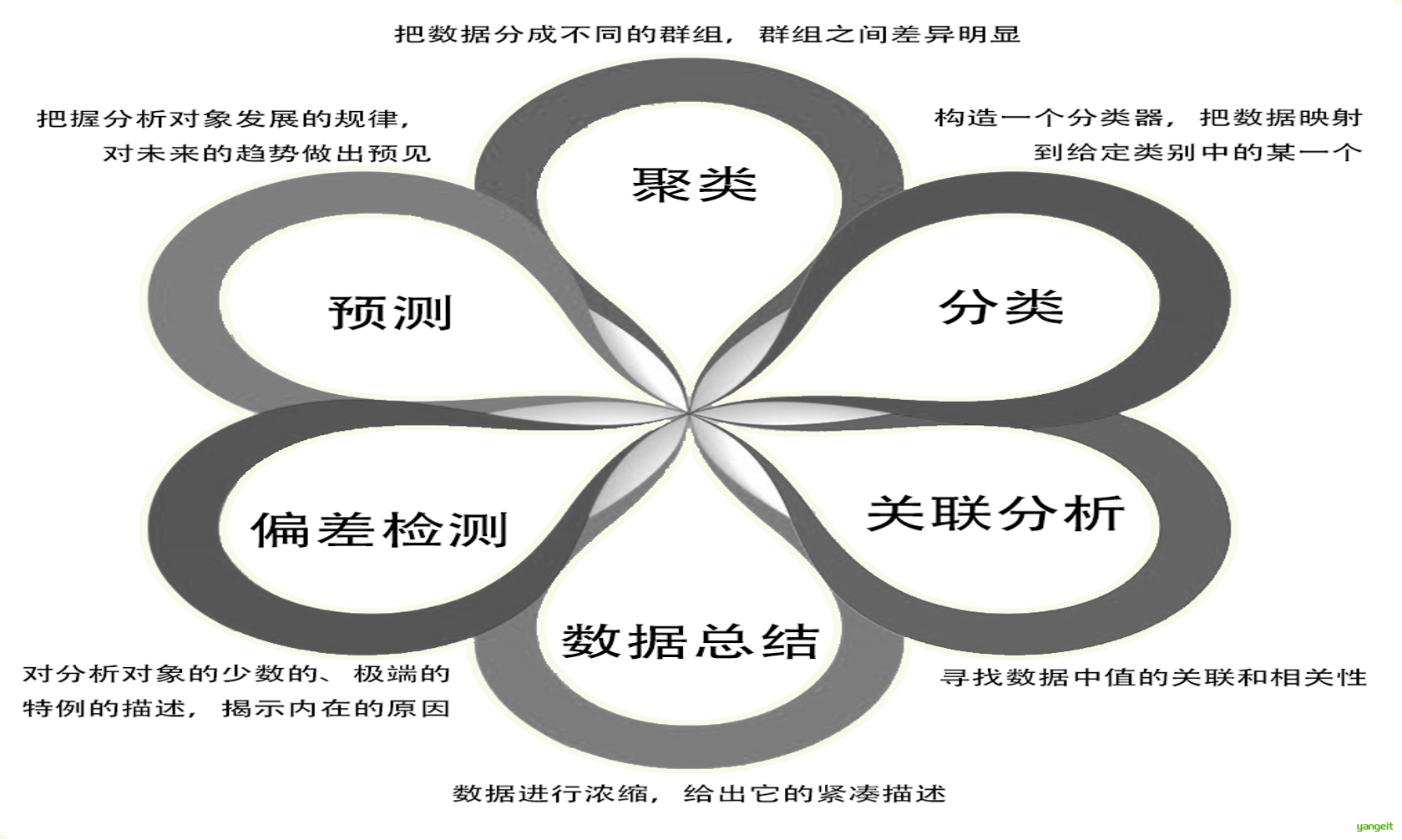
数据源:
- 关系型数据库、事务型数据库、面向对象的数据库
- 数据仓库/多维数据库
- 空间数据(如地图信息)
- 工程数据(如建筑、集成电路信息)
- 文本和多媒体数据(如文本、图像、音频、视频数据)
- 时间相关的数据(如历史数据或股票交换数据)
- 万维网(如半结构化的HTML、结构化的XML以及其他网络信息
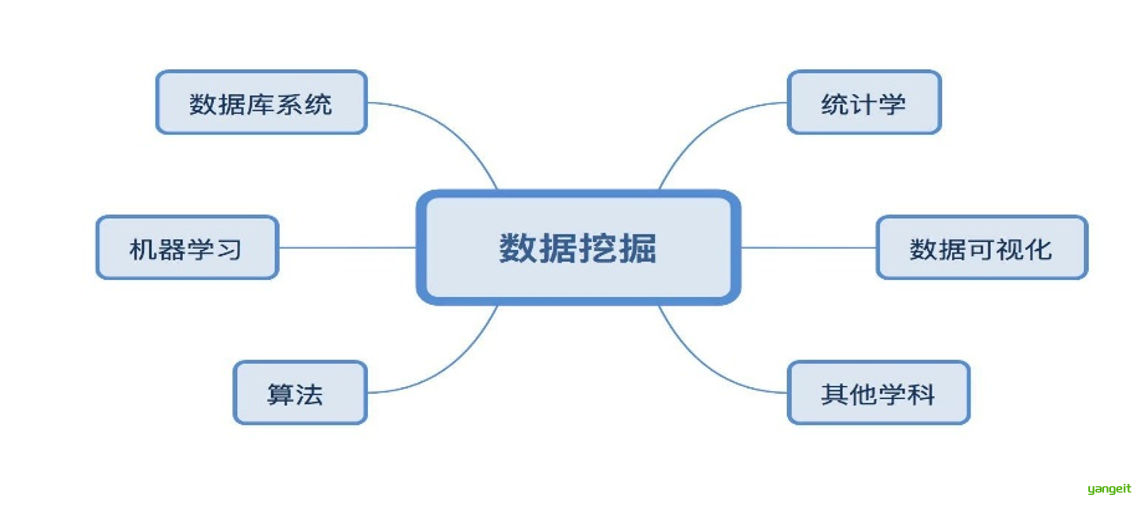
4.数据挖掘用到的技术 🚀
作为一个一个应用驱动的领域,数据挖掘吸纳了诸如统计学、机器学习、数据库、数据可视化等多个学科的知识,形成了自己的技术体系。
数据挖掘与机器学习有很多相似之处,但不同之处也十分明显
| 维度 | 数据挖掘 | 机器学习 | 共同点 |
|---|---|---|---|
| 核心目标 | 从数据中发现知识 | 构建预测/决策模型 | 均需数据驱动 |
| 数据要求 | 强调数据质量和适用性 | 更关注特征工程和样本量 | 依赖高质量数据 |
| 输出结果 | 可解释的规则/模式 | 高精度预测模型 | 均可用于决策支持 |
| 典型场景 | 购物篮分析、异常检测 | 图像识别、自然语言处理 | 用户分群、推荐系统 |
从某种意义上说,机器学习的科学成分更重一些,二数据挖掘的技术成分更中一些
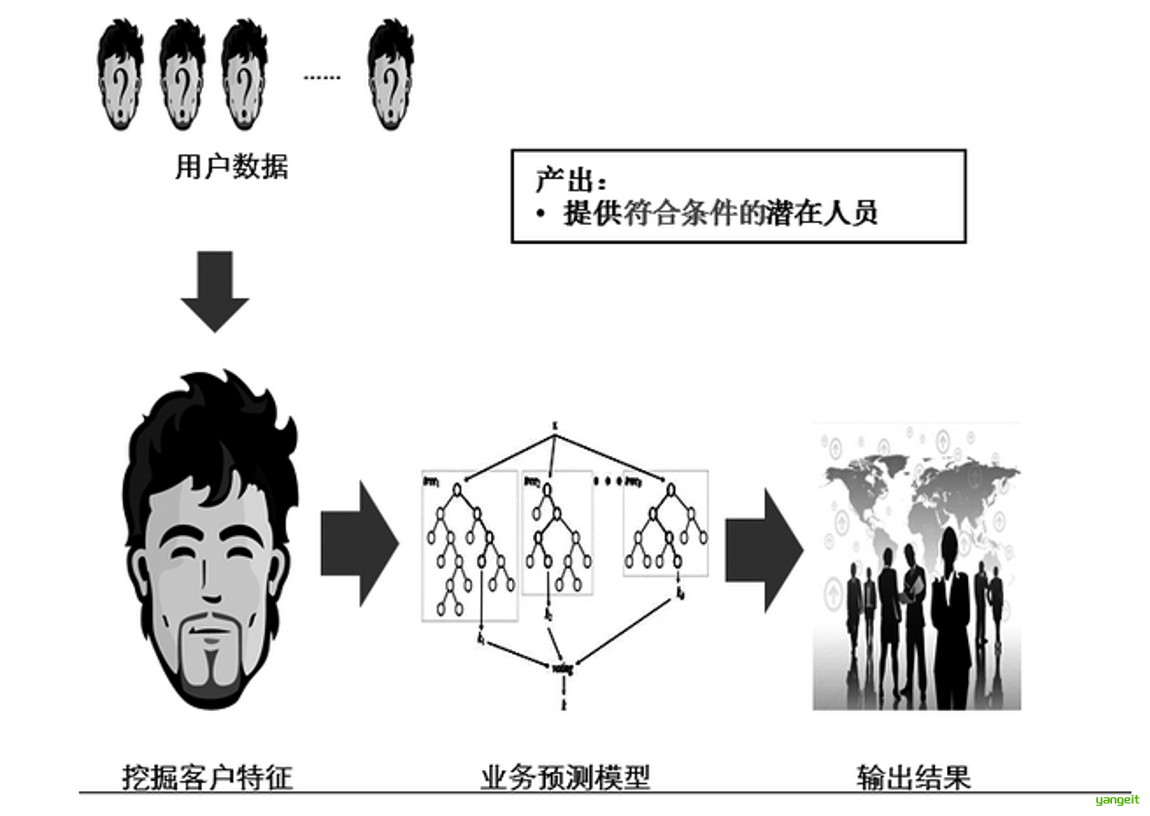
典型的数据挖掘与机器学习过程 👇
一个典型的推荐类应用,需要找到“符合条件”的潜在人员。首先需要挖掘客户特征,然后选择一个合适的模型来进行预测(机器学习),最后从用户数据中得出结果。
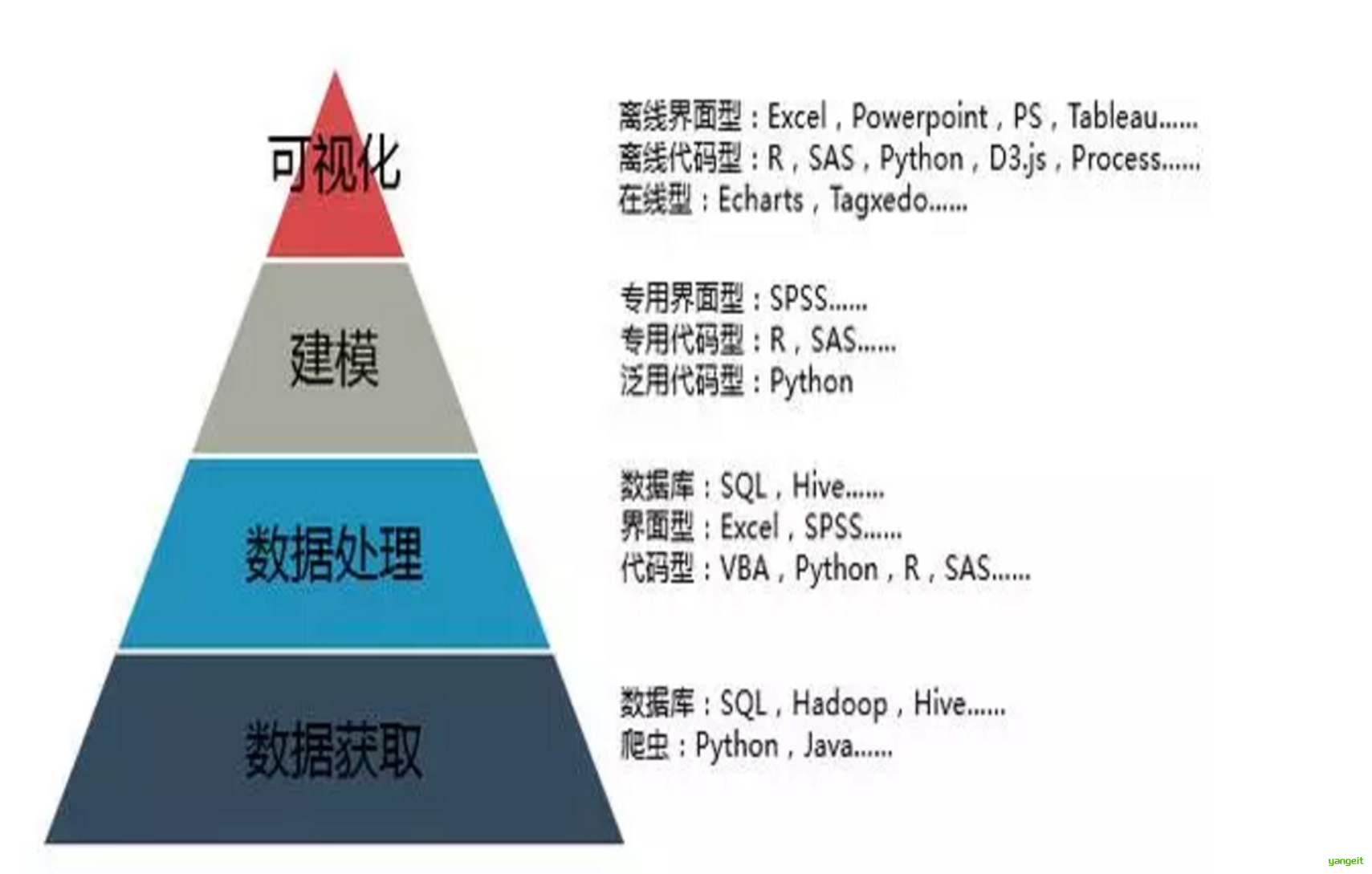
5. 数据挖掘用到的技术以及常用的Python技术库 🚀
- 商用工具
商用工具主要由商用的开发商提供,通过市场销售,提供相关的服务。与开源软件相比,商用软件更强大、软件性能更加成熟稳定。主要的商用数据挖掘工具有SAS Enterprise Miner、SPSS Clementine和IBM Intelligent Miner等。 - 开源工具
开源软件的最大优势在于免费,而且让任何有能力的人参与并完善软件。相对于商用工具,开源软件工具更容易学习和掌握。常用的开源工具有R语言、Python、Weka和RapidMiner等。
Python的第三方模块很丰富,而且语法非常简练,自由度很高。

6. 数据仓库与数据挖掘的区别与联系 🍐❤️
| 维度 | 数据仓库(Data Warehouse) | 数据挖掘(Data Mining) |
|---|---|---|
| 定义 | 面向主题的、集成的、稳定的、时变的数据集合,用于支持决策分析。 | 从大规模数据中提取隐含的、未知的、潜在有用的模式或知识。 |
| 核心目标 | 存储和管理历史数据,提供高效的查询和分析环境。 | 发现数据中的规律,用于预测、分类或描述。 |
| 主要功能 | 数据整合、ETL、OLAP分析、历史数据存储。 | 模式识别、预测建模、关联规则挖掘。 |
| 技术栈 | ETL工具(Informatica)、OLAP引擎、SQL、列式存储。 | 机器学习算法(决策树、神经网络)、Python/R、统计模型。 |
| 数据输出 | 结构化报表、聚合指标(如销售额趋势)。 | 预测结果(如用户流失概率)、聚类分组、关联规则(A→B)。 |
| 应用场景 | - 生成月度报表 - 监控KPI(DAU、GMV) | - 预测客户流失 - 购物篮分析(啤酒+尿布) |
| 决策支持 | 回答“发生了什么”(描述性分析)。 | 回答“为什么发生”或“未来会怎样”(预测性/诊断性分析)。 |
| 数据粒度 | 存储明细数据和聚合结果。 | 处理明细数据,输出模型或规则。 |
| 时效性 | 侧重历史数据(T+1或实时)。 | 可处理实时流数据(如风控场景)。 |
| 用户角色 | 数据分析师、BI工程师。 | 数据科学家、机器学习工程师。 |
| 类比 | 图书馆:分类存储书籍,提供索引查询。 | 研究员:从书籍中提炼新理论(如经济危机周期)。 |
零售行业示例:
超市通过分析购物小票数据,发现周五晚上购买尿不湿的年轻父亲群体中,啤酒购买率异常高。

4.数据挖掘的面临的主要问题:🍐
| 问题类型 | 具体表现 | 典型案例 | 应对策略 |
|---|---|---|---|
| 数据类型多样化 | 结构化/非结构化数据混合,相同类型数据字段差异大 | 电商数据包含表格订单和客服语音记录 | 建立统一数据湖(如下图) |
| 噪声数据 | 数据缺失率>30%,字段值异常(如年龄=200),数据采集时间不一致 | 传感器数据丢失,用户画像数据过期 | 数据质量监控体系,基于上下文的填充算法 |
| 高维度数据 | 特征维度超过10万维(如文本特征),传统算法性能急剧下降 | 自然语言处理中的词向量特征 | 特征选择(卡方检验)+ 降维 |
| 可视化挑战 | 多维关系难以在2D平面展示,聚类结果等复杂模式不易解释 | 用户分群结果需要向业务部门直观展示 | 交互式可视化工具,降维投影技术 |
拓展:👇
数据湖
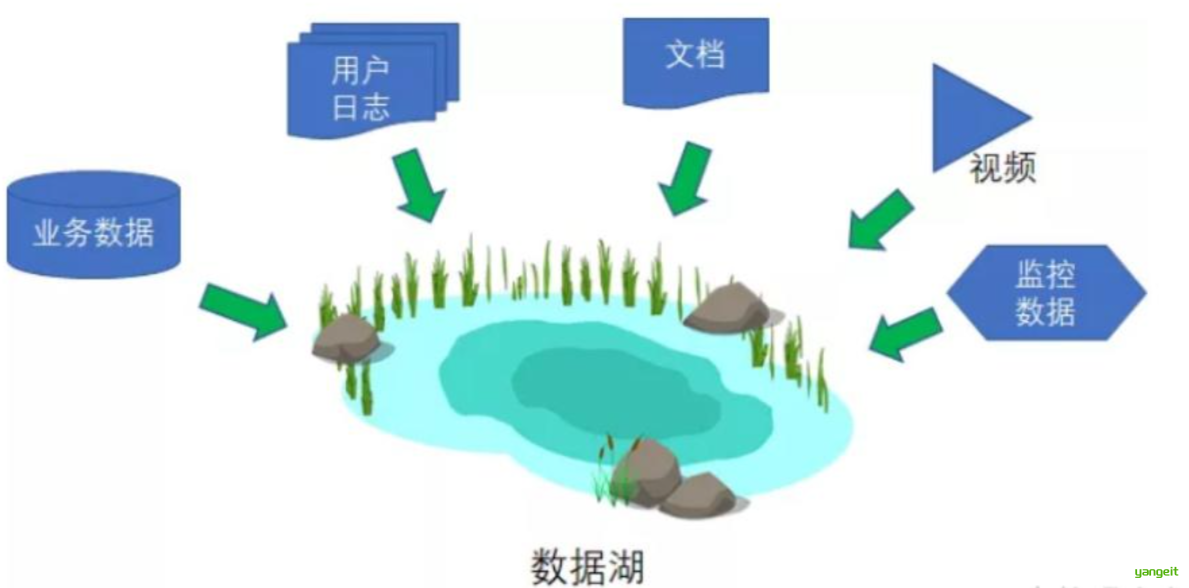
什么是高维度数据
| 场景 | 维度数量 | 具体表现 |
|---|---|---|
| 身高 | 1维 | 单一数值特征(如身高数值) |
| 用户画像 | 20维 | demographic + 行为基础标签 |
| 电商推荐 | 500维 | 点击/购买历史 + SKU特征 |
| 自然语言NLP处理 | 10万维 | 词汇表级别的one-hot编码 |
卡方检验是一种用于判断两个分类变量之间是否存在显著关联性的统计方法
降维投影案例:电商平台用t-SNE将用户1000维行为数据降维到2D平面,发现5个高潜力客群,精准优化了推荐策略。
总结
课堂作业
- 简述数据挖掘的主要步骤?
- 简述数据挖掘的主要任务
- 简述数据挖掘,机器学习的关系?
- 简述数据挖掘常用的数据源有哪些?
- 简述数据挖掘与数据仓库的区别?
- 简述数据挖掘面临的主要问题?
3.Anaconda平台 ✏️
Anaconda平台
1. 为什么选择Anaconda平台?
作为一名有着多年Python开发经验的程序员,曾因环境配置问题浪费了无数时间。直到遇见Anaconda,这些烦恼才终于得到解决。Anaconda是什么?简单来说,它是一个开源的Python发行版,专为科学计算和数据分析设计,已经成为数据科学工作者的必备工具。
选择Anaconda的核心理由:
- 一站式解决方案:预装了数百个常用科学计算库和工具
- 优秀的包管理功能:conda命令可以轻松安装、更新和管理各种包
- 完善的环境隔离:为不同项目创建独立的虚拟环境,避免依赖冲突
- 跨平台兼容:Windows、MacOS和Linux系统均可使用
- 图形界面支持:提供Anaconda Navigator可视化管理工具,适合新手使用
无论你是科学计算入门者,还是机器学习研究者,Anaconda都能极大提升你的开发效率。接下来,让我们一步步完成Anaconda的安装与配置。
2. 准备工作
在开始安装之前,先检查是否已经安装了Anaconda。打开命令行窗口,输入以下命令:
conda --version如果显示版本号,说明已经安装了Anaconda。如果没有安装,可以参考以下步骤进行安装。
👇 👇 👇👇
在开始安装前,请确保你的系统满足以下基本要求:
磁盘空间:至少5GB可用空间(完整安装后约3GB,使用过程中会增长)
系统要求:
- Windows: Windows 8.1或更高版本(64位)
- MacOS: 10.13+(推荐12.0+)
- Linux: 包括Ubuntu、CentOS、RHEL等主流发行版
温馨提示:安装前最好临时关闭杀毒软件,某些杀毒软件可能会干扰安装过程。另外,确保你有稳定的网络连接或使用本文提供的离线安装包。
3. 安装包下载
Anaconda的安装包可以从Anaconda官网下载,https://www.anaconda.com/products/distribution
也可以从清华镜像站下载,https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/

本课程使用 Anaconda3-5.3.1-Windows-x86_64.exe. 最新版本也可以!!
4. 安装Anaconda
右击用管理员身份运行安装包,进入安装向导,按照提示完成安装即可。安装过程中,需要选择安装路径,建议选择默认路径,避免后续出现环境变量问题。
安装步骤:
右击用管理员身份运行安装包
欢迎界面,点击Next,进入许可协议,点击同意
选择安装类型All User (推荐),点击Next
选择安装路径,强烈建议不要安装在C盘! , 我安装在
D:\javasoftware\Anaconda3非中文目录下,点击Next进入高级选项设置
- 【Add Anaconda to my PATH environment variable】:是否添加到系统环境变量--如果从来没有安装过Python,建议勾选,否则不勾选
- 【Register Anaconda as my default Python】:是否注册为默认Python环境--勾选
点击Install,等待安装完成,直到Finsh

验证是否安装成功
打开Anaconda Prompt,输入
conda --version,如果出现版本号,说明安装成功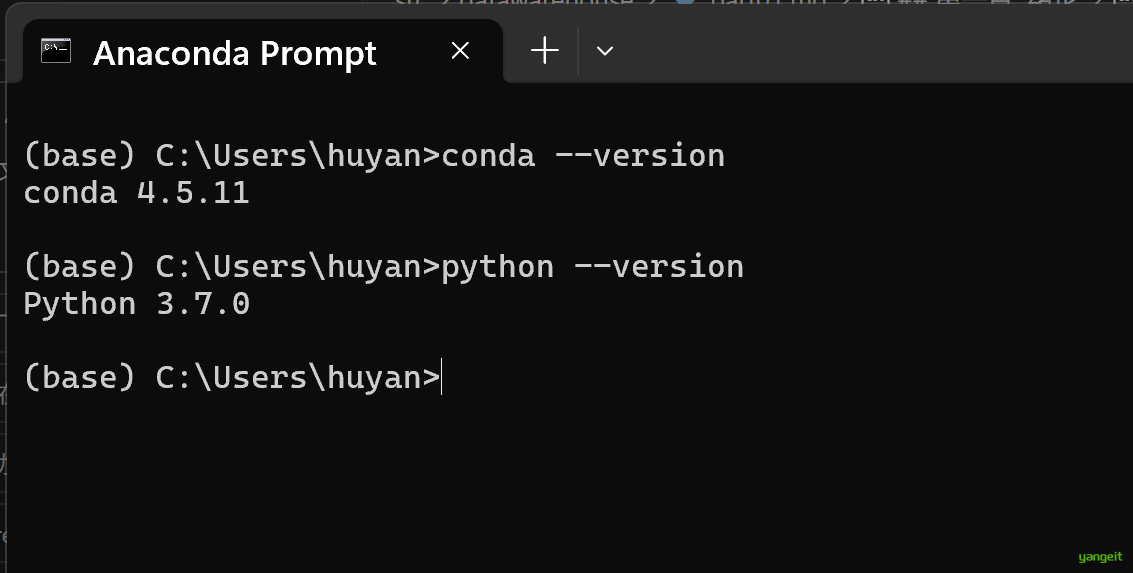
如果出现了
command not found,说明需要配置环境变量- 按下Win + R组合键,输入sysdm.cpl并回车(或者右键点击"此电脑"→"属性"→"高级系统设置")进入系统环境变量设置(如图1)
- 添加Anaconda相关路径到Path下,点击确定,保存。
- 重新打开Anaconda Prompt,输入
conda --version,如果出现版本号,说明安装成功 - 如果仍然出现了
command not found,举手问焱哥。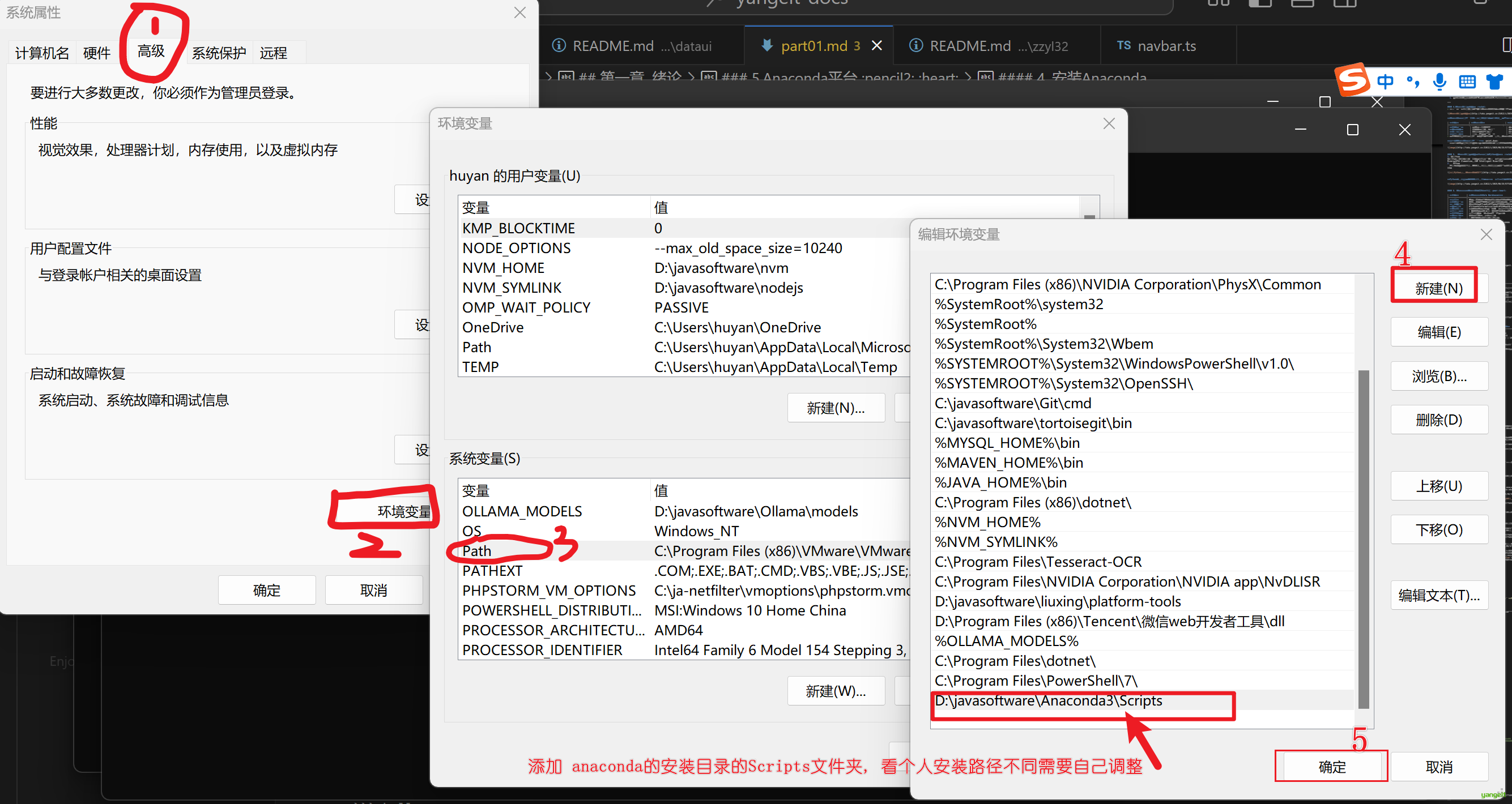
5. Anaconda 基础使用入门
1. Anaconda的两种使用方式
- 命令行界面(CLI)

通过命令提示符/终端使用conda命令进行操作:
打开命令提示符(Windows)或终端(MacOS/Linux)
直接输入conda命令,例如:
conda --version
conda list
小贴士:Windows用户还可以使用"Anaconda Prompt",这是一个预配置好环境变量的命令行工具,无需手动配置环境变量即可使用。在开始菜单中找到并启动它。- Anaconda Navigator图形界面
对于不熟悉命令行的用户,Anaconda Navigator提供了友好的图形界面:
在开始菜单/应用程序中找到并启动"Anaconda Navigator"
通过界面可以轻松管理环境、安装包和启动应用程序
启动Navigator的命令行方式:
anaconda-navigator2. 首次使用检查
无论使用哪种方式,首次使用时建议执行以下检查:
检查版本信息
conda --version
python --version查看已安装的包
conda list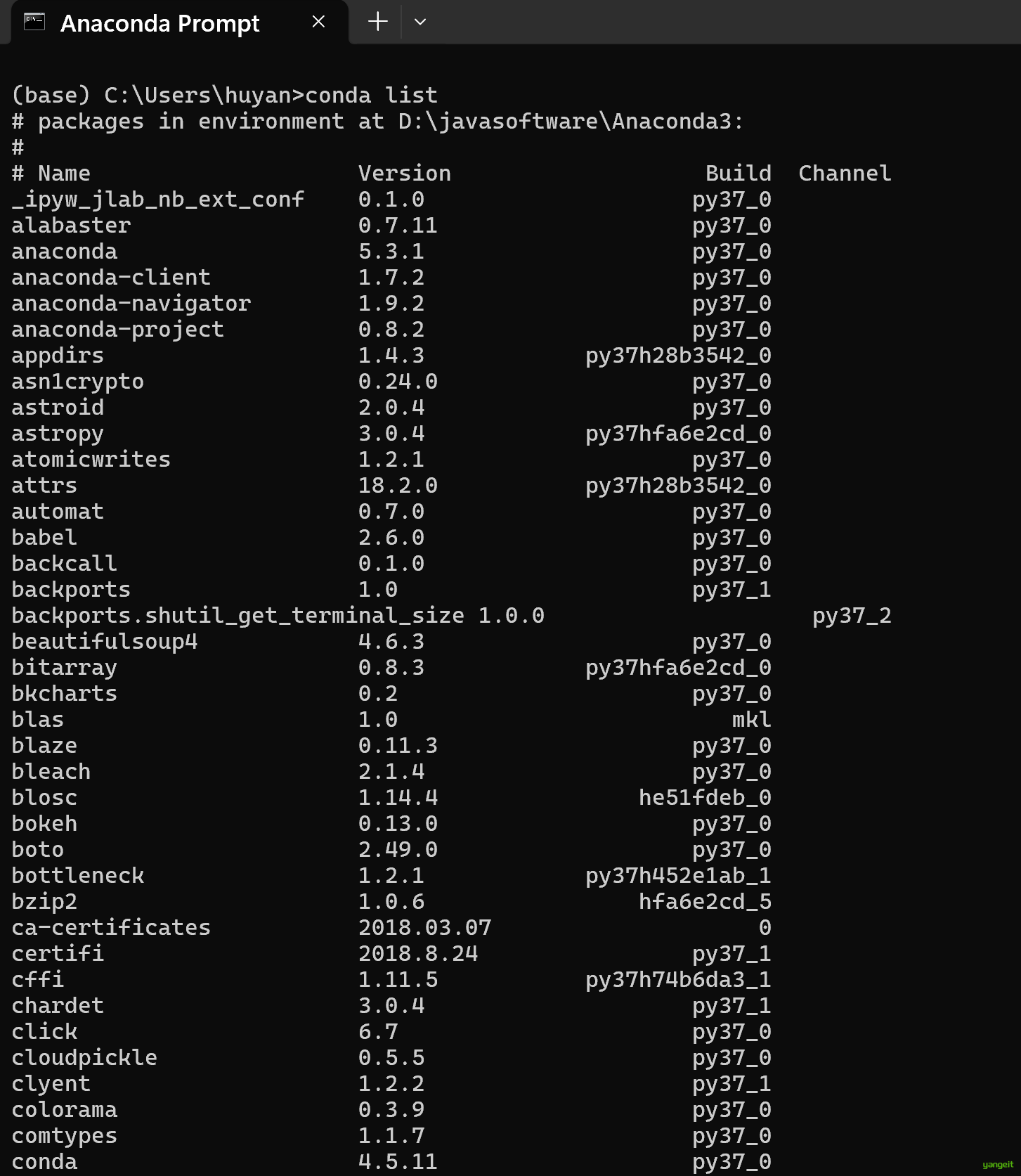
可以发现常见的数据挖掘用到的 numpy、scipy,pandas、matplotlib、statsmodels、scikit-learn等包已经安装了
检查Anaconda是否需要更新(一般不用更新)
conda update conda如果有更新,输入y确认更新。
3. 创建虚拟环境(可选)
在实际使用过程中,我们可能需要同时安装多个版本的Python,或者安装多个Python包,为了方便管理,我们可以创建多个虚拟环境。
conda create --name yangeit python=3.11解释:
conda create:创建新环境的命令--name yangeit:为新环境指定名称为yangeitpython=3.11:指定新环境的Python版本为3.11

激活虚拟环境
conda activate yangeit
# 然后输入python --version,可以看到已经切换到yangeit环境了
python --version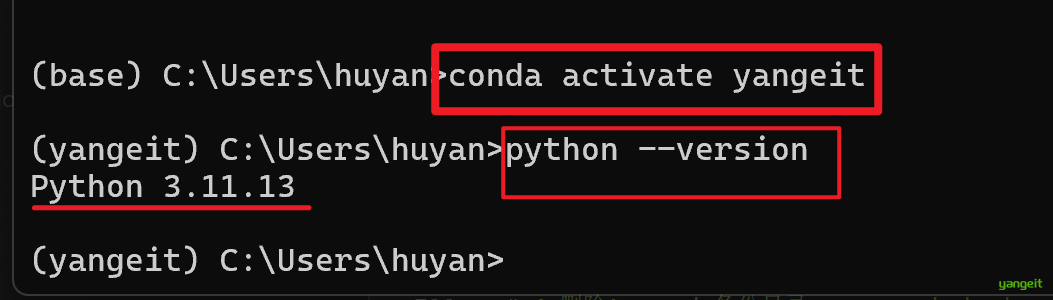
查看已经存在的环境
conda env list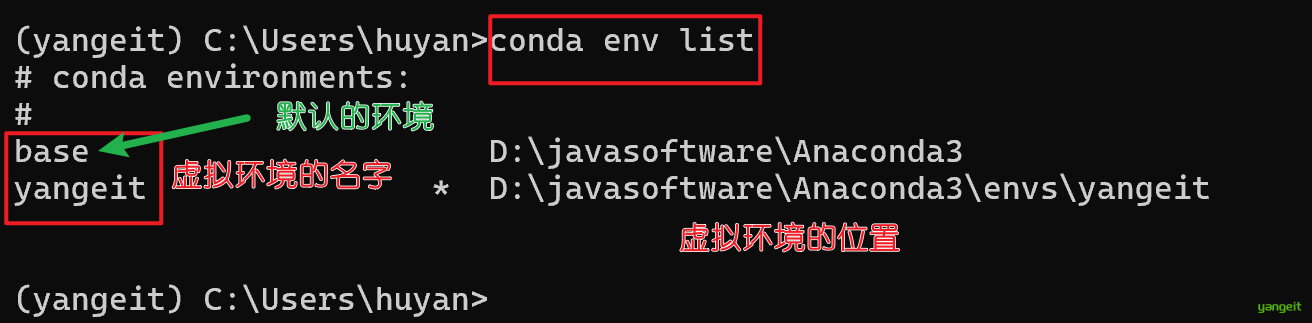
默认使用base环境,本课程使用的是默认的base环境
4. 配置下载源,加速下载
首先,打开Anaconda Prompt,输入以下命令:
# 添加Anaconda官方镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2/
# 添加PyTorch专属镜像(避免下载PyTorch时速度慢)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
# 添加NVIDIA相关镜像(加速CUDA工具包下载)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/nvidia/
# 添加conda-forge社区镜像(包含大量第三方库)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
# 设置搜索时显示通道地址(可选,方便确认是否使用了国内镜像)
conda config --set show_channel_urls yes验证 conda 镜像:
conda config --show channels接着配置pip下载源,配置 pip 国内镜像:
在Anaconda Prompt中执行以下命令,生成配置文件并添加镜像:
# 创建pip配置目录(Windows专用)
mkdir %APPDATA%\pip
# 生成pip配置文件并写入国内镜像
echo [global] > %APPDATA%\pip\pip.ini
echo index-url = https://pypi.tuna.tsinghua.edu.cn/simple/ >> %APPDATA%\pip\pip.ini
echo [install] >> %APPDATA%\pip\pip.ini
echo trusted-host = pypi.tuna.tsinghua.edu.cn >> %APPDATA%\pip\pip.ini接着,执行以下命令,pip config list,若输出global.index-url=pypi.tuna.tsinghua.edu.cn则表示配置成功。
5.卸载Anaconda(可选)
如果卸载,按照下面的指令
# 1.打开 Anaconda Prompt
# 2.安装 anaconda- clean 包
conda install anaconda-clean
# 3.运行 anaconda-clean
anaconda-clean --yes
# 4.删除Anaconda备份目录,.anaconda_backup,在用户目录下
# 5.删除Anaconda安装目录下的的envs和pkgs目录(这2个很大很大,一般10G以上),也可以直接卸载Anaconda,这些文件都会删除
# 6.打开「添加删除程序」,并且卸载 Anaconda
# 7.重启计算机总结
课堂作业
- 在自己的电脑上,安装Anaconda,并配置好环境变量🎤
4.Jupyter Notebook ✏️
Jupyter Notebook

Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。——Jupyter Notebook官方介绍
简而言之,Jupyter Notebook是以网页的形式打开,可以在网页页面中「直接」编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
1. 安装Jupyter Notebook
因为已经安装了Anaconda,所以Jupyter Notebook已经安装好了,无需单独安装。
直接在开始菜单中找到图标,点击即可打开即可
如果没有图标,则在Anaconda Prompt中输入以下命令:
jupyter notebook
自动打开浏览器,自动跳转到Jupyter Notebook的首页。
当执行完启动命令之后,浏览器将会进入到Notebook的主页面,如下图所示。
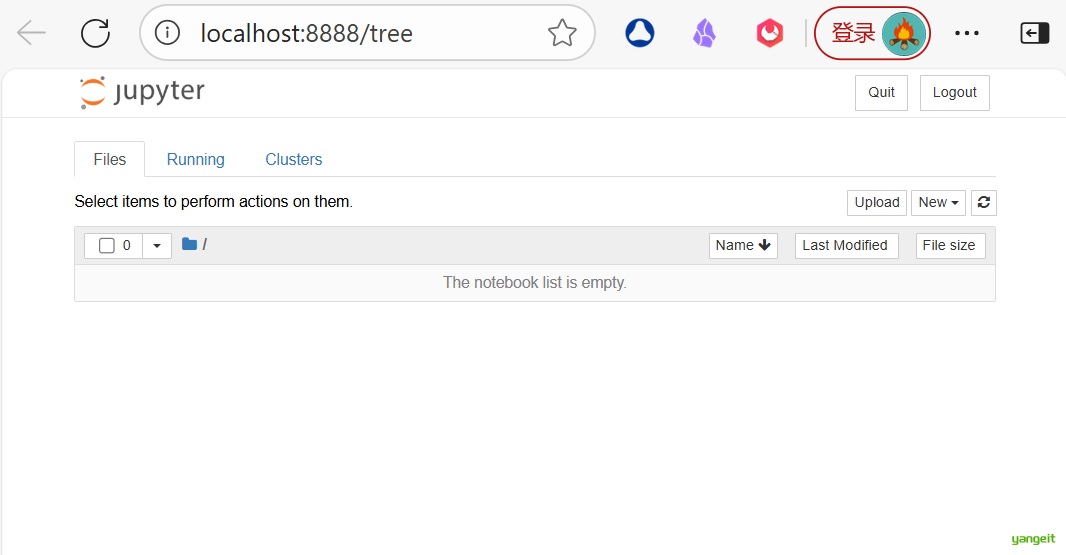
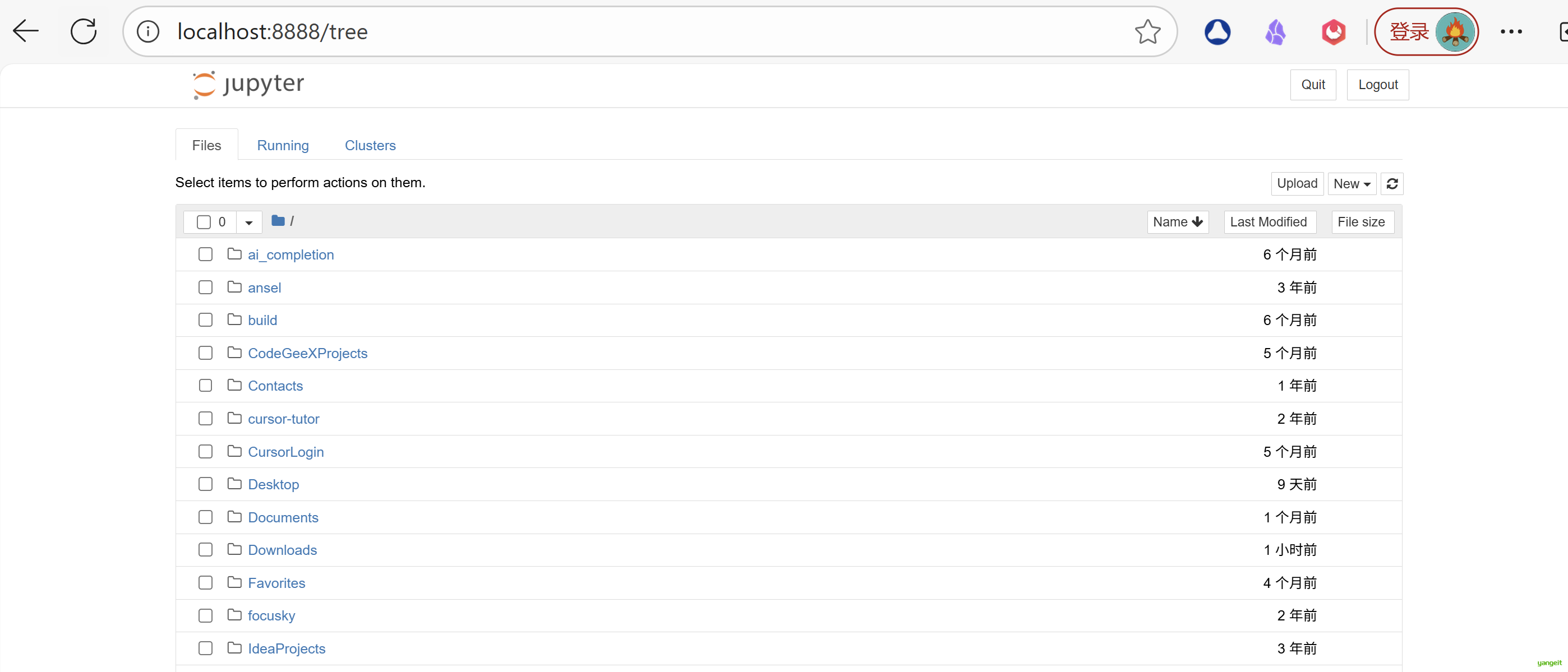
如果你的主页面里边的文件夹跟我的不同,或者你在疑惑为什么首次启动里边就已经有这么多文件夹,不要担心,这里边的文件夹全都是你的家目录里的目录文件。接下来
我们设置Jupyter Notebook文件存放位置:
- 在非中文目录下创建一个文件夹,例如:
D:\javasoftware\jupyter_notebook - 在Anaconda Prompt中输入以下命令:
# 生成配置文件
jupyter notebook --generate-config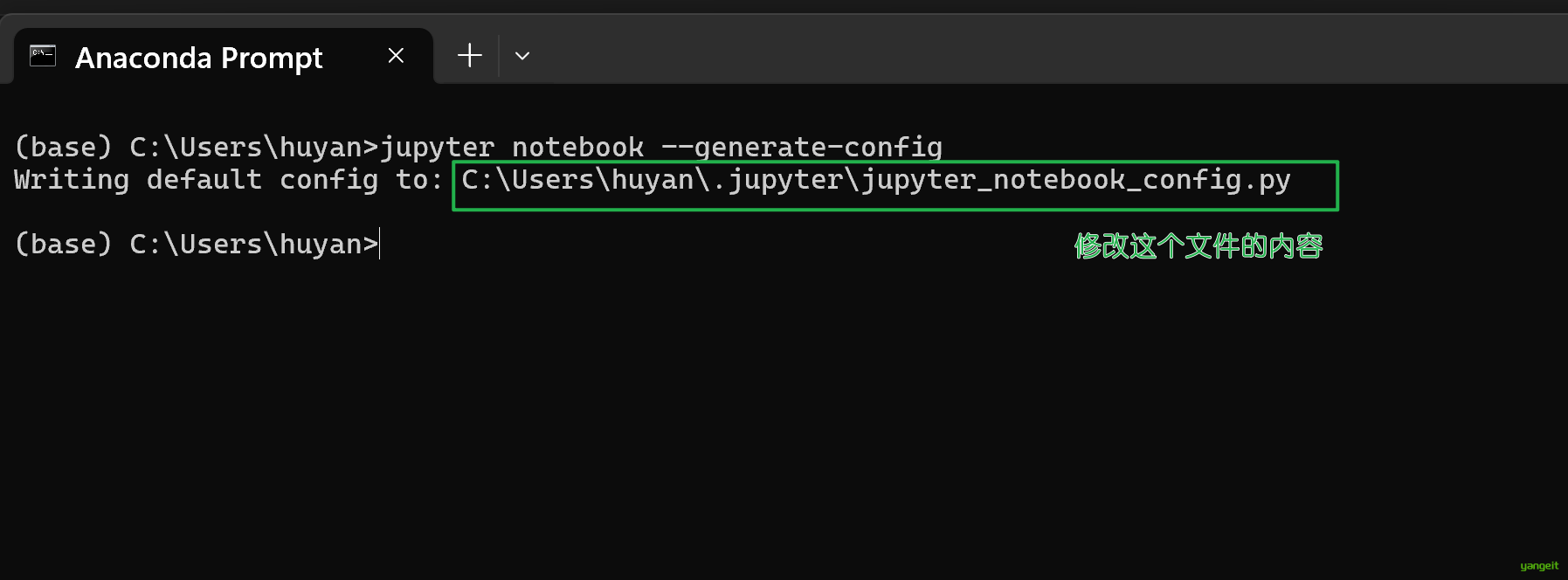
- 打开生成的配置文件,找到以下内容,修改为:
# c.NotebookApp.notebook_dir = ''
c.NotebookApp.notebook_dir = 'D:\\javasoftware\\jupyter_notebook'
- 保存并关闭配置文件,重新启动Jupyter Notebook,即可看到文件已经改变到我们指定的目录下。
2. Jupyter Notebook界面介绍
主页面内容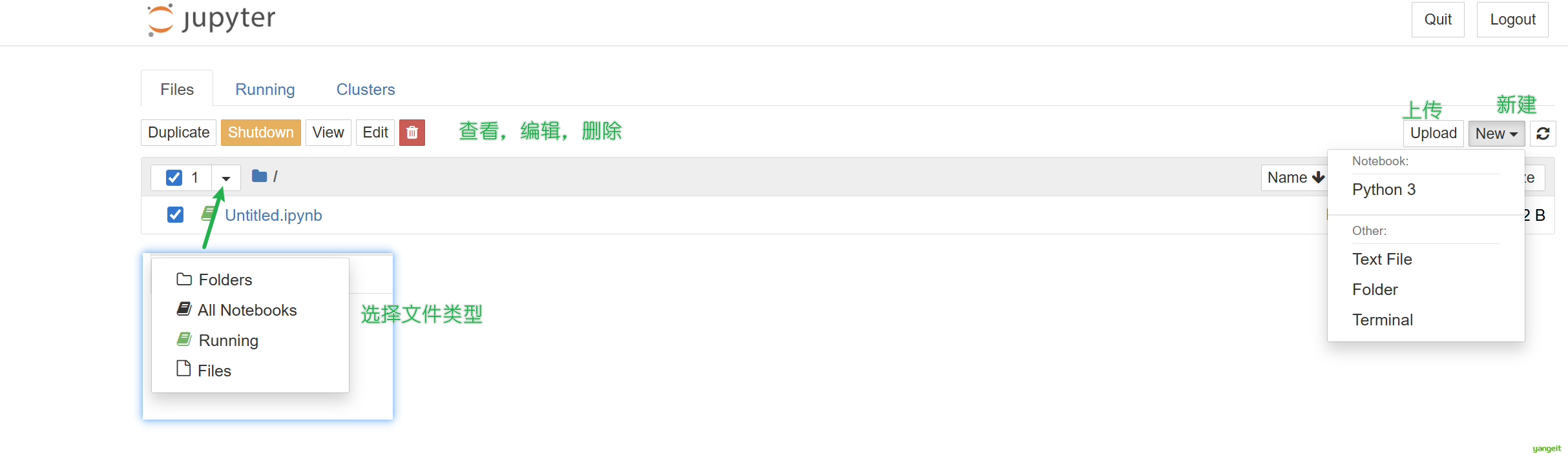
编辑界面(Notebook Editor)
一个notebook的编辑界面主要由四部分组成:名称、菜单栏、工具条以及单元(Cell),如下图所示:
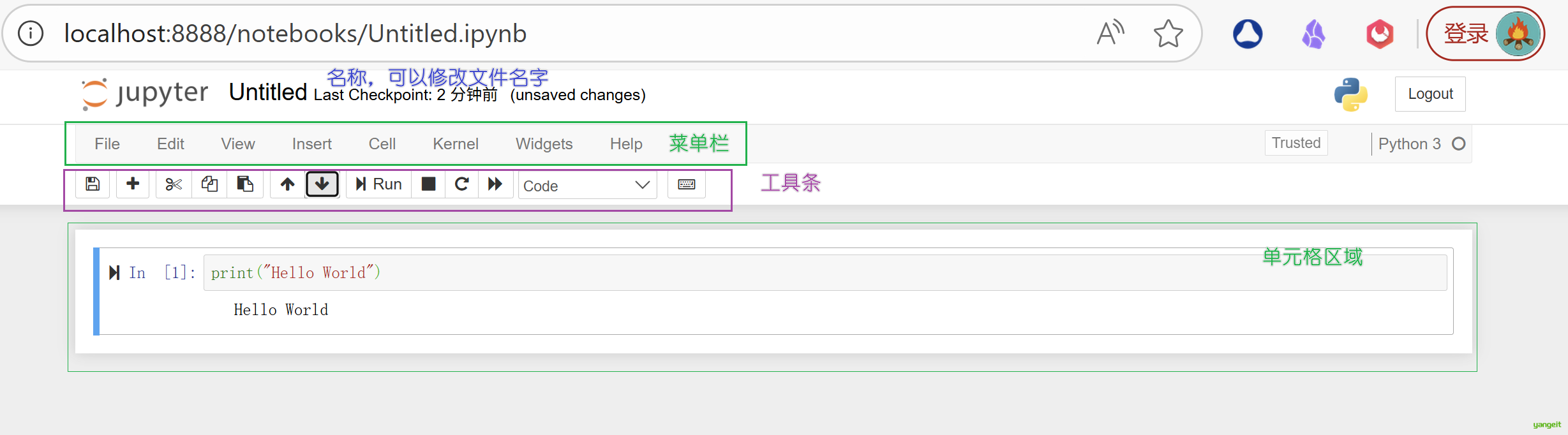
3. Jupyter Notebook的常用快捷键
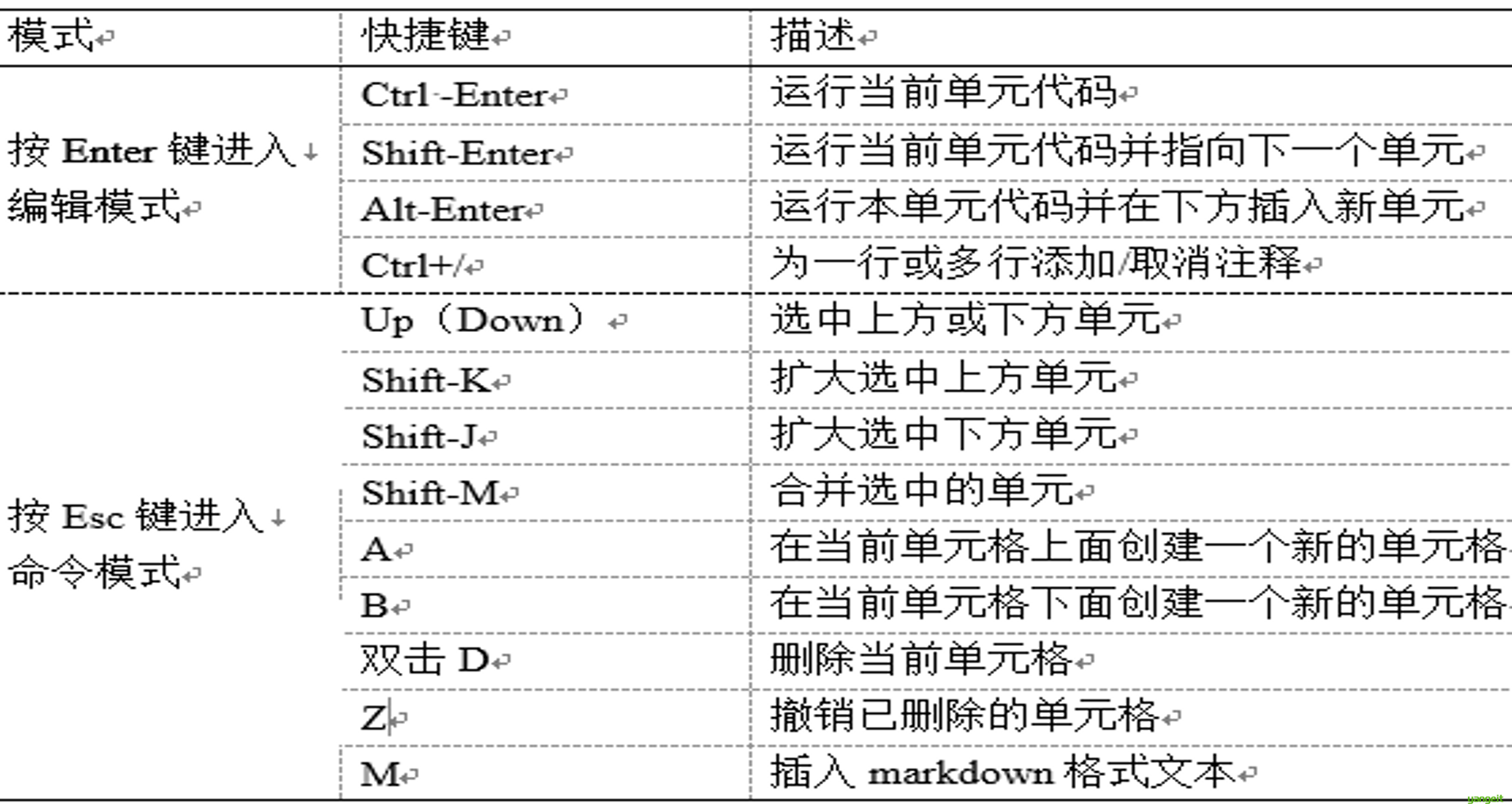
好,接下来,我们在Jupyter Notebook中编写第一个程序,来体验一下Jupyter Notebook的强大之处吧!!
print("Hello World!")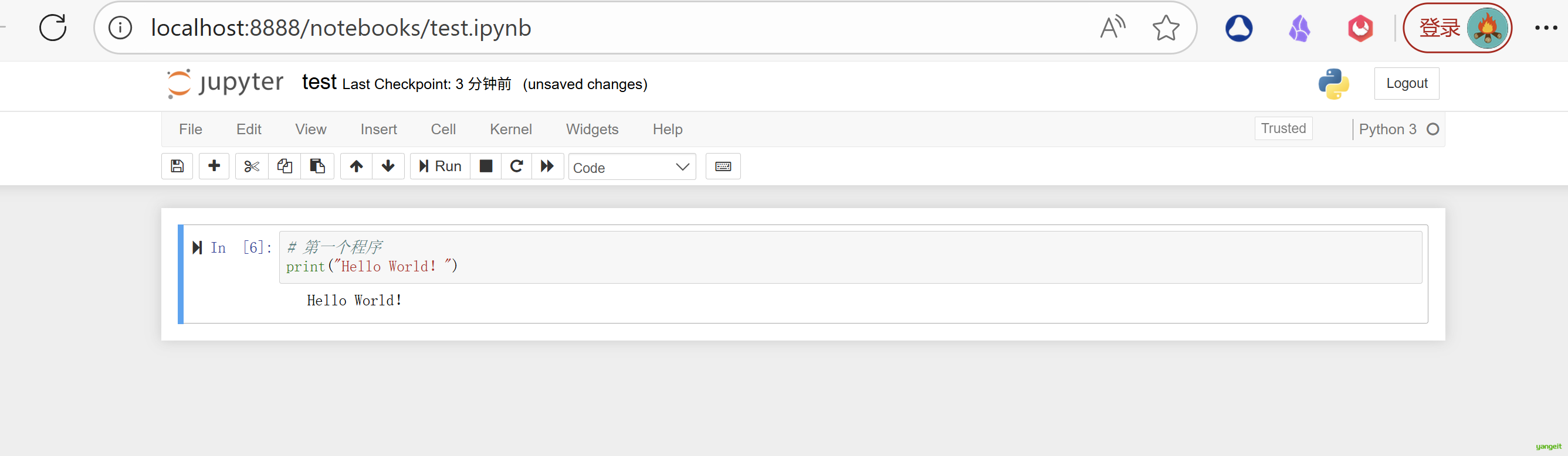
总结
课堂作业
- 在Jupyter Notebook中编写第一个程序,来体验一下Jupyter Notebook的强大之处吧!!
第二章 认识数据
1.认识数据
认识数据
1. 数据对象和属性
数据集 由 数据对象 组成,每个数据对象表示一个实体。
例如,在选课数据库中,对象可以是教师,课程或者学生,在医疗数据库中,对象可以是患者。
数据对象又称为实例、样本、对象。如果数据对象存放在数据库中,则他们称为元组。
一般数据库的行对应数据对象,列对应属性。
属性(Attribute):一个数据字段,表示 数据对象 的一个特征 ,属性的取值范围决定了属性的类型 。
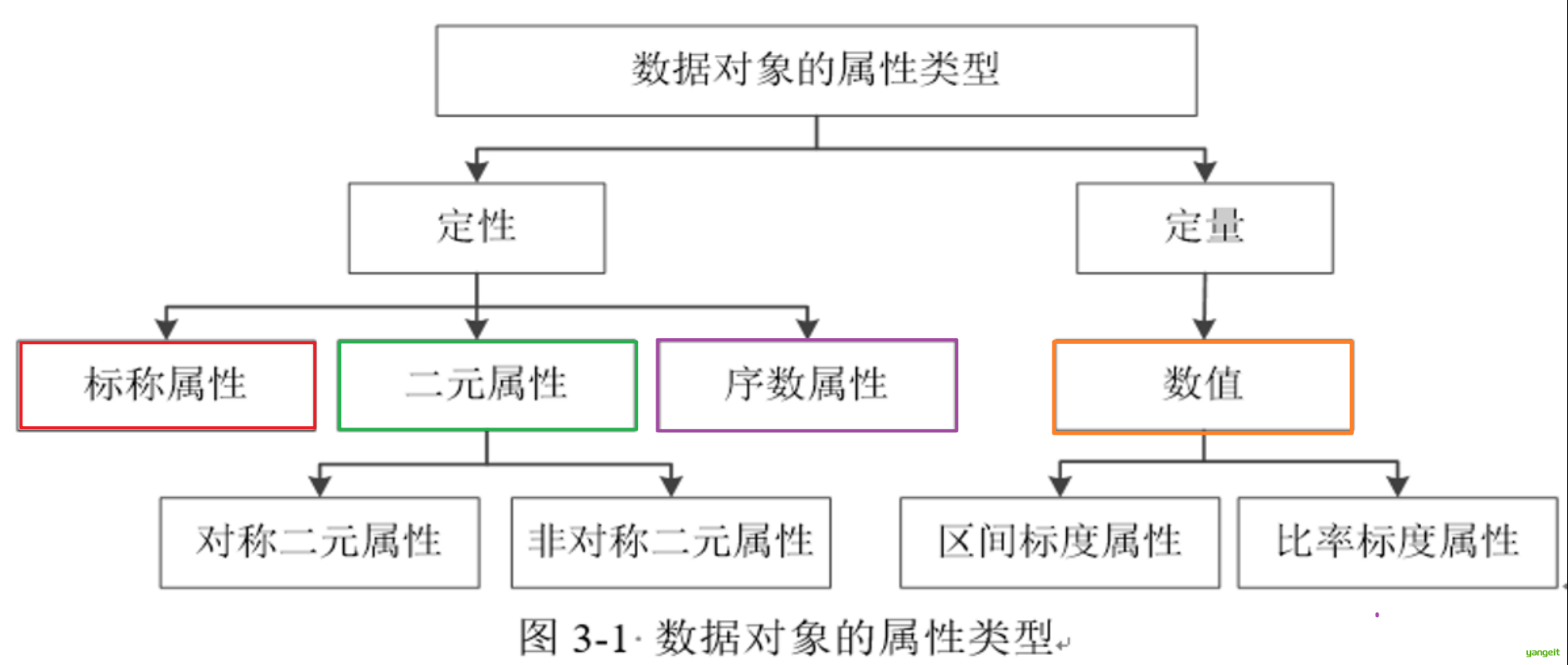
以下是一个超市顾客数据的案例,用一句话说明四种属性类型及其用途:
| 属性类型 | 案例 | 定义 | 典型用途 |
|---|---|---|---|
| 标称属性 | 顾客性别(男/女) | 无顺序的离散分类值 | 客户分群统计 |
| 二元属性 | 是否会员(是/否) | 只有两个状态的标称属性 | 快速筛选目标用户 |
| 序数属性 | 满意度等级(1-5星) | 有顺序但无明确量化的分类值 | 评价趋势分析 |
| 数值属性 | 消费金额(¥368) | 可数学计算的连续/离散值 | 预测模型输入 |
示例:超市通过分析这些属性,发现"女性会员的满意度与消费金额正相关",据此优化了会员福利策略
注意 :数值属性是定量的,可以是离散的,也可以是连续的,但是标称属性,二元属性 和序数属性是定性的,是离散的,只能表示类别。
2.数据的基本统计描述
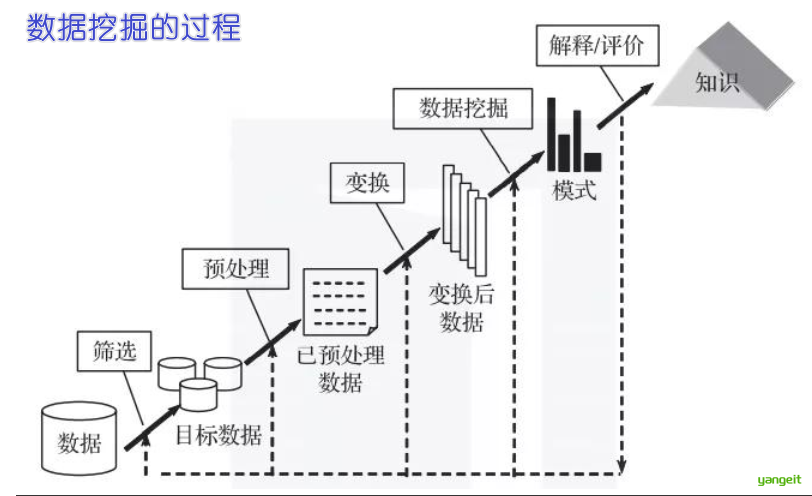
把握数据的分布对于成功的数据预处理是至关重要的。基本的数据统计描述可以识别数据的性质,并凸显哪些数据应被视为噪声或离群点
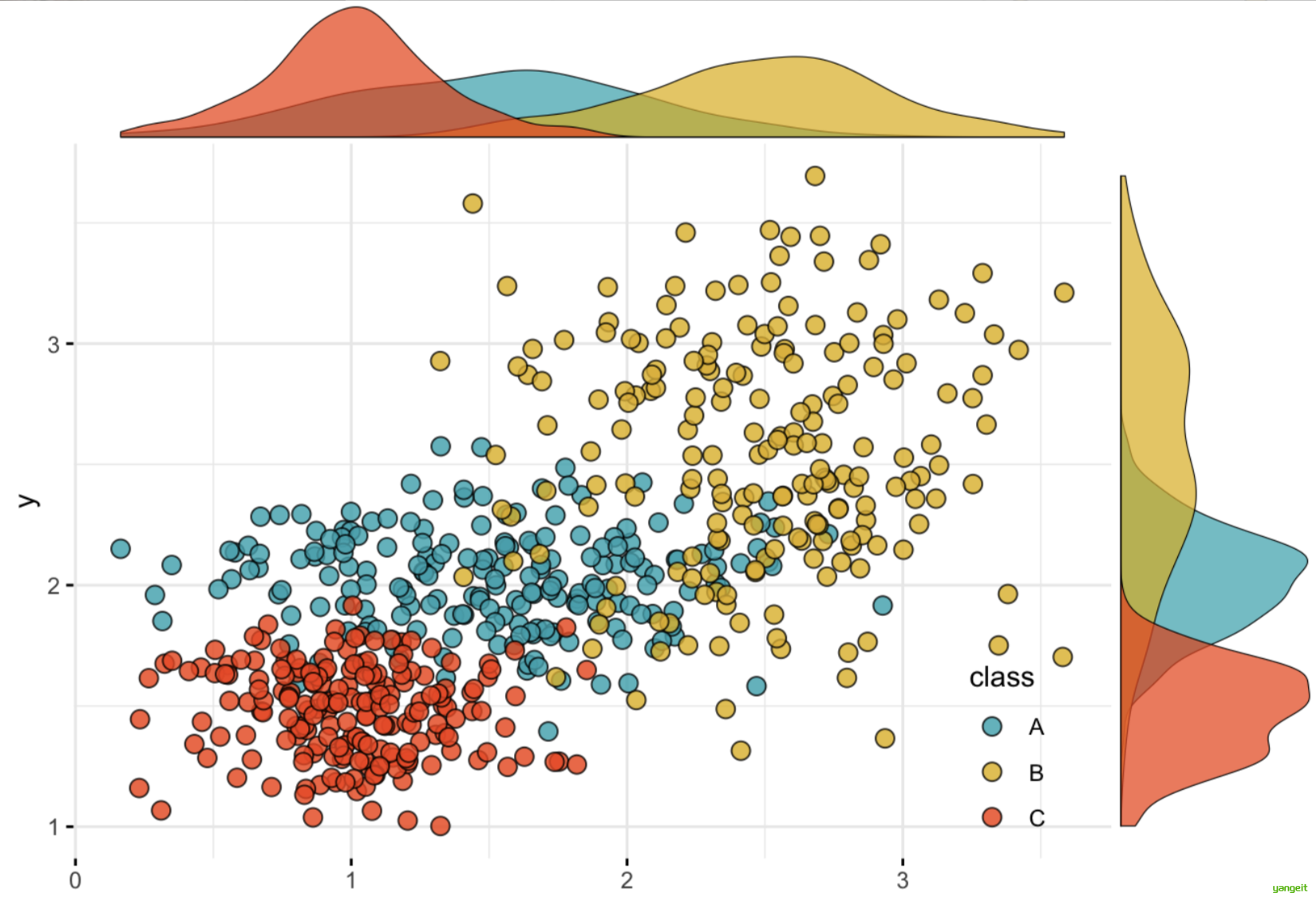
数据的描述性统计主要包括数据的集中趋势、离中趋势、相对离散程度和分布的形状四个方面
2.1 中心趋势度量
中心趋势度量:在统计学中是指一组数据向某一中心值靠拢的程度,它反映了一组数据中心点的位置所在。中心趋势度量就是寻找数据水平的代表值或中心值。中心趋势度量包括均值、中位数、众数和中列数.
| 统计量 | 定义 | 示例(数据集[1,2,2,6,10]) | 典型用途 | 受异常值影响 | 适用数据类型 |
|---|---|---|---|---|---|
| 均值 | 数据总和除以数量,反映平均水平 | (1+2+2+6+10)/5 = 4.2 | 工资、成绩等连续数据的总体衡量 | 高 | 数值型 |
| 中位数 | 排序后中间的值,抗极端值干扰 | 第3位数值 = 2 | 房价、收入等偏态分布数据的中等水平 | 低 | 数值型 |
| 众数 | 出现频率最高的值 | 数值2出现2次 = 2 | 最畅销商品、用户偏好等分类数据统计 | 无 | 所有类型 |
| 中列数 | 最大值与最小值的平均数 | (10+1)/2 = 5.5 | 温度、股价等范围数据的快速估算 | 高 | 数值型 |
注: 众数适用于标称属性(如颜色)、序数属性(如评分等级)和数值属性(如年龄),但二元属性(如性别)需先转换为分类形式。
代码实操:【例2-2】利用pandas统计中位数、均值和众数✏️
import pandas as pd
df = pd.DataFrame([[1, 2], [7, -4],[3, 9], [4, -4],[1,3]],
columns=['one', 'two'])
display(df)
print('中位数:\n',df.median())
print('均值:\n',df.mean(axis=1))
print('众数:\n',df.mode())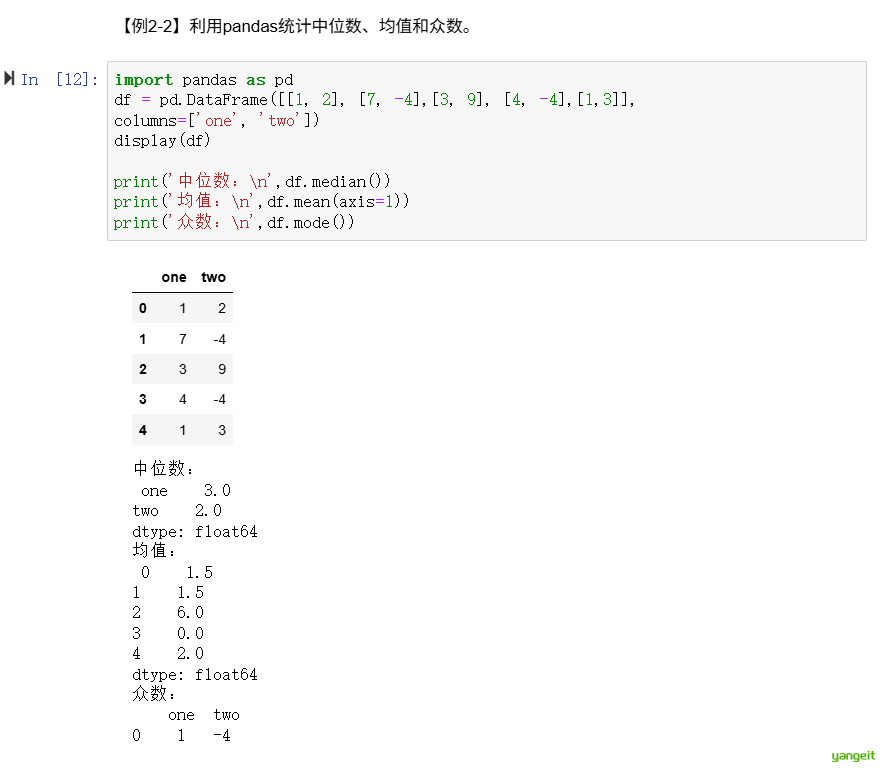
2.2 数据散布度量
数据散布度量用于评估数值数据散布或发散的程度。散布度量的测定是对统计资料分散状况的测定,即找出各个变量值与集中趋势的偏离程度通过度量散布趋势。
数据散布度量包括极差、分位数、四分位数、百分位数和四分位数极差。方差和标准差也可以描述数据分布的散布。
2.2.1 极差、四分位数和四分位数极差
| 指标 | 定义 | 计算方法 | 敏感度 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|---|---|
| 极差(Range) | 最大值与最小值的差 | Range = Max(X) - Min(X) | 高 | 计算简单直观 | 易受异常值影响 | 快速了解数据范围 |
| 四分位数 | 数据四等分的分割点 | - Q1: 25%分位数 - Q2: 中位数(50%) - Q3: 75%分位数 | 低 | 抗异常值,反映分布位置 | 需排序计算 | 箱线图、数据分布分析 |
| 四分位数极差(IQR) | Q3与Q1的差(中间50%数据范围) | IQR = Q3 - Q1 | 低 | 稳健衡量离散度 | 忽略两端25%数据 | 异常值检测、稳健统计 |
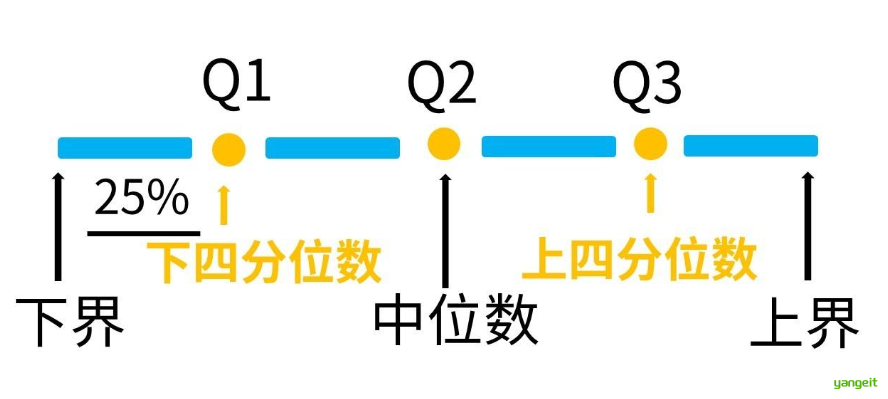
理解四分位数:中位数把数集分成两个50%,下四分位就是把前50%分成两个25%,上四分位就是把后50%,分成两个25%。
示例数据对比
| 数据集 | 极差 | Q1 | Q2 | Q3 | IQR |
|---|---|---|---|---|---|
| [1, 3, 5, 7, 9] | 8 | 3 | 5 | 7 | 4 |
| [1, 3, 5, 7, 100] | 99 | 3 | 5 | 7 | 4 |
代码实操:【例2-3】统计数据的分位数等统计量。✏️
import pandas as pd
df = pd.DataFrame([[1, 1], [3, 3],[5, 5], [7, 7], [9, 100]],
index=['a', 'b', 'c', 'd', 'e'],columns=['one', 'two'])
display(df)
df.describe()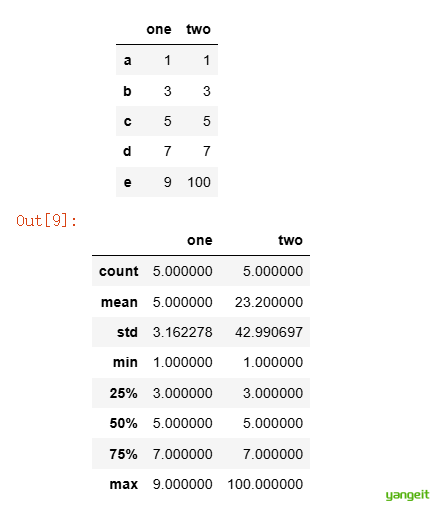
2.2.2 五数概括、盒图与离群点
1. 五数概括:五数概括(Five Number Summary)是数据集的五个统计量,包括最小值、下四分位数、中位数、上四分位数和最大值。五数概括可以快速了解数据分布,识别异常值。
2. 盒图也叫箱线图(Box Plot),是五数概括的可视化表示, 可以用来观察数据整体的分布情况,利用中位数,25/%分位数,75/%分位数,上边界,下边界等统计量来来描述数据的整体分布情况。
3. 离群点(Outlier)是指与数据集其他部分显著不同的数据点,通常由异常值引起。离群点对数据分析和建模有重要影响,需要特别关注。
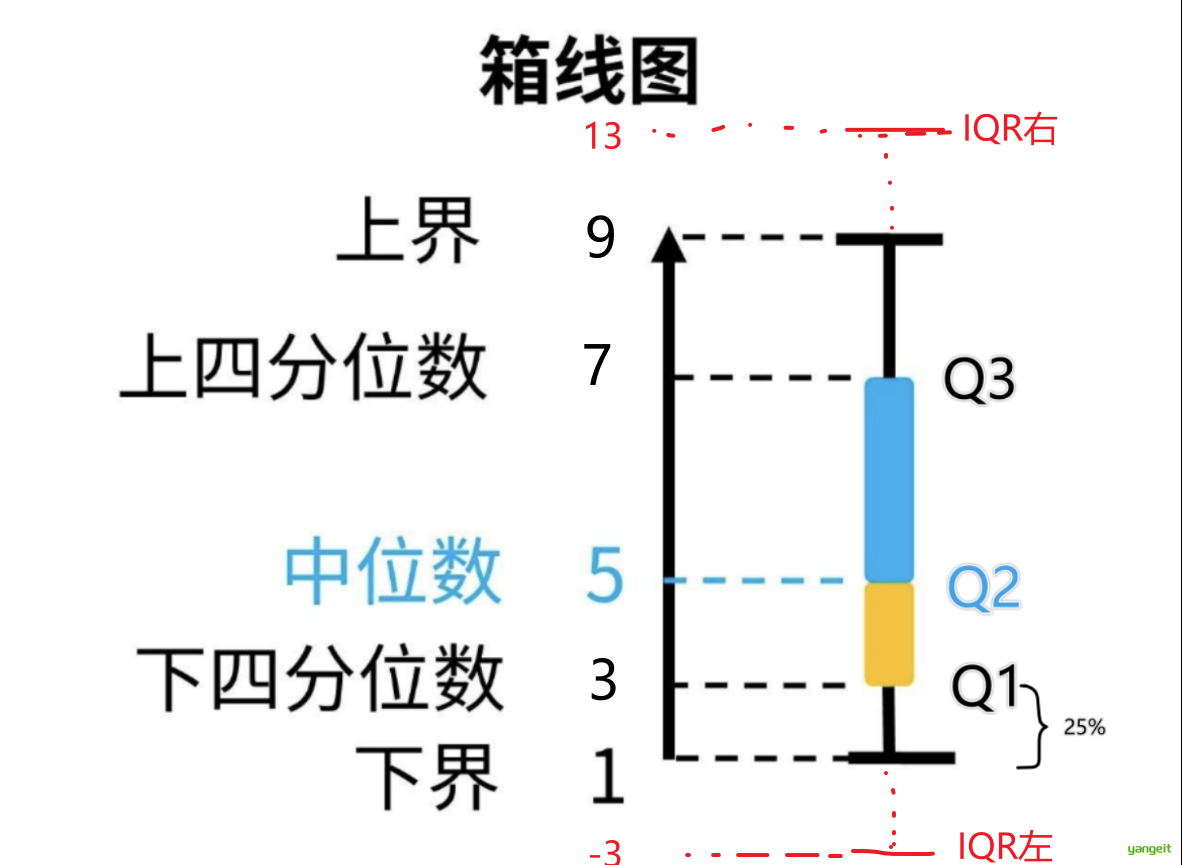
中位数距离下四分位数较近,代表大部分数值在Q1和Q2之间
当数值大于 最大估计值 或 数值小于 最小估计值,都记为异常
上述示例数据的第二组数据,边界值为[-3,13],而最大值是100,所以100是异常值。
关键说明 👇 🍐 ❤️
- 敏感度:极差对异常值敏感,IQR更稳定。
- 异常值规则:超出
[Q1-1.5IQR, Q3+1.5IQR]视为异常。 - 可视化:箱线图直接展示Q1/Q3/IQR和异常值
代码实操:【例2-4】利用matplotlib绘制箱线图。✏️
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
%notebook inline
np.random.seed(2) #设置随机种子
df = pd.DataFrame(np.random.rand(5,4),
columns = ['A', 'B', 'C', 'D'])
#生成0-1之间的5*4维度数据并存入4列DataFrame中
plt.boxplot(df)
# 显示表格
display(df)
df.describe()
# 显示箱线图
plt.show()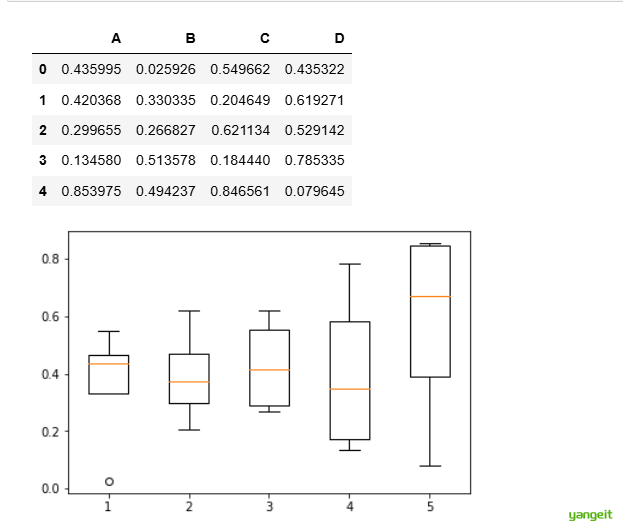
思考:如何判断异常值?
总结
课堂作业
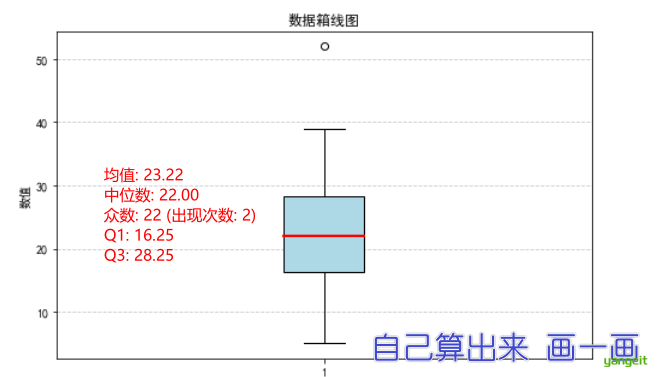
- 假设有数据属性取值(以递增序)为5、9、13、15、16、17、19、21、22、22、25、26、26、29、30、32、39、52。分别计算该列数的均值、中位数、众数,并粗略估计第一四分位数和第三四分位数,绘制该数据的箱线图。
2.数据可视化
认识数据
1. 数据可视化

数据可视化:(Data Visualization)通过图形清晰有效地表达数据。它将数据所包含的信息的综合体,包括属性和变量,抽象化为一些图表形式。
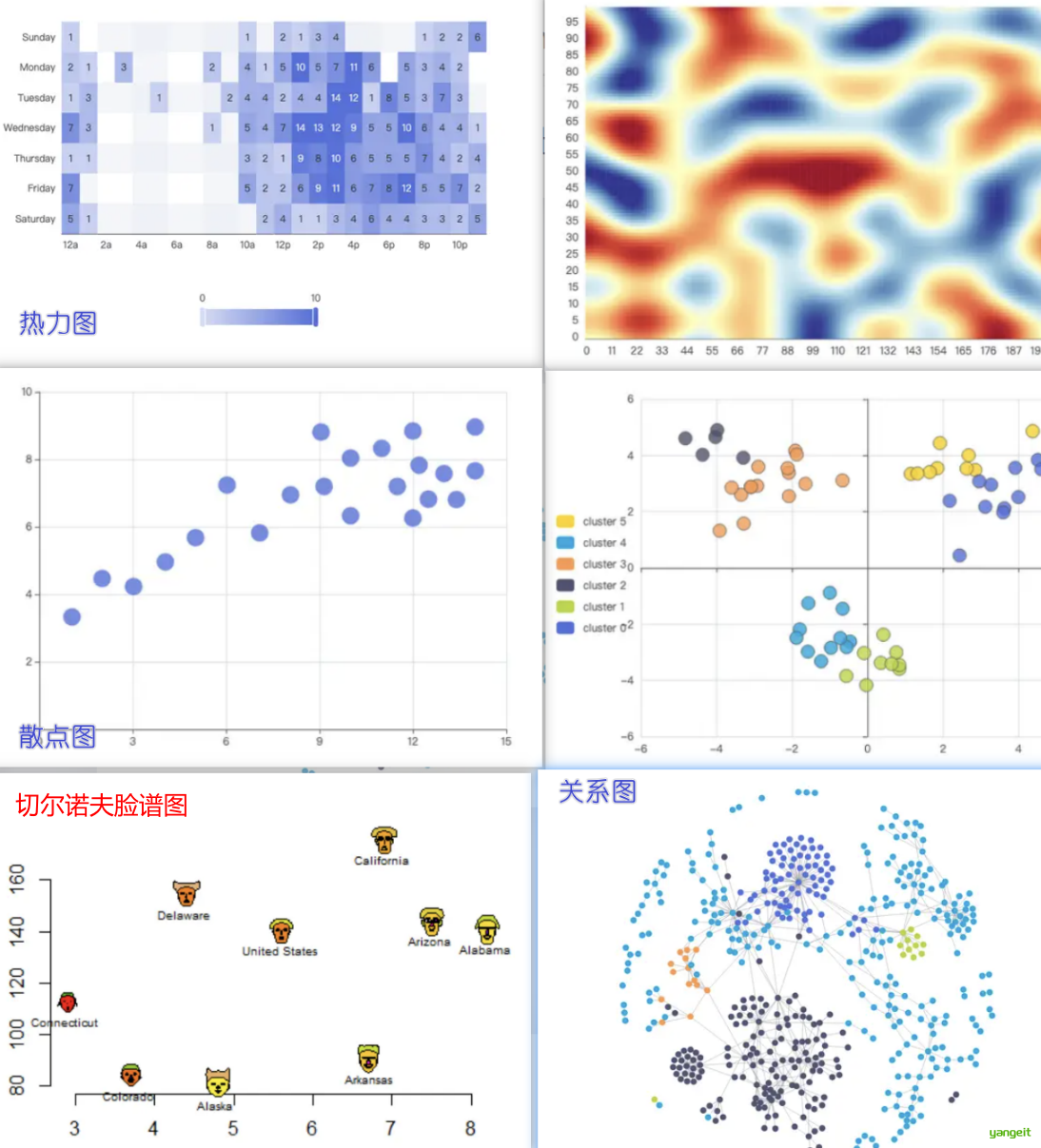
数据可视化方法包括 :
- 基于像素的技术
- 几何投影技术
- 基于图符的技术和基于图形的技术
| 可视化方法 | 定义 | 示例 | 典型用途 | 特点 |
|---|---|---|---|---|
| 基于像素的技术 | 将每个数据值映射为屏幕上的一个彩色像素 | 热力图 | 高维数据密集展示 | • 适合大规模数据 • 可能丢失细节 • 需合理设计颜色映射 |
| 几何投影技术 | 通过数学投影将高维数据降维到2D/3D空间展示 | 散点图、平行坐标图 | 探索数据关系 | • 保留数据关系 • 不同算法关系 • 不同算法侧重不同特性(如PCA保距,t-SNE保局部结构) |
| 基于图符的技术 | 用图标/符号的视觉特征(大小、颜色、形状)编码多维数据属性 | 人物线条图、切尔诺夫脸谱 | 多维数据对比分析 | • 直观形象 • 维度受限(通常≤10维) • 需训练读图能力 |
| 基于图形的技术 | 利用节点和边的关系网络展示数据关联 | 社交网络图、知识图谱 | 关系型数据分析 | • 显式展示连接 • 布局算法影响效果(如力导向布局) • 需防视觉混乱 |
注意:几何投影技术帮助发现多维数据集的有趣投影。 难点:在二维显示上可视化高维空间
2.Python可视化
在Python中,使用最多的数据可视化工具是Matplotlib,除此之外还有很多其他可选的可视化工具包,主要包括以下几类。
- (1)Matplotlib以及基于Matplotlib开发的工具包:Pandas中的封装Matplotlib API的画图功能,Seaborn和networkx等;
- (2)基于JavaScript和d3.js开发的可视化工具,如plotly等,这类工具可以显示动态图且具有一定的交互性;
- (3)其他提供了Python调用接口的可视化工具,如OpenGL,GraphViz等,这一类工具各有特点且在特定领域应用广泛。
1.代码演示:【例2-5】python绘制散点图示例。✏️
import matplotlib.pyplot as plt
import numpy as np
n = 50
# 随机产生50个0~2之间的x,y坐标
x = np.random.rand(n)*2
y = np.random.rand(n)*2
colors = np.random.rand(n)
# 随机产生50个0~1之间的颜色值
area = np.pi * (10 * np.random.rand(n))**2
# 点的半径范围:0~10
plt.scatter(x, y, s=area, c=colors, alpha=0.5, marker=(9, 3, 30))
plt.show()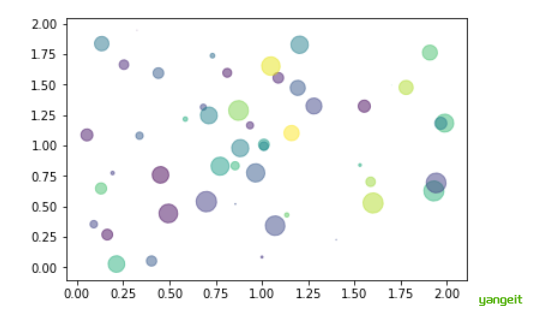
2.代码演示:【例2-6】Python绘制散点图矩阵示例。✏️
import seaborn as sns
df_iris = sns.load_dataset('iris')
sns.set(style = "ticks")
g = sns.pairplot(df_iris,vars = ['sepal_length', 'petal_length'])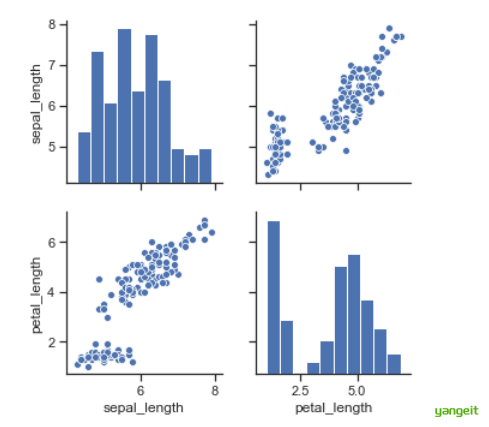
3.代码演示:【例2-7】Python绘制平行坐标图示例。✏️
from pyecharts.charts import Parallel
import pyecharts.options as opts
import seaborn as sns
import numpy as np
data = sns.load_dataset('iris')
data_1 = np.array(data[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]).tolist()
parallel_axis = [
{"dim": 0, "name": "萼片长度"},
{"dim": 1, "name": "萼片宽度"},
{"dim": 2, "name": "花瓣长度"},
{"dim": 3, "name": "花瓣宽度"},
]
parallel = Parallel(init_opts=opts.InitOpts(width="600px", height="400px"))
parallel.add_schema(schema=parallel_axis)
# parallel.config(schema)
parallel.add('iris平行图',data=data_1,linestyle_opts=opts.LineStyleOpts(width=4, opacity=0.5))
parallel.render_notebook()
如果使用jupyter notebook,需要安装pyecharts
pip install pyecharts剩余的效果可以查看,焱哥发送的Ch2_认识数据.ipynb文件
总结
课堂作业
- 数据可视化技术主要有哪些?简述高维数据可视化的方法有哪些?
3.数据对象的相似性度量
前言
1. 为什么要学习相似性度量?
现实中,我们需要处理的数据具有着不同的形式和特征。而对数据相似性的度量又是数据挖掘分析中非常重要的环节。听上去不好理解,举个栗子:👇
例子1: 👇
问题背景:某电商平台希望提升用户体验,希望向用户推荐他们可能感兴趣的商品。例如:
用户A刚刚购买了一部智能手机。系统需要从海量商品中找到与这部手机“相似”的商品,比如手机壳、耳机、充电宝等,而不是推荐完全不相关的商品(比如蔬菜或家具)。
关键挑战:
如何定义“相似”?不同商品之间的相似性如何计算?
例子2: 👇
假设某电商平台有以下用户行为数据:
用户A = [购买5次, 月活20天, 平均浏览时长10分钟]
用户B = [购买3次, 月活18天, 平均浏览时长8分钟]
用户C = [购买0次, 月活2天, 平均浏览时长1分钟]关键问题 :如何自动识别高价值用户群体?
- 直观观察:"用户A和B的行为模式是否比用户C更相似?"
- 数学表达需求:如何用数值精确衡量这种相似程度?
- 引入相似性度量:如欧式距离,余弦相似度等
- 业务应用: "通过相似性度量,系统可自动将用户A和B划分为同一高价值群体,实施精准营销策略"
代码如下:
# 欧氏距离计算:
import numpy as np
用户A = [5, 20, 10]
用户B = [3, 18, 8]
用户C = [0, 2, 1]
def euclidean(a, b):
return np.sqrt(sum((np.array(a) - np.array(b))**2))
print("用户A与用户B的欧氏距离:",euclidean(用户A, 用户B)) # 输出:3.7
print("用户A与用户C的欧氏距离:",euclidean(用户A, 用户C)) # 输出:13.3
# 余弦相似度计算:
from sklearn.metrics.pairwise import cosine_similarity
print("用户A与用户B的余弦相似度:",cosine_similarity([用户A], [用户B])) # 输出:0.997
# 输出:
用户A与用户B的欧氏距离: 3.4641016151377544
用户A与用户C的欧氏距离: 20.73644135332772
用户A与用户B的余弦相似度: [[0.99663582]]通过上述案例,我们可知:相似性度量是数据挖掘分析中非常重要的环节。针对不同形式的数据,不可能有一种万能的相似性度量方法。因此,我们需要根据数据类型和业务需求选择合适的相似性度量方法。
2. 相似性度量方法有哪些?
数据相似性度量全景对比表 🍐
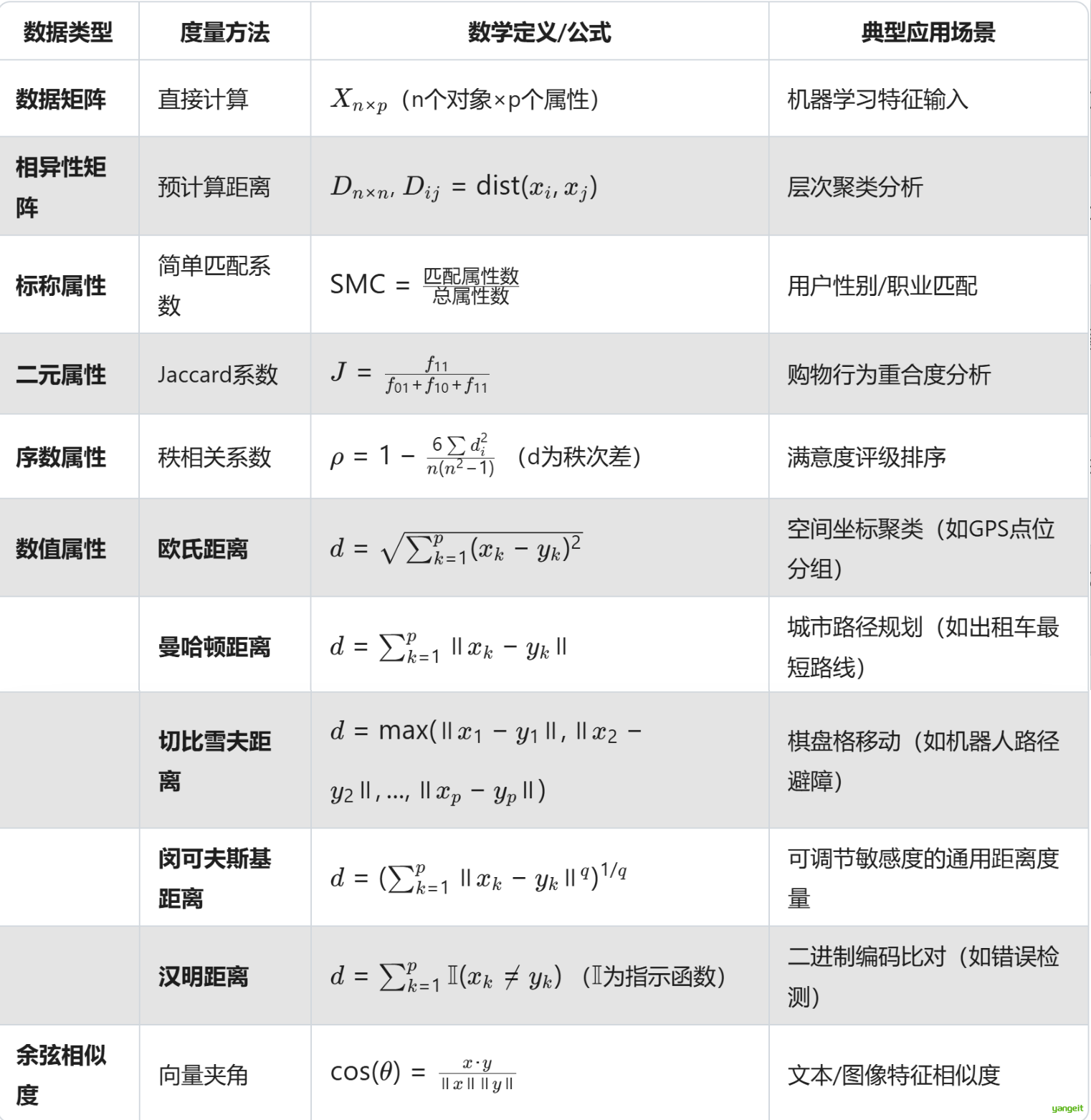
Jaccard距离 = 1 - Jaccard系数(用于聚类分析)
数值属性距离度量对比🍐 ❤️
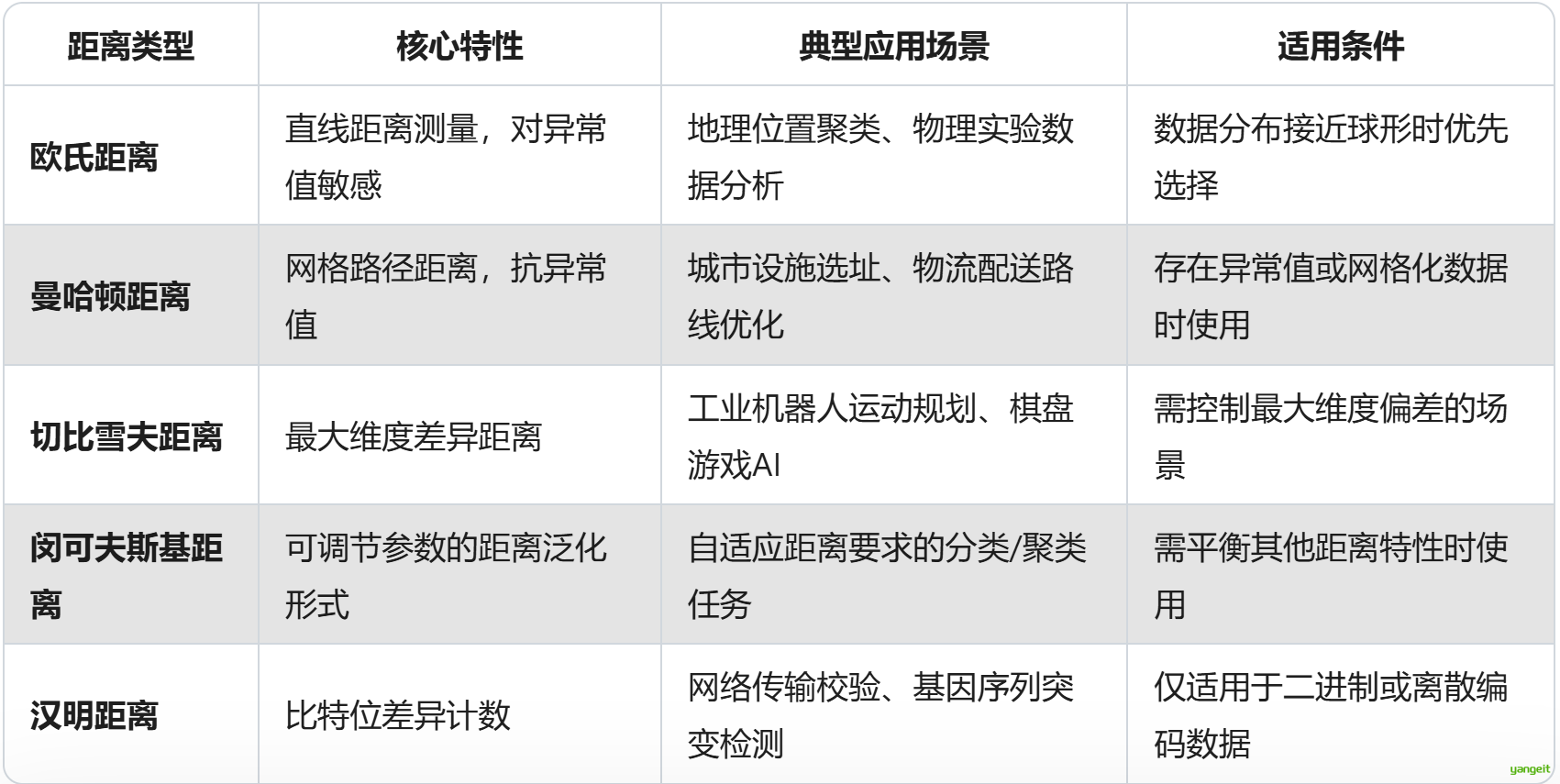
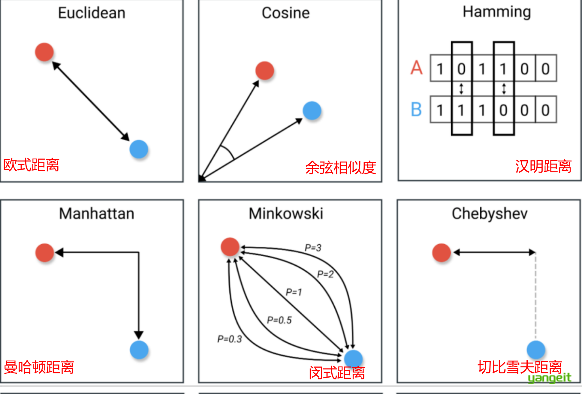
闵可夫斯基距离:通过调整q值可模拟其他距离(q=1→曼哈顿,q=2→欧氏)(q为公式中的指数)
Python实现距离度量
用Numpy实现常见的距离度量方法,代码如下:
import numpy as np
# 欧式距离(Eulidean distance)
def euclidean(x, y):
return np.sqrt(np.sum((x-y)**2))
# 曼哈顿距离(Manhattan distance)
def manhattan(x,y):
return np.sum(np.abs(x-y))
#切比雪夫距离(Chebyshev distance)
def chebyshev(x,y):
return np.max(np.abs(x-y))
# 闵可夫斯基距离(Minkowski distance)
def minkowski(x,y,p):
return np.sum(np.abs(x-y)**p)**(1/p)
# 汉明距离(Hamming distance)
def hamming(x, y):
return np.sum(x!=y)/len(x)
# 余弦距离
def cos_similarity(x, y):
return np.dot(x,y)/(np.linalg.norm(x)*np.linalg.norm(y))
# 创建示例向量
v1 = np.array([1, 2, 3])
v2 = np.array([4, 5, 6])
# 计算各种距离/相似度
print("欧氏距离:", euclidean(v1, v2)) # 输出:5.196152422706632
print("曼哈顿距离:", manhattan(v1, v2)) # 输出:9
print("切比雪夫距离:", chebyshev(v1, v2)) # 输出:3
print("闵可夫斯基距离(p=3):", minkowski(v1, v2, 3)) # 输出:4.3267487109222245
print("汉明距离:", hamming(v1, v2)) # 输出:1
print("余弦相似度:", cos_similarity(v1, v2)) # 输出:0.9746318461970762
案例:使用scipy的pdist进行数据对象的距离计算
X 是一个 2×9 的矩阵(两行九列),表示 2个9维向量。当您使用 pdist(X) 计算欧氏距离时,它计算的是这两个9维向量之间的直线距离。
无法直接可视化,因为数据是高维的(9维),但可以想象为两个点在9维空间中的距离。
欧氏距离的本质:无论维度多高,都是两点之间的直线距离
import numpy as np
from scipy.spatial.distance import pdist
x=(0.7,0.9,0.2,0.3,0.8,0.4,0.6,0,0.5)
y=(0.6,0.8,0.5,0.4,0.3,0.5,0.7,0.2,0.6)
X=np.vstack([x,y])
d1= pdist(X, 'euclidean')
print('欧式距离:',d1)
d2=pdist(X,'cityblock')
print('曼哈顿距离:',d2)
d3=pdist(X,'chebyshev')
print('切比雪夫距离:',d3)
d4=pdist(X,'minkowski',p=2)
print('闵可夫斯基距离:',d4)
d5=pdist(X,'cosine')
print('余弦相似性:',1-d5)输出:
欧式距离: [0.66332496]
曼哈顿距离: [1.6]
切比雪夫距离: [0.5]
闵可夫斯基距离: [0.66332496]
余弦相似性: [0.92032116]作业
课堂作业
- 计算数据对象 x=(2,4,3,6,8,2)和 y=(1,4,2,7,5,3)之间的欧氏距离曼哈顿距离和闵可夫斯基距离,其中闵可夫斯基距离中的p取值为3。
- 简述标称属性,非对称二元属性,数值属性和词频向量的相似度评价方法?🎤